
应用LTRNet卷积特征的ECO目标跟踪算法改进
2021-01-08 06:19陈志旺娟姚权允彭
控制理论与应用 2020年12期
陈志旺 王 莹 宋 娟姚权允彭 勇
(1.燕山大学智能控制系统与智能装备教育部工程研究中心,河北秦皇岛 066004;2.燕山大学工业计算机控制工程河北省重点实验室,河北秦皇岛 066004;3.国网黑龙江省电力有限公司佳木斯供电公司,黑龙江佳木斯 154002;4.燕山大学电气工程学院,河北秦皇岛 066004)
1 引言
目标跟踪是机器视觉当前研究的热点方向,也是一项非常具有挑战性的工作.目前,目标跟踪技术在高级人机交互、安全监控和行为分析等方面具有潜在的经济价值和广泛的应用前景[1].因此,需深入研究、设计高性能的目标跟踪算法.
近年来随着深度学习的不断发展,卷积神经网络强大的特征学习能力引起了国内外专家学者的广泛关注[2].基于深度学习的跟踪方法因精度高、性能稳定逐步成为了目标跟踪发展的主流方向.2015年,VGGNet[3]网络模型的出现将跟踪算法的精度提升到了一个新高度.Danelljan等提出的连续卷积跟踪算法(learning continuous convolution operators for visual tracking,C-COT)[4],采用多层VGGNet卷积特征,通过连续空间域插值转换操作,可以将不同分辨率的特征输入滤波器.2017年,Danelljan等以C-COT为基础,提出了一种具有高效卷积特性的跟踪算法(efficient convolution operators for tracking,ECO)[5],该算法从模型大小、训练集大小以及更新策略3个方面进行改进.在OTB2015[6]上的测试结果很长一段时间排名第一.随后,He 等基于ECO 提出了具有加权卷积响应的(correlation filters with weighted convolution responses,CFWCR)[7]改进算法,此算法使用VGGNet卷积特征的多尺度相关滤波跟踪方案,通过加权处理深、浅卷积特征的卷积响应结果提升了跟踪精度.2018年,Goutam等将ECO中的VGG16[3]换成了ResNet50[8],并加入数据增强处理提取目标特征,提出了可以有效利用深度卷积网络进行跟踪的(unveiling the power of deep tracking,UPDT)[9]跟踪算法,先对不同层次特征进行分治,然后,自适应计算两种特征的响应加权系数并加权融合,有效提高了深度特征下的跟踪算法性能.此外,在VOT2018[10]短时跟踪公开测试集挑战中,具有多分辨率融合特性的(multi-solution fusion for visual tracking,MFT)算法,通过针对不同分辨率特征独立求解,并根据跟踪视频的难易程度自适应优化融合多个解来预测目标位置,使算法鲁棒性排名第一.
以上算法除C-COT是ECO算法的基础外,其他都可看作是ECO算法的改进.这些算法主要利用深度卷积网络提取强表征能力的目标特征提高跟踪精度,且网络越深,精度越高.但随着卷积网络层数的增加,训练网络愈加复杂,目标特征提取效率逐渐降低,加上要对高维数据进行计算,开销较大,最终导致跟踪实时性差.
因此,本文在文献[5]的基础上,从深度卷积网络结构出发,提出了改进的ECO 算法LRECT(LTRNet for efficient convolution tracker).首先,引入了Dong等人[11]因受常微分方程(ordinary differential equation,ODE)[12]线性多步数值方法启发提出的LT残差结构,堆叠LT形成了利于目标跟踪的LTRNet(LT-ResNet)深度卷积网络;其次,利用该网络提取目标特征,并通过投影矩阵压缩特征,插值处理提高特征的亚像素精度.之后,在傅里叶域将处理后的特征与当前滤波器进行卷积定位计算.最后,利用高斯牛顿算法[13]和共轭梯度算法[13]联合求解优化目标更新滤波器和投影矩阵.
2 基础理论
2.1 ECO跟踪算法
ECO[5]是一种具有高效卷积特性的跟踪算法,其提取目标的VGGNet[3],HOG(histogram of oriented gridients),CN(color-names)特征用于相关滤波框架实现目标定位和滤波器更新.
首先,沿用C-COT[4]的插值方法对检测样本的目标搜索区域特征x进行如下式所示的插值运算:
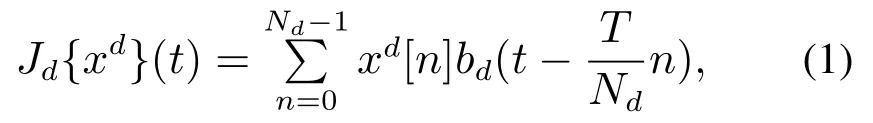
式中:xd表示x的d通道特征(d ∈[1,D]);Jd{xd}(t)是一个关于t ∈[0,T)的函数,表示xd的插值运算结果;是关于n ∈{0,···,Nd-1}的函数;Nd是其分辨率;是d通道的插值函数.用J{x}(t)∈RD表示的1至D通道的插值结果,简记为J{x}.其次,使用主成分分析法[14](principal component analysis,PCA)简化滤波器,然后与J{x}进行卷积计算求响应得分SPf{x}:

式中:f是通道数为D的滤波器,“*”是卷积运算符,P是D行C列的投影矩阵,PT是其转置矩阵.对SPf{x}使用高斯牛顿算法[13]进行优化,可找到最大得分值的位置(目标的新位置).最后,先使用高斯混合模型(Gaussian mixture model,GMM)[15]方法压缩训练集.之后,对训练样本和当前滤波器f的卷积响应得分SPf{µm}与训练样本高斯标签y0的误差取L2范数,并添加惩罚项构造如下所示的损失函数:

式中:µm和πm分别是训练样本的均值和权重;M是训练样本总个数;ω是f的惩罚项,此处使用的P仅在第1帧中计算确定,以后使用共轭梯度算法[13]每隔6帧求解一次式(3)更新f时,P保持不变.
综上,ECO通过减小滤波器、训练集以及滤波器更新频率降低了算法复杂度,提升了跟踪速度.但其忽略了深度VGGNet提取高维目标特征所消耗的时间.对此,本文从卷积网络结构出发,进一步研究提升ECO跟踪性能的方法.
2.2 LT残差结构
针对深度卷积网络的可解释性问题,Dong Bin等人[11]从数学的角度将ResNet[8]等深度卷积网络理解为常微分方程ODE[12]显式欧拉的数值离散近似.结合图1(a)可形象化地将ResNet残差结构Basic block写为

式中:un和un+1分别表示第n+1个Basic block残差结构的输入和输出,f(tn,un)表示由tn和un参数化了的两个卷积层(Conv). u′(t)=f(t,u(t))的显式欧拉离散如下:
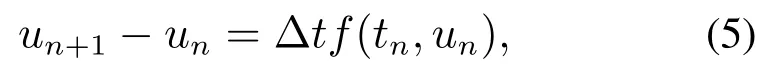
式中:un和un+1表示ODE在tn和tn+1处的数值解,Δt表示步长,f(tn,un)≈u′(tn),u′(tn)是函数u(t)在tn处的导数.对比式(4)-(5)可知,式(4)是式(5)步长Δt=1时的一个特例.
然后,为利用ODE的线性多步数值方法(式(6))可以提高当前数值解un+1对精确解u(tn+1)的近似精度的特性,提出了LT残差结构(式(7)):
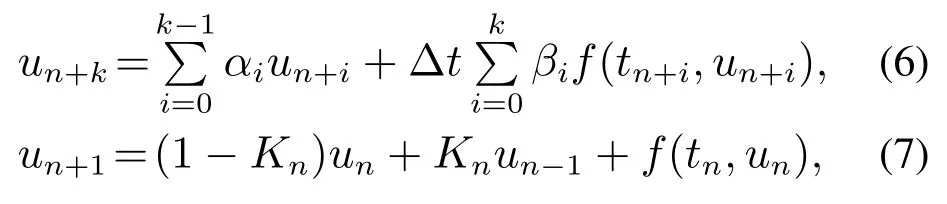
式(6)中:k表示步数,αi和βi为标量参数,un+k表示第k步的预测数值解,f(tn+i,un+i)表示u(t)在tn+i处的导数近似,且tn+i=tn+iΔt.取式(6)中的参数

可得到式(7).式(7)中Kn∈R表示第n个LT残差结构的可训练参数,un-1表示第n个Basic block残差结构的输入,其他变量含义同式(4).由un-1的含义解释可知,LT残差结构可用于任何类似于ResNet的深度卷积网络,本文称这一新网络为LTRNet.
图1(a)-1(b)分别是Basic block和LT残差结构原理图,对比可知,1个LT包含2个Basic block和1个训练参数Kn.在求解un+1时,图1(b)较图1(a)多引入一历史信息项un-1,且un-1和un分别配有Kn和1-Kn这样相互制约的训练权重,使LT能够选择保留un-1和un的有效特征信息融入到un+1.对比仅保留un这一历史信息项的Basic block,LT使历史信息遗忘较慢,更能得到充分利用.
此外,由原理图还可知,使用Basic block或LT堆叠而成的深度卷积网络训练的实质是进行残差学习.分别将式(4)和式(7)在保留Δt的情况下写成残差形式

对上两残差等式的左侧部分在tn处做泰勒展开,分别得到式(4)和式(7)忽略高阶项的残差式(8)-(9):
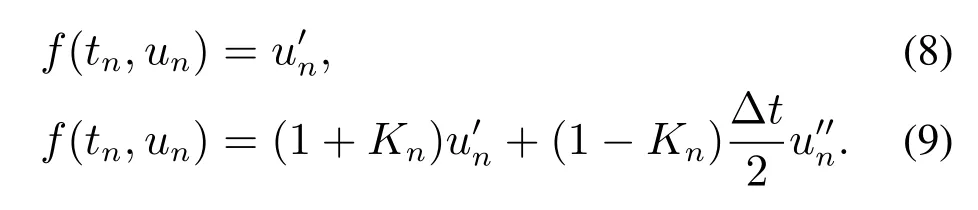
对比以上两式可知,式(9)对残差f(tn,un)的逼近程度较式(8)提高了一个级别的精度.综上可得:相比于Basic block,使用LT可以得到更高的深度卷积网络分类精度.

图1 残差结构原理图Fig.1 Schematics of residual structures
3 LRECT跟踪算法
本文提出的是一种应用LTRNet卷积特征对ECO[5]进行改进的目标跟踪算法,主要由特征提取模块、目标定位模块和滤波器更新模块3部分构成,跟踪过程如图2所示(图中⊗表示卷积操作).
3.1 特征提取模块
3.1.1 LTRNet32网络
根据第2.2节中的理论分析和第5.3节的实验结果,设计如图3所示的LTRNet32作为本文跟踪算法的特征提取模块.由图可知该网络由1个卷积层(Conv),4个卷积块(Layer 1,Layer 2,Layer 3,Layer 4),3个最大池化层(Pool 1,Pool 2,Pool 3),1个全局平均池化层(Gavp),1个全连接层(Fc)和1个Softmax函数层组成.若将含有2个卷积层的结构视为1个Block,Layer 1,Layer 2,Layer 3 和Layer 4分别包含Block 个数为1,2,8,4.考虑到新搭建的网络在使用前需要先进行训练,对于Conv,首先对输入依次进行BN归一化处理、ReLU激活和2D卷积操作的模式来解决网络训练初期误差下降缓慢的问题.其次,采用3×3的小卷积核,这样所需训练参数少,进行堆叠操作还能增加特征的多样性.此外,为了进一步减少网络训练参数,在Layer之间使用1个3×3的最大池化层,保留显著特征信息,降低特征图维度;对Layer 4的输出先进行全局平均池化,再执行全连接操作.最后加上Softmax函数形成了一个完整的LTRNet32图像分类网络.
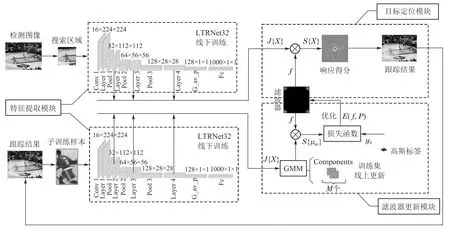
图2 LRECT跟踪算法框架图Fig.2 The framework of LRECT tracking algorithm
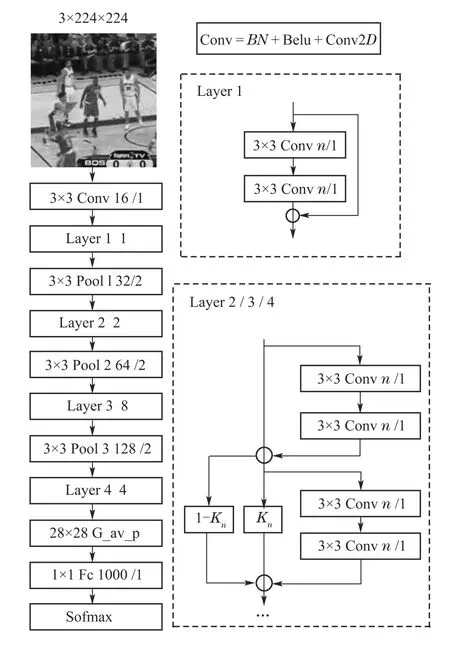
图3 LTRNet32网络结构Fig.3 Network structure of LTRNet32
3.1.2 卷积特征的选取
深度卷积网络不同层所提取的卷积特征侧重点不同,浅层卷积特征保留了更多细粒度的纹理信息以及空间信息;深层卷积特征含有丰富的语义信息.为了分析、选取有效的目标特征,对LTRNet32的不同Layer层进行如图4所示的可视化输出,图4(a)是检测图像中的目标搜索区域,图4(b)-4(e)分别是Layer 1,Layer 2,Layer 3,Layer 4对图4(a)卷积输出的特征可视化图.观察图像可知,图4(b)中包含较多原始图像的轮廓和位置信息,目标的有效特征信息占比少;图4(c)包含较为细致的轮廓信息;图4(d)包含高细粒度的纹理信息和部分语义信息;图4(e)包含丰富的高级语义信息,可以明显区分目标(人)和背景.考虑到视频跟踪任务需要利用目标的空间信息进行定位,高级语义信息应对目标表观变化,本文舍弃Layer 1,选取Layer 2,Layer 3,Layer 4 分别提取32,64,128维的卷积特征,用于后续目标定位和滤波器更新.

图4 LTRNet32网络Layers卷积输出可视化图Fig.4 Convolution output visualizations of Layers in LTRNet32
3.2 目标定位模块
目标定位是实现目标跟踪的表现形式.图2中的定位模块缺乏实现细节.对此,本节将从特征压缩、特征处理和卷积定位这3个方面对该模块进行详细论述,其实现框架如图5所示.
1) 特征压缩.
由于不同卷积核对图像的敏感方向不同,所以不是每个通道提取的特征都是有用的.图6是Layer 4输出特征的128个通道的可视化图,观察可知,1通道和127通道提取了较多的背景信息;65通道对图像不敏感,几乎没有提取到有效信息;128通道较2通道可以提取更为详细的目标信息.所以,可将一些类似于1通道和65通道等对目标定位贡献不大的卷积通道舍去,之后再用于目标定位,这样可以减少算法计算量,也不会影响所提取特征的表征能力.假设x是LTRNet32针对某帧检测图像的目标搜索区域提取的D维卷积特征,受式(2)启发,使用投影矩阵P对其进行压缩:

式中:x*表示压缩后的C维特征,即x*有C个特征通道. P是一个C行D列矩阵(C ≤D),随滤波器一起更新计算,其具体求解见第3.3节内容,计算见式(17).

图4 128个通道的特征可视化图Fig.6 Feature visualizations of 128 channels

图5 目标定位框架图Fig.5 Framework of object localization
2) 特征处理.
首先,对特征压缩所得的x*添加余弦窗Wcos解决边界效应问题:

式 中X=(X1,···,XC).取X通 项Xc(c ∈[1,C]),参考式(1),对其进行如下式所示的可提高亚像素精度的逐通道插值运算:

式中:J{X}(t)∈RC表示X的C个通道插值结果的叠加;随离散变量n ∈{0,···,Nc-1}变化而变化,Nc表示Xc的分辨率表示c通道的插值核函数.
3) 卷积定位.
目标定位主要是将处理后的低维压缩特征J{X}同当前滤波器f=(f1,···,fC)进行卷积计算.为了便于计算,先利用傅里叶变换将J{X}和f转化到频域,记为,然后通过下式得到频域的响应得分

式中:“∧”表示频域,时域中的卷积计算可参考式(2).取得分响应图中最大得分值的位置作为预测的目标位置,定位结果如图5中预测位置所示.
3.3 滤波器更新模块
滤波器更新模块包含生成训练集和优化损失函数两部分,其完整实现过程见图2下半部分.训练集的生成策略:将处理后的目标特征通过高斯混合模型(Gaussian mixture model,GMM)[15]聚类的方法合并入训练集进行训练样本在线更新(图2中GMM表示训练集,Components表示训练样本).该方法区别于“单纯添加新训练样本,盲目丢弃旧训练样本”的传统训练集更新策略,将空间内相距较近,且符合高斯分布的一组卷积特征视为一个训练样本,通过在线更新这些卷积特征组实现训练集的更新.
优化损失函数就是更新滤波器f和投影矩阵P.为了降低因目标被遮挡滤波器发生漂移的概率,本文沿用文献[5]的稀疏更新策略:在使用第1帧检测图像给出的目标初始信息计算f和P之后,每隔Ns帧检测图像,使用当前的Components训练样本进行一次f和P更新.参考式(3)构建如下所示的损失函数:
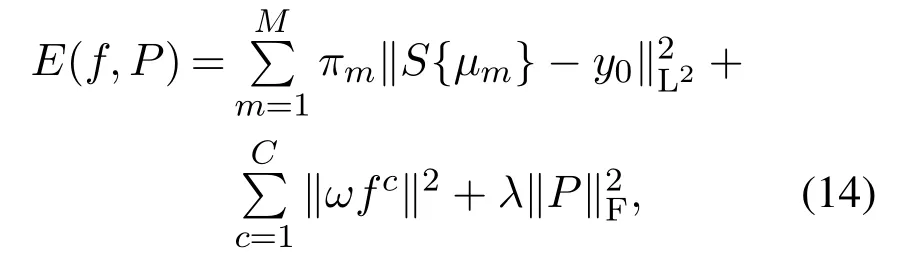
式中:M,y0,C,ω含义同式(3),分别表示训练样本的总个数、高斯标签、滤波器通道数和f的惩罚项;µm,πm,S{µm}分别表示第m个训练样本Component的均值和权重,以及其与f 的卷积响应得分;表示P的F范数,是P的惩罚项;λ为其权重系数.
优化求解式(14)完成f和P更新,常用的主流方法有标准梯度下降法[13]或随机梯度下降法[13]等,但这些算法收敛速度慢,针对这一问题,本文采用高斯牛顿算法[13]与共轭梯度算法[13]联合优化式(14).
首先,定义对应f=(f1,···,fC)和P的残差:

其次,引入高斯牛顿算法,对r(f,P)进行一阶泰勒展开:

式中:

是r在当前(f,P)下的雅可比式,Δ(f,P)是关于滤波器增量Δf和投影矩阵增量ΔP的表达式.将式(15)代入式(14)得E(f,P)二阶高斯牛顿近似表达式:

最后,使用共轭梯度算法迭代优化式(16),先得到Δf和ΔP,再通过下式更新f和P.

为了直观理解上述f和P的更新过程,给出如下联合优化的伪代码,其中NGN代表高斯牛顿算法的迭代次数,u代表和r大小相同的向量,NCG代表共轭梯度算法的迭代次数,p和α分别代表每步优化的方向和步长,β代表更新动量.


综合以上内容,本文算法LRECT舍弃了ECO中的传统手工特征HOG和CN,仅依靠深度卷积网络LTRNet32提取目标特征.为了使这一特征得以充分利用,本文算法选择采用投影矩阵随滤波器一起进行稀疏更新的策略.这是基于当前帧目标特征与临近帧中的目标特征相似性大这一基础理论,稀疏更新投影矩阵能够使其适应视频序列不同帧中目标的不同状态,保持较高效、准确的压缩特性.使用这样压缩后的目标特征作为训练样本,有利于学习得到更加稳定的滤波器.
4 算法步骤
LRECT跟踪算法具体过程如下:
步骤1初始化算法参数:初始化投影矩阵P,滤波器f,训练样本权重πm等;创建余弦窗口Wcos;构建高斯标签函数y0;设置特征压缩后维数C以及高斯牛顿和共轭梯度算法的迭代次数NGN和NCG等参数.
步骤2读取视频序列的第一帧检测图像,使用其提供的目标初始信息裁剪出子训练样本.
步骤3将子训练样本输入LTRNet32网络提取卷积特征x.先后利用式(10)-(12)对x进行压缩、加窗、插值处理得J{X}.
步骤4使用J{X}初始化训练集GMM中的第1个Component.
步骤5采用高斯牛顿算法和共轭梯度算法联合优化式(14)得增量Δf和ΔP,利用式(17)处理两增量得到新滤波器f和投影矩阵P.记录保存当前目标信息.
步骤6读取下一帧检测图像,使用LTRNet 32提取其搜索区域的卷积特征x,之后对x做同步骤3一样的压缩、加窗、插值处理得到J{X}.
步骤7使用傅里叶变换将J{X}和当前滤波器f转化到频域.之后利用式(13)完成频域中的卷积计算,得到卷积响应得分,找到图中最高响应得分值的位置,将其作为当前帧中目标位置进行保存.
步骤8根据上步得到的目标信息在当前帧中裁出子训练样本,并对其执行同步骤3的操作.
步骤9对J{X}使用GMM方法更新训练集.
步骤10判断是否需要更新f和P.如果需要,执行同步骤5的操作.
步骤11判断是否跟踪完视频序列,如果没有,跳转至步骤6;若跟踪完毕,输出视频所有帧的目标信息,保存结果.
5 实验结果与分析
5.1 实验平台
本文所做实验均在一台装有1 张Nvidia GTX 1080ti GPU 的计算机上进行,处理器为Intel core(TM)i7-8700K,主频为3.70 GHz,内存为32 GB,操作系统为64位Ubuntu16.04,编程环境为python3.6,深度学习框架为PyTorch.
5.2 实验参数设置
1) 网络训练参数设置:超参数设置如表1所示.
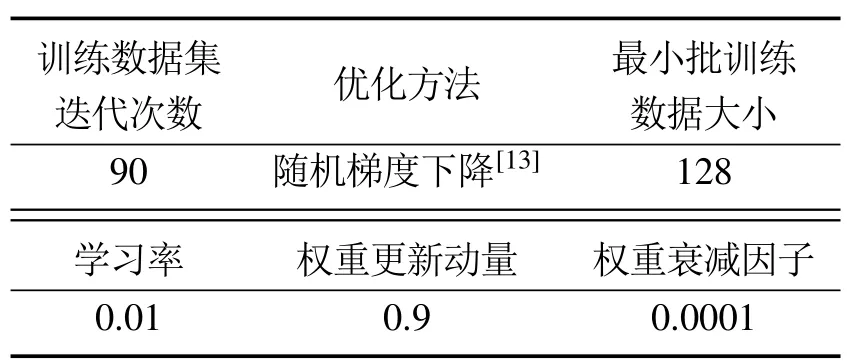
表1 超参数值Table 1 Values of hyper-parameters
2) LRECT跟踪算法参数设置:使用训练好的LTRNet32作为特征提取模块,设置其输入图像大小为224×224,选择Layer 2,Layer 3,Layer 4作为特征提取层,设置特征压缩后维数为8,116,32;使用零初始化滤波器f,随机方式初始化投影矩阵P;对于第1帧检测图像,设置高斯牛顿算法和共轭梯度算法的优化迭代次数:NGN=6,NCG=15.以后每隔Ns=6 帧检测图像,取NGN=1,NCG=10.此处未提及的需要初始化的参数均沿用文献[5]中的设置.
5.3 网络性能对比分析
为验证第2.2节中引入的LT残差结构和第3.1.1节中提取模块网络层数设计的有效性,本节将通过堆叠LT残差结构形成的LTRNet与通过堆叠Basic block残差结构形成的ResNet[8],先后在数据集CIFAR10[16]的训练集和验证集上进行训练与评估,训练超参数除训练数据集迭代次数为200外,其他设置同表1.实验细节:首先,采用Lee等人[17]的方法对CIFAR10的训练集图像做预处理,然后随机剪裁出32×32大小的图像块用于网络训练.当网络遍历学习一次训练集图像后,以验证集图像的初始目标中心为中心裁剪出32×32大小的图像块用于网络验证.此外,LTRNet中的参数kn在集合[-0.1,0.0]中随机取值进行初始化,其他参数和ResNet网络参数同文献[11],使用PyTorch框架下的随机方式进行初始化.最终测试评估结果见表2.
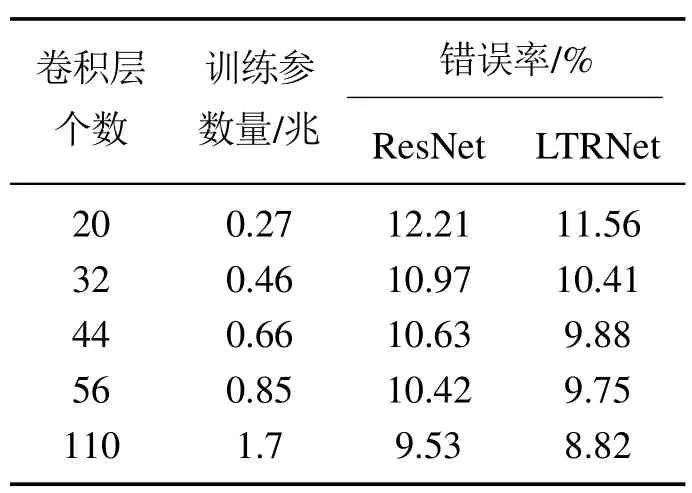
表2 卷积网络在CIFAR10验证集上的错误率Table 2 Error rates of convolution networks on CIFAR10 validation set
由表2数据可知,LTRNet和ResNet随着网络层数的加深,训练参数量逐渐增加,分类错误率逐渐降低;在两者同层情况下,参数量相同,但LTRNet的错误率比ResNet平均要低0.7%左右;LTRNet56几乎可以达到ResNet110的分类效果.以上实验结果说明,LTRNet是一种较ResNet拥有更高精度、更高效率的卷积网络模型.此外,对比LTRNet不同卷积层数的训练参数量和错误率,发现当卷积层数从20到32时,错误率下降了1.15%,之后随着网络层数的加深,错误率下降并不显著.结合这些数据并考虑跟踪的时效性,本文算法选择LTRNet32作为特征提取模块.
5.4 LTRNet32网络训练与特征选取结果分析
为了利用LTRNet32卷积网络提取强表征能力的目标特征,先利用ImageNet[18]数据集对其进行训练与验证评估,其训练超参数设置见表1,但学习率为0.01是初始值,当训练数据集迭代次数为30和60时,会相继缩减为0.001和0.0001.实验细节:首先,随机剪裁训练集图像为224×224大小的图像块.然后,采用同文献[18]的预处理方式处理图像块.当网络遍历一次训练集图像后,以验证集图像初始目标中心为中心裁出一个224×224大小的图像块用于网络评估,评估结果见表3.LTRNet32网络的参数初始化同第5.3节实验设置.之后,将训练好的LTRNet32的不同Layer的卷积输出进行组合用于本文算法LRECT,在OTB2015[6]数据集上进行分组测试,得到如表3所示的测试结果(LRECT的参数设置见第5.2节).
由表4数据可知,使用LTRNet32对一张图像进行分类时,由Softmax函数统计出1000个概率,其中,最大概率为正确识别答案的概率(Top--1)为82.0%,比VGG16[3]和ResNet50[8]分类网络的Top--1值分别高出6.7%和2.7%;排名前5的概率中包含正确识别答案的概率(Top--5)为94.5%,与ResNet50的Top--5仅差0.3%.综上可知,LTRNet32的综合性能优于VGG16和ResNet50.
表3中Layer 2,Layer 3,Layer 4表示其卷积输出的特征图,跟踪精度[6]指算法估计的目标中心点与人工标注的目标中心点两者的距离小于给定阈值的视频帧的百分比;跟踪成功率[6]指算法估计的目标边界框与人工标注的目标边界框的交并比大于给定阈值的视频帧的百分比.因Layer 1相对于目标包含较多背景信息,对表征目标和实现精确定位干扰性强,所以,此处未考虑Layer1层的卷积输出.另外,Layer 4作为LTRNet32的最后一个卷积块的输出,包含最为丰富的目标高级语义信息,在第3.1.2节的可视化图显示能够明显区分目标和背景,所以,将其列为特征组合中的一员,但不参与以下具体的数据对比分析.
对比Layer 3+Layer 4,Layer 2+Layer 3+Layer 4两组数据可知,后者较前者在跟踪精度和成功率方面,分别提升了2.3%和0.7%,这是因为Layer 2卷积特征包含了较Layer 3和Layer 4更为全面的目标边缘和位置信息,对目标定位贡献较大,所以提升跟踪精度比较明显.
对比Layer 2+Layer 4,Layer 2+Layer 3+Layer 4可知,后者较前者精度和成功率分别提高了3.5%和2.6%,这是因为Layer 3属于LTRNet32的中间层,含有非常细致的目标轮廓信息,和比较丰富的目标语义信息,使其具有了利于目标定位和表征目标的双重优势.
5.5 跟踪算法性能对比分析
为了验证本文提出的LRECT跟踪算法的有效性,引入近几年一些主流跟踪算法,同本文算法一起在OTB2015[6]数据集上进行对比测试,并采用一次跟踪评估(one-pass evaluation,OPE)[6]中的跟踪精度和跟踪成功率作为算法测试的评价指标.测试结果见图7.
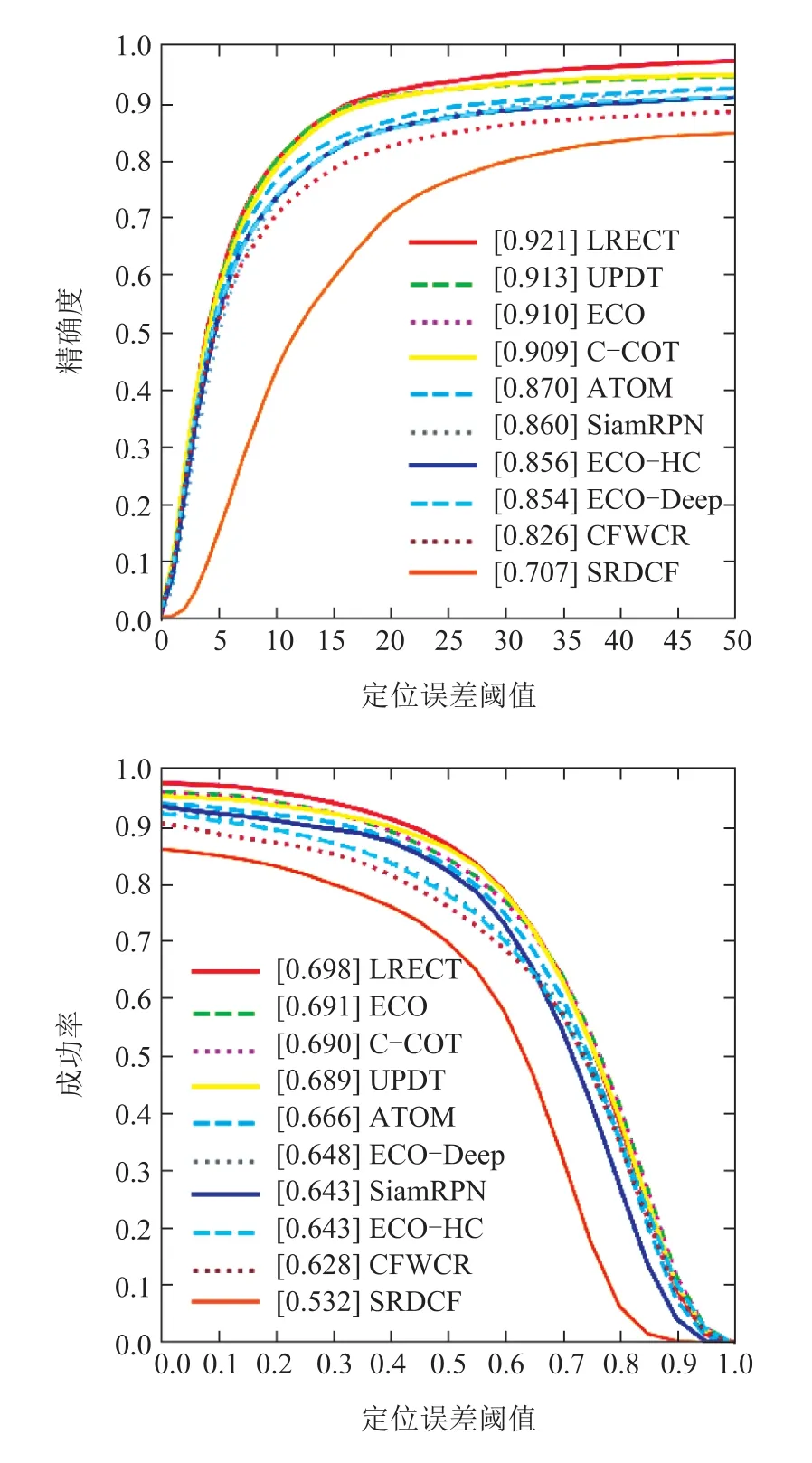
图7 算法在OTB2015上的对比测试结果Fig.7 Comparative test results of the algorithms on OTB2015
由图7可知,本文算法LRECT获得了0.921的跟踪精度和0.698的成功率,在10种算法中跟踪效果最好.将其他算法按照目标使用特征类型进行分类,与本文算法在精度方面相比较,得到如表5所示的LRECT 百分点提升结果,由表中数据可知,一般情况下卷积特征的表征能力优于传统手工特征,越深的卷积网络提取的卷积特征表征能力越强;本文算法使用LTRNet32提取的目标特征比使用ResNet50[8]的UPDT算法跟踪精度高了0.8%,这有效证明了LTRNet32网络的有效性.在成功率方面,本文算法较其他算法平均高出了7.1%,这可能得益于稀疏更新投影矩阵的策略,保留了适应目标状态的有效特征信息,提高了跟踪成功率.
图8是ECO[5],CFWCR[7],UPDT[9]算法与本文算法在OTB2015[6]数据集的11种属性上进行测试得到的精确度得分.横轴的11种属性的相关缩写英文含义见文献[6].由图8 可知,本文算法LRECT在SV,LR,BC,DEF,OPR这5个属性上均优于其他算法,尤其在LR,BC这两种属性上相比基础算法ECO分别提升了10%和13%左右,在DEF属性上比UPDT提升了3%左右.这有效证明了LTRNet32网络的强泛化能力,以及其提取卷积特征的强表征能力.同时,易知在OV 这一属性上本文算法较ECO 降低了7%左右,这是因为属于OV 属性的图像无法为LTRNet32 提供有效的目标信息,在跟踪过程中,投影矩阵的更新会对后续帧的表征能力造成一定程度的负面影响,严重时(当小目标超出视野时)可能导致跟踪失败.
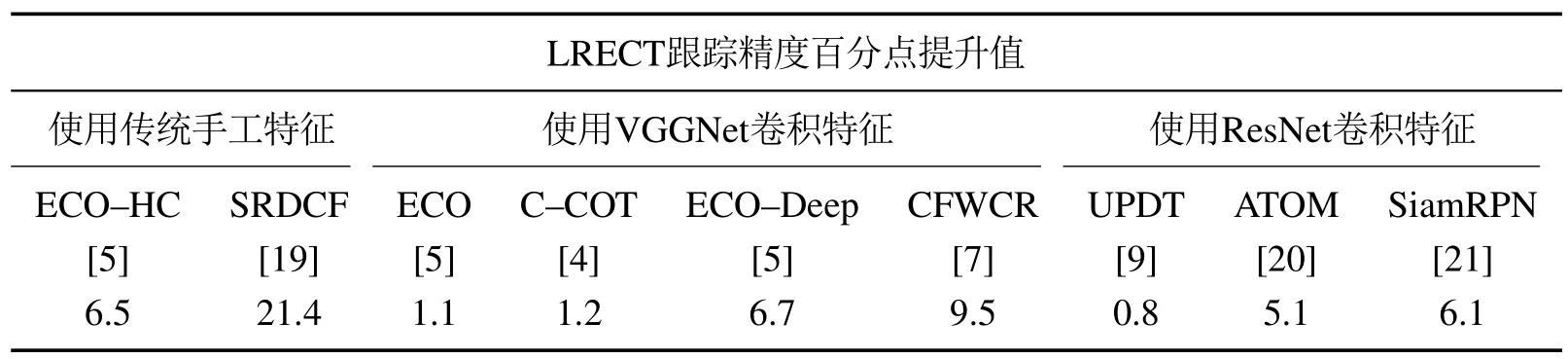
表5 LRECT较其他算法提升的精度百分点Table 5 The improved accuracy percentages of LRECT compared with other algorithms

图8 算法在OTB2015数据集的11种属性上的精确度得分Fig.8 Accuracy scores of algorithms on 11 attributes of the OTB2015
为了保证实验结果的客观性,测试对比本文算法与ECO[5]算法在OTB2015[6]数据集中的100个视频序列上的表现.跟踪精度测试结果:本文算法跟踪Basketball,Jump,Skiing,Trans 视频序列的精度结果较基础算法ECO提升了10%左右,在跟踪Soccer,Tiger 1,Tiger 2时,却减少了20%左右,表明本文跟踪算法所提取的目标特征并不有利于所有的视频序列,当遇到像Tiger 1这样涉及快速移动和遮挡等跟踪难点的序列时,算法所提取的特征缺乏高级语义信息,继续进行压缩操作导致其表征能力大大减弱,最终造成不同程度的精度损失.跟踪成功率测试结果:本文算法跟踪David时,由于高强度、高频率的光照变化,使其成功率较ECO低了25%左右,但成功率值还在60%以上.并且在100个视频序列中有84个的跟踪成功率在60%以上,整体比ECO提高了7%.以上结果表明,本文算法不能有效应对一个视频序列中所包含的所有跟踪难点,但与基础算法ECO相比,训练的滤波器跟踪性能更加稳定,验证了更新投影矩阵的有效性.此外,测得平均帧率如表6所示.

表6 100个视频序列的平均帧率Table 6 Average frame rate of 100 video sequences
由表6可知,本文算法平均每秒跟踪帧数比ECO多4帧,验证了使用特征压缩和高斯牛顿算法、共轭梯度算法联合求解损失函数策略的有效性.
6 结论
本文提出的LRECT跟踪算法利用LTRNet深度卷积网络提升了算法跟踪性能.首先,利用LT残差结构设计高效率、高精度的LTRNet32作为特征提取模块,通过观察、分析实验结果选取LTRNet32的Layer 2,Layer 3,Layer 4卷积块的输出表征目标.其次,通过分析卷积特征特点,使用投影矩阵压缩目标高维特征,在不影响特征表征能力的同时,降低了计算量.最后,先使用高斯牛顿算法构造损失函数的二阶高斯牛顿近似表达式,再使用共轭梯度算法对该表达式迭代优化,同时实现了滤波器和投影矩阵的更新,改善了在线学习滤波器收敛速度慢的问题,使投影矩阵保持了较高效、准确的压缩特性.最后,实验结果表明本文跟踪算法具有较好的抗非刚性形变、低分辨率、背景混乱等能力,以及拥有较高的精度和抗干扰能力.此外,帧率虽有所提升,但仍未达到实时性要求.对此,会考虑采用具有高效特性的端到端网络实现目标边界框的回归等策略实现算法加速.
猜你喜欢
成都信息工程大学学报(2022年2期)2022-06-14
网络安全与数据管理(2022年3期)2022-05-23
北京航空航天大学学报(2020年10期)2020-11-14
科技创新与应用(2020年6期)2020-02-29
北京航空航天大学学报(2019年9期)2019-10-26
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
电子制作(2018年1期)2018-04-04
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
