
历史建筑智能识别可行性研究
——运用正射影像和数字图像检测技术的江南水乡古镇实验
2021-01-20 07:01周俭ZhouJian
建筑遗产 2020年3期
周俭 Zhou Jian
叶振 Ye Zhen
俞文彬 Yu Wenbin
宋俊锋 Song Junfeng
李燕宁 Li Yanning
1 设计一种基于空间数据的历史建筑智能识别工具
1.1 目的
纵观国内外的相关研究和实践,甄别历史建筑、历史街区和历史村镇,均是由专家发现并采用专家现场踏勘的方法[1]。这种甄别方法首先是需要“人工发现”,其次是“人工识别”,现场踏勘工作量大,内外业工作耗时长,也难免存在遗漏。近年来随着信息技术、倾斜摄影,以及数字图像识别技术的快速发展,人们采集、存储、分析空间数据的能力大大提高,将这些新技术应用于城乡文化遗产(物质)的研究和保护是一个可期待的新领域,内容包括物质遗产的普查、评估和监测管理[2]。
本研究以无人机采集的空间正射影像数据为基准,借助形态学、类型学的原理,运用图像识别技术建立智能识别模型,通过模型运算对正射影像进行历史建筑智能化识别和空间定位,在正射影像上标注可能的潜在历史建筑点位。
作为一个法定概念,历史建筑是传统建筑中具有一定历史、科学和地方文化价值,并对历史文化空间和场所的保存具有核心作用的建筑物。本研究的目的是为人工现场核定历史建筑提供框定的范围和可能的对象。虽然传统建筑和历史建筑在外观影像上具有相似性,计算机通过外观影像的智能识别往往会将不具备历史建筑标准和价值的传统建筑误判为历史建筑,但这一结果恰恰可以为人工现场核定提供有价值的线索。
1.2 方法
建构历史建筑智能识别模型的基本方法包括三个步骤:①选取一个已具有研究基础的案例地作为测试地,通过无人机摄影,采集测试地的空间正射影像数据;②根据类型学和形态学,确定该测试地典型历史建筑的特征要素,并选取部分已知的历史建筑(群)作为学习样本,运用数字图像识别工具对其影像特征进行学习;③用经过学习训练建构的历史建筑智能识别模型(以下简称“识别模型”),对测试地全域进行历史建筑的智能识别,对潜在的历史建筑在全域正射影像图上进行自动空间定位。其中第二和第三个步骤需要反复校验,根据每次识别结果与现场历史建筑实际分布状况进行人工比对,对识别模型进行不断调整和优化,直至达到预期的精确度和召回率。
评价识别模型的性能指标主要包括正确性(correctness)和识别速度(speed),在某些场景下需要同时兼顾二者的平衡。本研究的目标是判断历史建筑(群)存在可能性的大小,因此对识别速度要求相对较低,而更为关注识别结果的正确性。正确性同时包含两方面:精确度(precision)和召回率(recall)。精确度指模型预测的所有历史建筑中确实是历史建筑的比例,召回率指所有在现实中确实存在的历史建筑被模型准确识别出来的比例。精确度和召回率是检验识别模型有效性的关键指标,一般规律是精确度越高召回率越低,反之亦然。为了更直观地阐明精确度和召回率的概念,我们定义了真阳性(TP, true positive),假阳性(FP, false positive),假阴性(FN, fasle negative)等概念。真阳性指模型预测的历史建筑确实是历史建筑,假阳性指模型错将非历史建筑识别为历史建筑,假阴性指模型未能将真实历史建筑识别出来。公式(1)(2)分别定义了精确度、召回率和上述概念之间的关系:

由此可以看到,精确度指明了模型错检的程度,而召回率指明了模型漏检的程度。基于本研究的目标,需要同时兼顾精确度和召回率的平衡,实现借助智能识别(模型)的技术手段,达到为专家现场确认提供先期依据的目的。
2 识别模型的基本原理
2.1 历史建筑与正射影像的耦合性
历史建筑的特征要素是维系历史建筑特征、承载历史建筑价值的关键性要素。如材料、色彩、样式、空间形制、地点、群体组合、与环境的空间关系、功能和文化象征与意义等。正射影像的全要素、所见即所得的特点,使得历史建筑的外部两维平面上的特征能够在正射影像上客观真实地表达出来,比如屋顶的形式、材料和色彩,建筑的空间形制和群体组合,建筑的尺度和密度等。
江南水乡古镇历史建筑(群)以下三个方面的特征,在正射影像上呈现出与非历史建筑较为显著的影像差异(图1),具有区分两者的影像学条件:
(1)屋顶的材料、色彩和形式。江南水乡传统建筑的屋顶材料多以小青瓦铺设,其瓦片铺设方式、尺寸、颜色、反光率等均与现代坡顶和平顶屋面材料有区别,除少数公共建筑采用庑殿顶、歇山顶等特殊的屋顶形式外,历史建筑屋顶多为双坡顶形式,在影像特征上易于识别。
(2)平面布局形制。江南水乡历史建筑的开间及进深规则有序,开间数多少于三开间,因此其单体规模较新的多层建筑要小,而比新建的一、二层民居建筑布局更加规整有序,在影像特征上也可被辨识。
(3)建筑群及历史地段的空间肌理。江南水乡历史建筑的平面布局基本是由围合院落和条状沿街两种类型组合而成,呈现出建筑与院落的相互嵌套及沿河沿街的连续绵延。这种嵌套和连续特征较非历史建筑群和非历史地段在正射影像上呈现出更为有序的特征。
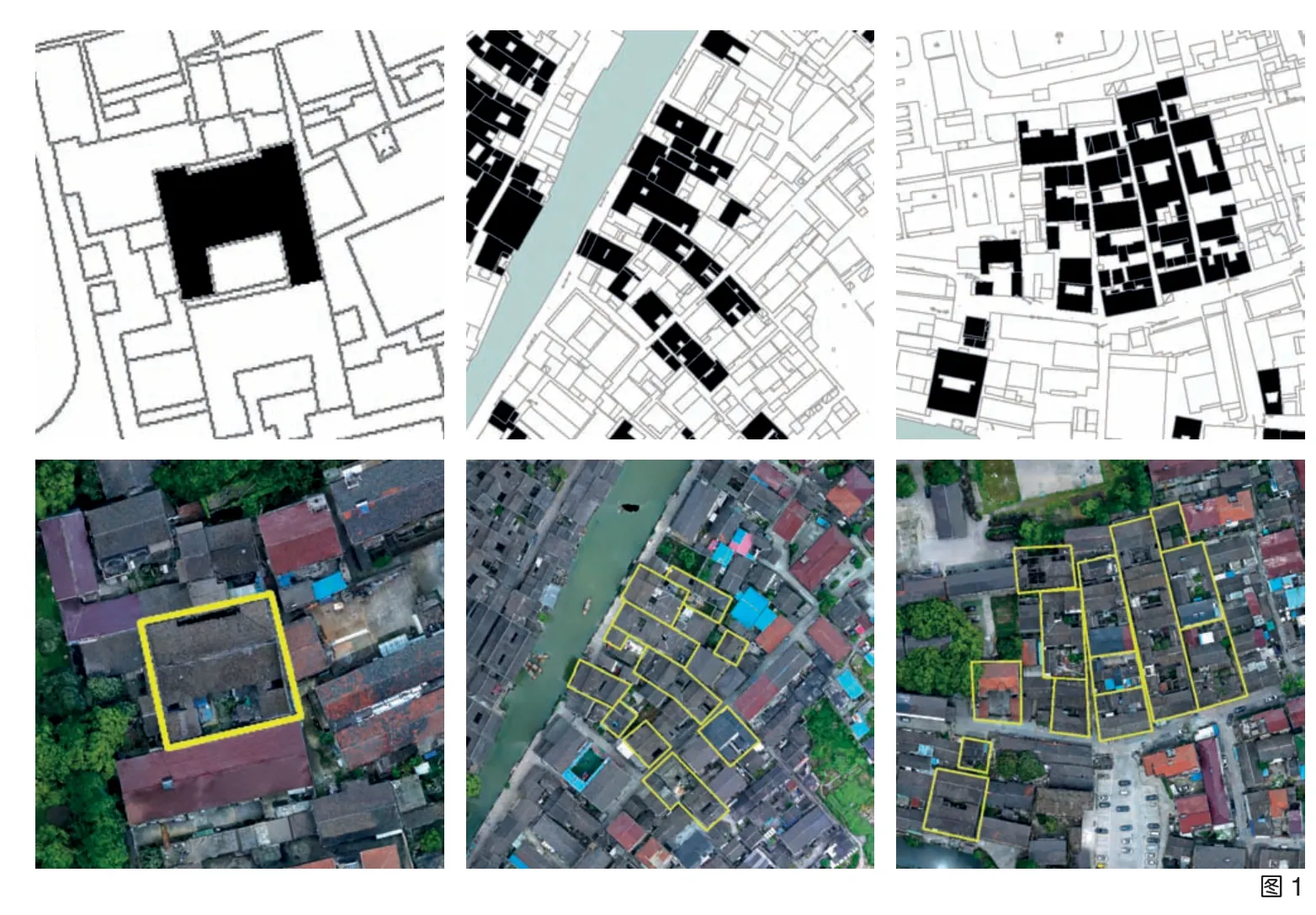
图1 震泽古镇历史建筑的正射影像特征(图片来源:作者提供)
2.2 识别算法方案
对智能识别而言,数字图像物体检测分析的任务,是从视频或者图像中,根据物体的外观特征,通过模型计算将该物体进行识别分类,并定位各类物体所在的空间位置。传统图像物体检测识别算法采用人工设计特征的方式进行,针对目标类型的特点设计不同的抽取特征,如行人检测多采用HoG 特征①HoG 特征是指通过计算和统计图像局部区域的梯度方向直方图来构成的特征。[3],人脸检测常采用LBP或Haar 特征②LBP 特征是一种用来描述图像局部纹理的特征;Haar 特征是采用积分图方法来反映图像的灰度变化情况的特征。[4-5]。此类人工设计特征策略对设计者的经验要求很高,但所提取的特征泛化能力有限,常存在欠拟合的情况。
随着计算机深度学习技术的发展,当前数字图像物体检测识别,已经从传统手动特征抽取策略,迅速转向了基于深度神经网络的自动特征抽取识别类算法[6]。基于深度学习的物体检测算法能利用当前计算机强大的GPU 运算能力,通过大量包含目标类别的样本图像训练,自动抽取出合适且具有较强表达能力和区分度的特征用于后续的物体识别。该类算法的特点:①无需手动设计抽取特征,对于不同类别的物体,深度神经网络能通过大量训练自动学习到该类物体的特征;②泛化能力强,在提供的训练样本数量大且具有广泛代表性的情况下,训练后的模型具有很高的识别准确率和环境适应性。
当前的物体检测算法主要分为两大类[7]:两阶段物体检测算法和单阶段物体检测算法。相对来说,两阶段物体检测算法检测精确度更高,但检测需时更久;单阶段物体检测算法的优点是可以进行实时检测,但精确度相对较低。考虑到在历史建筑智能识别的应用领域中,对识别精确度的要求相较实时性要求更高,本研究确定采用两阶段物体检测算法。
两阶段物体检测算法在进行物体检测分类时需要经历两个大的步骤:①通过深度神经网络模型生成多个可能包含某类物体的候选框;②在步骤1 的基础上,深度神经网络生成回归和分类两个分支的结果。通过在深度神经网络模型中增加回归分支修正候选框的位置,使其与实际物体位置更加接近。通过分类分支可以预测每个候选框是否包含物体、物体的类别,以及属于该类别的概率。两阶段物体检测算法类型多样,根据神经网络的架构模型不同、生成候选框的策略不同、采用的损失函数不同、底层的基础特征抽取神经网络不同,本研究选取了当前较具代表性的Faster R-cnn[8]两阶段物体检测识别算法进行历史建筑的智能检测识别。
基于Faster R-cnn 的历史建筑智能识别模型结构,由模型训练模块和实时检测模块两个相对独立的工作模块组成。模型训练模块利用大量包含历史建筑的样本图片对Faster R-cnn 模型进行训练,通过反向传播算法不断调优并自动抽取出历史建筑相关特征的参数值。该模块主要工作步骤包括:
(1)数据采集。如3.1 节所示,利用无人机倾斜摄影技术采集包含各类历史建筑的正射图作为训练和评估样本。
(2)数据标注。使用LabelImg[9]等工具手动将训练集图片中所有历史建筑的位置用方框框选出来。
(3)数据增广。如果用于训练的历史建筑数量较少,可以采用一系列的数据增广技术,通过对已有历史建筑图片样本进行各种变化以产生新的图片样本来增加训练样本数量。
(4)模型训练。将标注好的数据导入FasterR-cnn 模型进行训练,通过不断地迭代训练该模型中的多层神经网络,可以自动学习到历史建筑的相关特征,并通过反向传播机制相应调整网络模型中涉及到的众多参数。
模型训练后进入实时检测模块,即利用训练后的模型进行历史建筑的定位识别试验。将包含历史建筑的整个正射影像数据输入Faster R-cnn 模型后,模型首先会利用区域推选网络(RPN)[10],推举出该影像中若干可能存在历史建筑的区域作为候选区域,接着对这些候选区域的位置和大小进行回归修正,以使其更接近该物体的实际位置和大小;同时对候选区域中的物体进行分类判断,并将类别判断结果为历史建筑的方框选取后输出,最终得到在整个正射影像图中历史建筑的识别结果(图2,图3)。
2.3 模型结构与参数设置
基于Faster R-cnn 的历史建筑智能识别模型涉及到深度学习神经网络的众多模块,不同的模块在实现时可以选择不同的结构,其中涉及到数量众多的超参数值的设置。在本模型中,一些重要结构的选择及相关超参数的设置如下:
实现平台:模型使用Python 语言,基于Tensorflow①Tensorflow 是Google 公司开发的一款端到端的开源机器学习平台,包含各种机器学习和深度学习相关的工具、类库和社区资源。[11]框架实现。
数据增广策略:可用于训练的历史建筑的数量通常较少,为了提高训练样本的代表性,模型可采用水平/垂直翻转、旋转、平移、裁剪、颜色/对比度变化等方式增加历史建筑的样本数量。
特征抽取的骨干神经网络:物体检测算法依赖底层的深度神经网络提取相应的物体特征,不同的神经网络提取物体特征的能力不同,本模型采用深度残差网络Resnet101②残差网络是微软研究院提出的一款深度卷积神经网络模型,该模型采用残差结构在网络的不同层级实现跳跃连接,缓解随着网络深度增加造成的梯度消失问题,提高了神经网络识别的准确率。Resnet101 指的是一种共有101 层的深度残差网络实现。[12]进行历史建筑的特征提取。
学习率:模型采用分阶段的动态学习率设置,初始阶段学习率相对较大(0.0003),目的是使模型参数迅速收敛,提高训练效率。当已训练步数大于100 000时,采用更小的学习率(0.00003)进行更精准化的参数调整,以期获得更优解。
训练步数:模型中的样本训练次数为300 000 次,有较强GPU 配置的主机完成模型训练通常需要20 ~30 小时。
3 识别模型建构的技术方法
3.1 选取历史建筑存量丰富的测试地
根据研究的目标和对象,建构识别模型的测试地选择需要满足以下条件:①历史建筑存量丰富、类型较齐全;②历史建筑集中成片;③保留着传统格局和历史风貌;④已经掌握现状历史建筑保存情况与保护规划相关内容;⑤经历多阶段建设叠加,在图像识别上有一定的干扰因素,以适应模型今后的应用环境。基于以上筛选条件,本研究选择了江南水乡古镇震泽作为识别模型测试的实验地(图4)。
3.2 采集符合标准的实景空间数字影像
数据采集依据《数字航空摄影测量空中三角测量规范》《低空数字航空摄影规范》和《无人机航摄系统技术要求》等技术规范,采用多旋翼和固定翼无人飞机,通过规范的航线规划(图5)与多镜头组合的方式采集数据精度为3 cm(即每个像元所对应的实物为3 cm×3 cm)的正射像实景数据集,在相邻正射影像中相同地物影像灰度均值与方差一致,灰度均值之差小于15。数据预处理完毕之后,采用正射软件进行拼接,得到带地理信息的数字正射影像。由于震泽古镇的面积较大,拍摄的正射影像整图的像素量非常大,无法一次性在模型中进行训练识别,因此将整张测试地的正射影像图分割成大小相等的10 × 14 张正方形图片,每张方图(对应实际120 m × 120 m)的像素值为2 048 × 2 048,整图面积覆盖1.5 km2。
3.3 选取高效的学习样本与“精确度”和“召回率”
将实地踏勘确定的所有历史建筑位置,在分割好的震泽古镇全域正射影像图上进行手动标注(黄点),并根据震泽古镇历史建筑的类型特点,将部分典型历史建筑作为学习样本,由计算机专业人员使用LabelImg 数据框选工具框在正射影像图上对其进行框选(红底框)。将在不同位置、用不同范围框挑选的典型历史建筑学习样本输入Faster R-cnn 模型进行反复测试的结果表明(绿框),同样数量和同样类型的学习样本学习效果并不相同(图6)。首先,学习样本的选取在空间上越分散,模型的召回率越低;越集聚,召回率越高,且精确度损失很小(表1)。其次,在框选典型学习样本时应尽可能将历史建筑的特征要素,包括全部屋顶、完整的平面格局和周边的城市历史肌理,完整包含在框选范围(红底框)内,尽量少地包含其他无关要素。
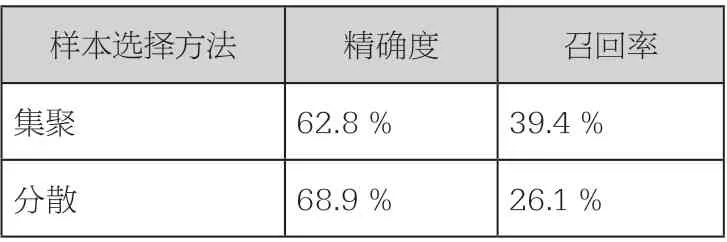
表1 两种选择方法下震泽古镇66 个学习样本训练的识别结果
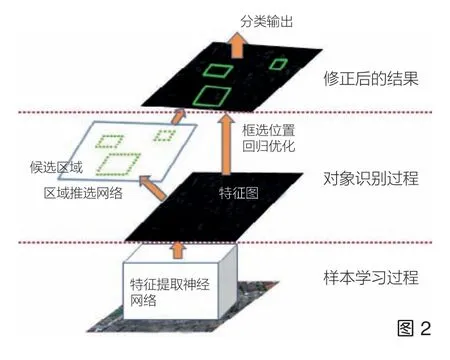
图2 基于Faster R-cnn 的历史建筑智能识别模型结构图(图片来源:作者提供)
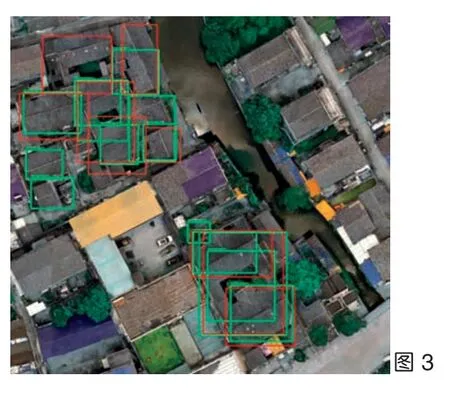
图3 基于Faster R-cnn 的历史建筑智能识别试验(图片来源:同图2 )图中红框为实际历史建筑的学习样本,绿框为模型识别生成的历史建筑选框
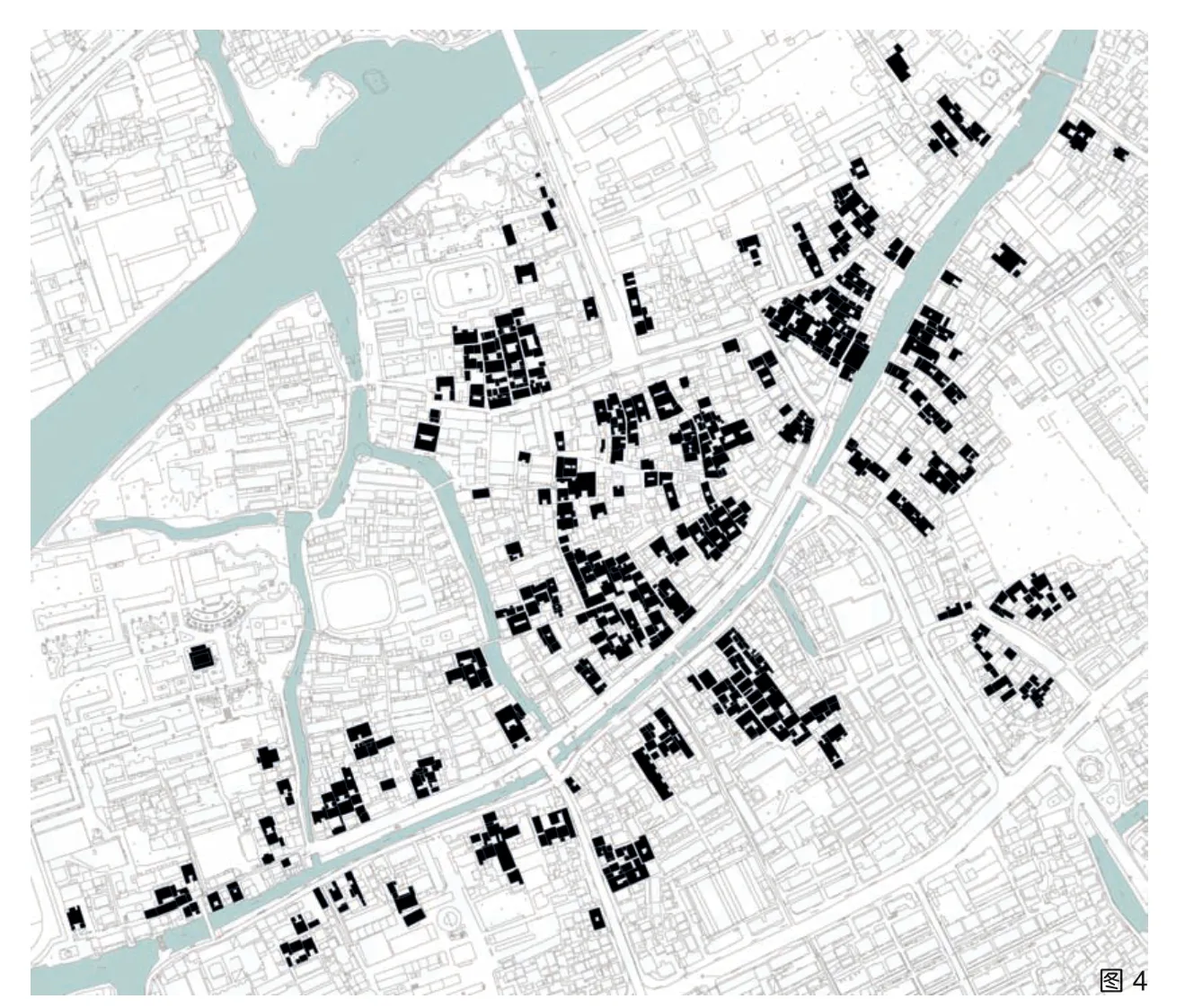
图4 震泽古镇历史建筑分布实地调研图(图片来源:同图2 )

图5 震泽古镇正射影像采集无人机航线规划图(图片来源:同图2 )航线规划软件:altizure;圆点:手动调整航线覆盖范围;十字圆点:新增加的航点

图6 两种选择方法下震泽古镇66 个学习样本训练的识别情况(图片来源:同图2 )6a. 66 个集聚学习样本的识别情况6b. 66 个分散学习样本的识别情况图中黄色点为实际历史建筑的位置,红底框为历史建筑的学习样本,绿框为模型识别生成的历史建筑选框,绿底框为模型正确识别选框
本研究模型识别的精确度和召回率的比较对象,是真实历史建筑的正射投影总面积和模型预测的历史建筑总面积。我们定义TotalSize_GroundTruth 为输入图片中手动标注的震泽古镇测试区所有历史建筑的正射投影总面积(重叠部分只算一次),TotalSize_Detected 为模型预测的历史建筑的正射投影总面积(重叠部分只算一次),TotalSize_IOU(预测正确的部分)为两者相交的总面积。即:
TotalSize_IOU(预测正确的历史建筑)=TotalSize_GroundTruth ∩TotalSize_Detected (3)
Precision_Size(精确度)=TotalSize_IOU/TotalSize_Detected (4)
Recall_Size(召回率)= TotalSize_IOU/TotalSize_GroundTruth (5)

表2 66 个学习样本(占现实总量的15%)训练下的震泽古镇历史建筑识别结果
3.4 确定适当的学习样本量与置信度阈值
在识别模型中,精确度和召回率是一组相互关联的指标,其中调整参数在模型中称作“置信度阈值”(confidence interval)。置信度指模型认为预测框中包含历史建筑的概率,模型可以设置一个置信度阈值,只有模型预测的概率值超过该置信度阈值时,模型才将其作为历史建筑纳入统计。
置信度阈值的选取会直接影响识别结果的精确度和召回率。一般来说,置信度阈值选取较低时,模型更倾向于将更多的非历史建筑误识别为历史建筑,从而降低模型的精确度;而当置信度阈值选取较高时,模型会更多地遗漏历史建筑,影响模型的召回率。
学习样本数量的多少同时关联识别的正确性和时间效率。为了确定最有效的学习样本量,测试模型选取了66、125 和215个三组学习样本进行训练,分别覆盖了震泽古镇测试区现状历史建筑的15%、30%和50%。将上述三组学习样本分别放入Faster R-cnn 模型中进行训练,获得三组不同参数的识别模型。当模型获得历史建筑识别结果后,再根据公式(4)和公式(5),分别统计计算三组数据在置信度阈值为0.1、0.25、0.5、0.75 及0.9 时,模型在精确度和召回率上的表现,如表2- 表4 所示:

表3 125 个样本(占现实总量的30%)训练下的震泽古镇历史建筑识别结果
过少的学习量会造成模型失效,但过多的样本学习则会带来工作量和工作时间的成倍增加。据表3,当选取的学习样本数占实际历史建筑总量的30%时,其最高召回率近60%,最大精确度超过70%。以增加学习样本的绝对数量与提高的召回率和精确度来看,该组在三组学习样本中识别效率最高。而三组不同数量学习样本的识别效果显示,根据不同的目的(对精确度和召回率的要求)确定适当的模型学习样本量,可以提高模型在实际应用时的工作效果。
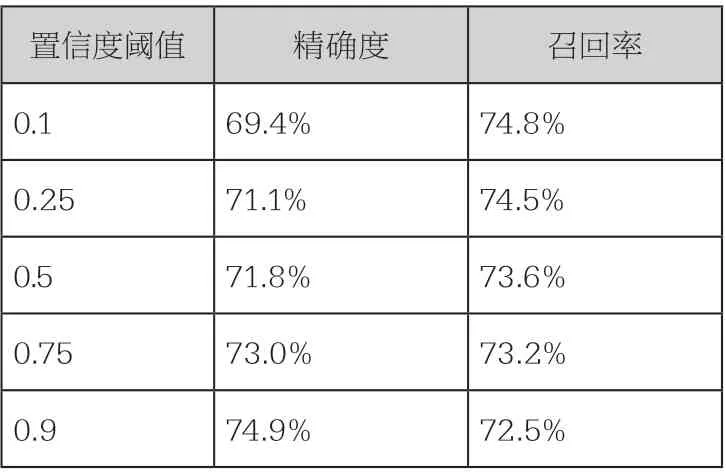
表4 215 个样本(占现实总量的50%)训练下震泽古镇历史建筑的识别结果
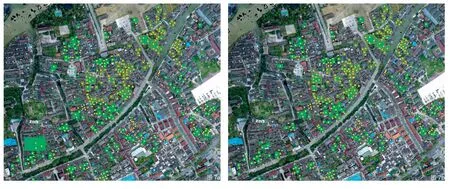
图7 125个样本量、不同置信度阈值选择下的震泽古镇历史建筑识别情况(图片来源:作者提供)图中黄色点为实际历史建筑的位置,红框为历史建筑的学习样本,绿框为模型识别生成的历史建筑选框,绿底框为模型正确识别选框7a. 0.1 置信度阈值时的识别结果7b. 0.9 置信度阈值时的识别结果
3.5 观察连续的识别数据组
置信度阈值在识别模型中是一个连续值,在识别模型完成识别计算后,可以根据需要提取其中任何一个置信度阈值的识别数据和识别图像。图7 显示的是同一样本量在选取不同置信度阈值时的识别结果,据此可以直观地看到:黄点(现状历史建筑)在绿框(模型识别的历史建筑)范围内的即为识别正确的历史建筑(TP),无黄点的绿框是误识别区域(FP),黄点未在绿框范围内的为漏识别的历史建筑(FN)。在实际应用中,识别模型的置信度阈值可以随时输出不同精确度和不同召回率情况下的识别结果,为进行比较判断提供条件。
4 识别模型的适用性分析
智能识别模型设计的主要目的之一,是为了用于对那些尚未进行实地调研区域的历史建筑存在状况进行整体“预判”,或对于已经完成实地调研区域的历史建筑确认情况进行全面“补漏”。
为了分析在震泽古镇建构的测试模型在其他区域识别历史建筑的适用条件,以及下一步的改进优化方案,本研究选择了同为江南水乡古镇的同里古镇,以与识别模型建构地相同的正射影像数据采集方法和技术标准,对同里古镇1.2 km2范围进行实例应用分析(图8)。
检测识别结果显示(图9),其识别的最高精确度近66%,最大召回率近30%,召回率偏低(表5)。造成漏检和误检的原因包括客观因素和模型因素两大方面。

图8 同里古镇历史建筑分布实地调研图(图片来源:同图7 )
4.1 客观因素的影响
(1)影像数据采集的外部环境条件
影像数据采集环境条件的差异将导致模型出现漏检情况。模型训练时所用的震泽古镇正射影像在采集时的外部环境,与在同里古镇采集时有较大差异。一方面,由于在同里古镇拍摄时的光照强度较强,正射影像上部分屋顶区域出现了明显阴影,使原有屋顶的纹理、色彩和形状等图像特征失效。同样的原因也使同类特征的历史建筑正射影像,在颜色、对比度等图像识别要素上出现较大的变化,导致在正射影像特征上形成了各不相同的差异。另一方面,同里古镇的树木较为茂密,部分历史建筑被树冠遮挡。这些影像采集环境的差异,导致了约30 %左右的历史建筑被漏检(图10)。因此,尽量选择相同或相似的数据采集外部环境,将大大提高模型识别的正确性。

表5 不同阈值选择下的同里古镇历史建筑识别结果

图10 模型验证地与建构地采集的影像对比(图片来源:作者提供)10a. 在模型验证地同里古镇采集的影像10b. 在模型构建地震泽古镇采集的影像由于两地在数据采集时环境条件的差异,导致同里古镇现状历史建筑(绿框外的黄圈)因为阴影和树木的影响被模型漏检;而有些新建筑则因为采用了传统平面形制和屋顶形式与材料,被模型误检为历史建筑(无黄圈的绿框)。在震泽古镇学习过的历史建筑样本(黄圈)类型,在同里古镇的模型验证中获得了较好响应(绿框中的黄圈)

图11 同里古镇部分误检的非历史建筑(图片来源:同图10 )无黄圈的绿框为被误检的部分非历史建筑
(2)历史建筑外部特征的人为改变
同里古镇旅游起步较震泽古镇早,规模较震泽古镇大,有许多历史建筑被加建改造成民宿或旅游接待设施,导致历史建筑平面格局的变化和建筑密度加大,改变了历史建筑布局的平面形制。历史建筑本身屋顶被破坏、材料被更换,以及历史建筑被加建改造所带来的不可预见的、无规律的客观因素,造成约有15%的历史建筑在同里古镇验证中漏检。
(3)传统形式和材料的新建筑与非历史建筑的传统建筑
造成误检的原因主要是有些不属于历史建筑的建筑物,仅从屋顶视角来看,和某些历史建筑较为相似,包括屋顶材料、平面形制和尺度,这类新建筑在保护和管控较好的同里古镇十分普遍(图11)。
另外,在同里古镇进行的模型识别结果中,将传统建筑误检为历史建筑的比例也有10%左右。但就本研究的目的而言,将传统建筑误检为历史建筑是可以接受的,识别模型优化的方向是降低漏检率。
4.2 模型的局限
除了避免客观因素的影响外,要提高识别的正确性,技术的优化是重要的工作。包括以下三个方面:
(1)模型算法升级
相较车辆、行人等大类间的粗粒度物体识别,将历史建筑和非历史建筑进行区分识别属于难度更高的细粒度精细化物体识别,目前采用的Faster R-cnn 技术并未针对这类细粒度的物体识别[13]场景做特殊优化,后续可以考虑使用区分度更强的模型进行历史建筑的精细化检测识别。同时,考虑模型要在少样本场景下适用,可采用生成式对抗网络GAN①GAN 是一种深度学习模型。[14]等技术,人工合成更多的历史建筑作为训练样本,使模型学习的外观特征更具有广泛性和代表性。
(2)运用更强大的计算机
此次识别模型分析的完整数据图像达到了数十亿像素,文件量大小为几十G。受制于当前常用计算机的性能,完整的数据图像不能一次性加载到计算机内存中,需要将其分割为数百张图片方能进行检测计算,这可能把某个历史建筑分割到不同图片中导致其完整性被破坏,造成漏检。
(3)采用三维影像数据
采用三维影像数据,增加历史建筑特征的辨识条件。当前技术只采用了从上到下视角的正射影像信息对历史建筑进行识别,但历史建筑和非历史建筑在其他视角下外观也存在较多区别。历史建筑的外观特征除了在正射影像图上表现出来的以外,还在建筑各个立面上,如山墙形式、立面形式、门窗、材料、色彩,甚至构件等,表现出特征要素。在理论上,借助全景化的三维倾斜摄影数据,历史建筑立面上的特征要素也同样可以实现被模型识别,从而对历史建筑形成多要素叠合的校验判断,这样可以大大提高检测识别的正确性。
5 结语
采用全数据的正射影像图能够对可能的历史建筑进行智能识别的空间定位,从而获得某一区域潜在的历史建筑分布图和数量统计数据;对已知历史建筑保存状况的区域,则可以检测其当前与过去状况的吻合度。这一方法对于历史建筑普查的前期摸底,以及历史建筑保护状况的持续监测,都有实际的应用价值。该方法可为减少普查遗漏,以及适应在较短时间内完成大区域历史建筑识别预判和监测评估的需求,提供一种技术解决方案,并可在大量减少户外工作时间的同时,整体提高工作效率。
模型的算法决定了训练模型的学习样本与识别对象的特征越相似,识别的效果越好。借助这一技术方法框架,用一地的历史建筑正射影像数据进行模型训练后,可以实现将识别模型迁移到其他地方去识别特征相似的历史建筑的应用目标。
在震泽古镇的模型识别测试中,不论采用哪组学习样本量,该组学习样本都可以实现100%的正确识别。同里古镇与测试模型建构地震泽古镇,在历史建筑和城镇肌理的特征上虽然具有相似性,但并不是完全相同。在同里古镇进行的应用检验中,部分历史建筑未被识别出来的主要原因,是其影像特征(包括被人为改变的、被树木遮挡和被日照阴影改变的)未曾在测试模型的学习样本中训练过。
根据模型的图像识别原理,以及识别模型检测结果分析,可以得到以下推论:模型学习的历史建筑样本类型越多,模型能够识别的历史建筑(包括类型)也就越多,模型越智能;在模型的技术架构上,每次的识别应用都是模型再次学习的过程,模型识别应用的次数越多,模型学习积累的样本信息就越丰富,识别的结果就会越精确。
如果智能识别模型不断地对各种特征类型的历史建筑及其多维度的空间特征进行学习,并不断升级识别模型的算法,它将有望成为一个可以广泛应用于不同地点、不同特征历史建筑识别的技术工具,并成为进一步构建一个基于空间实景大数据的城乡(物质)文化遗产智能识别模型的技术框架。
猜你喜欢
泉州师范学院学报(2021年6期)2022-01-07
宁波大学学报(人文科学版)(2021年4期)2021-07-07
山东煤炭科技(2020年1期)2020-03-06
乡村地理(2018年3期)2018-11-06
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
乡村地理(2017年4期)2017-09-18
新教育时代·教师版(2017年30期)2017-09-12
作文周刊·小学一年级版(2016年21期)2017-06-03
作文周刊·小学一年级版(2016年3期)2016-08-12
遥感信息(2015年3期)2015-12-13
