
Bi-LSTM+CRF的网络空间安全领域命名实体的识别
2021-01-04 00:59廉龙颖
黑龙江科技大学学报 2020年6期
廉龙颖
(黑龙江科技大学 计算机与信息工程学院, 哈尔滨 150022)
0 引 言
随着信息革命的不断演进,网络空间已成为继陆、海、空、天之后的第五大空间[1]。在网络空间里,安全问题的内涵和外延在不断扩大,针对网络空间安全面临的严峻形势,威胁情报技术应运而生。威胁情报是关于IT或信息资产所面临的已经存在或正在显露的威胁的循证知识[2]。这些知识通常存在于科学文献、安全站点、黑客论坛等非结构化的文本数据中,且具有海量化、碎片化、分散性和隐形关联性等特征。因此,如何从文本数据中抽取出网络空间安全的威胁主体、攻击方法、防御措施等内容是情报分析研究的热点问题。
网络空间安全知识图谱可以从多维角度组织海量信息和知识,并能可视化呈现知识及其关系,为威胁情报隐形关联分析提供了可能性。网络空间安全知识图谱构建主要包括命名实体识别、实体链接以及关系抽取等,其中命名实体识别是构建知识图谱的首要工作。网络空间安全实体识别是一种特定领域的命名实体识别,主要工作是识别网络空间安全文本数据中的对象、方法和事件等不同类型的实体。常用的命名实体识别方法有基于规则的方法[3]、基于统计的方法[4]和基于神经网络的方法[5]。基于规则的方法是早期命名实体识别中最有效的方式,依赖手工制定规则和权重赋值,通过实体与规则的相符情况来进行实体识别,但存在可移植性差、维护困难等问题。基于统计的方法是基于人工标注的语料,通过序列标注进行命名实体识别,主流的方法有隐马尔可夫模型[6]、最大熵[7]、支持向量机[8]和条件随机场[9]等,这些方法对语料库的依赖较大。基于神经网络的方法具有更低的特征依赖性和更密的泛化性,在命名实体识别中得到广泛应用,如循环神经网络RNN[10]、长短时记忆网络LSTM[11]、卷积神经网络CNN[12]等。近年来,利用双向LSTM模型结合CRF模型进行命名实体识别达到了很好的效果。Huang等[13]首次利用此模型进行命名实体识别。马建霞等[14]从科学文献中抽取生态治理技术命名实体。张若彬等[15]针对博客和安全公告数据识别安全漏洞命名实体。
由于网络空间安全领域缺乏大规模的专业语料库,通用语料库训练的模型在进行网络空间安全命名实体识别时效果不佳,不能准确地识别出一些网络空间安全术语,如DDoS、蠕虫等。彭嘉毅等[16]使用一种深度主动学习的方法对信息安全领域英文命名实体进行识别,秦娅等[17]基于深度神经网络进行网络安全实体识别。经统计发现,针对网络空间安全领域命名实体识别研究工作较少,且多数是基于英文文本的,并缺少对本体的描述。在中文环境下,网络空间安全命名实体识别主要存在难点:网络空间安全概念多且关系复杂,安全事件不同实体类型也可能不同,例如扫描可作为攻击方法也可成为防御措施。新实体不断出现,例如漏洞名称、病毒名称等。长度不确定且存在嵌套,例如蠕虫病毒Worm_Vobfus。针对上述难点,笔者提出基于Bi-LSTM模型与CRF模型相结合的命名实体识别方法,通过Bi-LSTM进行特征提取,使用CRF进行实体标注,主要识别网络空间安全领域中12类命名实体,以提高识别效果。
1 命名实体识别
网络空间安全命名实体识别框架如图1所示,主要包括预处理模块和实体标注模块。
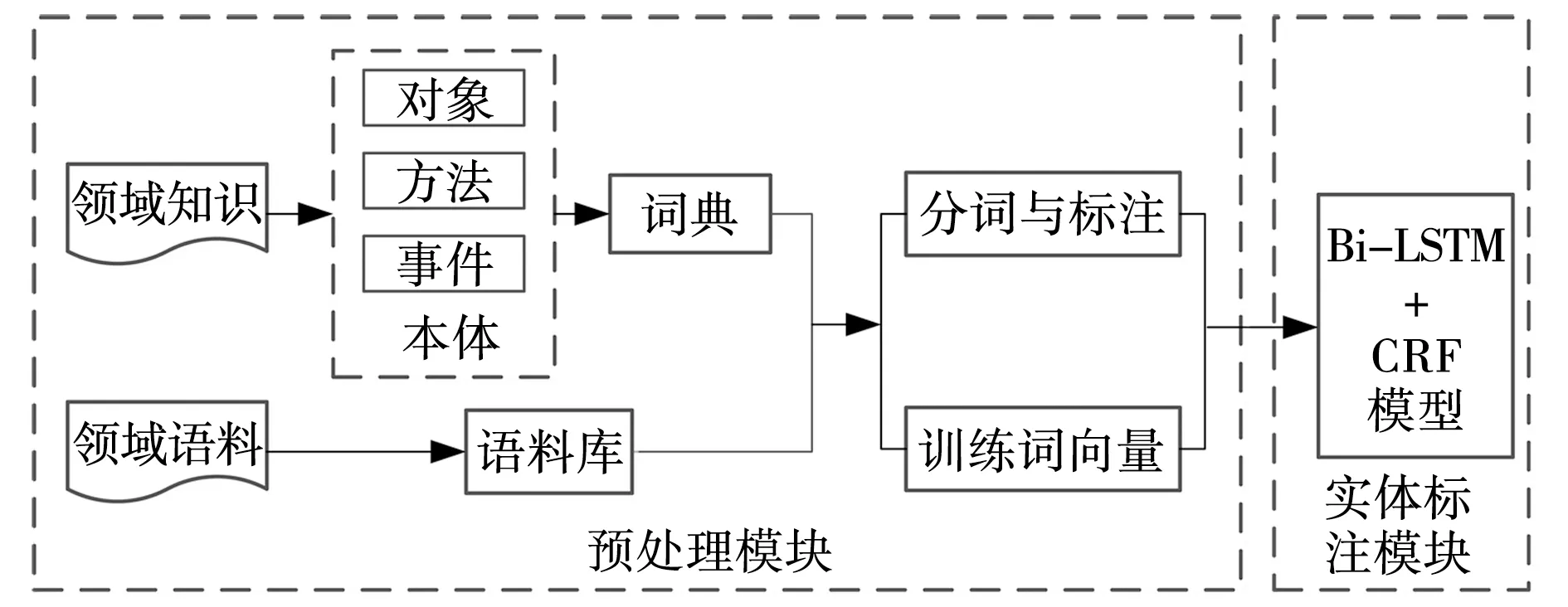
图1 网络空间安全命名实体识别框架 Fig. 1 Named entity recognition framework for cyberspace security
预处理模块主要包括语料预处理、词向量训练和序列标注。首先对网络空间安全领域的命名实体进行分析,抽象出本体模型,根据本体通过人工编写的方式构建领域词典,用于分词;构建网络空间安全语料库,使用Jieba对语料中的句子进行分词与词性标注,然后通过开源工具word2vec的CBOW模型进行词向量训练,得到词向量文件,将词性标注后的文本数据采用BIO标注法进行序列标注。
实体标注模块主要将测试语料放入模型进行训练和实体识别。基于Bi-LSTM+CRF构建网络空间安全命名实体识别模型,标注后的文本数据和词向量作为输入训练实体识别模型,Bi-LSTM模型用于特征提取,CRF模型用于实体标注。
1.1 预处理模块
在预处理模块中,使用网络空间安全领域词典进行分词,可以获得更高质量的word2vec词向量,从而提升实体识别效果。因此,对网络空间安全命名实体分析并抽象出本体模型,根据本体构建领域词典。本体是被共享的概念化的一个形式化的规格说明,是知识图谱的一种抽象表达方式,用来描述被广泛认可的概念与概念之间的关系[18]。利用网络空间安全领域知识对概念进行抽取构建本体,以明确学科知识图谱应用的范围。本文根据《信息安全技术网络安全威胁信息格式规范》定义网络空间安全包含对象、方法和事件等三个本体。对象指网络安全事件的主体,方法指攻防技术术语,事件指具体技术指标。
知识图谱中的实体是在本体的基础上进行扩充的,是指与网络空间安全相关的各类命名实体的统称,本文分析了科技文献,安全网站等,确定了12个网络空间安全实体类型。(1)威胁主体:指网络空间安全事件的人员,如“黑客”、“网络管理员”。(2)攻击目标:指网络中的资产,如“数据流”、“端口”。(3)攻击方法:指安全事件中的攻击技术,如“DDoS”、“中间人攻击”。(4)防御措施:指安全事件中的防御技术,如“防火墙”、“身份认证”。(5)软件:即软件名称,如“PortScanner”、“L0phtcrack”。(6)硬件:即硬件类型,如“路由器”、“主机”。(7)系统:即系统类型,如“Unix”、“Windows”。(8)协议:即协议名称,如“ARP”、“ICMP”。(9)算法:即算法名称,如“DES”、“RSA”。(10)语言:即编程语言,如“VB”、“C语言”。(11)病毒:即病毒名称,如“黑色星期五”、“Worm_Vobfus”。(12)漏洞:即漏洞类型或名称,如“缓冲区溢出漏洞”、“dll劫持漏洞”。
本文定义实体体系:O={per,net}表示威胁主体和攻击目标,E={soft,hard,sys,prot,alg,prog,vir,vul}表示软件、硬件、系统、协议、算法、语言、病毒和漏洞,M={att,def}表示攻击方法和防御措施。通过对语料进行人工分析,编写网络空间安全领域词典,词典中共881个词条,每个词条代表一个命名实体,具体数目如表1所示。
文本向量化就是将文本表示成一系列能够表达文本语义的向量。word2vec是一个将词表征为实数值向量的开源工具,采用的模型有CBOW和Skip-Gram两种。CBOW是使用周边词的词向量去预测当前的词向量,而Skip-Gram正好相反,是输入当前词的词向量去预测周边词的词向量。
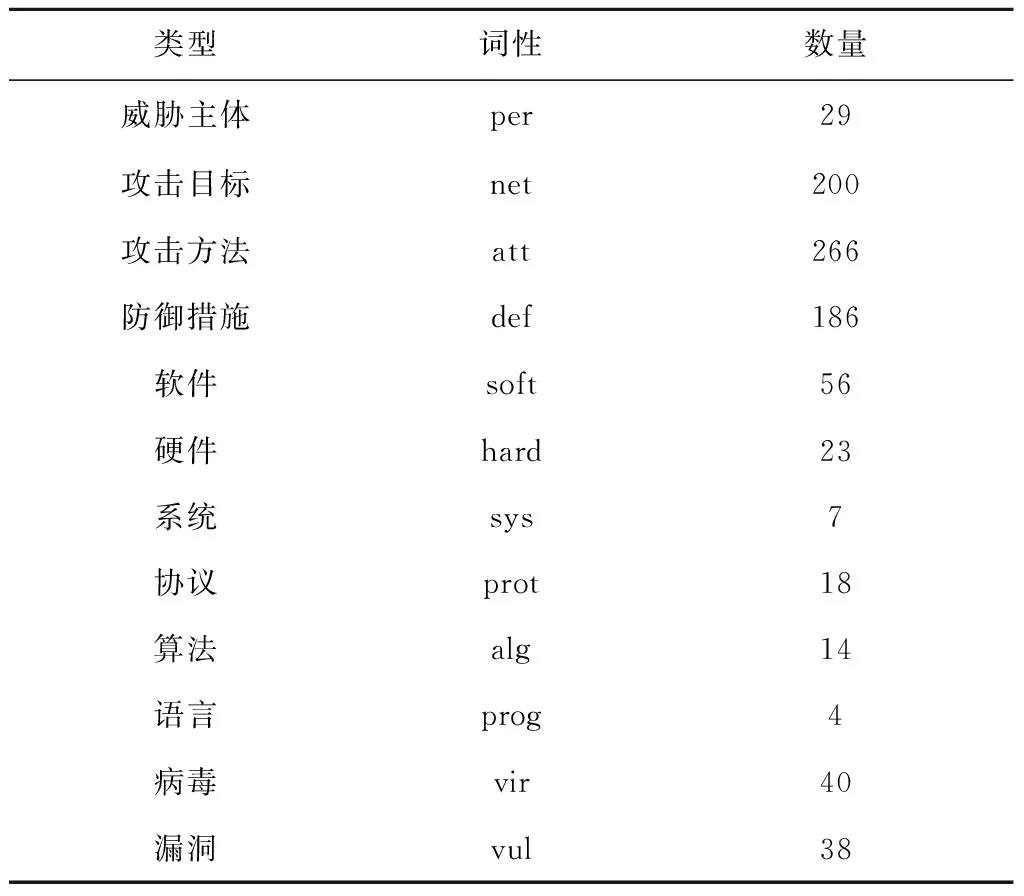
表1 网络空间安全领域词典数目
在预处理模块中,将网络空间安全语料使用Jieba分词后,通过word2vec的CBOW模型进行训练,每个数值维度设为100维,上下文窗口大小为3,迭代次数设置为10次,得到词向量文件,词向量文件中包括18 719个中文和英文词以及它们的向量数值,词向量中的每一维表示一个特征。
词性是词汇的基本语法属性,词性标注是在给定句子中判定每个词的语法范畴,确定词性并加以标注的过程。Jieba是中文分词的常用工具,具有分词、词性标注等功能。在Jieba中使用自定义的网络空间安全词典对语料进行词性标注得到标注后的文本数据,针对网络空间安全中12类实体,采用BIO标注模式[19]对文本数据进行序列标注,B代表实体开头字符,I代表实体中间字符,O代表其他非实体字符。即B-per和I-per代表威胁主体的开头与中间,B-net和I-net代表攻击目标的开头与中间,B-att和I-att代表攻击方法的开头与中间,B-def和I-def代表防御措施的开头与中间,B-soft和I-soft代表软件的开头与中间,B-hard和I-hard代表硬件的开头与中间,B-sys和I-sys代表操作系统的开头与中间,B-prot和I-prot代表网络协议的开头与中间,B-alg和I-alg代表算法的开头与中间,B-prog和I-prog代表编程语言的开头与中间,B-vir和I-vir代表病毒名称的开头与中间,B-vul和I-vul代表安全漏洞的开头与中间,O代表非实体。序列标注样例如表2所示。
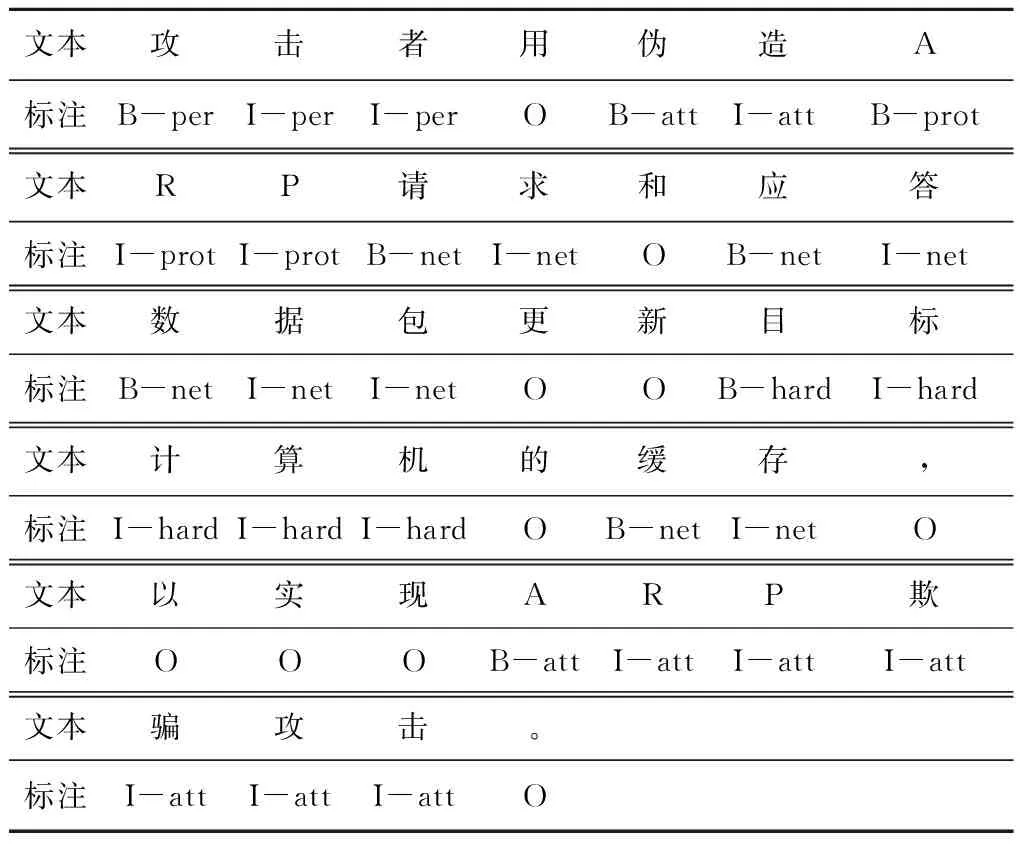
表2 序列标注样例
1.2 实体标注模块
网络空间安全领域语料经过预处理后,输入实体标注模块进行模型训练。实体标注模块使用Bi-LSTM+CRF模型结构,包括Bi-LSTM层和CRF层。Bi-LSTM层主要进行特征提取,CRF层主要进行命名实体标注。首先将已标注的领域词典输入到模型中,在加载训练集与测试集后,使用Bi-LSTM对文本中词向量序列获得特征并存储在输出的数值向量中,并作为CRF模型处理tag之间的依赖关系信息,选择出预测序列完成实体识别。模型训练后,重新加载模型,将预测文本输入,最终识别出文本中的网络空间安全实体。
1.2.1 Bi-LSTM层
长短时记忆网络LSTM由Hochreiter等[20]于1997年提出,是一种特定形式的循环神经网络。LSTM是链式结构的,输入层输入xt,隐藏层输出ht,每个LSTM记忆单元都由输入门it、输出门ot、遗忘门ft和记忆控制器ct等四部分组成。LSTM记忆单元如图2所示。
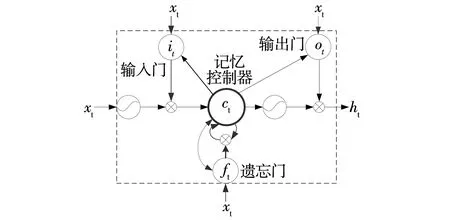
图2 LSTM记忆单元结构Fig. 2 Structure of LSTM memory unit
LSTM只能访问过去的上下文信息,但未来的上下文信息对网络空间安全实体特征提取同样重要,因此,采用双向LSTM即Bi-LSTM[21]神经网络模型。Bi-LSTM模型结构如图3所示,对输入的序列分别采用顺序和逆序计算获得两个隐藏层输出向量,两个隐藏层通过拼接获得最终的隐藏层输出向量。
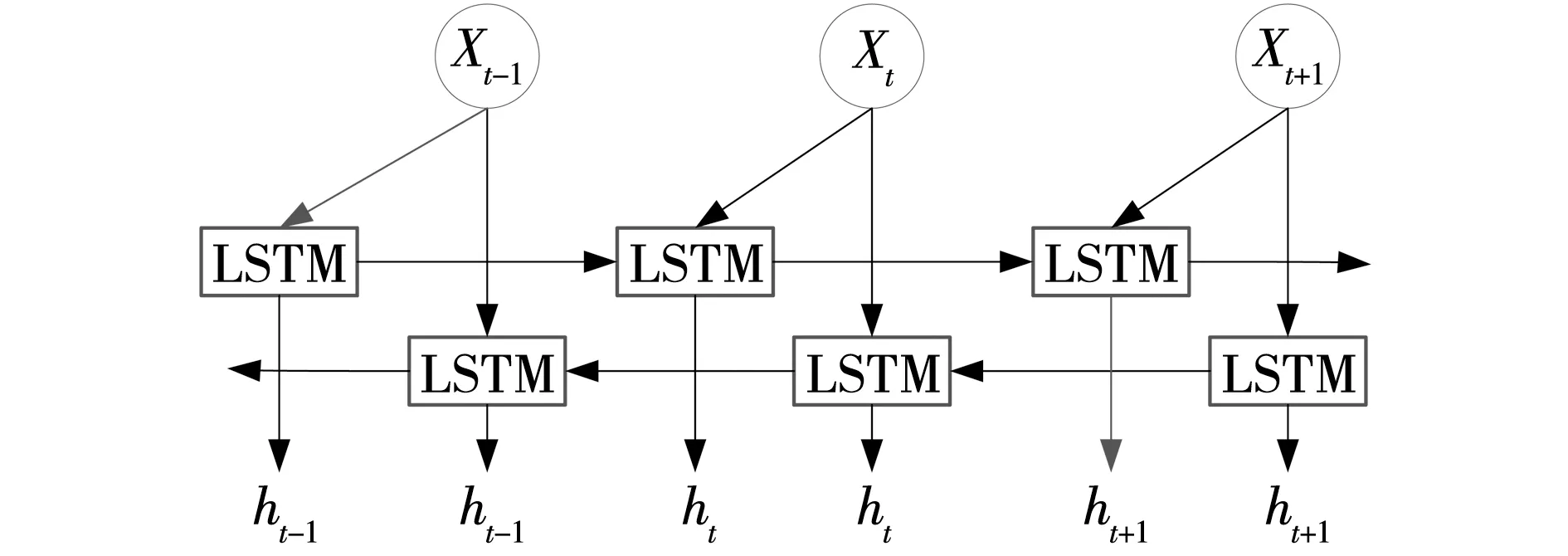
图3 Bi-LSTM模型结构Fig. 3 Structure of Bi-LSTM model
本文将预处理后的网络空间安全领域非结构化文本中的字符向量序列作为Bi-LSTM层输入,正向LSTM将输入序列表示成ht,再利用逆向的LSTM将输入序列表示成ht’,h=ht+ht’的拼接作为最终的结果,得到提取出的特征,并将特征表示进行Softmax分类,从而输出每个字的最终标签,为了利用已标注过的信息,将每个字表示的k维向量进行拼接并作为输入到CRF层的特征矩阵。
1.2.2 CRF层
2001年Lafferty等[22]提出了条件随机场,它是一种用来标记和切分序列化数据的统计模型,即在给定观测序列下,计算输出标记序列的条件概率分布。线性结构是最常用的CRF结构,文中使用线性链CRF。令X={X1,X2,…,Xn}为线性链表示的输入观测序列,Y={Y1,Y2,…,Yn}为线性链表示的输出标记序列,则条件概率分布P(Y|X)构成条件随机场,且满足马尔可夫性,则P(Y|X)为线性链的CRF。如图4所示,线性链CRF是一个无向图,图中的输出标记序列形成了一条马尔可夫链,线性链CRF依赖于当前状态的周围结点状态。在得到条件概率后,使用Veterbi算法进行最大可能序列路径求解,作为最终的网络空间安全命名实体识别的标注结果。
CRF层可以有效的考虑上下文的依赖关系,在Bi-LSTM层后加上CRF层,使得实体识别模型在结合上下文信息的同时可以有效考虑标签前后的依赖关系。利用训练好的模型,对语料进行实体标注,在CRF层引入转移矩阵作为参数,通过最大似然估计作为真实标记序列的概率来更新Bi-LSTM中的参数与CRF中转移概率矩阵A,标注实体类型,最终输出标注结果,从而完成网络空间安全命名实体识别。

图4 线性链CRFFig. 4 Linear chain CRF
2 实 验
实验所用的语料主要来自于科学文献、网络空间安全书籍、安全技术站点和漏洞库等,共计5 000条语句,将标注好的语料按7∶2∶1的比例分成训练集、验证集和测试集。
2.1 命名实体识别
在开源平台TensorFlow中使用Python语言,利用Bi-LSTM+CRF构建实体识别模型。首先对模型参数进行初始化,模型中共设置6类参数,其中隐藏单元数量hidden_size设置为512,单元数num_units设置为256,学习率learning_rate设置为0.001,梯度裁剪clip设置为5,迭代次数num_epochs设置为100,dropout_rate设置为0.5;然后通过运行Bi-LSTM模型前向和后向传递进行特征提取;再通过运行CRF模型前向和后向传递来计算输出状态;接着通过Bi-LSTM模型的反向传递重新更新模型参数。图5为模型训练过程。
2.2 方法
使用准确率P、召回率R和调和平均值F对命名实体识别指标进行实验结果评价,具公式为:
(1)
(2)
(3)
式中:N1——识别出的正确的网络空间安全实体数量;
N2——识别出的所有网络空间安全实体数量;
N——所有标注的网络空间安全实体数量。

图5 模型训练过程Fig. 5 Model training process
2.3 结果及分析
方法1仅使用CRF模型,它是对比实验的基线。方法2是秦娅[23]等提出的优良方法,在基线的基础上,利用基于规则的方法,对候选网络安全实体进行修正。方法3是文中提出的方法,使用Bi-LSTM模型提取特征向量,再经过CRF模型进行实体标注。实验结果如表3所示,具体评价指标包括准确率、召回率和F值。
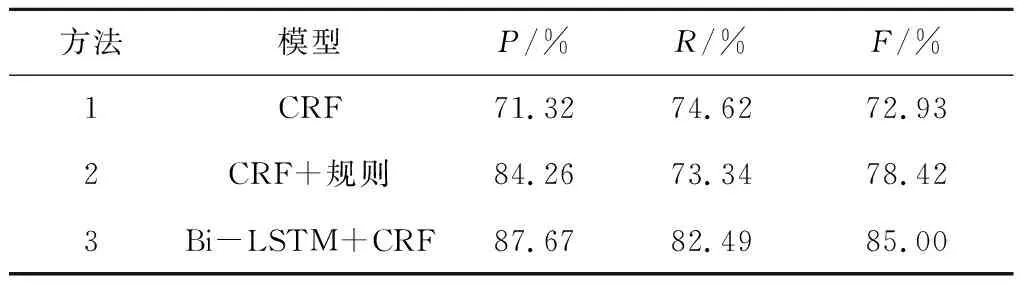
表3 实验结果
从表3可以看出,第1种方法CRF模型可用于命名实体识别,但仅使用CRF模型在非结构化网络空间安全文本中识别的F值为72.93%,识别效果不佳。第2种方法采用CRF与规则相结合识别网络安全实体时,由于添加了前缀“漏洞”、 “WooYun”和“注入”等规则对识别结果进行纠正,识别准确率和F值都有所提高,而召回率相对削弱,但差距不大,主要原因是手动添加规则并且训练语料库较小。第3种方法采用文中提出的Bi-LSTM+CRF模型,相比方法1与方法2评价值都有所提高,说明文中使用领域词典进行分词能够有效提升命名实体识别效果。在实验中发现,识别漏洞与病毒实体时的准确率较低,主要是因为两类实体存在中英文混合、大小写混合且边界模糊等问题,对整体识别效果有一定影响。对比三种方法的评价值,文中提出的方法结合了CRF模型与Bi-LSTM模型的优点,在网络空间安全命名实体识别中具有更好的表现,整体识别性能较高。
3 结束语
设计并实现了基于Bi-LSTM+CRF模型抽取中文语料中12类网络空间安全命名实体的方法。该方法首先进行语料预处理,通过人工构建领域词典进行分词,将标注的文本转成词向量文件,经过Bi-LSTM模型处理提取特征向量,再经过CRF模型进行实体标注,从而识别网络空间安全命名实体,通过实验对比验证了模型的有效性。该研究识别出的命名实体可用于网络空间安全知识图谱构建 ,对威胁情报的隐形关联分析工作有重要意义。在后续研究中,将扩大网络空间安全语料库,进一步挖掘实体扩充领域词典,通过提取词的字符级特征,提升模型训练的整体性能,从而提升实体识别效果。
猜你喜欢
通信技术(2021年12期)2022-01-25
中学生数理化(高中版.高考理化)(2021年2期)2021-03-19
军事运筹与系统工程(2019年1期)2019-11-16
网络空间安全(2019年12期)2019-03-18
网络空间安全(2019年7期)2019-03-18
计算机应用与软件(2018年9期)2018-09-26
东方女性(2018年3期)2018-04-16
散文诗(2017年17期)2018-01-31
军事运筹与系统工程(2016年3期)2016-09-26
外语教学理论与实践(2014年2期)2014-06-21
