
基于数据挖掘的太湖蓝藻生长水环境关键因子研究
2020-12-26 02:42李勇涛
河海大学学报(自然科学版) 2020年6期
李 蓓,李勇涛,蔡 梅
(太湖流域管理局水利发展研究中心,上海 200434)
湖泊富营养化是世界性水环境问题,20世纪80年代以来,受环太湖城市经济社会发展及人类活动影响,太湖水体富营养化问题日趋严重[1]。由于湖泊面积较大且环太湖出入湖河道众多,入湖污染负荷量远超湖体自净能力,2019年环太湖河流TP、TN入湖污染负荷分别为太湖纳污能力的3.6倍和4.28倍。受诸多自然及人为因素影响,湖泊水环境复杂多变,富营养化治理难度较大。
2007年无锡由于蓝藻暴发引发饮用水危机,蓝藻事件引起社会广泛关注。2008年5月,国务院批复实施《太湖流域水环境综合治理总体方案》[2]。2013年,为巩固治理成果,提升治理水平,国家发展和改革委员会牵头,会同有关部门深入调查研究,编制形成《太湖流域水环境综合治理总体方案(2013 年修编)》[3](以下简称《总体方案修编》),作为未来一个时期指导太湖流域水环境综合治理的基本依据。随着太湖流域大规模水环境综合协同治理工作的持续推进,太湖富营养化与蓝藻水华的发展势头得到初步遏制,但2016年以来,蓝藻水华仍呈现扩大趋势[4]。为进一步深入探究太湖水体富营养化影响因素及发生机理,郝晨林等[5]通过低通时序滤波轨线法识别出2006年、2011年为太湖营养过程轨线转折点,且气温变化可能是导致太湖富营养化加剧的主要原因。部分研究[6-9]表明,氮、磷是造成太湖富营养化的关键因子,还有大量相关研究则指出蓝藻水华暴发受多种因素影响[10-12],但目前仍未形成共识。
长期以来,太湖流域水环境治理积累了大量的多源监测数据,通过数据挖掘来揭示数据间内在联系、趋势和模式已经成为水环境数据科学领域新的研究手段。“数据挖掘”概念最早由Fayyad等[13]提出,目前广泛应用于教育、生物、金融、医学、电子商务等领域。在水环境领域,曹钦[14]将基于约束的序列模式挖掘算法应用到三峡库区水环境安全预警决策中,曹敏杰[15]基于时空影响域和上下文约束的海洋生态环境关联规则挖掘分析研究,设计了基于关联规则的海洋生态环境时空挖掘分析框架,用于对赤潮现象进行分析与预测预警,均取得了良好效果。目前国内外采用数据挖掘手段开展水环境关键因子识别研究的成果较少,在水环境领域内的关联规则挖掘研究及应用还不够深入,本文拟利用数据挖掘技术,另辟蹊径,基于不断更新的、迅速发展的系列外部多源数据,采用关联规则挖掘算法,识别太湖蓝藻生长水环境关键因子,为太湖水环境治理提供依据。
1 研究区概况
太湖是中国第三大淡水湖泊,位于北纬30°55′40″~31°32′48″、东经119°52′32″~120°36′10″之间。太湖是流域防洪及水资源调配中心和流域内最重要的水源地,苏浙两省环湖大中城市均以太湖为主要饮用水水源地,也是上海市、浙江嘉兴市等下游城市的重要供水水源,同时,太湖通过环湖河道出湖水量为周边及下游地区提供工农业生产、生活用水。按照自然条件和湖区水质研究需要,一般将全湖划分为东太湖、东部沿岸区(含胥湖)、贡湖、梅梁湖、竺山湖、西部沿岸区、南部沿岸区和湖心区。太湖(不含五里湖)目前共布设31个监测点,分设在8个湖区,分别在梅梁湖5个、竺山湖2个、贡湖4个、东太湖3个、湖心区6个、西部沿岸区2个、东部沿岸区4个和南部沿岸区5个(图1)。
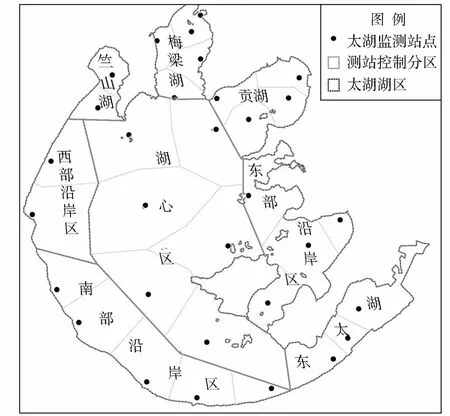
图1 太湖监测站点及分区示意图Fig.1 Distribution of lake sub-regions and monitoring sites of Taihu Lake
2007—2018年太湖蓝藻状况监测数据显示,2007年以来,太湖藻类及蓝藻总体呈扩张趋势,至2017年达到顶峰,2018年两项指标较2017年均有所缩减(图2),其中:2007年蓝藻占全湖藻类比重最低,占比为31.21%;2011年后蓝藻在全湖藻类中占比均不低于80%,且呈现逐年上升趋势;2017年太湖蓝藻占全湖藻类比重达到96.23%,为近12年来最高。研究太湖蓝藻生长机理对太湖水体富营养化治理意义重大。
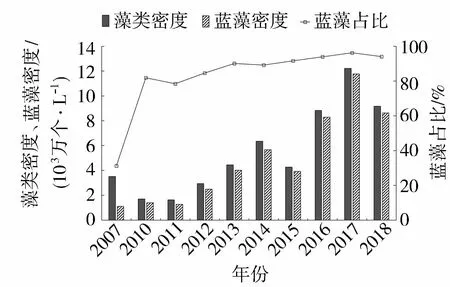
图2 2007—2018年太湖蓝藻状况Fig.2 Conditions of cyanobacteria in Taihu Lake from 2007 to 2018
2 关联规则挖掘原理及方法
2.1 原理
关联规则挖掘是数据挖掘技术中重要的研究内容,用于从海量数据中提取有用的关联信息,发掘数据背后隐藏的关联性[16]。Agrawal等[17]最早提出了基于频繁项集的经典关联规则Apriori算法,其优点为适合事务数据库的关联规则挖掘,主要思想是利用一个逐层搜索的迭代方法,对数据库中所有事务数据项进行扫描来完成频繁项集的挖掘。其中Apriori算法采用了两个重要的性质:
性质1频繁项集的所有非空子集必为频繁项集。
性质2非频繁项集的超集一定是非频繁的。
设I={i1,i2,…,in}是项的集合,事务数据集是由一系列具有唯一标志的事务组成,且每个事务均为I中的子集。设X、Y均为事务数据集中的子集,且互不相交:
X⊆IY⊆IX∩Y=∅
(1)
式中:I——事务数据项集合;X、Y——事务数据集合,皆为I的子集,若两者有关联则可表示为X→Y,X、Y分别为关联规则的前件和后件;∅——空集。
2.1.1 支持度
关联规则X→Y支持度是指事务数据集中包含项目集X和Y的百分比,支持度描述了X和Y同时出现在事务中的概率,支持度越大则表示关联规则越重要。在挖掘过程中,通过设置最小支持度阈值,将支持度不满足要求的关联规则剪枝以提高算法效率。
support(X→Y)=P(X∩Y)
(2)
2.1.2 置信度
关联规则X→Y置信度是指在事务数据集中包含X∪Y的事务与包含X的事务之比,置信度越高表明该规则的可靠度越高。在挖掘过程中,通过设置最小置信度阈值,将置信度不满足要求的关联规则剔除,提高挖掘成果的可靠性。
(3)
2.1.3 算法选取
Apriori算法的剪枝方法可大幅度减少候选项集,提高挖掘效率,国内外许多研究人员针对不同领域问题对Apriori算法进行了大量研究与改进[18-20]。常用关联规则挖掘算法主要特点见表1。

表1 常用关联规则算法及特点Table 1 Common association rule algorithm and its characteristics
经过对比分析,本研究主要针对可能与太湖蓝藻生长相关的多源外部数据进行挖掘,从候选数据体量及算法稳定性方面综合评价,拟采用综合性能较稳定的Apriori算法开展关键因子关联规则挖掘研究。
2.2 研究方法
浮游植物的大量生长是湖泊富营养化的重要现象,通常用Chl-a来表征湖泊富营养化程度[21],采用除Chl-a以外的多源水环境监测数据,通过数据清洗与数据离散后形成关联规则挖掘候选数据集。通过Apriori算法开展满足最小支持度和最小置信度的因子与Chl-a关联规则挖掘,并从中识别出与Chl-a关联性最强的因子,作为影响太湖水体富营养化程度的关键因子。
基于构建的数据集,挖掘关联规则的问题可以转换为寻找满足最小支持度和最小置信度阈值的强关联规则过程,分为两步:(a)生成频繁项集,由频繁项集生成满足最小支持度阈值的项集;(b)生成强关联规则,找出频繁项集中大于或等于最小置信度阈值的关联规则。关联规则挖掘流程见图3。
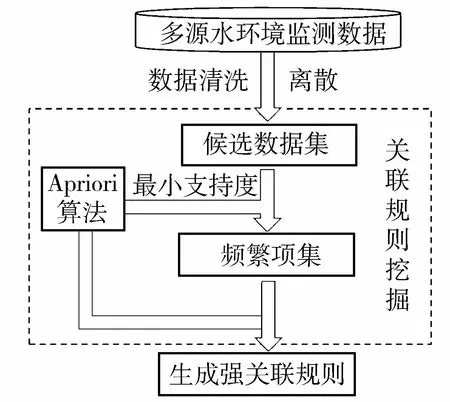
图3 关联规则挖掘流程Fig.3 Flowchart of association rule mining
3 太湖水环境关键因子关联规则挖掘模型构建
3.1 数据准备
为充分挖掘候选数据的内在联系,需尽可能多地考虑可能造成太湖蓝藻生长的因素,但候选数据的监测频次及样本体量应相当,以便对同一时间尺度内的相关因子进行横向关联挖掘。基于上述考虑,本文采用2006—2018年共13年太湖湖区31个监测站点逐月的水温、pH、DO、浊度、CODMn、TN、NH3-N、TP和Chl-a共9类指标序列数据作为关键因子关联规则挖掘研究的数据基础。每个测站同一时间的监测数据作为一条记录,数据标准化后存入数据库。经统计,累计获取监测记录4 703条。
3.2 数据清洗与离散
3.2.1 异常数据剔除
实测数据往往存在数据缺失和数据异常情况,通过数据库管理技术自动识别并剔除包含空值及异常符号的记录,针对数据异常及极端情况,为保证数据离散及挖掘成果的合理性,此处采用拉依达准则法对候选数据中存在粗大误差的数据进行剔除,经数据清洗,获取有效记录3 740条。
3.2.2数据离散
影响太湖富营养化的诸多环境因子均为通过实际监测获取的和时间相关的非连续数据点,需将多值关联规则问题转化为布尔型关联规则问题。考虑到监测数据按照GB 3838—2002《地表水环境质量标准》[22]规定的水质类别区间划分属于评价体系,由人为划定分级,较难体现数据本身的分布特性且易对挖掘结果产生干扰,因此采用无监督学习中的K-Means均值聚类算法(其中K为聚类簇数)。
结合数据本身分布特征进行聚类,参考水质指标分类,本次聚类各项按照不同数量簇别进行聚类,考虑到候选数据样本量,簇别太大虽可对候选数据离散级别进行细分,但较难挖掘出有效强关联规则,经综合考虑,拟采用4、6、8簇进行聚类,经聚类离散后形成候选数据集,分析不同簇别聚类条件对挖掘成果的影响(表2)。
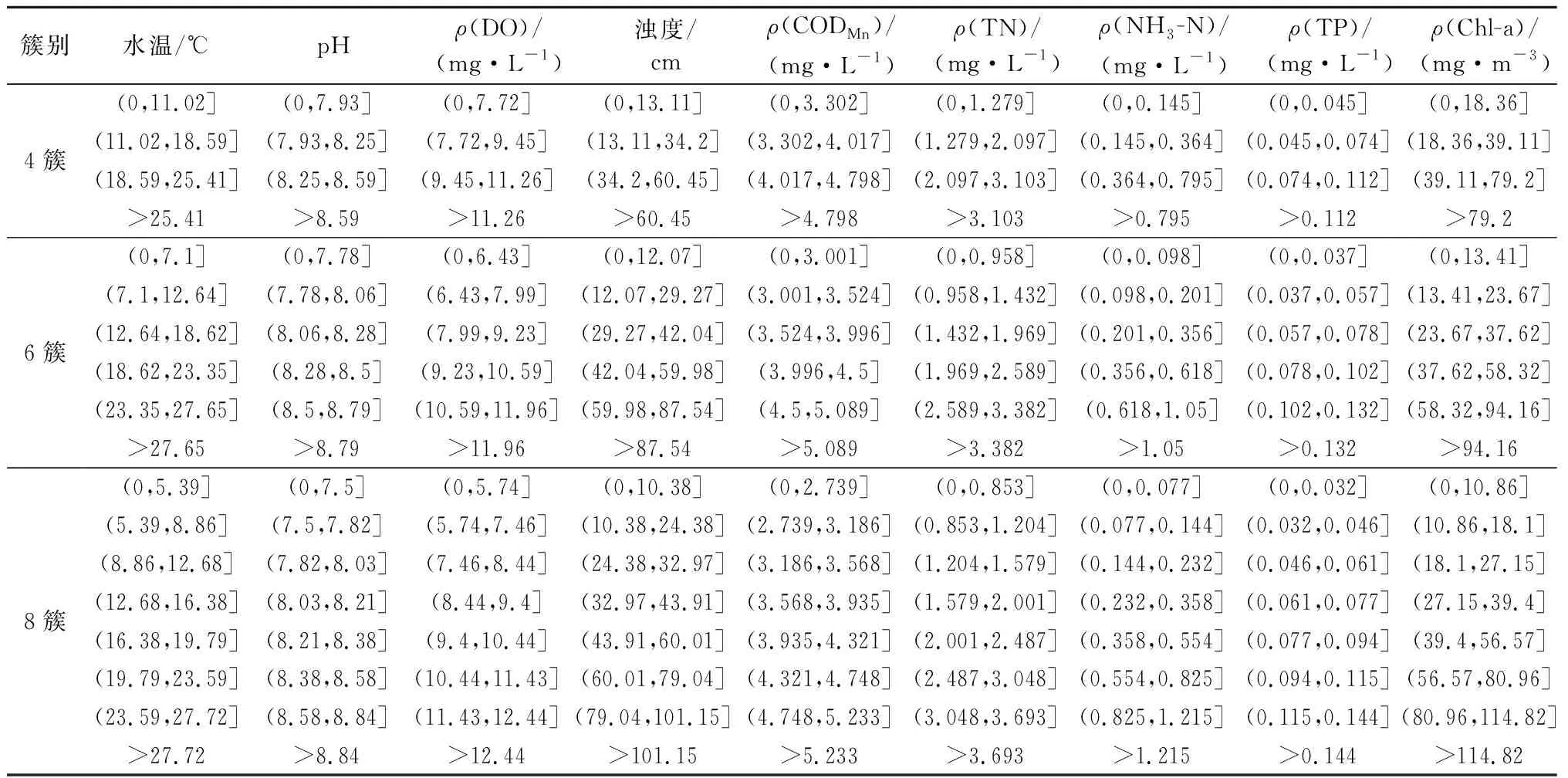
表2 K-means聚类结果Table 2 K-means clustering results
按照表2聚类离散成果,分别将水温、pH、DO质量浓度、浊度、CODMn质量浓度、TN质量浓度、NH3-N质量浓度、TP质量浓度和Chl-a质量浓度按照4簇、6簇、8簇离散形成3套布尔型关联规则挖掘候选数据集。
3.3 关联规则挖掘成果
对候选数据集进行Apriori关联规则挖掘,针对不同簇数据集方案,选定适合的最小支持度和最小置信度,获取关联规则挖掘结果见表3。

表3 关联规则挖掘成果Table 3 Results of association rule mining
从挖掘成果可知,相同样本记录条件下,离散簇类越多,获得强关联规则所需支持度和置信度阈值越小;在支持度和置信度阈值相同条件下,离散簇类越多,获取的强关联规则越少。
4 成 果 分 析
4.1 太湖水环境关键因子
太湖蓝藻生长是一个复杂、非线性的生态过程,涉及物理、化学等多方面影响因素,一些研究者[23-24]通过分析少数几个或某一类水环境因子与Chl-a质量浓度或蓝藻密度等指标间的关联关系,且存在数据量偏少的情况,可能导致结果存在片面性。从不同簇别离散的候选数据集挖掘成果可知,目前太湖水环境状况条件下,TP是影响太湖蓝藻生长的主要关键因子,此外NH3-N、pH和CODMn也与Chl-a存在不同程度的关联关系,研究结论与文献[25-28]总体一致,表明了基于数据挖掘研究方法的有效性。
4.2 关联程度分析
Apriori算法明确了只有在支持度和置信度均较高的情况下该关联规则才属于强关联规则。从关联程度分布情况来看,如图4所示,气泡直径大小表明了该关联规则的强弱,当簇别K越大时,挖掘结果的关联性越小;支持度和置信度阈值设置越小,获得的强关联规则越多,且规则的可靠性越强。
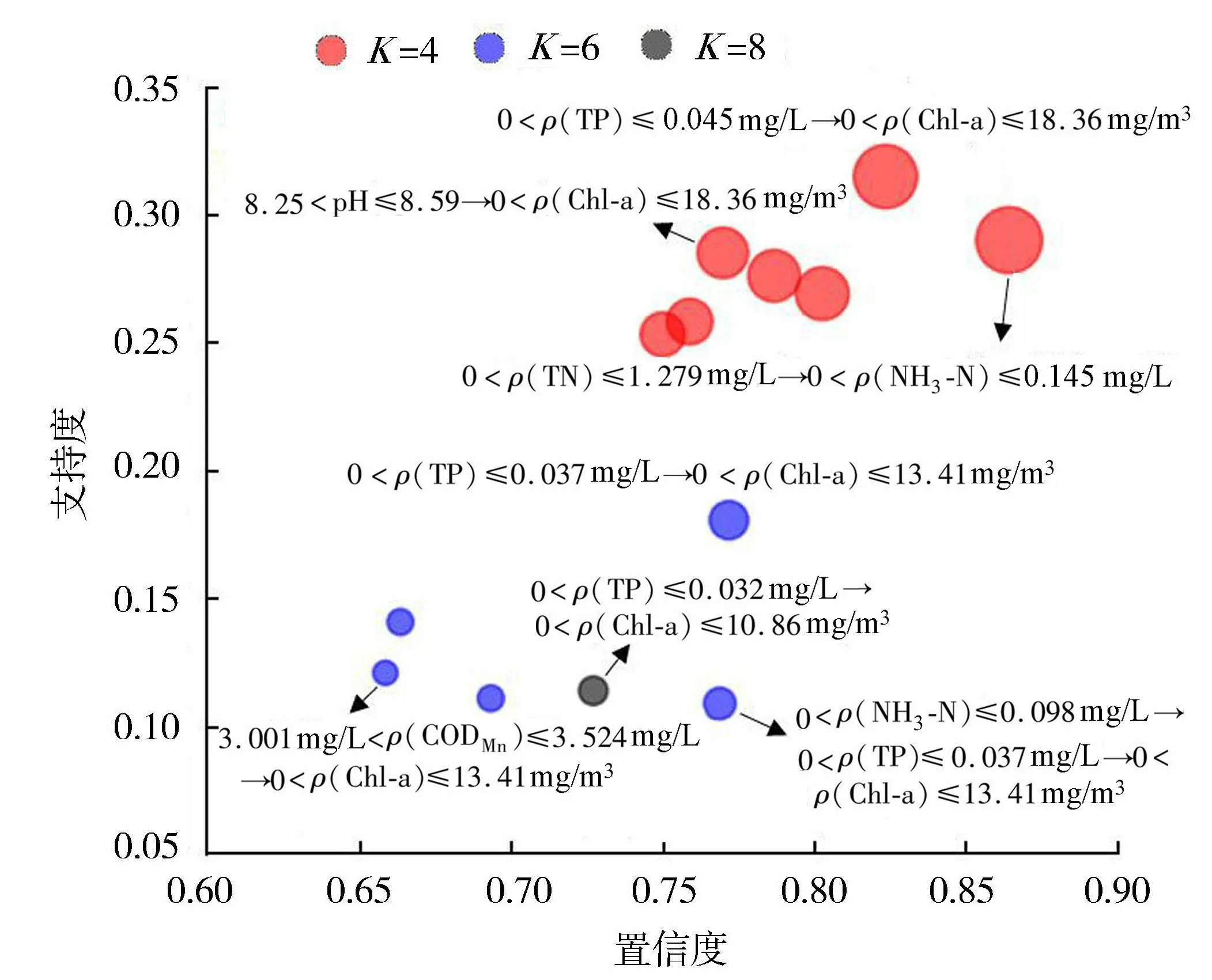
图4 挖掘结果关联程度分布Fig.4 Distribution of relevance degree of mining results
通过调整最小支持度和最小置信度等表征关联程度的参数的阈值,筛选获取候选数据集中蕴含的强关联规则。挖掘结果显示,Chl-a质量浓度与TP质量浓度、NH3-N质量浓度、pH和CODMn质量浓度均呈现不同强度的关联性,按照关联性强度排序为:TP>pH> NH3-N >CODMn,其中:当K=4时,Chl-a质量浓度在0~18.36 mg/m3区间内与TP质量浓度在0~0.045 mg/L区间内关联性最强,其支持度为0.291,置信度为0.866,与pH在7.93~8.25区间内关联性较强;当K=6时,Chl-a质量浓度在0~13.41 mg/m3区间内与TP质量浓度在0~0.037 mg/L区间内关联性最强,其支持度为0.181,置信度为0.773,与CODMn质量浓度在3.001~3.524 mg/L和NH3-N质量浓度在0~0.098 mg/L区间内关联性较强;当K=8时,Chl-a质量浓度在0~10.86 mg/m3区间内与TP质量浓度在0~0.032 mg/L区间内关联性最强,其支持度为0.114,置信度为0.728。
在关联规则挖掘研究中,合理设置关联程度参数能够加快算法计算效率,若最小支持度及最小置信度阈值设置不合理则较难获得理想的强关联规则,因此,在关联程度参数设置上需要首先设定最小支持度阈值,并结合挖掘成果调整最小置信度阈值,直至挖掘成果合理。
4.3 因子敏感区间
经分析,2006—2018年水体监测数据关联规则挖掘成果中TP质量浓度处于0~0.045 mg/L区间内对Chl-a质量浓度在0~18.36 mg/m3区间内敏感度最高。实测资料显示[29-31],2010—2017年太湖北部湖泛易发区Chl-a质量浓度从2010年最低值19.2 mg/m3呈逐年上升,至2017年达到最高,达到质量浓度为56.6 mg/m3,期间湖泛发生次数总体也呈现上升趋势(图5)。受时空分布影响,全湖Chl-a质量浓度较太湖北部Chl-a质量浓度偏低,变化趋势与蓝藻密度一致,2010年为太湖2010—2019年来蓝藻数量最少的年份,其中2015年和2018年各自较前一年略有下降,但总体仍呈现上升趋势。还有研究结论表示,当湖体中蓝藻细胞数量达到2 000万个/L时[32],可被称为蓝藻水华,2010—2019年太湖蓝藻细胞数量处于2 000万个/L以内的2010年及2011年Chl-a质量浓度均高于18.36 mg/m3。因此,从水环境治理角度看,若将太湖TP质量浓度控制在0.045 mg/L以下,则全湖Chl-a质量浓度处于18.36 mg/m3以下的概率最大,可以有效控制蓝藻数量总体处于较少状态,避免太湖蓝藻水华大规模暴发。

图5 2010—2019年太湖北部、全湖Chl-a质量浓度及蓝藻密度分布Fig.5 Distribution of chlorophyll a concentration and cyanobacteria density in northern Taihu Lake and whole lake from 2010 to 2019
对照《总体方案修编》确定的2020年控制目标(图6),截至2019年,太湖NH3-N、TN均已达到控制目标,但CODMn、TP尚未达到。由于近年来TP质量浓度呈现增长趋势,在流域治理中若进一步加大入湖磷负荷控制,将对改善太湖富营养化状况具有积极作用。太湖NH3-N质量浓度2019年已回落至0.087 mg/L,处于较强关联规则取值范围,CODMn在3.001~3.524 mg/L范围内与Chl-a质量浓度在0~18.36 mg/m3区间也呈现一定的关联性,因此,若进一步将太湖CODMn控制在3.001~3.524 mg/L范围内,则全湖Chl-a质量浓度小于18.36 mg/m3的概率最大。本成果在《总体方案修编》确定的控制目标基础上,进一步明确了TP及CODMn等指标控制的具体范围,可为下阶段太湖水环境治理控制目标研究提供技术支撑。

图6 近年来太湖主要水质指标质量浓度变化情况及因子敏感区间Fig.6 Mass concentration changes of main water quality indicators and factor sensitive interval in Taihu Lake
5 结 语
通过构建基于Apriori算法的太湖水环境关键因子关联规则挖掘模型,对影响太湖水体富营养化的水环境关键因子进行识别。经分析,表征太湖富营养化程度的Chl-a质量浓度与TP质量浓度、NH3-N质量浓度、pH和CODMn质量浓度均呈现不同强度的关联性,关联性强度排序为TP>pH> NH3-N > CODMn。
TP质量浓度处于0~0.045 mg/L区间内对Chl-a质量浓度在0~18.36 mg/m3区间内最为敏感。从水环境治理角度看,若将太湖TP质量浓度控制在0.045 mg/L以下,则全湖Chl-a质量浓度小于18.36 mg/m3的概率最大,可以有效控制蓝藻数量总体处于较少状态,避免太湖蓝藻水华大规模暴发。本研究可为下阶段太湖水环境治理控制目标研究提供技术支撑。
猜你喜欢
电子技术与软件工程(2022年15期)2022-11-11
小型微型计算机系统(2022年4期)2022-05-09
皮革制作与环保科技(2020年14期)2020-03-17
当代水产(2019年8期)2019-10-12
当代水产(2019年9期)2019-10-08
计算机应用(2018年5期)2018-07-25
湖北农业科学(2016年20期)2017-02-15
科技视界(2016年13期)2016-06-13
科技传播(2016年7期)2016-04-28
科学24小时(2015年3期)2015-09-10
