
基于评论个性化多层注意力的商品推荐算法
2021-01-15 08:28冯兴杰曾云泽
计算机应用与软件 2021年1期
冯兴杰 曾云泽
(中国民航大学计算机科学与技术学院 天津 300300)
0 引 言
推荐系统是一种在电商平台中十分常见的信息过滤系统,它能基于用户的历史记录来学习用户的兴趣和爱好,进而推测用户的偏好和对商品的评分。
近年大量推荐算法被相继提出,其中预测用户对未知商品的评分是一个主要分支。特别是作为工业界中极其流行的一种技术——协同过滤,其中很多都是仅使用评分数据的矩阵分解方法,但其性能主要受评分数据天然的稀疏性所制约。使用评论文本来对用户偏好和商品特点进行建模,是缓解数据稀疏的有效途径[1,4]。例如:ConvMF[1]将CNN结合到概率矩阵分解,能同时挖掘评分数据和商品描述文本数据;ANR[4]利用注意力机制,将评论与用户不同方面的偏好相结合来提高推荐性能。
尽管各种推荐算法性能的提高越来越显著,但是对于不同用户或商品时,提取评论信息所使用的模型是相同的,忽略了用户和商品的个性化特征。例如,假设用户A更关注价格问题,用户B更关心质量问题,他们同时写了一条相似的评论:该平板电脑价格高昂、质量不错。用户A由于价格的问题给出了一个不满意的评分,而用户B则给出了满意的评分。因此,对于不同的用户或商品,意思相近的一条评论将会有不同具体含义。特别是在学习用户偏好和商品特点的时候,要求模型学习出个性化的评论含义显得尤为重要。
本文提出基于个性化的多层注意力推荐算法PMAR(Personalized Multiple Attention Recommender)。具体地,PMAR包含两个模块:个性化评论编码器和个性化用户(商品)编码器。在个性化评论编码器中,先使用双向GRU对评论进行编码,使单词编码能考虑评论中的前后向上下文信息,然后基于单词级别的个性化注意力找出与当前用户(商品)最相关的单词,进而汇聚得到个性化的评论的隐表示;在个性化用户(商品)编码器中,基于评论级别的个性化注意机制,将个性化评论隐表示汇聚成用户(商品)隐向量。最后为了综合考虑用户隐因子和商品隐因子对最终评分的影响,设计了一种融合门机制将二者融合成一条隐向量,并将该隐向量送入因子分解机进一步挖掘不同隐因子间二阶组合影响,从而预测出最终用户对商品的评分。
1 相关工作
目前结合评论文本进行评分预测任务的相关工作众多,它们主要分为两类:基于主题模型的方法,基于深度学习的方法。
1.1 基于主题模型的方法
在传统自然语言处理领域,主要的文本数据特征提取器为主题模型LDA,基于评论文本的推荐算法也都是基于LDA来完成推荐任务。首个采用评论数据进行推荐的工作是HFT[5],其将以往的矩阵分解与LDA相结合。随后同样将LDA作为文本编码器的工作有RMR[6]和TopicMF[7]。RMR将LDA与混合高级模型相结合进一步提高评分预测精度。TopicMF通过非负矩阵分解得到评论的隐主题,并使得主题分布与用户(商品)隐因子建立映射关系。
随着自然语言处理技术的不断进步,CNN、RNN已经逐渐取代LDA,发展成为最主流的文本编码器,因而近年来基于深度学习的推荐算法已经成为研究热点。
1.2 基于深度学习的方法
最初使用深度学习组件CNN来提取评论信息进行推荐任务的是ConvMF,其能从评论文本中提取出用户和商品更深层的隐表达。而且CNN能够捕获卷积窗口内的局部上下文信息,ConvMF比基于LDA的方法取得一定的提升。随后同样基于CNN所做的改进工作如下:(1) DeepCoNN[2]指出ConvMF只使用了商品评论的信息,而忽略了用户评论,因而DeepCoNN采用并行的两个CNN同时提取用户评论和商品评论的信息;(2) TransNet[8]指出DeepCoNN在训练过程中保留待预测用户-商品对的评论是不合理的,因此其通过一个特制层使得模型能预测出待预测用户-商品对的评论的隐表达;(3) DRMF[9]在并行双CNN之后添加上一层双向GRU,达到捕获评论间交互信息的目的,其可以算作首个尝试运用RNN进行推荐的模型;(4) NARRE[3]同样采用双CNN结构,是首次通过注意力机制考虑评论对建模贡献的模型,其性能有着大幅度的提升。
上述研究表明,采取何种文本编码器对最终的模型性能并不能起到决定性作用。要取得进一步的性能提升,需要从编码过程如何结合实际的用户(商品)个性化信息着手。MPCN[10]采用Co-Attention机制,将用户评论的编码过程与商品评论的编码过程产生交互,这可以看作是在用户评论编码的过程引入了商品个性化信息,在商品评论编码过程引入了用户个性化信息。ANR是首个考虑评论不同方面(Aspect)编码的模型,因此对于同一条评论能编码出在不同方面下所对应的评论隐向量,能更好地从不同方面拟合用户的个性化信息。
尽管上述不同方法都能从不同方向进行改进,但是它们都忽略了用户单词级别、评论级别的个性化信息。因此,本文主要从这两个方面研究和实现了不同注意力机制来解决该问题。另外,用户和商品隐向量的最终融合交互方式是能影响模型性能的部分,因此本文提出了一种基于门控机制的融合策略。
2 本文模型
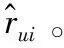
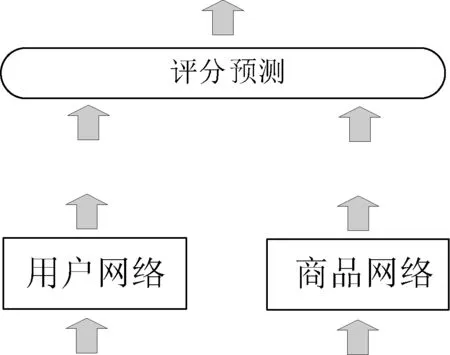
图1 模型整体示意图
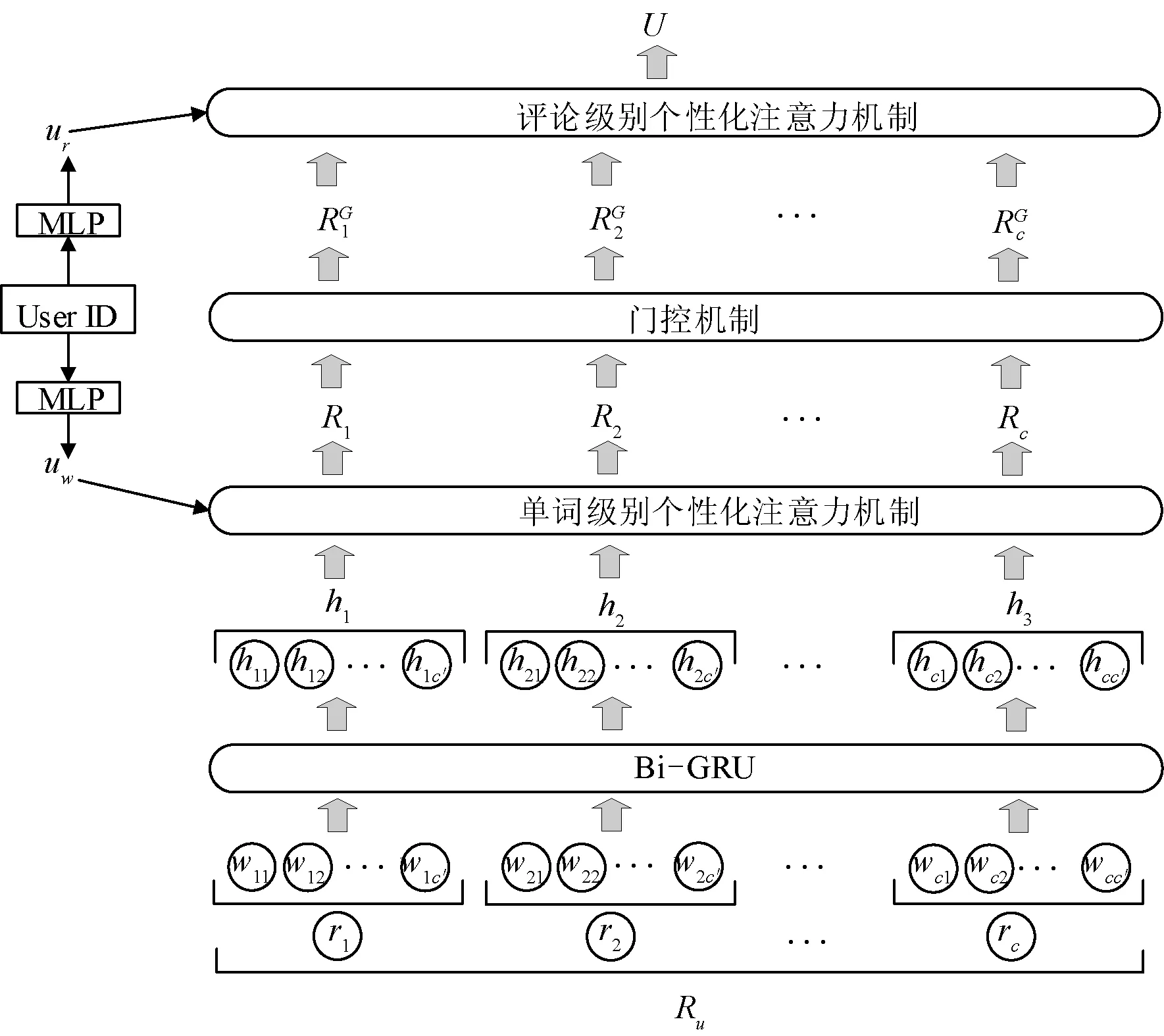
图2 用户评论网络内部结构图
2.1 个性化评论编码器
在用户评论网络,给定一个用户u的评论集Ru={r1,r2,…,rc},其中c表示用户评论集的最大评论数。特别地,每条评论rk都仅保留c′个单词。

由于每个用户(商品)都具有一个唯一的ID,本文先使用第一个全连接层(Multilayer Perceptron,MLP)将该ID映射成一个低维向量uw∈Rn,该向量用于捕获该用户单词级别的个性信息,其表达式为:
uw=ReLU(W1uid+b1)
(1)
式中:W1表示第一个MLP的权重;b1是偏倚项;uid为用户u的ID。
每个用户发表评论时的用词习惯及词语所表达的极性都具有个性化特性,为了使得单词隐向量具有个性化特性,这里首先需要学习出针对某用户u的单词级别的注意力向量,其具体计算如下:
(2)
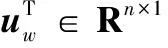
(3)

2.2 个性化用户(商品)编码器
考虑到R中并不是所有信息都有利于构建用户偏好向量,其存在少量不相关信息。因此,在汇聚c条评论前,本文添加一个门控机制来控制信息流。具体地,门控机制的输入为R,其输出为一个门控权重矩阵g∈Rc×2o:
g=σ(RWg+bg)
(4)
式中:σ为sigmoid函数;Wg∈R2o×2o为权重矩阵;bg为偏倚项。接下来使用g来控制R中各维度能流入下一层的信息量:
Rg=R*g
(5)
式中:*是对应元素的乘法,使得R和g中对应元素相乘,得到调整后的c条评论的表达为Rg∈Rc×2o。
现实中同一种表达方式或相似的评论,对于不同的用户将会产生出不同的情感极性。为了能基于用户的个性化信息来将汇聚c条评论用户的偏好向量,这里首先使用第二个MLP将用户ID映射成评论级别的低维向量ur∈Rn:
ur=ReLU(W2uid+b2)
(6)
式中:W2为第二个MLP的权重矩阵;b2为偏倚项。由于不同评论对用户偏好的建模贡献程度都不一样,这里需要学习出评论级别的个性化注意力向量:
(7)
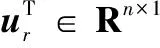
(8)
以上介绍了在用户评论网络中从用户评论集到用户偏好向量U的处理过程。同理,在商品评论网络中,从商品评论集同样可以得到商品特点向量I∈R1×2o。
2.3 个性化评分预测
在获取到用户偏好向量U和商品特点向量I后,以往的工作都是将二者拼接后送入因子分解机[12](Factorization Machines,FM)中回归出预测评分。FM的优点是能挖掘特征向量中二阶组合的影响。然而,本文认为通过拼接的方式来融合U和I的信息是相对朴素的手段,因此本文采用了一种基于门控机制的融合层,其能在维度层级进行向量间的融合[11]:
G=σ(UWG1+IWG2+bG)
(9)
Z=G*U+(1-G)*I
(10)
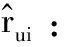
(11)
式中:b是全局偏倚项;wi是一次项的权重;〈vi,vj〉表示向量内积,其用于捕获二阶项交互的权重。
2.4 模型训练
本文模型的任务是预测出评分,实际上属于回归任务,常用的目标函数为评分损失函数:
(12)
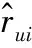
3 实 验
3.1 数据集和评估指标
本文实验使用的是公开的亚马逊评论数据集,其中包含24个类别的子集,本文选取其中3个数据集进行实验,它们分别为Tools and Home(TH)、Sports and Outdoors(SO)和Automotive(AT)。数据集的统计信息如表1所示。
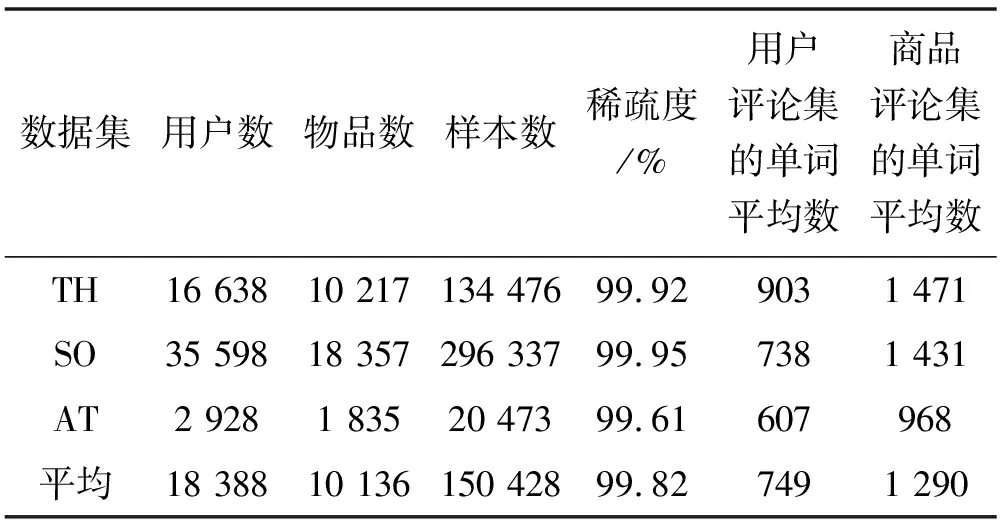
表1 数据集信息
模型的性能评估指标使用的是MSE(均方误差),其值越小代表模型预测得越准确,计算公式如下:
(13)
3.2 对比模型
本文模型主要是使用评论数据作为输入来预测评分,用作对比的经典模型有LFM[14]、NueMF[15]、ConvMF[1]、DeepCoNN[2]和NARRE[3]。其中评分数据指的是用户ID或商品ID,评论贡献指的是模型是否有区分评论集中各条评论的贡献。表2为对比模型比较。
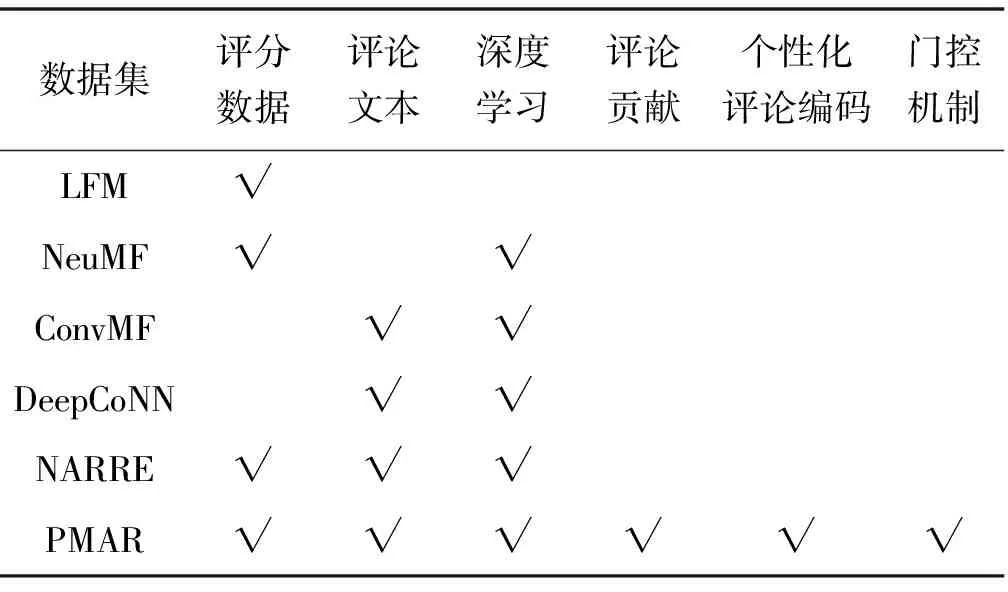
表2 对比模型比较
(1) LFM:最经典的矩阵分解算法,其仅用到评分数据,推荐性能严重受数据稀疏所影响。
(2) NeuMF:可以看作是LFM的深度学习版本。在LFM的基础上,添加深层的MLP来进行评分预测。
(3) ConvMF:首个使用文本信息进行评分预测的工作,采用CNN提取文本信息,并融入到概率矩阵分解中。
(4) DeepCoNN:首个将评论数据划分为用户评论集和商品评论集的模型,采用两个CNN分别提取二者的信息来进行评分预测。
(5) NARRE:在DeepCoNN的基础上进行改进,首次提出需要使用注意力机制来区分各条评论的贡献。
3.3 实验方案和模型超参数
为了实验的公平性,参照对比模型的文献,采取相同的划分策略:随机将实验数据集划分为训练集(80%)、验证集(10%)和测试集(10%)。在实验中,NeuMF采用三个全连接层,采用塔式结构,即从第一层到第三层的神经元为64、32、16。ConvMF、DeepCoNN和NARRE这三个基于CNN的模型,其卷积核个数都设置为50,卷积核大小为3。ConvMF、DeepCoNN、NARRE和本文模型都使用50维的Glove预训练词向量[15]。每个模型取得最优结果时,所需的用户(商品)特征向量的隐因子数都不同,因此实验中的隐因子个数在[5,10,15,20,25]五个数中遍历,选取最优结果进行输出。
3.4 性能对比
表3为各种算法在三个数据集上的对比结果。
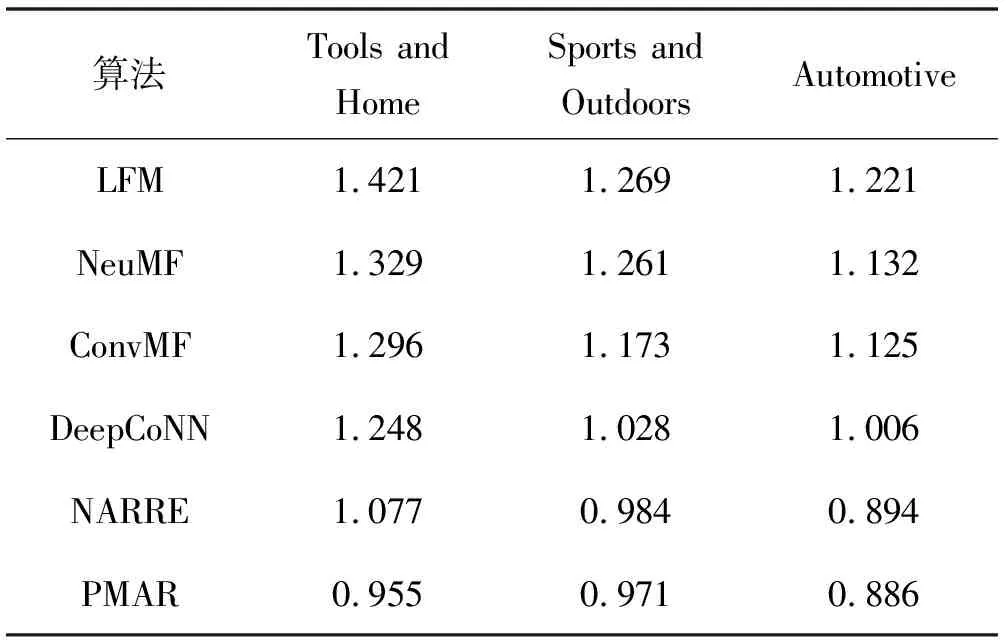
表3 各种算法在三个数据集上的结果
总体来看,仅使用评分数据的模型(LFM,NeuMF)的性能远不如使用评论数据的模型,仅使用评论数据的模型(ConvMF,DeepCoNN)性能不如同时使用评分数据和评论数据的模型(NARRE,PMAR)。另外,由于NARRE考虑了每条评论对建模的贡献,能够抑制无用评论对模型的影响,从而比不考虑评论贡献的模型(ConvMF,DeepCoNN)的性能有较大幅度的提升。然而上述模型在对评论文本编码的过程中,都忽略了个性化编码,即使两个不同的用户发表了一模一样的评论,该评论编码出来的隐表达是相同的。针对该问题,本文PMAR算法分别引入了单词级别的个性化注意力机制,使得评论编码的过程中引入了用户(商品)的个性化信息。相比NARRE,PMAR在考虑评论贡献的基础上,引入了评论级别的个性化注意力,使得从评论隐表达汇集成用户(商品)隐向量的过程中引入了个性化信息,因此取得了最好的性能。
3.5 消融实验
为了验证PMAR单词级别、评论级别的个性化注意力、门控机制的影响,本节设置了如下变体算法进行对比实验。
(1) PMAR-W:在PMAR的基础上,消除了单词级别个性化注意力机制。即将各个单词的贡献视为等同。具体的做法是将式(3)中的sw设置为sw=softmax(w),其中w=1,w∈Rc×c′×1中的各个元素的值都为1。
(2) PMAR-R:在PMAR的基础上,消除了评论级别个性化注意力机制,即将各条评论的贡献视为等同。具体的做法是将式(3)中的sr设置为sr=softmax(w),其中w=1,w∈Rc×1中的各个元素的值都为1。
(3) PMAR-WR:在PMAR的基础上,同时消除了单词、评论级别个性化注意力机制,将各单词、各评论的贡献视为等同。
(4) PMAR-G:用户偏好向量U和商品特点向量I后,都是直接将二者拼接来达到融合特征的目的。为了验证PMAR的门控融合机制,该变体采用拼接策略代替门控融合机制,即将式(10)修改为Z=U⊕I,其中⊕表示拼接操作。
各种变体算法和PMAR算法在3个数据集上的实验结果如图3所示。变体PMAR-WR由于不考虑各个单词、各条评论的贡献,且不具有个性化编码的特性,其性能最差。PMAR-W和PMAR-R由于不考虑单词级别或评论级别的贡献,都受到一定程度的影响,性能都不如标准的PMAR。另外,PMAR-W总会比PMAR-R更差,本文认为这是由于PMAR-W取消的单词级别注意力机制更接近模型的输入层,不仅影响了单词的编码也影响了评论的编码,其影响的覆盖范围比评论级别注意力更大。为了探究门控融合机制的影响,将其取代为DeepCoNN和NARRE所使用的拼接策略,结果表明,本文采用的门控融合机制能进一步提升模型性能。

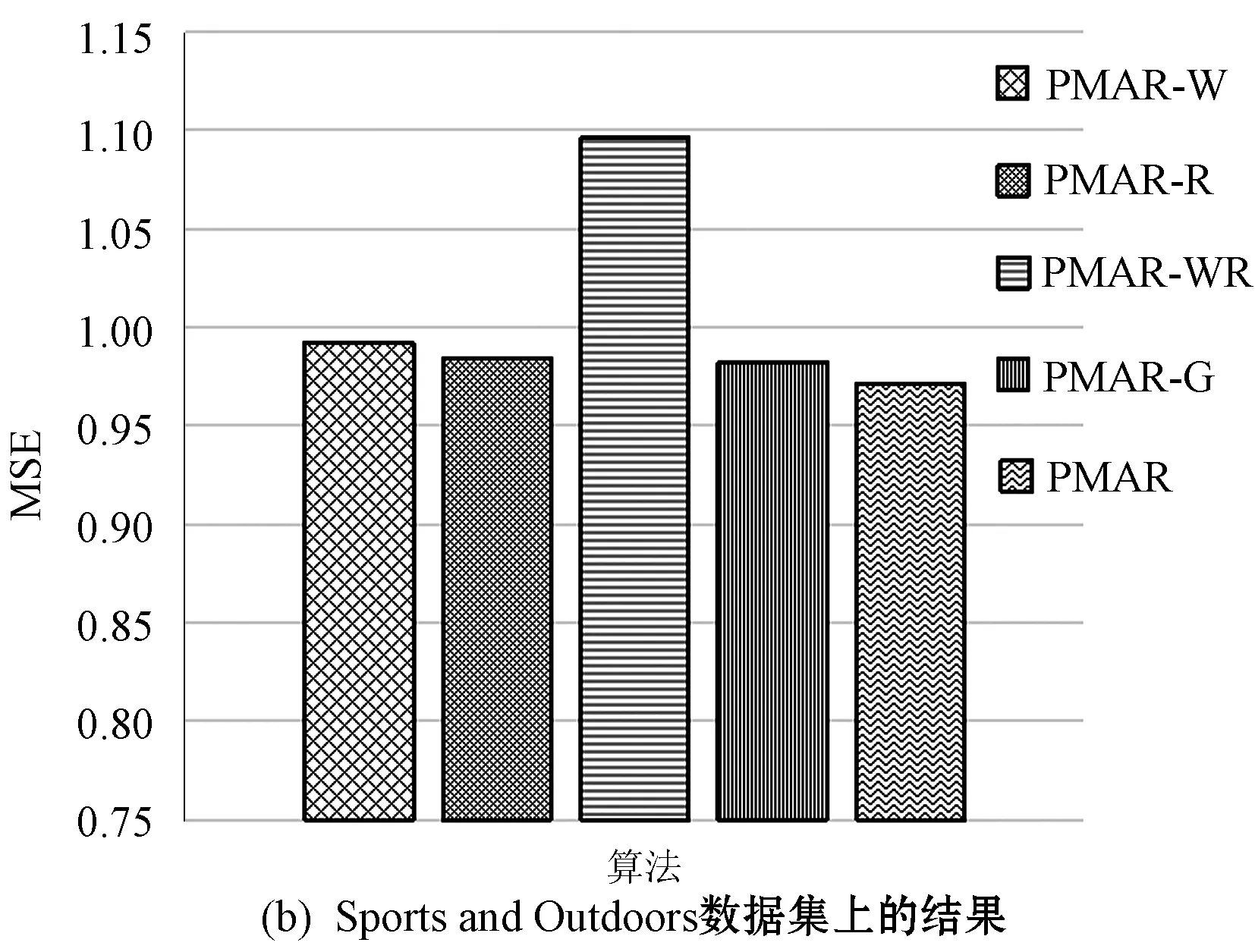
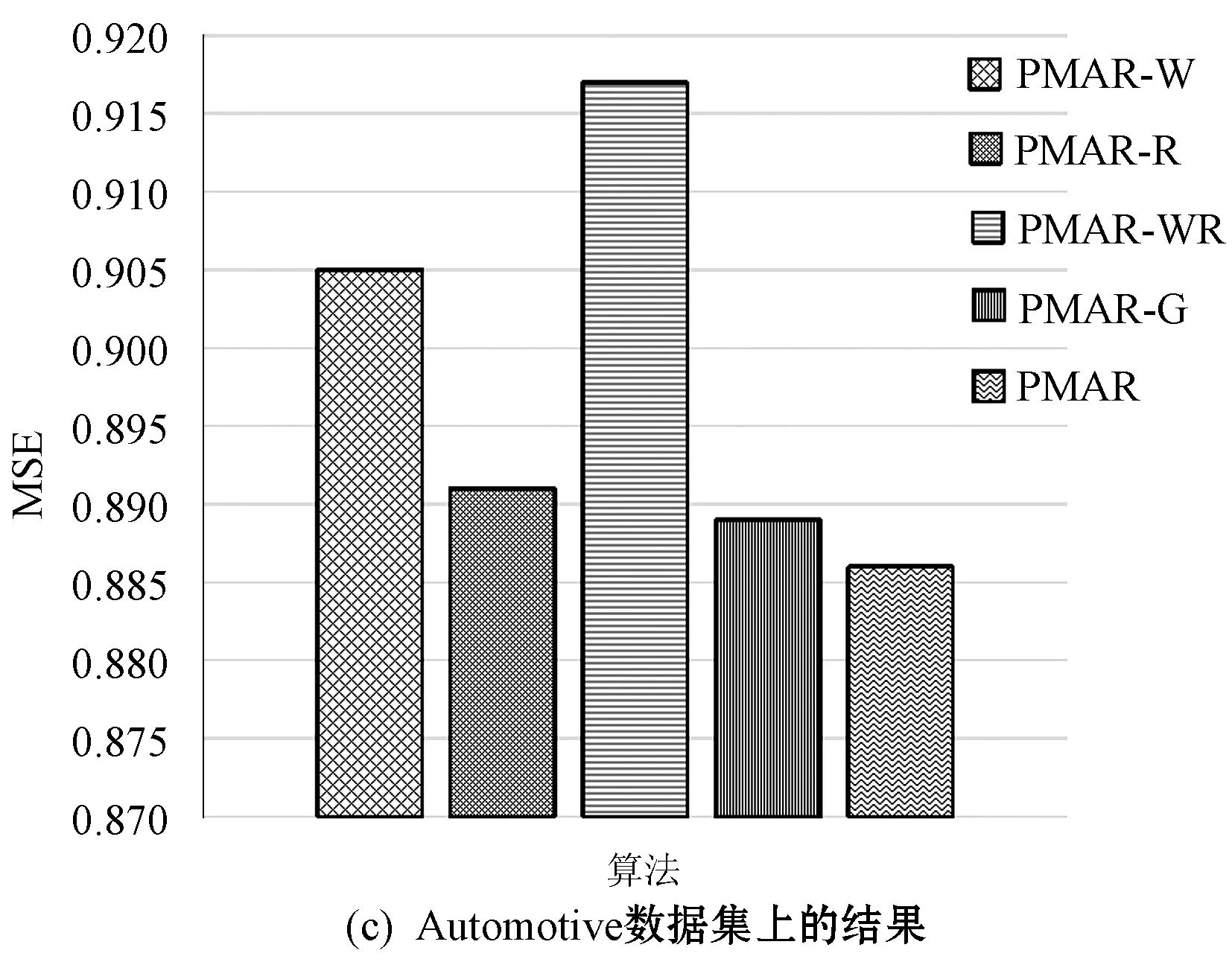
图3 各种变体算法的性能
3.6 可解释性实验
近年的模型对评论文本进行处理,将用户偏好和商品特点映射到相应的子空间,进而预测出用户和商品之间的契合程度(用户对商品的评分)。但是,仅基于预测的评分进行推荐面临可解释性差的问题。因此本文设置了单词级别和评论级别的注意力机制,要求模型得出预测评分的同时,找出能体现用户偏好和商品特点的单词和评论。在最理想的情况下,如果预测出的评分低,则能体现用户偏好的单词与最能体现商品特点的单词将相矛盾;如果预测出的评分高,则能体现二者特性的单词将相匹配。
表4展示了数据集 Tools and Home的四个不同用户-商品对的评论,其中前两个评论对是高评分,后两个评论对是低评分。对于每一个评论对,表中展示了其用户评论集中注意力得分最高的一条评论(最能体现用户偏好的评论)和商品评论集中注意力得分最高的一条评论(最能体现商品特点的评论)。同时,黑色选中的单词是评论中注意力得分高的单词,颜色越黑代表注意力分值越高。

表4 注意力分值可视化
观察前两个预测评分高的评论对,在用户568的评论中,看出该用户比较注重“comfortable”方面,这与商品52的“comfortable”的特点所匹配;在用户2272的评论中,知道该用户比较注重商品“easy”“setup”等易用性方面,这与商品5090中“setup”“no issues”等相匹配。相反,对于后两个预测评分低的评论对,用户619要求不能太重而商品1175则太重,用户29倾向价格实惠而商品1052则价格过高。
实验验证了本文模型能够从评论和单词级别提高预测评分的可解释性。特别是在给用户推荐商品的同时,通过展示注意力得分高的评论和单词给用户,更好地提高用户对推荐系统的信任度,并促进用户体验。
4 结 语
针对相关工作中忽略了单词、评论个性化信息的问题,本文提出单词级别、评论级别的个性化注意力机制,进一步提高推荐结果的可解释性。另外为了确保用户和商品隐向量之间的交互,本文设计出一种基于门控机制的融合策略,能取代以往工作中相对简单的拼接策略,进一步提高评分预测性能。
未来将采用目前最先进的文本编码器(BERT、CapsuleNet),并结合Co-Attention机制引入更高级的用户和商品的交互。
猜你喜欢
新高考·高一数学(2022年3期)2022-04-28
小雪花·成长指南(2022年1期)2022-04-09
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
———占旭刚4
北广人物(2020年48期)2020-12-22
经济数学(2020年4期)2020-01-15
晚晴(2018年3期)2018-12-06
第二课堂(课外活动版)(2016年2期)2016-10-21
高中生学习·高三版(2016年9期)2016-05-14
新高考·高二数学(2015年11期)2015-12-23
网球俱乐部(2009年9期)2009-07-16
