
计算机自动作曲综述:一种通用框架
2021-01-13 07:27井音吉李圣辰
复旦学报(自然科学版) 2020年6期
井音吉,李圣辰
(北京邮电大学 电子工程学院,北京 100876)
当下人工智能技术飞速发展,在很多领域都已经取得了超越人类的成绩,人们进而思考计算机是否可以像人类一样进行如美术创作、音乐创作等艺术创作.计算机自动作曲其实是算法作曲的狭义概念,从广义上来说,算法作曲是指在创作音乐时,利用算法思维对音乐要素进行合理地组织,从两两音符的音程关系到音乐的音乐结构都符合音乐的逻辑.计算机应用普及后,人们将算法的思想写为计算机语言,利用计算机来实现算法的功能,目前的算法作曲系统也都是利用计算机进行生成音乐,所以目前自动作曲可以认为就是算法作曲.计算机自动作曲的历史可以追溯到1959年,Hiller等[1]利用计算机自动地作曲,随后Xenakis[2]创作了使用随机模型来学习音乐特征顺序进而生成音乐的系统.1981年,作曲家Cope[3]开始了音乐智能实验(Experiments in Musical Intelligence,EMI),他利用计算机来学习自己创作的乐曲,试图为自己创作音乐提供灵感,随后Cope发现该系统同样可以学习生成不同风格的音乐.自Cope的EMI系统得到关注后,对计算机自动作曲的研究有了显著的增长,大量的方法被用到音乐的生成系统中,如随机过程、启发式算法以及人工神经网络等.时至今日,谷歌的Magenta项目利用深度学习的方法来生成音乐.目前有大量的文章提出了各种各样的算法与系统来实现自动作曲,同时也有多篇综述文章对自动作曲技术进行回顾,2000年,Diaz-Jerez[4]将自动作曲方法从数学的角度进行划分,将2000年前的自动作曲方法分为随机过程算法(其中主要利用了马尔科夫链)、混沌理论、利用噪声的方法、数论、细胞自动机以及进化算法几类.Nierhaus[5]在2009年对自动作曲做了详尽的综述,该综述先对算法的历史做了回顾,从算法的产生讲到计算机实现算法的发展,最后再到计算机作曲系统的产生,作者从哲学以及自然科学的角度进行了阐述,接着作者以不同算法为分类方式将自动作曲算法分为了马尔科夫模型、生成语法模型、转移网络、混沌理论、进化算法、细胞自动机、人工神经网络和机器学习等类型,针对每一种分类作者给出了算法的简单介绍并列举了一些典型的系统.Fernndez[6]于2013年引入了人工智能(Artificial Intelligence,AI)的概念对自动作曲进行综述,说明人工智能的概念已经在作曲中形成,该综述依然是利用不同的算法进行分类.Lopez-Rincon[7]在对AI生成音乐的综述中介绍了用深度学习、生成对抗网络这些最新的人工智能方法生成音乐的方式.Briot[8]更是直接对利用深度学习生成音乐的方法进行了回顾,总结了现有的典型的深度学习系统及其在音乐自动生成上的应用.针对自动作曲的综述不止有从算法上进行分类的,Herremans[9]在算法分类基础上更细化地从生成的音乐特征角度,将自动作曲分成了生成旋律、和声、节奏的系统;作者还从系统是否有与人的交互、是否表达了情感以及生成的乐曲是否可以用器乐演奏对自动作曲系统进行了分类.Liu等[10]的综述将作曲分成3个组成部分,分别是旋律、伴奏以及曲式,并且分别从这3个角度对计算机自动作曲进行了回顾.
通过对以上自动作曲文献综述的回顾,可以发现自动作曲伴随着各种算法的发展而发展,尤其是近年来深度学习算法的成功应用,利用深度学习生成音乐的结构也层出不穷,而以往的综述文章往往只针对系统来对计算机自动作曲进行回顾,并没有完全对计算机实现音乐生成的系统进行介绍,使得人们无法全面地理解计算机自动作曲系统的工作流程,因此本文在Kirke提出的“针对音乐表现力的计算机系统”模型基础上,总结得到了“计算机自动作曲系统”模型,利用该模型,人们可以了解到计算机如何实现自动作曲,以及实现自动作曲需要的技术.但本文并没有详细介绍每个系统的工作原理,这是本文的局限性.
1 “计算机自动作曲系统”模型
在对生成具有表现力的音乐的计算机系统进行回顾时,Kirke[11]提出了一个可以涵盖绝大多数系统的模型,该模型包含了“乐曲样本”、“乐理分析”、“音乐背景”、“模式识别”、“音乐理论”、“乐器模型”和“声音合成”7个部分,如图1(a)所示.在此模型的基础上,本文提出了“计算机自动作曲系统”模型,如图1(b)所示.“音乐样本”指的是现有的音乐数据,这些音乐可以是音频格式的或者是符号格式的.将音乐样本输入到“音乐分析”模块中,音乐分析有两个功能:首先是对音乐样本进行处理,给计算机提供可以进行分析的数据;其次,该模块还从乐理的层面对样本进行分析,分析音乐的结构,比如韵律的结构、旋律的结构与和声的结构.“音乐背景”模块在计算机自动作曲系统中指的是一首乐曲所包含的情绪或者是风格,情绪可以是欢快的,也可以是悲伤的;风格可以指某一特定风格的乐曲比如爵士乐、古典乐和摇滚乐,也可以是指中国音乐、西方音乐.“作曲系统”和“作曲理论”是密不可分的,可以进行学习的系统接受“音乐背景”、“作曲理论”的信息进行学习用来改进作曲理论,“作曲理论”是整个模型的核心,它包含了一系列的规则来控制乐曲的表现力,这些规则可以由“作曲系统”学习得到也可以直接由乐理知识得到,进而指导计算机生成音乐.“承载媒体”指的是计算机系统得到的音乐的承载格式,多数系统是生成符号形式的音乐,也有系统直接生成音频形式的音乐.然后“音乐评价”模块对生成的音乐进行评价并反馈给作曲系统,从而提升系统的性能.
2 音乐样本
无论是人类还是计算机都需要根据已有的音乐进行学习,进而创作音乐,这些被学习的音乐就叫做音乐样本.音乐的记载形式有很多种,从早期的乐谱到之后的模拟音频存储,如黑胶唱片、磁带,再到现代广为使用的数字音频文件如MP3、WAV格式的音乐,以及为了解决电声乐器之间通信而提出的乐曲数字接口(Musical Instrument Digital Interface,MIDI).针对计算机自动作曲,音乐大致可以分为两种格式:一种是音频波形格式;另一种是符号格式.
2.1 音频信号
音频信号是音乐最直接的表示方式,其可以是原始音频信号(波形),也可以是通过傅里叶变换处理的音频频谱.音频信号的生成一直是一个极具挑战的任务,原始音频信号的维数往往与有效语义级信号的维数相差很大.一般地,原始音频信号的高维性首先通过将其压缩成谱特征或手工设计的特征来处理,并在这些特征上定义生成模型.然而,当产生的信号最终被转成音频波形时,样本质量往往会下降,需要大量且专业的校正工作.目前利用音频波形信号作为样本输入生成音乐的研究有文献[12-16].Amiot等[17]利用了离散傅里叶变换在频谱上改变音乐的节奏.因为音乐需要更多考虑的是音乐要素之间的排列关系,而这些音乐要素可以用符号进行描述,并且人类也是基于符号化的音乐要素进行作曲的,所以目前自动作曲多是考虑符号化的音乐样本.
2.2 符号
目前大多数生成音乐的系统和实验都侧重于符号表示,音乐样本有很多符号化存储格式,每个系统使用的符号表示也不尽相同,下面我们总结最常见的几种符号表示形式.
2.2.1 MIDI
她仰头静静看着我,脸色苍白而憔悴,唇边仍渗出血迹,手帕触碰到嘴角,她身体发出轻微颤抖。她一定需要温热的液体安定悲伤的中枢神经,我起身走到桌边,在玻璃杯里放了两朵胎菊,以沸水冲之,边垫上茶托移到她面前边说:“小心烫。”
MIDI,即乐器数字接口,是20世纪80年代初为解决电子乐器之间的通信问题而提出的.MIDI是编曲界最广泛的音乐标准格式,可称为“计算机能理解的乐谱”.MIDI中存储的是控制音符参数的指令,比如控制音符起始、音高、音量大小等.这些指令以十六进制存储,图2展示了一个音符在MIDI中的形式.MIDI是符号化音乐样本中最流行的格式,存在着大量的资源,目前大多数自动作曲系统都使用MIDI音乐作为音乐样本[18-21].
2.2.2 文本
音乐可以用文本表示,并作为文本处理,如MusicXML和ABC记谱法.和MIDI不同,文本格式的音乐方便易读,并且可以很清楚地表明音乐的要素,如小节的表示.Sturm等[22]就在凯尔特人音乐生成系统中采用了ABC记谱法,并且对ABC记谱法做了一些改动,使之可以表达更为丰富的音乐信息.
2.2.3 功能谱(Lead sheet)
功能谱是流行音乐(爵士、流行等)一种重要的表示格式.一个功能谱的一页或几页就能表达出一段完整的音乐,并且可以表示指定相应和弦标签(和声)的注释,也可以添加歌词、作曲家名字、风格和节奏等信息.Eck等[23]的蓝调生成系统就利用了功能谱格式的音乐样本作为输入样本,Liu等[24]则直接生成了功能谱格式的音乐.
2.2.4 数据集
用于自动作曲研究的常用数据集见表1.
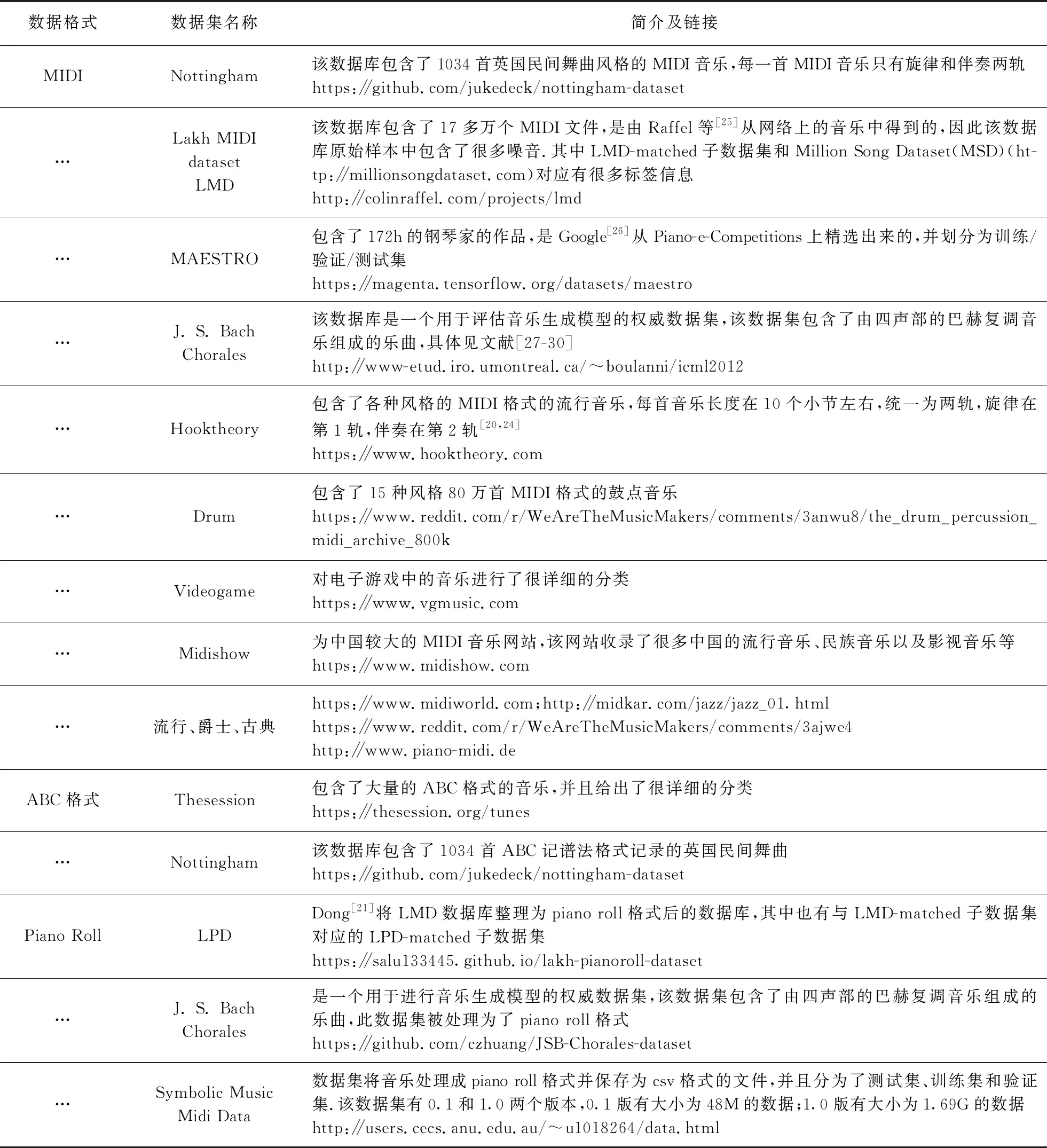
表1 自动作曲常用数据集Tab.1 Common datasets for automated composition
1) 独热编码(One-hot encoding):要将音乐信息交给计算机来处理,首先需要将音乐信息数字化.为了解决此问题,我们可以利用独热编码.独热编码的思想是定义一串二进制数,该二进制数长度等于待赋值对象的类别数,二进制数中只有一位是“1”,其余均是“0”.对于用“piano roll”表示的音乐,其本身自然以one-hot的方式展现;对于用“类MIDI形式”表示的音乐,可以对每一个音符事件进行one-hot编码.
处理MIDI格式的音乐需要一些特殊的工具来提高效率.下面介绍一些常用的处理MIDI格式音乐的第三方程序包(即在计算机程序语言如python中,利用该程序包可以很方便地处理MIDI格式的音乐):Mido是较为基础的处理包;pretty-midi是Raffel等[31]在mido基础上进一步简化了操作方式,按轨来处理信息,处理方式更加直观,目前谷歌Magenta项目就是基于pretty-midi处理MIDI信息的,python-midi对MIDI的操作很全面,但是操作方式不是很直观;music21是一个较为完善的处理包,不仅可以进行MIDI生成,也可以显示乐谱等.以上程序包都是基于python程序语言的,每种程序包各有优势,研究者可以选择合适的程序包使用.
3 音乐样本
音乐分析模块接受音乐样本,会对音乐样本进行预处理并分析其音乐结构.预处理将格式各异的音乐样本处理为计算机易处理的数据形式,分析音乐的结构信息如节拍、小节以及乐句,并将这些结构信息作用于作曲系统上,使生成的音乐具有更好的质量.
3.1 音乐表示
1) 钢琴卷帘窗(Piano roll):将音乐信息转换为piano roll是最常见的方式之一,钢琴卷帘窗如图3(a) 所示,横坐标代表音符持续时间,纵坐标代表音高值(音高值与钢琴键音高相对应),目前常见的做法是取十六分音符作为最小的时长单位,将音乐划分成piano roll,但这种方法无法区分同一音高下,该音符是一个长音符还是多个短音符相连.因此,还需添加一个维度的信息表示该音符是否与先前的音符相连.使用piano roll表示的优点在于:表示后的音乐既可以看成是由音符组成的1-D序列信息,也可以将一段音乐的piano roll看成一个整体,作为类似图像的2-D信息,这样就可以适应不同算法的输入要求.
2) 类MIDI形式的表示:该方法利用类似MIDI中音符事件“始”或“终”的形式,将音乐表示为一连串的音符事件信息,该形式没有piano roll直观,但是可以表示出更丰富的音乐信息,比如可以添加音乐力度和音符时移,进而添加音乐表现力信息.图3(b)所示为文献[32]中采用的类MIDI表示方法.
药敏结果采用WHONET5.6进行数据分析;采用SPSS19.0进行统计分析,计数资料采用例和构成比(%)描述,组间比较采用 χ2检验,P<0.05 为差异具有统计学意义。
3.2 算法输入
2.2.5 符号音乐处理工具
2) 词嵌入(Word embedding):使用one-hot编码得到的数据简单明了,但当数据类别分布不均匀时,会使得one-hot编码后的数据过于稀疏,并且当数据类别较多时,会使输入数据的维度过大,这两点都会对算法的性能造成影响;此外,one-hot编码不能很好地描述不同类别输入数据之间的关系.为了解决以上问题,人们引入了词嵌入技术.词嵌入技术将一个高维向量空间嵌入到一个维数低得多的连续向量空间,这样不仅会有效地解决输入数据维度的问题,还可以通过训练,使得相关的词语的词向量之间建立关联.
3.3 音乐结构
音乐分析的另一个作用是分析音乐数据中的音乐结构,将结构信息送入系统使得系统更好地生成音乐.人们根据乐理知识定义如小节或者乐句等结构,并选用特定的符号标注在音乐数据中.Makris等[33]提出的系统可用来生成节奏序列,并且在生成的过程中添加低音线和节拍作为条件信息来表示是否开始了新的小节,实验表明系统在添加了这种条件后提高了生成的音乐的质量.Lattner等[34]根据拍号来定义在重拍的时候需要有音符开始,如四四拍的音乐,在生成音乐时,就需要在第1拍和第3拍有新的音出现,该系统同样为音乐的整体结构提供了限制信息,比如AABA的结构.Deepbach系统[35]用到了延音记号,可以帮助生成更连续的乐句.
4 音乐背景
基于规则的自动作曲系统能让人们根据音乐理论知识定义一系列规则,并用此规则指导音乐要素的排列与组合,这些规则可以限定音高的范围,节奏的排列以及和弦的进行.Steedman[39]设计了一种生成爵士风格和弦序列的语法,利用该语法可以将最初的乐句重写成新的音乐乐句.邓阳等[85]将伊·斯波索宾的和声理论体系与动态规划相结合,基于和弦进行的逻辑优化目标函数,根据旋律生成和弦.Quick等[86]提出了针对和声与韵律结构的生成语法,该语法利用乐句的时间来参数化规则,利用共享节点的图结构生成重复的乐句.Herremans等[83]结合了巴洛克时期奥地利作曲家Johann Fux的理论来生成旋律,他们在目标函数中利用了这些规则,并且使用了变邻域搜索算法来加强规则之间的紧密性,随后Herremans等[87]又添加了新的规则并扩展了系统.
1) 由人将某一风格的固定规则、情绪涉及到的音乐心理学知识应用到作曲系统中.Zhu等[36]利用一种交互式的遗传算法来生成具有特定情绪的音乐,他们采用了演奏家演奏乐谱时的规则[37]系统作为评价规则,该系统模拟了音乐家使用的演奏原则.Onisaw等[38]使用了一种交互进化算法生成快乐或悲伤的旋律来反映用户的感受,他们得到的结论是欢快的旋律比悲伤的旋律更难评估,因为前者需要考虑更多的因素.同样可以根据某种音乐风格的特定性,定义相应的规则加入作曲系统中来生成具有某一特定风格的音乐.Steedman[39]设计了一种生成爵士风格和弦序列的语法,利用该语法可以将最初的乐句重写成新的乐句.Jaques等[40]在循环神经网络自动作曲系统后添加了强化学习部分,在强化学习中加入音乐理论来指导生成特定风格的音乐.
2) 要想利用规则指导系统,系统设计者需要对情绪与音乐的关系以及音乐风格特点有着很好的理解,需要专业的音乐理论基础,实现难度较大.另一种获得某种特定风格音乐的方式是直接从音乐样本中学习音乐的风格与情绪信息,让系统在某一特定风格的音乐数据中进行学习,进而生成对应风格的音乐.目前很多研究选用巴赫风格的钢琴曲作为音乐样本,Liang[30]的BachBot系统与Hadjeres等[35]的DeepBach系统都是直接用巴赫钢琴曲训练系统来生成巴赫风格的音乐.
第四,要注意鸡群非特异性的抗病力提高。在疾病发生的过程中,除了外界的环境和病原因素外,鸡群自身的抗病水平也是一个重要的因素。这就要求我们养殖场要加强鸡群的保健工作,保健的目的就是要通过使用适当的手段调节鸡群的免疫系统,增强免疫系统的机能,完善机体非特异性免疫屏障。当前行之有效的方案是使用促进免疫力,扶正驱邪的中药同时辅以生物制剂的使用,提高机体的免疫力和抗病力,以达到减少发病的目的。
该模块还为另一项音乐生成的任务提供了信息,即音乐风格转换.将已有的音乐转换为另一种风格并不直接生成音乐元素,而是通过改变原音乐中的音乐元素来改变风格.Dai等[41]对音乐风格转换进行了综述,给出了音乐风格转换的定义、重点问题和难点问题.Nakamura等[42]利用机器翻译的思想,在音乐语言模型基础上提出了风格统计公式来进行风格转换,并且修改模型来表示原有音乐与转移风格后音乐的相似性.
与其说这些公关危机是D&G所谓的因为不了解中国而产生的误会,不如说暴露了其深入其骨髓的以自我为中心和对中国的刻板成见。诚如网友所言,他们口口声声说“爱中国”,不过是爱中国的钱罢了。
5 作曲系统
5.1 混沌理论
从数学和物理学角度来看,难以预测的系统特定状态称为“混沌”.狭义的混沌理论也称为非线性动力学理论,建立混沌模型的数学系统可以是用非线性差分方程表示的迭代系统,也可以是连续流,用非线性微分方程表示,其中轨道是连续的、不间断的曲线.利用混沌系统来生成音乐的原理就是建立混沌理论与音乐之间的映射关系,这涉及到了数论、分形学、逻辑方程等一系列数学知识,近年来已经鲜有文章对此进行研究,已有利用混沌理论进行自动作曲的研究见文献[43-48].
5.2 细胞自动机
Von Neumann等[49]提出了细胞自动机的概念,该模型以生物的自我繁殖机制为基础.细胞自动机中一切都是离散的,也就是说系统中空间、时间和属性只能是有限状态的.细胞自动机有两个最基本的性质:
1) 一个规则的n维晶格,晶格中的每个细胞在给定的时间都有一个离散的状态;
2) 由一组规则控制的动态行为.这些规则根据相邻单元格的状态决定后续时间步骤的单元格状态.
图3为冷气循环流程。冷气循环流程是指当通过压缩机的操作点达到S2时,为防止压缩机操作点接近或达到S1,从压缩机出口冷却器或分离罐的下游将压缩机出口气体通过喘振控制调节阀循环到压缩机入口,增大压缩机流量以避免喘振工况的发生。相对于热气循环系统,冷气循环系统流程使压缩机出口管道系统有较大的容积,由于较大的管路系统体积,系统各参数的变化相对较慢(主要为压力、温度参数),喘振系统获得变化的工艺信号的时间相对较长,在一定程度上降低了压缩机喘振系统的反应速度,不利于在压缩机紧急停车时喘振的控制。但在压缩机启动过程中,在一定程度上延长了启动时的循环时间,降低了对压缩机启动时间的限制要求。
细胞自动机中的细胞就像存储设备,存储自动机的状态.最简单的情况是每个细胞只有两种可能的状态,通常是0(“死”)或1(“活”);在更复杂的细胞自动机中,细胞可以有更多的状态.控制细胞自动机动态行为的规则作用于晶格中的每个细胞,并考虑到每个细胞相邻细胞的状态.图4(a)解释了细胞自动机的工作原理,图中的最小方块结构代表一个细胞,其中:黑色方块代表“1”,白色方块代表“0”,最上面有8个大的矩形,每个矩形中有4个细胞,上面3个细胞代表当前时刻的细胞以及该细胞左右两边的细胞的状态,即是“黑色”还是“白色”的方块,下面的一个方块则是该细胞在此规则下下一个状态的输出,如第1个矩形代表着当前时刻细胞的状态为黑色,左边细胞的状态为黑色,右边细胞的状态为黑色,输出为黑色.我们称该图展示的细胞自动机的规则为150规则,因为下面一列输出的0与1组合对应的十进制数为150,图中呈三角形结构的则是在150规则下细胞自动机进化时的每一行的输出.
利用细胞自动机进行自动作曲可以将细胞与音高建立映射,进化的每一行表示一个节拍,这样细胞自动机每次输出的结果就代表着一个节拍的音高.Beyls[50]最先将细胞自动机应用在自动作曲,他为定义相邻的细胞建立了其他方法.此外,在计算下一个状态时,他考虑了单元格以前的更多状态,将人们选择的音高分配给细胞从而建立音高与细胞的映射关系.如果进化的下一步音高值不变则该进化的时间为该音符的时值.随后Beyls[51-52]引入了2维细胞自动机,能够实时更改不同的参数来生成音乐,并将细胞自动机与遗传算法结合起来.Millen[53-54]用1维到3维细胞自动机自动生成音乐,其中MIDI中音高值和持续时间值被映射到了细胞上.Orton等[55]在细胞自动机上用了交互式的方式生成音乐.利用细胞自动机自动作曲的弊端在于无法生成特定风格的音乐,因为很难利用细胞自动机去分析语料库中的信息.
5.3 马尔科夫模型
随机过程用来描述一系列依赖于时间随机事件的关系,这组事件称为“状态空间”,而这组参数称为“参数空间”.如果一个随机过程的状态是有限的,那么这个随机过程被称作随机链,在随机链中每个离散时间t都有一个随机变量x.马尔科夫链就是一种特殊的随机链,马尔科夫链中的下一个时刻状态Xt+1与且仅与当前状态Xt有关,从tm时刻的状态Xtm=i到tm+1时刻的状态Xtm+1=j的概率为
P(Xtm+1=j|Xtm=i)=pij(tm,tm+1).
(1)
马尔科夫链还可以用状态转移图(图4(b)),或者转移概率矩阵(图4(c))来表示.在自动作曲中,转移概率矩阵表示了音乐要素(如音长、音高)之间的关系,进而可以利用这种关系生成乐曲,使用的概率矩阵可以通过统计已有音乐数据库得到.Pinkerton等[56]最先使用马尔科夫模型进行音乐创作,他们根据39首简单的童谣的语料库建立了一个1阶马尔科夫模型“Banal Tune-Maker”,该模型可以生成类似于该童谣风格的音乐.近期Ackereman等[57]创造了ALYSIA系统来帮助人们生成旋律和歌词,ALYSIA系统使用随机森林的方式来训练马尔科夫模型.马尔科夫模型是自动作曲中很常用的方式,利用马尔科夫模型来生成旋律的研究可见文献[56,58-66],利用马尔科夫模型生成和声的研究可见文献[2,28,67-74],利用马尔科夫模型进行音乐节奏生成的研究可见文献[75-76].
但是马尔科夫模型也有一些缺点,如输出音乐的风格和质量在很大程度上取决于语料库的性质,在构建较长的序列上效果并不是很好,并且如果使用高阶马尔可夫模型,那么一个经常被忽视的缺陷是高阶马尔可夫模型不能准确地描述低阶模型中提供的信息,尽管如此,马尔可夫模型还是很适合某些音乐任务.
5.4 遗传算法
遗传算法作为一类特殊的进化算法,是一种基于自然界系统建模的随机搜索的策略.算法基本模型的灵感来自达尔文的进化论,解决问题的策略源于类似生物进化中的染色体交叉、变异等过程.遗传算法的术语包括“选择”、“突变”、“适者生存”等,这些术语体现了算法的原理以及它们与生物选择过程的密切关系.遗传算法在计算机中模拟进化过程,可以用来解决那些难以进行数学建模的任务或没有明确的优越规则系统的问题.下面先介绍一些遗传算法中的基本概念,通常把亟待解决的问题以数学方式建模为数学问题,那么这个问题的一个可行解被称为一条“染色体”;一个可行解中的元素或者变量被称为该染色体上的“基因”;用“适应度函数”来评价染色体的优劣;“交叉”是指两条染色体上的基因进行互换;“变异”是指随机修改染色体上的基因;“复制”是指将适应度最高的几条染色体直接原封不动地复制给下一代.整个遗传算法的实现过程如图5所示,算法的过程描述如下:
2018年年初,16岁华裔天才少女朱易夺得全美花滑锦标赛新人组女单冠军,超出第2名高达35分,成为令西方瞩目的新星。然而,她却毅然放弃在美国的发展机会,9月底加入中国国家队,成为偶像——“冰上蝴蝶”陈露的弟子,力争冲刺2022年北京冬奥会,为祖国夺金。而在这背后,是“科学大神”父亲的梦想,一直在激励着她!
1) 随机产生n条染色体的起始种群;
序列到序列模型(Sequence to Sequence,Seq2Seq)在机器翻译任务中被提出,解决了源语言语句与目标语言语句长度不同的问题[101].Seq2Seq包含了一个编码器(encoder)和一个解码器(decoder),编码器对源序列进行编码得到一个维度相对低一些的中间向量,解码器根据该中间向量得到对应的目标序列,这种翻译模型要求数据是成对的,并且成对的数据间需要存在联系,对于音乐来说,和弦进行与旋律、节奏型与音高线,或者复调音乐中的不同声部都是互相关联的序列信息,并且这些序列并不一定都是等长的,所以利用Seq2Seq可以有效地构建这种关系.微软[102]利用Seq2Seq生成流行音乐,根据流行音乐和弦进行影响旋律、节奏型影响旋律的特点提出了基于和弦的节奏和旋律交叉生成(Chordbased Rhythm and Melody Cross-Generation,CRMCG)模型,该模型包括音高编码器、节奏编码器、和弦编码器3个编码器,还包括音高解码器和节奏解码器2个解码器,生成节奏时将上一时刻的节奏与音高送到对应的编码器中进行编码,再将编码后的输出送入节奏解码器中得到当前时刻的节奏输出,生成音高时同理,区别在于生成音高时解码器会接受和弦编码器的信息.在这样生成旋律的基础上,文献[102]还提出了基于多任务学习的多乐器联合编曲(Multi-Instrument Co-Arrangement generation,MICA)模型,并且取得了很好的效果,生成的音乐通过了图灵测试.
3) 选择操作舍弃适应度低的染色体,保留适应度高的染色体,并决定哪些染色体进行“复制”操作,哪些进行“交叉”操作,哪些进行“变异”操作;
第二天,越秀在书桌上发现一大堆碎纸,这纸都是秀容月明用来练字的,跟往常不同,秀容月明都把纸撕了。越秀拼凑了几张,也没瞧出他写的是什么字。
4) 经过“复制”、“交叉”和“变异”操作后得到下一个种群;
5) 重新计算适应度,并进行迭代,直至得到输出结果.
利用神经网络自动作曲的原理是将数据输入给神经网络,定义神经网络输出与音乐要素的映射关系,定义预期输出结果,训练神经网络使得神经网络输出逐步接近预期值,训练完成后,将神经网络的输出映射为音乐要素,进而得到音乐.目前有很多研究利用了不同结构的神经网络进行自动作曲,这些结构又大致可以分为两种:一种是选取不同类型的神经网络,针对不同类型神经网络的特点对音乐数据进行分析建模,如使用循环神经网络(Recurrent Neural Network,RNN)、卷积神经网络(Convolutional Neural Network,CNN)以及使用了Self-Attention机制的神经网络,这里不同类型的神经网络是作为一种特征提取器,目的是从大量的音乐信息中提取到重要的信息;另一种是选取不同的深度学习模型来对音乐建模,如采用机器翻译模型中的“序列到序列(Seq2Seq)模型”,或者是深度生成模型,如限制性玻尔兹曼机(Restricted Boltzmann Machine,RBM)、变分自编码器(Variational Autoencoder,VAE)以及生成对抗网络(Generative Adversarial Networks,GAN).这些深度学习模型中的神经网络层又可以选取RNN或CNN等不同类型的神经网络,所以神经网络类型的选择与深度学习模型的选择对自动作曲算法都至关重要.
5.6.5 RBM
2) 随机交换元素的顺序得到Bb,F,Ab,Gb;
面对长形式图书阅读过程中的问题,图书出版业结合互联网时代阅读的大环境,开始从供给侧的角度做相应的对接。
学生乙:沿高把三角形剪成两个小等腰三角形,拼成一个边长为8÷2=4的正方形,如图3,原三角形面积等于正方形面积,列式为(8÷2)×(8÷2)=16(平方厘米)。
3) 根据参考模式删除了Gb,得到Bb,F,Ab;
4) 随机修改首个元素得到Eb,F,Ab;
5) 将每一轮得到的结果拼接输出可得到(Gb,Bb,F,Ab)i=1(Bb,F,Ab,Gb)i=2(Bb,F,Ab)i=3(Eb,F,Ab)i=4.
Horner等的系统虽然很简单,但是得到的音乐结果很好地证明了利用遗传算法进行自动作曲的可行性,到目前为止已经有了大量的研究利用遗传算法进行自动作曲.Eigenfeldt[78]提出了一种基于遗传算法的重组组合体,利用混合方法解决适应度的问题,他提出使用神经网络分类器或者从被分析的语料库中提取规则,从而从语料库本身派生出适应度规则.有些系统的方法是建立在某一特定领域或子领域已建立的规则的基础上的.Kunimatsu等[79]提出了一种基于遗传规划的音乐作曲模型.在这项研究中,他们考虑了和弦发展中布鲁斯风格的抑扬顿挫的特点.他们的系统将遗传算法中的树结构中的节点用音符表示,阶度用时长表示.适应度函数主要考虑两种比较:一种是和弦和旋律中的高音的比较;另一种是寻找部分和弦级数的熵函数的相似性.文献[80-81]利用人对生成音乐的评价作为适应度函数,而文献[82-84]则利用遗传算法进行自动作曲.
遗传算法最大的问题在于适应度函数的选取,适应度评价直接影响到生成音乐的质量,所以如何选取适应度函数,以及适应度函数选取是否合理是影响遗传算法在自动作曲领域能否有好的发展的重要因素.
5.5 基于规则的自动作曲系统
在计算机自动作曲系统中,音乐背景指的是一首乐曲所包含的情绪或者是风格.该“音乐背景”模块可以由两种方式生成音乐的背景信息.
如果利用既定的规则,那么生成的音乐始终会在一个范围内,生成的音乐会略显单调,并且多个规则之间很有可能会相互冲突,导致算法无法进行下去.所以基于规则的系统往往与其他作曲算法相结合,可以利用乐理规则作为遗传算法的适应度函数,根据乐理规则指导人工神经网络系统进行学习.这样在尽量符合乐理规则的情况下,通过其他算法引入随机性,会大大提高生成音乐的多样性.
5.6 神经网络
当下人工神经网络中的深度学习技术在图像识别、语音理解、机器翻译、文本生成等诸多领域取得了令人瞩目的成就,深度学习已经成了人工智能领域中炙手可热的技术.伴随着深度学习技术的迅速发展,利用深度学习技术来自动生成音乐也是当下最热门的研究方向之一.神经网络属于机器学习的一种,其是由神经元组成的广泛并且互连的网络[88].神经元采用的是McCulloch提出的“M-P神经元模型”[89],在该模型中,输入通过带有权重的连接传递给神经元,神经元将输入与自身的“阈值”比较,再通过“激活函数”得到输出,将这些神经元按一定的层次结构相连便构成了神经网络.图6(a)~(c)依次展示了神经元、激活函数和神经网络.将神经网络输出和预期输出的比较结果反馈给神经网络,神经网络改变连接权重使得输出不断接近预期输出,这种方式称为神经网络的学习过程,连接权重的参数存储着学到的知识.深度学习增加了神经网络隐藏层的数量,阈值与连接权重等参数也随之增加,增强了神经网络的学习能力.
在自动作曲中利用遗传算法则需要考虑遗传算法过程中每个步骤对应的音乐意义,Horner等[77]首次利用遗传算法进行自动作曲,其系统选择了6种参考模式并使用“输出的音高与参考模式音高的一致性”以及“输出长度与预期长度的关系”作为适应度函数,如开始输入的音高序列为Gb,Bb,F,Ab,Db,参考模式为F,Ab,Eb,则:
5.6.1 RNN
RNN是用来处理序列数据的神经网络[90],神经网络的隐藏层会受之前时刻隐藏层状态的影响.音乐信息正是随时间进行的序列数据,因此RNN很适合用来处理音乐信息.1994年,Mozer[91]的CONCERT系统是第一个利用RNN进行作曲的系统,但RNN只能记忆短时间的信息,因此生成的音乐质量一般.之后Hochereiter等于2002年在RNN结构中加入了“长短时记忆单元(Long Short-Term Memory,LSTM)[92]”(LSTM在神经元中加入了“门”来控制“记忆”和“遗忘”信息,因此可以记忆更长时间的信息)来生成蓝调音乐的旋律与伴奏,在生成旋律与伴奏时,先随机选择一个和弦作为输入,由系统生成下一个和弦,再将生成的和弦作为输入继续送到网络中,如此依次生成和弦序列.LSTM已经成为应用RNN进行作曲的系统中最常用的方法.Makris等[33]将LSTM与普通的神经网络结合生成节奏,RNN负责学习鼓的部分,普通神经网络负责学习低音线以及节拍的结构.Sun等[93]为神经网络添加了乐理限制使得生成的音乐更加合理.近年来利用RNN生成音乐依然是热门的研究方向,相关研究见文献[35,94,96-97].
5.6.2 CNN
CNN是用来处理类似“网格结构”的数据的神经网络[90],该网络至少需要在网络结构中的一层使用卷积运算.CNN首先在计算机视觉领域取得了极大的成功,在计算机视觉领域图像被看作2维的像素网格,随后CNN也被用在对序列数据进行建模,这时序列信息被看作在时间维度上的1维网格.Lecun在论文中首先使用了“卷积”一词来描述其网络结构.利用CNN进行自动作曲大多是将多声部的乐谱转换为钢琴卷帘窗的表示,再将一个小节或多个小节的钢琴卷帘窗看作一个2维的图像,进而利用CNN在该表示下对音乐信息进行处理.Yang等[20]与Dong等[21]利用生成对抗的思想进行自动作曲,其生成器和判别器均使用了CNN.Huang等[98]发现人类在创作音乐的时候往往会把动机随意地写在各处作为草稿,而且有时会重新回到草稿上,对动机进行修改并且对动机之间进行连接.为了模仿人类作曲家作曲的特点,本文使用了卷积神经网络来实现音乐的填补工作,用吉布斯采样的方法来重写乐谱.CNN因为不需要满足RNN在时间上的串行运算关系(即上一时刻的状态会参与到当前时刻的运算),所以CNN可以并行计算,其运算速率比RNN的较快.
5.6.3 Self-Attention
在场地方面,社工组织开展服务需要一定的场地支持。在广州市政府颁布的《实施办法》也明确提出“在场地设备保障方面,各街道要整合现有的街镇文化站、工疗站、党员活动中心、社区星光老年之家等社区服务场地资源。通过整合、新建、置换、租赁等方式,根据实际需要,多渠道解决服务中心场地,盘活国有产权闲置场地,通过‘租金’或象征性租金的方式用于街道家庭综合服务中心建设⑤。”这一政策文件在一定程度上解决了社工组织开展服务所需的场地支持。
自注意力(Self-Attention)机制是从机器翻译中Attention机制演化而来的,Attention机制通过加权求和的方式解决了翻译问题中源语言语句与目标语言语句中单词对齐的问题[99],Self-Attention通过加权求和的思想计算一句话中每个单词与其他单词之间的联系,以此来替代RNN抽取序列信息的特征.Google[100]提出了Transformer结构,该结构完全摒弃了RNN结构,只使用了Self-Attention机制,该网络结构可以更容易学习到每个句子中单词的长距离依赖关系,在机器翻译任务的表现超过了以往各种形式的RNN与CNN,并且与RNN相比,Transformer结构可以高效地并行计算.Transformer结构在自然语言处理问题上的优异表现使得研究者自然而然地将其用在自动作曲上,其中Huang等[32]提出的算法可以减少对计算机内存的使用,使Transformer可以生成距离更长的序列.本文用改进后的Transformer来生成复调音乐,取得了很好的效果,可以从生成的音乐中明显发现音乐结构的相似性,说明网络学到了音乐中更长距离的依赖关系.
5.6.4 Seq2Seq
2) 计算每条染色体的适应度,决定是否结束算法;
1) 根据参考模式删除了Db,得到Gb,Bb,F,Ab;
RBM是一种随机人工神经网络,由可见层和多个隐藏层组成,它可以学习输入集上的概率分布从而实现生成功能.限制性是相对原有的玻尔兹曼机来说的,限制性体现在模型必须为二分图,即可见层之间没有连接,隐藏层之间没有连接,连接只存在于可见层与隐藏层之间.RBM与自编码器结构的区别在于:1) RBM没有输出层,输入层即为输出层;2) RBM是随机的;3)RBM中的数值计算是布尔型的(即非0即1的操作).Boulanger-Lewandowski等[29]利用了RBM生成复调音乐,并利用数据对RBM进行训练,训练完成后可以通过块吉布斯采样对RBM进行采样进而得到音乐.Lattner等[34]提出的系统使用RBM来学习乐曲语料库的局部音乐结构,比如织体这种特性,再通过约束条件学习一些更全局的结构,例如AABA乐曲结构.
5.6.6 VAE
自编码器(Autoencoder)是一种要求输出层和输入层神经元数量相等的网络结构.自编码器由编码器和解码器组成,编码器将输入压缩为低维的隐藏向量,解码器将该低维度的向量解码为与原输入同维度的输出,利用这种编解码关系,解码器可以实现生成的功能.Bretan等[103]利用有多个隐藏层的“堆叠自编码”自动生成旋律.VAE在自编码器的基础上增加了限制条件,使得隐藏层输出的隐藏向量强制服从高斯分布,之后解码器学习隐藏向量中高斯分布与真实样本之间的关系.于是,在生成音乐的过程中,我们只需要给解码器输入一个服从高斯分布的向量,解码器就可以生成我们需要的样本.利用VAE的结构,我们很容易进行一些生成工作,目前也有很多研究利用VAE进行音乐的生成.现有的VAE模型很难对序列的长距离依赖关系进行建模.为了解决这个问题,Roberts等[27]提出使用分层解码器,首先将输入转换为子序列的向量,然后利用这些向量独立地生成每一个子序列.Brunner等[104]提出了基于VAE的自动作曲模型MIDI-VAE,该模型能够处理具有多个乐器音轨的复调音乐,并结合音符的持续时间和速度对音乐进行建模.MIDI-VAE可以自动地将一首乐曲的音高、力度和乐器由古典风格转变为爵士风格,从而实现对音乐风格的转换.Wang等[105]提出了VAE的一种新变体,即用模块化的方式设计模型结构来生成音乐.
坚持党的领导,是国有企业的独特优势,是国有企业必须坚持的一项重大政治原则。党的重心在基层,活力在基层。面对新时期党组织的重大任务与责任,以抓重点、多举措、重实效的工作思路,探索将“活力党建”落细于企业管理,传递活力、动力、能力,逐步形成体系、形成文化,让党建成为生产经营的源泉和永动机,从而实现以党建活力提升率先发展活力,凝聚科学发展合力,激发创新发展动力[1]。
区块链或许有可能颠覆现有平台,具有成为运行新模式基础的可能性。通过从现有流程中减少中间环节,减轻保存纪录和管理交易对账等的行政工作,就能有效降低成本。这样,企业从降低成本中获利,又为提供区块链服务的参与者创造了新的收入,这个模式就可以运行起来了。
5.6.7 GAN
GAN[106]是近来深度学习技术中最热门的研究方向之一,GAN最初用在图像生成上,网络由“生成器”和“判别器”两个神经网络组成,生成器输入随机噪声得到输出,再将“生成器的输出”与“现实中的真实图像”送入判别器中进行真假判断,判断的结果反馈给生成器和判别器,进而生成器会学习到如何生成更加真实的图像,判别器也被逐渐训练,可以更好地分辨图像来自生成器还是来自真实的图片库中.生成器和判别器在这种对抗的训练中达到平衡,即判别器无法判断出图像的来源,此时生成器可以输出相当真实的图像.为了解决GAN为生成序列数据时梯度无法从判别器传递到生成器的问题,研究者提出了很多方案,如SeqGAN[107]、ReGAN[108]、MailGAN[109]等.也有很多利用GAN的思想生成音乐的工作,如Olof Mogren[19]利用生成对抗的思想,结合RNN对时序信息处理的特性,提出了连续循环生成对抗网络(Continuous-RNN-GAN)来生成古典复调音乐.Brunner等[110]利用GAN实现了音乐风格的转换.CNN利用卷积的操作多用在图像领域,但是仍然有很多研究结合CNN与GAN来生成音乐,如Liu等[24]利用循环卷积的GAN学习从功能谱和MIDI中提出的3个音乐特征,该模型可以生成8小节长的功能谱.Dong等[21]的MuseGAN使用了CNN和GAN的结构来生成音乐.为了对音乐由低纬度到高纬度的不同特征进行建模,MuseGAN把音乐分为乐段、乐句、小节、节拍和像素这5个由高至低的层级,在生成的时候逐层进行生成,每条音轨之间相对独立的同时又需要相互配合,这样MuseGAN的输入为两个噪声向量:一个输入给所有音轨;一个输入给单独的音轨.在小节的处理上采用同样的方法,最后将所有音轨的输出合并在一起送到判别器中训练.同样使用了CNN与GAN的结构还有MidiNet[20],其使用了两种方法来保证生成音乐具有创造性:1) 生成器中控制因素——和声只加在生成器中间一层卷积层中,从而降低和声走向对旋律的控制;2) 降低特征匹配正则化中的两种控制参数,使得生成的旋律与数据库中原有的旋律保持不同.
通过以上对神经网络自动作曲系统的回顾,可以发现目前利用神经网络进行自动作曲的系统往往融合了很多种结构的神经网络,利用不同结构的特性来提高生成音乐的质量,这也是自动作曲技术未来发展的趋势所在.
6 作曲理论
自动作曲中的“作曲理论”是与人类“作曲理论”相对应的概念,但二者并不是同一概念.作曲系统是根据人们对音乐的理解定义的算法,这些算法的输出具有音乐美感,是一种“自上而下”的方法,“基于规则的自动作曲系统”可以认为是这种方法.而“作曲理论”是从作曲系统中学习得到的,可以是基于马尔科夫模型中的概率转移矩阵或者是遗传算法中经过一轮轮迭代后的染色体,也可以是人工神经网络中的所有参数,是“自下而上”的方法.在这些算法中,作曲理论更像是一个“黑盒模型”,即人们并不能理解作曲系统中参数的音乐意义,但这些参数确实存储着生成音乐的信息.这种“黑盒模型”的优势是不需要掌握过多专业的乐理知识,门槛较低,而且可以利用模型从数据中学到作曲理论,在当下互联网大数据时代凸显了其优势.但是正是因为“黑盒”问题,人们无法建立模型参数与音乐要素之间的联系,导致生成音乐的可控性降低,因此,此类“黑盒模型”作曲系统与作曲理论之间的关系亦是自动作曲技术未来研究的方向之一.
7 承载媒体
生成音乐的承载媒体有两种格式,分别是符号与原始音频波形.一般来说,输出音乐的格式与输入音乐的格式相对应.符号格式的音乐在生成后,需要利用特定的合成或者播放软件来转换为人耳可听见的音乐并播放,然后人们对生成音乐进行评价,若直接生成音频格式的音乐则不需要转换.但是若要利用计算机对生成的音乐进行客观地统计,那么音频格式的音乐只能采用音乐信息检索技术(Music Information Retrieval,MIR)再对音频进行分析,而符号格式的音乐则可以很容易地被转换为计算机可以处理的数据.
由于音乐具有高度结构化、复杂且连续的特点,到目前为止,计算机生成音乐的研究主要集中在生成符号化音乐上.但只生成符号化的音乐,如果从演奏音乐的角度来看便显得不够丰富,因为每个音符的力度、时长在由不同的演奏家演奏音乐时都会有不同,这些细微的差别正是音频文件的音乐和乐谱等符号化音乐的区别.Kalchbrenner等[12]使用单层的循环神经网络依次预测波形的下一个样本点来生成音频,Chung等[13]将潜在随机变量加入一个循环神经网络的隐藏层,提升了网络对结构化序列信息建模的能力.Van Den Oord等[14]提出了一种根据之前所有的音频样本来预测当前的音频样本,直接生成原始音频波形的深度卷积神经网络WaveNet.WaveNet的核心部分是因果卷积,因为因果性,网络可以保证生成的每一个音频样本都只取决于之前的样本.WaveNet可以用在文本转语音(Text to Speech,TTS)系统,也可用于直接生成音乐.在生成语音信号上,WaveNet取得了很好的效果,但是在生成音乐上,由于WaveNet直接生成的是波形,所以生成的声音有很多非乐音,并且在音符之间的衔接上仍十分不自然.与WaveNet没有考虑音乐构成的元素不同,Mehri等[15]提出了一个端到端的生成音频波形的模型SampleRNN.原始音频信号的建模极具挑战性,因为音频波形信号包含了很多不同尺度的结构,相邻样本之间以及相隔数千个样本之间存在相关性,为了解决这个问题,SampleRNN模型提出了多层模型,每一层处理一个时间维度上的数据,最底层处理音频样本级别的信息,每高一层要处理的信息在时间范围上越来越长,在时间分辨率上越来越低.由WaveNet和SampleRNN生成的音乐并没有在以秒为单位的数量级上展现出音乐结构,而这些时间尺度上的结构正是音乐的本质之一.目前基于自回归方法生成音频文件的音乐性最强的系统是Dieleman等[16]提出的自回归离散自编码器(Autoregressive Discrete Autoencoders,ADAs).在典型的确定性自编码器中,学习到的表示信息内容仅受编码器和解码器容量的限制,因为该表示是实值的(如果是非线性的,甚至可以将大量信息压缩成单个标量值).当音乐以音频信号的形式呈现时,这种结构在不同的时间尺度上表现出来,从毫秒级波形的周期性到一段跨度为几分钟的音乐的形式.为这个结构化序列中的所有时间相关性建模是极具挑战的任务.
8 音乐评价
音乐评价对于自动作曲非常重要,验证生成的音乐有更高的质量是对系统性能更出色的证明.但是音乐评价却是自动作曲中最困难的部分,因为音乐本身就很难评价,音乐评价可以分为“客观评价”和“主观评价”,目前来说并没有公认的客观评价体系,而人主观的听力测试也与被试者的年龄、性别、性格以及受音乐教育程度等诸多因素有很大的关系,所以如何评价作曲系统创作的音乐也一直是研究者想要解决的问题.下面通过对文献的回顾,总结目前较为常用的评价方式.合理的客观评价方式也是未来自动作曲研究的一个重要方向.
8.1 客观评价
Sun等[93]提出了3个客观评价指标来衡量生成的音乐质量,这3个指标分别是:1) 全音阶的音符占总音符的比率;2) 一个八度间的音程百分比;3) 一个八度间的三和弦百分比.
Jaques[111]根据Gauldin[112]提出的作曲理论规则制定了几个客观评价指标:如分数越接近于0越好的指标——重复的音符占比与不在调性内的音符占比;分数越接近于100越好的指标——从根音开始的音符占比、不和谐跳音的解决程度、动机内的音符占比以及重复动机内的音符占比.
大数据处理已被广泛应用于各个领域,人们已为此开发多个框架来加速不同类型的数据处理应用。由于一个大数据处理集群往往运行多个不同类型数据处理任务,公平资源共享是大部分平台所采用的资源配置策略[1]。然而,不同类型任务对服务质量的需求是不同的,绝对公平并不总是终端用户和服务提供商的最佳选择。例如,实时数据流分析,需要快速完成任务;而综合决策系统,则主要关注系统吞吐量。
Dong等[21]在MuseGAN系统中提出了5点客观指标,并且被很多文献[24,113]使用,这5点指标为:1) Empty Bars(EB),即空的小节数;2) Used Pitch Classes(UPC),即每个小节的音高种类、数量;3) Qualified Note(QN),代表着高质量音符与总体音符数的比率(音符时长要长于等于十六分音符,音符时值过短表示音乐过于碎片化);4) Tonal Distance(TD),表示两个音轨之间的和谐程度,和谐程度用Harte等[114]提出的比较两个音轨的色度特征之间的距离来表示;5) Drum Pattern(DP),即八分音符和十六分音符的占比,因为这两种音符时值是摇滚乐中常用的鼓的音符时长.
微软小冰团队[102]也提出了几点客观指标:1) 音符准确率,即在同一时刻,生成音符和数据库中音符相同的数量与总音符数量的比值;2) Levenshtein相似度,即Levenshtein距离[115],是通过计算将一个序列更改为另一个序列所需的单字符编辑(插入、删除或替换)的最小数量来度量的,它通常用来测量两个序列之间的差别;3) 音符的均方误差分布,用来衡量音乐中的音符分布情况.
8.2 主观评价
主观评价是指选择人类听众对生成的音乐进行听力测试,并用李克特量表[21,26-27]对音乐进行打分,然后对得到的分数进行检验,然后进一步地分析分数与音乐质量之间的联系.如可以利用克鲁斯卡尔-沃利斯检验(Kruskal-Wallis Test,亦称“K-W检验”、“H检验”等),该检验可以判断两个以上的样本是否来自同一个概率分布,还可以利用威尔科克森符号秩检验来检测成对数据是否有显著差异.目前有一些平台可以对计算机生成的音乐进行主观评价,如CrowAI平台(https:∥www.crowdai.org),该平台是生成音乐挑战的一部分.该挑战旨在对不同算法生成的MIDI文件进行评级,该平台让评估者给2个30s的音乐片段打分,而该30s的片段可能是从自动作曲系统生成的1h音乐中随机选择出来的,也可能是从John Sankey,Chorales和Nottingham等数据库中挑选的.
9 结 语
本文根据“针对音乐表现力的计算机系统”模型提出了“计算机自动作曲系统”模型,该模型包括了“音乐样本”、“音乐分析”、“音乐背景”、“作曲系统”、“作曲理论”、“承载媒体”和“音乐评价”7个部分.本文利用此模型的层次对计算机自动作曲的文献进行了回顾,可以发现该模型很好地描述了计算机自动作曲系统的架构.与此同时,本文给出了模型中的每个模块的简略介绍、所使用的重点技术、面临的难点问题以及未来发展的研究热点.对“音乐样本”模块,本文总结了符号格式音乐的常用数据库;对“音乐分析”模块,本文给出了几种常用的MIDI处理程序扩展包;对“评价方式”模块,本文总结了常用的客观及主观评价方法.本文并没有给出系统用到的每一种音乐表示方式以及系统的详细说明,但研究者依然可以根据本文的模型迅速地理清自动作曲中涉及到的问题、技术以及发展方向,这对初探自动作曲领域的研究者有着很好的帮助.
致谢:本文是2019年度上海市音乐声学艺术重点实验室委托科研项目(SKLMA-2019-02)研究成果,同时也是北京市中闻律师事务所周唯团队与北京邮电大学嵌入式人工智能实验室关于“计算机辅助作曲技术应用及其法律风险”研究项目的成果.感谢以上单位对本文的支持!
猜你喜欢
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
音乐天地(音乐创作版)(2021年9期)2021-12-01
北京航空航天大学学报(2021年4期)2021-11-24
大众文艺(2020年10期)2020-06-05
阅读(低年级)(2020年10期)2020-01-07
作文大王·低年级(2019年5期)2019-06-13
电子制作(2019年24期)2019-02-23
海峡姐妹(2018年9期)2018-10-17
疯狂英语·新读写(2018年2期)2018-09-07
