
基于深度学习的银行卡号识别研究与应用
2021-01-14 07:10李正辉高基豪
湖南邮电职业技术学院学报 2020年4期
刘 成,李正辉,高基豪
(郑州铁路职业技术学院,河南郑州450000)
人类对外界信息的认识及感知,最基本来自于视觉,因此对视觉信息的搜集与处理,一直是人类认识世界、认识规律的重要手段[1]。人工智能技术,通过对视觉信息的采集,对图形图像信息做科学的筛选、比对并分析,然后经过算法(深度学习)、理解和思考之后,将真实的现实内容呈现在计算机中[2]。
随着人工智能、深度学习技术的发展,人工智能技术在视觉领域方面的应用日益突出,得到了广泛的关注和研究[3]。尤其是随着电子商务的兴起,手机支付已成为主要的支付方式之一,在移动终端上快速准确地识别出银行卡号,完成银行卡与移动支付方式的绑定也成为了研究的热点。本文将使用基于深度学习的视觉识别技术,拓展现有的光学识别(OCR)银行卡号系统,解决目前卡号识别速度慢、效率低等问题,实现卡号的快速和准确识别[4-5]。
1 数据集制作
一般而言,对于常用的光学识别需要对图片进行预处理,包括灰度化、二值化、边缘检测、轮廓提取、归一化的处理,得到图片进行识别[6]。而基于深度学习的银行卡识别是在原来光学识别预处理的基础上,对处理过后的图片制作数据集。
原始数据集只有1084 张图片,为了提高模型准确性,使用数据增强技术。由于对图片的过度旋转以及对称处理会改变图片本质,这里采用的数据增强方式主要是对图片数据的亮度、饱和度、对比度进行随机变化,以及对图片加模糊和加噪声,共生成了8万张图片,用以辅助训练,同时对照片进行了小角度的随机翻转。
2 银行卡号定位检测
2.1 CTPN 网络介绍
对于复杂场景的文字识别,首先要定位文字的位置,即文字检测,深度学习框架CTPN 网络应运而生,CTPN 算法结合了CNN 与LSTM深度网络,能有效地检测出复杂场景下横向分布的不定长文字[7],如图1所示,是测试集中随机选取的银行卡定位效果。从图中可以看出,利用CTPN 算法可以将银行卡中的文字圈出,不超过两行。

图1 建设银行文本检测结果图
由于CTPN 网络是基于Faster R- CNN 改进而来,其基本结构和Faster R- CNN 结构类似,Faster R- CNN网络在2016 年被提出,经过R- CNN 和Fast RCNN的积淀,Ross B.Girshick 提出了新的Faster RCNN,在结构上,Faster R- CNN 已经将特征抽取(Feature,Extraction)、Proposa 提 取、Bounding box Regression(Rect,Refine)、Classification 都整 合 在 了 一个 网 络中,使得综合性能有较大提高,在检测速度方面尤为明显[8]。Faster R- CNN 网络结构如图2 所示。Faster R- CNN 网络主要有四个方面的内容:
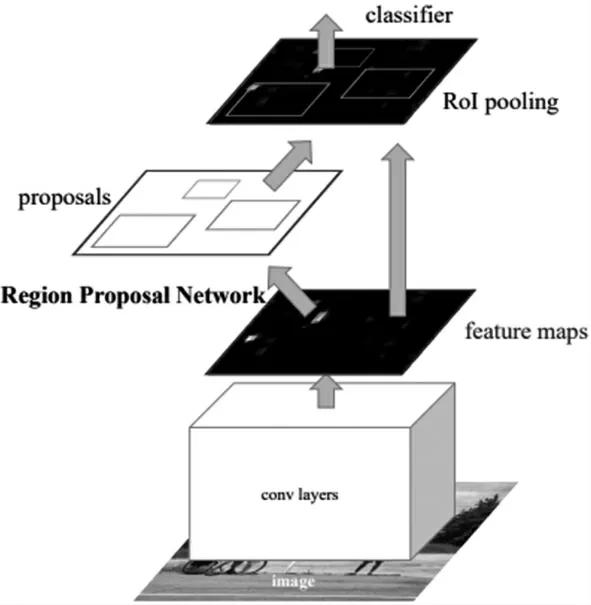
图2 Faster R- CNN 网络结构图
1)Conv Layers:作为一种CNN 网络目标检测方法,Faster R- CNN 首先使用一组基础的Conv + Relu+ Pooling 层提取Image 的Feature Maps。该Feature Maps 被共享用于后续RPN 层和全连接层。
2)Region Proposal Networks:RPN 网络用于生成Region Proposals。该层通过Softmax 判断Anchors 属于Foreground 或者Background,再利用Bounding Box Regression 修正Anchors 获得精确的Proposals[9]。
3)RoI Pooling:该层收集输入的Feature Maps 和Proposals, 综合这些信息后提取Proposal Feature Maps,送入后续全连接层判定目标类别[10]。
4)Classification:利用Proposal Feature maps 计算Proposal 的类别,同时再次Bounding Box Regression获得检测框最终的精确位置。
通过上述步骤,获得目标的检测位置和所属类别,银行卡号识别属于文本检测,有别于普通的目标检测,文本检测可以看成是特殊的目标检测,在通用目标检测中,每个目标都有定义好的边界框,检测出的Box 与当前目标的Groundtruth 重叠率大于0.5 就表示该检测结果正确。文本检测中正确检出需要覆盖整个文本长度,且评判的标准不同于通用目标检测,文字检测主要是Wolf 标准,而物体检测对边界的要求不高,一般IOU 大于0.7 即可,场景文字检测有明显的序列特征,而物体检测没有这些特征,和物体检测相比,场景文字检测含有更多的小尺寸的物体。
针对以上特点,CTPN 相较于Faster R- CNN 做了许多优化:在CTPN 中使用更符合场景文字检测特点的锚点;针对锚点的特征使用新的损失函数;改进了RPN,Anchor 产生的Window 的宽度固定为3;RPN 后面不是直接接全连接+ 分类/ 回归,而是通过一个LSTM 再接全连接层,RNN(双向LSTM)的引入用于处理场景文字检测中存在的序列特征,如在银行卡定位中,由于不同的银行卡卡号位数不同导致出现不定长字符,然而RNN 具有处理字符序列问题,在传统CNN 提取图像特征后,送入RNN 网络处理;Side-Refinement 的引入进一步优化文字区域。
2.2 CTPN 定位步骤
假设图片大小为C×H×W,输入为N 张:
1)利用VGG16 网络作为特征提取层,得到Conv5_3 的特征作为Feature Map,大小是W×H×C。
2)在Feature Map 上做滑窗,窗口大小是3×3,也就是每个窗口都能得到一个长度为3×3×C 的特征向量,这个特征向量将用来预测和10 个Anchor 之间的偏移距离,每一个窗口中心都会预测出10 个Text Propsoal。
3)将上一步得到的特征输入到一个双向的LSTM中,得到长度为W×256 的输出,然后接一个512 的全连接层,准备输出。
4)经过“FC”卷积层,变为的特征。
3 银行卡号识别
3.1 DenseNet 网络介绍
卷积神经网络在计算机视觉物体识别上优势显著,典型的模型有:LeNet5,VGG,Highway Network,Residual Network。一般卷积深度越深则效果越好,但随着卷积深度的增加也会面临梯度弥散的问题,即经过卷积层数越多,前面的信息就会渐渐减弱和消散。虽然目前已有很多措施去解决以上困境,如Highway Network、Residual Network 通过前后两层的残差链接使信息尽量不丢失。但这些措施都有一个共性:都是在前一层和后一层中建立一个短连接,无法很好地使信息在整个网络保持。DenseNet 网络相较于其他网络而言,是一种全新的网络结构,其网络中的每层都与该层之前的所有层相连,即每层的输入是前面所有层的输出的合并。这样的结构将需要更少的参数,减少中间变量,也增强了前向或后向计算时信息的完整性,进而达到更好的识别效果。图3 是DnseNet 结构图。因此,可利用DenseNet 网络实现银行卡号的识别。由于每个银行卡样式不一,卡号的整体长度也不一致,为处理不定长的字符,使用了CTC 损失函数。

图3 Densenet 网络结构图
3.2 模型训练
整个模型训练是在Linux 环境下进行,使用Python 3 语言与Keras 框架实现,并利用GPU 加速模型训练过程。在没有使用数据增强技术时,训练原始数据集100 个Epoch 后,得到如图4、图5 所示曲线。
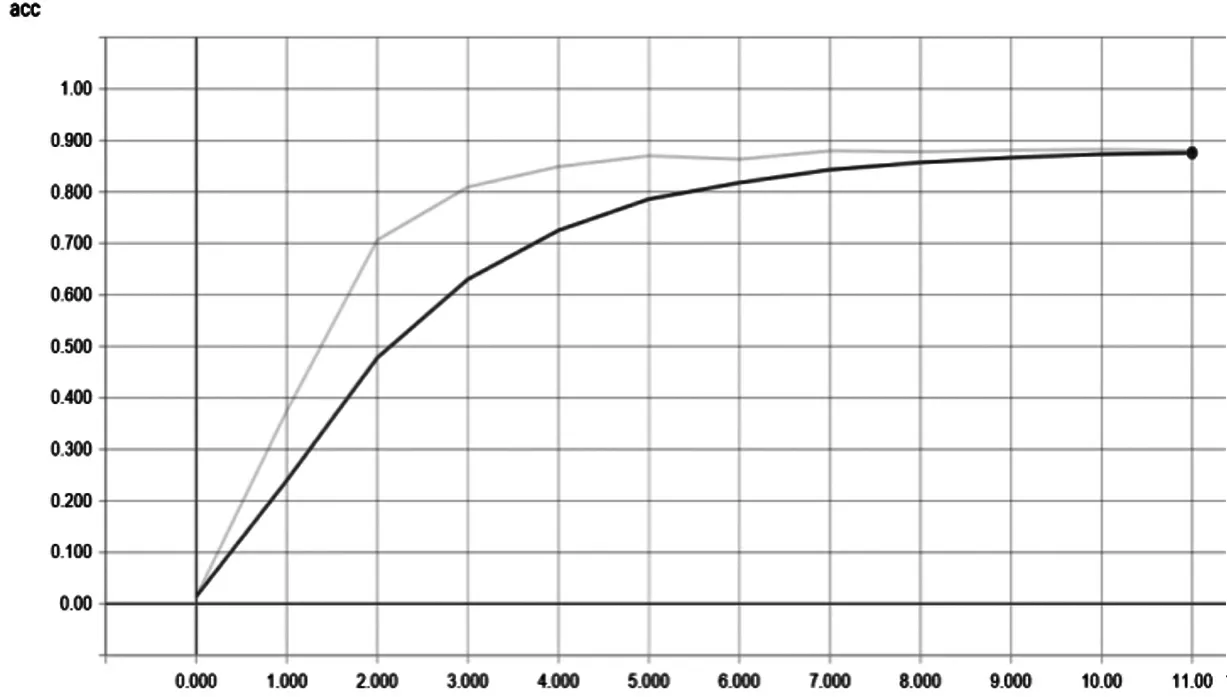
图4 训练集的正确率曲线图(横坐标为样本数,纵坐标为训练集正确率)
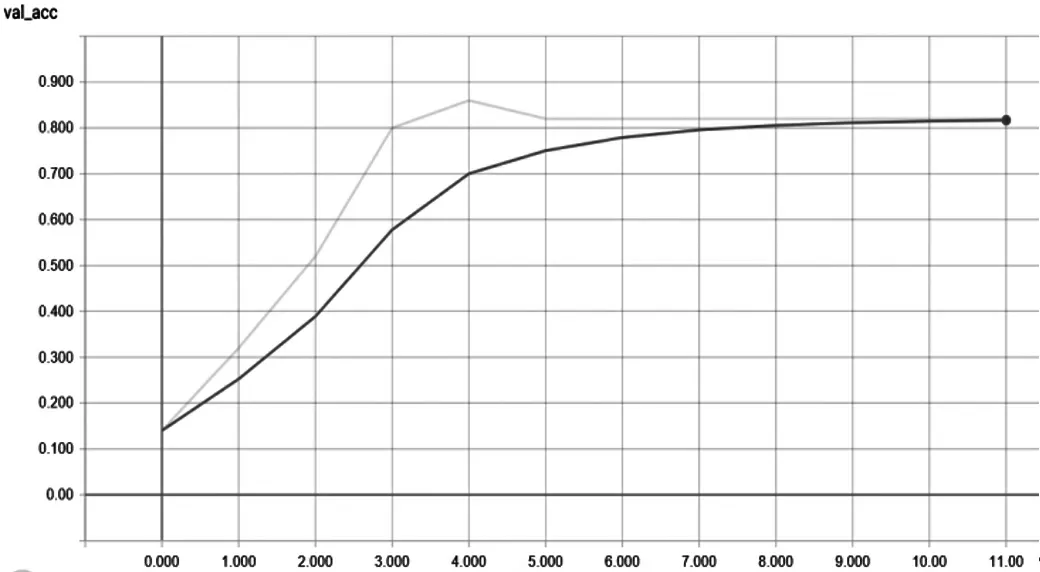
图5 验证集的正确率曲线图(横坐标为样本数,纵坐标为验证集正确率)
通过上图,可得原始数据训练集的正确率在90%左右,验证集的准确率在80%左右,很明显这是远远不能满足实际的工业化部署要求。因此,通过数据增强之后得到训练集约8 万张,按照二八原则,80%为训练集,20%为测试集,训练100 个Epoch 后,得到如图6、图7 所示曲线。
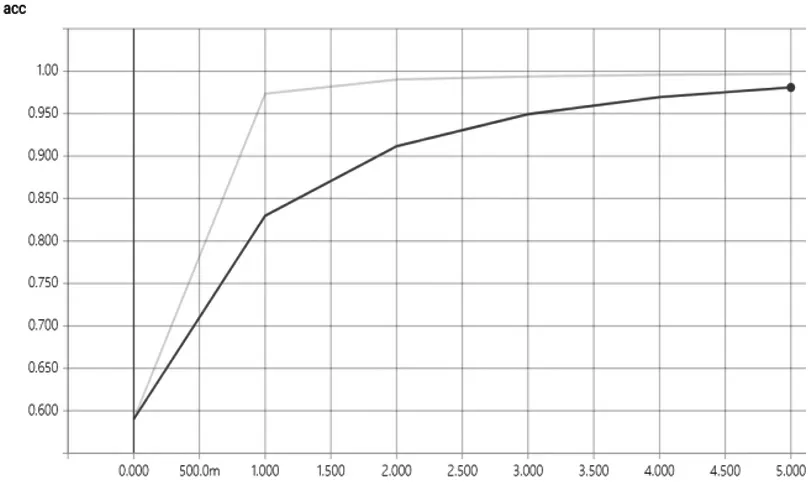
图6 数据增强- 训练集Acc 曲线图(横坐标为样本数,纵坐标为数据增强训练集正确率)
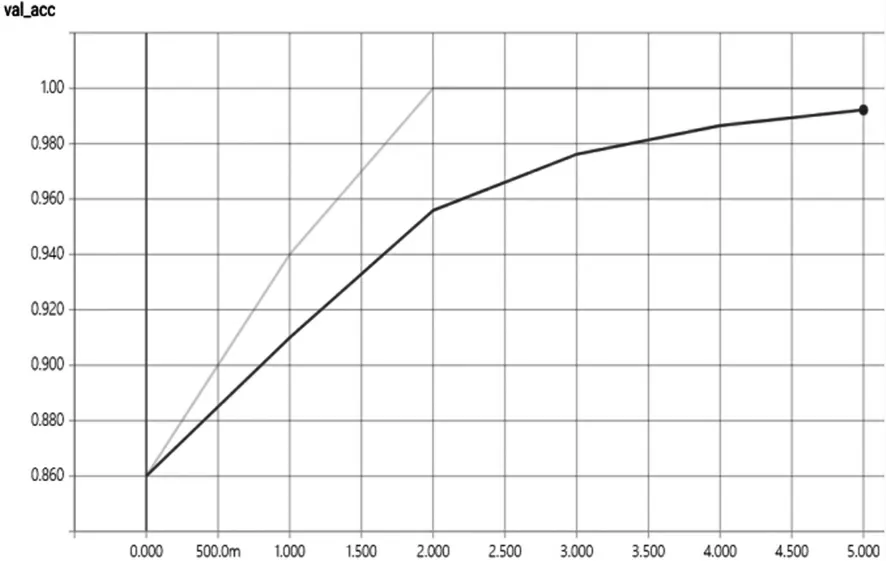
图7 数据增强- 验证集Loss 曲线图(横坐标为样本数,纵坐标为数据增强验证集损失值)
通过曲线图可以很清楚地看出,在使用数据增强技术之后,训练集的准确率达到了99%左右,验证集也达到了99%左右,模型的训练效果较好,在测试集中,模型准确率达到100%,因此可认为模型具有较强的泛化能力,能够快速准确地识别银行卡卡号。
4 结论
在模型都训练结束之后,对其识别结果进行了可视化展示,选择识别字体概率最大的框进行输出,也就是卡号,具有良好的用户交互式界面,方便用户操作。效果如图8 所示。
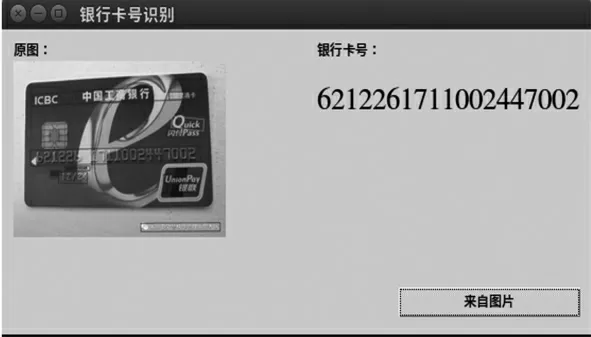
图8 银行卡号识别结果图
本文主要介绍了基于深度学习的银行卡卡号识别,包括了数据集的制作、卡号文本的定位及模型训练与验证,并着重介绍了CTPN 网络算法,为银行卡卡号文本检测提供了一种有效方法,通过深度学习网络DenseNet 进行模型训练使其达到了应用级别,极大地提高识别的效率和正确率。
猜你喜欢
蜜蜂杂志(2022年5期)2022-07-20
医学食疗与健康(2022年3期)2022-04-23
成都信息工程大学学报(2021年3期)2021-11-22
蜜蜂杂志(2021年11期)2021-02-18
中华养生保健(2020年7期)2020-11-16
语文世界(小学版)(2018年11期)2018-11-21
家教世界·创新阅读(2016年11期)2016-12-27
领导文萃(2016年20期)2016-10-26
故事会(2016年15期)2016-08-23
