
一种深度强化学习的机械臂控制方法
2021-01-21 06:35:52姬周珂徐巧玉王军委李坤鹏
河南科技大学学报(自然科学版) 2021年3期
姬周珂,徐巧玉,王军委,李坤鹏
(1. 河南科技大学 机电工程学院,河南 洛阳 471003;2. 洛阳银杏科技有限公司,河南 洛阳 471003)
0 引言
目前,随着工业领域大型装备使用需求的增多,液压机械臂广泛应用于重型工件及设备的运输装卸等任务中,但由于液压机械臂内部结构复杂、质量大、体积大,其控制易受到惯性、摩擦等因素的影响,因此液压机械臂的精确控制问题亟需解决[1-3]。
深度强化学习算法具备自主学习的特点,目前许多研究者基于深度强化学习对机械臂进行控制研究[4-9]。文献[10]提出了一种基于深度Q学习(deep-Q learning,DQN)算法的机械臂控制策略,采用了引导式DQN算法的控制策略,为了提高算法训练效率,在低精度要求的机械臂抓取任务中训练。文献[11]采用信赖域策略优化(trust region policy optimization,TRPO)算法对UR5机械臂进行到达目标点训练,训练到了一定的末端控制精度,但没有往更高精度进行探索。文献[12]基于归一化优势函数(normalized advantage function,NAF)算法在机械臂开门任务中训练,提高了机械臂到达门把手的准确度,但需要多个机械臂协同工作来促进算法收敛。文献[13]基于深度确定性策略梯度(deep deterministic policy gradient,DDPG)算法设计复合奖励函数来促进算法收敛,提高了机械臂在固定目标点抓取的精度,不足的是每个目标点需要分别进行训练。综上所述,目前深度强化学习机械臂控制算法在多个目标的精确控制方面研究较浅,在兼顾收敛速度和控制精度方面依然存在一定难度。
针对上述问题,本文提出了一种基于深度强化学习的机械臂控制方法。采用改进的DDPG算法与机器人操作系统(robot operating system,ROS)仿真机械臂交互训练,通过实际机械臂数据修正仿真机械臂的输出参数,基于低层奖励函数提高算法收敛速度,高层奖励函数提高机械臂末端控制精度,最终获得机械臂控制算法模型,从而进行机械臂末端的精确控制。
1 机械臂控制系统总体方案设计
深度强化学习机械臂控制系统总体方案设计框图如图1所示,该系统主要包括:仿真机械臂、机械
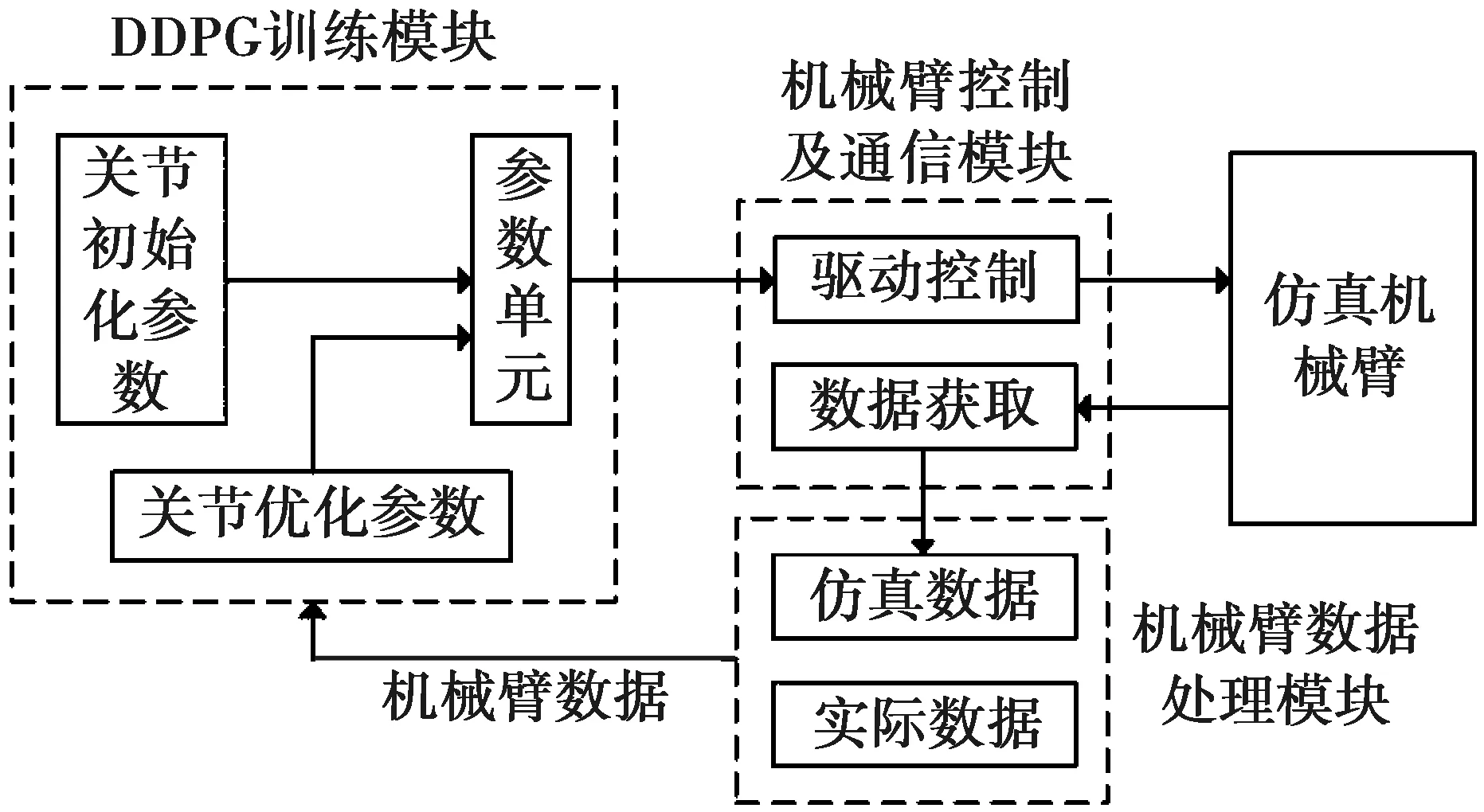
图1 机械臂控制系统总体方案设计框图
臂控制及通信模块、机械臂数据处理模块和DDPG训练模块。
仿真机械臂:根据实际机械臂参数搭建仿真机械臂,模拟实际机械臂的训练场景,并与深度强化学习算法进行交互训练,获得控制模型。
机械臂控制及通信模块:负责仿真机械臂的控制以及数据通信,包括驱动控制模块和数据获取模块。驱动控制模块输出机械臂的关节位置控制信号,数据获取模块获取机械臂根据关节控制信号动作后的数据。
机械臂数据处理模块:处理仿真机械臂数据和实际机械臂数据,将处理后的机械臂数据输出到DDPG训练模块。

图2 训练流程图
DDPG训练模块:包括关节初始化参数、关节优化参数以及参数单元。关节初始化参数为机械臂初始化时的关节参数。关节优化参数为经训练优化后的关节参数。参数单元传递关节参数,训练前输出关节初始化参数,训练过程中输出关节优化参数。
训练流程如图2所示,通过建立DDPG中Actor-Critic网络、分层奖励函数、回放经验池和仿真机械臂之间的联系,以迭代交互的方式来训练获得机械臂控制模型。
2 仿真机械臂的搭建
2.1 机械臂D-H运动学模型
本文以中信重工机械臂为原型搭建仿真机械臂,机械臂共6个关节,D-H运动学模型如图3所示。图3中:X0Y0Z0~X5Y5Z5坐标系为机械臂1~6关节的坐标系;d1、d3、d4、d5、L5、L6对应于各坐标系之间的位移变换,mm;X6Y6Z6为辅助坐标系,用于计算末端位置。

图3 机械臂D-H运动学模型
机械臂D-H参数如表1所示,其中:θi为Z轴旋转量,di为Z轴平移量,Li-1为X轴平移量,∂i-1为X轴旋转量。

表1 机械臂D-H参数表
2.2 机械臂输入状态、输出动作设计
在ROS环境中,按照中信重工机械臂的物理结构、关节范围、D-H坐标系以及质量、转动惯量等参数搭建仿真机械臂[14]。机械臂6个关节的运动范围不同,为方便算法处理,将机械臂各个关节的运动范围归一化到相同区间内。
机械臂的输入和输出以动作和状态来定义,为此进行了机械臂状态和控制动作的设计。机械臂的状态S如式(1)所示,其包含12维参数。
S=[x1,y1,z1,x2,y2,z2,a1,a2,a3,a4,a5,a6],
(1)
其中:(x1,y1,z1)为机械臂末端的三维坐标值;(x2,y2,z2)为目标点的三维坐标值;(a1,a2,a3,a4,a5,a6)为机械臂6个关节角度值。
机械臂的关节控制动作A如式(2)所示,其包含6维参数。
A=[△a1,△a2,△a3,△a4,△a5,△a6],
(2)
其中:△ai为机械臂关节的位置增量控制参数。
3 机械臂的控制、通信以及数据处理
3.1 机械臂的控制及通信模块
本文采用ROS节点实现仿真机械臂的控制与通信功能,通过ROS环境中的关节控制节点和数据获取节点设计驱动控制模块和数据获取模块,分别用来进行仿真机械臂的关节控制和数据获取。
在仿真环境中,为进行机械臂关节的位置控制,向驱动控制模块发送关节控制参数,从而使机械臂运动,改变机械臂的状态。机械臂运动后到达新的状态,通过数据获取模块获取机械臂状态数据,包括关节角度参数和末端位置参数。最终将状态数据送入数据处理模块中进行处理。
3.2 机械臂数据处理模块
因液压机械臂具有复杂的结构特性,仿真环境中的液压机械臂与实际机械臂有较大的输出偏差,为使仿真机械臂具有和实际机械臂相似的输入输出特性,本文通过数据引导的方式进行仿真机械臂输出参数的修正。实际机械臂和仿真机械臂的输出参数output如式(3)所示。
output=[a1,a2,a3,a4,a5,a6,x,y,z],
(3)
其中:(a1,a2,a3,a4,a5,a6)为机械臂关节参数;(x,y,z)为机械臂末端位置参数。
仿真机械臂和实际机械臂在输出相同关节参数的条件下,其输出的末端位置参数会有一定的偏差,△E=(△ex,△ey,△ez),△E代表末端在X、Y、Z这3个方向的偏差。在仿真环境中,数据处理模块根据偏差修正仿真机械臂的末端输出参数,从而达到仿真机械臂和实际机械臂输出参数接近的效果,在此条件下进行深度强化学习算法的训练。
4 基于DDPG的机械臂控制算法设计及改进
4.1 算法整体框架设计及应用
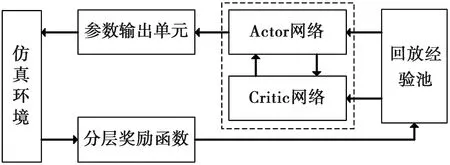
图4 DDPG控制算法整体框架
深度强化学习的机械臂控制算法通过机械臂数据进行训练,不断优化关节控制参数,从而实现机械臂的控制。本文机械臂控制算法基于DDPG框架进行设计与改进,DDPG控制算法整体框架如图4所示。
DDPG控制算法分为参数输出单元、分层奖励函数、回放经验池以及Actor-Critic网络几大部分,仿真环境用于与算法交互训练。参数输出单元输出机械臂关节控制参数,训练开始前先发送初始化关节参数到仿真环境中进行机械臂的初始化;分层奖励函数进行算法的奖励反馈,根据机械臂的状态进行奖励评价,将奖励数据和机械臂的状态数据一并送入到回放经验池中;回放经验池用来存储机械臂的状态数据和奖励数据;Actor网络和Critic网络之间进行参数传递,通过获取回放经验池中的数据进行训练,由Actor网络输出训练优化的机械臂关节控制参数,再经参数输出单元输出到机械臂环境中,以此迭代训练,最终输出机械臂控制算法模型。
4.2 Actor-Critic网络搭建
利用Actor-Critic网络进行策略函数和评价函数的拟合,本文采用Keras+Tensorflow的框架设计算法网络,通过设计Actor网络拟合控制策略函数,输出机械臂控制动作参数,设计Critic网络拟合评价函数,输出机械臂评价Q值。
将12维机械臂状态数据输入到Actor网络,采用全连接层神经网络进行训练,输出6个关节控制动作,将均值回归(Ornstein-Uhlenbeck,OU)噪声N添加到控制动作中进行探索,最终控制策略at如式(4)所示[15]。
at=u(St|θu)+N
。
(4)
向Critic网络输入机械臂的12维状态数据和6维机械臂关节动作参数,采用全连接神经网络输出1维的评价值。评价值的更新方式如式(5)和式(6)所示。
yj=rj+γQ′(Sj+1,u′(Sj+1|θu′)|θQ′)
;
(5)
(6)
其中:yj为目标评价Q值;Q(*)、Q′(*)分别为当前和目标评价函数;u(*)、u′(*)分别为当前和目标策略函数;θ*为评价函数和策略函数的内参数;γ为衰减因子;n为迭代训练次数;rj为奖励,通过最小化损失函数L更新评价值。
Actor网络和Critic网络之间通过策略梯度更新参数,策略梯度计算如式(7)所示:
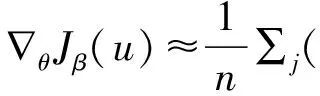
。
(7)
4.3 分层奖励函数的设计
深度强化学习算法通过奖励函数输出的奖励数据进行学习训练,但传统DDPG算法存在着奖励稀疏的问题。为此,本文结合机械臂逆运动学设计了分层奖励函数,当前关节值与参考逆解值的误差L如式(8)所示,当前关节值与实际关节值的误差L2如式(9)所示时,机械臂末端与目标点的距离d如式(10)所示,单位为m。
(8)
(9)
(10)
其中:aj为机械臂当前关节值;bj为机械臂理论逆解值;cj为机械臂实际关节值;(x1,y1,z1)为机械臂末端坐标;(x2,y2,z2)为目标点坐标。R为反馈奖励,则:
第1层奖励:R=-L,d≥0.1;
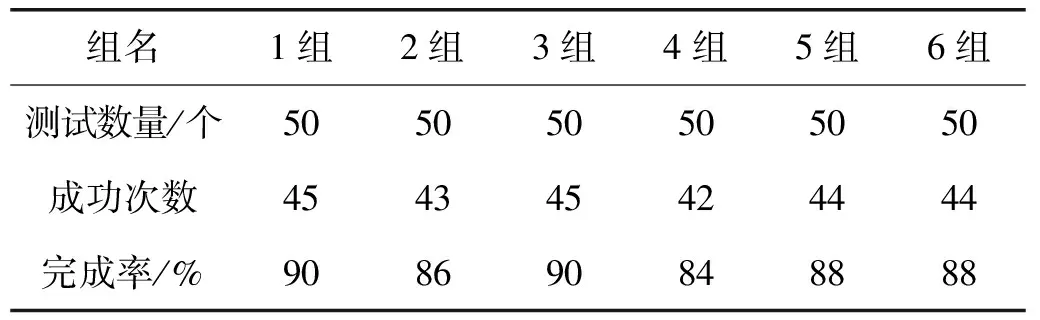
第2层奖励:R=-d-0.1lgd-L2-0.1lgL2,0 第3层奖励:R=R+3,0 本文设计的第1层奖励函数使用计算的关节逆解值作为引导项,以当前关节值与关节逆解值的误差作为奖励,引导机械臂在目标点范围运动,促进算法收敛。第2层奖励函数以机械臂末端与目标点距离d的相反数作为距离奖励,以当前关节值与实际关节值差的相反数作为关节奖励,将距离奖励和关节奖励组合,并引入lg非线性函数。第3层奖励函数为精度奖励函数,当距离d<0.006 m时,给当前奖励加3,提高控制精度。第1层奖励为训练前期奖励,当距离d稳定在0.1 m内时,以第2层奖励和第3层奖励作为后期的奖励。 为了验证改进DDPG算法的收敛性能和对机械臂的精确控制性能,本文进行算法的收敛速度对比试验和机械臂末端的精确控制性能测试试验。试验在Linux操作系统下的ROS-Kinetic 环境中进行,并基于Keras+TensorFlow框架搭建深度强化学习环境。中信重工实体机械臂如图5所示,中信重工仿真机械臂如图6所示。 图5 中信重工实体机械臂 图7 训练试验曲线 为对比改进前后DDPG算法的收敛速度,以机械臂末端控制精度奖励为指标进行改进前后DDPG算法的训练,平滑处理过的训练试验曲线如图7所示,平均奖励值越大,精度越高。 由图7可知:改进前DDPG算法在3 920训练回合左右收敛,改进后的DDPG算法在3 350训练回合左右收敛,收敛速度提升了约14.54%。 为验证改进后DDPG控制模型的机械臂末端精确控制能力,分别在仿真环境下进行了单点抗干扰重复性试验和多点测试试验。扰动噪声为在机械臂末端添加的随机噪声,噪声大小为-0.005~0.005 m,分别施加在末端的X、Y、Z方向上。 5.2.1 单点重复性测试 为验证控制模型的单点重复控制性能,分别在有扰动和无扰动的条件下进行25次的单点重复性测试试验,测试结果如图8所示。 由图8可知:在不加扰动时,末端的最大控制误差为5.335 mm,最小误差为4.616 mm,平均误差为4.924 mm;加扰动后,末端的最大控制误差为6.146 mm,最小误差为4.780 mm,平均误差为5.411 mm,验证了训练的控制模型具有较强的抗干扰能力。 5.2.2 多点测试 为验证控制模型的多点自适应控制性能,选取50组目标点进行测试,分别在无扰动和有扰动的环境下进行测试,测试结果如图9所示。 图8 单点重复性测试结果 由图9可知:在无扰动条件下,机械臂末端的最大控制误差为7.55 mm,最小误差为4.78 mm,平均误差为5.52 mm;在有扰动条件下,机械臂末端的最大控制误差为8.52 mm,最小误差为5.08 mm,平均误差为6.10 mm,验证了控制模型的多点自适应能力。 表2 多点完成率测试结果 为进一步验证控制模型的不同随机点控制性能,在所保存的实际机械臂数据中,每随机采集50个目标点位置数据为1组,进行多点稳定性测试,共测试6组,测试结果如表2所示,控制误差在6 mm以内为成功,完成率为成功次数与测试数量的比值。由表2可知:多点稳定性测试的完成率保持在80%以上,最高完成率达到90%。 改进后的DDPG算法相较改进前收敛速度提升了约14.54%,机械臂末端控制精度在6 mm以内,多点测试完成率最高达到了90%。本方案收敛速度较快,具有较强的抗干扰能力和自适应能力,能够有效实现机械臂末端的精确控制。5 试验结果分析

5.1 收敛速度对比

5.2 精确控制性能测试

6 结论
猜你喜欢
新世纪智能(数学备考)(2021年9期)2021-11-24 01:14:34中学生数理化·中考版(2021年3期)2021-07-22 07:41:30新世纪智能(数学备考)(2020年9期)2021-01-04 00:25:12中学生数理化(高中版.高考数学)(2020年9期)2020-10-28 08:43:52当代工人(2020年8期)2020-05-25 09:07:38小溪流(画刊)(2017年12期)2018-01-10 16:07:29当代医药论丛(2017年22期)2017-04-12 06:30:12科技知识动漫(2016年8期)2016-07-29 20:40:09儿童故事画报·发现号趣味百科(2015年12期)2016-01-25 00:41:49安徽医科大学学报(2015年9期)2015-12-16 11:09:44
