
自注意力的多特征网络流量异常检测与分类
2021-01-01 11:52皇甫雨婷李丽颖王海洲沈富可魏同权
华东师范大学学报(自然科学版) 2021年6期
关键词:特征选择
皇甫雨婷 李丽颖 王海洲 沈富可 魏同权














摘要:基于特征选择的网络流量异常检测引起了人们广泛的研究兴趣.现有的方案大多通过简单降低流量数据的维度来检测异常,却忽略了数据特征之间的相关性,导致异常流量检测效率低下.为了有效识别各种类型的攻击,首先提出了一种自注意力机制模型来学习网络流量数据多个特征之间的相关性.然后,设计了一种新型的多特征异常流量检测和分类模型,该模型分析了异常流量数据中多特征之间的相关性,达到检测与识别异常网络流量的目的.实验结果表明,与两种基准方法相比,所提出的技术将异常检测和分类的准确率提高了1.65%,并将误报率降低了1.1%.
关键词:网络异常检测;网络异常分类;自注意力;特征选择;多特征相关性
中图分类号:TP393文献标志码:ADOI:10.3969/j.issn.l000-5641.2021.06.016
Enabling self-attention based multi-feature anomaly detection and classification of network traffic
HUANGFU Yuting,LI Liying,WANG Haizhou,SHEN Fuke,WEI Tongquan
(School of Computer Science and Technology,East China Normal University,Shanghai 200062,China)
Abstract:Network traffic anomaly detection based on feature selection has attracted great research interest. Most existing schemes detect anomalies by reducing the dimensionality of traffic data,but ignore the correlation between data features;this results in inefficient detection of anomaly traffic. In order to effectively identify various types of attacks,a model based on a self-attentive mechanism is proposed to learn the correlation between multiple features of network traffic data. Then,a novel multi-feature anomalous traffic detection and classification model is designed,which analyzes the correlation between multiple features of the anomalous traffic data and subsequently identifies anomalous network traffic. Experimental results show that,compared to two benchmark methods,the proposed technique increased the accuracy of anomaly detection and classification by a maximum of 1.65% and reduced the false alarm rate by 1.1%.
Keywords:network anomaly detection;network anomaly classification;self-attention;feature selection;multi-feature correlation
0引言
随着数据量的快速增长和网络应用的广泛使用,网络安全引起了越来越多专家学者的关注.在网络流量中,异常现象是安全问题的主要症状[1].通常情况下,网络异常指的是行为和模式与正常网络状态存在偏差.网络异常的因素有多种,包括病毒、蠕虫、黑客入侵、广播风暴、网络流量超载和DDoS攻击等.网络异常会造成网络拥堵、资源分配不均衡、性能下降以及一些安全问题,最终可能导致数据泄露和经济损失[2].例如,2017年,一种名为Wannacry的类似蠕虫的勒索病毒爆发并在全球范围内传播.该病毒对电脑中的图片、程序等文件实施了高强度的加密锁定,并向用户索要赎金,导致社会的经济利益受损.网络异常流量检测可以检测网络中的突发攻击事件,检测到攻击后可以做出应对,减少损失,而分类可以把攻击的类型识别出来,针对不同的攻击采取不同的应对措施,对症下药.因此,进行网络异常检测,识别异常流量就具有重要的应用价值.
目前,异常流量检测的方法可分为基于签名的方法和基于统计的方法[3].基于签名的检测技术主要是利用模式匹配的思想,为每一个已知的攻击生成一个唯一的签名标记.基于签名的方法简单有效,不需要很高的计算能力,但需要为每种攻击类型设计一个签名.此方法虽然适用于单一网络行为模式的攻击,但是对动态攻击无效.此外,基于签名的方法只能检测已知的攻击,不能检测未知的攻击.基于统计的方法根据网络流量的行为来对流量的异常情况进行判断,该方法可以学习网络流量的行为,对于动态的、复杂的网络异常行为,可以达到更好的检测性能.机器学习技术是最常用的基于统计的方法之一,具有强大的功能,可以自动学习识别复杂的模式,并根据数据做出明智的决策巴在使用机器学习方法训练分类器进行异常检测和分类之前,有必要进行特征选择以降低数据的维度.特征选择的目的是在众多特征中挑选出对分类识别最有效的特征,实现数据空间维度的降低来减少计算量,提高分类速度,即获取一组少而精且分类错误概率小的子特征集合.目前的研究表明,基于特征选择的机器学习方法已经取得了比较令人满意的性能[4].经典的机器学习算法包括决策树(Decision Tree,DT),支持向量機(Support Vector Machine,SVM),k-Nearest Neighbor (kNN)和随机森林(Random Forest,RF)等.Sheen等[5]描述了3种不同的特征选择方法,并使用DT作为分类器来找到具有更好分类性能的特征选择方法.Kuang等[6]引入了一个基于SVM的模型,该模型使用内核主成分分析(KPCA)来选择特征并降低原始数据的维数.Farnaaz等[7]使用随机森林构造分类器并建立异常检测系统模型. 该方法旨在检测复杂的攻击并提高检测率.Wu等[8]提出了一种kNN的异常检测方法,利用该方法使用时间敏感性来查找在不同时间间隔内表现出不同行为特征的异常值.但是它使用的数据集KDD- CUP是20世纪90年代末提出的一个数据集,在互联网飞速发展的今天,里面涉及的数据以及攻击类型都具有一定的局限性.文献[9]提到基准数据集的可靠性也将对数据检测产生一定的影响.综上所述,基于特征选择的机器学习方法根据人为制订的规则,选取与流量重要性较高的特征,形成一个最优的特征子集,从而降低数据维度和计算成本.然后,通过机器学习算法训练分类器,达到检测和分类的目的.然而,基于特征选择的机器学习方法也有两个限制.一方面,特征选择的过程涉及人工的干预,所以时间成本和人力成本较高[10].另外,它忽略了特征之间的相互关系,只选择与网络流量关系最大的部分特征.另一方面,由于网络数据的流量大、结构复杂,机器学习的处理能力有限,容易出现误报率高、泛化能力差等问题[11].因此,建立一种能够有效识别异常流量的检测模型迫在眉睫.
近年来,深度学习优异的表示能力引起了人们的广泛关注,并在图像识别和自然语言处理领域取得了显著的成绩.由于传统机器学习方法的局限性,深度学习方法在网络异常流量检测领域也引起了很多学者的研究兴趣[12].深度学习方法最早在异常检测中的应用是循环神经网络(Recurrent Neural Network,RNN).Yin等[12]使用RNN模型来提高二进制分类和多分类的性能.由于RNN对于高维数据易产生梯度消失的情况且无法解决长期依赖的问题[13].为了解决这个问题,文献[14]提出了长短期记忆(Long Short-Term Memory,LSTM),它是RNN的一种变形.在实际操作中,卷积神经网络(Convolutional Neural Networks,CNN)和LSTM模型的应用更加广泛,在实验性能方面也非常出色. CNN是一类包含卷积计算的神经网络,通过卷积核进行特征提取和筛选.Wang等[15]结合使用LSTM和DT.在他们的方法中,数据首先通过LSTM,然后放入DT中进行二次检测,以提高准确性并降低误报率.Wang等[10]将CNN应用于网络流量中的流量分类.他们将二进制字节流转换为灰度图像,然后将这些图像形式输入CNN模型以完成分类.但是,网络流量包含的信息量少于图片包含的信息量,在转换过程中某些信息可能会丢失.Kim等[16]引入了一种新的编码技术,该技术增强了使用CNN结构识别异常事件的性能.不可否认,深度学习方法确实达到了很好的性能[15].但这些深度学习方法仍然存在一些不足之处.我们都知道,网络流量是一个数据序列.RNN只适用于局部依赖性,无法解决长期依赖性的问题[13],对于LSTM来说如果序列太长,它也无法更好地记忆[17].而CNN需要叠加多个过滤器才能学习到全局的特征,这增大了计算复杂度[18-19].
谷歌所提出的self-attention机制[20]取代了传统的RNN.该方法通过学习句子内的单词依赖关系,捕捉句子的内部结构.目前在自然语言处理(Natural Language Processing,NLP)領域得到了广泛的应用[21-22].与CNN相比,self-attention具有较低的计算复杂性.此外,与RNN和LSTM相比,self- attention可以关注一个序列中的所有元素,因此它被认为是解决长期依赖性问题的好办法.
为了解决上述问题,我们所提出的方案通过self-attention技术来学习多特征之间的相关性,解决了传统特征选择方法中为了减少计算量而仅挑选少量的最具代表性的分类特征组成子集合的方式,因此忽略了特征和其他特征之间微小的联系.本文所提出的策略,打破了传统特征选择方法,单纯选择网络流量中重要性高的特征规则.基于提取的特征相关性,我们提出了一个模型,对提取出的特征关系进行编码,并对网络攻击进行分类.本文的主要成果总结如下:
(1)设计了一个基于self-attention的模型来提取多特征的相关性.该模型旨在自动学习特征间的相关性,降低特征选择所带来的人工成本以及时间成本.
(2)提出了一种对所提取的特征间关系进行编码的模型,从而对网络流量异常进行有效检测和分类.
(3)进行了大量的实验来评估本文所提出方法的性能.实验结果表明,与两种基准方法相比,本文所提出的方法将异常流量识别的准确率提高了1.65%,并将误报率降低了1.1%.
1相关技术
1.1基于self-attention的特征相关性提取
传统的特征选择方法为了减少计算量,只选择最具代表性的特征来检测网络流量的异常.这些方法忽略了特征之间的相互关系,不能有效地对复杂的网络攻击进行检测和分类.self-attention技术可以学习特征间的相关信息,有效地解决上述问题.
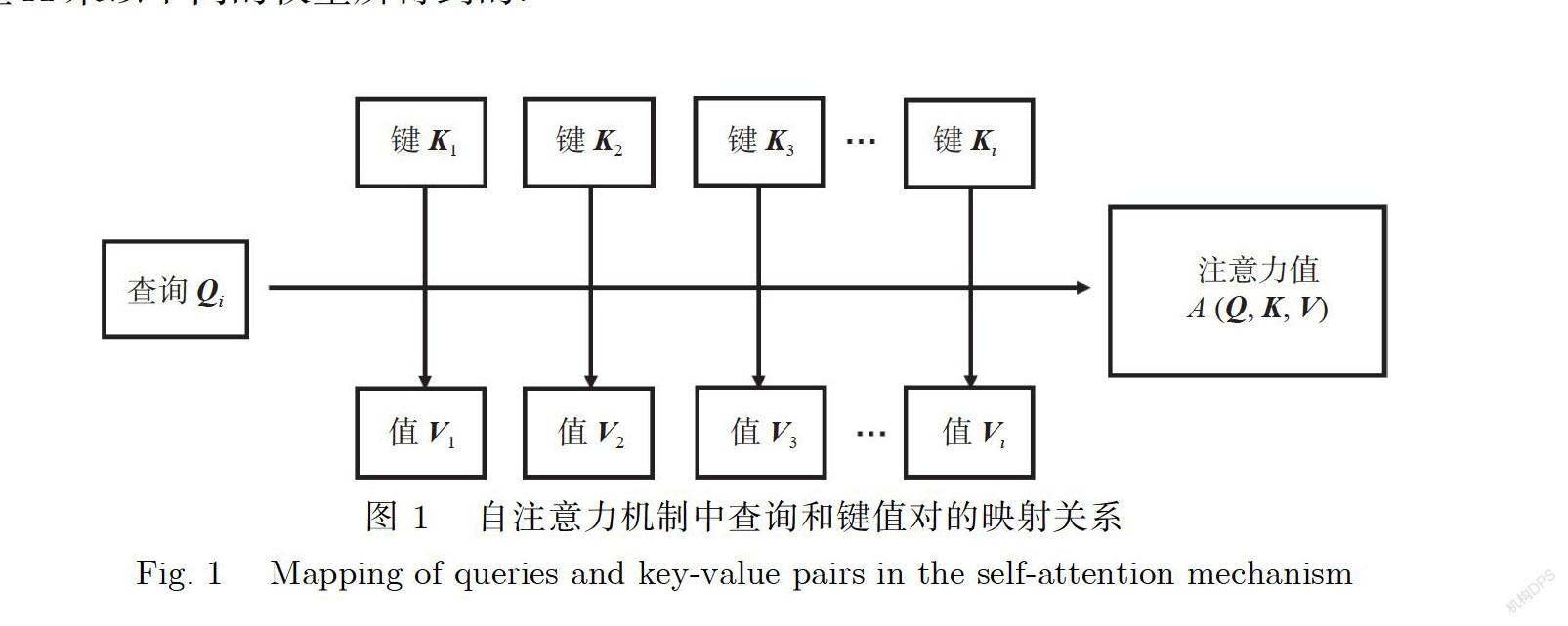
本文使用self-attention来捕捉多个网络流量特征之间的关系.self-attention可以描述为将查询Q和一组键值对(K-V)映射到输出,如图1所示.其中Q、K、V和输出都是向量.Q、K、V都是由输入向量X乘以不同的权重所得到的.
Q=XW,
K=XW,
V=XW.
其中,X代表输入向量,W、W、W是模型训练过程中学习到的参数,初始时W、W、W是随机赋值的,且它们的值都是一样的,即Q=K=V.在训练过程中会根据训练结果不断改变Q、K、V的值,直至找到各自合适的参数.设置Q、K、V的目的是通过计算的方式找到与其他特征之间的相关性系数大小,相当于给每个特征计算出一个权重,然后得出一个加权的结果来说明每个特征与哪一个特征之间关联最大,通过学习这些关注值中的信息来进行流量的检测与分类.self-attention主要做的工作是计算查询Q和所有键K的点积,并进行缩放,通过softmax函数得到值V的权重,然后把值V和权重相乘就得到最终的注意力值,用A(Q,K,V)表示.图1中的查询Q代表第,个输入的查询,键K代表第i个输入的键,类似于索引的一个值,值V代表第i个输入的值,包含了其输入的信息.因此计算得到注意力值相当于第i个输入与第1,2,…,i个输入之间的注意力值,即每个输入之间的相关性.
图2中详细说明了计算注意力值的具体操作过程.
计算过程可分为以下三步.以第一个输入为例,第一步是将Q与所有的键(K,K,…,K)相乘,然后进行放缩后得到S,一般都是通过除以(K的维度)来缩放.S由以下公式给出:
第二步是使用softmax对这些值进行归一化,得到这些值在整个输入中所占的权重,权重之和为1.
Z的计算方法为
其中,M为输入的个数,exp函数是以自然常数e为底的指数函数.第三步是利用权重计算加权和,得到第一个输入与所有输入之间的注意力值A.A由以下公式给出:
上述過程描述的是第一个输入与所有输入之间的注意力值的计算过程,剩下的第2,3,…,i个输入与所有输入之间的注意力值可以通过同样的方法计算得到.事实上,每一个输入的注意力值计算过程是可以并行操作,通过矩阵运算的方式得到.我们将所有的Q打包成一个矩阵Q,K、V也打包成矩阵K、V.注意力值A(Q,K,V)可以用以下方式给出:
其中,T表示矩阵的转置,S表示softmax回归假设函数.
1.2异常检测与分类模型
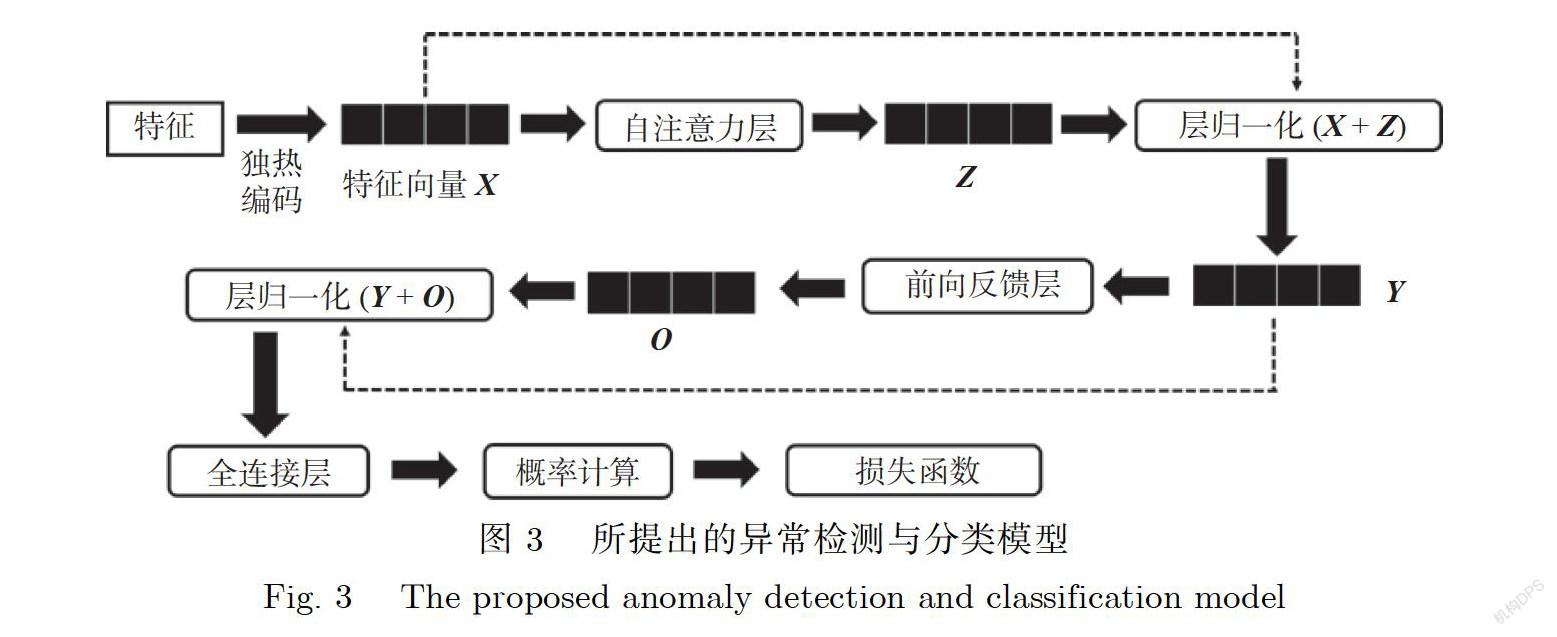
如同1.1节中的描述,使用self-attention机制来捕捉多特征之间的关系.捕获到的关系信息需要进一步编码来检测和分类异常流量.我们进一步设计一个模型来检测和分类网络异常流量.图3 显示了我们所提出的异常检测和分类模型的结构.
通过训练一个性能优良、泛化性强的模型来检测和分类网络流量.这个模型主要分为3个子层,第一个是自注意力子层,第二个是前向反馈子层,第三个是分类子层.在第一个子层中,因为数据集中的一条数据是由多个特征组成的,而自注意力中的输入是以向量的形式,要研究特征和特征之间的相关性,需要把特征转换成特征向量的形式.从图3可以看到,特征首先通过独热编码的方式转换成特征向量X的形式,以特征向量作为模型的输入.特征向量X经过自注意力层产生特征相关性的注意力向量Z,将特征向量X和注意力向量Z进行残差连接,再经过层归一化生成输出Y.残差连接是指将自注意力子层的输入X和输出Z相加的操作,其作用是避免梯度的消失.层归一化是为了加快收敛速度.第一个自注意力子层的输出Y经过前向反馈层,它是一个全连接的前馈网络,由两个线性变换组成,它们之间有一个ReLU激活函数.前馈子层F(Y)的定义由以下公式给出:
F(Y)=max(0,YW+b)W+b.
其中,W1,b代表从输入向量Y到第一个全连接层的权重和偏置.W,b代表从第一个全连接层到第二个全连接层的权重和偏置.前向反馈层的输出向量O和其输入向量Y也经过一个残差连接层和归一化处理,最后得到的结果放入分类子层中被进一步编码.分类子层中经过全连接层,通过softmax 函数来计算数据在各个分类上的概率情况,通过计算损失来训练模型.在我们的模型中,所使用的损失函数是交叉熵损失函数L,定义为
其中,p(x)表示实标的概率向量,q(x)表示预测结果的概率向量.计算出损失值后,进行反向传播,更新Q、K、V等参数.我们还使用Adam优化器来优化我们的模型,训练完所有数据后,保存当前模型参数.
2算法介绍
本章总结了所提出的基于self-attention的异常检测和分类算法,并介绍了相关的预处理、训练和测试算法.
2.1预处理阶段
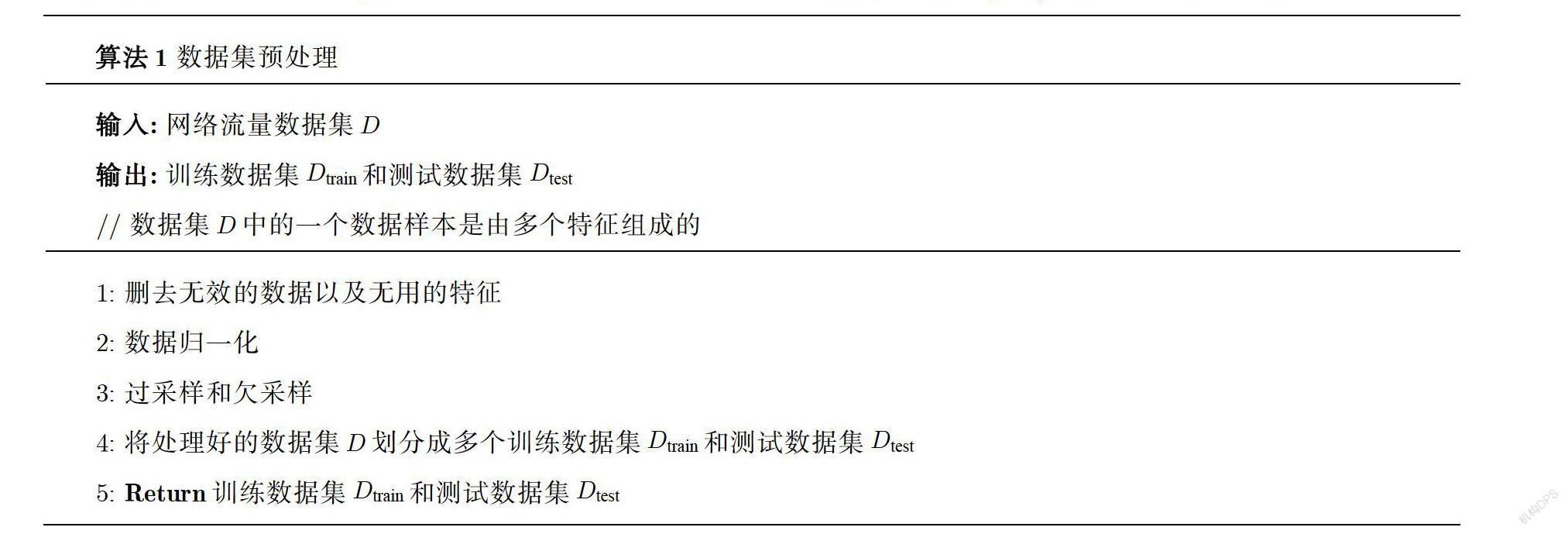
算法1展示了预处理步骤的伪代码,它以网络流量数据集。为输入,输出训练数据集Aram和测试数据集Rest.它包括4个步骤:数据清洗、归一化、过采样和欠采样、数据集分割.第一步是数据清洗.这是保证数据质量的一项重要工作.首先,因为数据是从真实的网络环境中抓取的,所以存在无效数据的可能性非常大.我们删除这些无效数据,以提高实验结果的准确性.通过进一步的检测,发现无效的数据量是比较少的,只有十几条,所以本文将这些无效的数据整条删除.另外一点,从原始数据中提取的特征有80多个,其中包括了IP地址、协议、端口号等特征,但这些特征并不是所需要的,所以我们将这些不需要的特征字段删除,只保留与数据流相关的特征字段,来减少对于分类的影响.第二步是数据归一化,即对数值进行缩放,使其落入一个小的特定区间,使不同的特征都具有相同的量级,方便后续的计算处理.我们使用max-min归一化方法将数据线性化在[0,1]区间上,具体如算法1.
其中,x表示需要做归一化处理的样本,x为处理过后的数据,x为样本数据的最大值,x为样本数据的最小值.第三步是过采样和欠采样.大多数公共数据集的常见问题是正样本和负样本在数量上的不平衡.在数据不平衡的情况下,如果选择的算法或评价指标不合适,其性能通常是不理想的.考虑到这种普遍情况,从数据的角度出发,我们选择采样的方式来改善数据分布的不平衡性.欠采样是指从数据集中不重复的随机抽取数据.过采样是利用聚类算法随机生成样本.最后,将处理后的数据集D分割成多个训练子集D和测试数据集D.数据预处理过程最后返回训练数据集D和测试数据集D.
2.2训练阶段
在训练阶段,使用训练数据集来迭代训练一个分类器.算法2展示了训练阶段的伪代码.它将训练数据集D作为输入,输出训练好的模型各项参数w.在训练过程中使用小批量训练,即把一个大的训练集分成多个小的数据集,以降低计算成本.D代表一个数据样本,其中包含许多特征.在每个小批量训练中,通过独热编码将D中的特征转化为特征向量.通过式(1)计算特征间相关性的关注值,进行残差连接和归一化.然后将注意力值通过前馈编码来分析相关信息.通过残差连接和归一化进行前馈,进一步实现分类,计算真实标签和预测结果之间的损失,通过减小损失函数的值来进行参数优化.所有batch结束后,模型参数w被训练并保存.最后返回模型参数w,具体如算法2.
2.3测试阶段
为了验证模型具有良好的性能和泛化性,我们使用几个不同的测试数据集.算法3展示了测试阶段的伪代码,它将模型参数w和测试数据集D作为输入并输出预测结果.第一步先加载训练好的模型参数w和测试数据集D.在D中,有多个不同的测试数据集.在每个测试数据集中,同样,将分成多个小数据集.每个小数据集中的每条数据D放入模型中得到分类结果,并保存其结果.最后返回预测结果,具体如算法3.
将数据集分成两部分,一部分用于训练,另一部分用于测试.而用于训练的数据集又分了一小部分用于测试,以此来验证模型是不是具有良好的泛化性能,因为在某一个数据集上的优秀性能并不代表在另一个数据集上它仍然具有良好的表现.所以,通过比较两个数据集的测试结果可以看出模型的泛化性.如果在训练集上测试的结果表现出性能较好,而测试集上的结果显示精度不高,则这个模型的泛化性能就是不太理想的,模型的参数是只适用于某一个数据集,导致了严重的过拟合,那么这不是我们想要的结果.
3实验结果与分析
为了验证本文所提出的方法的有效性,进行了一系列的实验.首先介绍了实验设置、实验中所采用的数据集以及评价指标的定义.然后,通过比较本文所提出的方法与两种基准方法在5个评价指标上的对比,来验证本文所提出方法的有效性.
3.1实验环境
所有的实验都是在配备2.11 GHz Intel Core i5-10210U CPU和16 GB RAM的机器上进行.使用Python 3.7和Pytorch 1.4.0来实现我们提出的异常检测和分类机制.本文中使用的数据集是CIC- IDS-2017,由加拿大网络安全研究所提供.CIC-IDS-2017数据集采集自真实的网络环境,包含了8种常见的攻击和正常数据.数据集所包含的攻击类型有DoS、PortScan、Heartbleed、WebAttack、Infiltration、Botnet、Patator和DDoS.需要注意的是,Heartbleed和Infiltration的数量非常少,不到40个,因此我们在实验中删除这些攻击.表1展示了CIC-IDS-2017数据集中的各类攻击的数量.
过采样和欠采样的目的是改变数据库中数据不平衡的情况.从表1中可以看到,没有数据采样之前,数据库中各类数据所占的百分比是严重失衡的,这样会导致模型在训练的时候把数量较少的类别都归为大类,如果个别类的数量少,精度的值仍然很高,但这并不是我们希望的结果,并且此时精度这个指标是失效的.所以为了模型可以有更好的性能,采用过采样和欠采样的方法来处理数据集中数据不平衡的情况.采样后的数据分布也在表1中给出,此时分布就比较均衡.
实验中涉及的参数作如下说明:输入的特征数量为77个,总共分为7个类.我们提出的方法所使用的mini-batch的大小为64,学习率为10,Q、K、V的维度都为512.优化器采用的是Adam优化器.经典LSTM的mini-batch大小也为64,学习率为10.隐藏层大小为512,层数为3,dropout为0.2.
3.2评价指标
评价指标采用混淆矩阵[22]来表示所提出的检测和分类方法的性能.如表2所示,混淆矩阵包含有关分类器完成的实际和预测分类的信息.在混淆矩阵中,TP表示实际为正,分类器预测为正的样本数.FN表示实际为正,分类器預测为负的样本数.FP表示实际为负,分类器预测为正的样本数.TN表示实际为负,分类器预测为负的样本数.
然后根据混淆矩阵,定义了5个常用指标:准确率(A),精确率(P),召回率(R),F值(F)和误报率(F)来评估分类器的性能.
A是正确分类的样本数与所有样本数的比率,它的定义为
R是覆盖率的度量,用于度量将多少阳性样本正确分为阳性样本.它的定义如下:
P代表示例中分为阳性示例的比例.它的定义如下:
F是P和R的调和均值,其值与P和R中的较小值比较接近.它的定义如下:
F用于验证分类器是否错误地将攻击分类为正常攻击.可以通过使用如下公式计算得出:
3.3结果分析
将本文所述的方法与经典的LSTM模型和AMF-LSTM[23]进行比较,选择一个子数据集,将其70%作为训练集,30%作为测试集,图4,图5,图6分别表示了训练数据和测试数据来自同一数据集时在精确率、召回率、F-1值3项指标上的结果.
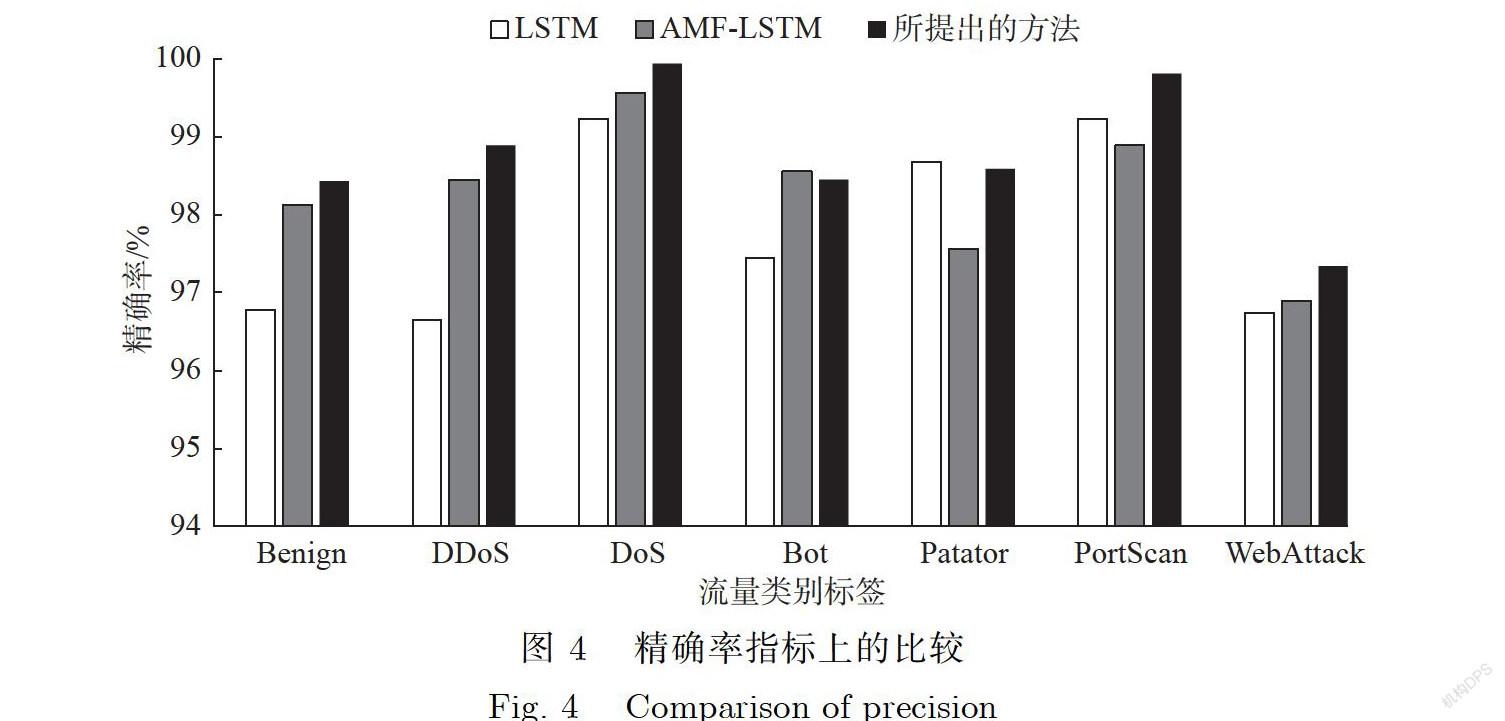
圖4绘制了本文所提出的模型与经典LSTM、AMF-LSTM[23]方法在精确率上的表现.据观察,本文所提出的模型在精确率指标上表现较好,可以有效区分攻击.例如,在正常类Normal中,本文提出方法的精确率最高达到了99.23%,平均水平在98.64%,比LSTM和AMF-LSTM分别高出1.58%和0.34%.
图5展示了召回率的性能.具体来说,本文所提出的模型在Normal类上的召回率为98.54%.在DoS类上,召回率的值分别比LSTM和AMF-LSTM的值高2.45%和1.58%.
图6显示了值的表现.从图6可以看出,在Dos和PortScan上,F的值分别达到99.32%、99.01%.这比其他两种方法要高得多.然而,无论是在图5还是图6中,3种方法在WebAttack类上的表现都不是很理想.可能的原因是WebAttack的数量没有其他类型的多,所以模型没有了解到更多的这种攻击类型.
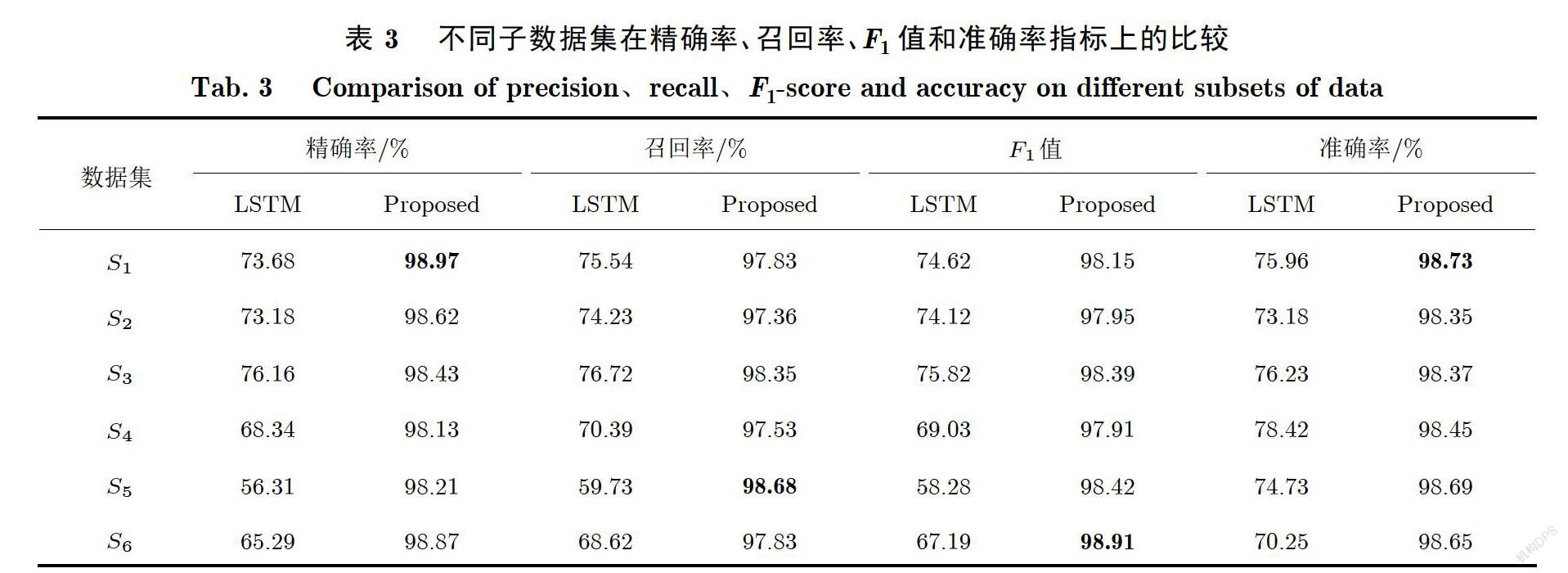
虽然本文所提出的方法在所有类别中的表现并不是最优秀的,但在泛化能力方面,本文所提出的方法具有明显的优势.为了验证泛化能力,本文所提出使用不同的子数据集作为测试数据集.表3显示了不同子数据集上精确率、召回率、F值和准确率的比较.从表3的数据可以清楚地看到,本文所提出的模型的性能比LSTM的性能高得多.具体来说,在6个不同的数据集上,最高的准确率达到了98.73%.同样,最高的精确率、召回率和F值分别达到98.97%、98.68%和98.91%.
除了以上4个指标外,还引入了误报率来考查误分类能力.从这个指标中,可以知道有多少攻击被误分类为正常流量.图7显示了误报率在不同子集的值.结果清楚地表明,本文所提出的方法的误报率值比LSTM的误报率值小得多,最高的只有0.69%,最低为0.41%.此外,LSTM的值达到了1.25%,且AMF-LSTM[23]方法的误报率为1.18%.结合表3和图7的结果可知,本文所提出的模型具有良好的通用性,而LSTM存在过拟合问题.
为了更好地观察模型的分类能力,利用混淆矩阵来观察各个类别的分类情况.结果如图8所示.横坐标代表真实标签,纵坐标代表预测值.对角线上的数值代表正确预测的数量.我们可以看到,除了Botnet和WebAttack类,分类器几乎可以正确分类.这是因为这两个类的样本数量较少,过采样产生的数据样本对分类有轻微影响.幸运的是,本文所提出的方法在其余类别中表现良好.总的来说,本文所提出的方法具有较高的准确率、较低的误报率和较强的泛化能力.
4总结
本文为了对网络异常流量进行检测和分类,提出了一种self-attention的多特征网络异常流量检测和分类方法.该方法不需要人力进行特征选择,可以自动提取特征之间的关系.
首先,应用self-attention技术来学习各特征之间的特征关系.在这种方式下,self-attention可以关注序列中的每一个特征,它很好地解决了长期依赖性的问题,对于一些新的复杂的动态网络攻击也能取得良好的性能.然后,对提取的特征关系进行编码和分析,达到检测和分类的目的.实验结果表明,与经典的LSTM和AMF-LSTM[23]方法相比,本文所提出的方案取得了优异的性能.在不同测试集上的验证结果表明,本文所提出的方案在准确率上提高了1.65%,在精确率上提高了1.27%,在召回率上提高了1.33%,在F值上提高了0.98%,误报率降低了1.1%.
[参考文献]
[1]CHANDOLA V,BANERJEE A,KUMAR V. Anomaly detection:A survey [J]. ACM Computing Surveys,2009,41(3):15.
[2]GARG S,SINGH A,BATRA S,et al. EnClass:Ensemble-based classification model for network anomaly detection in massive datasets[C]// 2017 IEEE Global Communications Conference. IEEE,2017. DOI:10.1109/GLOCOM.2017.8255025.
[3]LIMTHONG KTAWSOOK T. Network traffic anomaly detection using machine learning approaches [C]// Network Operations and Management Symposium. IEEE,2012:542-545.
[4]PACHECO F,EXPOSITO E,GINESTE M,et al. Towards the deployment of machine learning solutions in network traffic classification:A aystematic survey [J]. IEEE Communications Surveys and Tutorials,2019,21(2):1988-2014.
[5]SHEEN S,RAJESH R. Network intrusion detection using feature selection and decision tree classifier [C]// 2008 IEEE Region 10 Conference. IEEE,2008. DOI:10.1109/TENCON.2008.4766847.
[6]KUANG F,XU W,ZHANG S. A novel hybrid KPCA and SVM with GA model for intrusion detection [J]. Applied Soft Computing Archive,2014(18):178-184.
[7]FARNAAZ N,JABBAR M A. Random forest modeling for network intrusion detection system [J]. Procedia Computer Science,2016(89):213-217.
[8]WU G,ZHAO Z,FU G,et al. A fast kNN-based approach for time sensitive anomaly detection over data streams [C]// International Conference on Computational Science. 2019:59-74.
[9]GUMUSBAS D,YILDIRIM T,GENOVESE A,et al. A comprehensive survey of databases and deep learning methods for cybersecurity and intrusion detection systems [J]. IEEE Systems Journal,2021,15(2):1717-1731.
[10]WANG W,ZHU M,WANG J,et al. End-to-end encrypted traffic classification with one-dimensional convolution neural networks [C]// 2017 IEEE International Conference on Intelligence and Security Informatics. IEEE,2017:43-48.
[11]NGUYEN T T T,ARMITAGE G. A survey of techniques for internet traffic classification using machine learning [C]// IEEE Communications Surveys and Tutorials. IEEE,2008:56-76.
[12]YIN C,ZHU Y,FEI J,et al. A deep learning approach for intrusion detection using recurrent neural networks [J]. IEEE Access,2017(5):21954-21961.
[13]HOCHREITER S. The vanishing gradient problem during learning recurrent neural nets and problem solutions [J]. International Journal of Uncertainty,Fuzziness and Knowledge-Based Systems,1998,6(2):107-116.
[14]ZENG Y,GU H,WEI W,et al. Deep-full-range:A deep learning based network encrypted traffic classification and intrusion detection framework [J]. IEEE Access,2019(7):45182-45190.
[15]WANG S,XIA C,WANG T. A novel intrusion detector based on deep learning hybrid methods [C]// 2019 IEEE 5th Inti Conference on Big Data Security on Cloud (BigDataSecurity),IEEE Inti Conference on High Performance and Smart Computing,(HPSC)and IEEE Inti Conference on Intelligent Data and Security (IDS). IEEE,2019:300-305.
[16]KIM T,SUH S C,KIM H,et al. An encoding technique for CNN-based network anomaly detection [C]// 2018 IEEE International Conference on Big Data. IEEE,2018:2960-2965.
[17]SMAGULOVA K,JAMES A P. A survey on LSTM memristive neural network architectures and applications [J]. The European Physical Journal Special Topics,2019,228(10):2313-2324.
[18]RUI T,ZOU J,ZHOU Y,et al. Convolutional neural network simplification based on feature maps selection [C]// 2016 IEEE 22nd International Conference on Parallel and Distributed Systems. IEEE,2016:1207-1210.
[19]SINDAGI V A,PATEL V M. A survey of recent advances in CNN-based single image crowd counting and density estimation [J]. Pattern Recognition Letters,2018,107(1):3-16.
[20]VASWANI A,SHAZEER N,PARMAR N,et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017:5998-6008.
[21]WU X,CAI Y,LI Q,et al. Combining contextual information by self-attention mechanism in convolutional neural networks for text classification [C]// International Conference on Web Information Systems Engineering. 2018:453-467.
[22]CAI N,MA C,WANG W,et al. Effective self-attention modeling for aspect based sentiment analysis [C]// International Conference on Computational Science. 2019:3-14.
[23]ZHU M,YE K,WANG Y,et al. A deep learning approach for network anomaly detection based on AMF-LSTM [C]// IFIP International Conference on Network and Parallel Computing. 2018:137-141.
(責任编辑:陈丽贞)
猜你喜欢
计算技术与自动化(2022年2期)2022-07-04
现代电子技术(2016年23期)2017-01-12
电脑知识与技术(2016年25期)2016-11-16
计算机时代(2016年9期)2016-10-28
电脑知识与技术(2016年15期)2016-07-04
电脑知识与技术(2016年14期)2016-06-30
计算技术与自动化(2015年4期)2016-03-25
湖南师范大学学报·自然科学版(2015年4期)2016-03-01
现代电子技术(2015年12期)2015-06-15
