
基于高光谱和参数优化支持向量机的水稻施氮水平分类研究
2021-01-04 07:41:02罗建军杨红云孙爱珍易文龙
中国土壤与肥料 2020年5期
罗建军,杨红云,路 艳,万 颖,孙爱珍,易文龙
(1.江西农业大学计算机与信息工程学院,江西 南昌 330045;2.江西农业大学软件学院/江西省高等学校农业信息技术重点实验室,江西 南昌 330045)
氮素是植物生长所必需的元素之一,缺少氮肥的施用会造成植株叶片面积减小,降低光合作用、叶绿素浓度和生物产量[1]。过量氮肥的施用不仅会使大田土壤中的氮素过多残留,而且浪费了肥料,又污染了环境[2-3]。运用高光谱技术进行作物营养诊断,具有快速、便捷、无损害的优点,为实时监测作物氮素营养提供了新的技术手段和方法[4]。对此,多数研究者采用高光谱技术对水稻进行氮素营养研究表明,水稻冠层和叶片高光谱能够很好地反映其氮素营养状况。例如唐延林等[5]研究表明,随着施氮水平的提高,水稻冠层和叶片光谱的差异显著,其可见光范围的反射率有所下降,近红外区的反射率有所增加。Wang 等[6]发现水稻冠层高光谱反射率与不同氮含量具有显著相关性,可大致区分严重缺氮、适氮以及过氮的情况。Chu 等[7]运用高光谱技术,通过选用波长770 与752 nm 的反射率比值进行水稻叶片氮素积累量的判定,氮素积累量的判定模型效果较为优质。王树文等[8]研究表明,水稻冠层光谱反射率与水稻的氮含量具有密切关系,采用高光谱技术能够很好地进行水稻严重缺氮、适氮以及过氮的定性诊断。Du 等[9]采用基于光谱辐射和32 通道探测器的高光谱激光雷达(hl)技术进行特征波长反射率的选择,发现其与水稻不同含氮水平具有很高的相关性。祝锦霞等[10]、刘江桓[11]、孙棋[12]都研究发现不同时期的水稻顶三叶叶片能够很好地体现水稻植株的氮素含量;同时,张丽微等[13]研究表明,在水稻的分蘖期,合理适量的追施氮肥能够提高水稻的产量,改良水稻的品质。因此,选用水稻分蘖期顶三叶叶片进行水稻氮素营养诊断,能够很好地反映水稻氮素营养的缺失,并及时合理地追加施氮。支持向量机(SVM)是建立在统计学习理论中结构风险最小化基础上的监督学习模型[14],在解决小样本、非线性、高维数等模式识别问题时,支持向量机较其他建模方法来说具有更多的优点[15]。但支持向量机的模型性能主要受其误差惩罚参数C 和核函数参数g 的影响。
本研究采用支持向量机进行水稻氮素营养状况的定性诊断,并分别通过网格搜索算法、粒子群算法和遗传算法进行参数优化,以寻求支持向量机的最优参数。通过采用高光谱技术,获取水稻分蘖期顶三叶叶片的可见光到近红外波段350 ~2 500 nm 的光谱反射率,并采用平滑处理和归一化处理,消除噪声和量纲的影响以及主成分分析方法去除数据冗余,为水稻氮素营养状况的定性诊断研究提供一种更加有效、准确的方法,也为进一步研究水稻氮素营养高光谱诊断的定量分析奠定基础。
1 材料与方法
1.1 试验设计
水稻试验于2018 年在江西省南昌市成新农场(116º15’E,28º92’N)进行,水稻田土壤pH 值为5.30、有机质19.46 g/kg、全氮1.02 g/kg、全磷0.48 g/kg、全钾14.22 g/kg、碱解氮112.31 mg/kg,有效磷11.65 mg/kg,速效钾123.84 mg/kg。
根据汪寿根等[16]研究表明,“中嘉早17”水稻在中氮肥水平(150 kg/hm2)处理最佳,其水稻产量达到最高。因此,本试验选用“中嘉早17”水稻作为供试品种,施氮水平设4 个处理,分别为:第一类0 kg/hm2(不施氮)、第二类105 kg/hm2(低氮)、第三类150 kg/hm2(中氮)和第四类195 kg/hm2(高氮)。氮肥使用尿素(N 46%),按基肥∶分蘖肥∶穗肥5∶2∶3 施用。磷肥使用钙镁磷肥(P2O512%),钾肥使用氯化钾(K2O 60%),每种施氮处理下磷钾施肥量相同。人工移栽前1 d 施用基肥,人工移栽后7 d 施用分蘖肥,在叶龄余数1.5 左右时施用穗肥[17]。水稻在4 月9 日 播 种,4 月28 日 移 栽。栽 插 密 度 为13.3 cm×26.6 cm,其他管理按照一般的高产栽培管理。
1.2 光谱数据获取
在分蘖期(5 月17 日)进行水稻顶三叶叶片采集,4 种施氮各采集60 组,共240 组。分别选用每组叶片样本的叶尖、叶中和叶枕3 个部位,使用光谱分析仪进行光谱反射率值的测量,其中3 个测量位置点分别位于距叶尖方向的叶片长度1/4、1/2、3/4 处。以3 个部位位置点的光谱反射率值的平均值作为每组样本的光谱反射率值。光谱分析仪采用ASD 野外光谱分析仪FieldSpec 4,如图1 所示。其测量波长范围为可见光到近红外波段(350 ~2 500 nm)。反射光谱均值处理在Viewspec Program 软件中进行,且光谱测量每间隔15 min 进行一次标准白板矫正。

图1 ASD 野外光谱分析仪FieldSpec 4
1.3 水稻叶片光谱数据预处理
1.3.1 平滑处理
由于数据中或多或少存在噪声。因此,采用移动平均滤波器将原始数据进行平滑处理[18],平均滤波器的窗宽默认设置为5,平滑处理如公式(1)。

式中,x为原始光谱数据的波长反射率,y为平滑后数据的波长反射率,n为波长。
1.3.2 光谱数据归一化处理
处理后的每种特征量纲有所不同,为能够提高模型运行速率和模型准确率[19],使用公式(2)对平滑处理后的所有数据进行归一化处理。
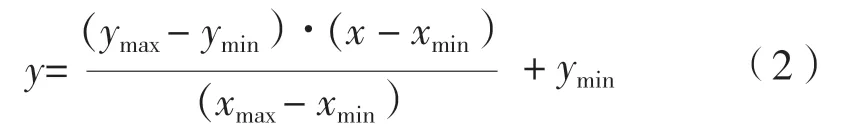
式中,xmax和xmin分别为原始光谱数据中的最大值与最小值,ymax和ymin分别为归一化处理后光谱数据的最大值与最小值,分别取1 和-1。
1.4 光谱特征降维处理
各波段光谱反射率值间存在一定的相关性,增加了预测难度[20]。主成分分析(PCA)利用降维的思想,在损失很少信息的前提下,将多个变量转化为少数几个不相关的综合变量[14,21]。本研究共获取了2 151(350 ~2 500 nm)个波长变量,为提高算法运行效率,降低光谱数据的数据冗余,通过采用主成分分析的方法降低光谱数据的变量个数。统计学认为,累计贡献率达到80%及以上[10],就能够很好地表征出原始数据的特性。因此,获取的变量方差累计贡献率越高,就越能反映原始数据的特征性。
1.5 不同算法优化支持向量机模型的建立
支持向量机模型性能的主要影响因素包括误差惩罚参数C 和核函数参数g 以及核函数类型[22]。本研究采用支持向量机对水稻氮素营养状况进行定性诊断研究,同时选用径向基核函数[23],径向基核(RBF)函数如公式(3)所示。考虑到误差惩罚参数C 和核函数参数g 对SVM 的性能有着很大影响[24],且合理选取不仅可以优化模型,而且能够适用于小数据样本集的模型建立。本研究分别选用网格搜索算法、粒子群算法和遗传算法进行支持向量机模型的最佳参数选取。其中,网格搜索算法设定网格搜索的变量C 和g 的初始范围为[2-8,28],搜索步距设为1,采用K-CV 方法对训练集进行测试,其中K=3[25]。粒子群算法和遗传算法优化支持向量机模型的变量C 和g 的变化范围都设定为[2-8,28],最大进化数量设定为200,种群最大数量设定为20。
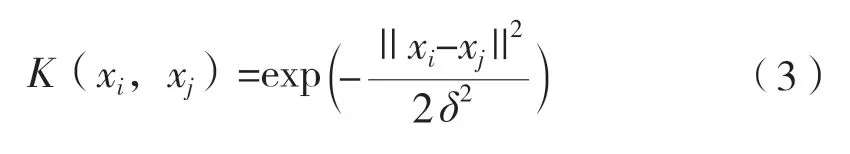
其中δ>0,为高斯核的带宽。
2 结果与分析
2.1 不同施氮水平下的水稻光谱数据分析
将4 种施氮水平的240 组(各施氮水平60 组)光谱数据求取平均值,各施氮水平下的水稻叶片光谱如图2 所示,不同施氮水平下的光谱变化趋势相同,但在红外区780 ~1 300 nm 4种施氮水平的光谱反射率有所不同,以第四类(高氮)施氮水平下的光谱反射率最高,第三类(中氮)施氮水平其次。在1 400 ~1 850 nm 及1 900 ~2 500 nm 左右都表现出第四类(高氮)施氮水平的光谱反射率最低,其次是第三类(中氮)施氮水平,第一类(不施氮)和第二类(低氮)施氮水平反射率值差别不大,二者(第三类、第四类)光谱反射率都高于第一类(不施氮)和第二类(低氮)施氮水平。由此表明应用水稻叶片光谱进行水稻氮素营养状况分类识别具有可行性。

图2 不同施氮水平下的水稻叶片光谱对比
2.2 光谱数据平滑处理分析
将240 组光谱原始数据进行平滑处理,平滑处理前后效果如图3、4 所示。由图3 可知,不同施氮水平的水稻叶片光谱反射曲线呈相同趋势。在绿光区的550 nm 处,水稻叶片反射率出现波峰,在红光区的680 nm 及短波红外区的1 450和1 900 nm 处水稻叶片出现强烈吸收,形成波谷。该光谱反射现象与张亚彪等[26]的研究结果一致。由图4 可知,经过平滑处理后的光谱反射曲线有效地消除了谱线平移、高频随机噪声和光散射等因素的影响。
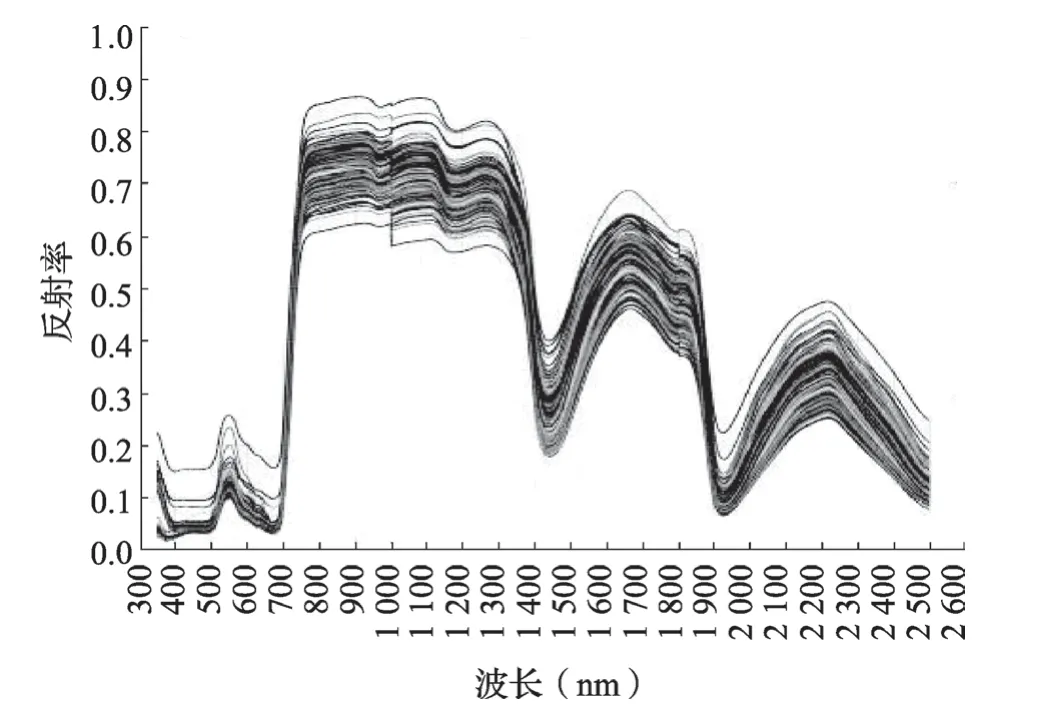
图3 240 组样本原始光谱
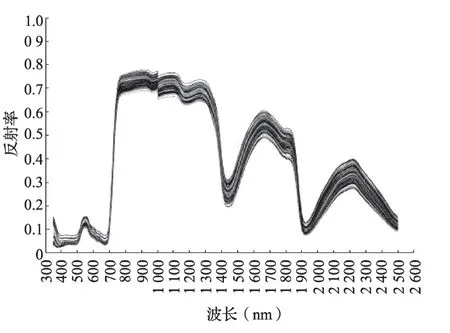
图4 平滑处理后的水稻光谱
2.3 水稻叶片光谱数据特征降维分析
本研究采用主成分分析将平滑处理和归一化处理后的光谱数据进行降维处理,由于光谱数据波长变量较多,本研究仅列出前30 个主成分的方差贡献率,如图5 所示。前3 个主成分相对较高,其中PC1 为62.310 2%、PC2 为26.326 2%和PC3 为6.418 46%,如图5 所示。虽然前3 个主成分方差贡献率较高,但从图中可以看出,各类样本点重叠严重,仍难以对4 类样本进行区分,因此前3 个主成分并不能完全表征出原始数据的特征性。为能实现良好的水稻氮素营养状况识别实验效果,本研究选取前22 个主成分作为模型输入数据,前22 个主成分累积贡献度高达99.995 1%。
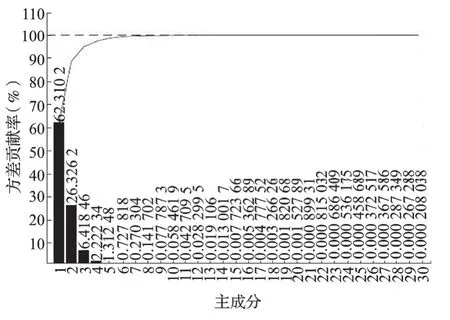
图5 前30 个主成分的方差贡献率
2.4 基于参数优化支持向量机的水稻氮素营养状况分类识别模型分析
为探寻快速、便捷、无损的水稻氮素营养状况定性诊断方法,将240 组样本数据随机分成两组,分别为建模训练集和建模测试集。其中160 组样本作为建模训练集样本(每种施氮水平各40 组),80 组样本作为建模测试集(每种施氮水平各20组)。本研究选用支持向量机模型(SVM 模型)进行水稻氮素营养状况分类识别模型的建立,并以主成分分析降维后的22 维主成分作为模型的输入数据。分别选用SVM 的默认参数[27]和网格搜索算法、粒子群算法、遗传算法选取的最佳参数进行SVM 建模。其中,默认参数下的SVM 模型选择误差惩罚参数C 为1.000 0,核函数参数g 为10.000 0。4 类施氮水平(施氮由低到高)数据的模型输出参数y 分别由1、2、3、4 代表。不同寻优方法选取最优参数的结果如表1 所示。由表可以看出,通过3 种参数优化的SVM 模型要优于默认参数下的整体识别效果,且基于遗传算法的SVM 模型与另外两种方法相比,寻优效果最佳,其误差惩罚参数C 为2.261 4,核函数参数g 为7.568 3。
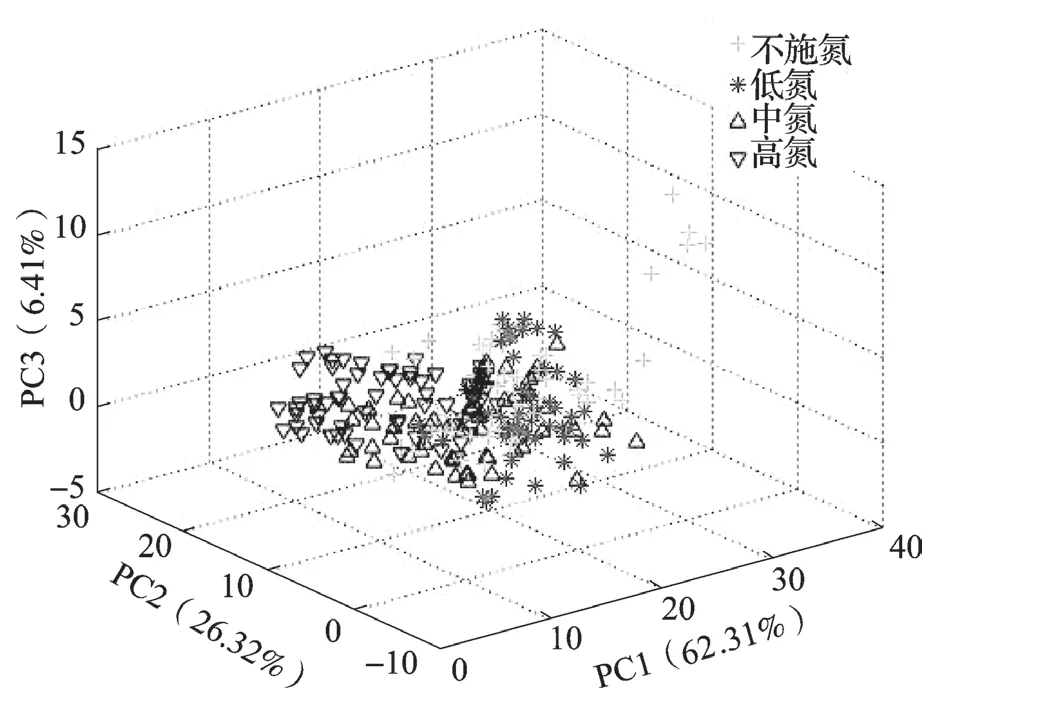
图6 PC1、PC2 及PC3 得分散点分布
采用默认参数及3 种寻优方法进行支持向量机的水稻氮素营养分类识别模型建立,建模测试集各施氮水平识别效果如表2 所示。从整体来看,默认参数下的SVM 模型测试集平均识别效果最差,仅为87.500%,3 种寻优方法的SVM 模型测试集实验效果较默认参数下的SVM 模型要好,均达到95.000%及以上,其中以基于遗传算法优化SVM模型(GA-SVM)实验效果最佳,高达98.750%,较基于网格搜索算法优化SVM 模型(Grid-SVM)和基于粒子群算法优化SVM(POS-SVM)分别高出3.75%和2.50%。从各施氮水平识别效果来看,默认参数下的SVM 模型在第二类(低氮)施氮水平上识别陷入局部最小,第二类(低氮)识别准确率仅为65.00%,其他3 类(第一类、第三类、第四类)施氮水平均达到95.000%,默认参数下的SVM 模型各施氮水平识别分类结果如图7 所示。其他3 种参数优化的SVM 模型对第三类(中氮)、第四类(高氮)施氮水平都能够很好地识别,达到100.000%,对第二类(低氮)施氮水平的识别都达到了95.000%。只有在第一类(不施氮)施氮水平上,识别效果产生了一定的差别。基于遗传算法的SVM 模型较其他两种优化算法优化的SVM 模型,仅第二类(低氮)施氮水平下的第40 组样本被误判为第三类(中氮)施氮水平;基于网格算法优化的SVM 模型中,第一类(不施氮)施氮水平下的第12、13 和14 组样本被误判为第二类(低氮)施氮水平,第二类(低氮)施氮水平下的第40 组样本被误判为第三类(中氮)施氮水平;基于粒子群算法优化的SVM 模型中,第一类(不施氮)施氮水平下的第12 和14 组样本被误判为N1 施氮水平,第二类(低氮)施氮水平下的第40 组样本被误判为第三类(中氮)施氮水平;而基于遗传算法优化的SVM 模型仅将第二类(低氮)施氮水平下的第40 组样本被误判为第三类(中氮)施氮水平。3 种优化算法优化SVM 模型的各施氮水平识别分类结果如图8、9、10 所示。
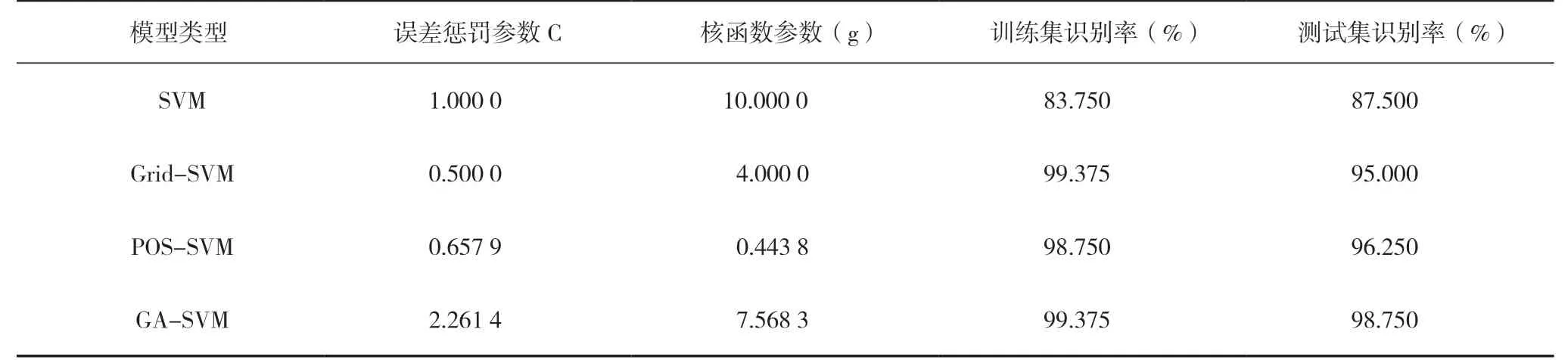
表1 不同参数寻优方法选取的最优参数及实验效果
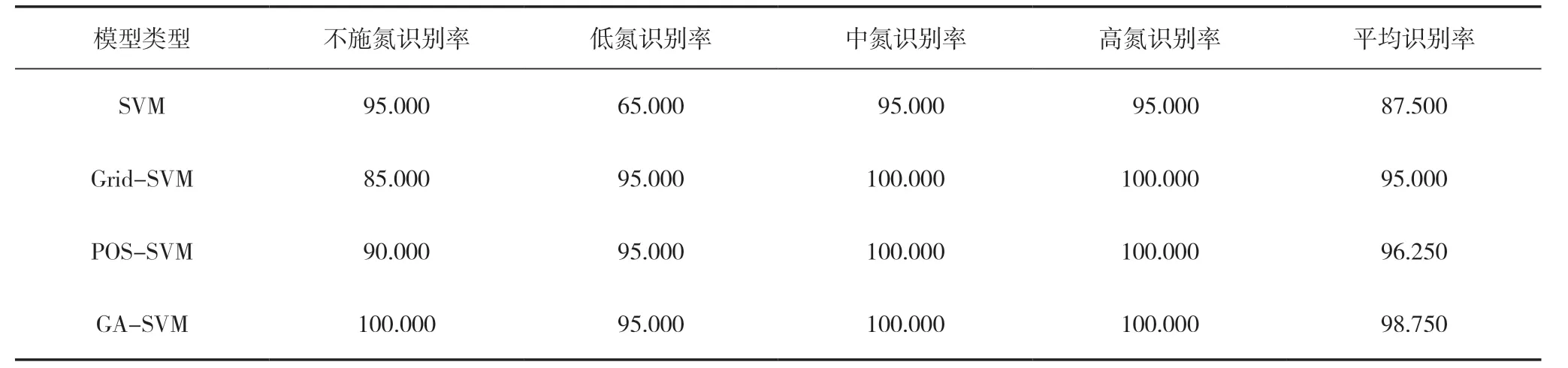
表2 不同施氮水平下的预测集识别效果对比 (%)
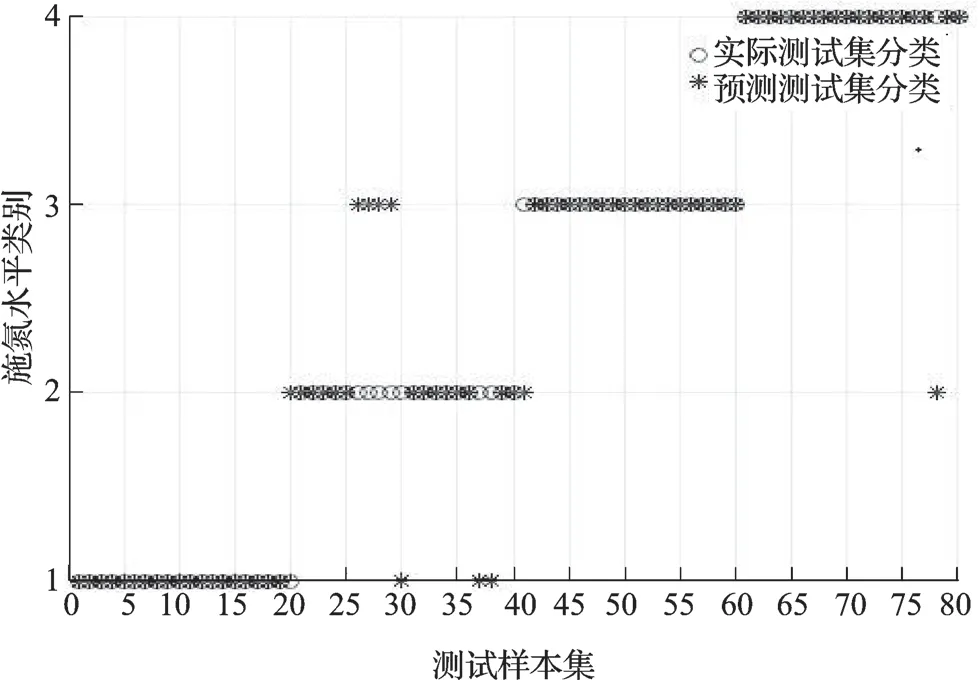
图7 默认参数支持向量机模型的预测集识别分类结果
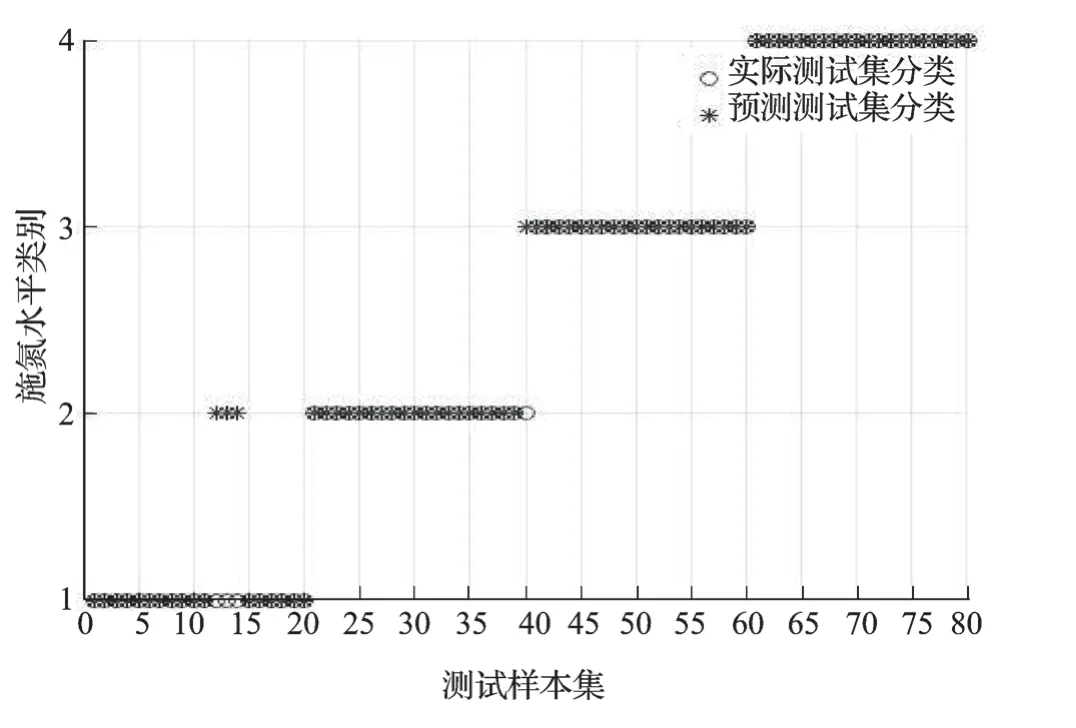
图8 基于网格搜索算法优化支持向量机模型的预测集识别分类结果
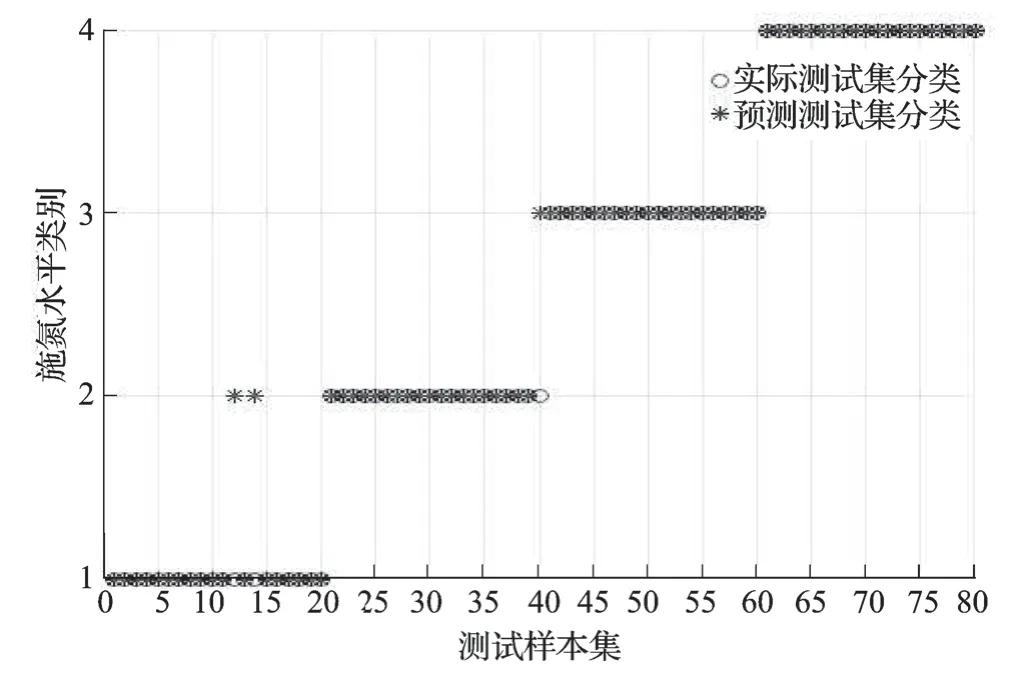
图9 基于粒子群算法优化支持向量机模型的预测集识别分类结果
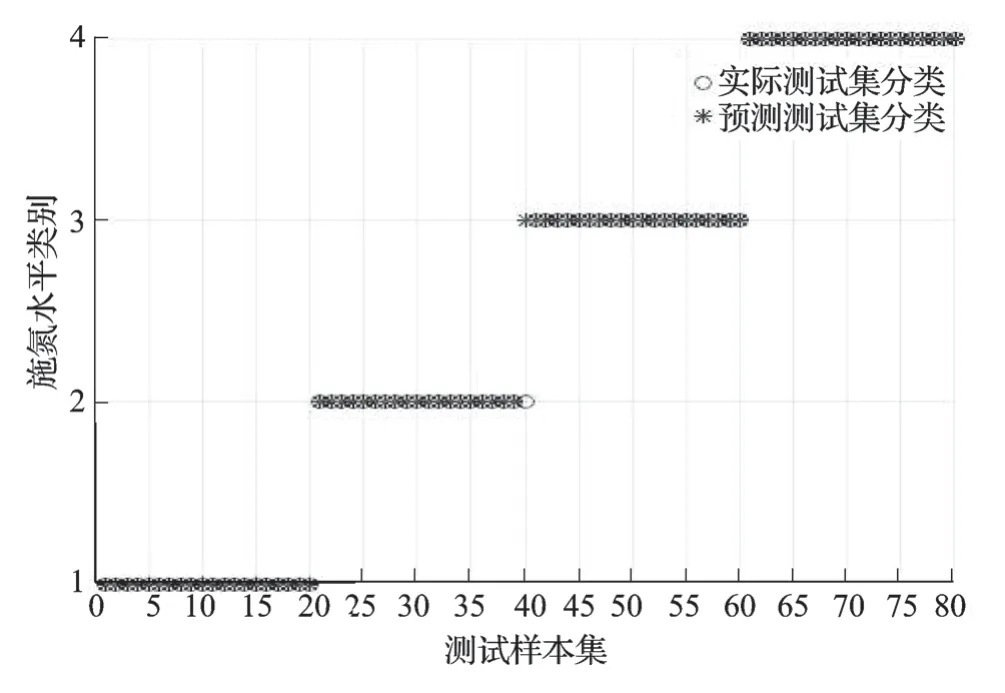
图10 基于遗传算法优化支持向量机模型的预测集识别分类结果
3 讨论
水稻冠层叶片光谱特征能够为快速、便捷、无损地诊断氮素营养提供有利依据[28]。同时,建立水稻氮素营养的光谱诊断模型,可以快速诊断水稻氮素状况,对指导有效施肥、合理施氮具有重要的现实意义[29]。因此,本研究通过光谱特征,利用机器学习方法建模进行水稻施氮水平分类识别,通过本研究的结果能够为进一步的水稻氮素营养诊断定量分析提供支持,且本研究方法可以为作物氮素营养诊断识别研究提供一定的参考价值。而且,通过参考高产施肥方案,可指导农户科学合理施肥[30]。
前人研究中,顾清等[31]提取了水稻叶片光谱和形状特征,采用支持向量机方法进行水稻氮素营养状况分类识别建模,其模型对于过氮水平样本难以识别;周琼等[23]采用遗传算法优化支持向量机方法进行水稻氮素营养状况分类识别中,能够很好地区分缺氮和过氮水平样本,但非低氮且非高氮的两类施氮水平样本却不易区分。杨红云等[32]采用高光谱技术和支持向量机方法建立了水稻氮素营养状况分类识别模型,其模型解决了水稻各类施氮水平样本难以识别的问题,且测试集平均识别准确率达97.5%。本研究同样采用高光谱技术和支持向量机方法建立水稻氮素营养状况分类识别模型,同时考虑到支持向量机惩罚参数C 和核函数参数g 的选择问题,并分别采用网格搜索算法、粒子群算法和遗传算法对支持向量机的参数进行优化选择。本研究的结果表明,建立的该模型不仅能够解决各施氮水平样本难以识别的问题,而且基于遗传算法优化支持向量机所建立的水稻氮素营养分类识别模型较杨红云等[32]的效果更佳,预测集平均识别准确率达98.750%,高出1.250%,仅第二类(低氮)的第40 组样本被误判为第三类(中氮)。
获取的原始光谱数据中必然存在数据噪声,各波长原始光谱反射率间必然存在相关性。因此,有必要对原始光谱数据进行有效的预处理。本研究中通过采用平滑处理和归一化处理消除噪声和量纲的影响,以及采用主成分分析方法对光谱数据进行降维,以减少各波长光谱反射率间的相关性。通过模型的氮素营养诊断识别准确率来看,虽通过本研究方法能够达到较为理想的效果,但在未来的研究中,需要引入更多的消除噪声和降维的方法,以实现更具通用性和实用性的水稻氮素营养诊断模型。降维处理可尝试使用连续投影算法(SPA)[6,33]、因子分析[34]等方法,去噪处理可尝试使用多元散射校正(MSC)[35-36]、变量标准化校正(SNV)以及基线校正的方法[18]。
本研究采用高光谱技术和支持向量机方法进行水稻氮素营养状况分类识别,属于水稻氮素营养诊断的初步性研究,改善之处尚多。研究中仅以2018 年的“中嘉早17”作为供试样本,所建立的水稻氮素营养分类识别模型在其他年限和水稻品种中的应用性还需要进一步研究。本研究仅获取水稻分蘖期顶三叶叶片的4 个施氮水平叶片高光谱数据,样本数目相对较少,仅有240 组。为能够使得水稻氮素营养分类识别模型更具有通用性与实用性以及提高样本的容错率,在未来的研究中,将获取更多年份、水稻品种及叶位等的高光谱数据进行研究,并且提高模型建立的样本总量,以及增加水稻氮素营养诊断的施氮水平数目,为进一步积极探索水稻氮素营养诊断的定量分析奠定理论基础,也为科学施肥,提高氮肥利用率,保证作物高产稳产提供理论依据。
4 结论
本文选用水稻分蘖期顶三叶叶片原始光谱数据,采用平滑处理去除光谱数据噪声、归一化处理消除光谱数据的量纲影响,同时采用主成分分析的方法减少各波长光谱反射率间的相关性。最后,分别采用网格搜索算法、粒子群算法和遗传算法优化的支持向量机进行水稻氮素营养诊断模型的建立。研究结果表明,通过采用3 种优化算法优化的SVM模型进行水稻氮素营养高光谱诊断具有一定可行性,都优于默认参数下的SVM 模型。其中,应用遗传算法优化的SVM 模型进行水稻氮素营养诊断最佳,各施氮水平测试集识别准确率分别为100%、95%、100%和100%,其预测集平均识别准确率达98.750%,仅第二类(低氮)的第40 组样本被误判为第三类(中氮)。说明利用高光谱技术进行水稻氮素营养水平的诊断具有一定的可行性。因此,基于遗传算法优化参数的支持向量机模型应用于水稻氮素营养的缺失识别具有一定优势。为实时、快速、准确地实现水稻氮素营养诊断研究提供了一种新思路和方法,以指导合理施氮,提高水稻的产量。
猜你喜欢
农业科技通讯(2023年1期)2023-02-12 07:08:04
印制电路信息(2022年11期)2022-11-30 03:40:58
海洋通报(2022年4期)2022-10-10 07:40:26
光谱学与光谱分析(2022年4期)2022-04-06 03:44:38
电子器件(2017年2期)2017-04-25 08:58:37
农业环境科学学报(2017年2期)2017-03-20 14:57:37
农家顾问(2014年9期)2014-10-20 22:52:38
植物营养与肥料学报(2011年5期)2011-11-06 07:30:52
植物营养与肥料学报(2011年2期)2011-10-26 03:52:10
植物营养与肥料学报(2011年2期)2011-10-26 03:52:00
