
基于集成特征选择的网络异常流量检测
2021-01-01 10:47黄奇文李丽颖沈富可魏同权
华东师范大学学报(自然科学版) 2021年6期
黄奇文 李丽颖 沈富可 魏同权











摘要:随着互联网技术的不断发展,网络的安全问题日益受到人们的重视.网络异常流量检测能够为拦截网络攻击提供有效的保障.然而,为了准确检测网络中的异常流量,通常需要分析海量的数据.分析这些数据不仅消耗巨大的計算资源,降低检测的实时性,还有可能降低检测的准确率.为解决这些问题,提出了一种基于集成特征选择的网络异常流量检测方法:采用5种不同的特征选择算法,设计了一种投票机制以选择特征子集;用朴素贝叶斯、决策树、XGBoost(eXtreme Gradient Boosting)这3种不同的机器学习算法,评估所采用的特征选择算法;选择表现最好的算法以实现网络异常流量检测.实验结果表明,在使用提出的算法所选取出的最优子特征上,所提方法的运行时间比在原始数据集上少了84.38%,平均准确率比单个特征选择算法提高了16.93%.
关键词:异常流量检测;集成特征选择;投票机制
中图分类号:TP393文献标志码:ADOI:10.3969/j.issn.l000-5641.2021.06.011
Network anomaly traffic detection based on ensemble feature selection
HUANG Qiwen,LI Liying,SHEN Fuke,WEI Tongquan
(School of Computer Science and Technology,East China Normal University,Shanghai 200062,China)
Abstract:With the continuous development of Internet technology,network security is garnering increasing attention. Network anomalous traffic detection can provide an effective guarantee for blocking network attacks. However,to accurately detect anomalous traffic in a network,analyzing large volumes of data is usually required. Analyzing this data not only consumes substantial computational resources and reduces real-time detection capability,but it may also reduce the overall accuracy of detection. To solve these problems,we propose a network anomaly traffic detection method based on ensemble feature selection. Specifically,we use five different feature selection algorithms to design a voting mechanism for selecting feature subsets. Three different machine learning algorithms (Naive Bayesian. Decision Tree,XGBoost)are used to evaluate the feature selection algorithm,and the best algorithm is selected to detect abnormal network traffic. The experimental results show that the runtime of the proposed method is 84.38% less than the original data set on the optimal feature subset selected by the proposed approach,and the average accuracy is 16.93% higher than that of the single feature selection algorithm.
Keywords:anomaly traffic detection;ensemble feature selection;voting mechanism
0引言
近年来,互联网技术已经融入了人们生活的方方面面,改变着人们的生活方式,互联网已成为全球经济增长主要驱动力,且用户与流量规模持续扩张.据思科的预测报告叫2017年全球互联网用户达到34亿,IP(Internet Protocol,IP)流量达到1.5 ZB;在2022年将达到48亿用户,全球IP流量将到达4.8 ZB.然而,由于网络安全意识的缺乏和攻击技术的不断向前发展,许多网络应用都遭受着各种各样的网络攻击和安全威胁,暴露出很多的网络安全漏洞.例如,域名系统提供商Dyn公司于2016年遭受的网络流量攻击[2],黑客恶意操控数以百万计的IP地址要求域名服务器进行大量域名系统协议(Domain Name System,DNS)解析从而导致数以万计的用户无法连接网络;2018年,GitHub公司遭到最高峰值为1.35 TB/s的分布式拒绝服务(Distributed Denial of Service,DDoS)攻击[3],断线至少5 min,给公司造成了巨大损失.网络异常流量检测能够有效检测网络攻击,避免用户遭受损失,因此,网络流量异常检测成Z为网络安全研究的热点.
目前很多学者对网络流量异常检测进行了研究,并提出相应的解决方法.传统的网络异常流量检测方法是基于端口和基于深度包检测(Deep Packet Inspection,DPI)[4].基于端口的方法是根据应用程序注册的端口来识别流量,这些端口由互联网数字分配机构回(Internet Assigned Numbers Authority,IANA)指定,由于应用程序未注册或随机产生端口,导致这种方法不可靠.基于深度包的检测方法是根据是否匹配数据包的有效载荷和数据包的存储签名对网络流量分类,但当数据包内容不被允许访问或数据包本身被加密时,该方法就会失效.为了解决上述问题,近年来机器学习算法越来越多地被用来解决网络异常流量检测问题.Callado等[6]提出了一种基于机器学习的网络异常流量检测,通过4种不同的联合机制,联合多种机器学习算法对网络异常流量分类.Belavagi等[7]提出的基于机器学习的网络入侵检测方法是通过比较几种不同的机器学习算法在入侵检测的表现,选取最佳表现算法.
机器学习算法能够快速并准确地进行异常流量检测.然而,在机器学习建立模型的过程中,原始的训练数据包含了很多无关特征和冗余特征,直接使用这样的训练数据不但会消耗大量的计算资源,而且可能降低模型的准确度.因此,如何有效选择网络流量数据中的特征尤为关键.常见的特征选择方法包括过滤法和嵌入法,过滤法是计算单个特征和目标变量的相关性的方法,嵌入法是根据某些机器学习算法和模型进行训练,得到各个特征权重系数的方法.Osanaiye等[8]提出了一种集成特征选择算法,使用信息增益、信息增益率、卡方和ReliefF这4种过滤方法进行特征选择,在特征选择后选取包含在这四种方法中的都存在的特征,最后采用决策树作为分类器評估模型.但是这种方案没有考虑特征与特征之间的联系,且该方法只使用单个算法评估模型,导致模型的稳定性较弱.Hoque等[9]在上述方法的基础上加入了对称不确定性方法,该方法也属于过滤法,选用了21种数据集,最后用决策树、随机森林、k-NN(k-Nearest Neighbor)和支持向量机(Support Vector Machine,SVM)评估模型. 但是这种方案只是增加了多个算法评估模型,并没有增加其他种类的特征选择方法,也没有解决特征与特征之间没有联系的问题.Singh等[10]提出了一种包含以上5种方法的集成特征选择算法,另外加入了相关系数和支持向量机,相关系数属于过滤法,支持向量机属于嵌入法,根据每个方法产生的特征权重筛选特征,最后用多层感知机作为二分类器评估模型.但是该方案过滤法和嵌入法的比例失调,过滤法有6种,嵌入法只有1种,导致模型存在偏向性,该方案采用的是二分类模型,即按照正常流量和异常流量进行分类,无法确定异常流量具体类型,且该方案也只使用单算法评估模型.为了解决上述问题,本文提出了一种基于集成特征选择的网络异常流量检测算法,本文的主要贡献如下.
(1)提出了一种集成特征选择方法,使用过滤法和嵌入法这两大类方法进行特征选择,其中,在过滤法中使用相关系数、卡方检验、互信息这3种方法,在嵌入法中采用随机森林算法和LGBM[11](Light Gradient Boosting Machine)算法计算特征的权重并排序;设计了一种投票机制用于集成这5种方案的选择结果,并进行了特征筛选.
(2)使用基于朴素贝叶斯、决策树和XGBoost[12]这3种机器学习算法作为多分类器,判断异常流量的具体攻击类型;采用综合表现最好的算法,比较所提出的集成特征选择算法与单个特征选择算法在模型上的表现,选出最优子特征.
(3)实验结果表明,在本文的集成特征选择算法选取的最优子特征上运行异常流量检测算法比在原始数据上的运行时间减少了84.38%;对比单个特征选择算法,本文算法平均准确率提高了16.93%,平均精确率提高12.31%,平均召回率提高15.34%,平均F-score(F)提高了18.00%.
1相关技术
1.1过滤法
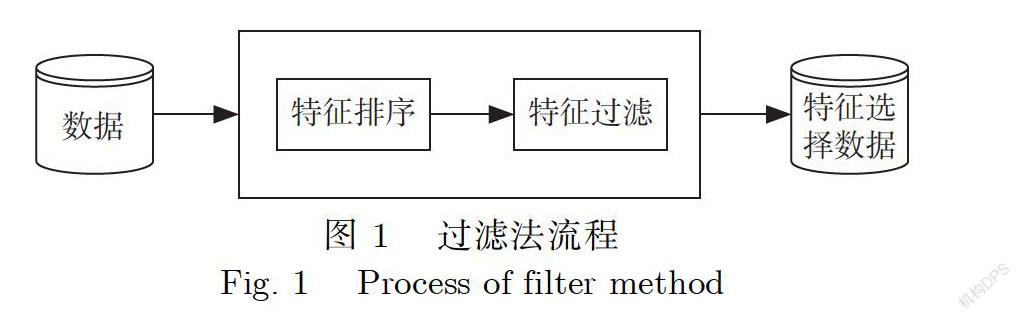
图1显示的是过滤法的主要流程.过滤法首先将数据输入特征排序算法中,根据相关性大小或者指定特征个数进行选择/过滤,最后得到特征选择数据.过滤法的优点是计算高效,对于过拟合问题也具有较高的鲁棒性;其缺点是倾向于选择冗余的特征,且没有考虑特征与特征之间的联系[13].在过滤法中,相关系数、卡方检验和互信息是3种常见的筛选方法,因此本文采用了相关系数、卡方检验和互信息这3种过滤方法.
1.1.1相关系数
计算训练集中特征与输出之间的相关系数,取值范围是[-1,1],正值表示正相关,负值表示负相关.本次实验在计算特征与输出相关系数时取绝对值,保证特征与输出之间正相关,相关系数越大表示特征与输出之间越密切.相关系数理论公式为
其中,x和y表示两个变量,cov(x,y)表示x与y的协方差,σ表示x的方差,σ表示y的方差,ρ表示x与y的相关系数.
1.1.2卡方检验
卡方检验是检验定性自变量对定性因变量相关性的一种方法.求出卡方值,然后根据卡方值,匹配出其所对应的概率是否足以推翻原假设,如果能推翻,就启用备用假设.卡方值越大,表明两个事件越密切.卡方值计算公式为
其中,A为观察(实际)频数,E为期望(理论)频数,n为总频数,P为期望频率,E=n×P,k为数据总量,χ表示卡方.
1.1.3互信息
互信息法常用于捕捉每个特征与输出之间的任意关系(包括线性和非线性关系).从信息嫡的角度分析每一个特征和输出之间的关系,互信息越大,说明特征与输出之间的相关性越大.互信息公式为
其中,X和Y是两个变量;p(x,y)是X和Y的联合概率分布函数,而p(x)和p(y)分别是X和Y的边缘概率分布函数;I(X;Y)表示互信息.
公式⑶中,log的底数可以为e或者2:若为2的话,互信息的单位就是比特;若为e的话,互信息的单位就是奈特.本文采用Python基准库方法以e为底数.
1.2嵌入法
图2所示是嵌入法的主要流程.嵌入法首先将数据输入机器学习算法中,得到每个特征的权值系数,然后根据权值系数的大小选择特征,被选中的特征对预测器的结果起较大作用;该方法主要是通过机器学习训练确定特征的优劣,而不是简单地根据特征之间的统计指标来决定所选特征.随机森林算法是时下非常流行的集成学习算法,其模型的泛化能力强.LGBM算法是目前很流行的高性能梯度提升算法.因此本文采用随机森林算法和LGBM算法作为嵌入法中的机器学习算法.
1.2.1随机森林算法
随机森林这个术语最初是由Ho于1995年[14]率先提出,然后Breiman在2001年[15]的一篇论文中正式提出随机森林算法.随机森林算法是一种以决策树为基础的算法,与决策树类似,它既可以用于回归也可以用于分类,是一个包含多个决策树的分类器.在决策树的训练过程中引入随机属性选择,各自独立地学习并做出预测,并通过多个决策树结果投票决定.因此随机森林算法的效果往往比单棵树的结果表现要好,其缺点是训练模型的时间要比单个决策树长.
1.2.2LGBM算法
LGBM算法是微软提出的一个快速的、分布式的、高性能的基于决策树的梯度提升算法,可用于处理机器学习中分类和回归的问题.梯度提升产生的分类器是串行的弱分类器的集成,下个分类器需要根据上个分类器的输出来计算自身的参数;与随机森林算法的并行不同,随机森林算法所有分类器之间没有联系.传统的梯度提升存在的问题是无法减少训练数据和特征,LGBM算法采用了直方图算法,加速了训练速度,故有更高的效率,且占用的更少内存.
2集成特征选择
2.1算法框架
本文所提出的集成特征选择算法的基本框架图如图3所示:首先将原始数据进行预处理,以去除掉原始数据中包含的冗余数据,并根据需要调整数据的格式问题;然后将处理后的数据经过过滤法和嵌入法处理之后,产生各自的特征子集;特征子集经过投票机制筛选后,得到3个特征子集F、F和F,它们分别表示包含3种及以上特征选择方法都选择的特征集合、包含4种及以上特征选择方法都选择的特征集合、包含5种特征选择方法都选择的特征集合.
2.2投票机制算法
在特征选择中,本文一共选取了5种特征选择方法,主要包括过滤法和嵌入法.过滤法中采用了相关系数、卡方检验和互信息这3种不同的评价标准来选择特征;嵌入法中采用了随机森林算法和LGBM算法来选择特征.随机森林算法和LGBM算法是目前很受欢迎且具有代表性的特征选择算法. 但这些方法都有局限性,如,过滤法的局限性在于没有考虑特征与特征之间的联系;嵌入法虽然能够体现特征间联系,但过于依赖所选算法的最终表现.为此,本文提出了一种投票算法来选择特征,得到3个特征子集F、F和F:设D=(x,x,…,x)表示数据集的m条实例,向量x=(f,f,…,f,c),f表示向量x第j个特征的值,F={f,f,…,f}表示数据的特征集合,f∈F,C={c,c,…,c}表示数据的标签集合,x∈C,选取的特征数量为T.基于投票机制的集成特征选择算法见算法1.
算法1中,P、f、f、R、L分别表示相关系数、卡方检验、互信息、随机森林、LGBM这5种方法,它们选出T个特征分别加入各自集合p、c、m、r、l中;U(p,c,m,r,l)表示选择包含3种及以上特征选择方法都选择的特征集合;U(p,c,m,r,l)表示选择包含4种及以上特征选择方法都选择的特征集合;U(p,c,m,r,l)表示选择包含5种特征选择方法都选择的特征集合.
3异常流量分类检测
3.1算法简介
3.1.1朴素贝叶斯
朴素贝叶斯(Naive Bayesian,NB)是基于贝叶斯定理与特征条件独立假设的分类方法叫是一种直接衡量标签和特征之间的概率关系的有监督算法,既可以做分类也可以做回归.对于给定的训练数据集,首先基于特征独立条件假设学习输入输出的联合概率分布;然后基于此模型,对于给定的输入,利用贝叶斯定理求出后验概率最大的输出.
3.1.2決策树
决策树(Decision Tree,DT)是一种非参数的有监督学习算法,能够从一系列有特征和标签的数据中总结出决策规则,并用树状图的结构来呈现这些规则,以解决分类和回归问题,而且决策树天然能解决多分类问题,具有非常好的可解释性.决策树学习算法包括3个部分:特征选择、树的生成和树的剪枝.特征选择的目的在于选取对训练数据能够分类的特征;决策树的生成通过计算一些特征指标,从根节点开始递归地生成决策树;由于存在过拟合问题,需要对其进行剪枝,以简化学到的决策树.
3.1.3XGBoost
XGBoost由Chen[17]设计,是一个优化的分布式梯度提升库.和传统的梯度提升算法相比,XGBoost提供并行树提升,可以快速准确地解决许多数据科学问题,它比其他使用梯度提升的集成算法更加快速,并被认为是在分类和回归上都拥有超高性能的先进评估器.
3.2流量分类
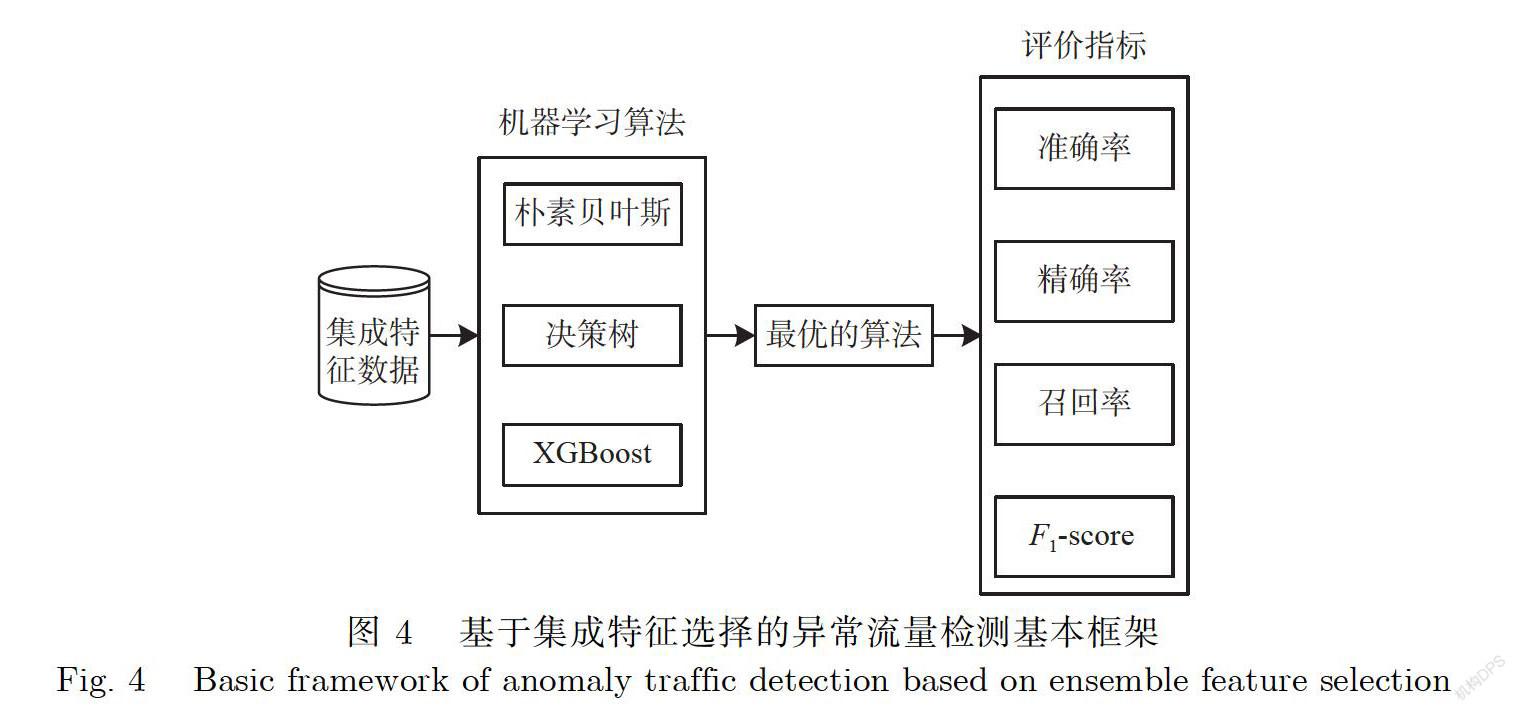
本文提出的基于集成特征选择的异常流量检测基本框架如图4所示:首先用3种机器学习算法评估集成特征选择后的数据;选出最优的算法;之后比较集成特征选择算法和单个特征选择算法的在模型上的准确率、精确率、召回率和F-score.
基于集成特征选择的异常流量检测算法的实现见算法2.
在算法2中,D表示全部特征数据,D、D、D表示经过集成特征选择后的F、F、F對应的数据.这些数据经过算法朴素贝叶斯(NB)、决策树(DT)、XGBoost(XG)计算后,可得到模型运行的时间(T)和准确率(A).模型的运行时间和准确率是最重要的2个指标,因此本文选择这2个指标来评估模型的表现.综合评估运行时间和准确率后选择表现最好的算法BA(BA∈{NB,DT,XG});表示5种特征选择算法前F个特征数据和D输入算法BA中得到评价指标,加入评价指标集合;表示5种特征选择算法前F个特征数据和D输入算法BA中得到评价指标,加入评价指标集合;表示5种特征选择算法前F个特征数据和D输入算法BA中得到评价指标,加入评价指标集合.最后输出A、P、R、.
4实验结果与分析
4.1数据预处理
实验数据选取CIC-IDS-2018[18]数据集,该数据集包含最新的网络攻击方式,且模拟真实的用户产生的正常网络流量.使用CICFlowMeter-V3[提取该数据集特征共76种,如表1所示.
该数据集中的攻击类型共有14种,其中6种攻击类型样本数量太少,不予考虑.正常流量样本数量太大,因此随机交叉提取20%的数据.最后选取的网络流量类型和数量(单位条)如表2所示.在表2中,Benign表示正常网络流量;DoS attacks-Hulk、DoS attacks-SlowHTTPTest属于拒绝服务攻击攻击,使攻击目标无法提供正常服务;DDOS attack-HOIC、DDoS attacks-LOIC-HTTP属于分布式拒绝服务攻击,是一种特殊形式的拒绝服务攻击,特点是分布、协同的大规模攻击;Bot属于僵尸网络攻击,使主机感染僵尸病毒,从而控制主机,FTP-BruteForce、SSH-Bruteforce属于暴力攻击,通过不断穷举破解密码;Infilteration属于渗透攻击,通过发现利用或直接利用已知漏洞来获得目标网络权限.
为了获得精确区分不同攻击类型的具有决定性的统计特征,我们首先删除了源IP地址、源端口、目标IP地址、目标端口、协议这5项特征.因为不需要考虑时间特性,故删除时间戳特征,同时删除数据集中存在的缺失值和每秒字节数或每秒包数为无穷大的数据.在训练模型时,将标签编码映射为数值.
由于方差用来描述一个变量的差异性,考虑在一个数据集中,如果一个特征的方差为0,就意味着这个特征只有唯一值,且该特征不能导入任何新的信息来帮助训练模型,因此需要删除数据中方差为0的特征.
4.2实验环境与评价指标
本次实验的环境为:Intel(R)Pentium(R)CPU G4600 @ 3.60 GHz;8.00 GB(内存);Windows10家庭版64位操作系统.算法运行环境是Python3.7,基准方法在Python库scikit-learn中实现;随机森林参数设置中nstimators表示树的棵树,设置为100棵树,100棵树能够在训练难度和模型效果之间取得平衡;LGBM中的nstimators也设置为100.
本次实验分类评价指标分别包括准确率(Accuracy,A),精确率(Precision,F),召回率(Recall,R),F-score (F),它们的定义如下.
在分类问题中,定义:TP(True Positve Prediction)为真阳性预测,n为真阳性预测样本;FP(False Positive Prediction)为假阳性预测,n为假阳性预测样本;TN (True Negative Prediction)为真阴性预测,n为真阴性预测样本;FN(False Negative Prediction)为假阴性预测,n为假阴性预测样本.
(1)准确率(A)的定义是所有测试样本中n+n的比例,公式为
表示预测成功的样本占总预测样本的比例.
(2)精确率(P)的定义是模型分类的预测为阳性样本中真阳性样本的比例,公式为
表示预测成功阳性样本中占预测阳性样本的比例.
(3)召回率(R)的定义是模型分类的实际为阳性样本中真阳性样本的比例,公式为
表示预测成功阳性样本中占实际阳性样本的比例.
(4)F-score(F)的定义是模型分类中精确率和召回率的调和平均数,公式为
表示在精确率和召回率之间的折中.
4.3结果与分析
对于特征选择,由于数据集中的特征有76个,去除方差为0的特征之后有68个,因此选择约一半的特征,即30个,且尽可能保证选择的是重要的特征.特征选择后的情况如表3所示,其中,1表示特征被该方法选取,0表示没有被该方法选取.本次实验根据投票规则选取F、F、F特征子集.从表3中可以看出,F包含的特征有5个,将其对应的数据记为F(数据大小约为229MB);F包含的特征有5+6=11个,将其对应的数据记为D(数据大小约为329 MB);F包含的特征有5+6+9=20个,将其对应的数据记为D(数据大小约为421 MB).将全部特征数据记为D(数据大小约为1426 MB).
在流量分类中,将D、D、D、D输入朴素贝叶斯、决策树、XGBoost算法,使用十折交叉验证计算模型的训练时间和准确率,实验结果见图5.由图5可知,在平均训练时间方面,朴素贝叶斯是76s,决策树是443 s,XGBoost是5572 s;在平均准确率方面,朴素贝叶斯是73.33%,决策树是90.22%,XGBoost是92.14%;XGBoost的平均准确率最高,但其平均训练时间高达5 572 s;朴素贝叶斯的平均训练时间最低,但其平均准确率只有73.33%,无法达到良好的分类结果;决策树的平均准确率只比XGBoost低1.92%,但其平均训练时间却比XGBoost减少了92.05%,XGBoost在时间上的花费相比准确率代价太高,且在数据集D、D、D的准确率上相差甚微.综合考虑,本文选择决策树作为建模算法,并对比集成特征选择算法和单个特征选择算法在该建模算法中的表现.
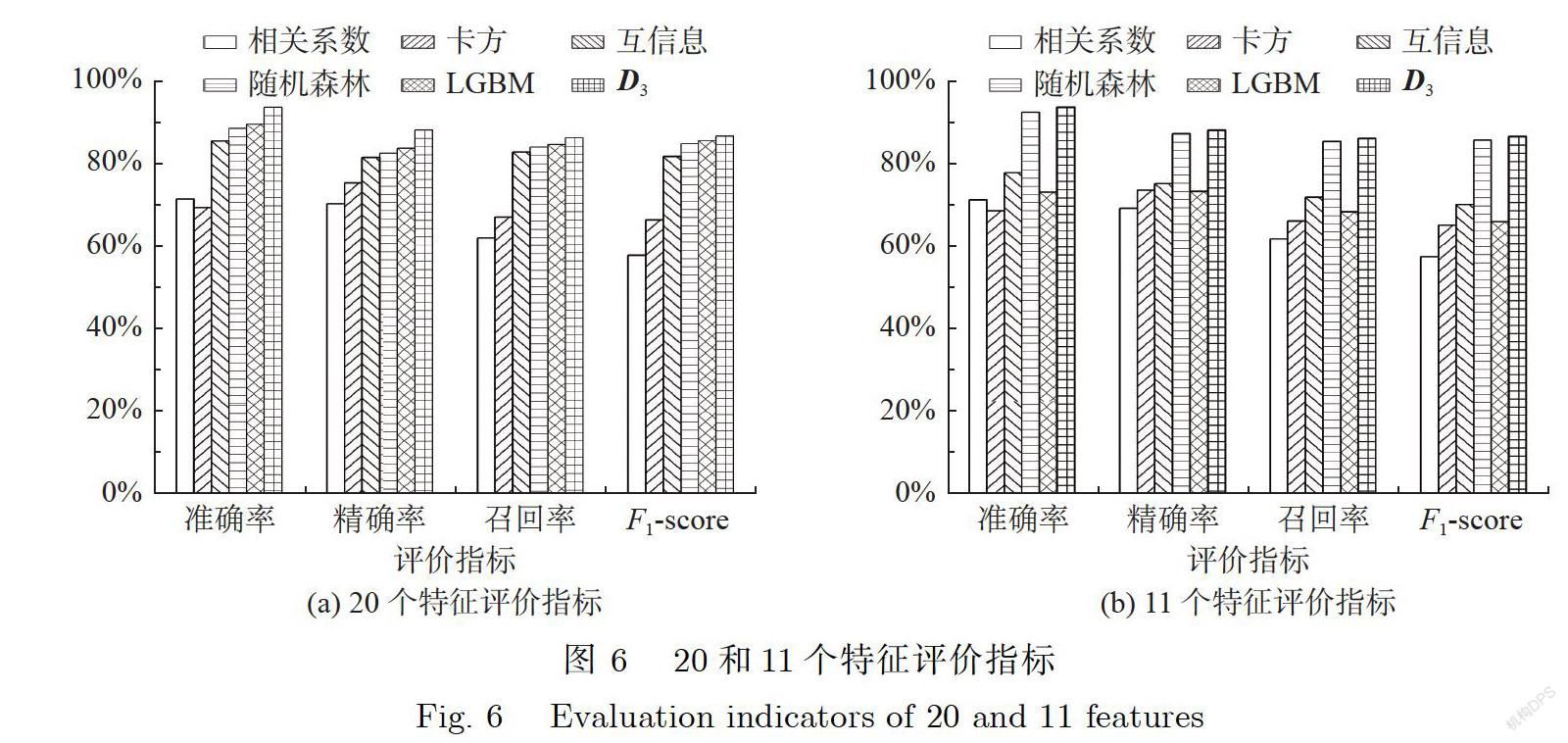
D有20个特征,因此5种特征选择方法分别选出前20个特征,经过决策树算法后,评价指标如图6所示.实验结果表明,D的准确率最高,比最低的卡方准确率高出24.19%,平均准确率高出12.71%.D的精确率最高,比最低的相关系数精确率高出17.76%,平均精确率高出9.41%,D的召回率最高,比最低的相关系数召回率高出24.14%,平均召回率高出10.12%,D的F-score最高,比最低的相关系数F-score高出28.79%,比平均F-score高出11.37%.
D有11个特征,因此5种特征选择方法分别选出前11个特征,经过决策树算法后,评价指标如图6所示.实验结果表明,D的准确率最高,比最低的卡方准确率高出了24.97%,平均准确率高出了16.93%;D的精确率最高,比最低的相关系数精确率高出了18.79%,平均精确率高出了12.31%;D的召回率最高,比最低的相关系数召回率高出了24.21%,平均召回率高出了15.34%;D的F-score最高,比最低的相关系数F-score高出了28.99%,平均F-score高出了18.0%.
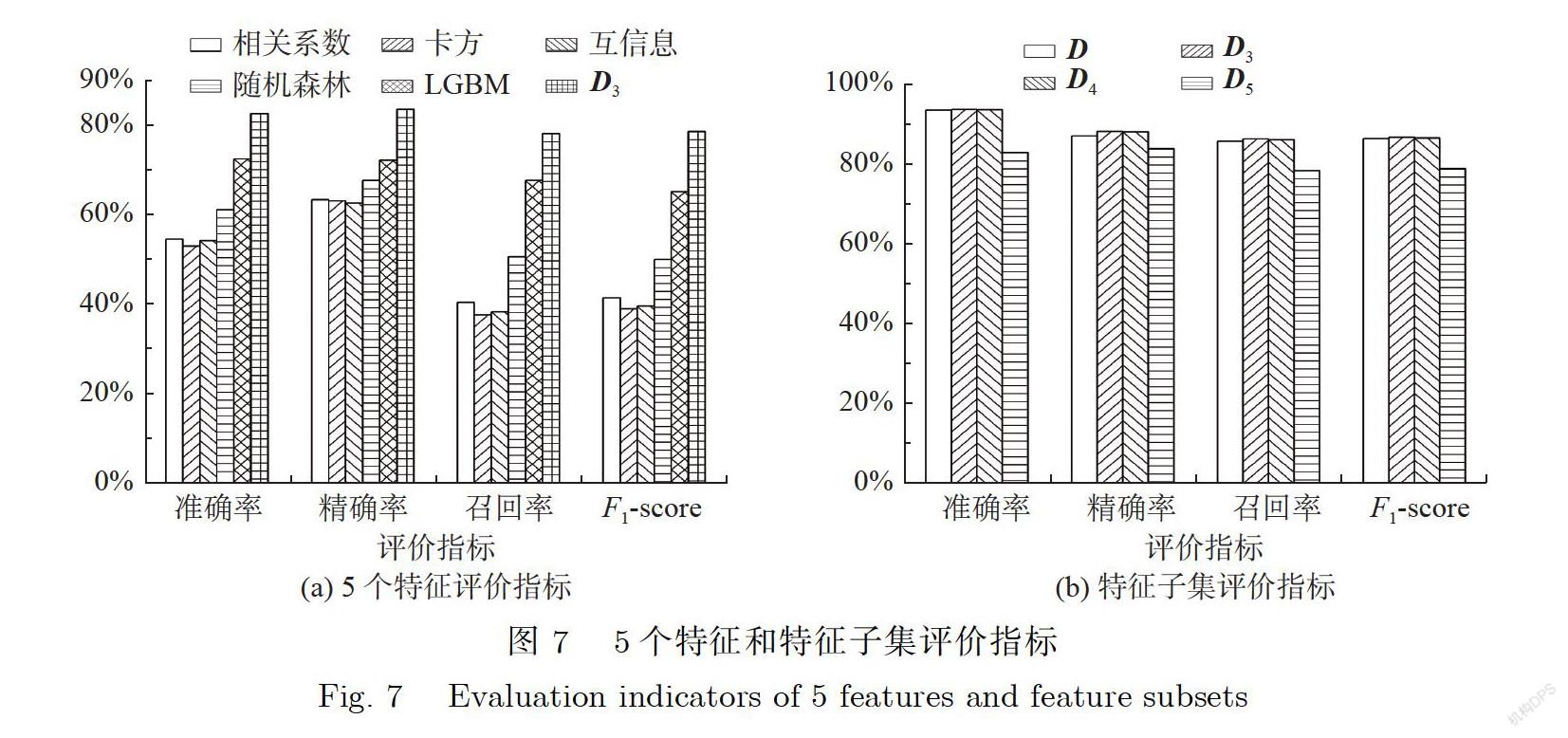
D有5个特征,因此5种特征选择方法分别选出前5个特征,经过决策树算法后,评价指标如图7所示.实验结果表明,D的准确率最高,比最低的卡方准确率高出29.57%,平均准确率高出23.48%.D的精确率最高,比最低的互信息精确率高出20.94%,平均精确率高出17.76%,D的召回率最高,比最低的卡方召回率高出40.44%,平均召回率高出31.15%,D的F-score最高,比最低的卡方F-score高出39.53%,平均F-score 高出34.50%.
從图5、图6和图7中可以看出,集成特征选择算法比单个特征选择算法在各项指标均有较高的提升,这说明集成特征算法能筛选出重要的特征.最后比较3个特征子集评价指标的差异,选出最优的特征子集.从图7中可以看出,准确率最高的是D,最低的是D,这是因为D的特征太少,损失了重要特征;D的准确率比D只高0.06%,精确率只高0.12%,召回率只高0.21%,F-score只高0.19%,说明D特征已经足够重要;但是D的模型运行时间比D高52.28%(由图5可知),时间花费的代价太大,提升太小.因此本文选择D包含的特征作为最优的特征子集.
5总结
本文提出了一种集成特征选择的网络异常流量检测算法:特征选择采用了包含过滤法和嵌入法的5种方法,提出了基于投票机制的特征选择算法,选出了3个特征子集;流量分类采用3种常用的机器学习算法对集成特征数据进行了多分类预测.实验结果表明,决策树表现最好,因此选用决策树建模.对比集成特征选择算法和单个特征选择算法之间的指标,集成特征选择算法的最优子特征比单个特征选择算法平均准确率提高了16.93%,平均精确率提高了12.31%,平均召回率提高了15.34%,平均F-score提高了18.00%,对比原始数据也稍有提升,但模型的运行时间比原始数据少了84.38% (数据量减少了1097 MB).本文的特征集无法保证是全局最优子特征,今后可以持续优化寻找全局最优子特征.
[參考文献]
[1]CISCO. Cisco visual networking index:Forecast and methodology,2016-2021 [EB/OL]. (2017-06-15)[2020-06-24]. http://www.cisco.com/c/ en/us/solutions/collateral/service-provider/visualnetworking-indexvni/complet e-white-paper-c11-481360.pdf.
[2]KYLE Y. Read Dyn's statement on the 10/21/2016 DNS DDoS attack [EB/OL]. (2016-10-21)[2020-06-24]. https://dyn.com/blog/dyn-statement-on-10212016-ddos-attack.html.
[3]PATIL N V,KRISHNA C R,KUMAR Ket al. E-Had:A distributed and collaborative detection framework for early detection of DDoS attacks [J/OL]. Journal of King Saud University-Computer and Information Sciences,2019. https://doi.org/10.1016/j.jksuci.2019.06.016.
[4]PACHECO F,EXPOSITO E,GINESTE M,et al. Towards the deployment of machine learning solutions in network traffic classification:A systematic survey [J]. IEEE Communications Surveys and Tutorials,2018,21(4):1988-2014.
[5]INTERNET ASSIGNED NUMBERS AUTHORITY. Protocol Assignments [EB/OL]. (2011-12-17)[2020-06-24]. https://www.iana.org/protocols.
[6]CALLADO A,KELNER J,SADOK D,et al. Better network traffic identification through the independent combination of techniques [J]. Journal of Network and Computer Applications,2010,33(4):433-446.
[7]BELAVAGI M C,MUNIYAL B. Performance evaluation of supervised machine learning algorithms for intrusion detection [J]. Procedia Computer Science,2016,89:117-123.
[8]OSANAIYE O,CAI H B,CHOO K K R,et al. Ensemble-based multi-filter feature selection method for DDoS detection in cloud computing [J]. EURASIP Journal on Wireless Communications and Networking,2016:Article number 130. DOI:10.1186/sl3638-016- 0623-3
[9]HOQUE N,SINGH M,BHATTACHARYYA D K. EFS-MI:An ensemble feature selection method for classification [J]. Complex &Intelligent Systems,2018(4):105-118..
[10]SINGH K J,DE T. Efficient classification of DDoS attacks using an ensemble feature selection algorithm [J]. Journal of Intelligent Systems,2017,29(1):71-83.
[11]KE G L,MENG Q,FINLEY T,et al. LightGBM:A highly efficient gradient boosting decision tree [C]// Advances in Neural Information Processing Systems (NIPS 2017). 2017:3146-3154.
[12]CHEN T Q,GUESTRIN C. XGBoost:A scalable tree boosting system[C]// Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. 2016:785-794.
[13]BOLÓN-CANEDO V,ALONSO-BETANZOS A. Ensembles for feature selection:A review and future trends [J]. Information Fusion,2019,52:1-12.
[14]HO T K. Random decision forests [C]// Proceedings of 3rd International Conference on Document Analysis and Recognition. IEEE,1995:278-282.
[15]BREIMAN L. Random forest [J]. Machine Learning,2001,45:5-32.
[16]李航.统计学习方法[M].2版.北京:清华大学出版社,2019:59-60.
[17]CHEN T Q. Story and lessons behind the evolution of XGBoost [EB/OL]. (2016-03-10)[2020-06-24]. https://homes.cs.washington.edu/~tqchen/2016/03/10/story-and-lessons-behind-the-evolution-of-xgboost.html.
[18]SHARAFALDIN I,LASHKARI A H,GHORBANI A A. Toward generating a new intrusion detection dataset and intrusion trafficcharacterization [C]// Proceedings of the 4th International Conference on Information Systems Security and Privacy - ICISSP. 2018:108-116.
[19]LASHKARI A H,DRAPER-GIL G,MAMUN M S I,et al. Characterization of tor traffic using time based features [C]//Proceedings of the 3rd International Conference on Information Systems Security and Privacy-ICISSP. 2017:253-262.
(責任编辑:李艺)
