
应用型大学发展中阶段性关键因素研究
——基于优化粒子滤波方法的分析
2021-01-05 03:09:34夏新颜
管理学刊 2020年6期
夏新颜
(新乡学院,河南 新乡453000)
一、引言
大数据、分析技术、人工智能、机器人、虚拟现实技术等新一代技术的兴起与应用,尤其是基于5G 技术的更高质量、更加流畅便捷的在线教育的兴起,迅速引发了教育领域的重大变革。 传承既有办学优势、应对稀缺教育资源的竞争和迎接科技进步带来的教育教学方式变革等等,已经成为高校面临的严峻挑战。
根据《2019年全国教育事业发展统计公报》,我国高等教育毛入学率为51.6%,标志着我国已经由高等教育大众化阶段进入普及化阶段。在高等教育快速发展过程中,在校生规模急剧扩大,结构性矛盾更加突出,同质化倾向严重,人才培养结构和质量尚不适应经济结构调整和产业升级的要求,高等教育功能释放存在毕业生就业难和就业质量低两大突出问题。 教育部《关于“十三五”时期高等学校设置工作的意见》明确指出,以人才培养定位为基础,我国高等教育总体上可分为研究型、应用型和职业技能型三大类型。 形成不同类型高等学校之间各安其位、相互协调,同类型高等学校之间有序竞争、争创一流的发展格局,是促进我国高等教育科学发展的关键。 其中,通过类型间以及类型内协调竞争推动应用型高校的发展是事关人才素质培养和我国高等教育发展的重要内容。 截至2018年底,全国普通本科院校有1243 所,除“双一流”大学外,大部分高校的定位为应用型,此类院校培养了超过全国高校学生总数3/4 的本科生,为推进我国经济社会发展以及高等教育大众化进程起到了积极的促进作用。 从规模数量角度来看,可以说,没有应用型大学的办学质量就没有我国高等教育的质量,没有应用型大学的强大就没有中国高等教育的强大。
自我国高等教育常态化以来,随着对高等教育认识的不断深化,应用型大学的发展经历了U 字型的发展历程,在当前百年未有之大变局的时代背景下,应用型大学教育成为解决当前一些突出问题的重要抓手,越来越受到政界和学界的重视。 但是,应用型大学相对于研究性大学,存在着资源总量稀缺、内部资源结构同质性较强等突出问题,且在不同的发展阶段中受到的制约因素不尽相同。 其原因在于,随着时间的变化,应用型大学投入产出因素的类型和权重不断变化。 如果能够提前通过分析获取和预测得到对投入产出比影响较大的因素,能够有针对性地将有限的人力和财力进行重点分配,将会对应用型大学的发展起到重要的指导作用。 因此,不同发展阶段影响应用型大学投入产出效率的因素有哪些,以及如何利用好有限投入的关键因素推动应用型大学的高质量发展成为亟待解决的难题。
二、相关研究文献综述
近年来,我国高等教育评估工作在不断适应现代高等教育的多功能、多目标、多类型、多层次的特点,评估主体、评估目的、评估标准和评估模式等呈现多元化发展趋势,但其整体创新能力较弱,理论研究相对滞后。 特别是在新时期我国高等教育分类发展快速推进历程中,关于应用型高校的评价标准和评估标准迟迟未出台,现有评估制度不完善、评估标准相对单一以及产生制度失灵等等都是导致高等学校趋同性、同质化、去特色化的重要因素。
针对以上问题,学界从不同角度对其原因以及对策进行了探讨。 黄彬、陈毅华研究了应用型大学教学质量标准的重要参数和内涵,并将人才培养目标分解在专业教育过程中[1]。张茂林等分析了福建省创新创业教育现状和特征,利用层次分析法构建了评价体系,其中包括政府扶持、企业支持、校园环境建设、师资力量培育、学生创新创业能力培养5 个方面要素的34 个评价指标[2]。 周琬謦依据胜任力理论和应用型本科教育基本理论,构建了应用型大学教师教学能力三维结构模型并对其构成要素进行了内涵解析[3]。祝建鹏基于平衡计分卡及层次分析法,构建了4 个维度25 个指标的非营利性民办高校绩效评价体系[4]。但是,学者们在构建指标体系的研究中普遍存在着分析方法手段单一以致无法解决多个因素之间的相互联系、无法预测随着时间变化不同因素的影响效果与权重发生改变等诸多问题。
为解决以上问题,本文提出基于优化粒子滤波的分析方法,以河南省8 所示范性应用技术类型本科院校为例(为引导和推动高校分类发展,2013年河南省探索实施新建本科院校转型发展工作,2015年河南省启动示范性应用技术类型本科院校建设,入选的10 所办学特色鲜明的新建本科院校,其转型发展过程在较大程度上代表着应用型高校的普遍特点),构建办学绩效综合评价体系。 结合对以上8 所高校2012年—2019年的办学数据分析以及数值拟合,通过定量分析不同因素相互重合的程度以及随着时间的改变各个因素影响权重的变化,对未来发展趋势做出科学预测。
本文首先介绍研究应用型大学投入产出指标常用的主成分分析(PCA)的原理,然后重点介绍粒子滤波方法(PF)的原理和数据分析优点,并将滤波方法进行改进,提出适用于大学投入产出指标分析的优化粒子滤波方法(AWPF),接着分别利用PCA 和AWPF 对河南省8 所应用型高校近7年来的投入产出数据进行处理,并对结论进行分析,最后得出不同发展阶段关键因素的变化,为高校工作重心的转移提供理论依据。
三、投入产出指标分析方法
(一)主成分分析法
主成分分析(PCA)是一种借助于正交变换将分析变量降维的统计方法,它的主要原理是将与其分量相关的原随机向量转化成与其分量不相关的新的随机向量。 主成分分析法的特点是:在损失很少信息的情况下,充分考虑信息的多元化变量,将复杂的因素归结为几个主成分指标,由于每个主成分都是原始成分的线性组合,同时各个主成分之间尽量保证互不相关,并且各个主成分的信息集合不存在交集,因此它保证利用已经确定的主要成分将大部分有用信息准确地反映出来。 主成分分析法优点很多,例如可以消除评估指标之间的相关影响,减少指标选择的工作量,可以在分析问题时根据计算量的需求有选择地舍弃部分主成分,只取方差较大的几个主成分来进行数据分析,从而在不影响评估结果的前提下降低计算工作量,可以尽可能地避免主观因素的影响[5],因而它适用于评价指标较多、指标之间联系紧密相关且主成分指标特征明显的评价体系。 主成分分析法也存在一定的局限性:该方法不具有时变性,只能分析当前已知指标的主要成分和评价结果,不能进行时间域的对比分析。 因此,在应用该方法时,需要确保各评价指标要有明确的数据值;在实际应用中,当主成分分析计算得出的评价结果无法直接反映被评价对象的时候,只能采用其他方法解决问题,例如方案排序[6]。
确定主成分的方法:通过比较方差累计贡献率来选取主成分,通常使得累积贡献率达到85%以上[7]。 具体步骤如下所示:
(1)首先将原始数据进行标准化处理。 因为在所选取的数据中,各个因素的量纲、数量级不一定相同,对数据的标准化处理可以消除原始数据之间量纲上的差异,避免数量级差别较大的影响,即:
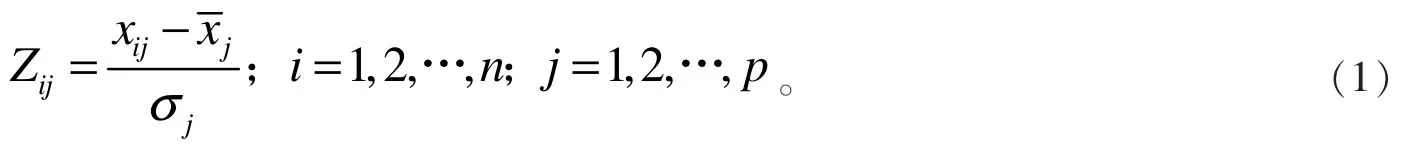
(2)确定标准化数据的相关系数矩阵,计算获得系数矩阵的特征值与特征向量:
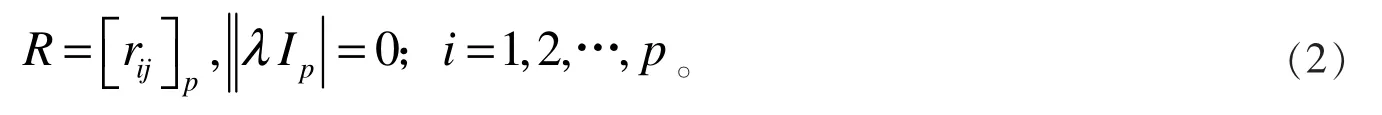
(3)计算方差贡献率与累计贡献率。 第k 个主成分Yk的方差贡献率为:
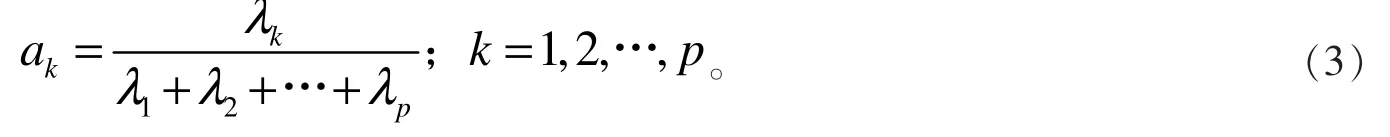
则Y1,Y2,…,Ym的累积贡献率为:

进行主成分分析的主要目的是降维,即减少变量的个数,因此一般情况下当假设主成分为m,原成分为p 时,通常是m<p。 并且m 取值原则为:通常是以所取最小正整数m 使得累计贡献率大于等于85%最为合适,这样既能保证信息量的无损耗传递,又能减少变量数目、降低计算复杂度。
(4)确定主成分,计算各主成分的得分值。 各主成分的得分为:

将计算得到的各主成分得分值作为模型的输入值。
(二)粒子滤波理论及优化粒子滤波算法
1999年,粒子滤波(PF)算法被首次正式提出,在各类多系统融合领域取得广泛的应用,例如:多传感器数据融合、多系统集成中子系统权值的确定。 粒子滤波的基本思想是:利用附带权重的随机样本粒子来计算整体系统的后验概率分布。 无论不确定因素如何干扰,它都能被用于对被估计对象的均值与方差进行计算[8-11]。

其中 δ( x)为狄克拉函数,即x=0 时δ ( x)=1;否则δ ( x)=0。
1.序贯重采样(SIS)及粒子滤波器的实现
粒子滤波是以序贯重采样为基础进行理论研究的[14],并且序贯重采样的基本理论是:在已知k-1 时刻的样本值的前提下,对k 时刻预测值的权值进行估计。 其实现步骤如下:
计算k 时刻权值:

(2)计算归一化权值:

利用粒子滤波器归一化的权值对样本状态和方差进行估计[15]:
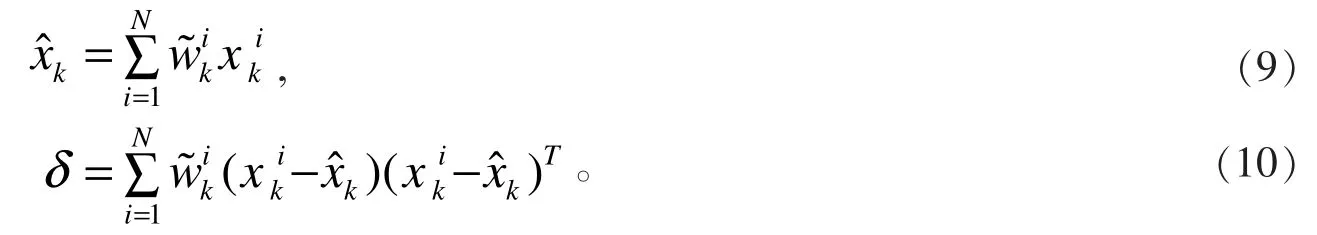
一般情况下从以下三方面对粒子滤波的效果进行评估:
首先,确定先验概率密度函数。 对样本权值计算有直接影响的就是先验概率密度函数,根据预测方程和观察方程的特征计算得到样本的先验概率密度函数。 正态分布、泊松分布和瑞利分布都常常被用来作为样本的先验分布密度函数。 为了比较粒子滤波器设计的性能好坏,本文以正态分布作为先验密度函数,如:

其次,选择随机样本区间和计算样本步长。 采样区间的选择决定了参数估计的计算量,样本的采样空间越大参数估计的计算量就越大。 为了达到相同的估计效果,当采样区间分别为[-20,20]和[-30,30]时,参数估计所需要样本数目是不同的,采样的区间[-30,30]比区间[-20,20]需要的样本数目大得多。 除此之外,影响计算量的另一个因素是选择的计算步长,计算步长越大估计效果越好,但是带来的后果就是计算 复杂程度增加,因此在设计粒子滤波器前需要根据实际的应用场合在满足计算精度的前提下,尽可能减小计算步长。
最后,选择样本门限权值。 在粒子滤波理论中,样本的除去和保留由提前设定的阈值也就是门限值来决定,当样本权值低于门限值的时候,通常认为该样本不再具备继续作为样本的价值。 一般情况下,样本有效容量的计算方法如下:
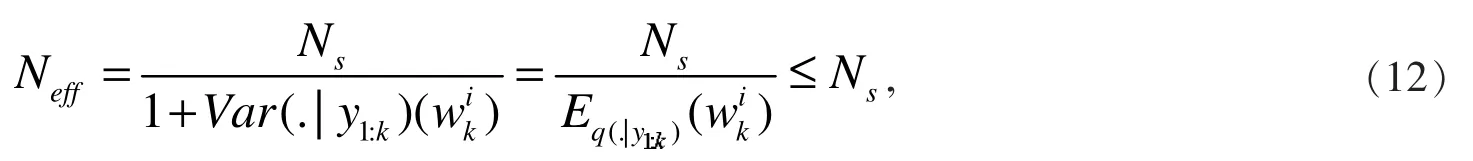
其中

为了便于计算机的数字实现,一般情况下将公式(12)、(13) 简化为:

假设设门限值为 Nthreshold: 当时,该样本不再具有分析的价值,该样本将被清除。 样本门限的设定非常重要,一般情况下观测方程中非线性强度越大,样本门限值越低;根据计算方法不同可分为软阈值门限和硬阈值门限,对于硬阈值门限通常情况下取
2.优化的自适应因子粒子滤波(AWPF)算法
基于传统的粒子滤波(PF)算法,本文提出优化后的自适应因子粒子滤波(AWPF)算法。 根据自适应因子公式,该算法能够根据最近实际发生的结果自适应调整样本之间权值,达到更好的样本权值分配效果。 具体实施步骤如下:
(4)接着根据以下自适应优化公式判断样本是否具有继续被保留的价值:
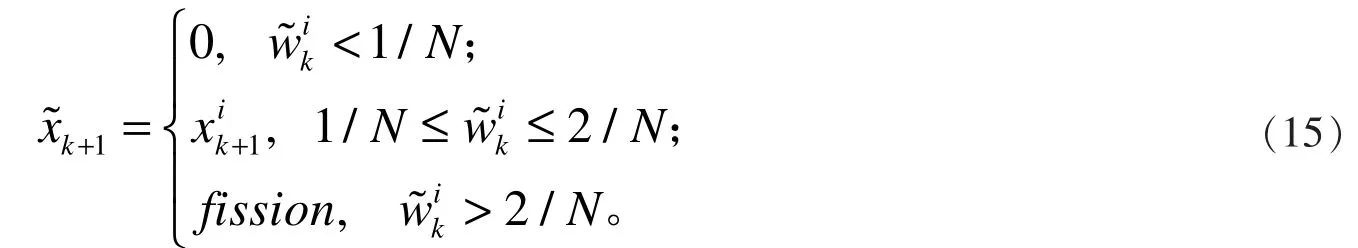
对于不同时刻的采样粒子,重复步骤1,2,3, 4 得到样本估计矩阵与归一化权值矩阵,其中N 表示某时刻的样本数目(由采样区间决定),T 表示采样时间长度(采样时长越长估计效果越好,但是计算量越大)。
为了便于仿真结果的比较和分析,本仿真模型采用参考文献[12]中典型的系统方程模型。 公式如下:
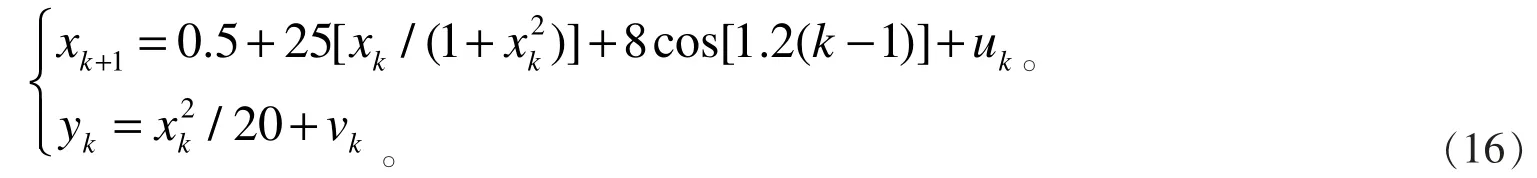
其中xk+1是估计预测的方程,yk是观察确认的方程;uk是系统模型不确定的因素 [本文将高斯噪声ukN(0,10)作为影响系统的不确定因素],vk是计算过程中的误差[本文将高斯噪声vkN(0,1)作为计算过程中的不确定因素];假设采样样本个数为500,计算步长为100。 一般情况下使用下式作为滤波精度的衡量公式,计算值越小,计算精度越高:

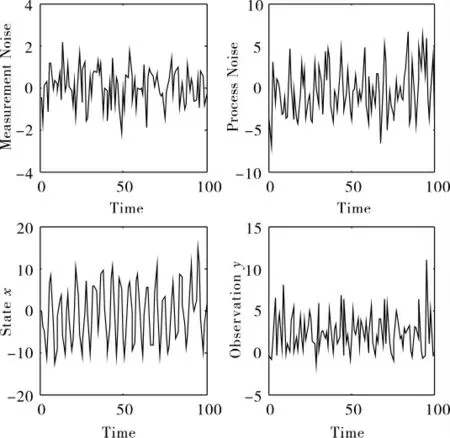
图1 模型与预测值图
图1 中的右上图是系统模型噪声的分布图,左上图为测量噪声的分布图,右下图是观察值的分布图,左下图是预测值的分布图,本文取样本分布区间为[-20,20]。
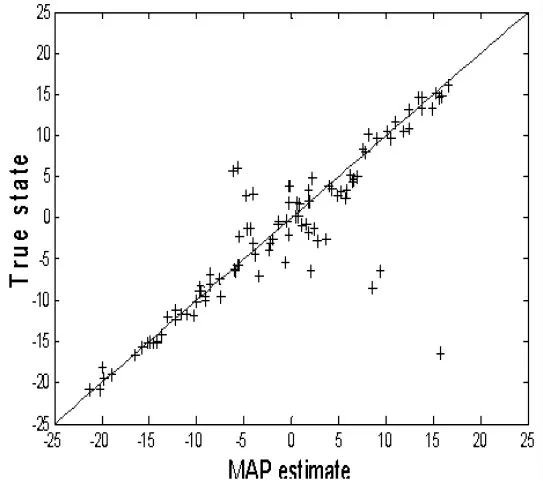
图2 AWPF 估计分布图
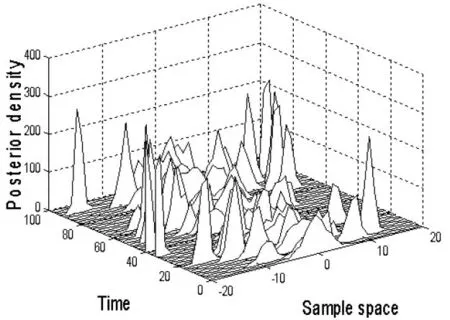
图3 AWPF 估计的瀑布图
图2 中的斜线表示真实值,“+”表示AWPF 滤波后的样本分布的MAP 估计值。 当估计值的分布与斜线重合时,估计的效果最好。从图2 可以看出,AWPF 算法仿真估计值在斜线两侧分布,虽然有个别点偏差很大(粒子滤波允许个别异样样本出现),但整体的分布较为均匀。
图3 是AWPF 滤波后的样本空间的分布图,即样本分布区间和样本估计值的分布密度图,该图的坐标轴分别对应样本分布区间、样本分布密度和样本采样时间。 图中的坐标位置表示特定的样本区间和样本采样时间下样本的密度分布值。滤波效果评判的标准是:样本在特定区域分布越集中,粒子滤波处理后的权重分布效果就越好。 从图3 可以看出,AWPF 滤波的效果较好,样本分布相对集中。
3.优化后AWPF 与传统粒子滤波的比较

表1 三种粒子滤波方法比较
表1 是三种滤波方法的估计精度(MAP 和PME 是两种不同的评估方法,其数值越小效果越好)和运行时间的比较,可以得出结论:在选取特定的模型仿真条件下,无论对于MAP 指标还是PME 指标,AWPF 处理效果都是最好的; 并且对于相同的粒子滤波器,MAP 又比PME 估计的效果好;AWPF 运行时间并不是最快的,但是对总体为2 秒的计算时间而言,0.2 秒的延迟并不影响整体的执行效率。 因此综合比较仿真结果,在PF、BPF、AWPF 中,AWPF 执行效果最佳。
四、实验数据分析
(一)办学绩效综合评价体系构建
办学绩效评价是一个系统的、具有复杂体系的工程,影响因素多,相互关联性强,数据采集难度大,数据量纲不统一。 为了使绩效评价相对客观、全面、真实反映办学资源的绩效,根据评估原则,构建基于部分应用型高校办学绩效综合评价体系。选取投入指标、产出指标等2 大类指标体系,其中投入指标、产出指标各设置12 个指标体系,重点选取8 所河南省示范性应用技术类型本科院校2012年—2019年的办学数据。数据来源于各个高校的本科教学质量报告,本文引用数据在这8 所学校法规处网站或者教学评估中心网站公开。
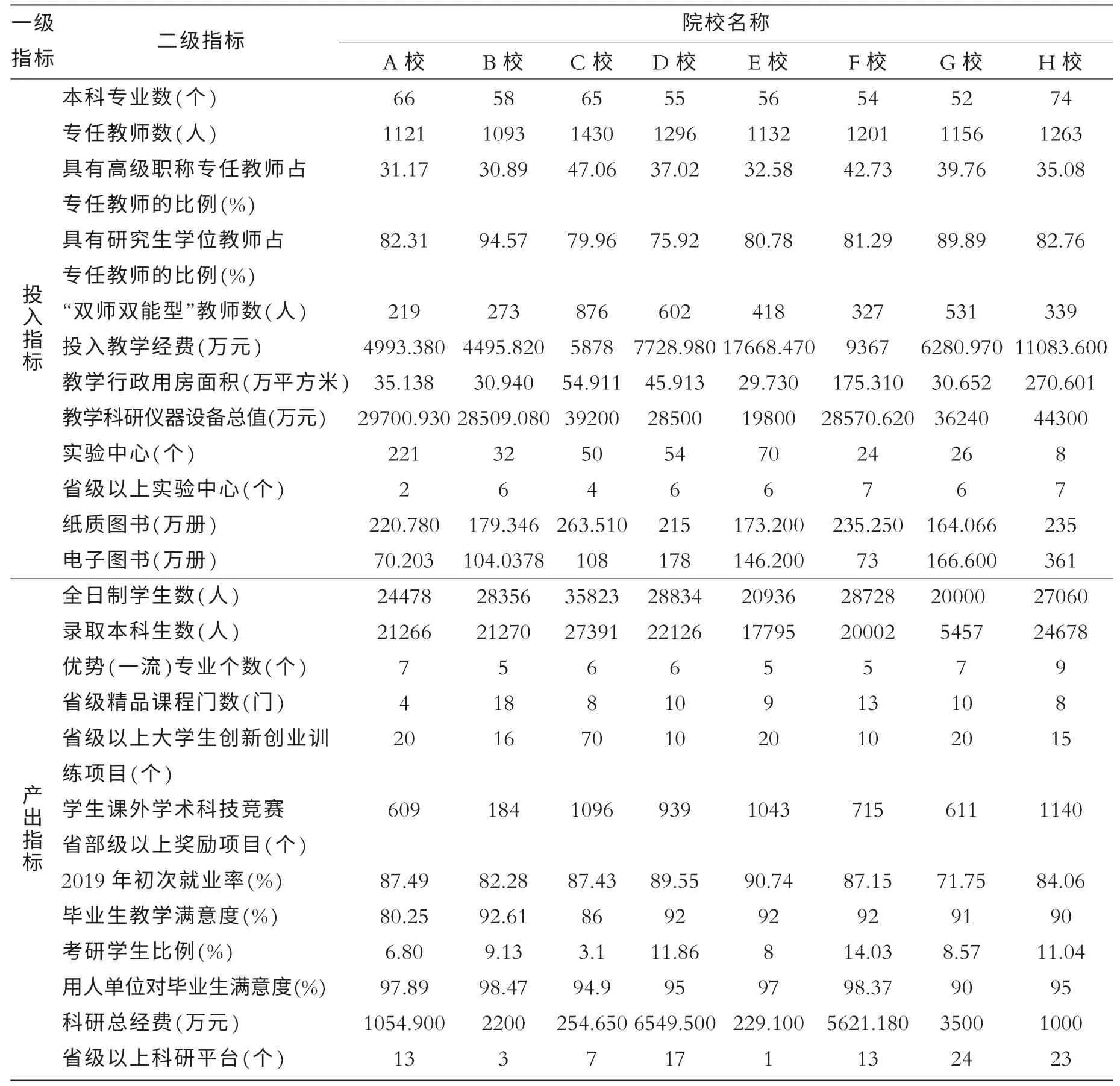
表2 部分应用型高校办学绩效综合评价体系
(二)主成分分析法数据分析
根据表2 的数据,运用主成分分析法,可得到如下结论:
其一,8 所学校投入指标主成分计算总得分分别为-0.7335、-0.3818、0.4316、-0.2250、 -0.8107、-0.1009、-0.1067、1.9270,对应学校分别为A 校、B 校、C 校、D 校、E 校、F 校、G 校、H 校。 依据分值从高到低排序为:H 校、C 校、F 校、G 校、D 校、B 校、A 校、C 校。
其二,8 所学校产出指标主成分计算总得分分别为0.0849、 -0.6100、-1.3410、0.2436、-0.5391、-0.0026、1.3550、0.8093,对应学校分别为A 校、B 校、C 校、D 校、E 校、F 校、G 校、H 校。 依据分值从高到低排序为:G校、H 校、D 校、A 校、F 校、E 校、B 校、C 校。
其三,8 所学校中D 校和F 校为行业院校,其他均为地方院校。从模型结果可以看出,D 校和F 校两个学校投入指标分别排第五名、第三名,产出指标分别排第三名、第五名。因此,虽然行业院校转型发展的基础好,但是和一般院校相比,投入产出指标因素均没有明显优势。
(三)优化的自适应因子粒子滤波算法数据分析
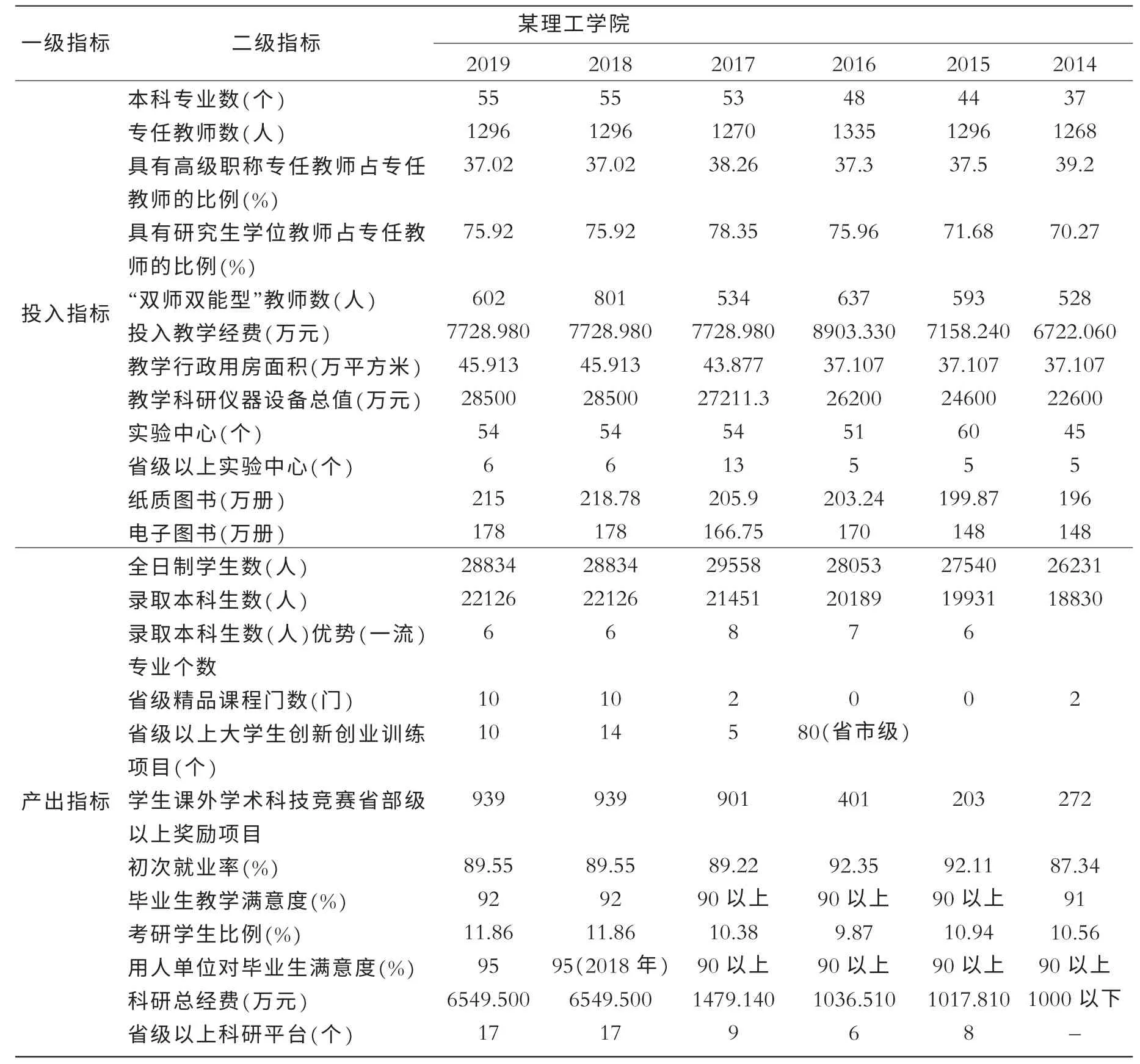
表3 某高校2014年—2019年的投入产出数据
将表3 的12 个投入指标数据分别代入公式(7)至(16),根据自适应因子粒子滤波法可以得到表4、表5所示的计算结果。
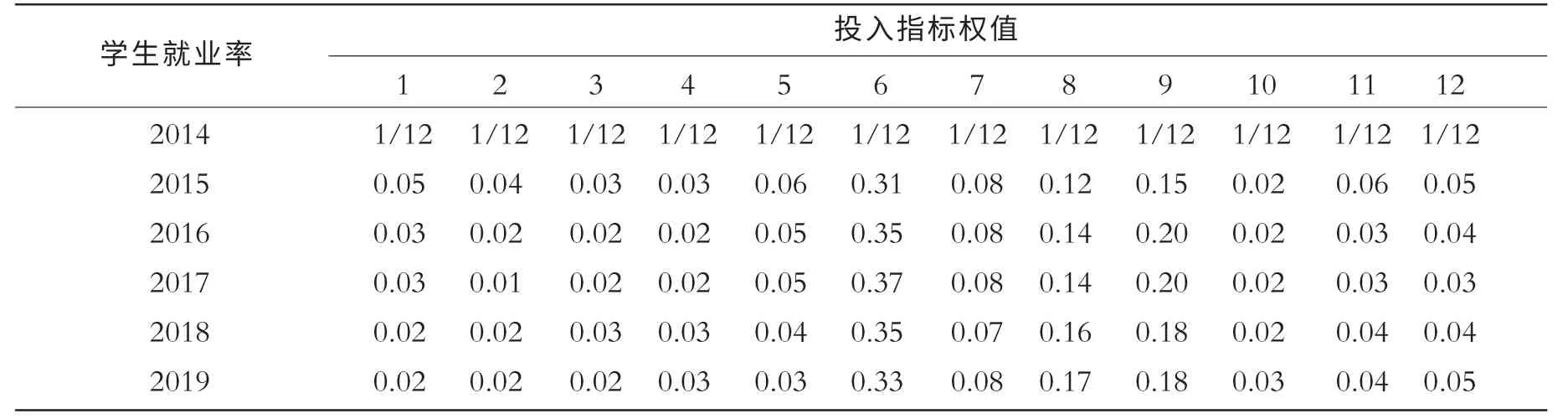
表4 投入指标对学生就业影响力变化表
表4 是针对产出指标之一的学生就业率的分析。 主要分析12 项投入指标每年对就业率影响的变化,即在高校不同发展阶段的影响力变化。 结果如下:2014年该校的投入指标全权假设为平均分配,即12 项指标平均分配,都为1/12,但是通过2015年的投入产出反馈计算得到12 项指标权值发生了变化,并且主要权值集中在学校的办学经费投入、教学科研仪器设备总值和实验中心这三项投入指标上,并且2016—2019 基本保持如此的分配区间,变化不大;但是随着时间的发展,办学经费对学生就业率的影响稍微减小,说明在学校发展阶段初期,学生就业率对学校的投入依赖性很大,但是随着学校的发展,学生就业率对投入的依赖度逐渐向其他投入指标均衡。
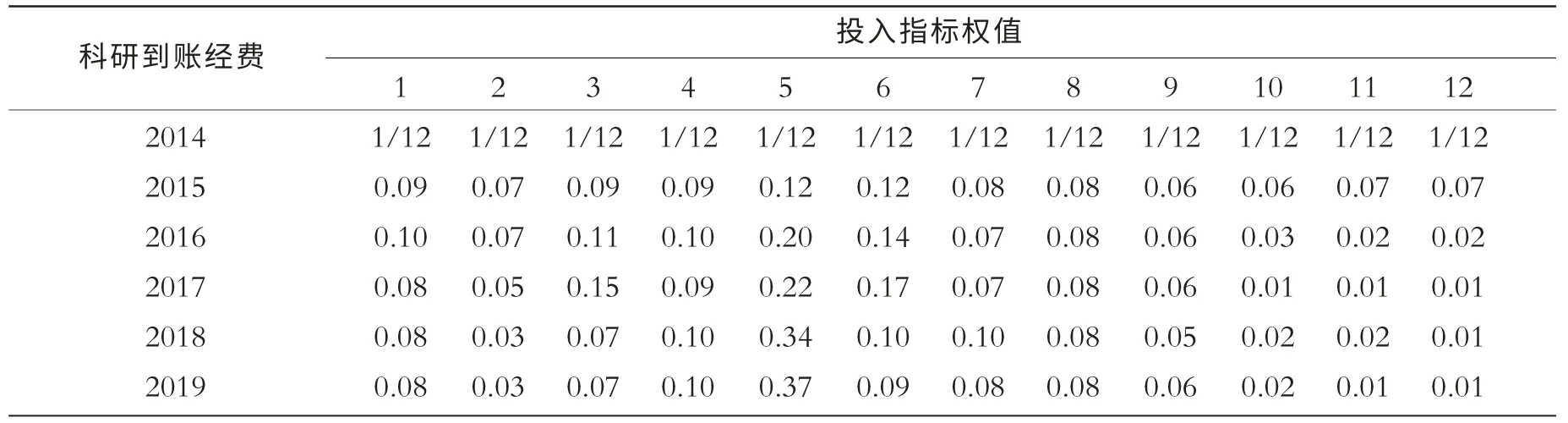
表5 投入指标对科研到账经费影响力变化表
表5 是针对产出指标科研到账经费的分析。 分析结果如下:依旧假设2014年投入指标权值平均分配,都为1/12;但是出乎意料的是通过2015—2019 的迭代反馈运算可知,“双师双能型”教师对科研到账经费影响力逐渐增加,而投入教学经费这项指标对科研到账经费的影响力并没有出现这种情况。 分析原因有两个:第一,应用型高校的经费来源主要是行业横向课题,因此“双师双能型”教师是完成此类项目的主体;第二,8所河南省示范性应用技术类型本科院校本身带有课题加入学校,增加了高校的科研经费。 同时通过权值的变化可知,具有高级职称专任教师占专任教师的比例和具有研究生学位教师占专任教师的比例对科研到账经费的增加也有一定的影响力,而图书的影响力几乎可以忽略。
五、结论
本文针对应用型高校的发展评价引入了粒子滤波的分析方法,并且对传统粒子滤波方法进行优化,提出了自适应因子粒子滤波方法,即通过后观察值反馈计算样本的权重,结合先验和后验观察值确定样本权值。将8 所河南省示范性应用技术类型本科院校作为主要研究对象,将12 个投入指标作为样本,分别利用主成分分析和优化粒子滤波两种方法对投入和产出进行分析;对比两种分析方法发现,主成分分析法主要应用于对高校综合数据的评价,即对比各个学校的数据排名,而优化粒子滤波算法更适合于针对某个高校做具体分析,计算不同发展阶段影响产出值的关键因素的变化,同时具有产出预测的能力,能为学校的发展提供更有力的规划理论工具。
同时,通过优化粒子滤波算法对8 所应用型高校的数据分析,获得了投入产出的变化分析结果。 例如:针对就业率而言,学校起步阶段依赖于办学经费投入、教学科研仪器设备总值和实验中心这三项指标,但是随着学校的发展,学校经费投入退出主要影响指标,学校可以根据影响因素的变化有针对性地进行工作方向的调整。 但是,鉴于优化粒子滤波模型仅仅能够对当前数据进行分析,为学校人力、物力和财力投入的短期分配提供依据,还不能够做到对投入产出因素进行长期的预测,因此,未来需要专家学者开展持续的算法和数据处理上的持续优化。
猜你喜欢
成都信息工程大学学报(2022年3期)2022-07-21 09:35:04
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
沈阳师范大学学报(教育科学版)(2021年2期)2021-02-01 07:00:46
测控技术(2018年10期)2018-11-25 09:35:54
浙江工业大学学报(2017年5期)2018-01-22 02:03:46
自动化学报(2017年7期)2017-04-18 13:41:02
空间控制技术与应用(2015年3期)2015-06-05 14:30:31
遥测遥控(2015年2期)2015-04-23 08:15:18
电子设计工程(2014年20期)2014-02-27 12:01:00
物理与工程(2014年4期)2014-02-27 11:23:08
