
长输热油管道非稳态油温预测
2020-12-29 08:53:10展明达张文瑄
石油化工高等学校学报 2020年6期
于 涛,展明达,张文瑄,胡 静
(1.国家管网生产经营本部(油气调控中心),北京100013;2.北京中油瑞飞信息技术有限责任公司,北京100007)
长输高含蜡原油管道沿线油温是最重要的控制参数。日常运行过程中,工艺调整、异常工况停炉、清管前热洗等作业均可导致上游站场出站油温变化。上游出站油温变化一般可短时间达到平衡,但下游进站油温经过沿线热损、冷热油界面掺混等达到相对稳定的时间较长。实际生产过程中,节能降耗需要控制全线油温一般高于油品凝点3~5℃,若加热炉故障停炉可导致管道下游进站油温过低,不能满足运行规程要求,增大运行风险。此外,每次清管前启炉热洗管道的时间无法实现精准控制,不利于节能降耗工作的开展。可见,油温非稳态过程的准确预测,可有效指导管道的工艺调整、节能降耗及维抢修工作的开展,具有重要的工程意义。
目前学者对原油管道非稳态油温的研究主要有两种方法,一是解析法,利用热力学理论公式,将管道划分区域,建立预测模型,如王海琴[1]建立含蜡原油热输管道沿程温度分布的计算公式。二是数值计算法,结合热力学公式,实现沿线油温的预测,如姜笃志[2]采用双极坐标保角变换的方法,提出热油管道非稳定热力过程计算方法;B.Yu等[3-4]通过引入热力影响区,采用非结构化网络和有限元容积法对不同月份、不同流量和不同出站油温下的工况进行较为准确的模拟。以上学者对热油管道非稳态油温研究取得一定成果,但因需要较为准确的油品物性、沿线温度场等参数,使用数值分析法时,对管道、结蜡层及土壤导热系数等一系列参数的获得难度较大,且建立模型时边界条件和初始条件的设定[5-7]导致模型的使用具有一定的局限性,实际生产适用性较差。目前长输管道均采用SCADA系统远程调控,现有的非稳态油温预测模型很难融入大数据平台,实现对油温的有效预测。对此需探索研究适应性强、准确率高的预测模型,便于当前长输管道实时参数预测及智能化控制的推广应用。
随着计算机科学技术的发展,数据挖掘技术逐渐被认可,并进行了深入研究与应用。近年来已有不少学者将大数据挖掘技术应用到工程实际中,如电力负荷预测[8-9]、航空等[10-11],不仅实现设备工况的诊断监测[12-13],还通过对生产数据的分析挖掘,有效发现潜在生产规律,提高生产效率。其中,石油行业大数据在油田勘探开发[14-18]、石油炼化[19-20]、管道内检测、泄漏监测等方面广泛应用[21-22],在提升油田采收率、优化炼化装置设备流程及管道完整性等方面发挥重要作用。但是大数据挖掘技术在建立原油管道非稳态油温与其影响因素的关系研究中,仍处于空白。
本研究通过分析HY热油管道上游站场启、停炉与下游进站相应的油温变化趋势,获得其数列对应关系。分析数据特点,给出上下游站场非稳态油温变化数据特点与时间控制范围。研究管道SCADA系统采集的油温、地温、流量等参数与油温的相关性,确定非稳态油温的影响因子。提出使用seq2seq算法建立非稳态油温与影响因素的映射关系,实现下游进站油温变化趋势的准确预测。
1 方法与理论
1.1 seq2seq模型
seq2seq是RNN最重要的一个变种,解决了RNN结构的“长期依赖”问题。该模型也可称为Encoder-Decoder模型,先通过Encoder过程将输入数据编码形成向量,再利用RNN模型进行解密,即Decoder过程,其结构示意如图1所示。

图1 seq2seq模型结构示意Fig.1 Schematic diagram of seq2seq model structure
x、y、h分别表示输入变量、输出变量和隐变量,向量C表示编码器的输出。假设模型当前的隐变量与上一时刻的隐变量和当前的输入x有关,在编码阶段,得到各个隐藏层的输出,然后汇总生成向量,也可将最后一层隐藏层作为输出向量C→:

将向量C→送入解码部分,根据给定的向量C→和输出序列y1,y2,…,yi-1来预测下一个数据yi,即:

通过式(1)、(2)实现 seq2seq的编码、解码过程。由于seq2seq模型的结构不限制输入和输出的序列长度,被广泛应用于机器翻译、语音识别等领域。本文模型隐层内部结构采用K.Cho等[23]提出的著名变种门控循环单元(Gated Recurrent Unit,GRU)(见图 2)。

图2 GRU结构示意Fig.2 Schematic diagram of GRU structure
GRU模型有两个门,分别为更新门和重置门,即图中的zt和rt,如式(3)、(4)所示。


更新门用于控制前一时刻状态信息被当前状态利用的程度,更新门的值越大,表示利用程度越高;重置门用于控制前一时刻信息被当前状态忽略的程度,重置门的值越小,表示忽略得越多。两个门的结果通过sigmoid函数获得,值域为[0,1]。


隐含状态ht通过更新门zt对上一隐含状态ht-1和候选隐含状态进行更新。更新门控制过去隐含状态在t时刻的重要性,若更新门近似1,t时刻前的隐含状态将通过时间一直保存并传递至t时刻,从而避免RNN中梯度衰减问题,捕捉时序数据间隔较大的依赖关系。
1.2 注意力机制
因seq2seq模型的Encoder输入参数压缩成固定长度的向量,若输入参数较多,导致误差增大,对此崔宇等[24]提出了注意力机制,其编码时仍然是将输入序列依次输入编码用的RNN,并记录每一时刻的隐藏状态ht,而编码器输出的中间码就是所有这些隐藏状态ht的集合,之后使用RNN解码,以第i时刻为例,其框架(见图3)及计算过程如下:
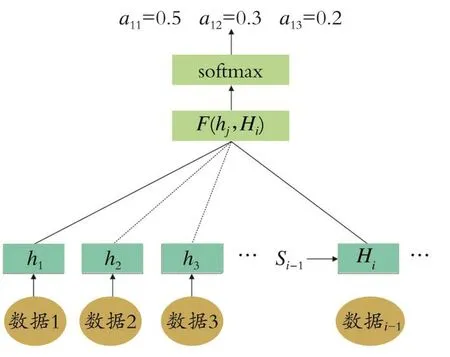
图3 注意力权重分配Fig.3 Attention weight distribution diagram
(1)计算C→中各值与上一时刻隐藏层状态si-1之间的相关程度eij,并进行softmax归一化得到每个值的权重aij,见式(7)、(8):

(2)对C→中各值进行加权平均求得i时刻的二次中间码C→i,见式(9):

(3)基于C→i和上一时刻的隐藏状态si-1、输出yi-1,计算i时刻的隐藏状态si,再利用si计算i时刻的输出yi:

首先,单独计算si-1与每个隐层状态h的每一个数值,再通过softmax获得i数据对应的Tx个编码时隐层状态内的注意力权重分配,从而求出C→i分配向量权重。
1.3 基于注意力机制的seq2seq模型
注意力机制可将模型在解码过程中的隐层数据进行权重分配,从而提高seq2seq模型的预测准确性和训练效率,其模型结构如图4所示。

图4 基于注意力机制的seq2seq模型Fig.4 seq2seq model based on attention mechanism
输油管道上游出站油温的调整存在稳态→非稳态→稳态过程,该过程时间较短,待冷热油到达下游站场后其也存在稳态→非稳态→稳态过程,这个过程因油品沿线运移的原因持续时间较长。对此可将该过程看成两个序列的对应关系,建立基于注意力机制的seq2seq非稳态油温预测模型。
2 实验
2.1 HY热油管道特性
HY长输热油管道,主要外输长庆油田高含蜡原油(见表1),管道全长132.1 km,管径Φ457 mm,设计压力6.3 MPa(局部10 MPa),设计流量为500×104t/a,全线共设 4座站场,其中,1#首站-2#热站间距为56.60 km,2#热站-3#热站间距为39.45 km,3#热站-4#末站间距为36.05 km。
根据HY热油管道沿线地温和油品物性特点,管道采用综合热处理、热处理、加热和常温输送4种不同工艺,全年启炉时间达到6个多月。可见,若管道上游站场启停炉,冷、热油到达下游站场的非稳态过程是管道维抢修和日常安全优化的重点。
2.2 停炉后油温数据分析
根据以往加热炉工况调整记录,本文选取HY两次停炉后,上游出站油温、下游进站油温数据变化趋势进行分析(见图5)。

表1 管道外输油品物性Table 1 Physical properties of oil products outside the pipeline
管道站场停炉后加热炉内炉膛温度随着低温油品的冷却,出站油温降低,达到平衡、稳定的时间约为15 min。由于热油温度高于管道沿线温度场温度,在径向温差的作用下,油流所携带的热量不断向周围环境换热,管内油温沿着轴向呈指数递减规律分布,最终到达下游站场进站油温达到稳定的时间较长。上游加热炉停用后,冷油到达下游站场达到稳定的时间约为24 h,但不同流量、不同管道距离达到稳态的时间不同。因下游进站油温与管道流量、沿线地温、油温等参数有关,实际生产中很难通过解析法或数值分析法获得较为准确的预测数据。
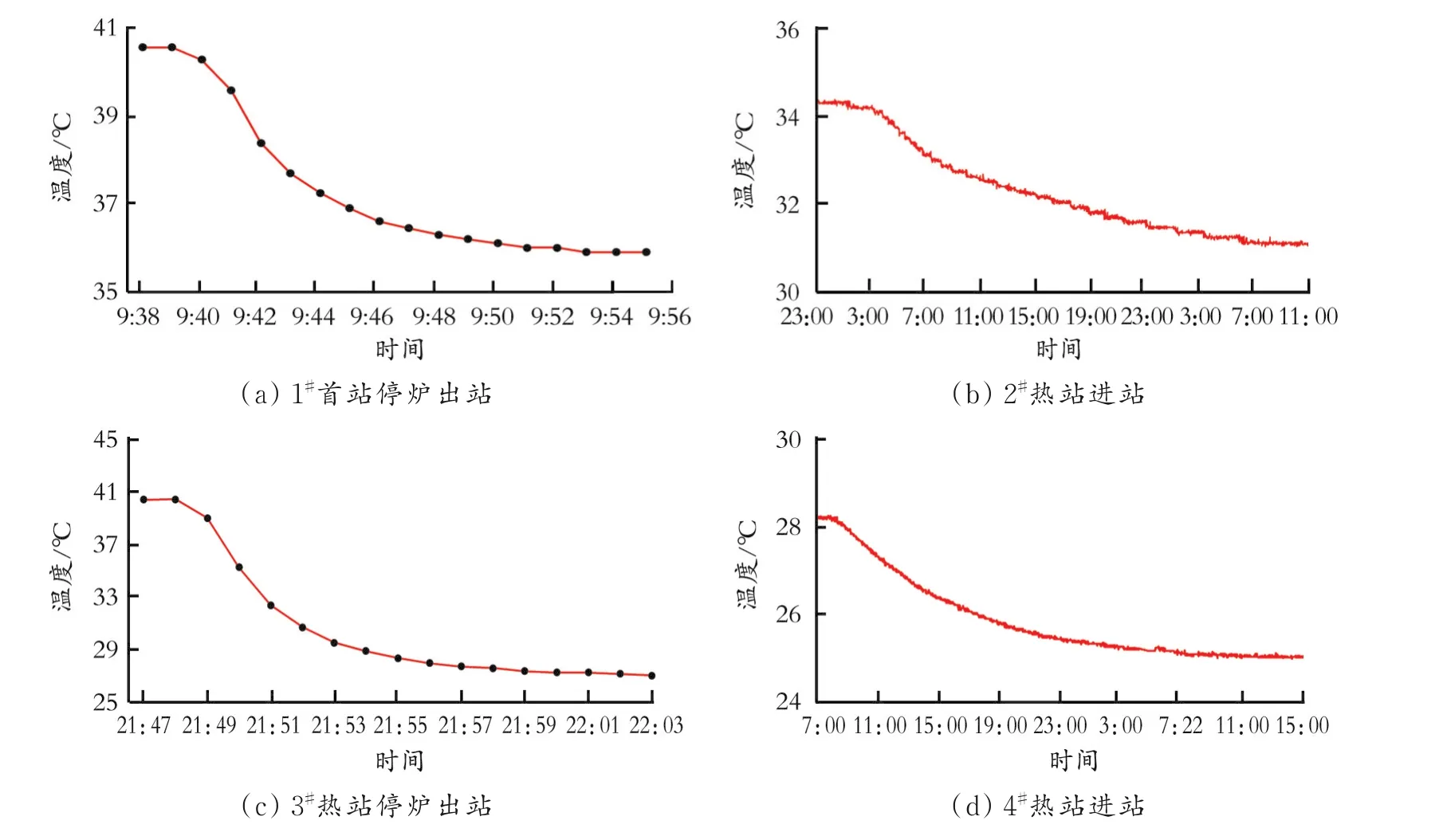
图5 加热炉停炉上下游油温趋势Fig.5 The trend of oil temperature in the upstream and downstream of the furnace shutdown
2.3 模型影响因子
崔慧[7]研究过程中采用的参数获取难度大且有可变性,影响模型的推广应用。本文从SCADA系统采集的生产数据进行相关性分析,结合苏霍夫油温计算公式,使用相关性公式(见式(12)),计算确定影响因子及其相关度。

式中,η为X与Y的相关系数;cov(X,Y)为X与Y的协方差;var(X)为X的方差;var(Y)为Y的方差。
根据式(1),对下游站场进站油温与上游出站油温、上游地温、下游地温、流量、管道沿线摩阻等参数进行相关性分析(见图6)。

图6 下游站场进站油温相关性分析Fig.6 Correlation analysis of oil temperature at the downstream station
上游出站油温、地温,下游地温,管道流量对下游进站非稳态油温的相关性较大,其中上游出站油温相关度最大为0.89,上下游地温的相关度分别为0.59和0.56,流量的相关度为0.29,即上游油温对下游非稳态油温的影响最大。沿线摩阻相关度较小,为0.07,可见管输油品黏度、管壁结蜡等参数对下游进站油温有一定影响。由于非稳态过程时间较短,沿线摩阻参数变化较小,本研究将其忽略。即将上游出站油温、上下游地温和流量4个参数作为非稳态油温模型的影响因子。
2.4 数据下载与处理
选取HY热油管道样本数据,包括该管道,3个管段的上游启、停加热炉,下游的非稳态油温变化数据(见表2)作为模型训练集。

表2 管道样本数据库Table 2 Pipeline sample database
可见上游出站油温和下游进站油温的数据密度分别为10个/min和2个/min数据点,数据量分别为150个和2 880个点。即通过建立模型,实现上游出站油温为150个数据点与下游进站油温2 880个数据点的映射关系。采用Min-Max算法对数据进行归一化预处理,如式(13)所示:

式中,xmax为样本数据的最大值;xmin为样本数据的最小值。
2.5 非稳态油温预测模型构建
基于注意力机制的seq2seq模型(见图4),结合非稳态油温的影响因素,令yt和xt分别为t时刻模型的输出和输入,xt,yt可以表示为:

非稳态油温预测模型架构如图7所示:

图7 非稳态油温预测模型架构Fig.7 Unsteady oil temperature prediction model architecture
流程如下:
(1)利用相关系数公式,获得下游进站油温的影响因素,并将影响因素作为后续模型的输入参数。
(2)根据管道上游出站油温特点,确定数据密度并通过SCADA系统下载相关数据。
(3)对数据进行预处理,剔除异常跳变值,同时进行归一化处置,即将不同表征的油温、地温及流量数据规约到相同的尺度内。
(4)基于注意力机制的seq2seq算法建立非稳态油温预测模型。使用TensorFlow搭建预测模型,隐藏层使用GRU结构,利用Python语言编写相关程序,采用RMSprop优化算法。
(5)将构建训练好的模型用于实际生产预测,并对模型进行评价。
2.5 模型精度评价
本文采用均方根误差(RMSE)和相关性系数(R)两种方法评估模型精度,如式(14)、(15)所示。使用绝对误差和相对误差分析油温的预测值与真实值。

式中,xi和x̂i分别为真实值和预测值和̂分别为真实值和预测值的平均值;N为样本数。
3 结果和分析
3.1 模型评价
对比增加注意力机制前后模型训练耗时和精度,结果如表3所示。由表3可见,增加注意力机制后的seq2seq模型,训练耗时大幅度降低,使模型的训练更加高效快捷。

表3 模型训练对比Table 3 Model training comparison
3.2 模型评价
利用训练完成的非稳态油温预测模型,预测HY原油管道2#热站至3#热站启、停炉后下游进站油温趋势。根据管道实际生产数据和预测数据分析评估模型的实际应用效果(见表4,图8、9)。
可见,上游站场启、停加热炉,所产生的热油、冷油到达下游站场后,油温经过24 h后达到稳态。期间油温的预测值与真实值的拟合度较高,误差为±0.2℃。油温在启炉工况的非稳态过程中,预测值与真实值的R、RMSE分别为0.96、0.11;停炉工况的预测值与真实值的R、RMSE分别为0.99,0.09。预测值的趋势图平滑,有利于分析油温发展趋势。因此,通过seq2seq算法建立的非稳态油温预测模型,可实现热油管道下游站场进站油温的非稳态预测,且具有模型预测准确性高,适于推广应用等特点。

表4 启停炉工况运行参数及预测误差对比Table 4 Comparison of operating parameters and prediction errors of start-stop furnaces

图8 上游启、停炉后下游进站油温趋势预测及误差对比Fig.8 Trend prediction and error comparison of oil temperature in upstream and downstream stations after furnace start-up and shutdown

图9 启、停炉预测值与真实值相关性对比Fig.9 Comparison of correlation between predicted value and real value of start-up and shut-down
4 结 论
研究长输热油管道上游站场启、停加热炉后,冷、热油到达管道下游站场的非稳态过程,提出了一种基于注意力机制的seq2seq算法的非稳态油温预测模型,通过研究得出:
(1)采用相关性公式分析油温的影响因素,获得不同参数对油温的相关度,为后续管道生产工艺调整所需关注的重点参数提供理论支撑。
(2)增加注意力机制的seq2seq非稳态油温预测模型,其训练速度和精度更高。将训练完成的模型应用于实际油温预测,预测结果与实际数据相关性好,可实现非稳态油温的准确预测。
(3)预测模型使用实际生产数据进行训练和测试,最终获得的预测模型可更好地适应于实际生产应用,且随着样本数据的积累,预测精度会逐渐升高。基于生产数据建立的大数据分析模型,更有利于模型在未来大数据平台分析、智能化控制等在线的实时应用。
猜你喜欢
有色设备(2021年4期)2021-03-16 05:42:32
保健与生活(2018年17期)2018-01-27 15:35:10
制造技术与机床(2017年6期)2018-01-19 02:41:14
铁路技术创新(2015年3期)2015-12-21 12:55:48
食品与健康(2015年1期)2015-09-10 07:22:44
铁路通信信号工程技术(2014年6期)2014-02-28 16:58:39
铁路通信信号工程技术(2014年3期)2014-02-28 16:56:30
文苑(2014年2期)2014-02-25 08:34:37
读者(2013年2期)2013-12-25 01:56:38
作文与考试·高中版(2013年9期)2013-04-29 00:44:03
