
决策树在高校学生学业预警中的应用研究
2020-12-24 07:47:38王芬芬
无线互联科技 2020年20期
张 军,王芬芬
(湖南铁道职业技术学院,湖南 株洲 412001)
0 引言
信息技术高速发展,高校在教育信息化推进的过程中,构建了大量的教育教学以及学工管理的相关学习平台或业务管理系统,随着这些的平台系统的推广使用,累计了大量的数据,将这些数据加以分析和利用,必然能为学校的教学和管理工作带来巨大的帮助。数据挖掘是一门新兴交叉学科,能从海量的、不完整的且有噪声的随机样本数据中训练出分析模型,能快速、有效地挖掘出隐藏在数据里的信息和关系[1]。利用数据挖掘技术提取高校学生数据中潜在的规律和信息,为学校的教育教学改革和学生管理水平的提高提供支持,已经成为当前教育信息化研究的热点。
1 决策树算法
决策树算法是机器学习中的一个重要的分类算法,其基本思想就是利用已有的数据集进行训练学习,生成一个树状模型。对新的数据而言,就可以利用生成的树状模型进行预测分类。简而言之,决策树就是一个利用树型结构进行决策的多分类模型,通过询问一系列二元选择题来做预测,简单有效,易于理解。
要生成决策树,首先要找到最上面的根节点(样本数据的某个特性),将所有样本数据进行分组,形成子节点,然后对每个子节点挑选特征属性,进行再次分组,重复递归这一过程,直到子节点为叶子节点,上述步骤中的关键问题是以何为依据挑选样本数据分组的特征属性。
Quinlan提出的基于信息熵的ID3(Induction Decision-tree 3)算法是决策树技术中的经典算法。ID3 算法以信息论为理论基础,在执行过程中要计算属性的信息熵与信息增益,然后在每次分类判断是以信息增益为标准,通过选择信息增益高的属性进行分类[2]。
信息熵值可以用来衡量一组样本数据的混乱程度,熵值越高,样本数据越混乱,反之,样本数据的“纯度”越高,信息熵值的计算方法如下:
(1)
式中:n表示样本数据集D中的类别数量,Pi表示第i类样本数据在当前数据集中所占的比例。
信息熵值可以度量出一个样本数据集合的“纯度”,但生成决策树是要在样本数据集中找出一个特征属性,利用其进行分组能使各组的样本数据快速变纯,于是就可以用未分组前的信息熵值减去分组后各组信息熵值的和,这样得到的值就可以衡量出利用该属性特征进行分组所获得的“纯度提升”到底有多大。考虑到不同分组所包含的样本数量的是不同的,所以可以给每个分组的信息熵值再赋一个权重(分组样本数/总样本数),这样样本数越多的分组影响就越大。于是便可计算出利用某个特征属性对样本数据集进行分组所获得的信息增益,计算过程如下。
首先,计算选定特征属性分组后各分支节点的加权信息熵值:
(2)
式中:N表示数据集样本总量,Na表示第a个节点的样本数,e表示第a个节点的样本类别数量,Na(i)表示节点a中第i个类别的样本数量。
用分组前的信息熵值减去用某一特征属性分组后各分支节点的加权信息熵的累加和就是该特性属性的信息增益[3],计算公式如下:
(3)
式中:t表示对样本数据集分组的特征属性,v表示属性t分组的节点个数。
每次分组都挑选信息增益值最大的特征属性作为根节点(父节点),这样即可完成一棵决策树的构造。
2 应用实现
2.1 样本数据的选取与处理
高校学生的学业情况有来自多个方面的影响因素,学生平时的努力刻苦起主要作用,也有很多其他客观因素的影响,本文结合高校的实际数据情况,所选取的样本数据特征属性如下。
入学成绩:学生考入学校的高考成绩,需做离散化处理。
操行评定:学生在学校的日常表现,有辅导员评定,包括考勤、平时参与各类活动情况。
是否兼职:学生是否在校外有课外兼职。
是否贫困生:学生的家庭收入情况,是否评定为贫困生。
学习情况:学生日常的作业完成和课堂表现情况。
从教务、学工等相关系统获取原始数据,对数据进行整合和离散化处理,整出600条样本数据,其中包括200条被预警的学生数据,基本结构如表1所示。

表1 样本数据基本结构
2.2 学业预警实现
本文学业预警系统构建使用操作系统平台为Windows 7,数据库管理系统使用Microsoft SQL Server 2012,系统构建流程如图1所示。
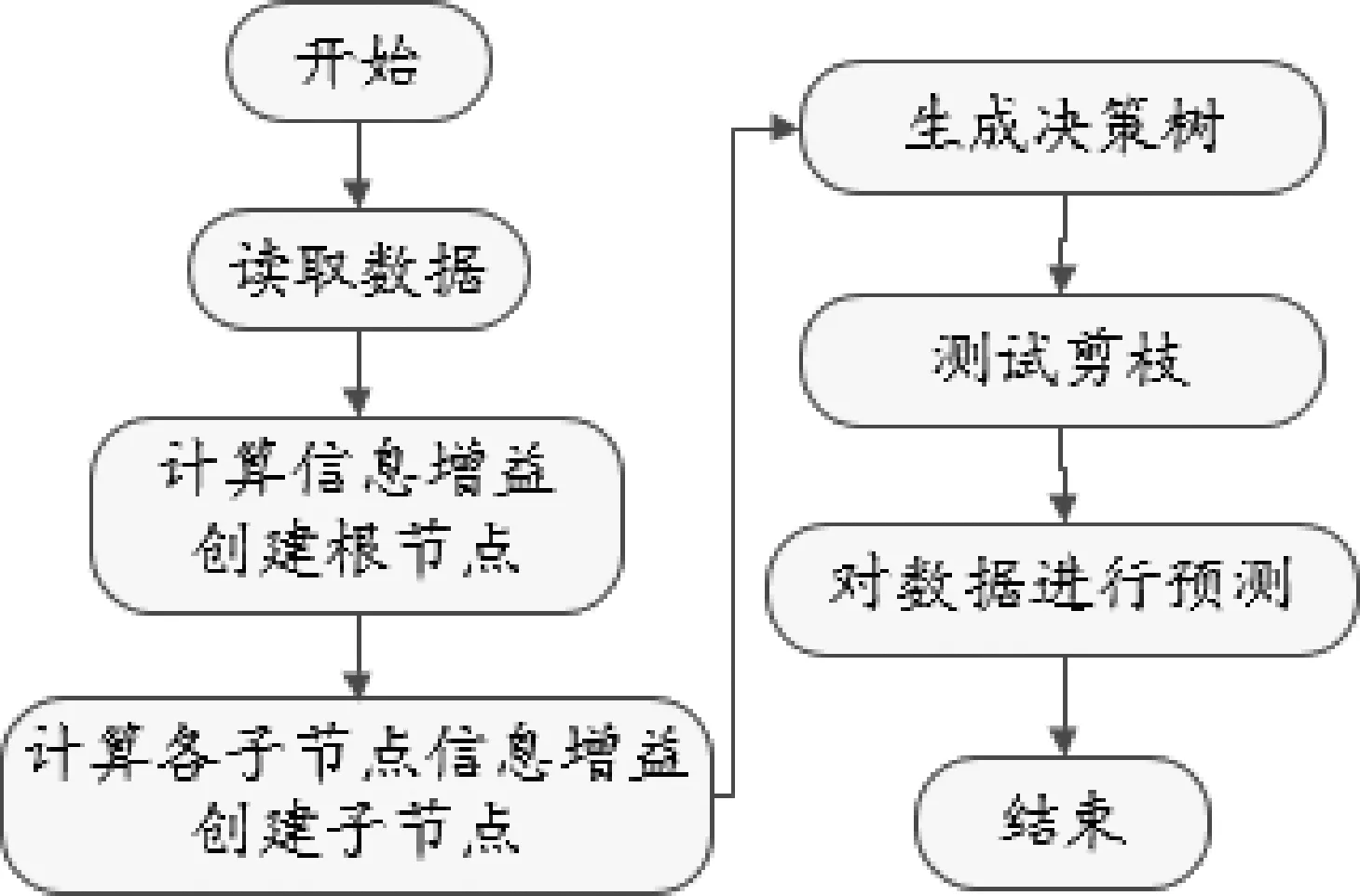
图1 系统构建流程
对样本数据5个特征属性所生成的5种分组情况,分别计算其信息熵值和信息增益值,以信息增益值最高的特征属性为决策树的根节点,根据计算结果,特征属性学习情况的信息增益值最大,可为决策树的根节点,然后将其各分支节点的样本数据作为独立样本集合,再次计算每个分支节点中可用特征属性的信息增益值,再次分组,重复该过程即可构建一棵用于学生学业预警的决策树模型。已构建完成的决策树存在训练过度的情况,需要进行剪枝处理,以提高决策树预测的准确性,本文经过测试分析,对生成的决策树剪枝处理后所获取的分类规则如下。
(1)当学生的学习情况为C,操行评定为C,且入学成绩也为C的情况下,出现学业预警的概率为76%;
(2)当学生的学习情况为C,操行评定为C,入学成绩为B,被评定为贫困生同时参加了社会兼职,出现学业预警的概率为58%;
(3)当学生的学习情况为C,操行评定为C,入学成绩为B,被评定为贫困生,出现学业预警的概率为30%。
3 结语
本文主要讨论了利用数据挖掘技术中的决策树算法来构建高校学生学业预警模型,分析了决策树算法的构建过程,基于高校的数据环境,综合学生在校相关数据,选取了5种特征属性,通过样本数据集构建了学业预警决策树模型,通过验证,该模型准确率高,具有良好的预测效果。将机器学习的相关算法应用到高校学生学业预警中,不仅能提高预测的针对性和准确性,同时可以为高校教学以及学工管理部门提供数据支持,保证了数据科学、有效的使用。
猜你喜欢
红蜻蜓·高年级(2022年6期)2022-06-16 02:53:58
军民两用技术与产品(2022年1期)2022-06-01 06:28:50
疯狂英语·新悦读(2019年12期)2020-01-06 03:28:06
中学语文(2019年34期)2019-12-27 08:03:46
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
电子测试(2017年12期)2017-12-18 06:35:48
雷达学报(2017年6期)2017-03-26 07:52:58
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
池州学院学报(2015年3期)2016-01-05 01:13:00
