
基于CNN-BGRU的音素识别研究
2020-12-18 07:31:22和丽华潘文林杨皓然
云南民族大学学报(自然科学版) 2020年5期
和丽华,江 涛,潘文林,杨皓然
(云南民族大学 数学与计算机科学学院,云南 昆明 650500)
现有的语音识别成果中,绝大部分学者的关注点还是集中于词和句子级别,对于音素的研究还较为少见.文献[1]在做区分汉语方言的研究时,语音变化的中的声韵母和变调能帮助人们进行汉语方言的区分,对于声韵母的标注,也就是音素级别的标注.文献[2]做普通话韵律单元分析时,对音节、词、短语的声学特征分析采用了音延、静音段、音高上下限差值等声学表现来做边界区分.对于语音学领域来说,语音学者们更加关注语音识别的微观正确率,音素作为组成1个读音的最小的语音单位,具有区分语言含义及读音的功能,不仅能解决人们学习新语言时的单词拼读问题,还能帮助语音学者探索不同语言的发声机理.
20世纪90年代语音识别中最主流的方法是采用隐马尔科夫模型[3],但是使用HMM训练时需要进行特征降维,这样的做法导致许多有用信息的丢失.为了克服以上缺陷,采用了神经网络代替HMM进行语音识别.基于神经网络的语音识别打破了传统语音识别对于手工设计特征的依赖,可以通过神经网络自动提取浅层和深层的特征,节省了手工设计特征所带来的大量前期工作.CNN、LSTM和DNN在建模能力上是互补的[4],CNN擅长减少频域的变化,LSTM提供长时记忆,DNN适用于将特征映射分类,利用3个网络不同的特性将它们组合在一起能有效提高语音识别的效率.文献[5]采用RNN进行音素识别,选取了具有双向循环结构的BLSTM网络与CTC相结合,并在语音分帧阶段去除相邻帧的重合部分,减少神经网络输入序列的数据,大幅度地提升训练效率,在TIMIT英语音素语料库上,BLSTM-CTC模型的效果优于BLSTM-HMM模型.文献[6]通过对LSTM进行端到端的训练,利用RNN拥有更大空间状态和LSTM的长时记忆单元能较好地处理数据之间的长期依赖关系的特点,避免了使用HMM出现不正确标签作为训练目标的问题,在TIMIT英语音素语料库上,音素识别的错误率达到了最低17.7%.文献[7]比多层感知器MLP、RNN、LSTM在音素识别任务上的训练效率和准确率,LSTM为性能最优的网络,后将LSTM和BiRNN两种网络结构进行融合,提出了新的网络结构BLSTM,并在TIMIT英语语音语料库上进行音素分类任务,证明双向LSTM的性能优于单向LSTM,上下文信息对于语音识别至关重要.文献[8]采用简化版的LSTM网络GRU,通过实验比较LSTM、GRU、tanh这3个单元在序列数据上建模的能力,结论证明GRU在网络结构简化且参数较少的情况下,性能与LSTM相当,但网络训练收敛速度更快,在不同数据集上的泛化性能也更佳.
综上所述,本文选取卷积神经网络CNN、循环神经网络RNN和深层神经网络DNN组合进行音素识别研究,其中RNN选取网络结构较为简单且能获取上下文含义的BGRU网络.基于上述研究提出了1种新的音素识别模型——CNN-BGRU模型.首先卷积神经网络模型VGGNet在图像识别任务中效果出色且参数量较低,在保持图像识别效果的同时对VGGNet网络结构的改进以降低网络参数的数量,有效提升VGGNet模型的性能;其次经过VGGNet模型输出的特征向量作为循环神经网络(RNN)的输入,采用双向循环单元(BGRU)对输入特征进行序列建模,并联合前后文信息进行预测;最后通过softmax分类器输出分类预测的结果.实验仿真证明:本文提出的CNN-BGRU模型与CNN(VGG)、CNN-RNN、CNN-BRNN、CNN-BLSTM这4个模型在TIMIT英语语音数据集上进行音素语谱图分类任务,基于CNN-BGRU的混合模型在识别效果的准确率明显高于其它4个模型,基于CNN-BGRU的混合模型的正确率可以达98.6%.
1 相关工作
1.1 VGGNet模型
2014年GoogleNet和VGGNet分别获得了ILSVRC图像分类大赛的冠亚军,两个模型都注重从加深网络深度的角度去提升卷积神经网络的性能.GoogleNet对传统卷积层的结构进行了改进,而VGGNet则采用了较小的卷积核,卷积核小能一定程度上减少参数量且方便模型快速收敛,并且在模型层数上VGGNet也少于GoogleNet[9].所以本文选用VGGNet模型作为音素语谱图的特征提取算法.
VGGNet模型的结构特点如下:
1) 网络结构为13层卷积层、5层最大池化层、3层全连接层、1个SoftMax分类器.
2) 利用小的卷积核堆叠得到与大卷积核相当的感受野范围,两个3×3的卷积层堆叠获得的感受野的范围与一个5×5的卷积层相当,3个3×3的卷积层堆叠获得的感受野的范围与1个7×7的卷积层相当[10],不同卷积核大小的影响如图1所示:
3) 卷积核大小均为3×3,stride=1,pad=1.
4) 池化层均采用最大池化,池化窗口为2,stride=2.
5) 每一层隐藏层后都有激活函数ReLU和BatchNormalization.
6) 在每层全连接层后都有加Droupout,防止网络过拟合.
VGGNet模型的参数如表1所示:
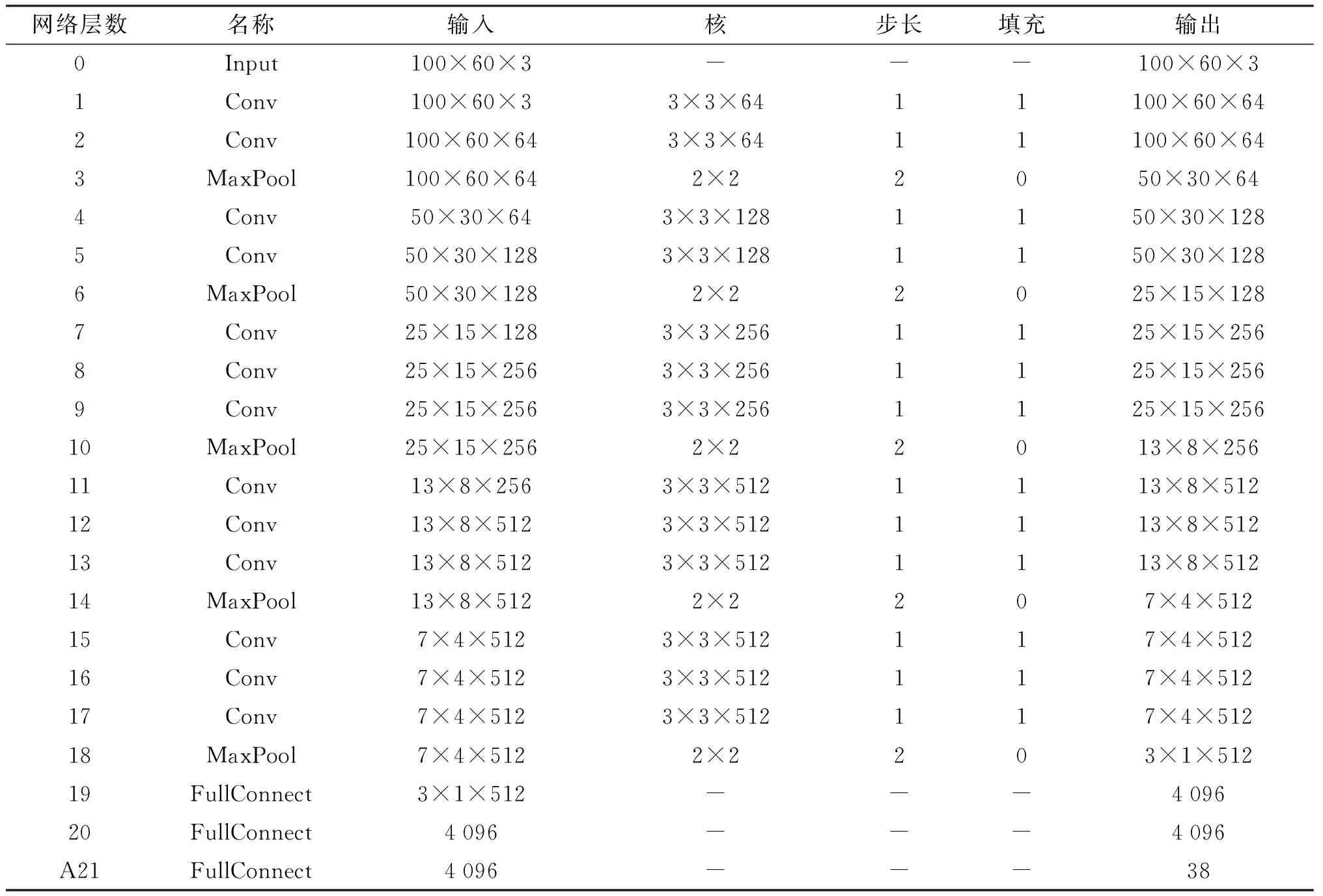
表1 VGGNet网络参数表
1.2 LSTM和GRU
长短期记忆网络(LSTM)和门控循环单元网络(GRU)都属于循环神经网络,它们都是为了改善由于循环神经网络迭代造成梯度弥散或是梯度爆炸的问题而提出的[11].LSTM引入了长时记忆单元Cell,并且由门控机制控制Cell的信息保留与否.LSTM模型有3个门控单元,分别是遗忘门、输入门、输出门,即图2左边图LSTM中的的f、i、o,其中遗忘门控制上一时刻长时记忆单元的信息是否被遗忘;输入门控制输入信息是否输入长时记忆单元的信息;输出门控制长时记忆单元的信息是否输出.
GRU网络是在LSTM网络的基础上进行了改进,由于LSTM网络中的输入门和遗忘门是1个互补的关系,在GRU网络中将这2个门合并为1个门:更新门[12].此外,GRU网络将长时记忆单元Cell与当前状态进行了合并,直接建立当前状态和历史状态之间的线性依赖关系.通过改进后的GRU网络在保留与LSTM网络同样效率的前提下,较大程度的简化了网络结构,减少了网络参数,具有更好的收敛性.LSTM网络和GRU网络的结构对比图如图2所示:
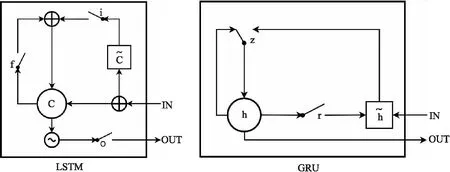
图2 LSTM和GRU结构对比图
与LSTM网络不同,GRU网络只有2个门控单元,分别为重置门和更新门,即图3中的rt、zt.重置门rt控制历史状态信息ht-1有多少需要被遗忘,即rt=1时历史状态信息ht-1全部被遗忘,rt=0时历史状态信息ht-1全部被传递到当前状态ht;更新门zt控制历史状态信息ht-1有多少信息传递到当前状态ht,即当zt=1时,计算过程如下所示:
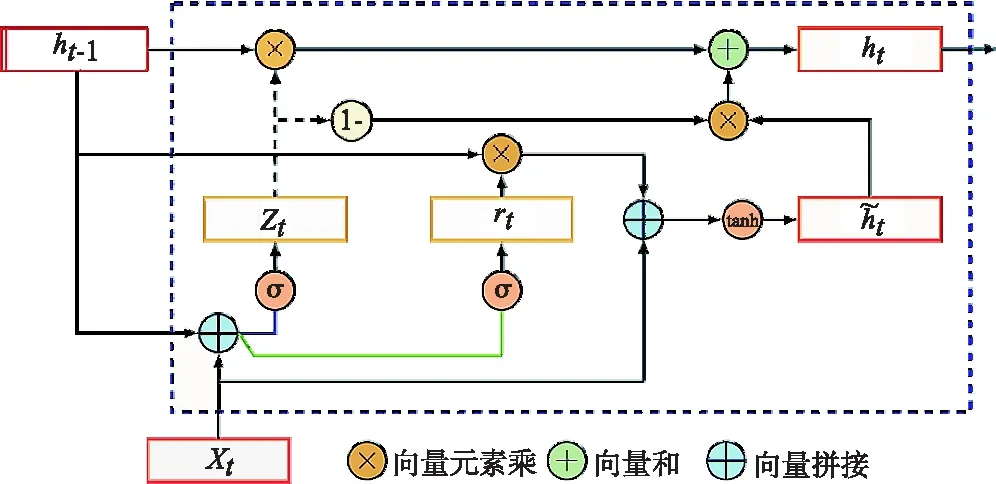
图3 GRU结构图
.
(1)
ht=zt⊙ht-1+(1-zt)⊙ht
.
(2)
(3)
(4)
其中⊙表示向量对应元素相乘.相较于LSTM网络,GRU网络能在保证网络性能的前提下达到同样的实验效果,并且能大幅度提高网络的训练效率,因此本文选用GRU网络作为音素语谱图的识别算法.
2 CNN-BGRU音素识别模型
2.1 改进的VGGNet模型
VGGNet模型对于图像得特征提取效果出色,但是由于网络的层数较多,导致训练时计算量较大,网络收敛速度较慢,因此为了提高网络的训练效率,需要减少网络参数.本章对于VGGNet模型改进主要包括两个方面:
1) 由于全连接层的参数量较大,所以通过减少全连接层来降低整个网络的参数总量,以此来提升VGGNet模型的性能,本文将VGGNet模型的3个全连接层减少为1个全连接层.
2) 由于全局均值池化层能通过加强特征图与标签之间的对应关系提升网络的特征提取能力,所以本章使用全局均值池化层代替最后1个最大池化层,求得每个特征图的平均值,然后将输出的结果向量直接输入softmax层,这样可以在保证网络性能的情况下,有效地减少网络的参数数量.
改进前后的网络结构对比如表2所示:
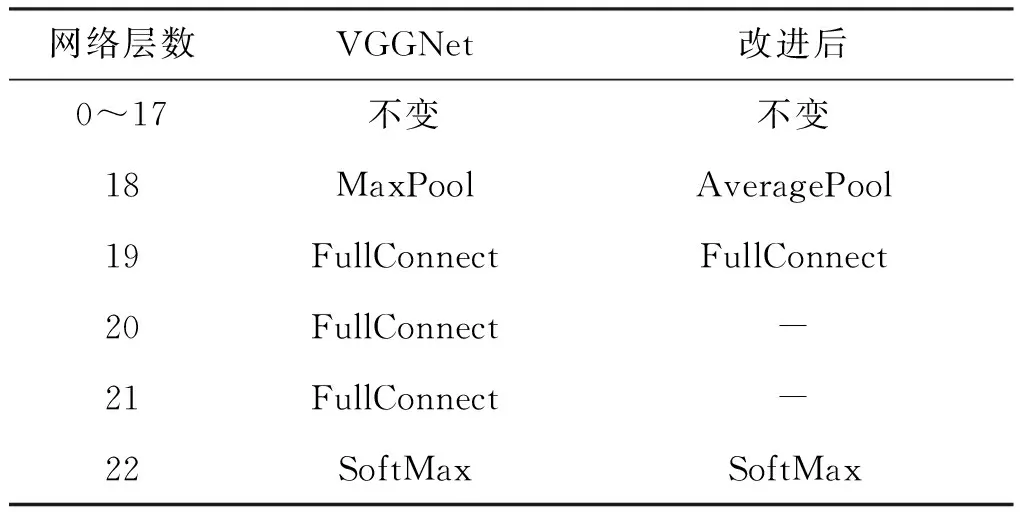
表2 VGGNet改进前后网络结构对比
2.2 双向GRU单元(BGRU)
传统循环神经网络只关注于上一时刻的信息,但是对于音素识别来说,下一时刻的信息也与预测值息息相关,双向循环神经网络的改进,正好弥补了这个问题[13].由于门控循环单元网络只能获取单向的数据序列信息,因此本文选取双向的门控循环单元网络(BGRU)实现音素语谱图的序列信息表示,BGRU模型就是在传统的GRU模型隐层上增加了正向传递的GRU和反向传递的GRU,即图4中的G′和G,以便于从这2个方向提取上下文的信息,所以BGRU模型比GRU模型效果更好,计算过程如下所示:
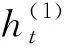
BGRU模型结构如图4所示,其中G表示GRU模块.

图4 BGRU模型结构图
2.3 CNN-BGRU音素识别模型
卷积神经网络CNN对于图像识别任务效果出色,VGGNet在提取图像特征上具有优势,循环神经网络RNN擅长时序数据的处理,BGRU对于序列信息识别效果出色.本文提出的CNN-BGRU模型利用VGGNet提取音素语谱图的图像特征;然后将图像特征输入BGRU模型,通过正向传递隐层和反向传递隐层实现音素语谱图的序列信息表示;最后输入给SoftMax分类器输出分类结果,VGG-BGRU模型结构图如图5所示:
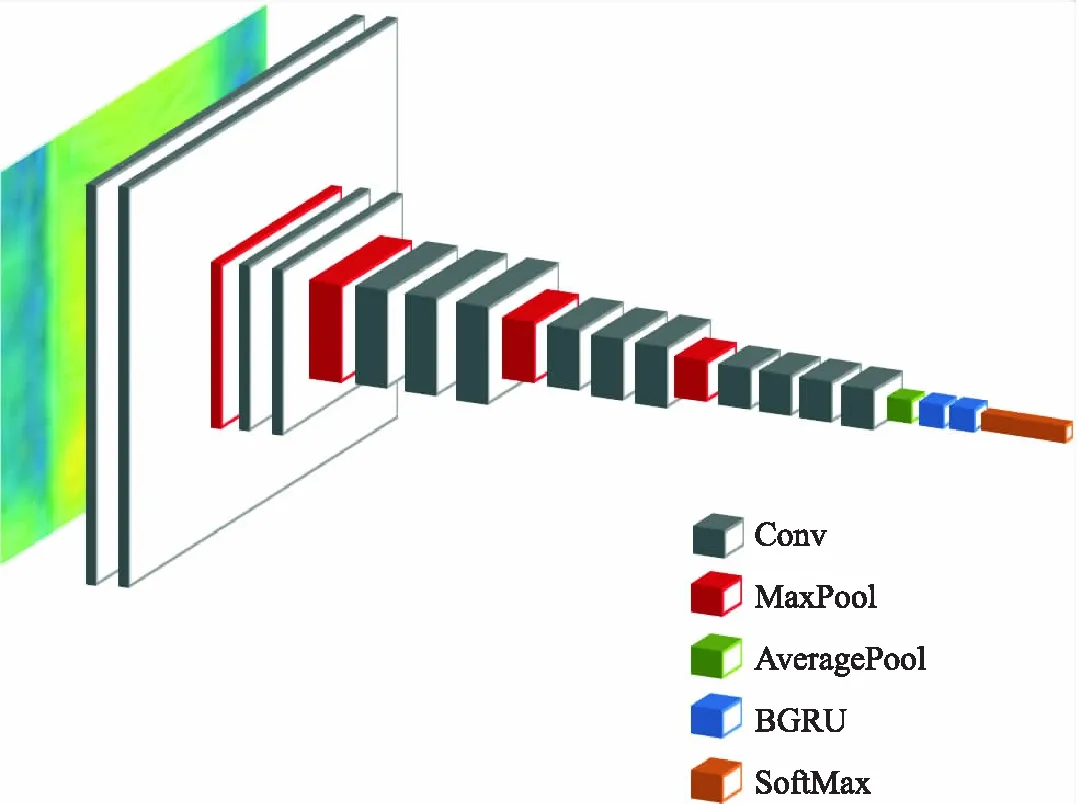
图5 改进CNN-BGRU模型结构
改进的CNN-BGRU模型:
1) 将英语音素语音转换为语谱图后输入到改进CNN-BGRU模型中进行训练;
2) 添加多层卷积层,通过卷积运算得到语谱图的局部特征矩阵;
5.使用药剂拌种来防止玉米粗缩病的发生。用吡虫啉拌种,对灰飞虱有短期的防治效果,这样有效的控制了灰飞虱在玉米苗期的发生数量,来达到控制玉米粗缩病毒的传播。
3) 最后1层池化层为均值池化层,球的每个特征图的平均值;
4) 添加双向GRU单元层(BGRU),增强语音的序列信息表示;
5) 添加全连接层,将每一层神经网络提取出来的特征综合起来进行分类,然后对每个分类结果都输出1个概率.
3 实验
3.1 实验环境
实验所选取的操作系统为Windows10,编程语言为Python,使用keras来构建深度神经网络,并使用CUDA技术对网络进行加速.
3.2 实验参数
输入数据为二维的音素语谱图,网络参数如表3所示.在网络训练方面,批次大小设置为30,训练次数为100次.
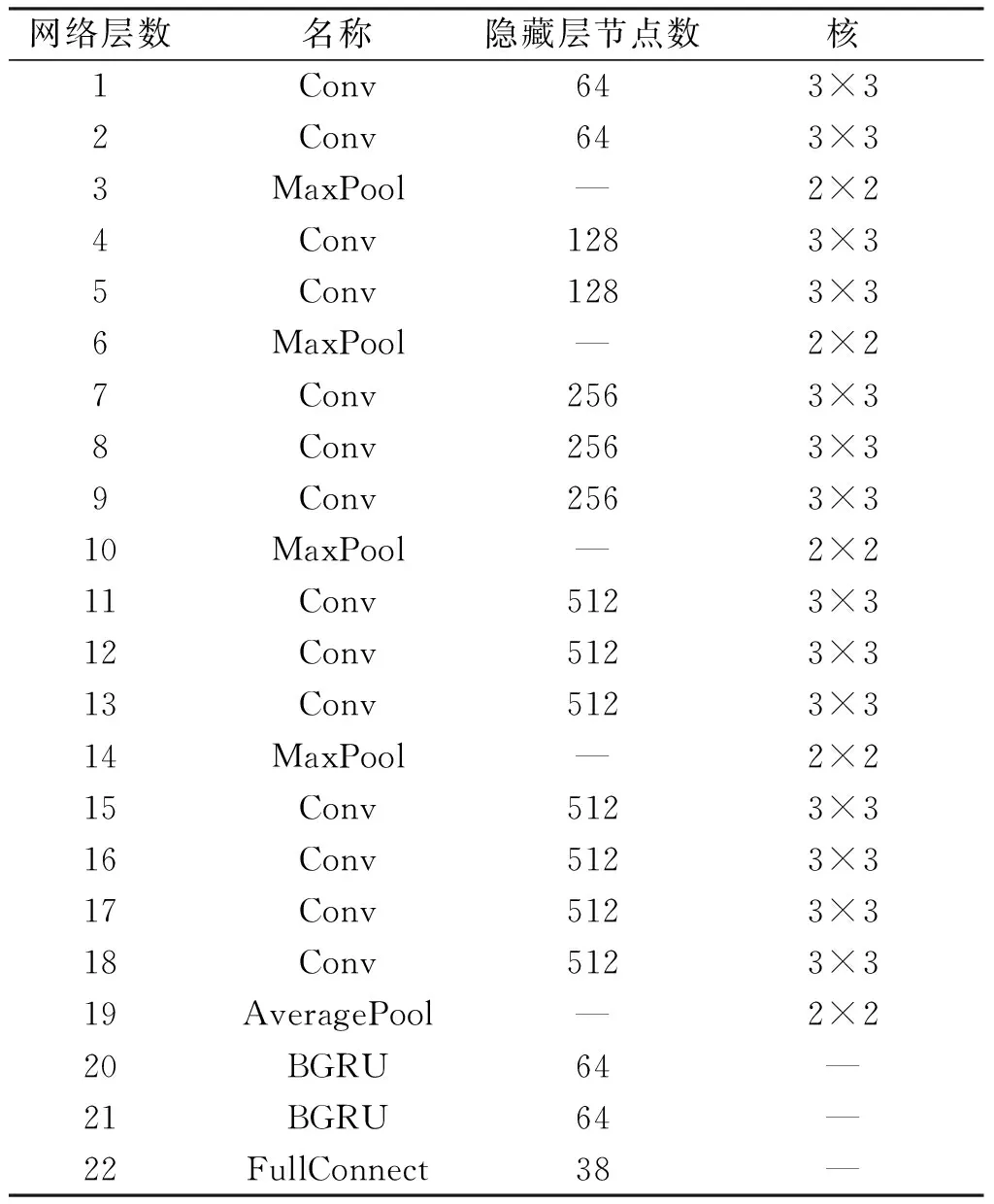
表3 CNN-BGRU模型参数配置表
3.3 实验数据
因为实验所选取的语音基元为音素,所以选用音素种类齐全且多样的TIMIT语料库作为实验数据集.它由630名演讲者,每人说10个句子组成,总共6 300个句子,其中包括2个“sa”的方言句子、5个音素紧凑的“sx”句子、3个音素多样的“si”句子.基于某些音素发音相近,甚至不发音,可以将这些音素统一化归为1个音素,将61个音素简化为38个音素,对应简化规则如表4所示[14].

表4 音素简化规则表
3.4 对比实验
本节实验的目的在于验证提出的CNN-BGRU音素识别模型的有效性.首先是对于模型参数的选择,选择不同的BGRU层隐藏层节点数、学习率、优化器以识别率最为评价指标进行实验,选出最优的组合参数.然后对CNN(VGG)、CNN-RNN、CNN-BRNN、CN-BLSTM、CNN-BGRU5个模型分别进行音素识别,验证提出的CNN-BGRU模型对于提高音素识别准确率的有效性.
表5为基于CNN-BGRU音素识别模型在学习率为0.000 1,BGRU层不同隐藏层节点数下的识别率.通过表格可以看出,BGRU层隐藏层节点数为64时CNN-BGRU模型在TIMIT数据集下的音素识别任务表现最佳,所以最终选定音素识别模型的BGRU层隐藏层节点数为64.

表5 BGRU隐藏层节点数对于音素识别的识别率
通过图6可以看出基于CNN-BGRU音素识别模型在BGRU层隐藏层节点数为64时,训练到最后的准确率较高.
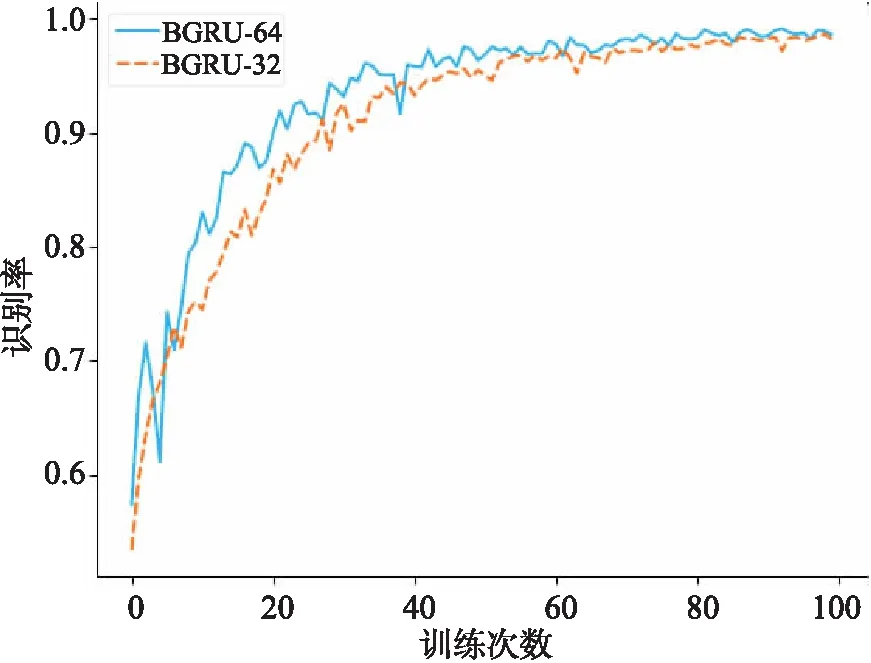
图6 BGRU隐藏层节点数的实验结果统计图
3.4.2 基于CNN-BGRU音素识别模型的学习率选择
表6为基于CNN-BGRU音素识别模型在隐藏层节点数为64,不同学习率下的识别率.通过表格可以看出,学习率为0.000 1时CNN-BGRU模型在TIMIT数据集下的音素识别任务表现最佳,所以最终选定音素识别模型的学习率为0.000 1.

表6 不同学习率对于音素识别的识别率
通过图7可以看出基于CNN-BGRU音素识别模型在学习率为0.000 1时,训练到最后的准确率较高.
3.4.3 基于CNN-BGRU音素识别模型的优化器选择
表7为基于CNN-BGRU音素识别模型在隐藏层节点数为64、学习率为0.000 1,不同优化器下的识别率.通过表格可以看出,选用Adam优化器时CNN-BGRU模型在TIMIT数据集下的音素识别任务表现最佳,所以最终选定音素识别模型的优化器为Adam.

表7 不同优化器对于音素识别的识别率
通过图8可以看出基于CNN-BGRU音素识别模型在优化器为Adam时,训练到最后的准确率较高.
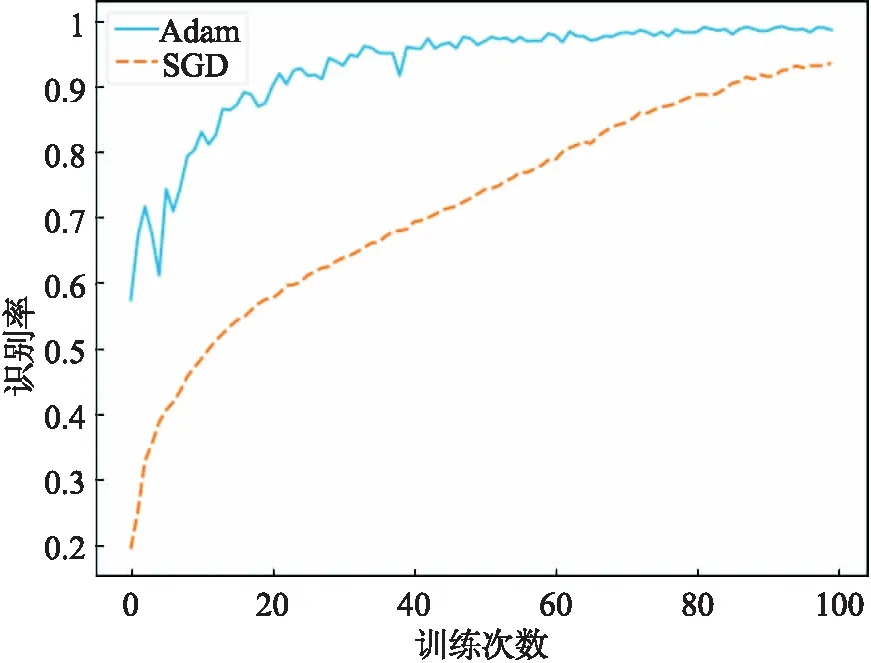
图8 不同优化器的实验结果统计图
3.4.3 不同模型对于音素识别率的影响
本文选择CNN-BGRU模型与CNN(VGG)、CNN-RNN、CNN-BRNN、CN -BLSTM这四个模型在TIMIT数据集上进行音素语谱图分类任务.通过准确率和损失作为评估指标进行结果分析,验证了CNN-BGRU模型对于音素语谱图分类任务的有效性.
通过表8中的实验结果可以知道,CNN-BGRU模型表现显著优于CNN-BRNN、CNN-BLSTM两个模型的效果.
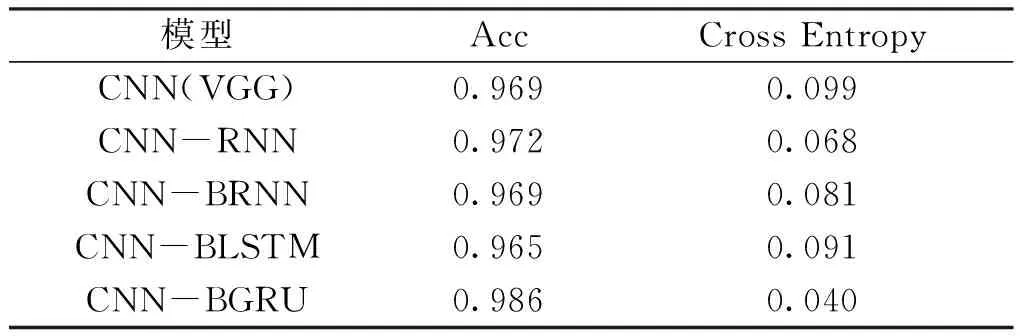
表8 不同模型的实验结果分析
1) RNN模型的有效性.从CNN(VGG)模型和CNN-RNN模型的实验结果对比可以看出,CNN-RNN模型的准确率高于CNN(VGG)模型,同时且损失低于CNN(VGG)模型,由此可以得出CNN-RNN模型提升了音素语谱图分类的结果.
2) 双向GRU的有效性.对比CNN-BGRU模型和CNN-RNN、CNN-BRNN、CNN-BLSTM模型的实验结果可以看出,CNN-BGRU模型的准确率高于CNN-RNN模型,准确率提升了1.4%,验证了BGRU模型的效果优于RNN模型.同时CNN-BGRU模型的准确率显著高于CNN-BRNN、CNN-BLSTM模型,且GRU模型的参数更少,可以有效提升模型的整体效率.
4 结语
本文提出了基于改进CNN-BGRU模型实现音素语谱图的分类,首先通过卷积网络VGGNet提取音素语谱图的特征信息;其次使用BGRU模型进行图像的前后文信息联合预测;最后通过softmax分类器输出分类预测的结果.相较于其他的方法,基于改进CNN-BGRU模型在提升模型分类准确性的同时,减少了模型中的参数数量,提升了模型的训练效率.后续工作是考虑基于多特征的音素语谱图识别,结合多种语音特征以提升音素语谱图识别的训练效率.
猜你喜欢
中学生英语·阅读与写作(2023年9期)2023-10-19 14:24:34
北京教育·普教版(2020年9期)2020-10-09 11:15:09
校园英语·中旬(2019年11期)2019-11-26 10:01:06
阅读(快乐英语高年级)(2019年5期)2019-09-10 07:22:44
小型微型计算机系统(2019年9期)2019-09-09 03:38:42
电子制作(2019年14期)2019-08-20 05:43:38
电子制作(2019年9期)2019-05-30 09:42:10
小说界(2018年5期)2018-11-26 12:43:42
疯狂英语·新策略(2018年7期)2018-08-29 08:54:26
吉林大学学报(信息科学版)(2018年3期)2018-06-13 10:36:38
