
基于生成对抗网络的遮挡人脸图像修复的改进与实现
2021-01-15 08:22武文杰王红蕾
计算机应用与软件 2021年1期
武文杰 王红蕾
(贵州大学电气工程学院 贵州 贵阳 550025)
0 引 言
在当今信息时代,图像是一个非常重要的信息载体,许许多多的信息都是从图像中获得的,因此图像修复工作十分重要。图像修复是指将一幅不完整的图片使用一定的手段进行填充或补全。图像修复的意义重大,其不仅能够在文物复原上发挥巨大的作用;在资料修复、辅助人脸识别等方面同样有很高的应用价值。
传统的图像修复方法主要分为两大类:(1) 适用于缺损面积较大的图像填充修复,常用的方法有块匹配(PatchMatch)方法[1]、统计块概率修复方法[2]等,这些方法主要是依据原图上已有的信息进行修复,如果图像上的信息与缺损区域相似度不高,则修复效果很差。(2) 适用于小尺寸的图像修复方法,常用的方法有全变分方法、Criminis 算法、快速行进算法等[3],这些算法内容修复较好,但是图像会缺乏高层次连贯性,且缺损区域变大就会变得模糊。总体来说,传统的图像修复的方法都是利用原图的已有信息进行修复,在内容和图像层次上缺乏连贯性,使得修复结果不够好,且当图像的缺损较大时,很可能会造成关键信息的丢失,使结果更加不如人意。
深度学习方法让图像问题有了新发展,其在图像修复、图像超分辨率[4]等图像处理问题上效果显著。与传统的图像修复方法相比,深度学习方法的优点在于可以通过不断学习图像的特征加深对图像的了解,从局部和整体对图像进行修复,弥补了传统方法内容纹理缺乏连贯性和大块缺失区域修复困难的缺陷[3]。2015年,Radford 等[5]提出深度卷积生成对抗网络(DCGAN),其基本原理是把卷积神经网络和生成对抗网络相结合,将CNN的思想加到生成器模型和判别器模型中,提高生成对抗网络的性能,从而提高对图像的修复能力。
相比前面提到的几种方法,本文使用的方法有以下如下特点:(1) 结合自动编码器和DCGAN方法,使用编码器-解码器(encoder-decoder)结构的卷积神经网络[6]作为生成器模型,生成与待修复图像近似的生成图像;(2) 使用改进的WGAN(WGAN-GP)来训练判别器模型;(3) 在生成器的层间增加跳跃链接(skip-connection)。
1 相关知识
1.1 生成对抗网络(GAN)
生成对抗网络(GenerativeAdversarialNetworks,GAN)是Goodfellow等[7]从博弈论中的 “二人零和博弈”中受到启发而提出的。如图1所示,生成器G和判别器D这两部分构成了生成对抗网络。其中:生成器的作用是获取训练数据分布并且不断地生成与真实图像相似的图像;判别器的作用是判断输入的数据是真实数据还是来自生成器的生成数据,将结果反馈回生成器。输出结果概率越接近50%,生成数据越逼真。
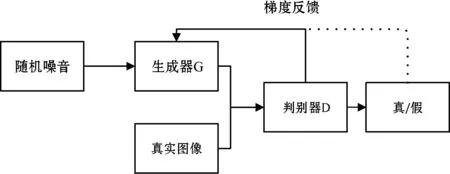
图1 生成对抗网络
1.2 Wasserstein GAN [8]
Wasserstein距离也叫Earth-Mover(EM)距离,为了将其引入到函数中使用,Arjovsky等[8]将Wasserstein距离转化为如下公式:
(1)
Wasserstein距离是一个连续的平滑函数,能在两个分布没有重叠的情况下依旧反映它们的远近,这是KL散度、JS散度所办不到的,这也是Wasserstein距离的优势所在[9]。其原因在于KL和JS散度不是平滑的,是突变的,只存在最大与最小。当用梯度下降法对模型进行优化时,Wasserstein距离能够提供梯度,KL和JS散度就没有作用了。同理可得,在高维空间中,两个分布不重叠,那么KL和JS散度便就完全失效而Wasserstein距离有效。
WGAN的生成器损失函数:
Ex~Pg[fW(x)]
(2)
WGAN的判别器损失函数:
Ex~Pg[fW(x)]-EX~Pr[fW(x)]
(3)
1.3 WGAN-GP[10]
WGAN-GP就是在连续性限制的条件方面改进的WGAN。在WGAN中,当权重剪切到某个范围时,网络的大部分权重可能就集中在两个数上,这对深度神经网络来说并不能很好发挥深度神经网络的强大的拟合能力。而且,盲目剪切权重可能导致梯度消失或者梯度爆炸,很容易造成训练的不稳定性。如果剪切范围过小就会导致梯度消失,如果剪切范围稍大一点,就会导致梯度爆炸。
文献[10]提出了使用梯度惩罚(gradient penalty)的方法来满足lipschitz连续性条件,解决了训练梯度消失和梯度爆炸的问题[10],其实质就是给连续函数增加了一个外罚。
实验表明,WGAN-GP的收敛速度更快,生成样本的质量更高,且训练稳定方便。
WGAN-GP的判别器损失函数为:
L(D)=-EX~Pr[D(x)]+Ex~Pg[D(x)]+
(4)
2 网络模型结构
生成对抗网络模型由生成器模型G和判别器模型D组成,整体网络模型如图2所示。本文方法的大体思路:先通过随机噪音训练生成对抗网络模型,再将待修复的人脸图像通过训练后的模型生成与原图相似的图像。

图2 整体网络模型
2.1 生成器模型
在进行图像修复工作时,极少有完全破损或全部遮挡的情况,一般都是局部破损或部分遮挡,图像上总会有完好的部分。因此在进行修复时可以将这些完好的信息保留下来,即将输入层完好的信息直接传到对应输出层,将这些信息共享,可能会提高输出图像的质量。所以,本文使用跳跃连接[11]的方式来连接编码器和解码器,从而将这些低级特征由低层直接传到更高层,这样就可以更大地保留图像的底层结构。普通的编码器-解码器连接如图3所示,跳跃连接如图4所示。
图3 编码器-解码器连接

图4 跳跃连接
图5为生成器的模型。conv指卷积层,deconv代表解卷积层,卷积核的大小为5×5。生成器分为编码器和解码器两部分,是由下采样的卷积层与上采样的解卷积层组成,同时通过跳跃连接将低级别的特征传到高层特征上。激活函数的使用借鉴WGAN,下采样层使用激活函数Leaky-ReLU[8],防止梯度稀疏;上采样层使用ReLU[12],最后一层使用Tanh激活函数[13]。生成器模型参数如表1所示。

图5 生成器模型
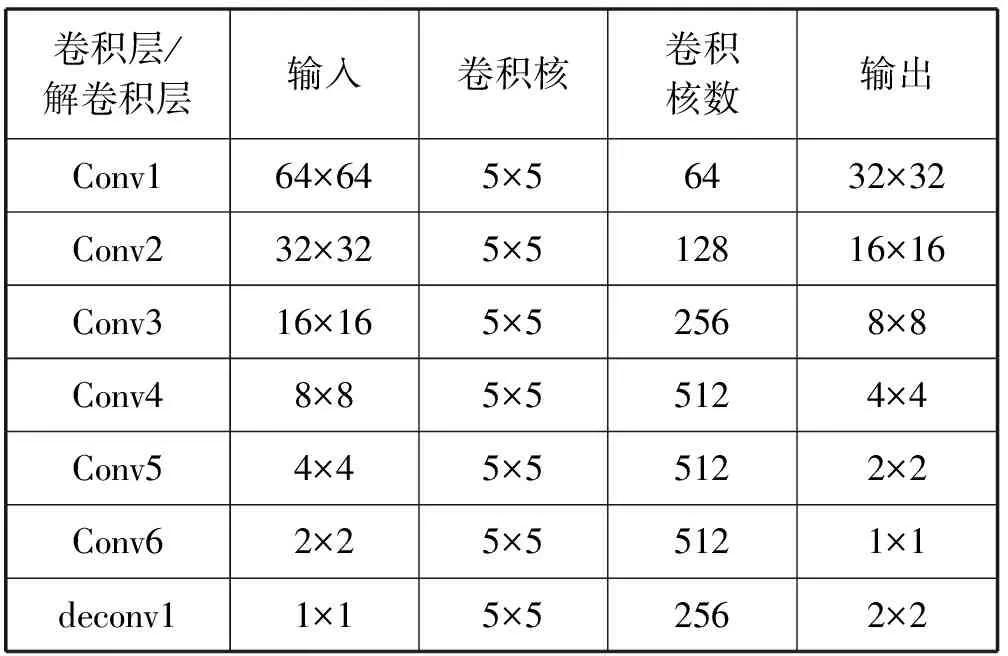
表1 生成器模型参数
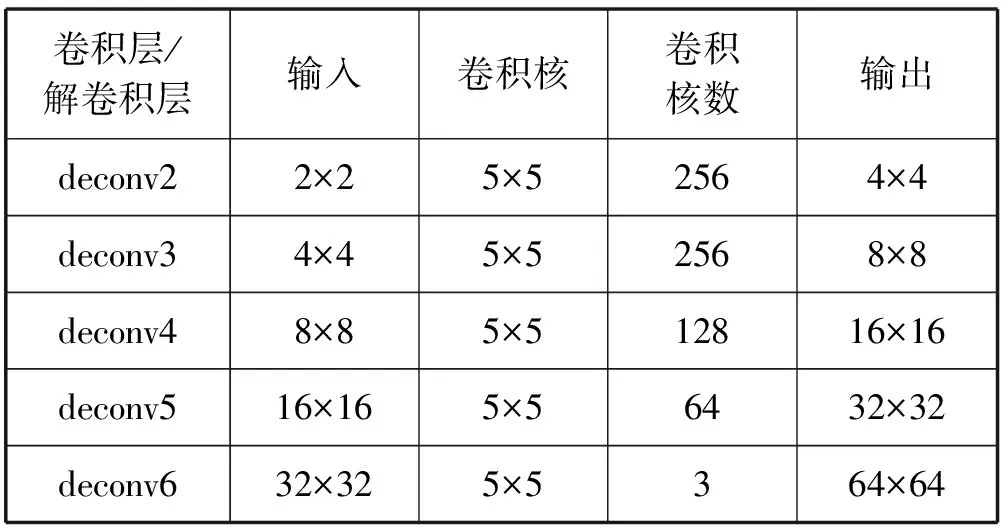
续表1
2.2 判别器模型
判别器D是通过与生成器进行对抗学习,不断提高识别能力,从而提高识别出真实样本的准确率。如图6所示,判别器由卷积网络构成。判别器的输入包括生成图像和真实图像两个部分。因为使用的是Wasserstein距离衡量去两个分布间的距离,所以判别器要单独对每一样本进行梯度惩罚,为了防止同一batch不同的样本相互依赖,判别器各层不用Batch Normalization[14]。判别器模型参数如表2所示。
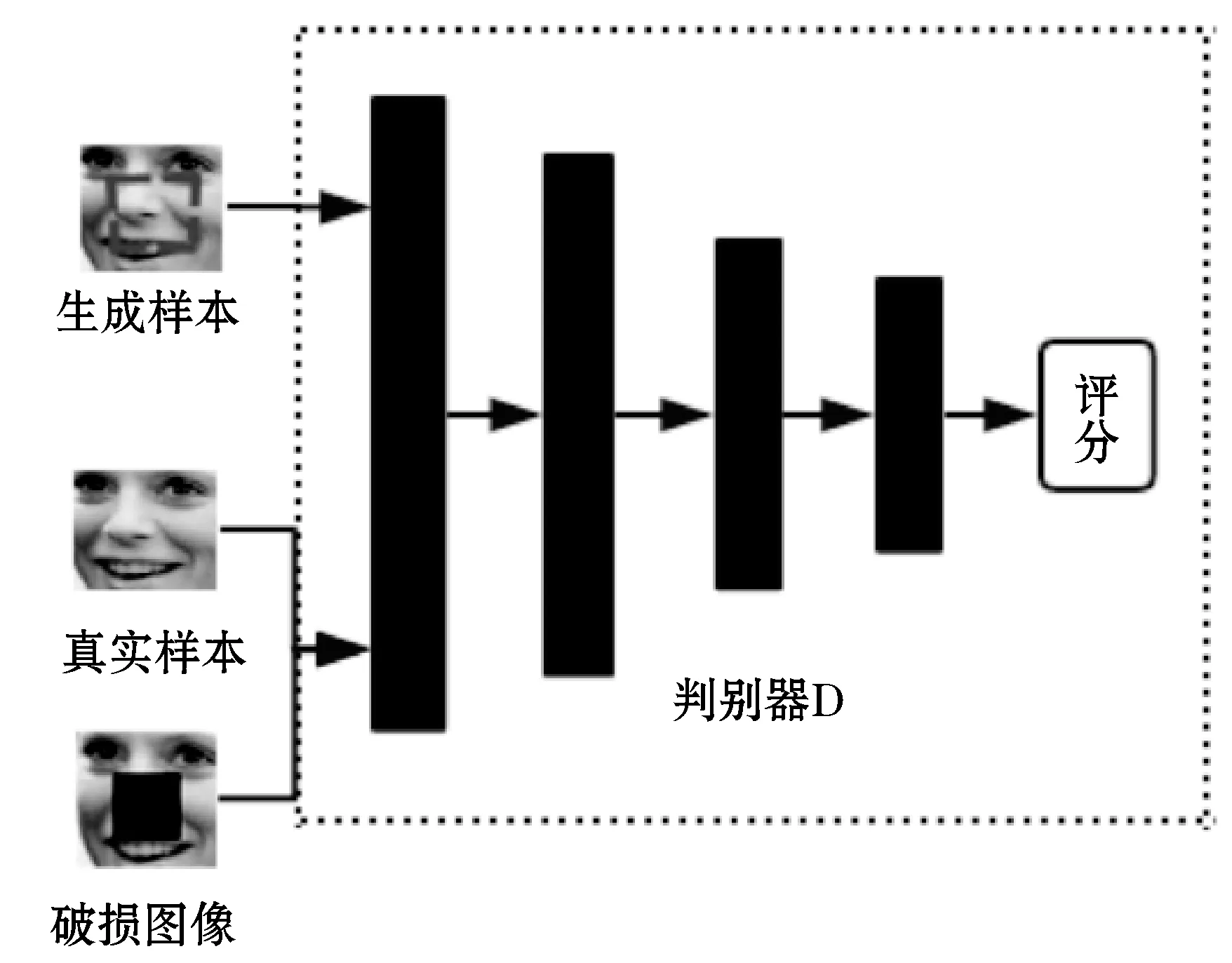
图6 判别器模型
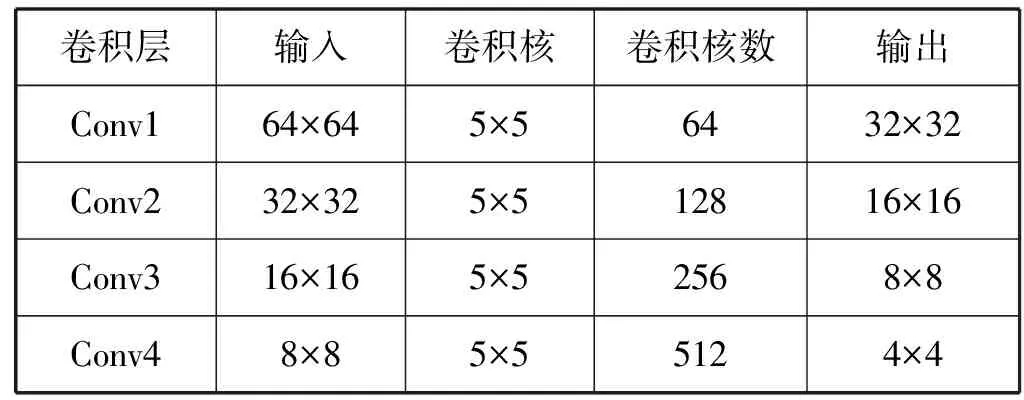
卷积层输入卷积核卷积核数输出Conv164×645×56432×32Conv232×325×512816×16Conv316×165×52568×8Conv48×85×55124×4
3 损失函数
3.1 生成器损失函数
传统的生成对抗网络的生成器损失函数只有生成对抗损失,为了生成器能够生成与真实图像更加相似的图像,本文在传统生成器的损失函数上增加了内容损失。对抗损失可以理解为破损图像生成与真实的差别,内容损失可以理解为有内容的区域(未破损区域)生成与真实的差别。
(1) 对抗损失。本文将破损图像当作条件加入到生成器输入中,此时对抗损失为:
-EZ~pz(z),(x,y)~prD(G(z,y),y)
(5)
(2) 内容损失。我们使用L1距离来判断生成器生成样本的未破损区域与真实样本的未破损区域的差别。假设M为图像掩膜,其与输入图像具有同样大小的尺寸,其中破损像素点用0表示,完好的像素点用1来表示,则内容损失为:
EZ~pz(z),(x,y)~pr(x,y)[‖M⊙(x-G(z,y))‖1]
(6)
式中:符号⊙代表两个矩阵的对应元素相乘。
最终,结合以上两部分损失函数,生成器损失函数的形式为:
-EZ~pz(z),(x,y)~pr(x,y)D(G(z,y),y)+
α1EZ~pz(z),(x,y)~pr(x,y)[‖M⊙(x-
G(z,y))‖1]
(7)
式中:α1为权重系数。
3.2 判别器损失函数

L(D)=-EX~Pr[D(x)]+Ex~Pg[D(x)]+
(8)
注意,Lipschitz限制区域只需在生成样本、真实样本集中区域以及夹在他们中间的区域。
最后在判别器增加了破损图像为条件,因此最终的判别器损失函数为:
EZ~pz(z),(x,y)~pr(x,y)D(G(z,y),y)-
E(x,y)~pr(x,y)D(x,y)+
(9)
式中:α2为权重系数。
4 图像修复与对比实验
4.1 数据预处理
本文使用CelebA数据集作为训练集,该数据集包含202 599幅人脸图像,对这些图像进行面部识别并截取,并且归一化到64×64尺寸大小。实验中选取处理完的150 000幅图像作为训练集来进行训练。并将剩余CelebA数据集图像和LFW数据集作为测试集,做相同的处理。
4.2 实验细节
实验过程中,在进行训练时,使epoch=20,batch设置为5,那么每一个epoch迭代训练30 000次,本文在训练时采用文献[15]中的生成对抗网络算法,由生成器与判别器交替训练。实验设置参数α1=100,参数α2=10。训练还采用了Adam[16]优化算法,将网络的学习速率设置为0.000 2,参数β1=0.5,β2=0.9。结束之后,交换训练集和测试集,检验模型的鲁棒性。
由于数据集LFW只有10 000幅左右的图像,所以在LFW数据集epoch=50,且每一个epoch迭代训练2 000次,其余参数保持一致。
4.3 实验结果分析
图7所示为本文方法与DCGAN和Context Enconder[17]的修复对比图像,通过对面部大面积遮挡进行修复,可以看出使用本文的修复方法要优于其他两种修复方法。由图8可以看出,使用本文方法对不同部位的遮挡进行修复,均有良好的效果。

图7 各方法比较图
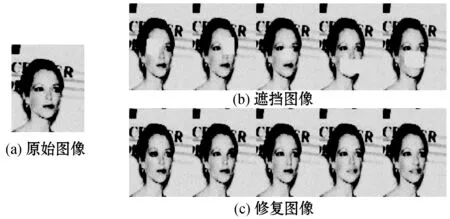
图8 不同部位修复效果
同时,本文对各种修复方法的修复时间也进行了对比,经过实验比较,这几种方法的修复时间相差很小,基本相同。
此外,通常图像修复有两个评估尺度:峰值信噪比(PSNR)和结构性相似(SSIM),这两个指标是现在使用较多的图像的客观评价依据。
峰值信噪比是基于误差敏感的图像质量评价[18]。PSNR值越大,修复的效果越好。
结构性相似是用来评判两幅图像整体的相似性,包括亮度、对比度、结构三个方面。SSIM值范围为(0,1),结果越靠近1,说明相似度越高。以图7中第一行的图像为例,本文方法与其他方法对比如表3所示。可见,不管是PSNR还是SSIM值,均是本文方法更好。

表3 不同算法峰值信噪比与结构相似度
5 结 语
本文提出一种新的基于生成对抗网络修复人脸的改进方法,对不同部位的遮挡修复和不同大小的遮挡修复均有较好的修复效果。这对于辅助人脸识别、社会治安管理、文物修复等方面都有应用价值。该方法的模型基于生成对抗网络,使用编码器-解码器(encoder-decoder)结构的卷积神经网络作为生成器模型,并且在隐含层的层间加入跳跃连接,加强网络自主学习能力,使生成图像更加真实。判别器损失函数用Wasserstein距离表示,并加入梯度惩罚,与DCGAN和Context Enconder相比最终使得修复效果较好。此外,本文方法还可以用于除人脸以外其他图像的修复以及文本修复。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
农业工程学报(2022年12期)2022-09-09
传感器世界(2022年4期)2022-08-05
传感器世界(2022年3期)2022-05-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
数字技术与应用(2021年1期)2021-03-24
华东师范大学学报(自然科学版)(2019年3期)2019-06-24
福建基础教育研究(2019年3期)2019-05-28
