
基于数理统计的北斗数据无损压缩方法研究
2020-12-23 11:37:28非鹏武汉理工大学
珠江水运 2020年22期
非鹏 武汉理工大学
钱廷发 上海普适导航有限公司
殷悦 交通运输部水运科学研究所
目前北斗卫星短报文通信系统中,普通北斗通讯终端,每分钟可以发一次通信,每次通讯容量为628 Bit(等于78.5 Byte);对于传输的中文正文,一般采用GB2312编码形式,GB2312采用2个By te编码一个汉字。因此每次北斗报文仅能传输39个汉字,相对传输信息量较小。对于稍大的通讯数据量都需要拆包分段发送,使得传输时间加长,用户体验度差。
《现代汉语词典》是目前较权威的大型现代汉语词典,最新版的收词56000多条。其中包括了字、词、短语、熟语、成语等。在日常的语言交流中,常用的词组、短语、短句在1000个左右。
本文通过对上海普适导航北斗运营系统中,包含的海量的北斗通讯内容,进行统计分析,发现大量的频繁词组、短语、短句。如能对其进行一定的编码,通过一定的格式和现有的编码进行兼容区分,做到唯一性解析,就能极大提升数据传输的效率,实现了北斗通讯的无损压缩传输。
1.编码兼容
GB2312中文编码采用2字节编码,从A1A0开始,到FEFF结束。为兼容ACSII编码,可以看到GB2312编码的第一字节的第一位都是1,ASCII编码的1字节表示,其第一位为0,如表1、表2。
由于GB2312中文编码第一字节从A1到FE,因此在兼容A SCII的情况下,GB2312首字节共有33个编码未使用(下文又称额外编码),对应的十进制范围为128~159(0X80~0X98)及255(0XFF)。如表3所示。

表1 ASCII 编码方式
2.自定义双字节编码
由于额外编码仅用1个字节表示,为了使编码效率最高,因此把最常用的可见ASCII码及部分常见的中文全角符放到额外编码表中。通过数据分析,33个常用的自定义额外编码,形成编码字典。编码形式如表4。

表2 GB2312中文编码

表3 GB2312未使用的首字节
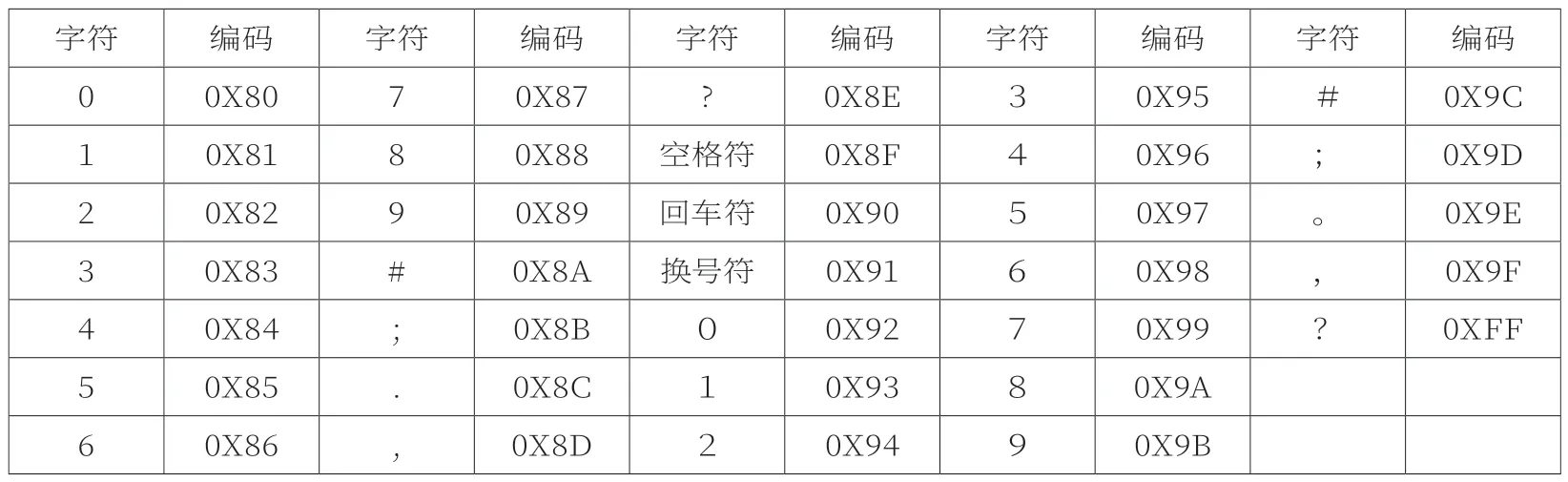
表4 自定义额外编码表

图1 对中文短信进行双字解码流程
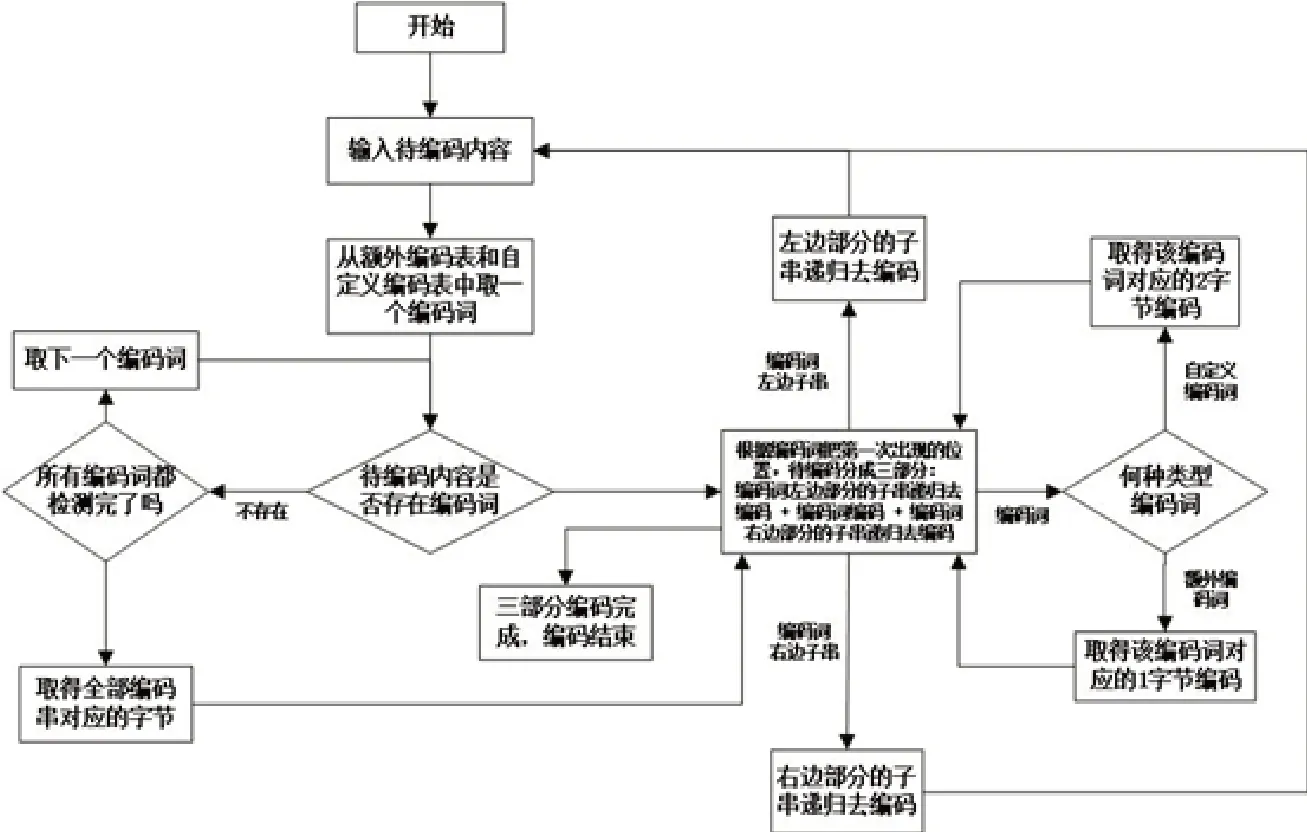
图2 对中文短信进行双字节编码流程

表6 哈夫曼字节编码
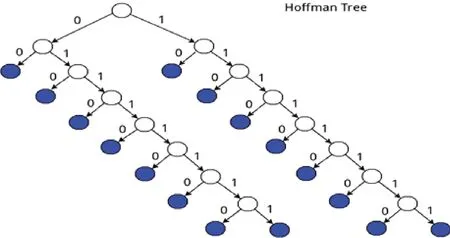
图3 哈夫曼编码树
采用2字节表示自定义编码,为解析兼容,其中第一字节第一位固定为0,有15位编码可以定义,因此可表示32768个编码组合,编码格式如表5所示。
可见的ASCII码共79个,表5中已经实现了28个编码,因此对剩下的51个编码进行编码,32768个编码组合还剩下32717个编码。根据统计数据取前32717个使用频率最高的词语、短语进行编码。形成编码字典。整个北斗通讯编码中,采用三种编码方式组合的形式:
33个额外编码+双字节自定义编码+GB2312编码
对于没有在编码字典中出现的中文字符使用GB2312编码,三类编码没有先后顺序,任意搭配,都能唯一解析。三种编码识别方法如下:
首先判断第1字节的第1 位是否为0,为0 说明是自定义编码,取走2字节到自定义编码字典中匹配还原;为1时候,再看该字节是否为128~159及255这33个数字,如是说明是额外编码,取走1字节到额外编码字典中匹配还原,如不是,说明是GB2312编码,取走2字节,并不需要到编码字典中还原,如图1所示。编码流程逆向处理,流程类似,如图2所示。
3.分组哈夫曼变长编码
哈夫曼树又称最优二叉树,是一种带权路径长度最短的二叉树。通过构建哈夫曼树进行编码的特殊之处在于,它是根据每一个源字符出现的估算概率而建立起来的,出现概率高的字符使用较短的编码,反之出现概率低的则使用较长的编码。这便使编码之后的字符串的平均期望长度降低。
自定义哈夫曼编码采用动态长度编码实现,自定义编码长度由10~16Bit组成,第1Bit为0,用于区分GB2312编码,第2~8Bit用来表示0000000~1111111共128个分组。哈夫曼编码动态由2~8Bits组成(其中第一bit表示左右子树),组成情况见表6。
对每分组中的哈夫曼树,如图3所示。
每棵哈夫曼树可以形成如下编码,哈夫曼编码的特殊性,可以确保编码、解码的唯一性,根据定义的规则产生如编码表6。
每棵哈夫曼树上可以形成16个编码,对应到128个分组上,就可以有2048个编码。哈夫曼编码由2~8Bits组成,优先编码51个ASCII可见字符(另外28个已经在拓展编码表中实现)和出现次数多的词语、词组、短语,使它们的编码长度尽可能小,出现次数少的,编码长度大。
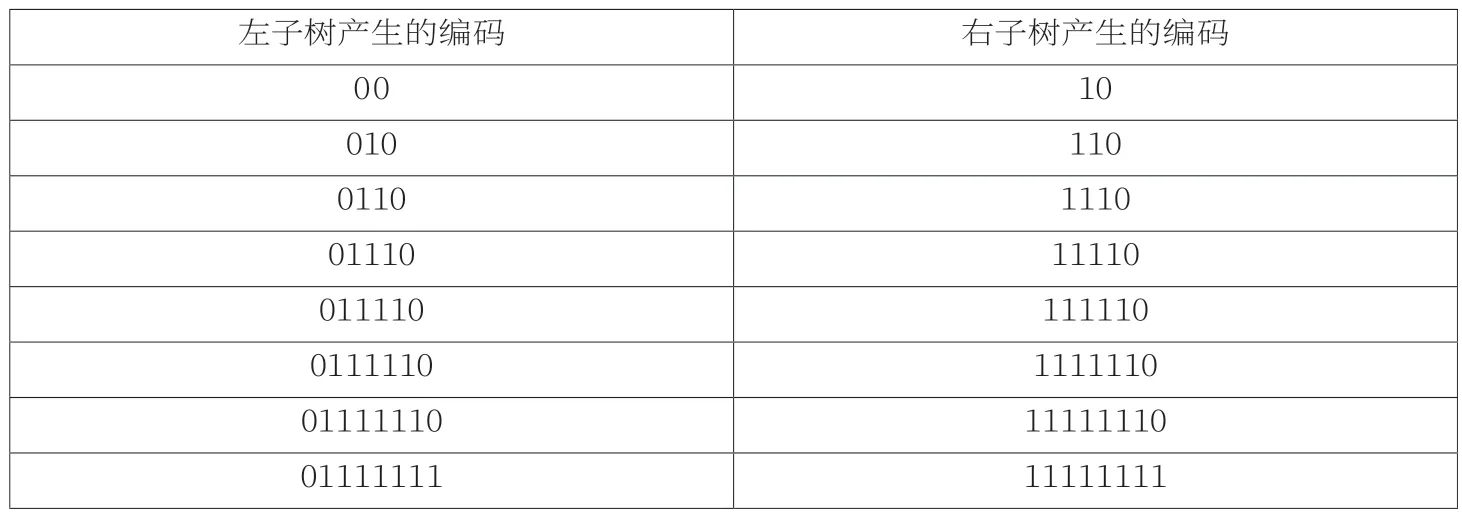
表6 哈夫曼编码表
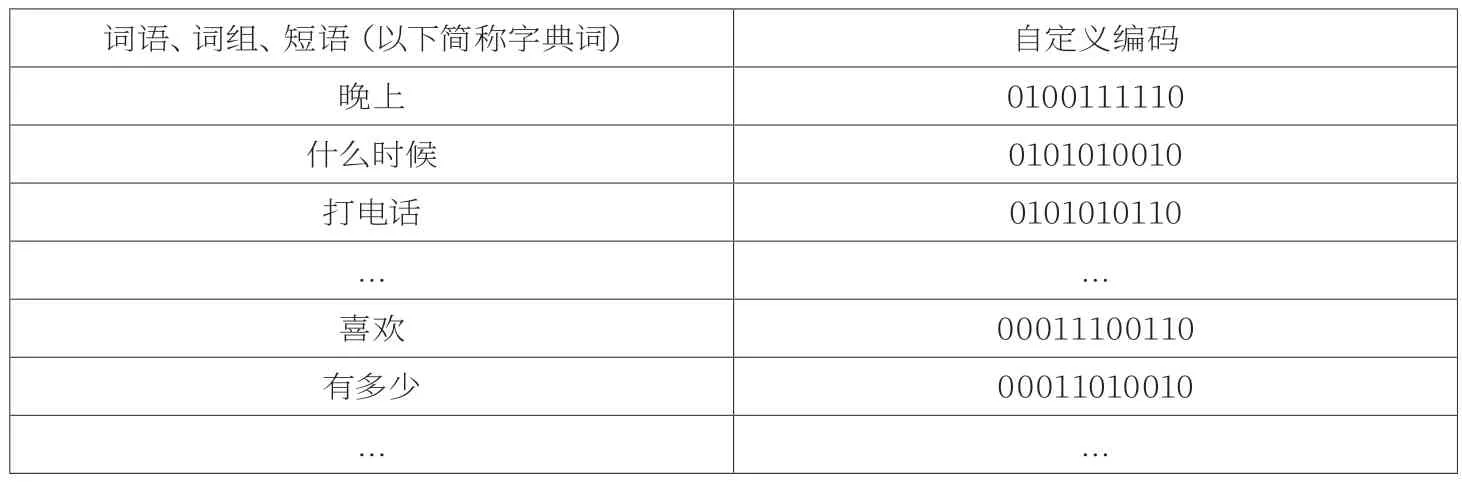
表7 哈夫曼编码字典
编码设定完成后,形成自定义哈夫曼编码字典,如表7所示。
哈夫曼编码解码过程,通过判断剩余下的解码缓存中的第1 bit,如是1Bit,再判断第一字节是否是128~159及255,如是说明是额外编码,取走1字节,把对应的额外编码词,放入解码串中,如不是128~159及255,说明接下来的16 Bits 是GB2312编码,表示一个汉字,解码缓存中移走16Bits,解码串中添加该16Bits;如是0 bit,说明接下来的是拓展编码,需要尝试匹配10到16Bit,有无该拓展编码,如是N Bit匹配到,从解码缓存中移走相应的N Bits,并把相应的词典词加到解码结果字符串中;重复上面的解码过程直到解码缓存小于8Bits。
编码流程逆向处理,流程类似,如图5所示。
4.实现效果
首先定义压缩倍数,在这里定义为分压缩传输所需的字节数除以压缩传输的字节数。随机抽取10个短信,分别进行双字节自定义编码和分组哈夫曼编码,进行效果验证分析,传输效率如图6所示。
针对10 个样本,不同的传输内容,压缩效率会不同。分组哈夫曼编码的平均压缩效率为 1.96,自定义双字节编码平均压缩效率为1.84。通过以上的研究分析,可以看出本文的研究具有较好的压缩效率和可行性。
5.结论
针对目前北斗卫星短报文通信系统中,普通北斗通讯终端每次北斗报文仅能传输39个汉字,相对传输信息量较小。对于稍大的通讯数据量都需要拆包分段发送,使得传输时间加长,用户体验度差的问题,本文通过对海量北斗通讯内容,进行统计分析,发现大量的频繁词组、短语、短句,对其进行一定的编码,通过一定的格式和现有的编码进行兼容区分,做到唯一性解析,极大提升了数据传输的效率,实现了北斗通讯的无损压缩传输。
猜你喜欢
家教世界(2023年28期)2023-11-14 10:13:50
家教世界(2023年25期)2023-10-09 02:11:56
中国石油石化(2022年12期)2022-07-16 08:28:28
销售与市场(营销版)(2021年10期)2021-11-21 20:15:03
中国外汇(2019年19期)2019-11-26 00:57:32
销售与市场(营销版)(2019年6期)2019-06-21 01:16:38
家庭影院技术(2018年11期)2019-01-21 02:20:50
家庭影院技术(2018年11期)2019-01-21 02:20:48
网络安全技术与应用(2017年9期)2017-09-20 09:54:28
创新作文(小学版)(2016年19期)2016-08-22 05:54:08
