
一种不平衡水声目标数据的选择性集成算法
2020-12-15 02:36程玉胜张宗堂李海涛刘振
哈尔滨工程大学学报 2020年10期
程玉胜,张宗堂,李海涛,刘振
(海军潜艇学院 航海观通系,山东 青岛 266000)
对于两分类问题,如果其中一类的样本数量远多于另一类,则这个问题就称为不平衡数据分类问题,其中,数量多的一类为多类,数量少的为少类。近年来,不平衡数据分类问题成为了机器学习的热点问题之一,在邮件过滤[1]、软件缺陷预测[2]、医疗诊断[3]、DNA数据分析[4]等领域得到了广泛的研究。在水声目标识别中,各种船舶、航行器、生物等目标种类繁多,不同种类之间的数量也相差较大,这也就形成了不平衡数据分类问题,但它在水声领域的研究较少。
集成学习及其改进算法[5-8]常用来解决不平衡数据分类问题,选择性集成学习是一种新兴的集成学习算法,它是在一定策略下从全部基分类器中挑选一部分来组成最终集成分类器,文献[9]通过理论分析,提出了“many could be better than all”理论:对于有监督学习,给定一组基分类器,选择其中一部分进行集成或许比选择全部要好。
选择性集成的核心是差异性,研究者从软件工程[10]、信息论[11]、统计学[12]等领域提出了有关差异性的度量方法,并在此基础上提出了许多选择性集成算法[13-14]。直观上看,基分类器之间的差异性越大,那么它们就可以“取长补短”,使得最终的集成分类器有较好的泛化性。选择性集成学习算法在不平衡数据分类问题上得到了一定的应用,文献[15]将几种选择性集成方法进行改造,提出了RE-GM、MDM-Imb、BB-Imb等算法,试验结果表明改进算法在不平衡数据集上性能有所提高,文献[16]采用重采样、集成算法与差异性提高方法相结合来处理不平衡问题。
本文从差异性和不平衡性2方面出发,首先通过间隔理论揭示了单纯增加差异性无法提高泛化性的原因,然后通过将间隔的概念在分类器空间扩展,定义了间隔度量,通过间隔度量刻画了不同基分类器对样本不平衡性的影响,从而选择出有利于少类目标分类正确率提高的基分类器,结合差异性和不平衡性2方面因素,通过差异性度量增加差异性并通过间隔度量倾向于少类目标,从而构建了间隔和差异性融合的选择性度量,根据选择性度量对基分类器进行筛选,形成间隔和差异性融合的选择性集成算法(margin and diversity fusion selective ensemble algorithm,MDSE),提高集成算法对少类目标的分类能力。
1 间隔理论
AdaBoost算法是集成学习中Boosting算法族的核心算法,它本质上是一种元算法,任何有监督基分类算法均可通过AdaBoost算法进行集成,它在统计学、机器学习和数据挖掘等方面得到了广泛的应用。间隔理论[17]是AdaBoost算法的重要理论基础,成功地解释其不易过拟合等性质。本研究用假设C(H)是基分类器空间H的凸包,集成分类器f∈C(H)可以表示为:
f=∑αihiwith ∑αi=1 andαi≥0
(1)
式中hi是权重为αi的基分类器。样本(xi,yi)关于由L个基分类器组成的集成分类器f的间隔定义为:
(2)
间隔的重要作用是它能够刻画分类系统的泛化性,文献[18]推导出集成分类器泛化误差界与其间隔统计特征的关系。
定理1从训练样本集上的一个分布Dist中独立随机抽取N(N>5)个训练样本组成集合Dtr,对任意的θ>0,每一个集成分类器f∈C(H)在Dtr上至少以1-δ的概率满足泛化误差界:
(3)
式中:
(4)
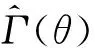
2 集成分类器泛化性与差异性的关系
对于一个分类系统,其泛化误差直接决定了分类性能的好坏。在选择性集成学习中,虽然差异性是关键因素,但很多试验表明,并不是差异性越大,泛化性就越好。这就使得研究者需要从理论角度解释这个问题,文献[19]通过对多种常用差异性度量的总结,引入最小化间隔,给出了最大化差异性和间隔最大化的一致条件。但其试验发现差异性与最小间隔又不是完全正比关系。从定理1可以看出,决定系统泛化性的是间隔的统计特征而不是最小化间隔,因此,本文从理论上推导出差异性度量与间隔统计特征的关系式,从而给出单纯增加差异性并不一定能改善泛化性的原因。
根据间隔的定义,得到训练样本集全部间隔的均值为:
(5)

由于:
(6)
(7)
两式相加得:
(8)
因此,基分类器的识别正确率为:
(9)
对于平均识别正确率:
(10)
文献[20]总结了6种差异性度量,根据上文符号将它们统一归纳为:
(11)
式中:div是基分类器的差异性度量;a、b、c为常数;li是对样本识别错误的基分类器的权重之和与L的乘积。
由于:
(12)
(13)
因此:
(14)



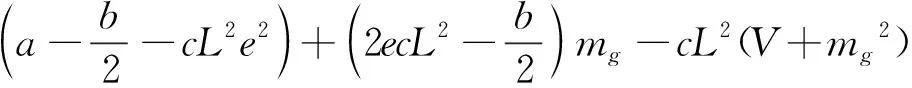

(15)
式中V为mi的方差,即间隔方差。定理1提到,间隔均值越大,同时间隔方差越小,则泛化误差越小,在式(15)中,差异性度量与间隔均值和间隔方差成非线性关系,提高差异性度量并不能保证增大间隔均值且减小间隔方差,因此单纯增加差异性并不一定能降低泛化误差,所以传统的差异性度量有一定的局限性。另外,由于差异性度量未考虑样本不平衡性,因此不适合直接处理不平衡数据分类问题,这就需要有新的度量准则。
3 间隔和差异性融合的选择性集成算法
3.1 间隔和差异性融合的选择性度量
间隔统计特征作为集成分类器泛化性的良好刻画,可以用来度量差异性,不过从间隔的定义可以看出,间隔是样本的特征量,而差异性度量的是基分类器之间的特性,因此需要把间隔的定义扩展到分类器空间,来刻画基分类器对间隔大小的贡献程度。
定义1基分类器hj对样本xi的间隔贡献量:
mc=yiαjhj(xi)
(16)
定义2基分类器hj对少类目标训练样本集Dp的少类间隔均值贡献量:
(17)
定义3基分类器hj对多类目标训练样本集Dn的多类间隔均值贡献量:
(18)
从定义可以看出,mp的值越大,基分类器对少类间隔均值的贡献就越大,则基分类器对少类目标的分类正确率就越高,因此可以将mp作为分类器选择的一种度量,但只提高少类目标正确率而完全忽视多类目标并不是想要的结果,所以也需要将mn纳入度量中。
定义4根据少类和多类间隔均值贡献量,定义间隔度量:
Cm=λmp+(1-λ)mn
(19)
式中:λ∈[0,1]为权衡系数;Cm用来度量基分类器对两类样本间隔均值的贡献量,可以在偏向于少类间隔均值的同时也兼顾多类间隔均值。
另一方面,传统的差异性度量一般分为成对型和非成对型,二者均无法与间隔度量直接融合,因此需要做一定的改进,本文采用Q统计量作为差异性度量进行改进。
表1中,nij表示符合相应条件的个数。Q统计量Qij是在2个基分类器的联合输出上构造的:
(20)
Qij越大,说明2个分类器之间的差异性越小。

表1 2个基分类器的联合输出Table 1 The joint output of two base classifiers
定义5根据Q统计量定义差异性贡献量:
(21)
从定义可以看出,Cq是hj与所有基分类器的Q统计量的均值的负数,Cq越大说明该基分类器对整体的差异性贡献越大。
定义6融合间隔度量和差异性贡献量,定义选择性度量:
Ms=γCm+(1-γ)Cq
(22)
式中γ∈[0,1]为权衡系数。
3.2 算法描述
选择性度量Ms兼顾了间隔和差异性两方面,既确保了基分类器之间的差异性,又可以筛选出对少类间隔均值贡献大的基分类器,从而提高少类识别正确率,利用Ms构造间隔和差异性融合的选择性集成算法。MDSE算法的输入是已经预训练完成的L个基分类器、训练样本集和最终子分类器集Hs的大小Ls,MDSE算法通过计算每个基分类器的间隔度量和差异性贡献量得到其选择性度量,根据选择性度量大小由高到低排序,选择前Ls个基分类器作为最终子分类器集并形成选择性集成分类器Fs(xi)。MDSE算法为:
1)对训练样本集进行预训练;
2)Forj=1:L
Fori=1:N
计算基分类器的间隔贡献量yiαjhj(xi);
计算差异性度量Qij;
End
计算少类间隔均值贡献量mp和多类间隔均值贡献量mn得到间隔度量Cm;
计算差异性贡献量Cq得到选择性度量Ms;
End
3)对基分类器按Ms大小由高到低排序,选择前Ls个基分类器组成子分类器集Hs;
4 实测水声目标数据试验
4.1 数据集及评价准则
试验采用整理得到的实测水声目标数据970条,其中,A类(少类)目标140条,B类(多类)目标830条。利用水声目标识别中常规的特征提取方法对数据集进行特征提取,分别提取其调制谱特征、高阶谱特征、MFCC特征和小波特征,特征维度如表2所示,将各自特征分别组成单独的特征集,下文的试验将在不同特征集上分别进行处理。

表2 试验数据特征维度Table 2 Feature dimension of experimental data
评价准则对于评估分类性能和指导分类器构建有重要作用,传统的分类器一般采用总体分类精度作为评价准则,但是总体分类精度并没有考虑样本的不平衡性,因此不再适合评价不平衡数据分类问题。F-measure准则、G-mean准则和AUC准则是不平衡数据分类问题的3种常用评价准则,其数值越高,说明算法处理不平衡数据分类的性能越好。
4.2 试验参数设置
预训练中,基分类器数量取50,基分类器种类选择决策桩。Ls是一个重要的参数,Ls过大则会增加参数数量和时间开销,过小则不能精确地表征数据。基分类器中,选择性度量为正的才对集成分类器有正面作用。通过不同参数下大量试验,对选择性度量中值为正的基分类器个数进行统计,统计结果如图1所示。可以看出,30作为值为正的基分类器个数的频率最高,因此取Ls=30。

图1 基分类器个数分布Fig.1 The number distribution of base classifiers
权衡系数中,由于首先要考虑的是偏向于少类目标,同时兼顾多类目标和引入差异性,因此取λ=0.6,γ=0.6。不平衡率是衡量数据不平衡性的一个重要指标,不平衡率IR定义为多类样本数量与少类样本数量的比值。一般认为,当不平衡率大于或等于2时,数据集为不平衡数据集。
试验中训练样本集和测试样本集中的少类数量相同且均为70,训练样本集和测试样本集中的多类数量相同,分别取140、210、280、350,对应的不平衡率分别是2、3、4、5。所有样本均随机地从样本集中抽取,训练样本集与测试样本集互斥,每个试验独立重复50次并取平均值。
4.3 试验结果与分析
为了验证MDSE算法的性能,将AdaBoost算法和基于Q统计量的选择性集成算法进行对比。利用F-measure准则、G-mean准则和AUC准则对测试结果进行评价,如图2~4所示。
图中,特征集1~4分别指调制谱特征集、高阶谱特征集、MFCC特征集和小波特征集,每一个特征集中,3个柱状图从左到右依次是AdaBoost算法、选择性集成算法和MDSE算法。从图中看出,在不同特征集、不同不平衡率下,MDSE算法的3种准则结果基本均高于AdaBoost算法和选择性集成算法。对每种特征集上不同不平衡率结果求均值,得到3种准则的平均结果如表3所示。平均来看,相对于AdaBoost算法和选择性集成算法,MDSE算法在F-measure准则下分别从0.26和0.32提升到0.38,在G-mean准则下分别从0.39和0.43提升到0.48,在AUC准则下分别从0.37和0.47提升到0.49,结果显著提高,说明在处理不平衡水声目标数据分类问题上,MDSE算法性能相对于AdaBoost算法和选择性集成算法有明显改善。
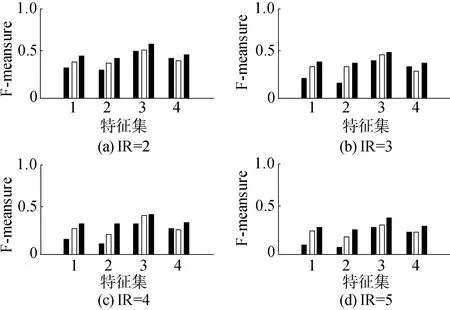
图2 F-measure准则结果Fig.2 The results of F-measure

图3 G-mean准则结果Fig.3 The results of G-mean

图4 AUC准则结果Fig.4 The results of AUC

表3 不同特征集准则均值结果Table 3 The criterion mean results of different feature set
5 结论
1)试验结果显示,相对于AdaBoost算法和选择性集成算法,MDSE算法在不平衡数据集上性能更优,说明差异性和不平衡性均对算法本身有影响。
2)对于差异性,本文证明了单纯增加差异性无法改善泛化性;对于不平衡性,以间隔理论为基础,提出了间隔度量来定量刻画不平衡性。理论分析对算法提供了有力支撑,而试验结果则印证了算法的有效性。
本文提供了一种解决不平衡数据分类问题的新思路,即兼顾不平衡性和差异性,有一定工程应用前景。下一步的工作中,可以将两分类问题扩展到多分类问题进行相应的研究。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
电子技术与软件工程(2019年18期)2019-11-18
五邑大学学报(自然科学版)(2019年3期)2019-09-06
第一财经(2019年8期)2019-08-26
江西教育B(2019年2期)2019-04-12
中南民族大学学报(自然科学版)(2019年1期)2019-04-04
中国诗歌(2018年6期)2018-11-14
电子技术与软件工程(2017年14期)2017-09-08
