
基于卷积自编码和哈希算法的图像检索研究
2020-12-15 11:18邱奕敏吴振宇
仪表技术与传感器 2020年11期
周 纤,邱奕敏,吴振宇
(武汉科技大学信息科学与工程学院,湖北武汉 430081)
0 引言
随着互联网上图像资源指数级增长,根据不同用户的要求来查找相似图像极为困难。基于内容的图像检索与给定查询图像类似的图像,其中“相似”可以指视觉上相似或语义相似。因此,本文针对语义相似性进行检索。假设数据库中的图像和待查询图像都是由实值特征表示的,那么查找相关图像最简单的方法,是根据数据库图像与特征空间中查询图像的距离对数据库图像进行排序,并返回最接近的图像[1]。然而,对于当前常见的数据库而言,即使进行线性搜索也会花费大量的时间和内存,所以基于深度学习哈希检索的方法被学者们广泛研究[2-4]。
近些年,深度学习广泛应用于图像检索,因此基于卷积神经网络(convolutional neural network,CNN)[5-7]提取特征的方法被广泛研究。深度卷积神经网络在各类数据集中应用广泛,且其性能也较为优良。但神经网络取决于训练数据集的大小,当训练样本覆盖范围较大时,所训练网络的准确性相对较高。但在神经网络模型建立中,若采用特征覆盖性较小的数据集进行训练测试,所训练的神经网络模型将会过度拟合数据集。此外,卷积神经网络池化层会丢失较多的信息,从而降低空间分辨率,导致对于输入的微小变化,其输出几乎是不变的,容易降低模型的准确性。因此找到合适的特征提取算法,以及选择特征覆盖较大的图像数据集来训练数据,成为相似图像检索的关键问题之一。
为了解决特征提取的准确性问题,本文将自编码器与卷积神经网相结合,提出基于卷积自编码神经网络(convolutional auto-encoders,CAE)的特征提取算法。该算法根据手写数字图像与服装图像特点,设置卷积核参数,以此进行特征提取。所提取的特征不仅具有自动编码器输出特征与输入相同、无监督快速提取的优点,还拥有卷积神经网络权值共享的优点,能够较大程度解决卷积神经网络池化易丢失信息,以及自动编码器提取特征准确率低的缺点。同时,为了解决图像检索时间和精确率问题,本文将CAE与哈希算法结合,提出了基于卷积自编码和哈希算法相结合的图像检索算法(convolutional auto-encoder and hash,CAEH),能够显著降低相似图像检索的时间,提高图像检索的准确率。
1 相关工作
1.1 相关基础研究
传统的图像检索方法一般是将SIFT、GIST和HOG等的人工特征[8-9]编译成哈希编码[10]。虽然这些哈希方法在某种程度上取得了一定的效果,但均使用了手工制作的特征,这些特征无法捕捉真实数据中剧烈外观变化下的语义信息,低层特征对图像内容的表现力亦不足,不能反映图像之间的语义相似性。
为了解决语义相似问题,近年来学者们提出了几种基于卷积神经网络的哈希方法[11-15],利用CNN来学习图像的二进制代码和表示。Zhao F等[11]提出了一种基于语义排序和深度学习模型框架,用于学习哈希函数,以保持语义空间中多标签图像之间的多级相似性。Lai H等[12]提出了一种“one stage”的监督哈希方法,通过将输入图像映射到二进制代码的深层架构来进行哈希编码。Xia R等[13]提出了一种用于图像检索的监督哈希方法,该方法同时学习图像的良好表示以及一组哈希函数,通过深度卷积网络,学习哈希编码和可选离散类标签的图像。虽然使用卷积神经网络自动学习图像的特征表示,已经取得较好的性能。然而,由于卷积网络池化会丢失较多信息,特别是当数据量较大时,容易降低检索精度,因此深度学习获取图像深层有限特征成为检索的关键。Lin K等[14]提出了一种简单有效的深度学习框架来创建类似哈希的二进制编码,用于图像检索。Zhang R等[15]提出了一种比特可扩展的哈希方法,通过深度卷积神经网络特征学习和哈希函数学习,集成到联合优化框架中,利用卷积神经网络建立原始数据与二进制哈希码之间端到端的关系,实现快速检索。然而,这些方法仍存在以下缺点:图像特征表示不够准确,导致检索精度下降;由于用于学习的哈希函数不同,对检索的时间和精度均有影响。针对这些缺点,本文提出了基于卷积自编码和哈希算法相结合的图像检索算法CAEH,能够极大降低相似图像检索的时间,提高图像检索的准确率。其中,卷积自编码神经网络特征提取是基于卷积神经网络和自编码器两者特征提取的优势而确定的。
1.2 卷积神经网络
卷积神经网络是一种常见的深度学习网络框架,受生物自然视觉认知机制启发而来。CNN是分层模型,其卷积层与子采样层交替,使人联想到初级视觉皮层中的简单和复杂细胞[16]。卷积神经网络的网络体系结构由3个基本构建块组成,可根据需要进行堆叠和组合。由于它的权值共享结构和生物神经网络更类似,因此可以减少权值的数量,从而降低网络模型的复杂度,其近年来已成为深度学习的研究热点之一。
1.3 自动编码器
自编码器是一种基于无监督学习的神经网络,用来提取样本内在特征,由编码器和解码器2部分组成,通常用来作特征学习或数据降维[17]。编码器将输入数据编码成潜在变量,解码器再把潜在变量重构为原数据。由于自编码器能够对数据进行降维,并有效滤除冗余信息,在图像检索方面极具优势,因此被广泛采用。
2 研究方法
本文结合基于卷积自编码神经网络的非线性特征提取方法,以及哈希算法加速检索的特点,分析无监督特征提取和哈希方法降低存储空间(低内存耗费)的特点,综合两者优势,提出了一种基于卷积自编码神经网络和哈希算法的图像检索算法CAEH,本文算法模型如图1所示。

图1 本文算法模型
本文算法将28×28大小的图片输入到卷积自编码网络,经过卷积层和反卷积层,预训练卷积自编码,得到编码器模型。提取图像深层特征向量,进行哈希编码,用较短的编码来代表一张图片。
当输入一张要查询的图像时,将其经过上述处理后,得到哈希编码。然后,将该编码与图像库里图片的哈希编码共同计算汉明距离。距离越小,表明哈希编码越接近,那么可以认为这两张图片也越相似。
本文算法将从图像预处理、卷积自编码特征提取、哈希编码3部分来介绍图像检索的研究方法。
2.1 图像预处理
本文图像预处理阶段分为2步进行,第一步对MNIST数据集和Fashion-MNIST数据集中的图像进行灰度处理,转化为灰度图像,所处理的图像均为28×28像素。第二步将得到的灰度图像归一化,加快训练网络的收敛性。
2.2 卷积自编码特征提取方法
卷积自编码器实现的过程与自编码器的思想是一致的,都是使用先编码再解码,比较解码数据与原始数据的差异来进行训练,最后获得稳定的参数。卷积自编码神经网络的学习是使其损失函数最小,对于输入图像x={x1,x2,…,xi},假设有k个卷积核,每个卷积核参数由Wk和bk组成,用hk表示卷积层,得到式(1):
hk=σ(x*Wk+bk)
(1)
式中:σ为Relu激活函数;*表示2D卷积。
其中偏差被广播到整个图,每个潜在图使用单个偏差,因此每个滤波器对整个输入的特征进行特殊化操作,再利用该方法进行重建。每张特征图h与其对应的卷积核的转置进行卷积操作并将结果求和,然后加上偏置,得到反卷积操作,如式(2):
(2)

将输入的样本和最终利用特征重构得出来的结果进行欧几里得距离比较,并通过BP算法进行优化,就可以得到一个完整的卷积自编码器损失函数,如式(3)所示:
(3)
与标准网络一样,反向传播算法用于计算误差函数相对于参数的梯度。使用式(4)通过卷积运算可以很容易地获得梯度值。
(4)
式中:δh和δy分别为隐藏状态和重建状态的增量。
然后使用随机梯度来更新权重。
适当改变CAE编解码器中的卷积核的大小与卷积层的个数,可以实现特征全面有效提取,易于各层分工合作,实现相应的特征提取功能。本文使用的卷积自编码网络结构及参数如表1所示。

表1 卷积自编码网络结构及参数配置
CAE模型由2个卷积层(conv1~2),3个反卷积层(deconv1~3)和1个潜在层构成。表1中卷积层和反卷积层的第一行参数表示卷积滤波器的数量和局部感受野的大小。其中,“st.”表示卷积的步幅,“pad”表示空间填充,“ 2 pooling”表示max-pooling下采样,“ 2 Upsampling”表示上采样。CAE的激活函数除了反卷积第三层采用sigmod激活函数外,其余的都使用矫正线性单元Relu。
2.3 哈希编码
在获得图像深层特征表达式之后,通过哈希算法可以获得最终的检索结果。哈希方法是一种常用的近似最近邻搜索(approximate nearest neighbor search,ANNS)方法,它将高维的特征映射到低维空间,随之产生二进制编码,再计算汉明距离,这样大幅度降低了计算代价。
近年来,虽然利用哈希方法来学习保持相似性的二进制代码已得到广泛的应用,但普遍受到手工制作的特征或线性投影的限制,因此大规模图像检索时,检索性能会极大降低。为了解决上述问题,本文对图像进行紧凑二进制编码,以便使得类似的图像编码为汉明空间中的类似二进制编码,以便有效地计算二进制编码,从而提升图像检索的精度,并降低检索时间。
这种二进制紧凑编码可以使用汉明距离进行快速比较图像深层特征的相似性,能有效降低计算成本。对于输入的图像x,提取LatentFC1层的输出记为O(x),然后通过将阈值进行二值化,从而得到图像x的二进制编码。对LatentFC1层中的每一位,将其二进制码表示为X:
(5)
使用Γ={x1,x2,…,xn}表示用于检索的数据集,包括n张图像。与其对应的每张图像的二进编码表示为Γx={X1,X2,…,Xn},其中Xi={0,1}k对于任意查询图像xq和它的二进制编码Xq,使用xq的特征向量和第i幅图像的特征向量之间的汉明距离来表示它们之间的相似性。汉明距离越小,两幅图像就越相似。按照汉明距离的大小将用于检索的数据集中的图像按照升序排列,故而能够检索出排在前k的图像。
3 实验结果及分析
3.1 数据集
为了证明本文方法的有效性,在以下2个图像集上对本文方法进行了评估。MNIST[18]数据集是美国国家技术与标准研究所收集制作的0~9手写数字数据集,来自250个不同的人手写而来。其中训练集包含60 000个28×28灰度图的数字(0~9)图像及标签,测试集包含10 000个28×28灰度图的数字图像及标签。MNIST部分测试图像2所示。

图2 MNIST部分测试图像
Fashion-MNIST[19]是由德国的时尚科技公司Zalando旗下的研究部门提供,涵盖了来自10种类别共7万个不同商品的正面图像。Fashion-MNIST的大小、格式和训练集/测试集划分与原始的MNIST完全一致,该数据集部分测试图像如图3所示。

图3 Fashion-MNIST部分测试图像
本文中,相似性标签由语义级标签定义。对于MNIST/Fashion-MNIST,来自相同类别的图像被认为在语义上是相似的,反之亦然。本文方法仅采用10类70 000张图像,输入图像尺寸均为数据集原始尺寸。其中,60 000张图像用于训练模型,10 000张图像用于评估模型的测试。在选取的图像中,随机抽样10 000张图像形成测试查询集,并将剩余图像用作训练集。
3.2 实验设置
实现评估部分,将本文方法的检索性能与其他的哈希方法作比较,包括非监督的哈希方法LSH、SH、ITQ,监督的哈希方法KSH,以及深度学习与哈希技术相结合的哈希方法CNNH、DLBHC。本文实验环境采用Windows10系统,Python编程语言,Keras框架作为神经网络学习框架。在MNIST和Fashion-MNIST数据集中,每一类选择1 000张图像构成包含10 000张图像的测试集。对于无监督的哈希方法,其余的数据作为训练集。对于监督的哈希方法,每类选择6 000张,组成包括60 000张图像的训练集。对于深度学习与哈希计算相结合的算法,直接使用图像作为输入。而其余的方法,数据集MNIST和Fashion-MNIST采用深层特征表示图像。
为了评估图像检索性能并与已有方法作比较,本文采用平均精度均值(mean average precision,MAP)、检索返回top-k近邻域的准确率曲线这2个参数进行评估。通常根据查询图像的汉明距离和计算的MAP值来对图像进行排序,MAP值是由Precision-Recall曲线所包围的面积,MAP的值是哈希函数整体性能指标。MAP值计算过程主要分为2步。第一步计算平均准确率AP,假设经过检索系统返回K个相关图像,其位置分为x1,x2,…,xK,则单个类别的平均准确率APi表示为
(6)
第二步对AP进行算术平均,定义图像类别数为M,则MAP为
(7)
除此之外,本文还采用top-k近邻域检索准确率作为评估的方法,该指标表示的是与查询图像汉明距离最小的k张图像中正确的结果所占的比列,换言之,就是查询出来排名前k的图像中有正确结果的比例。
3.3 实验性能分析
在MNIST数据集上,本文方法与现有方法MAP值的比较结果如表2所示。从表2可以看出,本文算法的MAP值远远高于传统特征与哈希方法结合的算法(KSH、ITQ),因为本文利用深度卷积自编码网络同时学习特征表示和哈希函数,极大提高了图像的表示能力。与其他的深度卷积神经网络与哈希技术相结合的方法相比,本文算法的MAP值最高,表明深度哈希的效果更好,说明深度网络是一种学习图像深层特征表示和生成哈希编码的有效方法。在任何情况下,本文提出的CAEH方法在检索性能优于其他比较方法。
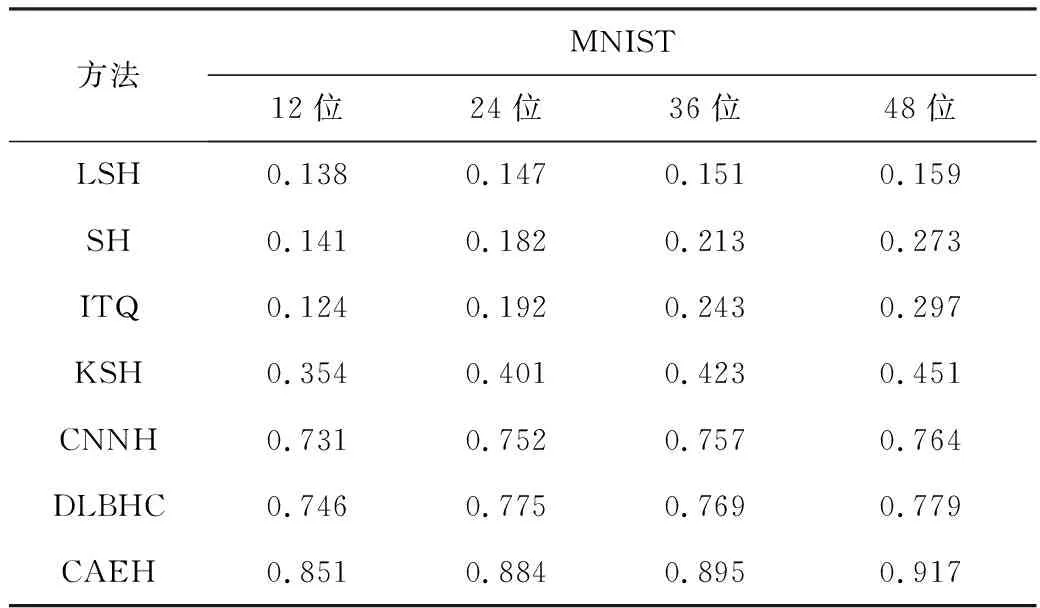
表2 在数据集MNIST上按汉明距离排序的MAP值
表3中给出在Fashion-MNIST数据集上,本文方法和现有方法MAP值的比较结果。从表3可以看出,本文算法的MAP值远远高于传统特征与哈希方法相结合的算法(如KSH),提高了40%。与现有的深度卷积网络与哈希技术相结合的方法相比,不仅同时进行特征学习和哈希函数的学习,并且采用了深度结构去学习哈希函数与深度特征,因此本文算法的MAP值最高。
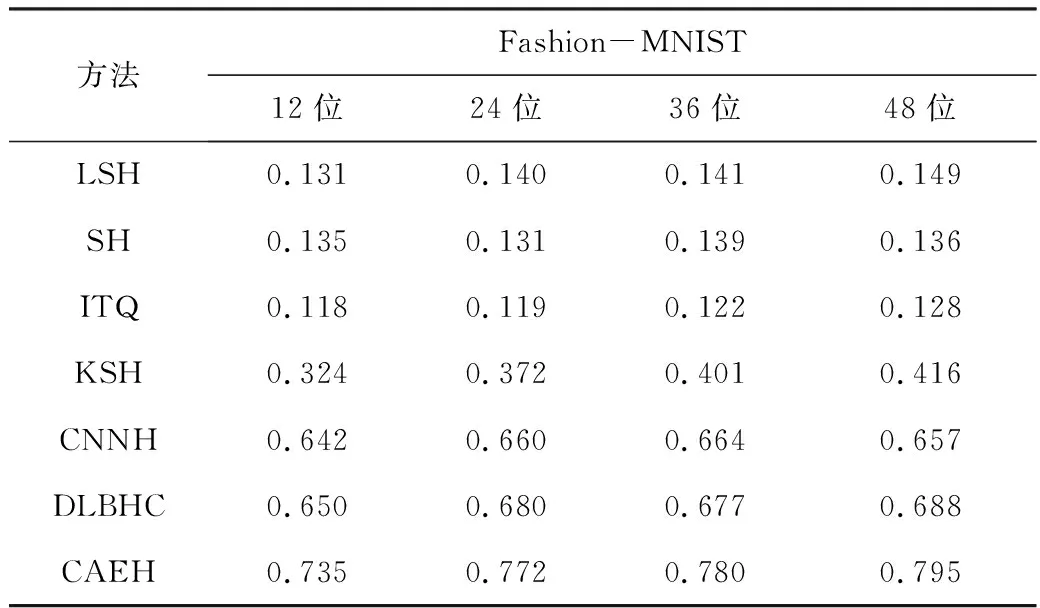
表3 在数据集Fashion-MNIST上按汉明距离排序的MAP值
图4和图5分别为本文方法在MNIST和Fashion-MNIST数据上的top-10检索结果。从图中可以看出,通过潜在二进制代码的变化位数从MNIST和Fashion-MNIST数据集中检索到前10个图像,当位数增加时,检索具有相似外观的相关图像。
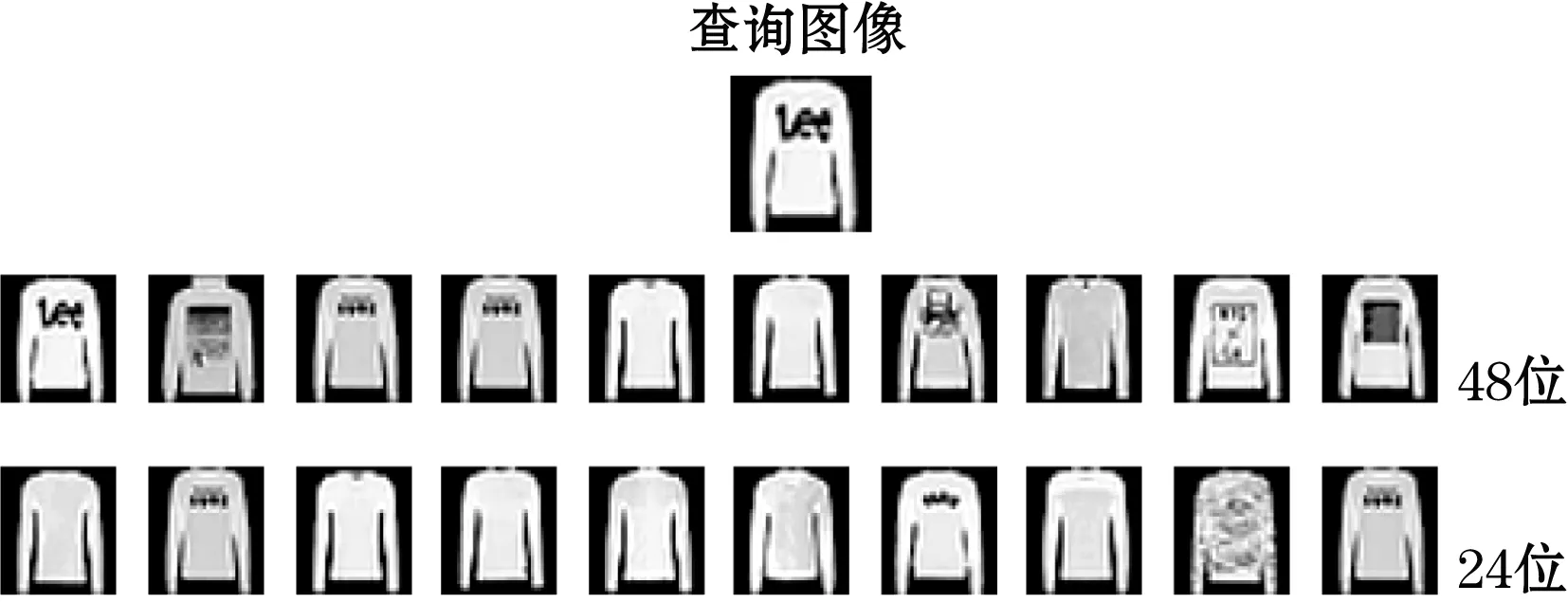
图5 Fashion-MNIST数据集中检索到的前10个图像
本文的实验部分统一使用48位二进制编码和汉明距离测量来检索相关图像的检索评估。通过从系统的测试集中随机选择1 000个查询图像来执行检索,获得相关的查询图像。图6为不同哈希算法在Fashion-MNIST数据集上top-k检索精度曲线图,从图6可以看出,本文算法CAEH的检索精度明显优于其他哈希算法。
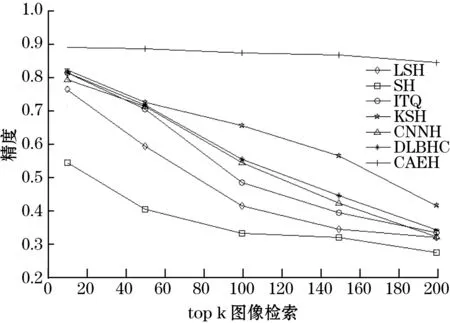
图6 不同哈希算法top-k检索精度曲线
4 结束语
本文提出一种基于卷积自编码神经网络与哈希编码的图像检索算法CAEH。在大规模相似图像检索问题上,检索准确率和检索时间上得到明显提升。本文算法先采用CAE网络模型对目标图像集提取图像的深层特征表示,再使用哈希编码策略把这些特征编码成二进制码。为了验证本文算法的有效性和准确性,实验采用MAP值和检索返回top-k近邻域的准确率曲线的评估方法。实验结果表明,本文方法与LSH、SH、ITQ、KSH CNNH和DLBHC相比,能获得更高的性能。在MAP值上远高于传统方法,在top-k检索相似图像上获得非常高的精确率。虽然本文算法对比传统方法和深度学习方法取得了很好的效果,但是还有一些问题有待解决,如卷积自编码器不是对所有图像深层特征的提取,都能表现良好的效果;如哈希编码也并不是对所有图像深层特征编码进行图像检索,都能表现良好的效果,这些问题均有待进一步的深入研究。
猜你喜欢
网络安全与数据管理(2022年1期)2022-08-29
大数据(2021年6期)2021-11-22
电脑爱好者(2021年8期)2021-04-21
电脑爱好者(2020年20期)2020-10-22
制造技术与机床(2017年7期)2018-01-19
西安工程大学学报(2016年6期)2017-01-15
专利代理(2016年1期)2016-05-17
探测与控制学报(2015年4期)2015-12-15
电脑爱好者(2015年13期)2015-09-10
质量与标准化(2010年5期)2010-05-03
