
基于数据挖掘技术的冠心病诊断预测模型
2021-01-07 11:53:20李雨洁郑锐龙杨旭明
医学信息 2020年24期
李雨洁,郑锐龙,杨旭明
(上海中医药大学针灸推拿学院,上海 201203)
随着社会发展水平的提升,人民生活水平的不断提升以及人口老龄化使得我国心血管疾病患病率处于持续上升的阶段。2016 年我国心血管疾病的死亡率率居首位,高于肿瘤等疾病。与此同时,2009~2016 年的数据显示,农村心血管疾病死亡率远高于城市水平[1]。在各种心脏疾病当中,冠心病是一种较为常见且对人体危害较大的心血管疾病。冠心病一般指冠状动脉粥样硬化性心脏病,目前该病的检查手段的“金标准”为冠状动脉造影及血管内成像技术,其成本相对昂贵[2]。基于此,本文对冠心病的诊断所涉及的因素做出讨论,试图通过数据挖掘的方法探究不同生理状态及检测结果对冠心病诊断的影响,建立一个冠心病早期预测模型,从而降低检查成本,帮助医护人员对患者病情做出准确判断。
1 资料与方法
1.1 数据采集及预处理 冠心病的诊断数据来源自UCI 数据库,是由匈牙利冠心病研究所的医学博士Andras Janosi、瑞士苏黎世大学医院的医学博士William Steinbrunn、瑞士巴塞尔大学医学医院的医学博士Matthias Pfisterer、长滩和克利夫兰诊所VA医疗中心的医学博士Robert Detrano 共同创建的。共收集272 个数据实例,剔除残缺数据之后将剩余的270 个实例导入到Excel.CSV 当中,再将数据导入到WEKA 当中。通过WEKA 中的数据处理工具将数据进行离散化,对部分噪声数据进行处理,再使用WEKA 平台的数据挖掘算法对数据进行挖掘。
1.2 属性的选择 本数据集共259 个实例(处理噪声数据后),分为两类、13 个属性。其中类别分为患有冠心病和未患冠心病,本文选择的属性共12 个,分别为年龄、性别、胸痛类型、静息血压、血清胆固醇、空腹血糖是否大于120 mg/dl、静息心电图结果、最大心率、运动诱发的心绞痛、运动相对于休息引起的ST 压抑、运动时ST 段峰值的斜率、心脏缺陷种类。
1.3 算法选择 决策树可看作一个树状预测模型,它通过把实例从根节点排列到某个叶子节点来分类实例,叶子节点即为实例所属的分类。决策树的算法有很多,如ID3、C4.5[3]等。其中WEKA 中的J48 决策树挖掘工具则是是基于C4.5 实现的决策树算法。关联规则挖掘是数据挖掘中重要的一种挖掘方法,其中Apriori 算法是一种非常经典的关联规则挖掘算法。该算法利用层次顺序搜索的循环方法来完成频繁项集的挖掘工作[4]。人工神经网络是一种模仿人脑神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络时通过大量简单的神经元广泛互连形成的复杂的非线性系统,从而达到处理信息的目的。其中在其算法中最具代表性的BP 神经网络算法结构简单,可操作性强,输入输出能模拟任意的非线性关系。目前,BP 神经网络算法已成为人工神经网络算法中应用比较广泛的一种[5]。对于该冠心病数据集,本研究将采用WEKA 中的J48 决策树、关联规则中的Apriori 算法、Multilayer Perceptron算法来进行挖掘。
2 决策树算法构建冠心病诊断预测模型
基于WEKA 中的J48 决策树算法的模型建立以年龄、性别、胸痛类型、静息血压、血清胆固醇、空腹血糖是否大于120 mg/dl、静息心电图结果、最大心率、运动诱发的心绞痛、运动相对于休息引起的ST 压抑、运动时ST 段峰值的斜率、心脏缺陷种类12 个属性为“输入值”,以是否患有冠心病为“可预测值”,来进行决策树分类。使用WEKA3.8.4 中的J48 决策树进行建立模型,在参数方面,将minNumObj 参数调整至5 以增加模型的准确性,其他参数为默认参数设置。最终实验结果的准确率为77.2201%,决策树可视化所呈现出的结果见图1。
通过该结果,可以依据该决策树来帮助医护人员对疑似患有冠心病的患者做出进一步判断。众所周知,决策树在某种程度上来说,可以看作为ifthen 规则的一个集合。以下实验所得到的部分ifthen 规则:①IF 缺陷种类<=3(即不存在缺陷)AND胸痛类型<=3(存在心绞痛现象)THEN 未患有冠心病(P 正确率=90.08%);②IF 缺陷种类>3(存在任意类型缺陷)AND 胸痛类型>3(无任何胸痛症状)THEN 患有冠心病(P 正确率=87.95%)。
3 Apriori 算法得到冠心病诊断的强关联规则
3.1 基于Apriori 算法的预测模型的建立 WEKA 平台的关联规则分析要求所有属性的类别为Nominal,本文的数据集的数据类型全部为数值型,因此需要对数据进行离散化以满足Apriori 算法的要求。对此本文选用WEKA 平台的数据处理工具Discretize(采用默认参数)对数据进行离散化,相对于J48 所选择的12 个输入属性,在Apriori 算法中则选择其中的6 个属性作为输入属性,其原因在于,在初次使用原本的12 个输入属性进行Apriori 算法时所得到的结果并不符合预期,产生较多无意义规则。因此需要对数据属性进行约简,属性约简是在保证系统本身分类能力不变的前提下删除其中冗余的属性,保留起决定作用的核心属性,它是粗糙集理论中最重要的一个部分。通过知识约简,导出问题的决策或分类规则,其对于研究关联规则的知识发现有着极其重要的意义[6]。针对本数据集,本研究采用WEKA 平台上的InfoGainAttributeEval 算法来评估属性的信息增益,使用Ranker 算法作为检索方法对数据进行属性约简。其中信息增益是指信息熵与条件熵的差值,信息熵体现了信息的不确定程度,信息熵越大则代表无序度越大,不确定程度越大,其信息的效用值越小。与此同时条件熵体现了依据该特征分类后的不确定程度,条件熵越小则说明分类后越稳定。因此对于信息增益来说,信息增益越大则说明该特征越重要以及该特征所包含的信息量越大[7]。InfoGainAttributeEval 算法和Ranker 检索算法均使用默认参数,通过以上两种算法的结合,得出了12种属性信息增益的排名以及具体数值,见表1。
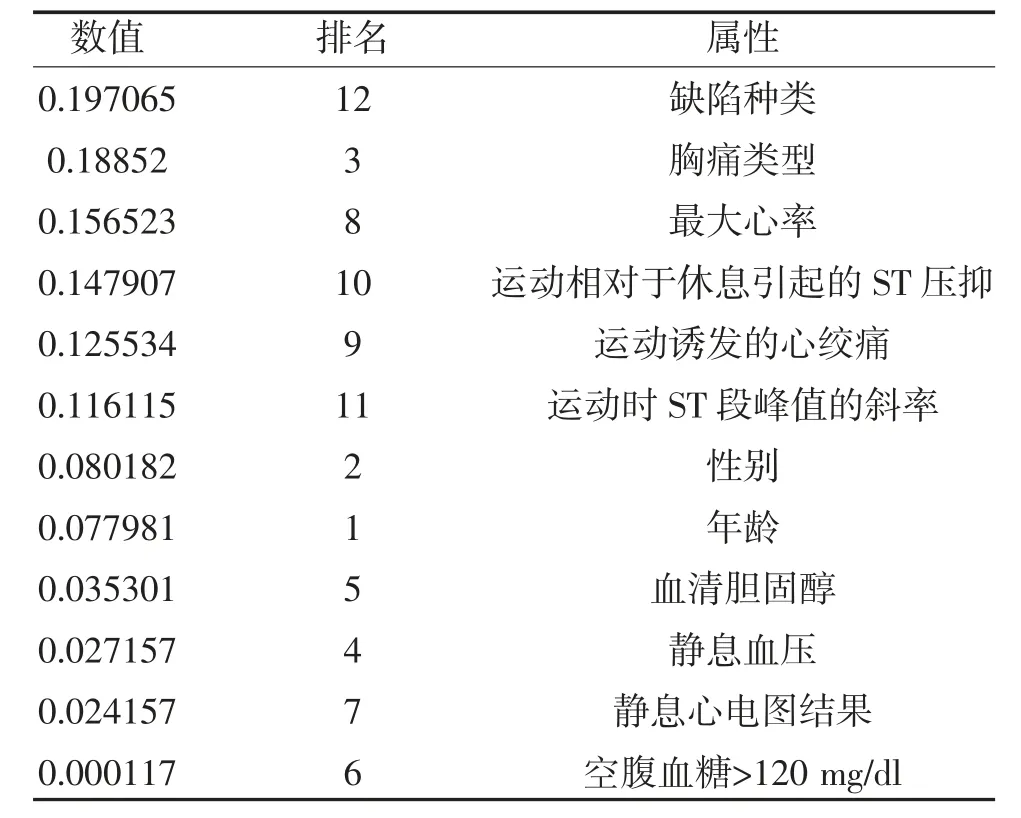
表1 12 种属性信息增益排名及具体数值
信息增益越大则表明该属性越重要以及所包含的信息量更大,所以根据排名,选择前6 个属性(信息增益在0.1 以上的6 个属性)进行关联规则分析。使用WEKA 中的Apriori 算法,以缺陷种类、胸痛类型、最大心率、运动相对于休息引起的ST 压抑、运动诱发的心绞痛、运动时ST 段峰值的斜率6 个属性为“输入值”,以是否患有冠心病为“可预测值”进行关联规则分析。同时,Apriori 算法的参数设置采用默认参数设置。通过Apriori 算法共得到了10 条规则,且从结果评估得知,以上10 条规则的可信度均在94%之上,具有一定的参考价值。以下是部分规则展示:①最大心率=(162.7-175.8)运动相对于休息引起的ST 压抑=(0-0.6)缺陷种类=无生理性缺陷==>未患有冠心病<conf:(0.97)>lift:(1.72)lev:(0.05)[12]conv:(6.76);②最大心率=(162.7-175.8)运动时ST 段峰值的斜率=上坡缺陷种类=无生理性缺陷==>未患有冠心病<conf:(0.97)>lift:(1.71)lev:(0.05)[12]conv:(6.54)。
3.2 结果分析 通过Apriori 算法得到了10 条可信度较高的规则,这10 条规则揭示了一定的规律。以下对部分规则进行解读。
第1 条规则:当患者的最大心率在162.7~175.8、运动相对于休息引起的ST 压抑在0~0.6 且缺陷种类为无生理性缺陷,其有97%的概率未患有冠心病。该条规则说明该类患者有极大的概率并非是冠心病患者,因此该类患者的运动相对于休息引起的ST 压抑可能并非是冠心病所引起的而是由其他原因导致的心肌缺血、心肌病等等[8],需要做进一步的排查。
第二条规则:当患者的最大心率在162.7~175.8、运动时ST 段峰值的斜率为上坡且缺陷种类为无生理性缺陷,其有97%的概率未患有冠心病。该条规则表明该类患者有极大的概率并非冠心病患者,因此该类患者的运动时ST 段峰值的斜率为上坡可能是由其他原因造成的并非冠心病所引起的[8],因此该类患者大概率需要做进一步排查。
4 通过MultilayerPerceptron 算法获取影响冠心病诊断的主要因素
基于MultilayerPerceptron 算法的预测模型的建立 以年龄、性别、胸痛类型、静息血压、血清胆固醇、空腹血糖是否大于120 mg/dl、静息心电图结果、最大心率、运动诱发的心绞痛、运动相对于休息引起的ST 压抑、运动时ST 段峰值的斜率、心脏缺陷种类12 个属性为“输入值”,以是否患有冠心病为“可预测值”,利用WEKA 中的MultilayerPerceptron 算法进行神经网络分析。MultilayerPerceptron 算法的参数选择为默认参数,输出结果见图2,模型的正确率为74.1313%,实验结果见表2、表3。这12 个输入属性中对判断患者是否患有冠心病影响力从高到低排布为胸痛类型>血清胆固醇>运动相对于休息引起的ST 压抑>最大心率>年龄>运动时ST 段峰值的斜率>缺陷种类>性别>空腹血糖值>运动诱发的心绞痛>静息心电图结果>静息血压,见表4。
5 讨论

表2 MultilayerPerceptron 算法Node 结果

表3 12 个属性对于的Node 结果

表4 各因素对患者是否患有冠心病判断结果的影响
冠心病是一种常见的心血管疾病,其检查手段的“金标准”——冠状动脉造影,因其相对高昂的检查费用和较为繁琐的检查要求而受到局限。同时,医学诊断是一项艰巨而复杂的任务。因此通过J48 决策树、关联规则Apriori 算法和MultilayerPerceptron算法来建立一个冠心病预测模型以辅助医护人员的判断。借助J48 决策树所挖掘出的模型,可以帮助医务人员通过一些寻常且相对廉价的检测手段对患者的病情进行一个初步的判断,对评估冠心病的患病风险以及诊断冠心病具有一定的临床指导作用。借助该决策树可以通过一系列的寻常的体检检查(如静息血压、心电图检查、最大心率等)和患者描述(如是否出现心绞痛、是否出现运动诱发的心绞痛现象等)来判断是否有较大的可能患有冠心病以及下一步的诊疗方案。与此同时,根据关联规则分析所得出的十条结论,可以对患者的病情做出一个准确的判断,并且根据该十条规则,可以对患者的病情进行实时的监护,当符合条件的患者出现不符合规则的症状时说明该患者的病情发生了变化,则需要进一步的检查和治疗。这为医护人员更好的把握救助时机有一定的指导意义。同时,通过MultilayerPerceptron 算法得出的12 种输入属性对于冠心病诊断的影响力的大小的量化将帮助医护人员及患者更好的理解冠心病诊断的过程。借助该模型,可以通过一系列基础的体检检查来帮助医护人员对患者的病情有一个基本的判断,以为医护人员的下一步决策提供参考,在一定程度上帮助患者节省了医疗费用。
现如今,医生对冠心病的诊断所依据的是既往的经验以及确切的病变影像图片。想要得到确切的病变影像图片所要支付的医疗费用是相对昂贵的,因此如何通过较为寻常且价格低廉的检查手段对患者的病情进行判断以及帮助医生决策在当前环境下是需要解决的。但是不同因素对于冠心病确诊的影响的大小尚无明确的定量分析,医护人员对于检查结果的评估尚未具体。因此在大量的数据支持下,对影响冠心病诊断的多种因素进行量化讨论是积极的,本次三种数据挖掘手段所得出的模型对该问题进行了讨论,并给出了具有一定参考意义的答案。为了实现基于WEKA 的数据挖掘平台的医学数据整理及冠心病的早期预测诊断,使用J48 决策树、Apriori 算法和MultilayerPerceptron 算法对冠心病数据集进行数据挖掘,并利用多种指标对挖掘结果进行评价,最终得出基于WEKA 数据挖掘平台的冠心病早期预测诊断模型。通过该模型帮助医护人员判断患者是否患有冠心病以及对罹患冠心病的风险的评估,该模型具有一定的医学指导意义。
综上所述,运用数据挖掘的技术手段对冠心病数据集进行发掘,有助于寻找影响冠心病诊断的主要因素,并且帮助医护人员准确把握患者病情的变化情况,为医生的决策提供一份相对可靠的参考。
猜你喜欢
小猕猴智力画刊(2022年3期)2022-03-29 01:09:42
数学小灵通(1-2年级)(2021年4期)2021-06-09 06:26:14
大众投资指南(2021年35期)2021-02-16 01:06:26
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
Coco薇(2017年11期)2018-01-03 20:59:57
电力与能源(2017年6期)2017-05-14 06:19:37
暨南学报(哲学社会科学版)(2016年9期)2017-01-15 13:52:02
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
信息通信技术(2015年6期)2015-12-26 01:16:46
