
能源互联环境下考虑需求响应的区域电网短期负荷预测
2021-01-09 05:38孔祥玉朱石剑田世明鄂志军
电力系统自动化 2021年1期
李 闯,孔祥玉,朱石剑,田世明,鄂志军
(1. 智能电网教育部重点实验室(天津大学),天津市300072;2. 贵州电网有限责任公司电力科学研究院,贵州省贵阳市550007;3. 中国电力科学研究院有限公司,北京市100192;4. 国网天津市电力公司,天津市300010)
0 引言
精确的电力负荷预测对保障电力系统经济、安全运行和电力服务部门的精细化运营具有重要实用价值和意义[1]。在能源互联系统中,随着通信技术的发展和量测设备的安装应用,相关部门获得了海量的信息数据,为训练、提升负荷预测模型的性能提供了大数据支撑。
近年来,短期负荷预测(short-term load forecasting,STLF)技术的创新及应用不断涌现,依据其技术特点大致可分为统计学模型、神经网络模型以及组合预测模型,应用时需根据具体的预测环境并结合输入数据的特征来合理选择预测模型[2-3]。常见的统计学模型包括自回归综合移动平均(autoregressive integrated moving average,ARIMA)模型、支持向量回归(support vector regression,SVR)等,因其数学原理与统计学关联,本文将其归类为统计学模型[4-5]。目前,深度神经网络模型备受关注,但随着网络规模的扩大,其训练效率明显降低,并且易出现过拟合现象[6]。而长短期记忆(long shortterm memory,LSTM)网络因其特殊的门结构既可以利用当前时刻的数据特征,也可以利用门结构来遗忘或记忆前一时刻的数据特征,这使得并非所有的输入数据都对网络参数的更新产生影响,可在一定程度上改善过拟合问题[7]。此外,结合模态分解技术(小波变换、经验模态分解[8]等)、特征选择技术(互信息[9]、最小冗余度最大相关性准则[10]等)、误差修正技术[11]等各类技术的组合预测模型成为研究热点。文献[12-13]分别构建了基于LSTM 网络的组合预测模型,以及双向LSTM 网络来处理选择后的数据,并通过LSTM 网络实现预测精度的提升。
随着市场化的发展,电网采用电价或激励手段来引导用户参与需求响应(demand response,DR)以实现削峰填谷,但用户的不确定性将影响区域负荷预测的精度[14]。文献[15]基于消费者心理学原理建立了DR 机理模型来获取用户对分时电价的响应参数并将其量化,结合电价、温度等影响因素采用径向基函数神经网络模型提高了预测精度。文献[16]提出一种逆优化方法来预测因电价响应的负荷时间序列。上述研究为处理DR 因素提出了主流解决方案,但是由于用户侧DR 具有较强的差异性,特别是在区域能源互联系统中,多种能源类型相互耦合必然会增加对DR 负荷直接预测或分解的难度。因此本文尝试将引发用户参与DR 的DR 电价分离出来以间接考虑DR 负荷。
针对具体化DR 环境,本文构建基于误差修正技术和LSTM 网络的组合模型,通过动态模式分解(dynamic modal decomposition,DMD)技术来预测误差序列,通过误差修正来实现更精确的负荷预测。事实上,基于误差修正技术的组合模型已有应用,且其有效性已被证明[17-19]。此外,文献[20-21]验证了DMD 在预测单变量时间序列方面的独特优势,而本文将其应用于预测误差时间序列。
与传统方法相比,本文方法采用灰色关联分析(gray relation analysis,GRA)法以气象特征作为参考序列来选取强相关的相似日特征变量以减少模型的数据输入量和提高输入的数据质量。提取了DR电价作为需求特征变量,建立基于LSTM 网络和DMD 的组合预测模型来分别预测负荷和误差时间序列,并将其线性叠加获得误差修正后的电力负荷预测值,最终实现了预测精度的提升。
1 能源互联系统中的电力负荷特征
1.1 DR 环境中的区域负荷分类
在能源互联系统中,电能已逐渐成为主导能源,随着源端光伏、风力等可再生电源以及微燃气轮机等热电联供设备的不断接入,同时荷端除了传统的各类电负荷,柔性电热设备、电动汽车设备也在逐渐增加,此外部分用户还具备蓄电、蓄热设备。源荷端发生的变化将直接或间接地影响电力用户从大电网中获取电能的需求,简化的区域能源互联系统如图1 所示。

图1 简化的区域能源互联系统Fig.1 Simplified regional energy interconnection system
图1 的区域能源互联系统通过灵活的能源转换和各层次的能量管理系统实现了集中式与分布式相结合的能源管理模式,构建用户与电网之间的供需互动[22],同时用户侧综合能源系统增加了用户电力需求的随机性,使得电网公司难以通过分析用户的用电习惯来获取其用电行为特征,进而影响区域能源调度侧的负荷预测。在区域能源互联系统中考虑DR 的负荷分类及特征如附录A 表A1 所示。
1.2 DR 对负荷时间序列的影响
需求侧管理通过控制价格信号和制定激励措施来吸引越来越多的电力用户参与DR,随着量变的累积,规模效应逐渐显现,最终实现对电力负荷时间序列波动特征的控制[15]。在电力负荷时间序列曲线中,这种控制主要表现为削峰、填谷和改变爬坡率,如附录B 图B1 所示。
为了实现电力系统的经济化运行,电网公司可采用一些有效手段或策略,通过结合电力系统的承受能力实现电量在一定范围内的供需平衡。一般来说,在供不应需时电力系统的运行压力较大,电网公司可通过提高该时段电价来降低峰值负荷以达到削峰的目的并缓解发、输电的压力,降低对峰值发电设备的投资需求[16]。在需不应供时,降低电价和实行激励策略可增加该时段的用电量以达到填谷的目的。如果需要调整爬坡率,可通过制定合理的电价或激励政策来改变峰、谷值时段的爬坡率,从而直接改变电力负荷时间曲线的特征。
2 考虑DR 的短期电力负荷预测方法
本文所研究的考虑DR 的短期负荷预测思路主要包括以下4 个阶段。
1)数据处理阶段:基于历史数据样本集,采用GRA 法处理气象数据来获取相似日特征变量,并提取DR 电价以获得DR 特征变量。
2)负荷预测阶段:基于相似日特征变量,采用LSTM 网络获取测试集电力负荷的预测值。
3)误差预测阶段:基于误差数据样本集,采用DMD 来获取测试集误差序列的预测值。
4)误差修正阶段:基于阶段2 和3 的预测值,用误差的预测值修正负荷的预测值来获取最终预测结果。
2.1 数据集的获取与处理
2.1.1 相似日特征变量的选取
在能源互联和DR 的背景下,影响电力负荷的因素变量变得更加多元化,并且相关的因素数据也更易获得。但是对于预测模型而言,输入变量的多少与预测模型的精度没有必然联系,其中弱相关变量的输入对模型的训练并没有积极意义[23]。因此,本文采用GRA 法[24]从历史样本数据集中选择与待预测日气象特征相似的相似日变量作为输入模型的强相关变量。GRA 法的基本思想是通过计算2 个时间序列变量之间的关联度值来判断两者的相似度,具体的计算步骤如附录C 所示。
2.1.2 数据样本集的划分
本文采用GRA 法从历史数据样本中获取相似日特征变量作为预测模型的数据样本集,若以第i 天相似日为例,则模型的输入特征变量如表1 所示。表中,xit为负荷变量,xit,1为温度变量,xit,2为湿度变量,xit,3为光照强度变量,xit,4为风速变量,xit,5为PM2.5 浓度变量,xit,6为降雨量变量,pt为电价变量。
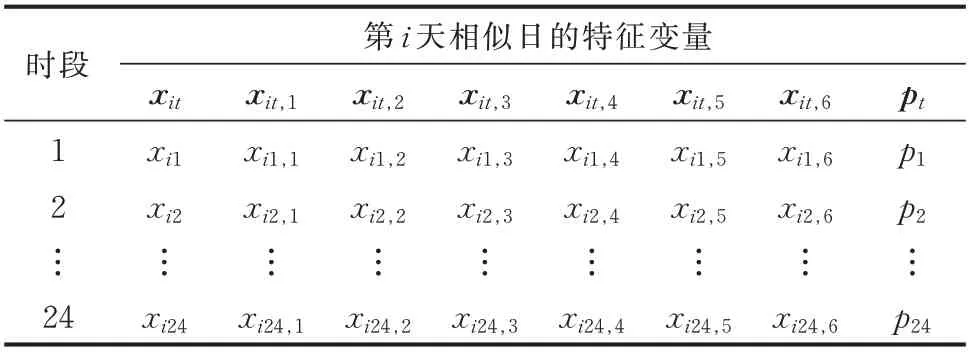
表1 模型的输入特征变量Table 1 Input characteristic variables of model
在所研究的区域中,随着DR 愈发频繁,电价成为影响电力用户参与DR 的主要因素,分时电价是电力用户承担的基础电价,当电网公司需要进行削峰填谷时会调整电价策略,在基础电价(基价)上叠加DR 电价(因价)以吸引更多的电力用户参与DR。为了获取DR 电价特征变量,本文将DR 电价从电价数据中分离出来。

如果经过GRA 法处理后,获得了d 天符合关联度Ri>0.8 的相似日,将d 天的特征变量矩阵按照日期顺序进行拼接以获取LSTM 网络模型的输入特征变量矩阵H,即

式中:xk,xk,1,xk,2,xk,3,xk,4,xk,5,xk,6,pk分别为负荷、温度、湿度、光照强度、风速、PM2.5 浓度、降雨量、电价 变 量;t 和k 为 特 征 变 量 的 时 间 长 度;i 和n 分 别 为待预测日之前的第i 和第n 天。
基于特征变量矩阵H,本文获得了LSTM 网络模型的数据样本集,在预测之前按比例划分数据样本集是必要的。以负荷数据集为例,数据样本集的划分方式如图2 所示。结合所提方法的思路,划分后各部分样本集的使用流程如附录B 图B2 所示。

图2 数据样本集的划分方法Fig.2 Segmentation method of data sample set
2.2 考虑DR 的电力负荷预测
2.2.1 LSTM 网络的预测过程
LSTM 网络作为一种特殊的递归神经网络(recurrent neural network,RNN),被广泛应用在时间序列预测的问题中[25]。由于输入特征并不唯一,本文应用LSTM 网络模型的预测方法通过将输入特征It和输出特征xt一起作为预测模型的输入实现将数据集转化为监督学习问题。同时,由于电力负荷时间序列的特殊性质,其变化特征不仅仅与当前时段的影响因素有关,其他时段的影响因素也可能间接影响电力用户参与DR 的积极性或者改变电力用户的用电行为。因此,所采用的输入数据样本集D 包含多个影响因素特征和历史时段信息,即

式中:It-1和xt-1分别为t-1 时段LSTM 网络模型的输入与输出特征,(It-1,xt-1)为输入、输出数据对。
为了让变量的选取与使用贯穿全文,本文续用式(2)的变量表达方式,则包含各种特征信息的It可表示为:

式中:S 为时间步长,且S∈(0,k];若以温度变量为例,xt-S,1表示待预测时段t 之前S 时段对应的温度值。
考虑到每个时段的负荷特性不同,需要分别训练不同时段的网络参数,因此本文将D 的每个时间步长S 中所包含的输入变量均当作一个单独的训练样本。以预测次日电力负荷为例,则LSTM 网络的输入和输出如附录B 图B3 所示。
在训练时,D 中的特征量{ I1,I2,⋅⋅⋅,It-1}作为网络的输入,采用对应负荷特征量{ x1,x2,⋅⋅⋅,xt-1}作为网络的输出来训练LSTM 网络。在预测时,将t 时段的特征量It输入到训练好的LSTM 网络即可预测t 时段对应的电力负荷值xt。
2.2.2 基于DMD 的误差预测过程
本文利用DMD 学习误差数据特征,通过识别误差的动态变化模式和相应的特征值来预测非线性的误差时间序列[21],具体预测过程如下。

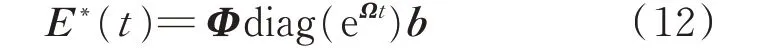
式中:b=Φ-1为动态模式的初始振幅。
2.2.3 基于LSTM 网络和DMD 的误差修正过程
在能源互联环境下基于DR 特征明显区域的数据样本集,所提方法首先通过LSTM 网络的训练与预测来获取负荷时间序列,其具体过程如图3 所示。然后,基于误差数据采用DMD 模型来预测误差时间序列。最后,用基于DMD 获得的误差值来修正基于LSTM 网络获得的负荷值以实现误差修正,并输出最终预测的电力负荷时间序列。
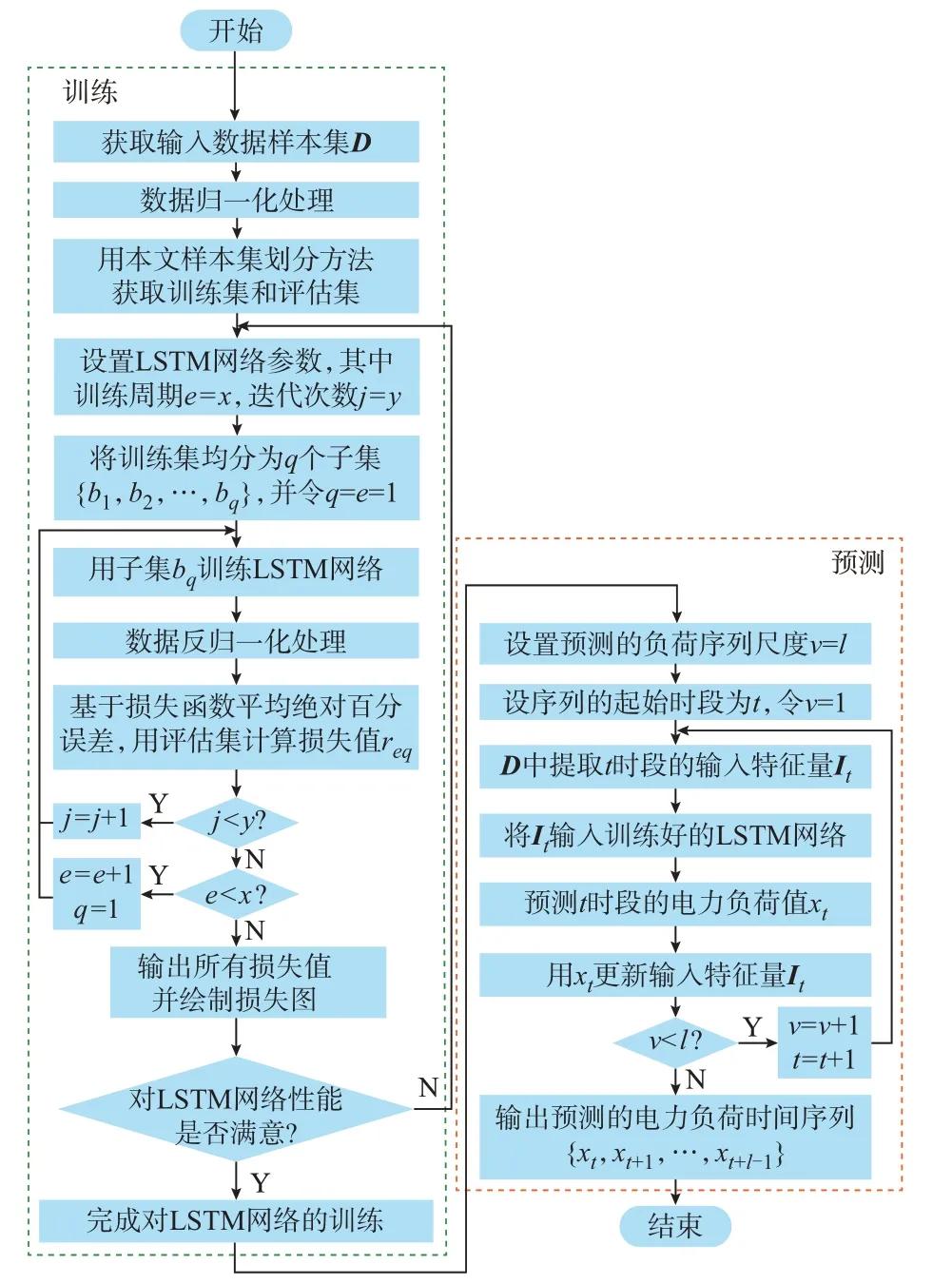
图3 LSTM 网络的训练和预测过程Fig.3 Training and prediction process of LSTM network
3 算例分析
本文以中国天津市某区域2017 年1 月至2019 年8 月采集时间间隔为1 h 的实际数据作为算例分析数据集,具体包括3 类数据集:电力负荷数据、电价数据和气象数据。其中,6 种气象数据包括温度、湿度、光照强度、风速、PM2.5 浓度和降雨量。此外,针对预测环境需要说明的是该区域主要采用基于电价的DR 调度方式,通过DR 电价吸引大约90%的电力用户参与DR,进而实现削峰填谷,缓解电网的运行压力。
3.1 所提方法的验证
3.1.1 输入特征变量的选取
本文采用GRA 法通过计算历史日气象特征变量与待预测日(2019 年7 月1 日)气象特征变量的关联度来选取具有较强相关性的相似日特征变量。相似日选取的结果包括:前一天(2019 年6 月30 日)、前2 天(2019 年6 月29 日)、前1 星期同一天(2019 年6 月24 日)、前2 星期同一天(2019 年6 月17 日)、前3 星期第3 天(2019 年6 月12 日)等。由于选取的相似日数据量巨大,本文只列举了有限几个数据来展示相似日特点。然后,基于选取的相似日,本文提取与相似日日期对应的3 类特征变量(即电力负荷、DR 电价和6 种气象)作为预测模型的输入特征变量。
3.1.2 模型性能的评价指标
由于平均绝对百分误差(mean absolute percentage error,MAPE)是衡量短期负荷预测模型性能最为常用的指标,且均方根误差(root mean square error,RMSE)对数据集中的异常值敏感,可以反映误差的分散程度,因此本文选择MAPE 和RMSE 来评估预测模型的性能。上述指标的值越小,代表模型的预测性能越好,定义如下。

式中:IMAPE和IRMSE分别为MAPE 和RMSE 指标值;P 为时间序列的采样点数;Ap和Fp分别为第p 个采样点对应的实际值和预测值。
3.1.3 基于LSTM 网络的负荷预测
基于选取的所有输入特征变量,需根据图2 来进一步划分数据样本集。基于分割后的A 集、B 集样 本 数 据,建 立 了2 个LSTM 网 络 模 型M1和M2来分别预测B 集负荷和待预测日(2019 年7 月1 日)负荷。为保证客观性,实验结果均为执行50 次实验得到的平均值。LSTM 网络的优化器均采用计算精度高且收敛速度快的Adam 优化器,损失函数均采用MAPE,超参数设置如附录A 表A2 所示。
在训练模型M1和M2的过程中,本文依据损失函数MAPE 来评估训练模型的性能。基于损失函数的变化特征来确定模型是否需要停止训练或者调整部分参数值重新训练。若损失函数曲线的波动趋于平稳化且MAPE 值降到预期值以下时,则完成训练。基于训练好的模型M1,将A 集特征向量和B 集气象特征向量输入模型M1来预测B 集的负荷时间序列以获取误差数据样本集,预测结果如图4 所示。基于训练好的模型M2,将B 集特征向量和待预测日气象特征向量输入模型M2来预测待预测日的电力负荷时间序列,预测结果如图5 所示。
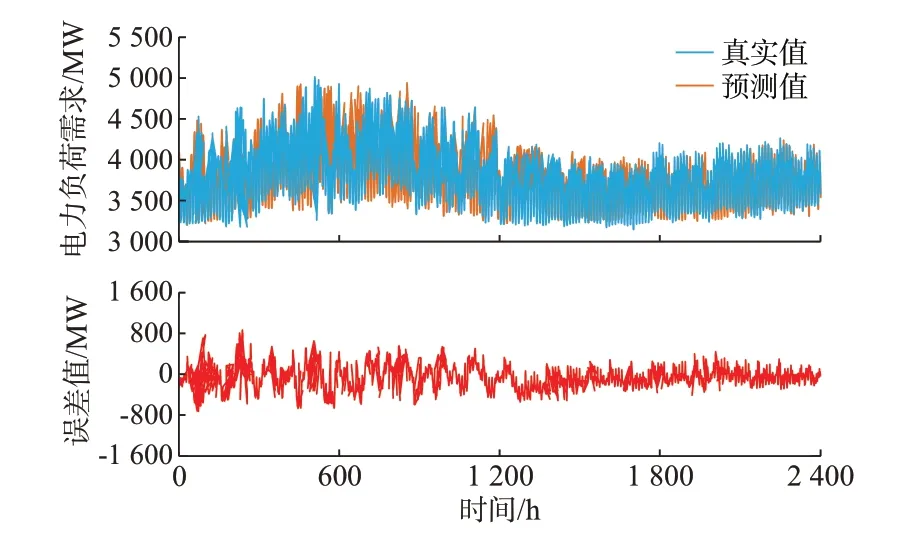
图4 B 集负荷的预测结果和获得的误差样本Fig.4 Forecasting results of B set and obtained error samples
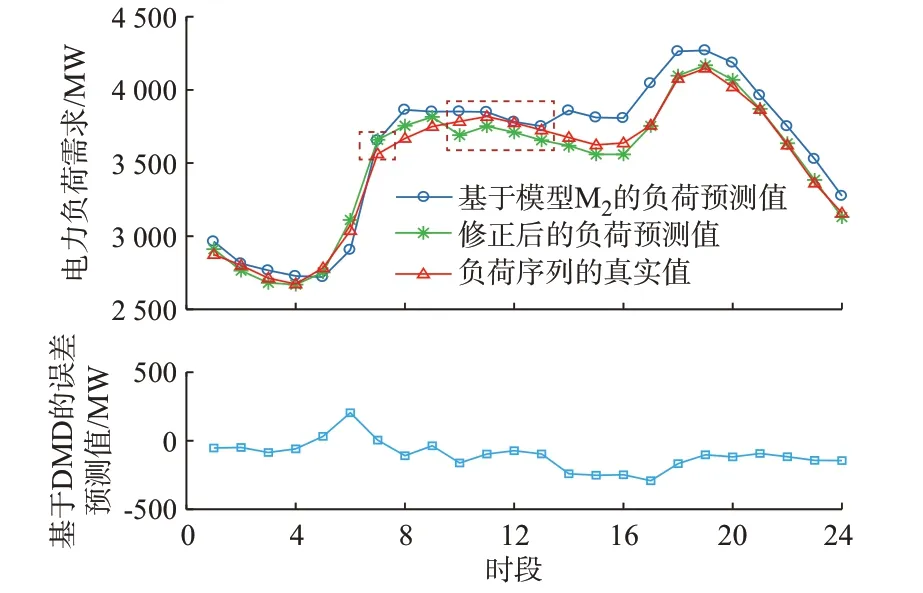
图5 2019 年7 月1 日的预测结果Fig.5 Forecasting results for July 1, 2019
3.1.4 基于DMD 的误差预测
由于用预测的误差值来修正预测的负荷值的方式在实际的应用中存在误差累积的现象,即若某时刻对应的负荷值小于真实值,而该时刻预测的误差值为负值,那么当通过叠加误差值与负荷值来实现误差修正时会导致修正后的负荷值与真实值的误差更大。因此为尽可能地降低误差累积发生的概率和发生时所带来的负面影响,本文选择了DMD 模型,利用其分解动态趋势特征的突出能力来预测误差序列的变化趋势[20]。然后,对图4 所获取的误差数据样本集进行简单的数据处理,即通过设置误差阈值来删除部分样本,若样本中含有绝对值大于阈值T 的误差值,则清除该类样本。需要说明的是阈值需依据误差样本集的容量来设置,本文取T=400 MW。基于处理后的误差样本,采用DMD 预测待预测日的误差时间序列,预测结果如图5 所示。
3.1.5 预测结果的分析
为了获取更为精确的预测结果,本文将基于DMD 的误差预测值与基于模型M2的负荷预测值相叠加来实现误差修正,修正后负荷时间序列的最终预测结果如图5 所示。从图5 中可以观察到在红色虚线框中有5 个时段对应的预测值出现了误差累积现象导致修正前比修正后的负荷预测值更接近于真实值,但是总体而言修正后的负荷值明显更加精确,这进一步验证了所提方法的有效性。
3.2 不同方法的对比
为了验证所提方法的优越性,本文设置了2 个案例分析。案例分析Ⅰ的目的是验证考虑DR 因素对预测精度的重要性,而本文与DR 有关的因素主要考虑了DR 电价,因此针对每个预测方法的输入变量设置了2 个对照组,即不输入电价变量和输入DR 电价变量。然后,选择LSTM 网络和本文方法来 预 测2019 年7 月1 日 至2019 年7 月7 日 的 负 荷,并取7 d 预测结果的均值作为各对照组的最终指标值,具体如表2 所示。
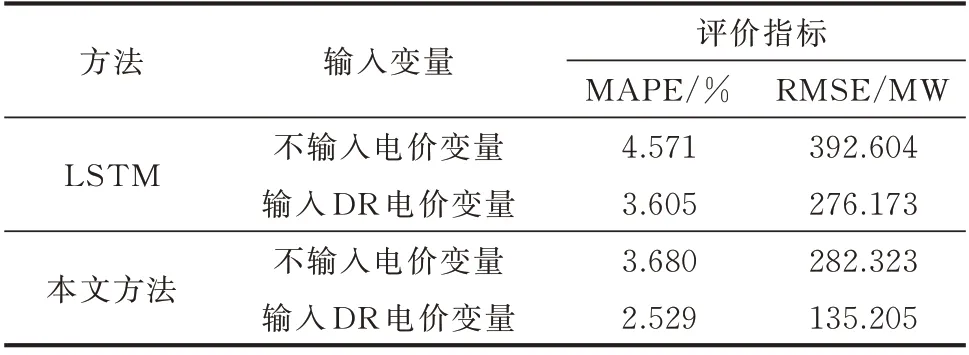
表2 输入变量对预测精度的影响Table 2 Effect of input variables on forecasting accuracy
由表2 可知,考虑DR 电价可改善预测精度,与不输入电价变量相比,其MAPE 降低了大约1%。因为该区域参与DR 的电力用户已经接近实现全面覆盖,这意味着基于电价的DR 调度将较大程度地影响用户用电行为,进而直接影响电力负荷曲线的变化,因此考虑DR 电价因素对预测精度的提高十分重要。
案例分析Ⅱ选择ARIMA 模型、反向传播(BP)神经网络、LSTM 网络和本文方法共4 种模型来分别预测2019 年8 月1 日至2 日连续2 d 共48 个负荷值。ARIMA 模型属于传统的线性预测模型,可作为评估其他模型的基准。BP 神经网络在预测领域中被广泛应用,案例Ⅱ使用3 层BP 网络结构,输入层为13 个神经元,隐藏层为35 个神经元,输出层为1 个神经元,学习率为0.001。LSTM 网络为所提方法的负荷预测模型,案例Ⅱ将其单独提出作为对比模型,4 种模型的性能指标值如图6 所示。

图6 2019 年8 月1 日至2 日连续2 天的预测结果Fig.6 Forecasting results for two consecutive days fromAugust 1 to 2, 2019
由图6 可知,本文方法的预测性能最好,其MAPE 达 到 了3.623%,而LSTM 网 络 的MAPE 为4.101%,由于DMD 擅于捕捉动态趋势的变化特征,并被广泛应用于流体动力学领域来分析更为复杂的流体特征,本文将其用于预测误差时间序列,并最终实现了有效的误差修正,改善了LSTM 网络的性能,使其MAPE 降低了大约0.5%。此外,ARIMA模型的MAPE 为6.533%,就线性模型而言,能达到这个预测精度说明其性能不算太差,由于ARIMA模型的数学原理决定了该模型无法综合分析多种变量的特征,并且对负荷时间序列的平稳性有较高的要求,这些特点限制了ARIMA 模型的预测性能。
BP 神经网络的MAPE 为4.875%,其性能优于ARIMA 模型,而逊色于LSTM 网络。由于训练时随着网络结构逐渐复杂化,BP 神经网络的过拟合问题较为突出,而LSTM 网络因特殊的门结构使其具有记忆和遗忘功能,这样在更新网络参数时,LSTM网络既可以利用当前时刻的数据特征,也可以利用门结构来遗忘或记忆前一时刻的数据特征,这就使得并非所有的输入数据都对网络参数的更新产生影响,因此可以在一定程度上改善过拟合问题。而与本文方法相比,BP 神经网络没有LSTM 网络的预测优势,也缺少误差修正对预测精度的进一步改善。
4 结语
在能源互联背景下,本文选取需求侧管理较为完善的地区作为目标区域,针对性地提出了考虑DR 的区域电网短期负荷预测方法。该方法经过数据处理、负荷预测、误差预测和误差修正4 个阶段对历史数据和预测模型进行适当处理,最后基于电网实际数据验证了所提方法的有效性和优越性,并得到以下结论。
1)在提取相似日特征变量过程中,本文选取多种气象数据作为比较特征,并通过设置恰当的阈值来控制样本数量,提高了相似日变量的选取标准和可控性,为获取更好的预测精度奠定了基础。
2)基于DMD 的误差预测可以有效实现误差修正,帮助LSTM 网络提升预测精度,并且在应用时,不需要选择模型参数。
与DR 相关的因素,本文主要考虑了DR 电价,这对于影响因素的挖掘并不全面,尤其对于需求侧管理较为完善的区域,因此未来可尝试将基于激励的DR 策略数据化,便于预测模型的使用,也为进一步改善预测精度提供可能。
附录见本刊网络版(http://www.aeps-info.com/aeps/ch/index.aspx),扫英文摘要后二维码可以阅读网络全文。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
河北理科教学研究(2020年2期)2020-09-11
能源(2018年10期)2018-12-08
商周刊(2018年16期)2018-08-14
当代经济(2016年26期)2016-06-15
能源(2016年11期)2016-05-17
东北电力技术(2016年2期)2016-05-17
中国化肥信息(2016年35期)2016-05-17
数学年刊A辑(中文版)(2015年2期)2015-10-30
核科学与工程(2015年2期)2015-09-26
