
基于异构网络的无监督作者名称消歧
2021-01-01 11:52郭晨亮林欣殷玥
华东师范大学学报(自然科学版) 2021年6期
郭晨亮 林欣 殷玥















摘要:作者名称消歧是构建学术知识图谱的重要步骤.由于数据缺失、人名重名、人名缩写导致论文重名现象普遍存在,针对无法充分利用信息和冷启动问题,提出了基于异构网络的无监督作者名称消歧方法,自动学习同作者论文特征.用词形还原预处理作者、机构、标题、关键词的字符,用word2vec和TF-IDF(Term Frequency-Inverse Document Frequency)方法学习文本特征嵌入表示,用元路径随机游走和word2vec方法学习结构特征嵌入表示,融合文本、结构特征相似度后用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类算法、合并孤立论文方法完成消歧.最终根据实验结果,模型在冷启动无监督作者名称消歧的小数据集和工程应用中优于现有模型,表明了模型有效且可以实际应用.
关键词:作者消歧;学术知识图谱;异构网络;元路径随机游走
中图分类号:TP182文献标志码:ADOI:10.3969/j.issn.l000-5641.2021.06.015
Unsupervised author name disambiguation based on heterogeneous networks
GUO Chenliang1,LIN Xin1,YIN Yue2
(1. School of Computer Science and Technology,East China Normal University,Shanghai 200062,China;2. Shanghai Technology Development Co.,Ltd.,Shanghai 200031. China)
Abstract:Author name disambiguation is an important step in constructing an academic knowledge graph. The issue of ambiguous names is widely prevalent in academic literature due to the presence of missing data,ambiguous names,or abbreviations. This paper proposes an unsupervised author name disambiguation method,based on heterogenous networks,with the goal of addressing the problems associated with inadequate information utilization and cold-start;the proposed method automatically learns the features of papers with the ambiguous authors' name. As a starting point,the method preprocesses strings of authors,organizations,titles,and keywords by lemmatization. The algorithm then learns the embedded representation of text features by the word2vec and TF-IDF methods and learns the embedded representation of structural features using the meta-path random walk and word2vec methods. After merging features by similarity of structure and text,disambiguation is done by a DBSCAN clustering algorithm and merging isolated papers. Experimental results show that the proposed model significantly outperforms existing models in a small dataset and in engineering applications for cold-start unsupervised author name disambiguation. The data indicates that the model is effective and can be implemented in real-world applications.
Keywords:author disambiguation;academic knowledge graph;heterogeneous network;meta-path random walk
0引言
近年來,随着网络数据的不断积累与发展,电子形式的学术论文数据也越来越多,学术资源的共享使研究人员越来越依赖公共学术资源.为了更好地进行学术知识图谱的构建和使用学术知识图谱对论文数据进行查询,学术论文的作者名称消歧任务具有重要的意义,关系到信息检索的准确性.学术知识图谱是由论文、作者、机构等信息构成的知识图谱,作者消歧是构建学术知识图谱的重要步骤. 近年来,已经有许多相关学者对作者消歧领域进行研究,但这个问题目前仍然没有得到较好的解决.
由于长期以来论文相关信息的缺失、论文作者名字常用缩写、现实生活中的重名现象,导致论文作者名字与作者本人难以对应,可能出现两种问题:(1)同一个作者在不同的论文中用了不同的名字形式,有的是缩写,有的是全称;(2)由于重名或姓名缩写可能有相同的名字形式,无法判断作者是否为同一个人.已经有一些方法对监督学习和无监督学习的不同情况,使用相似度规则进行匹配、使用概率模型进行分类、使用网络表示学习聚类等方法尝试解决这个问题.大多数消歧方法的主要过程是,首先对具有相同名称作者的一组论文学习它们的特征表示,然后根据不同文章的特征进行聚类来获得哪些文章属于同一作者的消歧结果.
目前对于冷启动作者消歧问题,存在的主要挑战是:(1)由于标记数据需要大量的成本,如何在监督数据不足甚至无监督的情况下获得较好的作者消歧结果.(2)在获取论文的特征表示时,有些论文存在相关信息的缺失现象,如何对这些缺失数据进行合理的处理.⑶如何综合利用论文的作者、机构、年份、标题、摘要、内容、来源、关键词等相关信息较好地学习文本特征表示.⑷如何学习论文、作者异构关系网络中的结构信息并与文本特征较好地结合,从而使聚类效果更好.
本文根据作者名称消歧任务的特点,提出了一种基于异构网络特征学习的无监督作者名称消歧方法.我们首先对作者与机构名称、标题与关键词的字符形式进行词形还原等标准化处理,然后用基于元路径随机游走[1-2]的异质网络嵌入方法学习論文的结构特征,用word2vec词向量、TF-IDF(Term Frequency-Inverse Document Frequency)[3]、词向量随机打乱方法加权学习论文的文本语义特征,融合论文的结构特征和文本特征相似度,在融合相似度时用最优权重搜索方法,然后用DBSCAN(Density-Based Spatial Clustering of Applications with Noise)聚类方法,制订相似度规则合并孤立点得到消歧的结果.最后在AMiner数据集[4]、SCI论文数据构建的一个小数据集上进行测试,证明我们的方法可以获得较好的消歧效果,并应用到项目中对1800万篇SCI和600万篇Elsevier论文数据进行消歧,取得了较好的效果.
本文的主要贡献总结如下:
(1)提出了一种基于异构网络特征学习的无监督作者名称消歧的方法,分别学习论文的结构特征、文本特征并融合,根据不同特征的相似度完成聚类.
(2)在以前方法基础上进行改进,对作者与机构名称、标题与关键词的字符形式使用词形还原等预处理方法,使用TF-IDF[3]、词向量随机打乱的方法表示论文文本特征,使用最优权重搜索方法融合结构、文本特征的相似度.
(3)使用AMiner数据集[4]、SCI论文数据进行实验测试并应用,统计了数据集中的数据分布与缺失,与其他现有方法进行对比证明了本文所提出方法的较好效果,对比删除模型部分的效果证明了模型结构设计的有效性,对比了一些模型参数在不同取值情况下的实验效果寻找最优取值.
本文的剩余部分结构如下:第1章介绍作者消歧的相关研究;第2章介绍作者消歧问题的形式化定义;第3章介绍本文所提出的基于异构网络的无监督作者名称消歧方法;第4章介绍实验所用到的数据和分析实验效果;第5章总结并展望未来的研究方向.
1相关工作
在这部分介绍作者消歧的相关研究.目前,作者消歧方法可以分为监督学习、无监督学习,监督学习通常需要借助来自网络的外部知识或已有的标记数据进行模型训练,无监督学习大多数依靠自然语言处理中的词向量、网络表示学习等方法学习特征.此外,还有一些方法主要研究如何合理确定聚类类别数量、如何更新消歧结果、如何使人类参与迭代更新模型和主动学习方法.
监督学习的作者消歧方法需要一组已经标记的数据集,用于训练模型学习消歧任务的聚类方法,标记数据可以通过人工标记也可以来自网络中.文献[5]中用数据训练每个作者姓名的分类模型,用生成模型的朴素贝叶斯和判别模型的支持向量机两种方法预测论文属于哪个作者.文献[6]中提出了急切的EAND、延迟的LAND和自适应的SLAND三种关联作者名称的消歧方法,用训练数据中的论文特征结合概率策略和规则识别作者身份.文献[7]中提出了两阶段的聚类方法,通过多次聚类更好地学习论文特征.文献[8]中用维基百科的资源构造网络,对特征信息用HAC层次聚类消歧.这类方法虽然效果较好,但需要大量获取监督数据成本高且无法扩展到更多的数据量,具有局限性.
无监督学习的方法自动学习论文的特征表示,然后对来自同一作者名称的论文进行聚类.文献[9]用马尔可夫随机框架建立概率模型,用隐藏变量表示一组同名作者论文对应的真实作者,提出了一种动态估计聚类种类数的方法,可以在同名作者数据量差别较大时避免设置参数的误差.文献[10]中构建了作者单步与两步合作、作者一论文、论文相似性关系网络,通过建立概率模型制订规则合并网络结点聚类.GHOST方法[11]提出了构建图结构、选择有效路径、计算相似度、聚类、用户反馈的消歧方法,并获得了较好的准确率,较好地分析了关系网络的拓扑结构.文献[12]和[13]用网络表示学习方法消歧,文献[12]首先结合合作关系等信息构建作者间社交网络,然后通过网络结构获取作者间相似性对论文的同名作者进行聚类,文献[13]在论文异构网络中用随机游走学习特征,但这些方法只考虑了论文间的结构信息而较少考虑文本.文献[14]提出了一种概率模型构建作者-作者、作者-论文、论文-论文的多个网络结构共同学习同名作者论文的特征,但这种方法为了保护隐私没有充分利用论文的文本特征.文献[15]用手动提取特征和学习文本向量结合的方式进行消歧,利用负样本感知全局特征.Diting方法[16]根据标题、机构等信息建立多个异构网络用正负样本学习论文特征,用无监督或结合网络信息的半监督完成聚类.在OAG比赛第一名方法中,分别学习了论文的关系和语义表征并进行融合聚类.文献[17]和[18]中用对抗网络学习进行消歧,文献[17]用对抗网络学习异构网络的特征,文献[18]用对抗网络判断两篇论文是否属于同一作者.
文献[19]用GCN学习异构网络特征,并提出了加入新论文增量更新消歧结果的方法.文献[20]中用主动学习消歧的方法,对已完成的消歧结果制订策略抽取一组数据向用户进行询问,通过交互方式学习更多有效信息改善结果.文献[4]结合了结构特征和文本特征的表示学习,用监督数据学习自动获取聚类种类,并允许人工加入限制条件不断优化聚类结果,用两篇论文是否属于同一作者、某篇论文是否属于某个作者进行标记.对文献[4]有用的细节进行改进,得到了效果较好的无监督作者名称消歧结果.
一些词义消歧[21]的方法与作者名称消歧问题相似,都是为了识别不同位置多个名称的出现是否对应现实生活中的同一个实体,但区别是词义消歧有上下文语义信息而作者名称只有相关的论文信息.对于学术知识图谱,知识图谱间的实体对齐任务[22]也是寻找图谱中表示相同实体的不同结点,但区别是实体对齐用于两个知识图谱之间而作者名称消歧用于一个知识图谱内部.
2问题定义
作者消歧任务可以定义为已知一组论文数据T,每篇论文有对应的作者、机构、来源、发表时间、题目、摘要、关键词信息,其中机构为作者所在的机构,来源为论文发表的期刊会议.由于每篇论文中有多个不同的作者,可以将具有同名作者的一组论文提取出来,对于某个作者名称a,可以得到对应的一组论文,这组论文由多个名字为a的作者创作,需要对这n篇论文进行聚类,把它们分割成c个不相交的集合,,…,,满足,i,j=1,2,…,c且i≠j,,每个集合对应一个现实生活中的作者,分别对应到c个作者.作者消歧模型需要确定同名作者数量。的取值和论文与真实作者的对应关系.
例如,表1是作者名称为LIANG Hongbin的5篇论文的信息,对这组论文进行消歧的结果为3个不同的作者的论文集合,分别为{P,P},{P},{P,P}.观察数据可以发现属于同一作者的论文通常具有较多的相同合著者和相似的机构名称,并具有相似的文本内容,如P与P中都包含了作者LI Xia,P与P、P与P都含有接近的机构名称与关键词.但属于不同作者的论文有时会有同名的合著者或机构名称有相似性,如P,P都包含作者PENG Daiyuan,P,P,P的机构名称中都包含engineering.
本文主要针对无监督的情况进行研究,在没有额外已知数据的情况下,作者消歧任务主要依靠论文的文本信息、论文与作者间的关系计算完成.对于一篇论文的相关信息,由于作者名称、机构名称基本不包含语义信息,我们将这些内容看作论文的结构信息处理,将其他信息作为论文的语义信息处理.我们分别学习了论文的结构和文本的特征表示,根据论文与作者的关系构建论文、作者、机构的异构关系网络学习论文的结构特征表示,通过论文自身的语义信息学习论文的文本特征表示,融合两种特征的相似度完成聚类.
3模型结构
本章介绍用于解决无监督情况下作者名称消歧问题的一种模型,详细介绍模型每部分的结构和特点,模型结构如图1所示.图1中左侧为包含标题、作者、摘要、机构、出版机构、关键词信息的同名作者论文集,首先,用词形还原、分词、去停词的方法分别对作者名称、机构名称、标题、关键词进行规范化和预处理,定义了两个作者名称字符串的比较规则,用于减少错误字符的干扰.然后,分别学习论文的结构特征向量、文本特征向量表示,用异构网络上的元路径随机游走方法获得论文的结构特征向量表示,用所有文本数据word2vec训练词向量、词向量随机打乱、统计词频计算TF-IDF同加权求和词向量的方法,以此获得论文的文本特征向量表示.最后,分别计算结构、文本特征的相似度并融合相似度,用DBSCAN方法对论文进行初步聚类,对信息缺失无法学习文本特征、关联较弱无法学习结构特征聚类后是孤立点的论文与初步聚类的结果继续计算相似度合并,得到最终消歧聚类的结果,完成论文作者名称的消歧任务.
下面分别描述模型中5个步骤的具体实现方法,包括:作者名称、机构名称、标题与关键词预处理,异构网络上的结构特征学习,论文相关信息的文本特征学习,融合特征表示,聚类消歧.
3.1作者名称、机构名称、标题与关键词预处理
由于从论文数据中提取到的作者名称字符串格式不规范,需要预先对作者名称进行处理,改为规范的格式.如果作者名称为中文,首先将中文转换成对应的拼音.对于每個作者名称,需要将字母全部转换成小写,去除其中的特殊符号,将其中连续的多个空格替换为一个空格,最后得到作者名称的标准形式.当比较两个不同的作者名称时,若“a,b,c,d,e”表示单词,将名称为“a b”和“b a”的两个作者、名称为“c d e”和“e c d”的两个作者视为同名作者,例如“aldstadt joseph”和“joseph aldstadt”可以视为同一个名称.通过上述的预处理过程,可以减少作者名称中不同的特殊符号、空格、语序的影响,从而更准确地识别相同的作者名称.
在异构关系网络G(V,E)中用到了机构中的单词,对机构分词时需要首先将非字母字符替换为空格,大写字母全部变成小写字母,然后按空格分词,对比892个单词的停词库去除机构名称中的停词,去掉名称中长度小于3的词,对剩余单词的形式进行词形还原,保留词形还原前后的所有单词作为机构的分词结果.在词形还原时使用nltk先进行词形标注,然后对其中的名词、动词、形容词等按类别分别进行词形还原.上述词形还原的方法也被应用到标题、关键词的预处理中.
例如,作者名称为“Aldstadt,Joseph.”时,将其修正为“aldstadt joseph”,当遇到名称为“Joseph,Aldstadt”的作者时,由于反转单词顺序后相同可以匹配为同一个名称,修正为“joseph aldstadt”,对于机构名称“State Key Lab. of Struct. Chemistry”,经过上述处理后得到机构的分词结果“key、lab、struct chemistry”;对于标题名称“Determining message delivery delay of controller area networks”,词形还原将“determining”改为“determine”,将“networks”改为“network”.
3.2异构网络上的结构特征学习
为了在异构网络上学习论文点的结构特征表示,用基于元路径的随机游走算法[1-2]进行特征表示的学习.首先定义论文的异构网络,然后用基于元路径的随机游走方法首先在异构网络中采集多条按元路径规则随机游走得到的路径,这些路径转换为多个由论文点组成的序列,将每个论文点看作一个单词,用这些序列作为训练word2vec的方法的输入,得到每个论文点对应的结构特征词向量,重复这个过程多次,并把每次获得的特征向量计算平均值,得到最终的论文结構特征表示.
根据论文的作者、机构,这些结构信息可以构建与作者a有关的论文、作者、机构间的异构关系网络G(V,E).网络中的点集合V=T∪A∪W,其中T={t,t,…,t}表示与作者a有关的所有论文,A表示与论文集合T相关的所有作者的集合,P表示与论文集合T相关的所有机构的集合,W表示P中机构名称包含的所有单词集合.因此,每篇论文、每个作者、每个机构中的单词分别对应一个点.网络中的边的集合,其中论文与作者关系集合,表示论文与机构单词关系集合,若作者a∈A创作了论文t∈T,将对应的两个点连接边;若论文t的机构是p∈P,且p的名称包含单词w∈W,将对应的两个点连接边.
例如,图2是表1中5篇论文形成的异构网络图,其中圆形表示论文,三角形表示作者,正方形表示机构分词,论文与作者、机构包含的词连接,图中只画出了连接多个论文点的作者和机构词.如P的机构名称分词中包含college、mechanical、engineering,所以与对应的3个机构词连接;P,P都包含作者LI Xia,所以都与LI Xia连接.
具体来说,为了充分学习每个论文点的向量表示,在随机游走采集元路径时,以每个论文点作为起点采集b条“论文-作者-论文-机构单词-论文”重复r次的随机游走路径,首先选择某个论文点t∈T作为起点,随机选择一个与t连接到作者点a∈A的边,再随机选择一个与a连接到论文点t∈T的边且i≠k,若找不到满足条件的边(a,t)或(a,t),就跳过这一步骤的随机游走过程,否则将已经走过的a,t点加入这条路径中;然后随机选择一个与t连接到机构单词点w∈W的边,再随机选择一个与w连接到论文点tT的边且k≠m,若找不到满足条件的边(w,t)或(w,t),就跳过这一步骤的随机游走过程,否则将已经走过的w,t点加入这条路径中.
重复上述过程r次就完成了对一条路径的随机游走采集,并且路径中只保留其中论文点组成的序列,不保留路径起点的论文点t.用这个方法采集论文t为起点的b条随机游走路径,最终将以每个论文点为起点的n组路径作为word2vec的训练输入,并且设置最小词频为1,词向量维数为d,训练得到每个论文点的特征向量表示.若某个论文点没有出现在随机游走的路径中,用word2vec方法无法得到这个点的特征向量表示,将这个点的特征向量设为零向量.
为了让每个论文点有更大概率出现在随机游走产生的序列中,从而得到论文点更准确的结构特征表示,用bagging的方法,重复s次采集随机游走元路径和word2vec训练词向量的过程,得到s组论文点的结构特征向量表示,计算平均值得到最终的每篇论文t结构特征向量表示.
如果考虑这个关于作者a的异构网络中两篇论文间的关系,可以发现包含路径“论文-作者-论文”形成的CoAuthor关系和路径“论文-机构-论文”形成的CoOrg关系.如果在集合T中的两篇论文t,t(i,j=1,2,…,n且i≠j)间具有CoAuthor共同作者关系,连接点t,t的“论文-作者-论文”的路径数量就对应了论文t,t间的共同作者数量;如果两篇论文t,t间具有共同机构CoOrg关系,连接点的“论文-机构-论文”数量就对应了论文t,t间的机构名称中共同单词的数量,也就是机构的相似度.
根据随机游走的方法,从论文t经过作者点游走到论文t的概率与两篇论文间的共同作者数量成正比,若论文t与其他论文间的共同作者太少就有可能在这一步骤中查找路径失败而跳过.从论文t经过机构单词点游走到论文t的概率与两篇论文机构间的共同单词数量成正比,与机构间相似度相关,若论文t与其他论文机构的相似度太低就有可能在这一步骤中查找路径失败而跳过.因此,随机游走得到的路径可以较好地将论文间关于作者、机构而产生的联系强度转换为随机游走路径中词的相邻概率,使word2vec方法较好地学习论文的结构特征表示.而将机构名称拆分为词并进行词形还原的方法,可以将机构名称中包含的少量语义信息转换为结构信息进行学习,同时考虑到了同一机构文本相似的不同表达方式.
3.3论文相关信息的文本特征学习
为了在异构网络上学习论文点的文本特征表示,首先用论文的标题、来源、摘要、年份、机构word2vec训练词向量,然后计算每个单词的逆文档频率值IDF(Inverse Document Frequency)[3],最终用IDF值加权平均论文信息中所有词向量得到论文的语义特征表示.
具体来说,对于一篇论文t∈T(i=1,2,…,n),将论文的标题、来源、摘要、年份、机构、关键词的字符串按空格分隔拼接,去除其中的特殊符号、非数字字母的字符,将字母转换为小写,分词后去除21种含义较少的停词,将得到的一组词随机打乱顺序,得到论文t相关的一个单词可重复的长度为z个单词的语句u={w,w,…,w},这个语句表示了论文的文本信息.将T中n篇论文的文本信息组成的一组语句U ={u,u,…,u}作为训练词向量word2vec的输入,词向量维数为d,得到每个文本单词的向量表示.
逆文档频率IDF用来评估一个单词在一组语料中的重要程度,包含一个词的文档数越多,这个词的IDF值就越低;词频TF值表示某个词在一个文档中的出现频率,一个词在一个文档中出现次数越多,这个词就越重要;词x在文档y中的TF-IDF值[3]o是通过将词的TF值q与IDF值u相乘来表示词的重要程度.若共有N篇文档,包含词x的文档数为N,在文档y中共有M个词,其中有M个词为x,计算公式为
将每篇论文对应的一组文本看作一个文档,统计词频计算每个单词的IDF值,然后对每篇论文对应的一组单词的向量表示按IDF值加权求和,若单词w的IDF值为u,TF-IDF值为o,词向量为u,论文t的文本特征计算为
若论文t的文本信息u包含的单词集合为,单词在u中重复c次,,论文的文本特征也可以表示为词集合的词向量按TF-IDF的加权平均为
用TF-IDF对论文文本词向量加权求和可以对词的重要性进行准确评估,从而得到更精确的论文文本特征向量表示.对没有相关文本信息的论文,将它的文本特征向量设为零向量.
3.4融合特征表示
为了融合论文结构、文本两种特征的向量表示,首先将结构、文本特征为零向量的论文加入孤立点集合G,对剩下的论文分别用两种特征向量计算任意两篇论文间的余弦相似度,得到论文间的结构相似度矩阵M和文本相似度矩阵M,令I为单位矩阵然后将两个相似度矩阵加权求和M=(M+eM)/(I+eI)得到融合后的相似度矩阵,融合的权重比例e用最优权重搜索的方法寻找.
在最优权重搜索的方法中,为获得最优的e,通过在已知正确结果的消歧测试数据集上等间距尝试0.5到5之间的多个权重e取值的实验效果,并对每次取值进行多次实验取均值得到结果,并在准确率较高的取值附近缩小间距继续实验,最终选择所有实验中准确率最高的e值作为模型的比例,部分实验结果在第4章中.
3.5聚类消歧
使用DBSCAN算法采用融合得到的论文间相似度矩阵对不在集合G内的论文进行聚类,将聚类中的孤立点和集合G内的孤立点通过比较相似度加入已有聚类或生成新的聚类,最终完成对与作者a相关所有论文的聚类.
DBSCAN是一种基于密度的聚类方法,使用扫描半径R和最小选取个数I作为参数,每次将扫描半径内最小包含点数较大的点合并,可以将紧密相连的任意形状的一些点聚类为一组,并且可以自动选择聚类数量而不需要参数指定,可以在无监督的情况下完成自动聚类.
为了计算孤立点与任意论文的相似度,定义论文t,t间相似度的计算方式为
f(t,t)=df(A,A)+df(P,P)+df(S,S)+df(L,L),
其中,d,d,d,d是可调整的超参数,A,A分别为两篇论文的作者集合,P,P分别为两篇论文的机构单词集合,S,S分别为两篇论文的来源单词集合,L,L分别为两篇论文的标题、关键词的单词集合,函数f(X,Y)表示集合X,Y的交集大小,函数f(X,Y)集合X,Y的交集大小除以并集大小.其中,对论文来源单词的分词进行与机构分词同样的词形还原处理,保留词形还原前后的所有单词.
首先,设置阈值F,对于每篇论文t∈G,查找与t相似度最高的论文,即f(t,t)≤f,k=1,2,…,n.若论文,查找与论文相似度最高的论文且j∉{j,j,…,j},重復直到.若相似度,将论文t合并到所在的聚类,否则将论文t留在G中,完成第一轮聚类合并.
然后,对于G中剩余的论文,若任意两篇论文t,t∈G的相似度f(t,t)≥F,将它们合并为同一个聚类,使用并查集算法完成这个过程,完成第二轮聚类合并,得到最终的论文聚类结果.
4实验结果
4.1数据集与实验设置
在学习异构网络结构特征时,设置元路径重复次数r=25,设b为随机游走路径采集数量,d为词向量维数,每篇论文作为起点采集b=10条路径,使用随机游走路径训练词向量时使用d=100维词向量,设置窗口大小为10,使用CBOW方法,最小词频为1,设置负采样数为25;在学习论文的文本特征时,训练词向量时使用d=100维词向量,设置窗口大小为5,最小词频为2,负采样数为5,使用CBOW方法;在特征融合时,使用效果最好的权重e=3.0;在聚类消歧时,设置DBSCAN的参数R=0.2,I=1,设置参数d=3/2,d=1,d=1,d=1/3,阈值F=1.5.
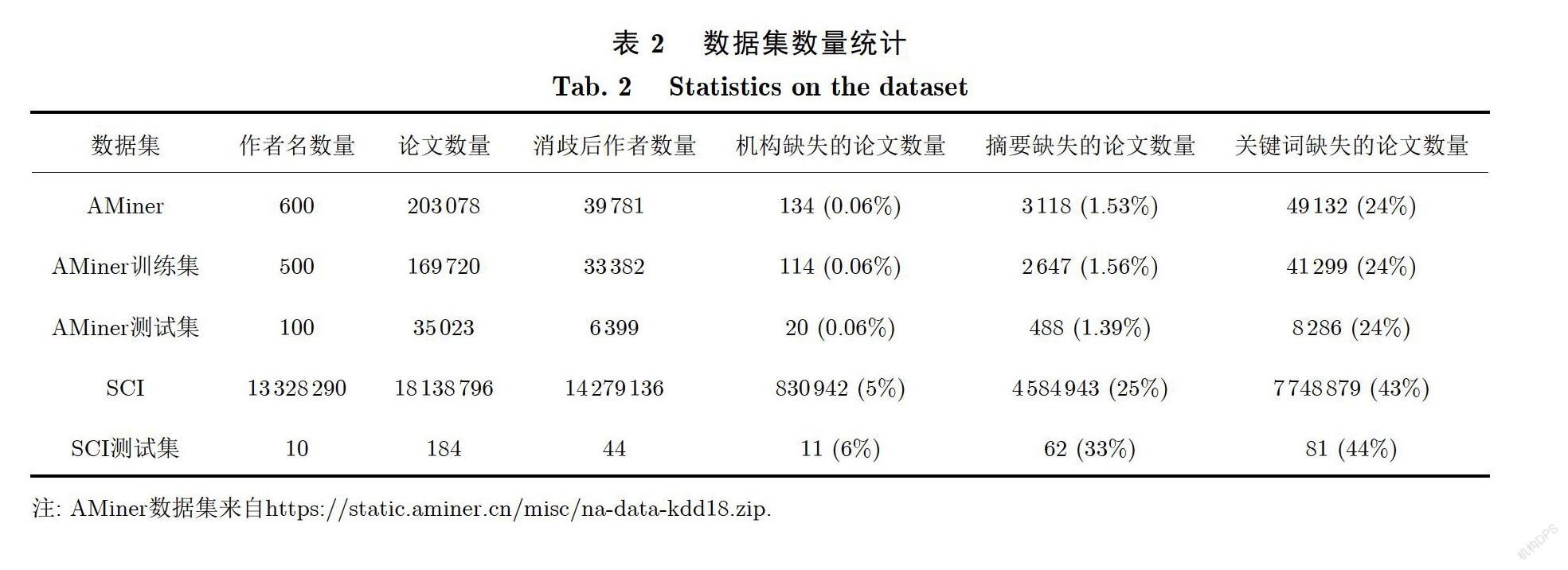
使用AMiner[4]的数据集、SCI论文数据构建的一个小数据集上进行测试.AMiner的数据集中包含600个同名作者的203078篇论文,每篇论文包含标题、摘要、作者及其所在机构、年份、来源、关键词,并将数据分成了500个作者名的训练集和100个作者名的测试集,由于我们是无监督训练的方法,将所有数据直接用于测试,并使用包含100个作者名的测试集与其他方法进行对比.SCI论文数据构建的测试数据集包含10个同名作者的184篇论文,每篇论文包含标题、摘要、作者、机构、年份、来源、关键词.为了将两个数据集转换为同一格式,将AMiner数据集中的待消歧作者的机构信息作为机构,将所有作者的机构信息加入文本信息用于学习文本特征.数据集的数量统计在表2中,包含了数据集的作者、论文数量以及信息缺失情况,没有提及的来源、出版时间等信息没有缺失,部分作者对应的论文数量在表3中.
从表2中可以发现论文的相关信息都存在部分缺失,主要是在机构、摘要、关键词的缺失,并且关键词缺失比较严重,摘要、机构的数据相对完整,在AMiner数据集中机构、摘要基本完整,关键词有24%的论文数据缺失;在SCI数据集中机构、摘要、关键词的缺失分别为5%、25%、43%,SCI数据缺失比例相对更高.从表3中可以发现每个作者的论文数量为5到20篇.
为了评价实验结果,采用与AMiner方法[4]中相同的成对F值评价方式,对于一个作者名称的消歧结果,比较任意两篇论文对是否属于同一作者的分类结果,属于同一类且分类为同一类的论文对数量。v称为真阳性,属于同一类且分类为不同类的论文对数量v称为假阴性,属于不同类且分类为同一类的论文对数量v称为假阳性,计算召回率值v、精确率值v、F值的公式为
对于多个作者名称的平均F值,首先计算每个作者名称数据的召回率v、精确率v的平均值,然后使用F值的公式计算平均的F值,这种计算方法可以给每个作者名称均匀的权重并合理计算实验的平均效果.
4.2实验结果
在测试时,用有监督的AMiner[4]和无监督的概率模型[14]、GHOST[11]、OAG比赛第一名4种方法在AMiner数据集上进行对比测试,测试结果在表4中,使用我们的方法在SCI数据集上进行消歧,并人工标记少量数据进行评价.AMiner数据集上实验对比的结果在表4中,SCI数据集上的测试结果在表5中.对比实验效果可以发现,我们的方法比其他4种对比的方法总体效果更好,并且AMiner方法[4]使用了500个作者名称的训练数据,而从表4的本文方法100个均值的F值可以看出,我们的方法在无监督的情况下达到了更好的效果.
为了验证模型每个部分的效果,我们删除了一些模型中的部分进行对比,包括只用结构特征计算相似度、只用文本特征计算相似度、去除词形还原等单词预处理、去除TF-IDF加权、去除文本特征词向量训练的随机打乱、去除关键词或来源或摘要信息,结果在表6中.
对比实验结果可以发现,去除模型中任意部分准确率都会下降.只用结构特征的效果比只用文本特征的效果更好,但明显比同时使用的效果更差,在作者消歧问题中结构信息比文本信息具有更加重要的作用,但需要两者同时考虑才能获得较好的效果.对文本特征训练时进行词向量打乱分词顺序很重要,对比表6 AMiner测试集上原始模型和去除词向量随机打乱的F值发现产生了4.77%的F值提升,可能是因为简单拼接论文的标题、机构等文本信息由于文本较短不能很好地学习词义,而打乱单词顺序可以在单词之间、论文的不同信息之间产生更多关联.单独去除来源、关键词、摘要信息对实验结果的影响都不明显,所以论文某个单一信息的使用方式对聚类效果影响不大,OAG比赛第一名方法没有在训练词向量时随机打乱单词顺序但准确率高,可能是由于没有使用关键词用于聚类相似度、没有使用摘要用于文本特征表示,雖然没有更好地学到文本信息,但也减少了多余信息的干扰.因此实验效果的提升是模型多个部分共同作用的综合效果,与融合论文相关信息的方式有关. 只用文本特征的召回率v明显大于精确率v,而其他大多数方法都是召回率v小于精确率v,因此利用文本信息更容易完全找出属于同一作者的论文对,但更容易将不同作者的论文合并为同一作者而出错.
為了探索模型参数的最佳取值,我们对融合特征使用的权值e、聚类孤立点集合的相似度阈值F、随机游走路径采集数量b、词向量维数d、随机游走路径长度r不同取值的情况进行实验测试,实验结果在表7—9和图3中.
为了寻找准确率最高的融合特征使用的权值e,对e取值范围为[0.5,5]的情况进行测试,可以发现e的值过高或过低都会使准确率下降,当e取值为1.3和3.0附近时准确率较高,而当e=3.0时得到效果最好,因此文本特征和结构特征有相似的重要性,在融合结构特征和文本特征时,文本特征相似度数值的权重应该比结构相似度数值的权重更高.为了研究聚类孤立点集合的相似度阈值F对实验结果的影响,测试了F取值为[0.5,2.5]的实验效果,F取值过高或过低都会使聚类不准确而使F值降低,当F=1.5时获得较好效果.为了研究元路径随机游走以每篇论文为起点的路径采集数量b的值对结果的影响,测试了b取值为[5,25]的效果,若b取值过低则采样数量太少而不足以学到图中的特征,若b取值过高则学到了过多的噪声信息而影响结构特征学习,当b=10时获得较好效果.为了研究词向量维数d的影响,对d=10,20,50,100,200的取值分别进行测试,可以看出词向量维数过少不足以表示论文特征而使准确率严重下降,词向量维数过多会导致参数过多使模型准确率逐渐下降.为了研究随机游走路径长度r的影响,对r=10,25,35,50,100的取值分别进行测试,可以看出路径长度太短不能生成足够长的路径而难以表达结构信息使准确率严重下降,路径长度太长会引入过多噪声使准确率逐渐下降.
综合上述分析可以得到以下结论:论文的结构特征相比文本特征更重要,但融合时文本特征相似度所占比例应该相对更高,训练文本特征词向量随机打乱单词顺序很重要,作者与机构单词预处理、关键词、摘要等信息的使用方式会综合影响模型准确率,模型中的阈值、词向量维数和随机游走的采样数与路径长度过高和过低都会导致准确率下降.
5总结
本文提出了一种基于异构网络的无监督作者名称消歧方法,用于解决消歧时的冷启动问题.首先对论文作者、机构、来源等信息进行分词、词形还原等预处理,分别使用论文相关信息学习论文的文本特征表示、使用异构关系网络学习论文的结构特征表示,然后分别计算文本和结构相似度并进行融合聚类.在计算文本特征表示时用TF-IDF[3]、word2vec、词向量随机打乱的方法,在计算结构特征表示时用元路径随机游走[1-2]和word2vec的方法,加权融合特征表示后用DBSCAN聚类并合并孤立点,最终完成消歧任务.在AMiner数据集[4]和SCI数据中验证了模型的有效性,分析了模型每部分的有效性和模型参数取值的合理性,获得了较好的消歧结果.
[参考文献]
[1]DONG Y,CHAWLA N V,SWAMI A. metapath2vec:Scalable representation learning for heterogeneous networks [C]// Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2017:135-144.
[2]PEROZZI B,ALRFOU R,SKIENA S. Deepwalk:Online learning of social representations [C]// Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2014:701-710.
[3]ROBERTSON S. Understanding inverse document frequency:On theoretical arguments for IDF [J]. Journal of Documentation,2004,60(5):503-520.
[4]ZHANG Y,ZHANG F,YAO P,et al. Name disambiguation in AMiner:Clustering,maintenance,and human in the loop [C]// Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2018:1002-1011.
[5]HAN H,GILES L,ZHA H,et al. Two supervised learning approaches for name disambiguation in author citations [C]// Proceedings of the 2004 Joint ACM/IEEE Conference on Digital Libraries. IEEE,2004:296-305.
[6]VELOSO A,FERREIRA A A,GONCALVES M A,et al. Cost-effective on-demand associative author name disambiguation [J]. Information Processing and Management,2012. 48(4):680-697.
[7]YOSHIDA M,IKEDA M,ONO S,et al. Person name disambiguation by bootstrapping [C]// Proceedings of the 33rd International ACM SIGIR Conference on Research and Development in Information Retrieval. 2010:10-17.
[8]HAN X,ZHAO J. Named entity disambiguation by leveraging wikipedia semantic knowledge [C]// Proceedings of the 18th ACM Conference on Information and Knowledge Management. 2009:215-224.
[9]TANG J,ZHANG J,ZHANG D,et al. A unified framework for name disambiguation [C]// Proceedings of the 17th International Conference on World Wide Web. 2008:1205-1206.
[10]DENG C,DENG H,LI C. A scholar disambiguation method based on heterogeneous relation-fusion and attribute enhancement [J]. IEEE Access,2020,8:28375-28384.
[11]FAN X,WANG J,PU X,et al. On graph-based name disambiguation [J]. Journal of Data and Information Quality,2011,2(2):1-23.
[12]MALIN B. Unsupervised name disambiguation via social network similarity [C]// Proceedings of the Workshop on Link Analysis,Counterterrorism and Security. 2005:93-102.
[13]ZHANG W,YAN Z,ZHENG Y. Author name disambiguation using graph node embedding method [C]// Proceedings of the 2019 IEEE 23rd International Conference on Computer Supported Cooperative Work in Design (CSCWD). IEEE,2019:410-415.
[14]ZHANG B,HASAN M A. Name disambiguation in anonymized graphs using network embedding [C]// Proceedings of the 2017 ACM on Conference on Information and Knowledge Management. 2017:1239-1248.
[15]KIM K,ROHATGI S,GILES C L. Hybrid dee pairwise classification for author name disambiguation [C]// Proceedings of the 2019 ACM on Conference on Information and Knowledge Management. 2019:2369-2372.
[16]PENG L,SHEN S,XU J,et al. Diting:An author disambiguation method based on network representation learning [J]. IEEE Access,2019,7:135539-135555.
[17]PENG L,SHEN S,LI D,et al. Author disambiguation through adversarial network representation learning [C]// International Joint Conference on Neural Networks. 2019:paper N-19712.
[18]WANG H,WANG R,WEN C,et al. Author name disambiguation on heterogeneous information network with adversarial representation learning [C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2020:238-245.
[19]QIAO Z,DU Y,FU Y,et al. Unsupervised author disambiguation using heterogeneous graph convolutional network embedding [C]// Proceedings of the 2019 IEEE International Conference on Big Data. IEEE,2019:910-919.
[20]WANG X,TANG J,CHENG H,et al. ADANA:Active name disambiguation [C]// 2011 11th IEEE International Conference on Data Mining. IEEE,2011:794-803.
[21]NG V. Machine learning for entity coreference resolution:A retrospective look at two decades of research [C]// Proceedings of the AAAI Conference on Artificial Intelligence. 2017:4877-4884.
[22]TANG X,ZHANG J,CHEN B,et al. BERT-INT:A BERT-based interaction model for knowledge graph alignment [C]// Proceedings of the Twenty-Ninth International Joint Conference on Artificial Intelligence. 2020:3174-3180.
(責任编辑:陈丽贞)
