
基于分层最大边缘相关的柬语多文档抽取式摘要方法
2020-12-23 11:25曾昭霖严馨余兵兵周枫徐广义
河北科技大学学报 2020年6期
曾昭霖 严馨 余兵兵 周枫 徐广义

摘 要:为了解决传统多文档抽取式摘要方法无法有效利用文档之间的语义信息、摘要结果存在过多冗余内容的问题,提出了一种基于分层最大边缘相关的柬语多文档抽取式摘要方法。首先,将柬语多文档文本输入到训练好的深度学习模型中,抽取得到所有的单文档摘要;然后,依据类似分层瀑布的方式,迭代合并所有的单文档摘要,通过改进的最大边缘相关算法合理地选择摘要句,得到最终的多文档摘要。结果表明,与其他方法相比,通过使用深度学习方法并结合分层最大边缘相关算法共同获得的柬语多文档摘要,R1,R2,R3和RL值分别提高了4.31%,5.33%,6.45%和4.26%。基于分层最大边缘相关的柬语多文档抽取式摘要方法在保证摘要句子多样性和差异性的同时,有效提高了柬语多文档摘要的质量。
关键词: 自然语言处理;柬语;抽取式摘要;深度学习;瀑布法;最大边缘相关
中图分类号:TP391文献标识码: A
doi:10.7535/hbkd.2020yx06005
Khmer multi-document extractive summarization method
based on hierarchical maximal marginal relevance
ZENG Zhaolin1,2, YAN Xin1,2, YU Bingbing1,2, ZHOU Feng1,2, XU Guangyi3
(1.Faculty of Information Engineering and Automation, Kunming University of Science and Technology, Kunming,Yunnan 650500,China;2.Yunnan Key Laboratory of Artificial Intelligence,Kunming University of Science and Technology,Kunming, Yunnan 650500,China;3. Yunnan Nantian Electronic Information Industry Company Limited, Kunming,Yunnan 650040,China)
In order to solve the problem of ineffective utilization of the semantic information between documents in the traditional multi-document extractive summarization method and the excessive redundant content in the summary result, a Khmer multi-document extractive summarization method based on hierarchical maximal marginal relevance(MMR)was proposed. Firstly, the Khmer multi-document text was input into the trained deep learning model to extract all the single-document summaries. Then, all single document summaries were iteratively merged according to a similar hierarchical waterfall method, and the improved MMR algorithm was used to reasonably select summary sentences to obtain the final multi-document summary. The experimental results show that the R1, R2, R3, RL values of the Khmer multi-document summary obtained by using the deep learning method combined with the hierarchical MMR algorithm increases by 4.31%, 5.33%, 6.45% and 4.26% respectively compared with other methods. The Khmer multi-document extractive summarization method based on hierarchical MMR can effectively improve the quality of Khmer multi-document summary while ensuring the diversity and difference of the summary sentences.
Keywords:
natural language processing;Khmer; extractive summarization;deep learning;waterfall method;maximal marginal relevance(MMR)
随着“一带一路”倡议的实施,中国和柬埔寨作为重要的双边贸易国家和友好合作伙伴,交流与往来日益增加,有关柬埔寨语(简称柬语,下同)的自然语言处理技术[1]研究变得尤为重要。随着互联网技术的发展、信息的增加以及传播和交互速度的迅速加快,人们对互联网的需求正在发生变化[2]。如何从大量冗余信息中快速得到主要内容已成为当前研究的热点。简短的摘要可以帮助人们快速获取信息,加快信息传播速度。根据待观察文档数量的多少,可以将文檔摘要的形式分为单文档摘要[3]和多文档摘要[4]。前者是对一个文档内容进行提取生成一篇摘要,后者是从一个话题下的多篇相关文档中生成一篇摘要。单文档摘要技术主要面向单个文档,随着时代的发展,多文档摘要技术逐渐得到重视。迄今为止,已经有很多方法被应用到多文档摘要技术中,主要分为基于特征的方法、基于聚类的方法、基于图模型的方法和基于深度学习的方法。
基于特征的方法即对语料进行特征构造,转化为句子排序问题,依据句子的重要性挑选摘要句,组合形成摘要。常用的句子特征如句子位置、句子长度、线索词等[5]。常用于基于特征的多文档摘要方法还有基于中心性(Centrality)[6]相关方法,其是在识别输入源中心通道的基础上检测出最显著的信息,用于生成通用的摘要;而基于覆盖率(Coverage)[7]的方法则产生由单词、主题、时间驱动的摘要。基于特征的多文档摘要方法虽然已得到广泛研究,但该方法无法理解文档的上下文信息,仅在句子级别对句子进行评分。
基于聚类的方法即将句子集进行归类。尽管多文档包含多个主题且各文档内容通常有所不同,但是通过聚类方法可以提取出在聚类簇中表达主题信息的句子形成摘要[8]。RADEV等[9]提出了基于质心代表文档集合的逻辑主题的抽取式摘要方法;MCKEOWN等[10]开发了基于片断聚类方法的多文档摘要系统MultiGen,识别出不同文件间的相似之处和不同之处,通过语义相似度提取主题,从主题中抽取交集作为关键词,生成连贯的摘要。但是,基于聚类的方法需要事先知道聚类的类别数。
基于图模型的方法广泛用于多文档摘要任务中,把诸如句子和段落之类的文本单元集成到基于图的结构中,使用类似投票机制提取文本摘要[11]。典型的图模型为PageRank算法[12], 初始时为每个页面分配相同的重要性评分,根据算法迭代更新每个页面的PageRank评分,直至评分稳定。TextRank是在PageRank算法基础上,对每个词节点附上权值,构建关于词的无向带权图,建立图模型,利用投票机制对文本的重要成分进行排序,生成摘要[13]。YASUNAGA等[14]提出了GCN(graph convolutional network)模型,将句子关系图融入到神经网络模型中,得到句子的重要性,利用依此产生的句子高维表征,通过重要性估计提取摘要句。
基于深度学习的方法即利用深度学习训练出词、句子等级别具有上下文信息、语义关系的表征,以便更好地生成摘要[15]。CAO等[16]针对基于查询的多文档摘要任务,提出了AttSum模型,采用联合学习的方法结合卷积神经网络和注意力机制对句子进行建模表示,能够有效学习到文档主旨和摘要句子之间的相关性;NALLAPATI等[17]提出了基于循环神经网络的SummaRuNNer模型,从文本的重要性和新颖性等角度出发,解释文本摘要的生成过程;NARAYAN等[18]利用基于Encoder-Decoder框架的分层文档编码器和基于注意力的解码器结构,结合附带信息的关注来更好地选择摘要句。但是单纯的基于深度学习的方法需要大量数据对模型进行训练。
目前柬语自然语言处理研究的基础较为薄弱,且主要集中在命名实体识别与可比语料方面,关于多文档摘要方面的研究十分稀少,领域专家人工标注的代价十分昂贵,柬语多文档摘要语料较为匮乏。已有多文档抽取式摘要方法大多使用的是有监督的学习方法,不太适用于柬语多文档摘要。本文利用无监督学习方法,在不依赖任何标注数据的情况下,通过对多文档内在特征的挖掘,找到文档间的关系,使用类似瀑布分层的方式,结合改进的最大边缘相关算法MMR[19],基于句子特征的5种评估方法的综合得分决定摘要句的重要性,依据ROUGE-L[20]召回率评估候选摘要句与已选摘要句之间内容的冗余关系,迭代合并通过深度学习模型得到的单文档摘要集,有效提高柬语多文档摘要的质量,保证摘要结果的多样性和差异性。
1 多文档抽取式摘要的主要內容
在通过训练好的CNN-LSTM-LSTM深度学习模型得到柬语单文档摘要集的基础上,添加一种分层最大边缘相关算法,迭代合并所有单文档摘要作为最终的多文档摘要。考虑到多文本摘要任务中存在较多的冗余内容,本文用于抽取单文档摘要的深度学习模型参数无法识别多文档文本中较多的冗余内容,于是提出了一种基于分层最大边缘相关算法的柬语多文档抽取式摘要方法。该方法分2步完成:第1步,将每个单文档文本输入到已经训练好的CNN-LSTM-LSTM深度学习模型中,获取所有的单文档摘要;第2步,依据类似瀑布的方式,将按新闻时序排序的单文档摘要集通过改进的最大边缘相关算法,迭代合并所有单文档摘要,得到最终的多文档摘要。过程如图1所示。
本文中的CNN-LSTM-LSTM深度学习神经网络模型的输入层为已经过分词、词性标注、去噪等预处理之后的柬语多文档新闻语料。在深度学习神经网络模型中,先使用卷积神经网络CNN对输入文档D中的n个句子进行编码,获得所有句子S的句子表征{S1,S2,…,Sn},将其作为长短期记忆神经网络LSTM(long short-term memory)[21]的输入。根据CNN-LSTM-LSTM网络结构可知,文档编码器LSTM的隐藏状态为{h1,h2,…,hi,…,hn},其中hi表示文档D中第i个句子对应的文档编码器LSTM中的隐藏状态,通过文档编码器LSTM得到该输入文档的表征hn,hn为包含文档D中所有句子信息的最后一个隐藏状态。句子提取器LSTM作为另外一种循环神经网络,初始的隐藏状态的输入为与其相连的文档编码器LSTM中的最后一个隐藏状态hn,也是输入文档的表征。句子提取器LSTM中的隐藏状态表示为
t=LSTM(pt-1St-1,t-1) 。
式中:t表示在第t个时间步句子提取器LSTM的隐藏状态;pt-1表示句子提取器认为前一句应该被提取的概率;St-1表示前一句的句子表征。
结合注意力机制[22]的句子提取器在处理第t个时间步的句子时,通过将其当前的隐藏状态t与其在文档编码器中的隐藏状态ht相关联,经过以下处理得到该句子为摘要句标签的概率:
P(yL=1|St)=σ(MLP([t;ht]))。
式中:yL∈{0,1}为文档D中的句子是否为摘要句的标签,1表示该句为摘要句;MLP是一个多层神经网络,输入为[t;ht],“;”表示连接;σ表示Sigmoid激活函数。CNN-LSTM-LSTM神经网络模型结构示意图如图2所示。
1.1 从单文档摘要到多文档摘要
通常将包含多个单文档文本摘要的集合称为多文档摘要,与单文档摘要相比,多文档摘要包含众多的冗余内容,同一话题在不同摘要中重复出现。如何将单文档摘要集转化为更为高效的多文档摘要是本文解决的问题。传统的多文档摘要方法[23]是将所有单文档文本连接起来,看成一个文档,再使用单文档摘要方法生成最终的多文档摘要。当单文档文本数目较少时,该方法表现出良好的效果,但随着文档数量的逐渐增加,该方法的性能逐渐下降,在识别冗余内容时具有局限性。另外,该方法也忽略了事件发生的时间信息。为了克服该方法的局限性,一种可能的策略是先逐个抽取出单文档摘要,并将它们有规则地迭代组合在一起。为了迭代组合单文档摘要,笔者提出瀑布法,如图3所示。瀑布法包含2步。首先,将柬语多文档文本通过CNN-LSTM-LSTM深度学习神经网络模型,获得关于每篇文档的单文档摘要集{S1,S2,…,Sj,…,Sn},Sn假设为最后一篇单文档摘要;其次,将第1个单文档摘要S1和第2个单文档摘要S2连接在一起,合并为一个输入摘要,通过改进的MMR算法和句子的重要性得分评估对2个单文档摘要的句子进行排序,挑选前若干个MMR总得分最高的句子进行合并,作为该阶段合并后的文档摘要S1,2,再采取同样方法,將合并得到的文档摘要S1,2与第3个单文档摘要S3连接合并,得到该阶段合并后的文档摘要S1,2,3。重复上述方法,直到迭代完成所有抽取出来的单文档摘要,得到一个最终的柬语多文档摘要。
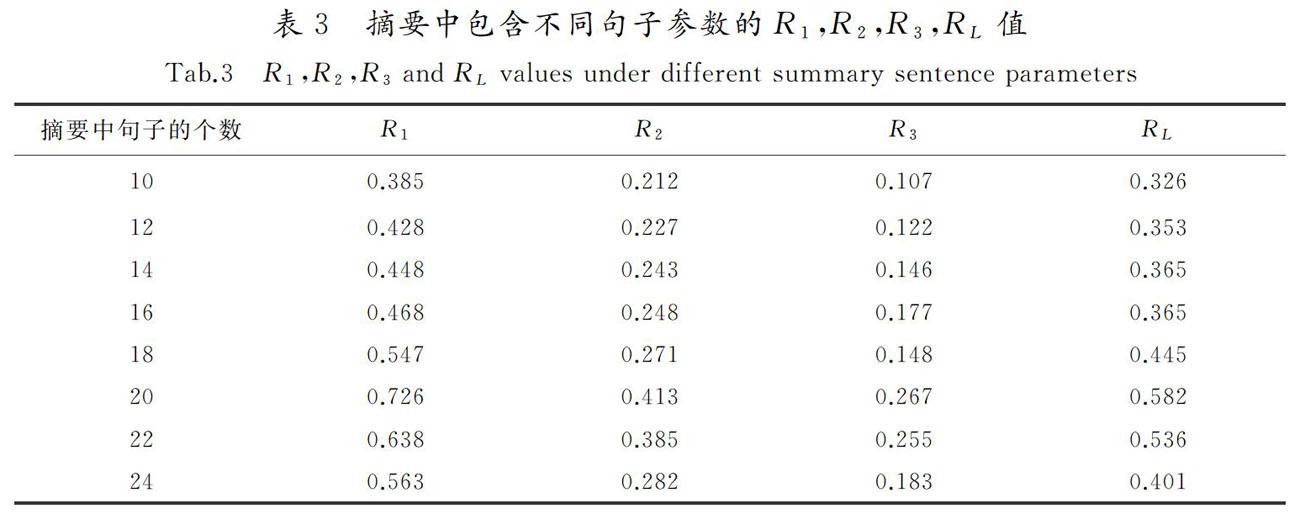
该方法对输入文档摘要的时间顺序较为敏感,在每次迭代过程中,候选摘要都要与已选摘要合并,所以初始文档的摘要比后面文档的摘要更有可能被删除。由于较新的新闻内容更符合人们的信息需求,因此本文依据新闻文档的时间顺序对单文档摘要集进行排序后再进行合并。通过实验表明,摘要中包含的句子个数为20的时候,效果最好,因此把20设为本文摘要包含的句子个数参数。这种方法可以很好地解决每个文档内与每个文档之间的信息冗余问题,在保证多文本摘要多样性的同时,可以保证多文档摘要的差异性。
1.2 分层最大边缘相关算法
最大边缘相关算法MMR(maximal marginal relevance),是一种用于实现文档摘要的方法。新闻文本中包含许多重复的背景信息。MMR的主要思想是使所选的摘要句与文档主旨高度相关,在确保摘要多样性的同时,使候选摘要句与已选摘要句之间的差异性尽可能大,最终摘要结果仅有较低冗余信息,达到平衡摘要句之间多样性和差异性的目的。
本文使用改进的MMR算法,在句子重要性评估得分上,使用基于句子特征的5种评估方法的综合得分表示句子和文档主旨的相似性得分,以便更好地选择摘要句子;在句子的差异性比较上,利用ROUGE-L召回率进行评估,依据候选摘要句子与已选摘要句子之间的差异性得分,降低多文档摘要内容的冗余。首先,在已按新闻时序排好的单文档摘要集D中,利用句子重要性评估方法选择得分排在最前的摘要句Sj作为初始摘要句子,将其添加到已选摘要句集S中,初选摘要句子Sj是单文档摘要集D中重要性得分最高的一句,同时也是当前已选摘要句集中内容重叠最少的;然后,通过MMR算法计算剩余摘要句的得分值,决定是否将其添入已选摘要句集S中。不断迭代计算单文档摘要集D中的剩余摘要句子,直至已选摘要句集S达到摘要长度的限制。改进的MMR算法计算公式表示为
MMR=arg max[DD(X]Si∈D\S
[λsim1(Si,D)[TXX}-*2][DD(X] 重要性
-(1-λ)max[DD(X]Sj∈S sim2(Si,Sj)][TXX}]
冗余性。
式中:D为单文档摘要的结果文档集,由所有抽取出来的单文档摘要按新闻时序排列组成;S为当前已选摘要句集;Si表示候选摘要句;Sj表示已选摘要句集S中的已选摘要句;λ是平衡因子;λsim1(Si,D)表示候选摘要句Si与单文档摘要集D的相似度,作为该句重要性的评估,其值越大,表明句子Si与文档主旨的相关度越紧密,包含重要的文档主旨信息,适合作为摘要句;(1-λ)max[DD(X]Sj∈S sim2(Si,Sj)表示候选摘要句Si与已选摘要句Sj之间的相似性,作为句子Si的冗余性评估,其值越小,表明该句与已选摘要集S之间的差异性越大,两者间的冗余内容越少。迭代计算能使重要性和差异性之间平衡最大的候选摘要句加入已选摘要句集S。通过实验调整λ值,达到摘要句多样性和差异性之间的平衡。 分层最大边缘相关算法描述如表1所示。
1.2.1 句子的重要性评估
为了评估摘要句子的重要性sim1(Si,D),选取若干关于句子不同特征的比较方法,通过计算基于句子不同特征的综合得分,用来代表摘要句子与文档之间的重要性得分。本文使用基于句子5种不同特征的得分评估摘要句的重要性,包括基于句子中关键词的得分、基于句子与多文档标题相似性的得分、基于句子中线索词的得分、基于句子长度的得分以及基于句子位置的得分。
1)基于句子中关键词的得分
关键词是反映文章中主题的词语,句子包含的关键词越多,其包含文档主题的信息量就越大,句子就越重要。关键词的提取,首先要将分词后的单文档摘要文本过滤掉无意义的停用词,然后使用TF-IDF(term frequency-inverse document frequency, 词频-逆文本频率)算法计算出每个词语的权重,最后根据词语的权重提取出关键词。词语TF-IDF权重的计算公式为
Wi,j=tfi,j×logNnj+1。 (1)
式中:Wi,j表示特征词的TF-IDF权重;tfi,j表示词语wi在当前文本dj中出现的频率;N表示抽取出的单文档摘要集的文本总数;nj为单文档摘要集合中包含词语wi的单文档摘要文本数目;nj+1中的+1为拉普拉斯平滑,防止当nj为0时出现分母为0的非法情况。
计算得到每个词语的权重是出于关键词得分对句子重要性的影响考虑,挑选出词语权重排在前面的若干实词作为关键词短语(通常为5~10个)。研究发现,抽取出权重最大的前8个实词作为关键词较为合适。基于关键词的得分计算公式为
WX(Si)=∑8k=1W(Si,k)。
式中:WX(Si)表示句子Si基于关键词的得分;∑8k=1W(Si,k)表示句子Si包含的关键词得分之和;Si,k表示句子Si中所包含的关键词;W(Si,k)表示句子Si中包含的关键词所对应的权重大小。
由于柬语句子长度变化较大,为了避免因为句子长度差距导致的句子间重要性得分差距过大,在句子包含TF-IDF关键词权重的基础上进行归一化处理,使不同长度的句子基于关键词权重值处于同一数值范围,计算公式为
W1(Si)=(WX(Si)-min WX(S))(max WX(S)-min WX(S))。
式中:W1(Si)为句子Si归一化后基于关键词的句子得分;WX(Si)为句子Si归一化前基于关键词的句子得分;max W(S)为所有句子中得分的最大值;min W(S)为所有句子中得分的最小值。
2)基于句子与标题相似度的得分
新闻文本标题通常能反映該文本的主题,对摘要句的重要性评估具有很大影响。通过计算摘要句和标题之间的相似度得分来评估单文档摘要集中摘要句子的重要性,相似度越大,则该句就越重要,被选中的可能性就越大。在向量空间模型VSM中通过余弦相似度计算,句子Si和标题C以包含关键词的得分作为特征的向量表示之间的相似度得分,表示摘要句和标题的整体相似度得分。本文中Si=(WSi,1,
WSi,2,…,WSi,8),
C=(WC1,WC2,…,WC8)。基于句子和标题的余弦相似度得分计算公式为
W2(Si)=
∑8k=1W(Ck)×W(Si,k)
∑8k=1W(Ck)2×
∑8k=1W(Si,k)2。
式中:W2(Si)表示句子Si与标题C的相似度得分,分值越高,与文本主旨的相关度越高,句子Si越应该被选取;W(Si,k)表示句子Si中所包含的由式(1)得出的第k个关键词权重;Ck表示标题C中所包含8个关键词中的第k个关键词;W(Ck)表示标题C中所包含的第k个关键词得分。
3)基于句子中线索词的得分
句子中某些词语并不是关键词,但是依然可以起到提示性的作用,如“综上所述”“总而言之”“说明”等具有对文本主旨内容牵引的指示词,会包含更多的信息,应该给予较大权重。句子Si基于是否包含线索词WC的得分规则如式(2)所示:
W3(Si)= 1, WCSi,
0, WCSi。(2)
4)基于句子长度的得分
过短的句子通常没有实际意义,并且包含文档主旨的信息很少;过长的句子虽然包含了更多语义信息,但是内容过于繁杂,通常不属于摘要。因此,摘要句的选择应该选择长度适中的句子。句子Si基于句子长度LSi的得分规则如式(3)所示:
W4(Si)=
1, 15≤LSi≤25,
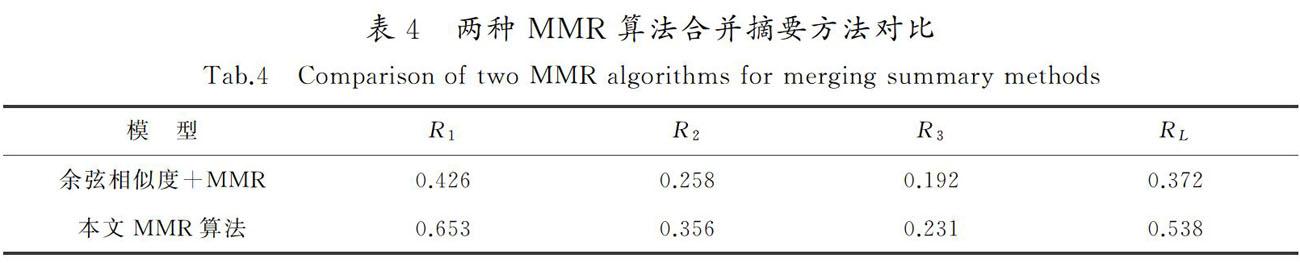
0.5, 5≤LSi<15 or 25 0, others 。 (3) 5)基于句子位置的得分 大部分柬语新闻文本结构的特点会在首段或者首句对该篇新闻报道的主题核心进行说明。通过阅读大量新闻报道发现,为了吸引读者的阅读兴趣以及方便读者能够快速了解所报道的事件,新闻报道文章往往会在首段的首句引出新闻主题核心,在首段的非首句仍然是对新闻报道的总结性描述。因此应该给予句子Si位于首段 Pfirst首句Sf和首段非首句更高的权重,计算规则如式(4)所示: W5(Si)= 1, SiPfirst and Si=Sf, 0.5, SiPfirst and Si≠Sf, 0, SiPfirst。[JB)][JY] (4) 通过计算上述基于句子5种不同特征重要性得分的组合,对单文档摘要集中每个摘要句子的相关度和重要度进行综合评分。基于句子综合特征的重要性得分计算式如(5)所示: Score(Si)=∑5n=1(γn×Wn(Si)) 。 (5) 式中: Score(Si)表示句子Si的综合评估得分;Wn(Si)表示第i个句子基于第n项句子特征的重要性得分;γn表示关于上述5项基于句子不同特征得分在综合得分中的比例因子系数,且∑5n=1 γn=1,1≤n≤5,且n为整数。通过计算Score(Si)得到每个摘要句Si的sim1(si,D)的重要性得分。 1.2.2 句子的冗余性评估 为了评估候选摘要句与已选摘要句之间的差异性得分 max Sj∈S sim2(Si,Sj),Si表示候选摘要句,Sj表示已经被选中的摘要句,S表示已选摘要句集,利用ROUGE-L召回率评估,通过计算候选句子和已选摘要句子之间的最长公共子序列长度,除以已被选中摘要语句的长度,作为候选摘要句子的差异性得分。产生较高ROUGE-L精度的候选语句认为与已选摘要有着显著的内容重叠,它将获得较低的MMR分数,因此不太可能作为摘要句,达到去除多文档摘要内容冗余的目的。计算式如式(6)所示: Rlcs=LCS(X,Y)m 。 (6) 式中:X表示候选摘要句;Y表示已经被选中的摘要句;LCS表示X与Y的最长公共子序列的长度; m表示已被选中的摘要句的长度;Rlcs表示候选摘要句与已选摘要句的内容重叠率,即冗余程度。通过计算ROUGE-L的值,得到max[DD(X]Sj∈S sim2(Si,Sj)得分。 2 实验数据分析 2.1 实验数据 本文中所使用的柬语多文档实验语料主要来源于柬埔寨新闻日报网、Koh Santepheap以及柬埔寨MYTV等网站,通过人工收集和网页爬取方法获得相关主题新闻文档,再进行分词、词性标注等预处理,所采集到的语料涵盖了政治、体育、娱乐和军事等众多领域。利用实验室分词平台进行分词预处理,得到大约700个新闻标题,5 000篇左右的新闻文档,每个新闻标题下大约包含7篇新闻报道,每篇文档中包含30个左右的句子,每个新闻标题下的所有新闻文本按照新闻时间顺序排列成1份柬语多文档语料。该多文档摘要系统的任务是从包含7篇新闻文档的单文档摘要结果中合并抽取生成1份简洁、流畅、涵盖主题内容的多文档摘要。 2.2 评价指标 自动文本摘要质量的评估是一项比较困难的任务,通常选取1个或多个指标对生成摘要和参考摘要进行内部评价,内部评价比较的是摘要内容的信息覆盖率。在本实验中,对摘要结果的评价通过与专家标注的参考摘要进行对比,实验数据经过专业人员审核,参考摘要通过多个专家标注,准确性高。目前较为广泛使用的摘要评价指标为ROUGE指标,其评测原理采用召回率作为指标。ROUGE-N基于摘要中N元词的共现信息评价摘要,通过比较生成摘要中包含的基本语义单元数目在专家标注参考摘要数目的占比衡量摘要质量,是一种面向N元词召回率的评价方法。ROUGE-L基于抽取出的摘要与参考摘要匹配到的最长公共子序列的占比评价摘要质量,能在一定程度上反映摘要的质量,其值越高,表示抽取出来的摘要质量越高。本文采用一元召回率(R1)、二元召回率(R2)、三元召回率(R3)和最长公共子序列的召回率(RL)作为摘要评价指标。计算公式表示为 ROUGE-N=∑S∈RS∑n-gram∈SCountmatch(n-gram) ∑S∈RS∑n-gram∈SCountmatch(n-gram) , 式中: RS表示参考摘要;Countmatch(n-gram)表示在生成摘要与标准参考摘要中匹配到的共现n-gram数量之和;Count(n-gram)表示标准参考摘要中的n-gram数量。 2.3 实验结果与讨论 2.3.1 最大边缘相关算法中λ因子系数的选择 為了选取最佳λ因子系数,保证多文档摘要句子相关性和差异性的平衡,进行了30组实验对比。研究发现,当选取λ值以小于0.1的级数增加时,摘要结果得分变化并不明显,所以以0.1的倍数增加选择了11 组实验进行对比,实验结果见表2。 由表2可知,当λ值为0或者为1.0时,在R1,R2,R3,RL上的得分很低,主要是因为当λ值为0或者为1时,仅仅考虑了摘要句子之间的相关性或差异性,没有综合考虑。随着λ值的增加,R1,R2,R3,RL的得分也呈现增加的趋势,当λ值为0.5时得分最高,展现出很好的性能,故将其作为MMR算法的平衡因子系数值。由表2还可以看出,当λ值超过0.5时,ROUGE各项评估得分开始下降,原因是阈值设置过大,导致许多重要性得分很高的句子不能满足冗余性约束而无法加入到摘要中。 2.3.2 摘要中包含句子个数参数的选择 为了选取合并摘要中句子个数参数的最优值,使用本文方法分别进行了30组实验。研究发现,当设置的摘要中句子个数参取值以小于2的级数增加或者减少时,R1,R2,R3和RL的得分变化不太明显,所以每次在选取摘要中包含句子个数参数的取值时,选取2的整数倍值增加或者减少进行实验。初步选取摘要中句子的个数为16,在此基础上进行增加或递减实验。选取相同的λ=0.5,在相同的语料集下使用瀑布法结合本文中的MMR算法合并单文档摘要,挑选了有代表性的8组实验结果进行对比,实验结果如表3所示。 由表3可知,随着摘要中包含句子个数的增加,在R1,R2,R3,RL上的得分呈现递增趋势,体现了自动文本摘要包含信息的多样性。可以看出,当摘要中句子的个数值为20时,在R1,R2,R3和RL上的得分最高,效果最好。随着摘要中包含句子个数继续增加,R1,R2,R3和RL的值呈现下降趋势,主要是由于当摘要中句子的个数值过大时,存在较多的冗余内容,无法保证摘要的差异性。所以,本文选取摘要中句子的个数值为20,作为最终的多文档摘要长度。 2.3.3 改进MMR算法的重要性验证 在句子重要性评估上,使用了基于摘要句5种特征的综合句子得分表示句子和文档主旨之间的相关性,效果理想。采用本文中改进的MMR算法与基于单纯余弦相似度计算的MMR算法,在进行单文档摘要合并为多文档摘要时进行了对比,实验结果见表4。 由表4可知,与基于单纯余弦相似度计算方法的MMR算法相比,本文中使用改进的MMR方法合并摘要的效果更好,R1,R2,R3和RL都要比前一种方法要高,证明了本文使用方法的有效性。这主要是由于本文使用的MMR方法可以更好地利用句子的特征信息综合评估句子的重要性,在保证多文本摘要准确性的同时也可以保证多文档摘要的信息丰富多样性,提高了柬语多文本摘要的质量。 2.3.4 基于分层最大边缘相关方法抽取多文档摘要的优越性验证 将本文基于分层最大边缘相关的多文档摘要方法与另外3种对多文档进行摘要的无监督方法,在使用相同训练集时进行R1,R2,R3和RL结果的对比。3种对比方法包括:1)基于文档中词的TF-IDF特征的方法[24],联合句子的长度、位置等表面特征进行摘要句的选择;2)基于图的排序模型TextRank用于文本处理,构建关于词的无向带权图,利用投票机制提取关键词;3)基于MMR的方法。结果见表5。 由表5结果可知,相比于其他3种对比方法,本文提出的基于分层最大边缘相关的多文档抽取式摘要方法,在R1,R2,R3和RL上取得了最高的得分。利用本文中的改进方法抽取出来的多文档摘要与专家人工标注的参考摘要更加吻合,深度挖掘了文本之间的语义关系,并且有效减少了多文档摘要中的内容冗余,抽取出的柬语多文档摘要质量更高,也进一步说明本文所提方法的有效性。 3 结 语 1)提出了一种基于分层最大边缘相关的柬语多文档抽取式摘要方法。首先,将收集来的柬语多文档语料输入到已经训练好的深度学习神经网络模型中,获得单文档摘要集合;然后,依据类似瀑布的方式,将单文档摘要结果通过改进的最大边缘相关算法,迭代合并所有单文档摘要作为最终的多文档摘要结果。 2)与直接对多文档文本进行自动摘要相比,该方法深度挖掘了文本间的语义关系,在保证摘要句多样性的同时,也降低了多文档摘要的内容冗余,提高了柬语多文档摘要的质量。 3)由于柬语多文档摘要语料较为匮乏,因此本文采用的是无监督学习方法,导致抽取出来的多文档摘要不如半监督和有监督的学习方法效果好。下一步工作将尝试探讨使用半监督的学习方法,解决柬语多文档摘要标注语料匮乏的问题,提高多文档摘要的流畅性。 参考文献/References: [1]HIRSCHBERG J, MANNING C D. Advances in natural language processing[J]. Science, 2015, 349(6245): 261-266. [2]秦兵,刘挺,李生.多文档自动文摘综述[J].中文信息学报,2005,19(6):13-22. QIN Bing,LIU Ting,LI Sheng.Summary of multi-document automatic summarization[J].Journal of Chinese Information Processing, 2005,19(6):13-22. [3]ISONUMA M, MORI J, SAKATA I. Unsupervised neural single-document summarization of reviews via learning latent discourse structure and its ranking[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics.[S.l.]: Association for Computational Linguistics, 2019:2142-2152. [4]MOHAMMED D A, KADHIM N J. Extractive multi-document summarization model based on different integrations of double similarity measures[J]. Iraqi Journal of Science, 2020, 61(6):1498-1511. [5]程園,吾守尔·斯拉木,买买提依明·哈斯木.基于综合的句子特征的文本自动摘要[J].计算机科学,2015,42(4):226-229. CHENG Yuan, WUSHOUER Slam, MAIMAITIYIMING Hasim. Automatic text summarization based on comprehensive sentence features[J].Computer Science,2015,42(4):226-229. [6]GUPTA A, KAUR M. Text summarisation using laplacian centrality-based minimum vertex cover[J]. Journal of Information & Knowledge Management, 2019, 18(4):1-20. [7]李强,王玫,刘争红.基于RFID覆盖扫描的标签定位方法[J].计算机工程,2017,34(3):294-298. LI Qiang, WANG Mei, LIU Zhenghong. Label positioning method based on RFID overlay scanning[J].Computer Engineering, 2017, 34(3):294-298. [8]BLISSETT K, JI H. Cross-lingual NIL entity clustering for low-resource languages[C]//Proceedings of the Second Workshop on Computational Models of Reference, Anaphora and Coreference.[S.l.]: Association for Computational Linguistics, 2019:20-25. [9]RADEV D R, JING H. Centroid-based summarization of multiple documents[J]. Information Processing & Management, 2004, 40(6):919-938. [10]MCKEOWN K, RADEV D R. Generating summaries of multiple news articles[C]//Proceedings of the 18th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval.[S.l.]: Association for Computational Linguistics,1995:74-82. [11]PAUL C, RETTINGER A, MOGADALA A, et al. Efficient graph-based document similarity[C]//European Semantic Web Conference: Springer Cham.[S.l.]:[s.n.],2016:334-349. [12]LANGVILLE A N, MEYER C D,FERNNDEZ P. Google's pagerank and beyond: The science of search engine rankings[J]. The Mathematical Intelligencer, 2008, 30(1):68-69. [13]WEN Y, YUAN H, ZHANG P. Research on keyword extraction based on word2vec weighted Textrank[C]//2016 2nd IEEE International Conference on Computer and Communications (ICCC).[S.l.]: IEEE, 2016:2109-2113. [14]YASUNAGA M, ZHANG R, MEELU K, et al. Graph-based neural multi-document summarization[C]//Proceedings of the 21st Conference on Computational Natural Language Learning.[S.l.]: Association for Computational Linguistics, 2017:452-462. [15]江躍华,丁磊,李娇娥,等.融合词汇特征的生成式摘要模型[J].河北科技大学学报,2019,40(2):152-158. JIANG Yuehua, DING Lei, LI Jiao′e, et al. A generative summary model incorporating lexical features[J]. Journal of Hebei University of Science and Technology,2019,40(2):152-158. [16]CAO Z, LI W, LI S, et al. Attsum: Joint learning of focusing and summarization with neural attention[C]// Proceedings of Coling 2016, the 26th International Conference on Computational Linguistics.[S.l.]:Technical Papers, 2016:547-556. [17]NALLAPATI R, ZHAI F, ZHOU B. SummaRuNNer: A recurrent neural network based sequence model for extractive summarization of documents[C]//Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence.[S.l.]: AAAI Press, 2017:3075-3081. [18]NARAYAN S, PAPASARANTOPOULOS N, COHEN S B, et al. Neural Extractive Summarization with Side Information[EB/OL]. [2017-09-10].https://arxiv.org/abs/1704.04530v2. [19]BOUDIN F, TORRES-MORENO J M. A scalable MMR approach to sentence scoring for multi-document update summarization[C]//Companion Volume: Posters and Demonstrations.[S.l.]: [s.n.],2008:23-26. [20]SCHLUTER N. The limits of automatic summarisation according to rouge[C]//Conference of the European Chapter of the Association for Computational Linguistics.[S.l.]:Sociation for Computational Linguistics, 2017:41-45. [21]RAO G, HUANG W, FENG Z, et al. LSTM with sentence representations for document-level sentiment classification[J]. Neurocomputing, 2018, 308(25):49-57. [22]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing System.[S.l.]: Curran Associates Inc, 2017:6000-6010. [23]ZHANG Y, ER M J, ZHAO R, et al. Multiview convolutional neural networks for multidocument extractive summarization[J]. IEEE Transactions on Cybernetics, 2017, 47(10): 3230-3242. [24]CHRISTIAN H, AGUS M P, SUHARTONO D. Single document automatic text summarization using term frequency-inverse document frequency (TF-IDF)[J]. ComTech: Computer, Mathematics and Engineering Applications, 2016, 7(4):285-294.
猜你喜欢
计算机应用(2016年12期)2017-01-13
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
软件工程(2016年8期)2016-10-25
电脑知识与技术(2016年10期)2016-06-16
求知导刊(2016年10期)2016-05-01
电脑知识与技术(2016年5期)2016-04-14
