
基于LUR模型的北京市PM25浓度的空间分布模拟
2021-01-16 02:53杜宝强杨明亮张金润
廊坊师范学院学报(自然科学版) 2021年4期
杜宝强 杨明亮 张金润
【摘要】通过北京市34个国控监测站点,建立0.5、1、1.5、2、3、4、5km的缓冲区,应用土地利用回归模型(Land UseRegression,LUR)对北京市采暖季与非采暖季PM2.5浓度进行空间分布模拟,并采用留一交叉互验法验证模型精度。结果表明:采暖季LUR模型调整R2为0.799,模拟精度为0.7992,均方根误差(Root Mean Square Error,RMSE)为6.66μg·m-3;非采暖季LUR模型调整R2为0.807,模拟精度为0.8198,均方根误差为5.91μg·m-3,模型表现良好。从模拟结果来看,北京市PM2.5主要分布在东南部人口、交通密集的平原区域,整体呈现南高北低的状态。
【关键词】PM2.5;空间分布;土地利用回归模型;北京市
〔中图分类号]X513 〔文献标识码〕A 〔文章编号〕1674-3229(2021)04-0051-05
0 引言
随着经济的快速发展,环境污染问题也随之而来。空气动力学直径小于等于2.5微米的颗粒物PM2.5是造成雾霾天气的主要原因[1]。对PM2.5浓度进行空间分布模拟有助于推进我国大气污染治理。
目前国内外对大气污染物浓度模拟的方法主要有空间插值、气溶胶反演、土地利用回归模型等[2]。其中土地利用回归模型(Land Use Regres-sion,LUR)的特点是基于多种可能对大气污染物产生影响的变量进行回归训练,可以用来确定大气污染物与影响变量之间的关系,从而模拟城市地区大气污染物的空间分布,并在一定程度上识别大气污染物的成因,而且还具有模拟精度高、考虑因素广、数据易获取等优点,已在欧美、日本等国家得到了广泛应用[3-4]。国内对PM2.5浓度的研究主要集中在来源分析、化学特征、环境危害及健康影响等方面[2,5],对LUR模型应用处于起步阶段,国内吴健生等[6]、许刚等[7]、汉瑞英等[8]运用LUR模型模拟了研究区内年均PM2.5浓度,但却少有学者对不同时间段PM2.5浓度以及影响因素进行研究。
本研究基于采暖季与非采暖季两个时间段建立回归预测模型,分析PM2.5浓度在采暖季与非采暖季的空间分布,进一步验证了LUR模型的适用性,揭示了PM2.5浓度相关影响因素。为大气污染防治、城市土地及道路规划、公共卫生管理提供了科学依据。
1 材料与方法
1.1 数据来源及预处理
1.1.1 PM2.5浓度与气象数据
PM2.5数据来自北京市范围内34个国控站点2018年11月-2019年10月空氣质量日值数据(数据来源中国环境监测总站http://www.cnemc.cn/)。对数据进行统计计算,得到34个监测站点的采暖季(11月-3月)与非采暖季(4月-10月)PM2.5浓度。气象数据来自于国家气象科学数据中心的中国地面气候资料日值数据(http://data.cma.cn/),采集了北京市20个气象站点2018年11月-2019年10月观测数据,包括气压、风速、气温、相对湿度、降水量5类,对数据进行计算统计得到采暖季与非采暖季的气象数据,并通过Kriging插值法对采暖季与非采暖季的气象数据进行插值模拟,提取监测站点所在位置的气象数据作为气象因子。
1.1.2 高程与人口数据
高程数据来自Earth Data的中国区域30m分辨率的数字高程模型(Digital Elevation Model,DEM)数据,人口数据来自WorldPop全球高分辨率人口计划项目(www.worldpop.org),提取监测站点所在位置的高程及人口数量作为高程因子和人口因子。
1.1.3 土地利用与路网数据
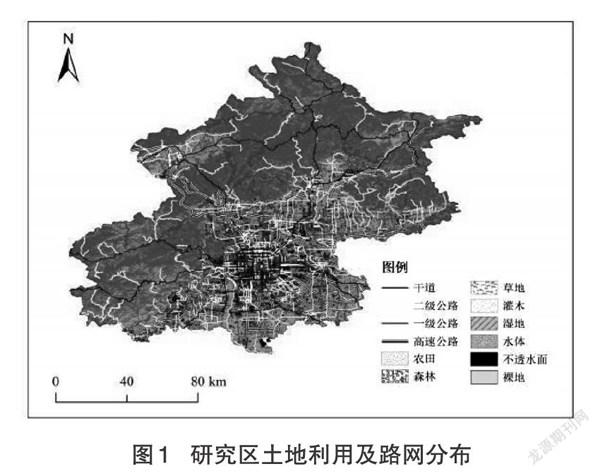
土地利用数据来自清华大学宫鹏等2017全球10m分辨率土地利用数据,将北京市土地利用类型分成农田、森林、草地、灌木、湿地、水域、不透水面、裸地8类,路网数据来自于OpenStreetMap,提取数据中的高速公路、干道、一级公路、二级公路4类作为北京市的路网数据。本研究参考已有的LUR模型缓冲半径设置[9-10],以监测站点为中心,设置0.5、1、1.5、2、3、4、5km为缓冲半径,以缓冲区内各类土地的面积及各类道路长度作为土地因子和路网因子。北京市土地利用及路网分布如图1所示。
1.2 研究方法
1.2.1 LUR模型构建
本研究采用的LUR模型是基于监测站的大气污染物浓度对周围多种可能对大气污染物产生影响的变量,进行多元线性回归的模型。LUR模型的基本形式如式(1):
y=α0+α1x1+α2x2+…+αnxn+β(1)
式中y为因变量,即本研究中采暖季与非采暖季PM2.5浓度值,x1,x2,…,xn为自变量,即本研究各类影响因子,α1,α2,…,αn为待定系数,β为随机变量。构建模型分为以下3步:(1)在SPSS中将PM2.5浓度与各影响因子进行双变量相关性分析,去除与PM2.5浓度相关性不显著(p>0.05)的变量。(2)在剩余变量中去除与同类相关性最高影响因子相关(皮尔森系数r>0.6)的变量。(3)以PM2.5浓度为因变量,剩余的变量为自变量进行逐步线性回归,得到的回归方程就是LUR模型。
1.2.2 模型验证
模型的验证采用留一交叉互验(leave-one-outcross validation)[11],将34个监测站点划分为训练集(33个)和验证集(1个),通过对训练集(33个)站点进行多元线性回归,得到验证集(1个)站点的预测值,对比预测值和实测值,重复34次。这种方法虽然繁琐,但可以有效验证模型精度。最后通过调整R2、均方根误差(Root Mean Square Error,RMSE)、模拟精度3项指标来验证模型。
1.2.3 PM2.5浓度模拟
在ArcGIS中通过创建渔网把北京市划分成1km×1km规则格网点,通过LUR模型计算出各格网点PM2.5浓度预测值,再利用Kriging插值法就可以得到北京市的PM2.5浓度空间分布。
2 结果与讨论
2.1 PM2.5浓度统计
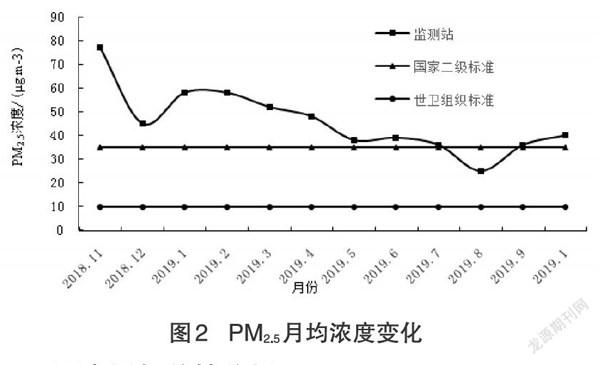
根据图2可以看出北京市2018年11月-2019年10月PM2.5浓度变化趋势,采暖季(11月-3月)PM2.5整体浓度偏高,计算可得采暖季PM2.5浓度为58pμg·m-3,严重超出国家二级标准。非采暖季(4月-10月)PM2.5浓度为37μg·m-3,相对采暖季有所下降,但也只有8月份满足了国家二级标准,远达不到世卫组织标准。
2.2 双变量相关性分析
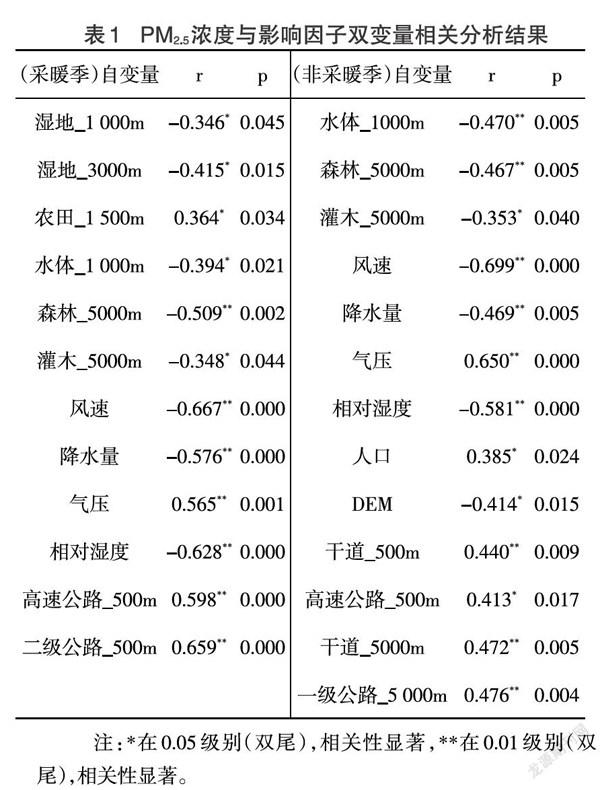
在SPSS中将PM2.5浓度与各影响因子进行双变量相关性分析,去除与PM2.5浓度相关性不显著(p>0.05)的变量(如不透水面、温度、三级公路等),剩余变量中去除与同类相关性最高影响因子相关(皮尔森系数r>0.6)的变量(如森林_1000m,灌木_1500m等),最后满足多元线性回归的变量如表1所示。从表1可以看出影响因子在采暖季与非采暖季下呈现的相关性不同,采暖季PM2.5浓度与农田、气压、高速公路、二级公路呈正相关;与湿地、水体、森林、灌木、风速、降水量、相对湿度呈负相关。非采暖季PM2.5浓度与气压、人口、干道、高速公路呈正相关;与水体、森林、灌木、风速、降水量、相对湿度、DEM呈负相关。其中水体、森林、灌木、风速、降水量、气压、相对湿度、高速公路与采暖季和非采暖季PM2.5都呈现很高的相关性,说明北京市PM2.5浓度受这些因素影响很大。
2.3 LUR模型构建及精度验证
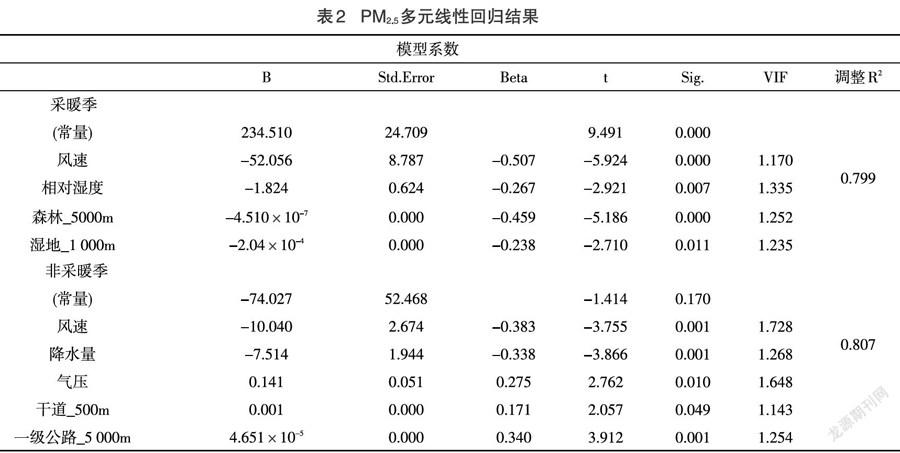
将满足多元线性回归的变量与PM2.5浓度进行逐步线性回归,逐步线性回归可以有效避免自变量共线性的可能。由于PM2.5浓度在采暖季出现较高的情况,为了分析其原因,本文建立了采暖季与非采暖季LUR模型。从表2可以看出,进入采暖季LUR模型的变量有风速、相对湿度、森林、湿地;进人非采暖季LUR模型的变量有风速、降水量、气压、干道、一级公路。其中风速均参与了两个模型的建立,且与PM2.5浓度呈负相关性,原因是大风可以使空气中的细颗粒物稀释和扩散,颗粒物不容易堆积,从而降低了浓度[12]。相对湿度、森林、湿地参与了采暖季LUR模型的建立,且均呈现负相关性,原因是相对湿度高使得PM2.5颗粒物吸湿变大,加速颗粒物沉降,森林、湿地的植物具有净化和吸附PM2.5的功能[13-14]。降水量、气压、干道、一级公路参与了非采暖季LUR模型的建立,其中降水呈现负相关性,原因是降水对PM2.5颗粒具有清除作用[15];气压、干道、一级公路呈现正相关性,原因是高气压时,天气系统稳定,PM2.5颗粒物扩散条件不好,以及机动车驾驶排放的尾气以及扬尘[16-17]。
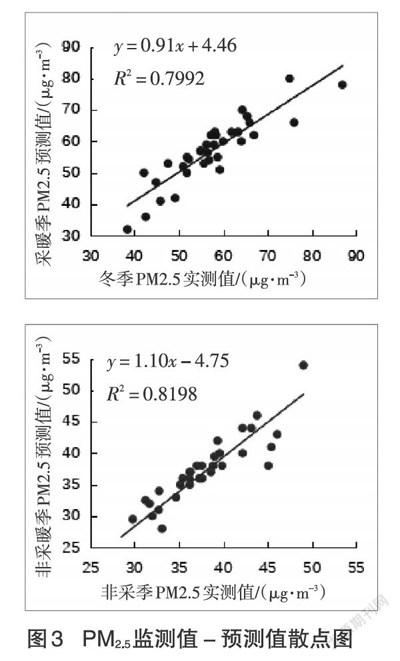
为了进一步验证模型精度,本研究采用留一交叉互验法,从图3可知采暖季LUR模型的模拟精度为0.7992,非采暖季LUR模型的模拟精度为0.8198,模型的模拟精度整体表现良好。经过对PM2.5的监测值和预测值进行计算,得到采暖季均方根误差为6.66μg·m-3,非采暖季均方根误差为5.91μg·m-3。
表2 PM2.5多元线性回归结果吴健生等[6]利用LUR模型模拟重庆市PM2.5浓度的调整R2为0.800;Wu等[18]利用LUR模拟北京市PM2.5浓度的精度的调整Rz为0.58,均方根误差为9.31μg·m-3。与文献[6]、[18]相比,本研究的LUR模型误差更小、解释度更高。
2.4 采暖与非采暖季PM2.5模拟
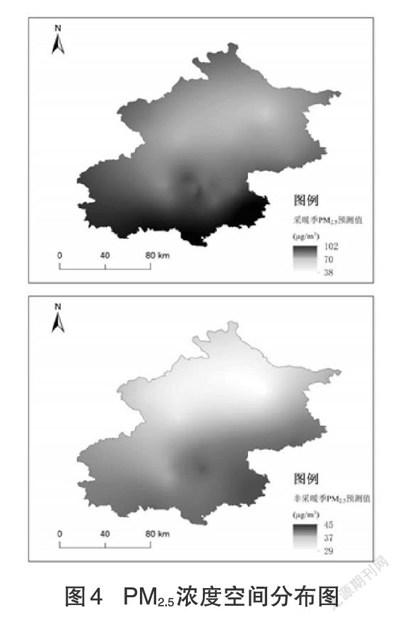
通過ArcGIS创建渔网把北京市划分成1km×1km规格网点,利用LUR模型计算出各格网点PM2.5浓度预测值,再用Kriging插值法就可以得到北京市的PM2.5浓度空间分布。北京市的采暖季与非采暖季PM2.5浓度模拟如图4所示,可以看出北京市的PM2.5污染主要集中在东南部人口、交通密集的平原区域。通过对比采暖季与非采暖季PM2.5浓度,发现采暖季的PM2.5污染尤其严重。
3 讨论
(1)采暖季的逆温天气以及人口密集区污染物排放对PM2.5浓度的影响很大,但本研究没有加入研究区内重点废气排污企业,未来可以考虑加入研究区重点废气排污企业等因素,进一步探索PM2.5的相关影响因素。
(2)本研究是基于国控监测站点,通过LUR模型进行北京市的PM2.5浓度空间分布模拟,但由于国控监测站点主要分布在城市区,在一定程度上限制了模型精度,未来可以考虑加入分布在偏远地区的省控、县控监测站点进行模拟。同时本研究采用的LUR模型是通过线性回归的方法,对于复杂的大气污染物,模型解释力度还远远不够,未来可以考虑使用非线性回归的方法,或者加入深度学习算法改进LUR模型来进一步提升模型的解释性。
4 结论
(1)2018年11月-2019年10月北京市PM2.5浓度整体偏高,采暖季(11月-3月)PM2.5浓度为58μg·m-3,非采暖季(4月-10月)PM2.5浓度为37μg·m-3,严重超出国家二级标准和世卫组织标准。PM2.5浓度整体呈现采暖季高、非采暖季低的现象,这与采暖季处于逆温天气多发季节有很大关系。
(2)采暖季PM2.5浓度与农田、气压、高速公路、二级公路呈正相关;与湿地、水体、森林、灌木、风速、降水量、相对湿度呈负相关。非采暖季PM2.5浓度与气压、人口、干道、高速公路呈正相关;与水体、森林、灌木、风速、降水量、相对湿度、DEM呈负相关。采暖季LUR模型的变量有风速、相对湿度、森林、湿地;非采暖季LUR模型的变量有风速、降水量、气压、干道、一级公路。
(3)采暖季LUR模型调整R2为0.799,模拟精度为0.7992,均方根误差为6.66μg·m-3:非采暖季LUR模型调整R2为0.807,模拟精度为0.8198,均方根误差为5.91μg·m-3,模型表现良好。
(4)北京市PM2.5浓度主要分布在东南部人口、交通密集的平原区域,整体呈现南高北低的状态,PM2.5浓度受地形地貌、人口活动、机动车驾驶、污染物排放的影响很大。
[参考文献]
[1]常彦君,王进,许明,等.河北地区雾霾天气下大学生健康路径研究lJ].廊坊师范学院学报(自然科学版),2019,19(4):87-90.
[2]刘炳杰,彭晓敏,李继红.基于LUR模型的中国PM2.5时空变化分析[J].环境科学,2018,39(12):5296-5307.
[3]HOEK G,BEELEN R,HOOGH K D,et al.A Review ofLand-Use Regression Models to Assess Spatial Variation ofOutdoor Air Pollution[J].Atmospheric Environment,2008,42(33):7561-7578.
[4]TANG R,BLANGIARDO M,GULLIVER J.Using BuildingHeights and Street Configuration to Enhance Intra UrbanPM10,NOx,and N02 Land Use Regression Models[J].En-vironmental Science&Technology,2013,47(20):11643-11650.
[5]江笑薇,任志远,孙艺杰.基于LUR和GIS的西安市PM2.5的空间分布模拟及影响因素[J].陕西师范大学学报(自然科学版),2017,45(3):80-87+106
[6]吴健生,廖星,彭建,等.重庆市PM2.5浓度空间分异模拟及影响因子[J].环境科学,2015,36(3):759-767
[7]许刚,焦利民,肖丰涛,等.土地利用回归模型模拟京津冀PM2.5浓度空间分布[J].干旱区资源与环境,2016,30(10):116-120.
[8]汉瑞英,陈健,王彬.利用LUR模型模拟杭州市PM2.5质量浓度空间分布[J].环境科学学报2016,36 (9):3379-3385.
[9]阳海鸥,陈文波,梁照凤.LUR模型模拟的南昌市PM2.5浓度与土地利用类型的关系[J].农业工程学报,2017,33(6):232-239.
[10]彭霞,佘倩楠,龙凌波,等.基于移动监测和土地利用回归模型的上海市近地面黑碳浓度空间模拟[J].环境科学,2017,38(11):4454-4462.
[11]王睿哲,胡荣明,李朋飞,等.基于 LUR模型的PM2.5度空间分布监测及分析[J].环境工程学报,2020,14(10):2843-2852.
[12]张南,熊黑钢,葛秀秀,等.北京市冬季雾霾天人体呼吸高度PM2.5变化特征对气象因素的响应[J].环境科学,2016,37(7):2419-2427.
[13]高振翔,葉剑,周红根,等.江苏省PM2.5和PM10时空变化特征及其与气象因子的关系[J].环境科学与技术,2020,43(7):51-58.
[14]康晓明,崔丽娟,赵欣胜,等.北京市湿地削减大气细颗粒物PM2.5功能[J].生态学杂志,2015,34 (10):2807-2813.
[15]栾天,郭学良,张天航,等.不同降水强度对PM2.5的清除作用及影响因素[J].应用气象学报,2019,30(3):279-291.
[16]王嫣然,张学霞,赵静瑶,等.北京地区不同季节PM2.5和PM10浓度对地面气象因素的响应[J].中国环境监测,2017,33(2):34-41,
[17]袁小燕,叶芝祥,杨怀金,等.成都市道路细颗粒物污染特征[J].环境工程学报,2015,9(9):4598-4602.
[18]Wu J,Li J,Peng J,et al.Applying Land Use RegressionModel to Estimate Spatial Variation of PM2.5 in Beijing,China[J].Environmental science and pollution researchinternational,2015,22(9):7045-7061.
[收稿日期]2021-06-02
[基金项目]空间天气学国家重点实验室开发课题(201909);安徽省高校自然科学基金重点项目(KJ2019A0103)
[作者简介]杜宝强(1972-),男,中国电子技术标准研究院高级工程师,研究方向:能源与环境污染防治。
[通讯作者]杨明亮(1995-),男,安徽理工大学电气与信息工程学院硕士研究生,研究方向:能源与环境污染防治。
猜你喜欢
大气科学学报(2022年3期)2022-07-22
科技研究·理论版(2021年20期)2021-04-20
初中生世界·八年级(2021年2期)2021-03-11
理财·市场版(2019年5期)2019-09-10
检察风云(2018年12期)2018-07-04
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
电子技术与软件工程(2016年24期)2017-02-23
山东农业科学(2016年11期)2016-12-17
环球时报(2016-11-25)2016-11-25
商(2016年33期)2016-11-24
