
一种改进的用户隐式反馈协同过滤推荐算法*
2020-12-18 07:46何丽麻强
北方工业大学学报 2020年5期
何 丽 麻 强
(北方工业大学信息学院,100144,北京)
根据中国互联网信息中心发布的《中国互联网发展状况统计报告》中显示,我国上网人数已达8.29亿,其中通过网络购物的用户超过了6亿,年增长率为14.4%. 由此可见,我国的互联网已经进入了高速发展阶段,但随之也带来了信息过载的问题[1],在网络中获取所需的信息成了一件困难的事情,因此推荐系统应运而生. 通过分析用户数据为其推荐可能感兴趣的信息已经在电商、电影、图书、音乐、广告、新闻等各大领域中应用,并取得了良好的效果. 近几年,相关学者致力于研究提升推荐精度的方法,并提出了基于内容的推荐、基于邻域的推荐、基于模型的推荐和协同过滤推荐.[3]其中,基于用户和商品的协同过滤(Collaborative Fdtering,简称CF)推荐是目前使用较多的算法. 其核心思想是根据用户真实的评分,预测出一个密集的评分矩阵. 但是如果数据非常稀疏,可能造成预测的矩阵不准确,进而影响推荐效果. 在电商领域中,用户在购买商品后得到的评分数据相对于行为数据来说非常少,如果只用较少的显式评分作为判断用户对商品的喜好程度,并不能产生好的推荐结果. 对于这些问题,不少学者提出了解决方案. 例如:Ma和Liu等人将用户的社交关系融入到模型学习过程中[4];Chen等人提出了一种融合时间序列和近邻信息的奇异值分解特征算法.[5]
然而,上述工作均是基于显式信息的评分矩阵,在真实情景中,用户产生更多的是隐式行为数据,由于其数量巨大,更加稳定的特点,近几年研究的学者越来越多,用户在挑选商品的过程中产生的数据可以真实地反映用户的态度,具有很高的研究价值.
隐式反馈数据一般存在以下3种明显的缺陷:1)数据噪声高:用户的行为记录是购买过程中的一种操作,这种操作有很大可能来自于随便看看或者误点广告等,不能代表用户的偏好. 2)缺少负反馈:隐式反馈数据不能反映出用户对某物品是否喜欢. 3)偏好程度无法评估:单次行为记录可信度并不高,只有高频率的事件才有可信度.
针对这些缺陷,研究人员提出了许多基于隐式反馈的推荐算法,其中较主流的方法是将隐式反馈转换为显示评分形式,通过协同过滤推荐算法进行推荐. Pan等人提出了加权的交替最小二乘法算法(Weighted Alternating Least Squares,简称WALS),其核心思想是对所有的样本进行加权,判断用户是否对某件商品进行了操作,从而将其权重设置为1或小于1的值,通过WALS算法有效地对行为数据进行了转换.[6]Min等人提出了一种MCF算法,将用户隐式行为转换为评分,用户对物品每产生一次行为,便给该物品的计数加1,用来建立用户与物品间的偏好对应关系,用户喜欢某物品的程度跟计数高低有直接关系.[7]王聪提出了主观上给用户的行为设定数值,点击1分、收藏2分、加购物车3分、购买5分,然后通过协同过滤算法进行推荐,也能够得到较好的推荐结果.[8]但由于该算法是主观的赋值,缺乏对整个数据环境的客观分析,并且每个用户对于每种行为的权重也不一样,不能够做到个性化的推荐.
本文将用户不同的隐式反馈信息转换为显示评分的形式,并融入了用户行为购买率,对层次分析法(Ardytic Hierarchy Process,简称AHP)算法得到的权值进行个性化的调整,通过spark大数据平台中的交替最小二乘法 (Alternative Least Squares,简称ALS)进行模型训练. 实验结果表明,该方法能够有效的为每个用户赋予不同行为权重,缓解了数据稀疏问题,使推荐的准确性有了更好的提升.
1 关键技术分析
用户在购买商品的过程中会产生大量的隐式反馈信息,一般可以采用主观和客观2种赋权方法将其转换为分值的形式,最长用的主观赋权法分为二项系数法、AHP算法和专家调查法;客观赋权法分为标准离差法、熵权法和CRITIC法.
1.1 熵权法
在信息论领域,事务的稳定性一般是通过信息熵来度量,得到的信息量越多,不确定性越低,信息熵越小. 相反,信息量越少,不确定性越高,信息熵越大. 根据熵的性质,一般可以把熵看作是一种物质的无序程度或随机性,也可以通过熵来判断一种指标的离散程度. 一个指标的离散度越高,该指标对整体评价的影响就越大.
因此,通过每种指标的不确定性,可以通过熵权法来为各个指标计算出权重,对整体评分有一个较好的依据. 计算过程有7个步骤:
1)选取n个用户和m个指标,在本文中指标为用户产生的浏览、加购、删购、下单、收藏5种行为,符号xij表示第i个用户的第j个指标的数值(i=1,2,…,n;j=1,2,…,m).
2)归一化:由于每项指标的单位不同,因此需要将不同单位的指标进行标准化处理,由于存在正负差异较大的指标,因此对正负指标的标准化处理也会不同,正向指标越高越好,负向指标越低越好.
正项指标:
(1)
负项指标:
(2)
则x′ij为第i个用户的第j个指标归一化后的数值. 为了方便起见,归一化后的数据仍记为xij.
3)计算第j项指标中第i个样本占当前指标的比重:
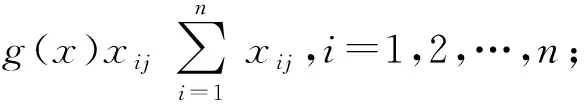
j=1,2,…,m
(3)
4)计算第j项指标的熵值:
(4)
5)计算信息熵冗余度:
dj=1-ej,j=1,2,…,m
(5)
6)计算各项指标的权值:
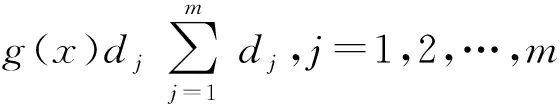
(6)
7)计算各样本的综合得分:
(7)
1.2.AHP算法
AHP是一种具有系统性和层次性,并且将定性与定量融合在一起的分析方法. 根据每个指标对结果的影响程度,主观的对指标进行比较,得出比例结果. 最后通过联合已知函数求解出每个指标的权重. 这种方法的特点是使用更少的定量信息使决策的思维数学化,在此基础上深入研究本质,影响因素和内涵,比较适合在指标数量较少的情况下使用.

表1 熵权法赋权结果
分析问题的性质并结合想达到的目标,层次分析法能够把问题分解成不同的元素,元素之间存在相互关系、从属和影响,从而形成一个多层次的结构模型. 在确定每一层的权重时,主观赋值往往比较困难. 因此,Saaty等人提出将所有的指标进行两两比较,尽量减少因性质不同而造成比较的困难,提高比较的准确性.[9]两两比较的赋值可参考表2.

表2 AHP算法赋值参考表
对于实验中的5种行为,按照重要性顺序为依次排列为下单、加入购物车、收藏、浏览、删除购物车,权重分别记为:w1,w2,w3,w4,w5. 其中删除购物车体现出用户不在关注此商品,因此可以当做负反馈,本文给出表3比值作为实验参数.
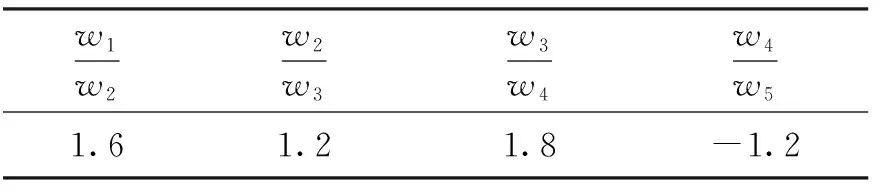
表3 AHP算法公式取值
由于权值的总和为1,通过联合表3中的式子得出每种行为对应的权值,结果如表4所示.

表4 AHP算法赋权结果
1.3 目前存在的问题
推荐系统想要得到更加准确的数据,训练数据必然非常庞大,但数据量过大会造成运行时间过长,基于此,本文利用处理大数据业务的spark平台,进行推荐算法的模型训练.
除了计算速度慢、运行时间过长的问题,有些用户喜欢“货比三家”,仅浏览商品但不下订单;有些用户在挑选商品时不浪费太多时间,看到比较满意的商品便会下单. 因此第一类用户的浏览行为权重应该低于第二类用户,这种现象说明了不同用户在购买商品时的行为权值不尽相同,不论主观赋权法还是客观赋权法,得到的权重只有一组,只能代表当前数据集下的平均权重,不能反映出每种用户的个性行为权重.
2 改进的AHP算法
在AHP算法的基础上,本文提出了AHP-PR(Analytic Hierarchy Process Purchase Rate)算法,由于每个用户对待商品的态度各不相同,有的用户喜欢将商品添加到购物车或者收藏夹然后慢慢比较,最终挑选出来一款比较喜欢的产品购买,因此在众多行为数据中,浏览和加购物车的数据远不如购买行为的数据重要;相反的,有的用户看好一件喜欢的商品便会购买,不会产生更多的数据,因此浏览行为或者加购行为变得比较重要. 本文将各种行为的购买率(Purchase Rate,简称PR)融入到AHP方法中,在得到每个行为的权重后,融入了每个用户的每种行为购买率,对AHP算法得到的权值进行调整,设置最大浮动比例为f. 由于每个用户的购买率各不相同,因此对2种行为的调整幅度也会不同,进而构造出个性化的权重值. 以浏览购买率为例给出公式(8).
(8)
其中n为用户产生每种行为的次数,r浏览为用户的浏览购买率. 将浏览购买率划分为9个阶段,若为0时,则代表该用户的浏览行为相对购买行为而言极不重要,因此将其权重降低百分之百最大浮动比例. 若为1时,则代表该用户的浏览行为相对购买行为而言极其重要,因此将其权重增加百分之百最大浮动比例. 剩下7个阶段将按照浏览购买率的均值进行划分,详情如表5所示.
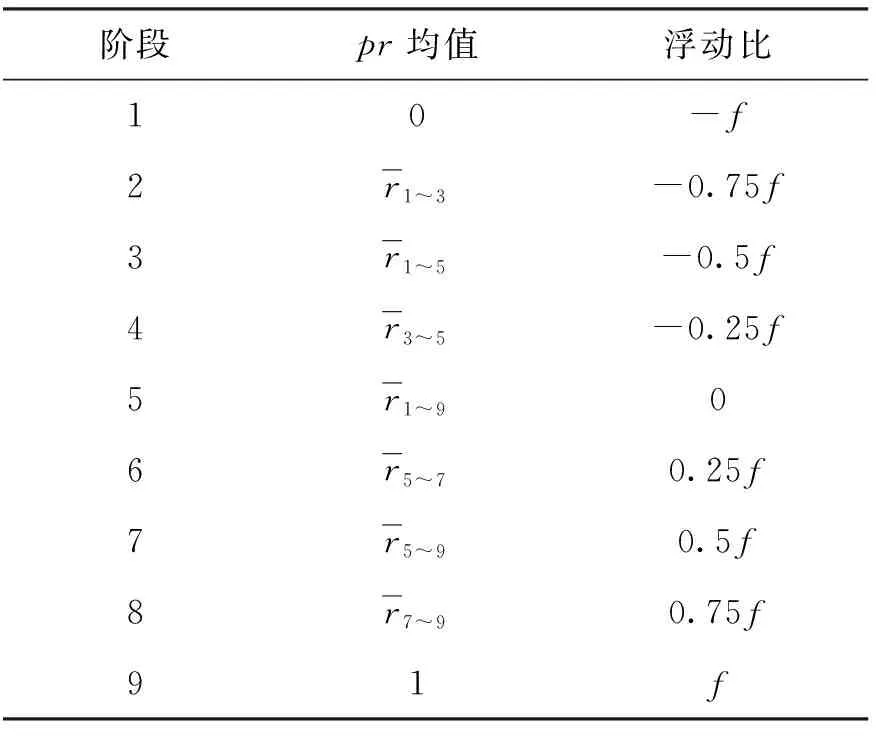
表5 PR浮动比例
根据表5,浏览行为权重会根据每个用户的购买率不同进行相应的调整,同样的,加入购物车的购买率和收藏的购买率也按照上述方法进行计算,最终得到了基于用户实际购买情况产生的权重,进而得到个性化的评分结果.
3 实验结果分析
3.1 介绍实验数据集
本实验数据集来自京东算法大赛中提供的2018年2月— 4月京东商城中用户对商品的6种行为数据,分别是浏览、加购、收藏、删够、下单和点击. 将数据按照月份划分,得到3个数据集,每个月的行为数据均达到了千万级,以3月数据为例,共有96 087个用户,23 753件商品以及25 916 378条行为. 但并非所有数据都是有效的,本文首先对原数据集进行清洗,由于点击行为和浏览行为在一定程度上非常相似,且浏览行为是指对商品详情页的浏览,比点击行为更具有代表性,因此本文只分析浏览、加购、删购、下单、收藏这5种行为. 按照下面3种情况进行过滤:1)点击行为数量巨大但无购买行为的数据;2)点击行为数量较大但无任何收藏或加购等其他行为的数据;3)无任何浏览或点击行为,但有收藏或加购行为的数据. 表6为清洗前后数据情况.

表6 数据集清洗前后数据总数
3.2 实验环境及参数
本实验的环境基于spark平台, spark提出了一种弹性分布式数据集RDD(Resilient Distributed Dataset). 具有非常好的容错性,当一个RDD分片丢失时,spark会根据日志中的信息复原RDD,从而保证数据前后一致性. RDD缓存会存储在内存中,下次计算时直接从内存中读取,比一般的大数据平台节省从磁盘中读取数据的时间,提高计算速度,非常适合做迭代计算的矩阵分解算法.
本实验采用spark的原生语言Scala编写程序,综合利用spark的机器学习库和Hadoop的分布式文件系统,实验中的参数按如下设定,maxIter为15、rank为50、lambda为0.25、floatMax为0.5.
3.3 实验结果
熵权法是目前主流的赋权方法,具有客观公正的特点. 采用ALS作为优化矩阵分解模型损失函数的算法[10],为了确定实验中ALS算法的最优参数,本文先通过熵权法对隐式信息进行转换,并将数据集按照8∶2的比例划分为训练集和测试集. 使用参考文献[11]中的评估方法作为评价指标,RMSE和MAE的计算方法分别如公式(9)和(10)所示.
(9)
(10)
这2种评估方法的误差越小,表示算法的预测准确率越高. 协同过滤推荐算法中rank一般设置在10~100为最好,随着rank越来越高,执行所消耗的时间会成倍提升,设计此实验是为了获取最优rank和lambda的值,如图1所示.
通过图1可以看出当rank值在50以上会有良好的结果,但随着rank取值越大,消耗时间成倍增长,因此rank选择50,而lambda为0.25时RMSE和MAE最小,因此下面将基于这2个取值进行实验. 本文采用了4种赋权方法进行实验:熵权法、AHP、混合法以及AHP-PR算法. 将隐式反馈信息转换为显式评分,并通过隐语义模型(LFM)的ALS算法对京东数据集中不同月份的数据进行训练. 实验结果如表7所示.
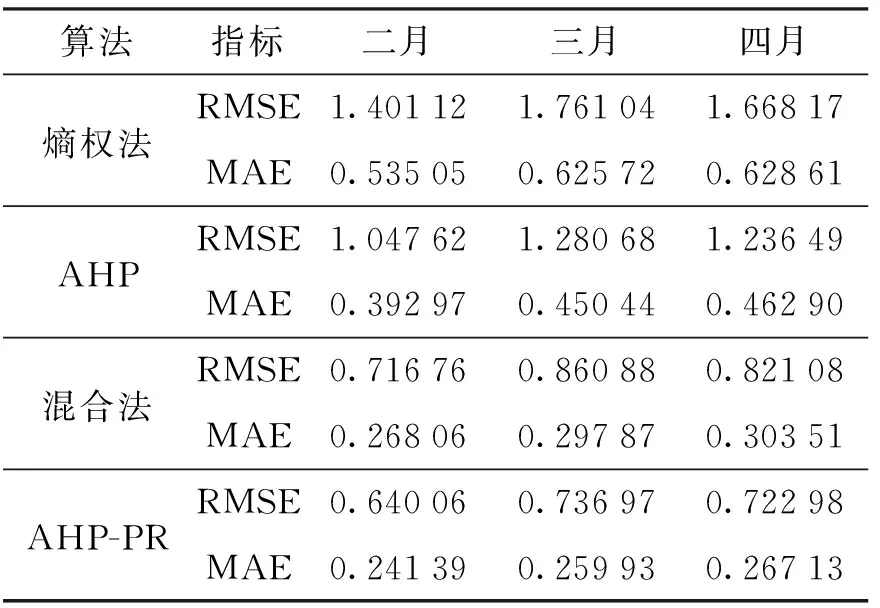
表7 实验结果
从表7中可得出,使用AHP-PR算法在RMSE和MAE两个评估方法中分别比熵权法提高了58.15%和58.46%,比AHP算法提高了42.45%和42.29%,比混合法提高了14.39%和12.74%,从图2也可值观看出改进后的AHP算法能够较好地提高推荐的准确度.
4 结语
针对推荐系统中存在的因用户评分数据稀少而导致推荐结果精度较低的问题,本文提出了一种将用户的隐式行为转换为分值形式,通过融入用户的浏览购买率给每个用户分配个性化的行为权重,大大提高了推荐系统的准确率. 借助大数据平台加快计算效率,在spark集群下进行实验,结果表明,使用AHP-PR方法不仅可以有效的解决推荐系统中矩阵稀疏的问题,还能提高推荐的准确率,接下来的研究工作将引入时间梯度和各行为的收藏率或加购率,以期获得更好的推荐效果.
猜你喜欢
运筹与管理(2022年9期)2022-10-20
导航定位学报(2022年4期)2022-08-15
冰川冻土(2022年1期)2022-06-19
心理学报(2022年5期)2022-05-16
民族文汇(2022年9期)2022-04-13
现代临床医学(2022年1期)2022-02-12
昆明医科大学学报(2021年12期)2021-12-30
客联(2021年3期)2021-09-10
当代陕西(2020年17期)2020-10-28
人大建设(2018年5期)2018-08-16
