
Research on the application of improved machine learning collaborative recommendation algorithm in intelligent control
2020-12-23 05:16:12JihuiFANShaohuaTENG
机床与液压 2020年18期
Ji-hui FAN,Shao-hua TENG
(1 Guangzhou Institute of Science and Technology,Guangzhou 510540,China)
(2Guangdong University of Technology,Guangzhou 510006,China)
Abstract:Firstly,this paper proposes a hybrid nearest neighbor collaborative filtering algorithm based on user rating,we talk about several existing collaborative filtering algorithms and the existing problems of the current algorithm,and compares it(not accurate)with the classical algorithm:item-based collaborative filtering algorithm,and compares itwith several popular recommendation algorithms.The nearest neighbor idea is used to solve the problem of degraded accuracy caused by sparse data.User rating attributes are used to conclude recommendation with better accuracy and improved quality.In this paper,we use MoiveLens data set,sorting algorithm in machine learning,and analyze the advantages and disadvantages of different algorithms through vertical and horizontal comparison.Intelligent recommendation is realized bymachine learning,intelligent information processing and intelligent control decision-making can help us to derive better recommendations,and good results are achieved in intelligent control.
Key words:Collaborative filtering,Nearest neighbor collaboration,User rating,Recommendation,Machine learning,Intelligent control
1 Introduction
With the rapid development of themobile Internet,the number of data has increased drastically,and mobile users receive a large amount of data every day.How to make decision from massive information and how to get effective information is a problem,we should pay more attention to this question.At present,there are twomain types of recommendation systems:User-based collaborative filtering and Itembased collaborative filtering.Most of the POI recommendationmethods are based on the user’s sign in data and multi-source heterogeneous information to mine the user’s preference for the non-signed in POIs[1].At present,these two algorithms arewidely used in social networks,e-commerce,audio and video applications.Themain idea of the collaborative filtering algorithm based on items is collaborative filtering based on items(avoid repetition,explain it in detail),through the user’s rating of different items to evaluate the similarity between items,based on the similarity between items to make recommendations to users,recommend items similar to his previous favorite items.The essential partof the recommendation algorithm is the similarity calculationmethod,which determines the efficiency and effect of the recommendation algorithm[2].Simultaneously,many excellenthybrid recommendation algorithms emerge:current popular algorithms based on User-Means-Interest,based on project nearest neighbor collaborative filtering algorithm(UA-IBCF).
By improving the recommendation algorithm and sorting on the basis ofmachine learning,the optimized recommendation algorithm will generate an optimized recommendation list.The improvement of recommendation algorithm achieves a better recall rate.Recommendation(Recall)ismainly responsible for generating recommended candidate sets,and sorting is responsible for personalized sorting of the results from multiple algorithm strategies.Intelligent recommendation and intelligent information processing is realized bymachine learning,intelligent recommendation used in this paper,and good results are achieved in intelligent control.
2 K-nearest neighbor collaborative recomm endation algorithm based on user rating
K-nearest neighbor(KNN)classification algorithm means that ifmost of the k-most-similar samples in the feature space belong to a certain category,then the sample also belongs to this category.In KNN algorithm,its neighbors have been classified correctly.In the decision of classification,only one or several nearest samples are used to determine whether the classification of the samples is classified or not.By finding the k nearest neighbors of one sample,we can not only classify but also regress it.By assigning the average values of the attributes of these neighbors to the sample,the attribute values of the sample can be obtained.According to the actual situation,we can also assign different weights to the influence of different distance neighbors on the sample.
A user-means algorithm is a non-probabilistic collaborative filtering algorithm.We call those userswith similar interests as neighbors(explain it as it appears for the first time in the paper.If user N is similar to user U,we say that N is a neighbor of U.The prediction of unknown targets is based on the scores of similar users.The algorithm in this paper is based on two aspects:neighborhood based collaborative filtering algorithm and matrix decomposition based collaborative filtering algorithm.The main contribution is to solve the problem ofmaximum sparsity caused by big data and the problem of recommendation effect,and tofind the score of the target projectwith the target user,users and projects with high correlation improve the accuracy of the scoring value[3].
In this paper,we use MovieLens data set(100 k).The algorithm is designed and implemented in Anaconda(Python 3.7.2)environment.The final algorithm evaluation result is drawn through the python drawing library:Matplotlib.
The algorithm consists of five steps:
Step 1:Collaborative filtering based on items.
Step 2:Find a collection of users(neighbors)with similar interests.
Step 3:According to the neighborhood set,calculate the user’s forecast score for the items that have not been scored.And list thenitemswith the highest prediction score and recommend them to the user.
Step 4:According to the user scores of the firstnitems and items in the recommendation list,carry out weighted calculation,and optimize the proportion distribution of theweight coefficient through experiments.
Step 5:Get the final recommend-ation list.

Fig.1 Nearest neighbor co IIaborative recommendation fram ework based on user rating
Project similarity can be measured by Pearson correlation coefficient or cosine similarity.Due to the sparse user scoring data,there are few items in the two users’common scoring.In this paper,cosine similarity is selected to measure the similarity of the two users’scoring[4].Different users have different scales of project evaluation,which will affect the accuracy of the prediction.In this paper,Pearson correlation coefficient is used to calculate the similarity between users.As Formula-1
We calculate the predicted value of userufor itemi,using Formula-2
Formula-1:
The movie will be recommended to users when the following two conditions aremet:(1)the recommended movie has a higher score in the targetuser profile;(2)the recommended product has a higher rating in the similar users of the target user.Through the test clustering of training setand selectingknearest neighbors,the prediction value of commodity(not purchased by the target user)score is obtained from the purchase frequency of k-nearest neighbors.At the same time(simultaneously/concurrently/parallelly),according to the new implicit user rating information to select the nearest neighbors from the whole user space,and according to the adjustment weighted sum of these nearest neighbors’ratings to give the prediction value of commodity scores.Concurrently,the whole time is divided into three periods,and the data of each period is analyzed by clustering,and then the sequence pattern is obtained by clustering the three stages of sequential transaction data,thus the sequence pattern of thewhole time period represented by a series of movies is obtained.KNN algorithm integrates a variety of implicit information into themodel on the traditional recommendation algorithm tofurther improve the recommendation accuracy and form a targeted recommendation algorithm.Therefore,this method is better than other methods in that it can makemore personalized recommendation[5].Whenktakes different values,the results of the recommended algorithm are different.We can train the algorithm with a large number of data tofind themost suitableKvalue for the system,so that the algorithm can meet the requirements of the system in terms of accuracy.In general,the accuracy of the new algorithm is improved.
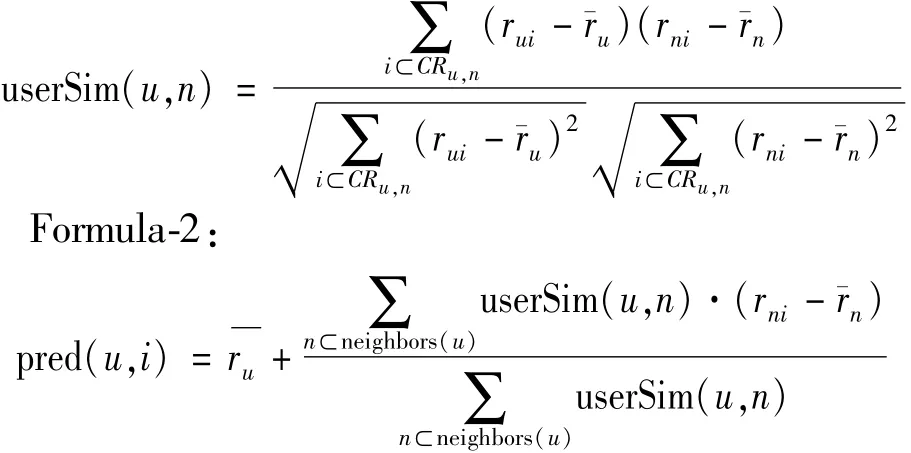
We usemovielens data to set(100 k).The algorithm is designed and implemented in Anaconda(Python 3.7.2)environment.The final algorithm evaluation result is drawn through the python drawing library:matplotlib.In order to prove the effectiveness of the algorithm(user-means),we compare several popular recommendation algorithms at present:item based collaborative recommendation algorithm (Item),based collaborative recommendation algorithm(Item-KNN),and horizontally compare the current popular algorithm based on usermeans interest(User-Means-Interest)[6],collaborative filtering algorithm based on project nearest neighbor(UA-IBCF)[7].Through the data statistics of recommendation effect,time and top-n recommendation,we made comparison charts.The experimental results are compared as follows:
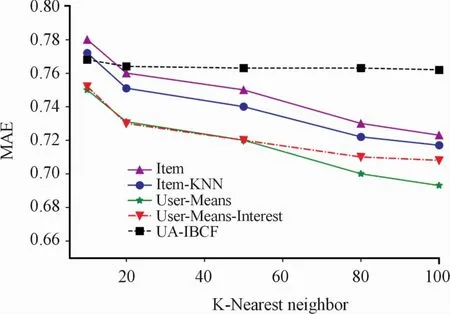
Fig.2 Com parison of the recommended effects of five a Igorithm s
The value ofKis added from 1 to 100,and the recommendation effect of the algorithm is observed.The larger the value ofKis,the better the recommendation effect is.Whenk=100,the lowest Mae value is 0.69,and the best recommendation effect is achieved(x=0.8,y=0.2).Parallelly,we compare the timeconsuming of the three algorithms vertically,and the more test data,the more time-consuming.The time consumption of the three algorithms is basically within 0.05 s.There is no big difference.

Fig.3 Com parison of time consum p tion of three a Igorithm s
In training,the computational complexity is directly proportional to the data in the training set,so the time complexity isO(n*m),nis the size of the training data set,and m is the dimension.KNN algorithm needs to calculate the distance between the target user and other users every time,so it increases the time complexity of training.However,the nearest neighbor collaborative recommendation algorithm based on user rating increases the dimension of user rating,with the complexity ofO(n*(m+1)),and the order ofmagnitude is still onO(n*m).
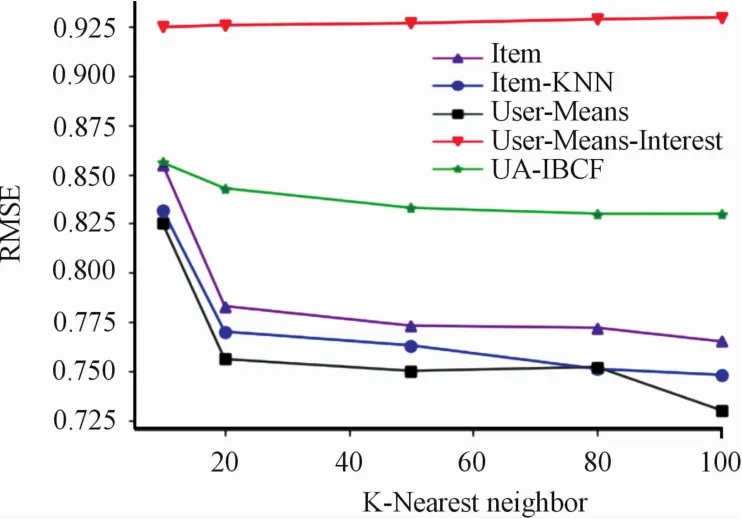
Fig.4 RMS error effect of five a Igorithm s
At the same time,we simulate and demonstrate the effect of recommendation,test and count the data of 1 000 teachers and students from different regions,specialties and grades,and compare the top n recommendation effect of five algorithms.When providing recommendation service,the prediction accuracy of top n recommendation is generally measured by precision/recall.The accuracy rate is the proportion of the target results in the assessment of the captured results;the recall rate is the proportion of the target categories in the areas of concern;
R(U):listof recommendationsmade to users based on their behaviors in the training setT(U):user behavior on the test set.
Recall rate is defined as:

Accuracy is defined as:

In PR(precision recall)curve,recall is thex-axis and precision is they-axis.Draw precision recall curves to help with analysis.As shown below:
We hope that the higher the precision is,the better the recall is,but in fact,there is a contradiction between the two.Therefore,you need to judge whether you want a higher precision or recall in different situations.Among the five algorithms discussed in this paper,we can see from Fig.4 that under the same recall rate,User-Means Algorithms show higher accuracy.If theP-Rcurve of one learner is completely wrapped by theP-Rcurve of another,it can be concluded that the performance of the latter is better than that of the former,we can see from Fig.5 that user-means algorithms show better.
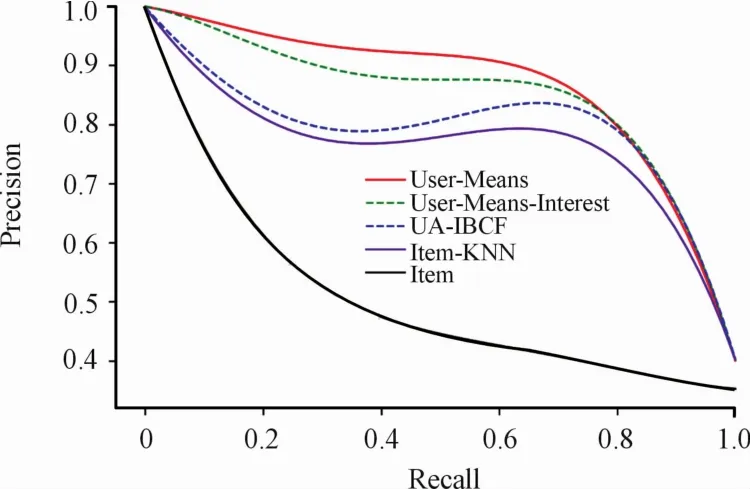
Fig.5 PR curve of five aIgorithm s
3 App lication and p romotion of recomm endation algorithm in m achine learning
In recent years,machine learning has made outstanding achievements in the field of recommendation,and has become one of the hot spots in the research of scholars.In the field of recommendation,machine learning technology has been integrated,and has achieved remarkable results.The purpose of improving themovie recommendation algorithm is to provide the latest,hottest and best quality movie watching service,so as to better guarantee the efficiency and quality of user experience.
However,the recommendation system currently faces twomajor problems:the need to deal with massive users and massive content;content needs to be updated in real time.We try to use this recommendation system,includingmulti-channel recall and sorting strategy based onmachine learning,and recommendation engine from off-line calculation ofmassive big da-ta to high concurrent online service。
This algorithm uses collaborative filtering recommendation,and uses the relationship matrix of users and items to model users and items for recommendation.First of all,we use high-quality users to train and ensure the clustering uniformity,all users to predict,select clustering algorithm,user vector representation,and control clustering uniformity.In this paper,under the framework ofK-means algorithm,the row vector of relation matrix is used as the vector representation of users.
The user group’s behavior to each movie under each cluster is recorded,and then weighted,sorted and top selected.When users need to recommend,they can find the corresponding recommendation list by clustering ID.We can achieve intelligent control through intelligent information processing,intelligent information feedback and intelligent control decisionmaking.
4 Conclusion
Whenktakes different values,the results of the recommended algorithm are different.We can train the algorithm with a large number of data tofind the most suitable K value for the system,so that the algorithm canmeet the requirements of the system in terms of accuracy.In general,the new algorithm improves the accuracy and reduces the cold start problem to a certain extent.In order to providemore accurate recommendations for new registered users or userswithout scoring records,we proposes a cross domain recommendation algorithm optimized for cold start users,which integrates expertise and user similarity,to generate a more accurate recommendation list for cold startusers[8].We applymachine learning technology in recommendation system,and improve the algorithm with the characteristics of recommendation scene.In the aspect of recommendation algorithm,the nearest neighbor collaborative filtering hybrid recommendation scheme based on user rating is used to balance the algorithm effect and offline computing scale.Solve the problem of sparse data caused by sparse behavior and repeated content.In the aspect of sorting algorithm,large-scale feature combination obtains rules and features in feature engineering practice,andmulti-objective machine learning tries to solve the problem of multi task recommendation.At present,it is a recent development trend to do personalized recommendation through fusing multi-view of interest preferences to build the hybrid recommendationmodel,which usually make personalized recommendation with user-item interaction ratings,implicit feedback and auxiliary information in hybrid recommendation system.In some paper,a novel hybrid recommendation algorithm is proposed that based on deep sentimentanalysis of user reviews and multi-view collaborative fusion[9].
At the same time,the algorithm also needs to be improved.In terms of time performance,we hope to improve it through algorithm optimization and hardware equipment improvement.More and more fields introduce recommendation algorithm[10],How tofurther improve the accuracy of recommendation,improve the quality of recommendation,and realizemore independentand humanized recommendation in the field of intelligent control.We can achieve better optimization and recommendation to a certain extent by collecting the user’s operation and preference.The recommender system which optimizes a single goal cannotmeet such a complex requirement.How tofind out the potential needs of users and how to optimize these objectives as a whole is an important step for recommendation system tomove towards intelligent system.

- 机床与液压的其它文章
- Study on Face detection method based on lightweight convolutional neural network
- Application of genetic optim ization lvq neural network in equipment fault diagnosis system
- Research on sliding mode control of manipulator based on RBF neural network optim ized by bionic swarm intelligence
- Research on bearing fault diagnosis technology based on deep convolution neural network
- Design of liquid filling machine positioning system based on RBFneural network activedisturbance rejection controller
- Kinematics and dynam ic performance analysis of a 3-R2H2S parallel robot