
基于Canopy-K-means算法的高校贫困生预测的研究*
2021-01-19 11:01王全民张书军
计算机与数字工程 2020年12期
王全民 张书军
(北京工业大学计算机学院 北京 100124)
1 引言
党的十九大提出,坚决打赢扶贫攻坚战,坚持精准扶贫、精准脱贫[1],确保2020年实现全部脱贫;同时提出要优先发展教育事业,要健全学生资助制度,使更多人接受高等教育。到2018年初,我国贫困人口预计还有3000万左右[2],这些贫困人口主要集中在农村,农村是打赢脱贫攻坚战的主要短板。据统计,农村贫困人口出现的主要原因包括教育致贫、因病致贫,其中相当一部分是由于教育致贫[3]。对于这些农村贫困人口的脱贫问题,关键在于减轻家庭因教育相关费用而产生的负担。因此,高等教育领域的精准扶贫工作非常重要,要实现精准扶贫,核心在于精准资助[4],而贫困生认定是高校贫困生精准资助的前提与基础,只有找准扶贫对象,才能进行有效资助。因此,解决高校贫困生资助工作中的认定问题迫在眉睫。
高校贫困生是指学生本人及其家庭难以支付其在校期间的学习生活费用的学生人群[5]。随着国家经济的发展,国家对于教育事业发展的支持度不断提升,让更多的人能够得到高等院校的教育。不过高校中存在的经济困难的学生也逐渐增加,在高校占比15%~30%[6]。目前由于学生的贫困生申请信息偏于主观、贫困指标难以量化等因素,使得贫困生认定工作仍然是高校资助决策中的难点问题。高校数字化校园的建设中一卡通的应用极大方便管理校园学生的日常生活,其应用的范围比较广泛,食堂、超市、洗浴、门禁、图书借阅等都可以直接刷卡。基于校园一卡通的消费数据,对其采用数据挖掘技术,分析学生消费特性及其能力,可作为一项评价标准,为贫困生认定提供数据依据。近年来,国内已有一些初步研究,如马玲玲[7]利用一卡通消费数据采用数据挖掘技术设计了一套高校贫困辅助分析系统;张玺[8]利用支持向量机(Support Vector Machine,SVM)算法进行数据分类认定贫困生;费小丹[9]选用K-means模型作为分析贫困生一卡通数据的聚类算法计算学生贫困指数。
综上所述,虽然各种研究方法都对贫困生认定有了相关预测,但大多数研究都使用单源一卡通消费数据进行分析,而较少关注学生在校的其他行为对于贫困生评价的作用。高校校园网的建设也比较普及,学生可以通过登录账号上网,通过学生上网日志可以查到学生的登陆下线时间、上网使用流量、上网时长、上网消费金额等。对于学生来说,在校学习是当前最重要的任务,过度沉迷网络的学生不应该受到学校的资助。本文在已有的研究基础上提出了一种基于Canopy-K-means算法的高校贫困生认定方法。以某211高校一卡通消费数据、上网日志等多模态数据使用数据作为研究内容,通过高效聚类获取贫困生类别,并采用数据统计和对比分析的方法预测贫困生划分的合理性,为高校贫困生的资助提供辅助决策作用。
2 相关工作
2.1 聚类算法
聚类算法是数据挖掘中的重要算法之一[11],在无先验知识的条件下,按照数据集中数据本身的特点和差异,把一个数据集分割成若干个不同的类和簇,使得在同一个类中的数据对象的差异性尽可能地小,而处于不同类中的数据对象的差异性尽可能地大[11]。
2.2 K-means算法
K-means算法是聚类算法中使用最为广泛的算法之一[14~15],其用到的数学思想是基于距离的相似度计算,相对简单,而且效率高,且对于“圆形-球形”性质集合进行分类是,可以达到良好的聚类结果[10]。传统K-means算法的工作流程如图1所示,步骤如下。
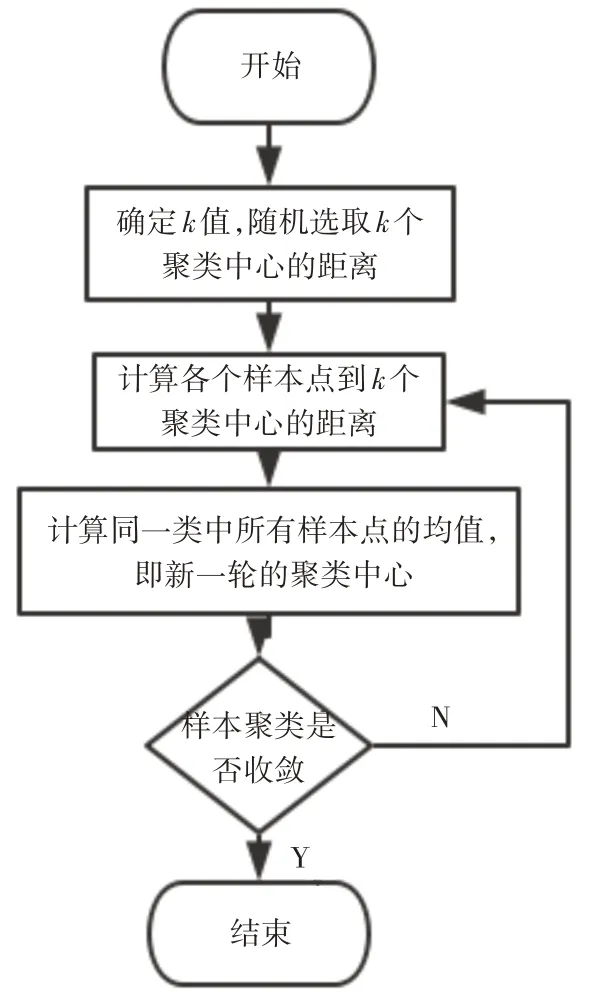
图1 K-means算法流程图
1)对于数据集X=(x1,x2,…,x n),首先通过人工指定数字K作为聚类的数目,并随机从样本点中选取相应数目的初始聚类中心{c1,c2,…,c k};
2)计算各个样本点xi到K个聚类中心的距离,并把样本xi归到与他距离最近的那个聚类中心ci所在的类中;
3)根据划分的类别,计算同一个类中所有样本点的各维平均值,作为新一轮聚类的k个中心;
4)重复上述过程继续聚类,直至收敛。即使得式(1)最小化:

其中:
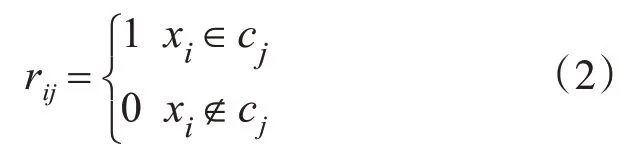
K-means算法虽然简单易懂、高效,但其缺陷也比较明显,主要有以下几个方面:由于聚类的簇数K值需要预先给定,然而在实际中这个K值的选定是非常难以估计的,很多时候如果不是很了解样本的大致分布情况,就不太好确定;K个初始中心点的选取存在随机性,每次算法开始时不同的初始点悬着将可能导致完全不同的分组,在数次迭代之后,得到完全不同的聚类结果,使得聚类的结果具有不稳定性[12];K-means算法中许多计算是冗余的,若计算量很大时,算法的时间开销也非常大。
2.3 Canopy算法
Canopy[13]也是一种聚类算法,主要用于海量高维数据的聚类。Canopy可以粗略地将数据划分成若干个重叠子集。每个子集作为一个类簇,其一般使用一种代价低的相似度度量方法,以加快聚类的速度。Canopy算法一般用于其他聚类算法的初始化操作。Canopy算法工作流程如图2所示,步骤如下。
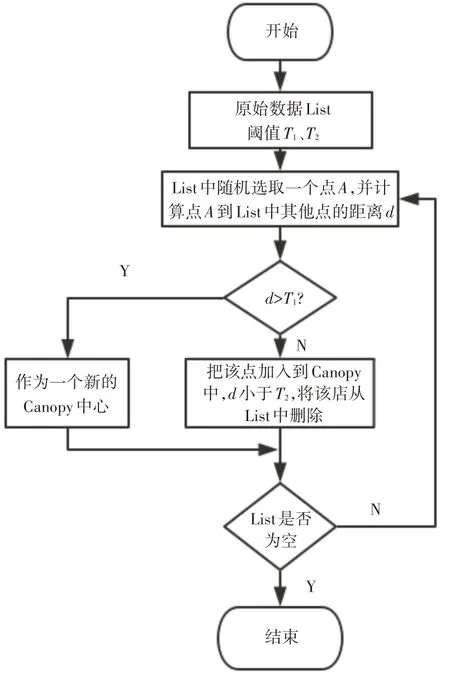
图2 Canopy算法流程图
1)首先需要指定两个距离阈值,T1、T2(T1>T2),在数据集中选择一个点作为初始中心点加入到Canopy中心列表C中。
2)对于数据集中任意一个点xi(xi∈C),若xi与cj(cj∈C)的距离均大于T1,则将xi作为一个新的Canopy中心加入到C中;若距离小于T1,则将xi加入以cj为中心的Canopy中;若xi与cj的距离小于T2,将x i与cj强关联,xi不能再作为其他Canopy的中心,将其从数据集中删除;
3)重复上述过程,直至数据集为空。
Canopy聚类允许有重叠子集,增加了算法的容错性和消除孤立点作用;同时,由于只需在每个Canopy中心内进行精确聚类,从而避免了对多有点精确聚类带来的计算量大的问题。
2.4 改进的Canopy-K-means算法
传统的K-means算法由于初始聚类中心选择的随机性,算法结果随着中心点选择的不同而改变,导致结果的不稳定性,可能会造成局部最优值的问题。针对中心点选择的问题,通过引入Canopy算法,为K-means算法确定初始聚类中心。在进行K-means聚类过程中,将不在考虑每个点到所有中心的距离,只需计算点到其所属的Canopy中心的距离,即K-means算法将在每个Canopy中进行,而随着K-means算法的迭代,每个Canopy中心不断变化,直至收敛。具体执行流程如图2所示。
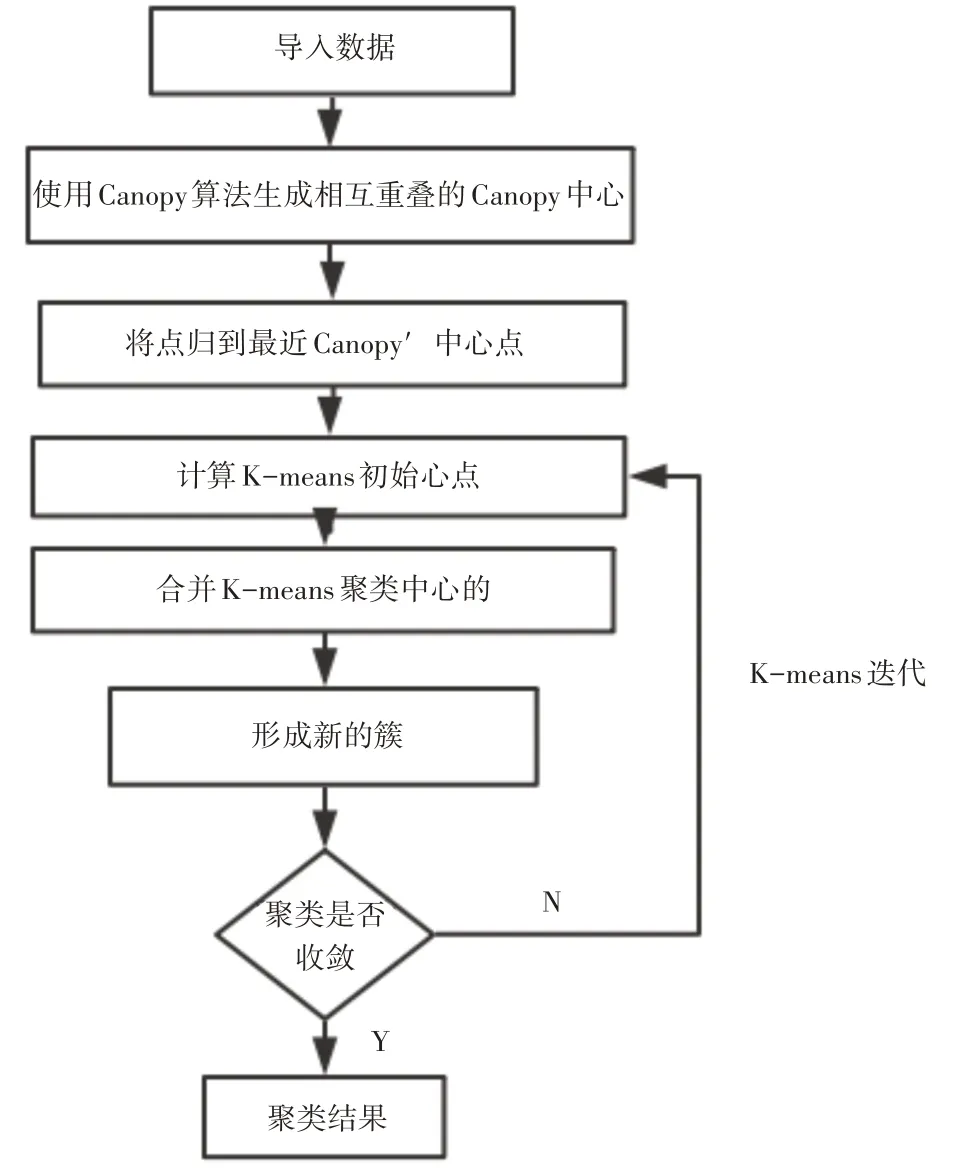
图3 改进的Canopy-K-means算法
从图3可知,改进的Canopy-K-means算法首先通过Canopy算法形成相互重叠的Canopy,再进行K-means迭代,最后产出聚类结果。其算法步骤如下。
1)给定数据集,利用Canopy算法生成相互重叠Canopy聚类中心。
2)计算合并K-means算法中心点。将点归到最近的Canopy中心点,计算每个簇点的平均值即K-menas算法的初始聚类中心。由于前期采用了Canopy算法生成初始中心,在确定T1、T2时,由于半径过小会导致聚类后的中心点过多的问题,因此选择一定的范围,将中心点间距离过小的点合并求均值,即K-means的中心点。
3)对每个Canopy内的点使用K-means算法进行精确聚类,进行K-means迭代。在迭代结束之后,形成不重叠的最终簇,完成聚类。
3 实验
3.1 数据集
本文研究数据主要是基于2017年9月~2018年1月的某211高校学生一卡通食堂消费数据和上网日志分别见间表1中的表(a)和表(b)。其中表(a)原始数据包含学号、消费时间、消费金额、消费地点,表(b)原始数据学号、上网消费金额、上网使用流量、上网时长、上网IP地址、上网上线和下线时间等,其中表(b)提供了部分的原始数据集。为了保护数据隐私,将学生学号和IP地址的部分用“***”表示。
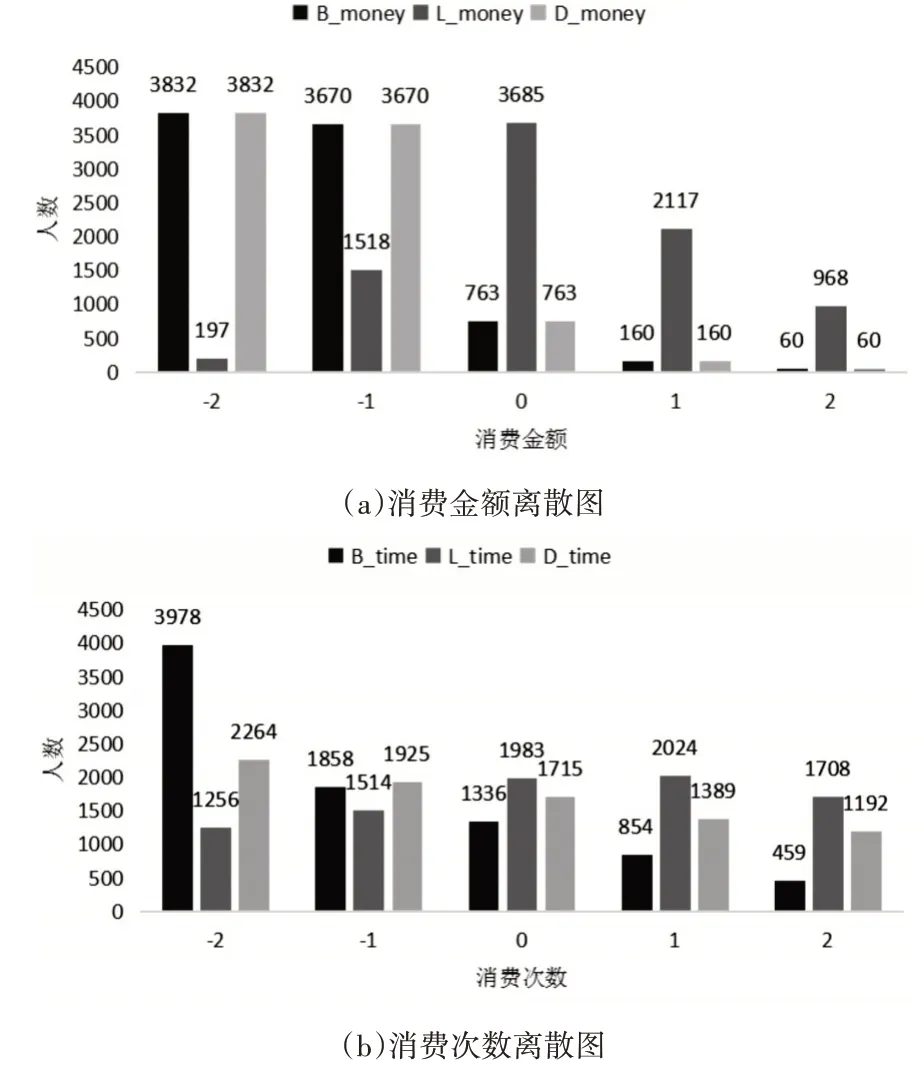

表1 学生一卡通食堂消费数据和上网日志
原始数据需要进行数据预处理才可应用算法进行模型训练和预测分析,具体数据处理信息如下:本文研究的对象为本科生,需要对数据中博士研究生数据需要剔除;一卡通食堂消费数据提取学生早中晚三餐消费金额和消费次数,其中早餐时间段为6:00-9:59,中餐时间段为10:00-14:59,晚餐时间段为15:00-20:00,由于在同一时间段内会有多次消费,所以在这一时间段内的消费按一次计算,消费金额累加;上网日志需要提取每次上网上线下线所消费金额、使用流量、上网时长。为了便于聚类分析,需要将以上处理的数据离散化,按照数据进行等宽划分五个区间,即很高(2)、高(1)、中(0)、低(-1)、很低(-2),所得结果如图4所示。
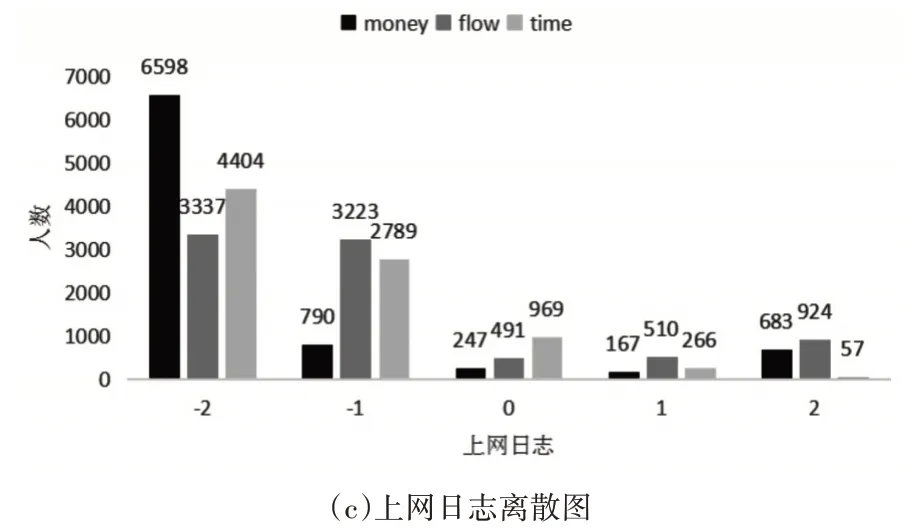
图4 食堂消费和上网日志数据离散图
3.2 运用Canopy-K-means聚类算法确定聚类中心
首先,获取学生一卡通消费数据和上网日志,对数据进行预处理。其次,Canopy-K-means聚类算法需要分两步使用,Canopy算法聚类过程包含两个参数T1、T2(T1>T2),其中T1、T2都表示数据集中的点距Canopy算法中心点C i的距离;若距离小于T1且小于T2,则将该点与C i强关联,在使用K-means算法是则不需要计算数据点到给定随机点的距离,只需要计算数据点到Canopy中心点的距离即可。T1、T2的选取将影响聚类结果的效果。最后,经过多次迭代试验,确定T1的值为15、T2的值为6时,得到的效果最佳,此时可划分5类,其聚类结果如表2所示。

表2 Canopy-K-means聚类结果表
从表2聚类结果可对这5类学生食堂消费习惯和上网行为进行分析如表3。

表3 学生类别食堂消费习惯和上网行为分析
将实验结果与在校实际评定的贫困生进行对比,可以发现第II类学生中有378名贫困生,占贫困生总数的75.6%,第II类学生表现出的食堂消费比较规律,消费金额少消费次数高,上网使用金额、流量、时长较少。从表3分析结果可知第二类特征习惯符合一个贫困生在校的生活规律,这类学生可推荐贫困申请,为高校工作人员提供辅助决策作用。其他类别分布较少,这其中可能有一些特殊的原因被评定为贫困生。比如单亲家庭,家里突发事故等。
4 结语
本文研究以某211高校2017年9月~2018年1月本科生一卡通食堂消费数据和上网日志数据作为研究对象,结合Canopy-K-means算法对数据进行聚类,分析聚类的类别,对比通过实验获得的结果与实际评定的贫困生,预测准确度达到75.6%,找出相应的贫困生类别并做深入分析,分析贫困生食堂消费习惯和上网行为,为高校贫困生认定提供辅助决策作用。贫困生认定工作在高校中是比较重要的环节,有效的评定贫困生能够让真正贫困的学生得到学校的资助,让他们能够在校园健康成长。我们应该从学生在校生活中挖掘更多的信息来为贫困生评定工作提供数据依据,提高贫困生认定的准确度。
猜你喜欢
锦州医科大学报(2022年3期)2022-06-06
农村农业农民·B版(2020年12期)2020-12-28
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
电脑报(2019年4期)2019-09-10
新西部(2018年8期)2018-08-31
婚育与健康(2016年6期)2016-05-14
大众摄影(2015年9期)2015-09-06
新高考·高一物理(2015年5期)2015-08-18
教师·上(2009年9期)2009-11-24
