
恶性肿瘤与工业污染之间的模糊关系挖掘*
2020-12-15 08:13:36储传鑫王丽珍周丽华李旭阳
计算机与生活 2020年12期
储传鑫,王丽珍,周丽华,李旭阳
云南大学信息学院,昆明650500
1 引言
恶性肿瘤是危害人类健康的重要疾病之一,在肿瘤的治愈率上,目前发达国家已达65%,而我国仅有25%左右。我国居民肿瘤治愈率远低于发达国家。面对肿瘤,防治结合是基本思路,虽然肿瘤并非不治之症,但面对我国幅员辽阔,人口众多,医疗基础设施不完善的基本国情,大多数肿瘤患者往往无法及时得到相应的治疗,通过在“治”上下功夫以求降低肿瘤致死率的想法尚不现实,而在计算机数据处理技术磅礴发展的今天,应用新兴技术,使得从“防”上降低肿瘤发病率已经成为可能。
想从“防”上降低肿瘤发病率,首先就必须了解人类致癌的因素。人类致癌的因素有很多,包括先天的基因遗传、物理因素(如多种电离辐射、紫外线等)、化学因素(来自生活、生产的各种化学物质)、病毒感染、细菌感染等。如今,在国家工业化建设的大背景下,各种各样的工厂在人们生活的邻近区域内建立起来,其在推进经济高速发展的同时,也排放出了工业污染,这与我国日益增长肿瘤发病率有潜在的联系。
数据挖掘是指从数据库的大量数据中揭示出隐含的、先前未知的、并有潜在价值的信息的非平凡过程。目前,利用数据挖掘技术挖掘疾病与潜在致病因素的联系方面已有一些研究成果,如:文献[1]利用粗糙处理先天性神经缺陷(neural tube defects,NTD)疾病数据,从海量的潜在致病因素中挖掘出了相关度较高的因素,但其用“有”“无”来衡量一个村庄的患病情况,不能反映一个村庄的患病的严重程度。文献[2]在粗糙理论的基础上,使用了模糊化的方法衡量每一个村庄患病的严重程度,利用模糊粗糙集技术处理NTD数据,取得了长足的进步。文献[3]则利用子组挖掘和统计检验的方法处理乳腺癌病患数据,挖掘出了一些有价值的信息,但假设检验方法一般计算复杂度较高。这些已有的研究除了各自固有的不足,还有一个共有的缺陷,就是它们都是针对一种疾病与多种致病因素关系的研究,针对多种疾病对应多种致病因素的情况,目前还没有发现相应的研究成果,考虑到疾病之间也存在潜在的联系,对于“多”对“多”情况下的研究是完全有必要的。
空间数据挖掘是从空间数据库中发现潜藏的、有趣空间模式的过程。一个空间共存(co-location)模式是一组空间特征(对象)的集合,它们的实例在空间中频繁地相关联,显然,它可以用来挖掘在空间中频繁相关联的不同疾病的组合。因此本文基于空间共存模式挖掘技术,结合模糊理论,提出了模糊共存度的概念,在数据处理阶段引入聚类的方法,最终提出了一种可以同时挖掘出多种疾病与多种潜在致病因素之间模糊关系的算法,并提出了相应的有效性度量方法,通过大量的实验分析,证明了算法是切实有效的。
2 相关工作介绍
1966年,Marinos发表模糊逻辑的研究报告,1974年,Zadeh发表模糊推理的研究报告,从此,模糊理论成了一个热门的课题,将数据挖掘与模糊理论相结合也成为了研究热点。文献[4]阐述了模糊关联规则挖掘的基本定义和一般模型,详细介绍了一般模型的一些应用;文献[5]提出了一种基于AprioriTid方法的模糊数据挖掘算法,该算法首先将数量型数据进行离散化,然后根据最大隶属度原则进行过滤,大大减少了挖掘时间;文献[6]提出了一种基于概率原理的不确定数据的表示方法,对于由于数据的不确定性所造成的一个模糊项对应多个支持度的问题,论文首次提出用支持度的均值来衡量模糊模式是否频繁,而模糊模式的频繁程度则用方差来描述;文献[7]提出了一种新的子组发现方法,利用动态规划算法发现模糊子组,该算法证明了动态规划与贪婪方法相结合的有效性,还展示了如何使用模糊逻辑来处理连续属性并生成高质量的模糊子组。
在空间模式挖掘与模糊理论相结合的研究中,也有一些研究成果。文献[8]研究了针对模糊对象的空间co-location模式挖掘问题,提出了两种新的挖掘方法SCP(single co-location pattern mining)和RCP(range co-location pattern mining),为了提高SCP方法挖掘的效率,对基本挖掘算法进行了优化,加快了co-location模式的生成,为了提高RCP的挖掘性能,提出了有效的剪枝策略来减少搜索空间,并通过大量的实验验证了所提算法和优化技术的有效性;文献[9-10]将模糊理论和聚类算法相结合,研究了空间co-location模式挖掘中的模糊挖掘技术,在对邻近度进行度量时引入了模糊的方法,提出了特征间的邻近度度量函数,利用模糊聚类的方法挖掘co-location模式。
文献[9-10]利用了模糊的挖掘方法,挖掘到了比传统方法更加丰富的信息,但得不到模糊的结果,文献[8]针对模糊对象进行挖掘,能得到模糊的结果,但其以“点”作为模糊对象,在衡量实例之间的影响时只考虑了邻近关系,这不符合绝大部分的应用场景,如,在衡量污染源对肿瘤的影响时,考虑到污染源会随空气、水流传播,污染源对肿瘤的影响绝不是简单的邻近关系。本文以区域为模糊对象,在衡量肿瘤对肿瘤的影响时使用邻近关系,在衡量污染源对肿瘤的影响时则考虑了用区域划分影响范围,采用了决策表提取规则的方法,挖掘得到的信息比以往的研究都更加丰富。
3 基本思想与挖掘框架
首先,本文想要挖掘恶性肿瘤与各种工业污染源之间的潜在联系。在这里,将肿瘤疾病的患病情况叫作决策属性D,工业污染源信息叫作条件属性C,条件属性与决策属性之间必定是空间相依的。例如,在化学需氧量(chemical oxygen demand,COD:以化学方法测量水中需要被氧化还原的物质的量)污染源附近出现了甲状腺肿瘤,但这种简单的“有”和“无”远远不能反映工业污染对肿瘤疾病的影响程度。为此,拟将条件属性、决策属性及它们之间的影响关系等进行模糊度量,同时,通过对研究区域的适当分区,分别基于真实数据计算各区域的患病率(用模糊值度量)和污染源的严重程度(也用模糊值度量),最后推导出肿瘤疾病患病率与工业污染之间的模糊关系。例如,模糊关系“COD排放量高→甲状腺肿瘤的患病率高(置信度=0.7)”。
基于上述基本思想,提出的挖掘框架如图1所示。输入的数据信息包括:(1)病患基本信息(决策属性),包括所患肿瘤、编号(患肿瘤的具体病例)和住址的经纬度信息,如(肺部恶性肿瘤,1(表示第一个病例),100.365,23.569 8);(2)工业污染源数据信息(条件属性),包括污染源主要排放的污染物以及排放地经纬度坐标信息,如(氨氮化合物,102.984 56,24.357 9)。首先,采用基于现有的行政区划的Voronoi图划分方法,对获取的数据进行区域划分,因为谈论某个人时是以“是哪里人”,而不是以经纬度进行描述,行政区划较好地划分了人们的生活空间。得到划分的区域后,就可以将肿瘤病患按区域进行分组,同时挖掘分区模糊共存模式,这样得到了各个区域的频繁共存的肿瘤疾病类型及其严重程度,结果形成了目标决策属性。对于条件属性(图1左列),基于工业污染源数据信息的区域划分结果,统计每个分区的污染源,采用聚类技术得到区域受各种类型污染的严重程度,形成模糊条件属性。最后,基于得到的模糊决策属性和模糊条件属性,采用决策表方法提取恶性肿瘤与工业污染源之间的模糊关系。
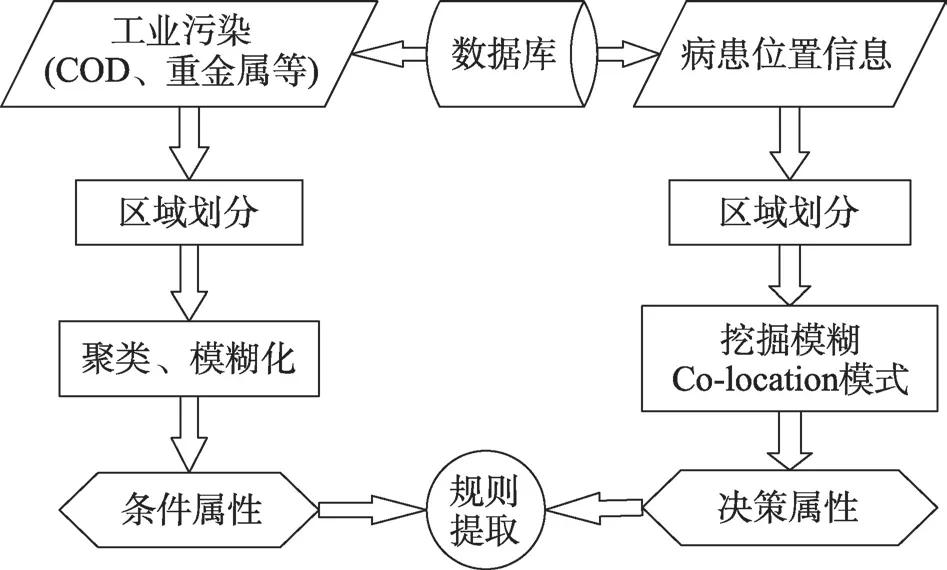
Fig.1 Basic framework of algorithm图1 算法基本框架
4 基于空间共存模式挖掘技术处理决策属性
4.1 空间特征及空间实例
空间特征(对象)代表了空间中不同种类的事物。空间特征集代表空间中不同种类事物的集合,记作F={f1,f2,…,fn}。把空间特征在一个具体空间位置上的出现称为空间实例。将实例的集合称为实例集,为了区别不同实例,给每个实例一个唯一的编号,于是一个空间实例信息通常包括<实例所属特征,实例编号,空间位置>。在本文中,将肿瘤疾病的类型看作特征,具体的一个肿瘤病患看作一个实例,特征集F={白血病,头颈癌,…,血液肉瘤},总共26种肿瘤疾病,将这26种疾病分别用26个英文大写字母表示,特征A的实例集{A1,A2,…,As}即为患肿瘤A的所有病患的集合。如图2是肿瘤疾病A、B、C和D的实例分布示意图。
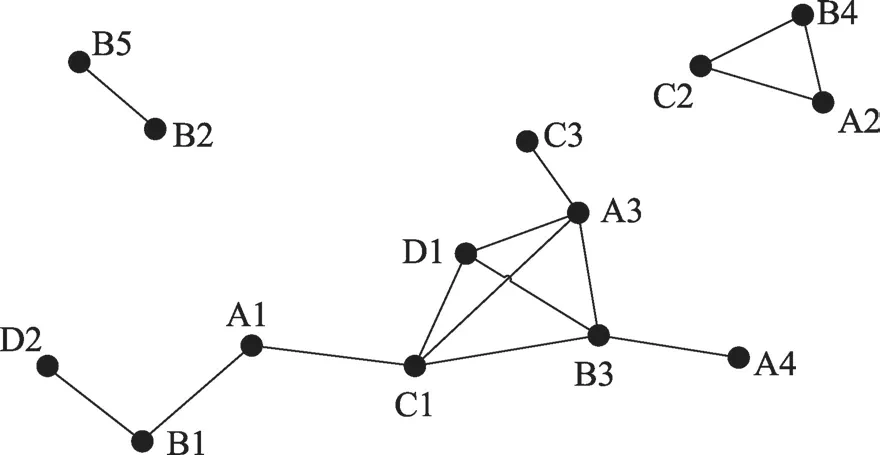
Fig.2 Example distribution of tumor diseases A,B,C and D图2 肿瘤疾病A、B、C和D的实例分布示意图
空间邻近关系描述了空间实例之间的一种空间关系。空间邻近关系可以是空间拓扑关系(相连、相交等)、距离关系(如欧几里德距离)等。空间邻近关系需要满足自反性和对称性。
若定义一个空间邻近关系R为欧几里德距离小于等于用户给定的阈值d,那么两个实例满足R时即可表示为:
R(A3,B3)↔(distance(A3,B3)≤d)
当两个空间实例满足邻近关系R时,称这两个实例为R邻近,在实例分布图中用线段将它们连接起来,如图2所示。
在本文中,当两个肿瘤病患实例满足R邻近关系时,称这两个病患为R邻近,其中距离阈值d一般视具体应用由用户设定(阈值d的讨论见第6章)。
若存在空间实例集I={I1,I2,…,Im},如果有{R(Ij,Ik)|1 ≤j≤m,1 ≤k≤m},则称I是一个团。团在带邻近关系的实例分布中表现为一个完全连通的子图。如图2中,{A3,B3,C1,D1}就是一个团。
一个co-location模式是一组空间特征的子集c,即c∈F。
一个co-location模式c的长度称为此co-location模式的阶,即co-location模式里空间特征的个数,记作size(c)=|c|。例如size({A,B,C})=3。
如果一个团I′中包含co-location模式c中的所有特征,并且I′中没有一个子集可以包含c中的所有特征,那么I′被称为co-location模式c的一个行实例,co-location模式c所有行实例的集合称为表实例。如图2中,团{A2,B4,C2}是co-location模式{A,B,C}的一个行实例,co-location模式{A,B,C}的表实例table_instance({A,B,C})={{A2,B4,C2},{A3,B3,C1}}。
在co-location模式挖掘中使用参与度[11]度量一个co-location模式的频繁(有趣)程度,在介绍参与度之前,先要引入参与率的概念。
设fi为某个空间特征,fi在k阶co-location模式c={f1,f2,…,fk}中的参与率表示为PR(c,fi),它是fi的实例在空间co-location模式c的表实例中不重复出现的个数与fi总实例个数的比率。如式(1):
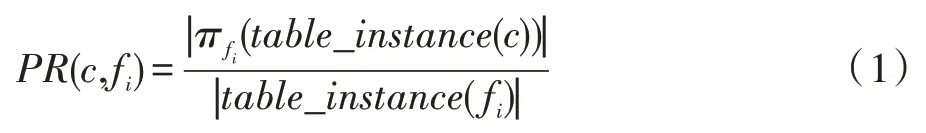
其中,π是关系的投影操作。
例1如图2,特征A有4个实例,特征B有5个实例,特征C有3个实例,特征D有2个实例,对于colocation模式{A,B,C},其表实例有{A2,B4,C2}和{A3,B3,C1},A的实例只有2个出现在表实例中,因此PR(c,A)=0.5,同理,PR(c,B)=0.4,PR(c,C)=0.667。
Co-location模式c={f1,f2,…,fk}的参与度表示为PI(c),它是co-location模式c的所有空间特征PR值的最小值。如式(2):

例2如图2,c={A,B,C},PI(c)=min{PR(c,A),PR(c,B),PR(c,C)}=0.4。
通常,由用户给定一个最小参与度(最小频繁性)阈值min_prev,当PI(c)≥min_prev时,就称co-location模式c是频繁的,c中特征的实例在空间中频繁相关联。
在本文中,将肿瘤疾病的类型看作特征,单个出现的肿瘤病患看作实例,则可以得到肿瘤疾病的频繁co-location模式,它表示在空间中频繁相关联的肿瘤疾病的组合。例如,{A,B,C}是一组疾病的频繁colocation模式,则表示A、B和C三种肿瘤疾病在空间中频繁共存。
4.2 模糊共存模式
针对本文的目标,得到频繁的co-location模式不足以表现肿瘤疾病共存的程度,因此提出模糊共存度的概念。
定义1(模糊共存度)对于一个频繁co-location模式c,用户自定义的阈值为p1、p2(min_prev<p1<p2),其模糊共存度μ(c)如式(3)所示:
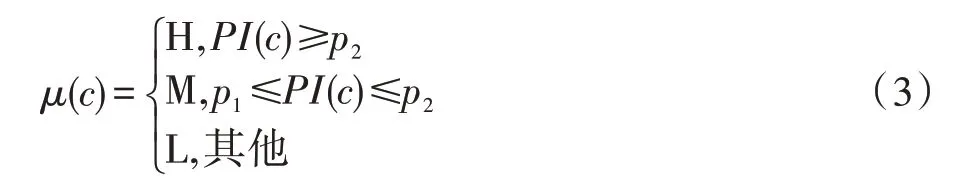
频繁co-location模式是通过参与度PI值度量的,一个模式c的参与度PI(c)大于等于最小参与度阈值时,称模式c为频繁co-location模式。从参与度的定义可以看出,参与度就是该模式在空间中共存的程度的一种度量,参与度值越大,共存的概率越高;相反,则共存的概率越低。因此,通过参与度值的范围具体划分了共存的程度,得到一种模糊co-location模式。
例3如图2,当频繁性阈值min_prev为0.3时,规定co-location模式c的PI值大于等于0.7时,μ(c)为H(高度共存);大于等于0.5但小于0.7时,μ(c)为M(中度共存);其余则为L(低度共存)。在如图2的例子中,PI({A,B,C})=0.4,因此模式{A,B,C}为一个低度共存的co-location模式,表示为{A,B,C}.L,PI({A,C})=0.75,co-location模式{A,C}是一个高度共存的co-location模式,表示为{A,C}.H。
传统的co-location模式挖掘得到的频繁co-location模式,只能反映一个模式是否频繁出现,而对于其频繁的程度一无所知,这导致频繁co-location模式无法反映肿瘤疾病的共存程度,而使用模糊共存度就可以做到。将肿瘤疾病的类型看作特征,单个出现的肿瘤病患看作实例时,模糊共存度H、M、L就可以用来表示共存肿瘤疾病的共存程度,若是从某一区域挖掘到的模糊co-location模式,则这种模糊度量可以反映该区域同时患这些疾病的广泛程度,如某一区域的co-location模式{A,B,C}的模糊共存度为H,则A、B、C三种疾病在该区域以很高的概率扎堆出现。
4.3 挖掘算法的选择
空间co-location模式的挖掘算法有很多,可以将其分为基于最小参与率的挖掘算法、基于最大参与率的挖掘算法和复杂模式挖掘算法三类。其中基于最小参与率的算法由于最小参与率概念的自然和向下闭合等性质被广泛研究,包括:(1)基于全连接的join-based算法[12],join-based算法在特征数较多和实例分布稠密时连接操作的开销很大;(2)partial-join算法[13],是一种基于部分连接的挖掘算法,其核心思想是空间实例的划分,目的是减少连接操作的计算量;(3)join-less算法[14],一种基于星型邻居扩展的无连接算法,在稠密型数据中,效率比join-based高。鉴于本文的肿瘤疾病数据在挖掘之前已进行了区域划分,肿瘤病患实例分布的稠密度也相当高,因此选择join-less算法进行相应的空间co-location模式挖掘。
5 条件属性处理、规则的提取及有效性度量
5.1 条件属性的模糊化
经过区域划分的各个区域的工业污染情况作为条件属性,条件属性的模糊化,就是要将每个区域,按其工业污染的严重程度,划分为不同的类(高、中、低)。一般能得到的数据包括污染源的位置和污染类型(重金属、COD等)。首先需要得到每个区域初步的污染情况,即统计各个区域所拥有的不同类型的污染源的数量。例如,区域1:COD为2,NOx为2,SO2为1等。在初步得到各个区域的污染情况后,进行污染情况的模糊化处理,模糊化即分类,聚类分析是很好的选择。
聚类分析根据在数据中发现的描述对象及其关系的信息,将数据对象分组。其目标是,组内对象相互之间是相似的,而不同组对象之间是不同的。这十分适合本文对于污染源数据信息的处理要求。
聚类也分不同的类型。划分聚类简单地将数据对象划分为不同的子集,如果允许簇存在子簇,就可以得到一个层次聚类;将每个对象指派到单个簇,则每个簇都是互斥的,一个对象只能属于一个簇,在某些情况下,一个对象可以属于多个簇,这种情况则可以使用非互斥聚类方法。
针对已经事先知道了聚类的簇数以及污染数据划分的、互斥的属性,经典的K-means聚类算法是一种很好的方法,但K-means聚类算法的结果易受随机选择的初始聚类中心的影响,这对挖掘的结果造成了很大的不确定性。在使用多种改进型K-means聚类算法对污染数据进行实验分析后发现,二分K-means算法的聚类效果最好。将二分K-means算法作为污染数据的聚类算法,污染源数据总共聚成三类,污染源数量较多的一组为“高污染源”组,污染源较少的一组为“低污染源”组,剩下一组为“中污染源”组。
5.2 规则提取
现在,已经得到了每个分区的决策属性(即疾病的类型组合及其组合的共存程度)和条件属性(即污染的严重程度),二者生成决策表,如图3(a)所示。在决策表中,每一行都对应一个区域。其中,对于相似污染情况的区域,如果所患的疾病类型的组合及其共存程度也很相似的话,提取公共规则并计算其置信度。具体定义如下:
定义2(置信度)在决策表中,区域i的决策属性为ti,条件属性为si,对于任意t∈D,s∈C,(s→t)的置信度计算如式(4):
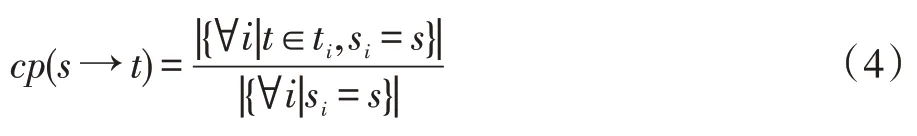
定义3(规则提取)对于任意t∈D,s∈C,如果cp(s→t) 大于等于一个给定的最小置信度阈值min_conf,那么模糊规则(s→t)称为强规则。
基于决策表提取模糊强规则的算法:

例:具体过程如图3所示,聚类得到有5个区域条件属性同为(COD.H,SO2.M,NOx.H),在这5个区域中,4个区域有{A,B,C}.H,2个区域有{L,M,O}.L,则:
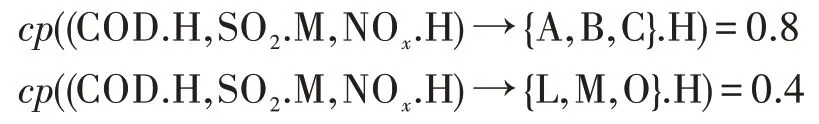
若设min_conf=0.5,则(COD.H,SO2.M,NOx.H)→{A,B,C}.H,cp=0.8就是一条强规则。规则表示当一个区域的3种污染源分别满足COD为高污染源,SO2为中污染源和NOx为高污染源时,则3种疾病A、B、C一起出现的概率为高,置信度为0.8。
5.3 规则的有效性度量
提取出规则后,还需要一个参数衡量规则是否与客观事实相符合,是否具有有效性。
规则反映了肿瘤实例与污染源在地理空间上是否存在高度关联,而衡量空间中的关联性,主要有两个指标,肿瘤实例与污染源的聚集程度及肿瘤实例与污染源的数量N。聚集程度用平均误差平方(average of square error,ASE)度量,如式(5):
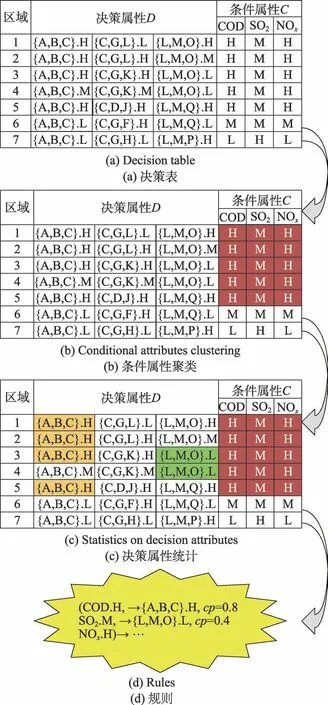
Fig.3 Rule extraction process图3 规则提取过程
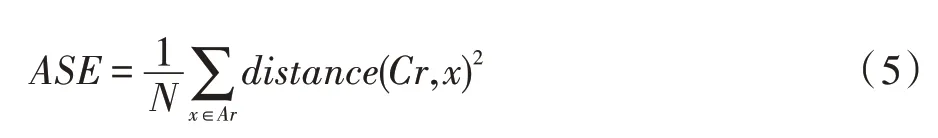
其中,Ar为区域内规则所涉及到的肿瘤实例与污染源集合,distance是标准欧几里德距离,Cr是Ar内所有点(肿瘤实例和污染源)的质心,由式(6)定义:

ASE越小,则说明Ar内肿瘤实例与污染源的聚集程度越高。除了ASE外,还需要看数量N,当N很小时,聚集程度也不能反映肿瘤疾病及污染源的关联度。最后,综合ASE与N,用SDC(severity of disease and contamination)同时衡量肿瘤实例和污染源的聚集程度和数量,如式(7)所示,SDC越小,则肿瘤和污染的聚集度越高,同时关联度也越高。

反映高关联度的规则,其SDC值必然相对较小,反之亦然。对于挖掘得到的规则,若规则所反映出来的关联度与计算得到的SDC值相符合,则该规则就具有有效性。
6 实验及分析
6.1 Voronoi图分区及实验数据
实验数据(包括肿瘤病例数据和污染数据)来自云南省一些医院和相关部门,实验数据参数说明如表1所示。以云南省县区级行政单位的中心点为Voronoi图原点进行区域划分。划分结果如图4所示。

Table 1 Description of experimental data parameters表1 实验数据参数说明
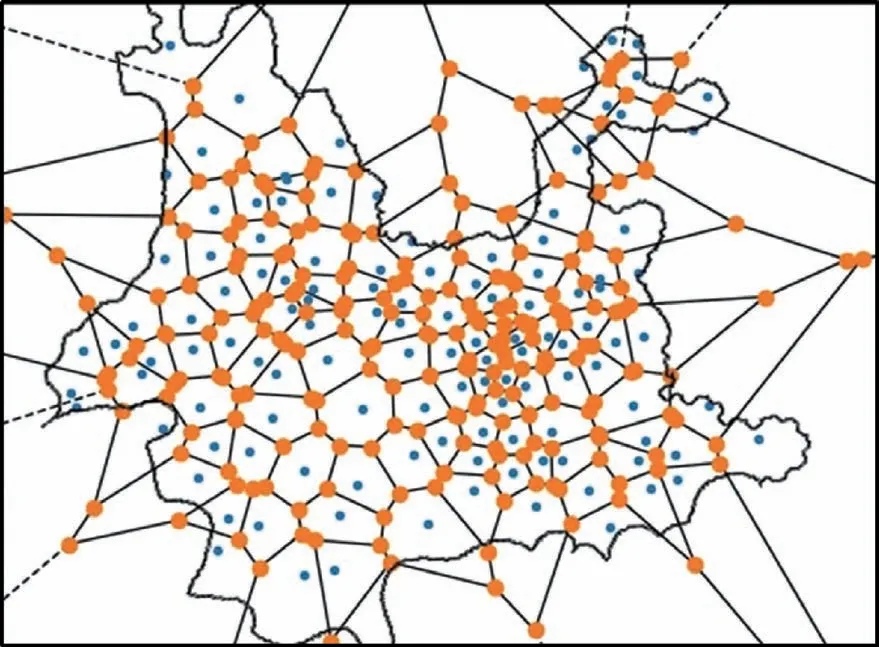
Fig.4 Region division based on Voronoi diagram图4 Voronoi图区域划分
(1)决策属性数据
首先将肿瘤病患实例投影到Voronoi图对应的区域内,每个区域所拥有的肿瘤病患个数示例如表2所示。
按区域将肿瘤病患实例分组后,接下来就可以按分区挖掘co-location模式了。对于co-location模式挖掘所需的两个参数(参与度阈值min_prev和距离阈值d),参与度阈值需要用来度量co-location模式的共存程度,假定参与度大于等于0.6的模式为高共存模式(H),大于等于0.4小于0.6的为中共存模式(M),大于等于0.2小于0.4的为低共存模式(L)。而对于距离阈值d,根据每个区域的不同人口密度来设置不同的距离阈值,众所周知,人口密度大的区域,其病患也相对集中,距离阈值设置应相对较小,而人口密度小的区域,病患比较分散,其距离阈值则应相对较大,否则就得不到人口密度小的区域的co-location模式。各区域距离阈值的具体计算如式(8)所示:

Table 2 The number of tumor instances in region表2 分区肿瘤病患实例数

其中,pi、di分别是区域i的人口密度和距离阈值,pave是所有区域平均人口密度,dave是经过实验分析得到的pave情况下的最佳距离阈值。
实验中各个区域的人口密度和距离阈值的设置如表3所示。最后得到的各区域中共存疾病类型组合及其共存率如表4所示,大写字母表示肿瘤疾病的类型。
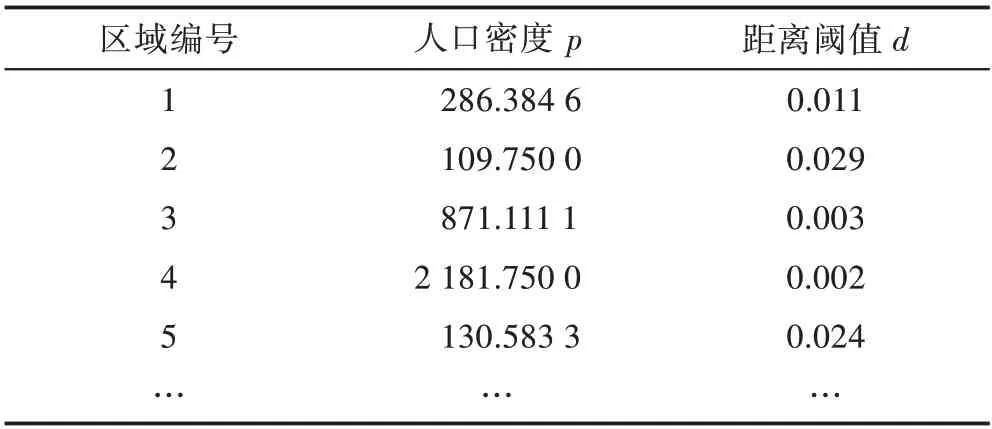
Table 3 Regional population density and distance threshold setting表3 区域人口密度及距离阈值设置

Table 4 Combination of co-location diseases and their degrees表4 共存疾病类型组合及其共存度
(2)条件属性数据
本文所用的污染源数据来自《2016国家重点监控企业名单》,从中选取了位于云南省的企业,包括6种污染类型(COD、NOx、SO2、氨氮、重金属、危险废物)。统计各区域的污染源类型及数量,结果如表5所示。再运用二分K-means聚类算法分别将每种污染源类型按数量聚成3类(H,M,L),结果如表6所示。
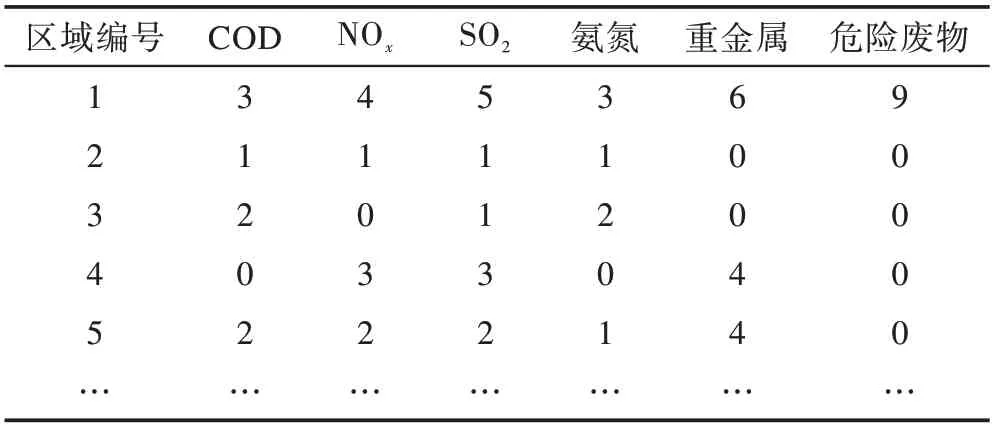
Table 5 Types and quantities of pollution sources in each region表5 各区域污染源类型及其数量

Table 6 Types and degrees of pollution sources in each region表6 各区域污染源类型及污染程度
6.2 挖掘结果及分析
对表6中的数据再次进行聚类,聚类得到的簇,其内部所有区域的污染类型的严重程度都相同,这就表示簇内区域具有相似的工业污染情况,至于相应的患病情况如何,则需要看表4。例如,有4个地区满足(COD.L,NOx.L,SO2.L,氨氮.L,重金属.M,危险废物.L),其中有3个区域满足{白血病,头颈癌,胆部恶性肿瘤}.M,则cp((COD.L,NOx.L,SO2.L,氨氮.L,重金属.M,危险废物.L)→{白血病,头颈癌,胆癌}.M)=0.75。
根据所感兴趣的内容,可以从中提取出不同的规则,比如,如果想得到那些污染与高患病率之间的模糊关系,则可以得到以下规则:“(COD.L,NOx.L,SO2.L,氨氮.L,重金属.H,危险废物.L)→{头颈癌,肠部恶性肿瘤,多系统恶性肿瘤,腹部恶性肿瘤,肝部恶性肿瘤,卵巢癌,皮肤恶性肿瘤,乳腺恶性肿瘤,胸部恶性肿瘤}.H,cp=1”(记为规则1)。该规则表示重金属污染与头颈癌等多种疾病的关联度为高,对应的区域42的实例分析如图5所示,其SDC(42)=0.000 083。
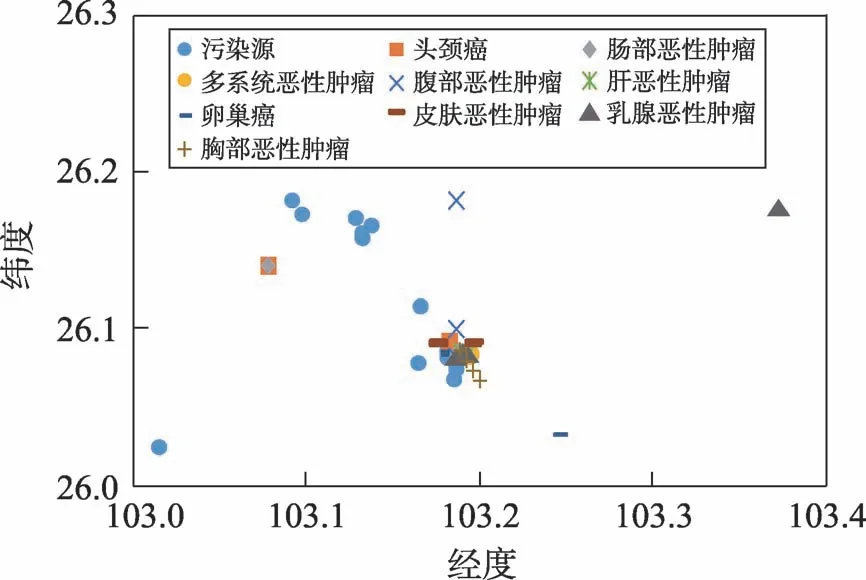
Fig.5 Tumor instances and pollution sources distribution in Region 42图5 区域42中肿瘤实例和污染源分布图
再看一条规则“(COD.L,NOx.M,SO2.L,氨氮.L,重金属.L,危险废物.L)→{白血病,胆部恶性肿瘤,骨恶性肿瘤,肢体恶性肿瘤,泌尿系统恶性肿瘤,脑部恶性肿瘤}.M,cp=1”。该规则表示NOx污染与白血病、胆部恶性肿瘤等多种疾病的关联度为中,对应区域66,如图6所示,计算得到SDC(66)=0.000 78。SDC(42)小于SDC(66),可知区域42的肿瘤实例与污染源的关联度要比区域66高,这与得到的规则相符合,本文算法挖掘得到的结果可以反映真实世界的客观规律。
6.3 效率分析
(1)实验分析
实验采用的计算机配置:Intel®CoreTMi7-8700K CPU@3.70 GHz,16 GB内存;操作系统Windows 10;开发语言Python。
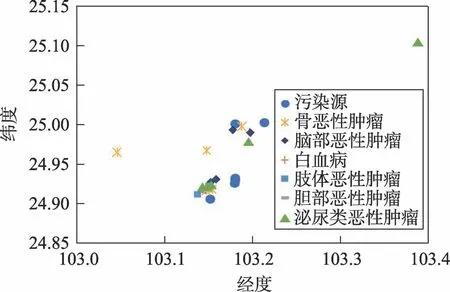
Fig.6 Tumor instances and pollution sources distribution in Region 66图6 区域66中肿瘤实例和污染源分布图
实验所用的模拟数据是随机产生的,均匀分布在经度97至107、纬度20至30的空间中。
接下来将分析不同参数对算法运行时间的影响。
由于污染源在数量上与肿瘤病例相去甚远,算法的时间消耗主要在肿瘤病例的共存模式挖掘中,因此主要探索肿瘤实例个数对算法运行时间的影响,如图7所示,随着肿瘤实例数的增长,算法的运行时间呈增加趋势。
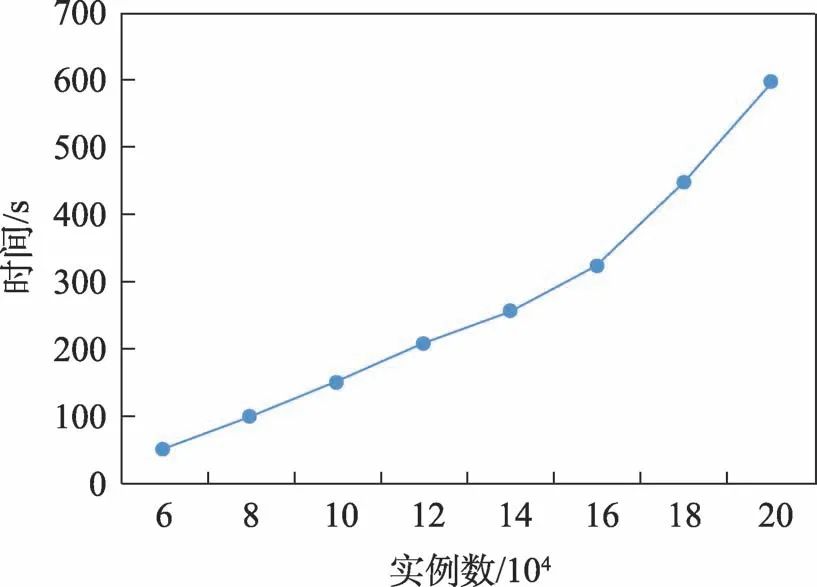
Fig.7 Influence of the number of instances on running time图7 实例个数对算法运行时间的影响
本文采用分区挖掘肿瘤的共存模式,不同区域由于人口密度的不同,距离阈值的设置也不同,通过在预先设置好的距离阈值(如表3所示)的基础上增加或减小距离阈值来探索距离阈值对算法运行时间的影响,如图8所示。可以看出,在设置的距离阈值的范围,算法的运行时间变化不大,但当距离阈值增加到一定的值时,算法运行时间开始急剧上升。
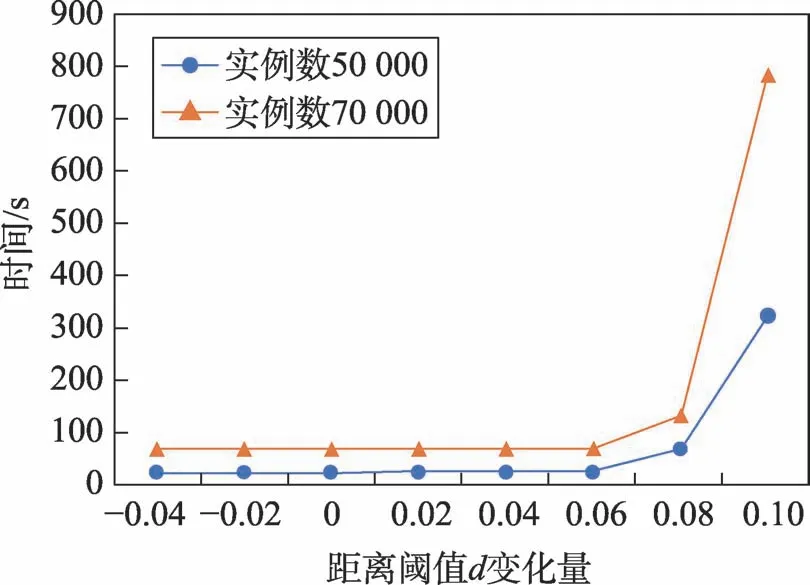
Fig.8 Influence of d on running time图8 距离阈值d 对算法运行时间的影响
参与度阈值对算法运行时间的影响如图9所示,算法运行时间并没有随着参与度阈值的变化而呈现出明显的变化趋势,可以得出,算法运行时间与参与度阈值的设置关联不大。
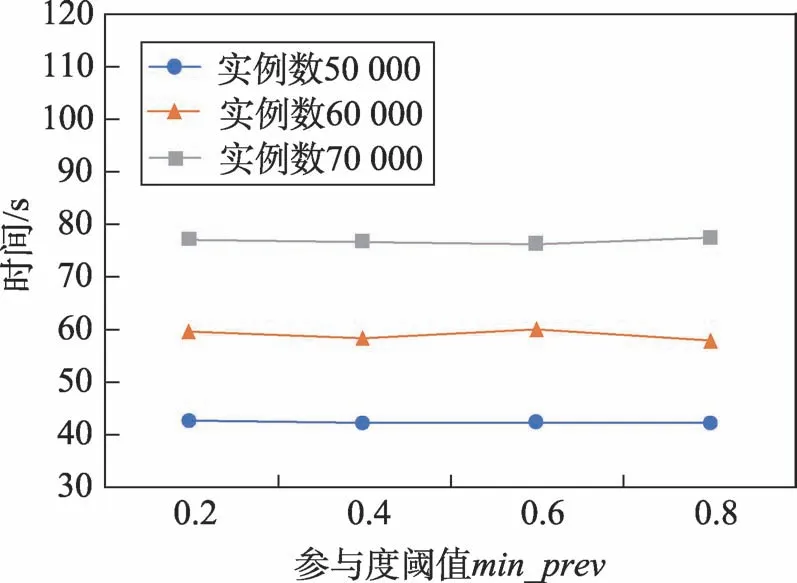
Fig.9 Influence of min_prev on running time图9 参与度阈值对算法运行时间的影响
特征个数,即所挖掘肿瘤疾病的种类个数,特征个数对算法运行时间的影响如图10所示,特征个数对算法运行时间的影响也不大。
(2)理论分析
本文算法主要分为三部分:co-location模式挖掘、二分K-means聚类、规则提取。下面针对这三部分进行时间复杂度分析。
挖掘co-location模式使用了join-less算法[14],join-less算法又可分为三步:生成星型邻居集、生成二阶频繁co-location模式及生成k(k>2)阶频繁模式。因此,用join-less算法挖掘频繁co-location模式总的时间复杂度Tjl为:
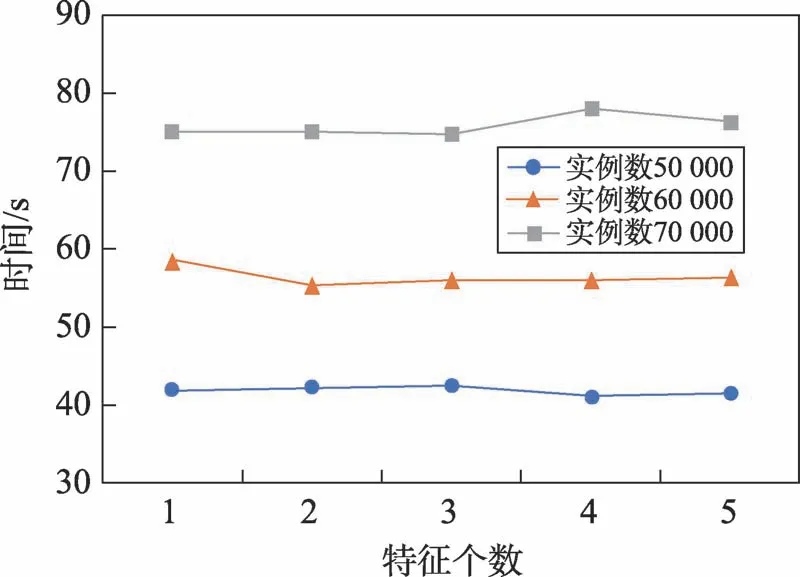
Fig.10 Influence of the number of features on running time图10 特征个数对算法运行时间的影响
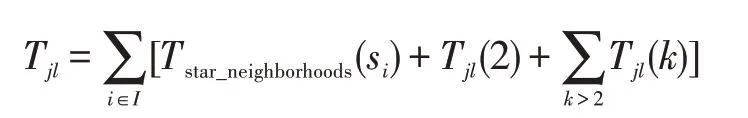
I为划分区域的集合,si为隶属于i区域的实例的集合,Tstar_neighborhoods(si)表示产生星型邻居的耗费,Tjl(2)为产生2阶co-location模式的耗费,则是生成k阶模式的耗费。
在传统的co-location模式挖掘中,挖掘的实例数越大,算法的时间耗费必然越大;当距离阈值增加时,生成的二阶频繁co-location模式的表实例数量就会增加增加,总的时间耗费也必然增加,这与本文的实验结果相符合,如图7、图8所示。当参与度阈值减小时,生成的频繁co-location模式数会增多,模式长度也会变长,增加,从而造成运行时间增加;而当特征数增多时,邻近关系的计算量增加,Tstar_neighborhoods(si)阶段的运行时间增加,生成co-location模式的数量和阶数也会增加,增加,从而导致整体运行时间变长。但是在本文的实验结果中,算法运行时间与参与度阈值和特征个数的关系不大,如图9和图10所示,造成这个结果的原因是本文算法在挖掘co-location模式之前进行了区域划分,按分区挖掘频繁co-location模式,总体的特征数增加,但在局部区域内的特征个数变化不大,特征个数对算法运行时间的影响也变小了;同样的,在采用分区挖掘后,每次挖掘的实例数都不多,无论参与度阈值如何变化,生成的colocation模式数都较少,其长度也相对较短,对总的运行时间的影响微乎其微。
二分K-means算法的时间复杂度是适度的,只要簇个数|V|显著小于点数m,则K-means算法的时间与m线性相关,所需时间为O(J×|V|×m×n),其中J是收敛所需的迭代次数,在用聚类的方法对污染源数据进行模糊化时,属性n为1,m为区域数,聚类生成的簇数|V|为3,因此所需时间为O(J×m)。
在进行规则提取时,首先进行聚类,聚类的属性个数即为污染类型的个数,所需时间为O(J×|V|×m×n),接下来遍历聚类得到的每一个簇,统计簇内相同的决策属性,计算置信度。最终,规则提取总的时间复杂度Trule为:

其中,V为聚类生成簇的集合,m为区域数,n为污染源的类型数,Tsc(v)为统计每个簇相同的决策属性所需的时间。
综上,整个算法总的时间耗费T为:
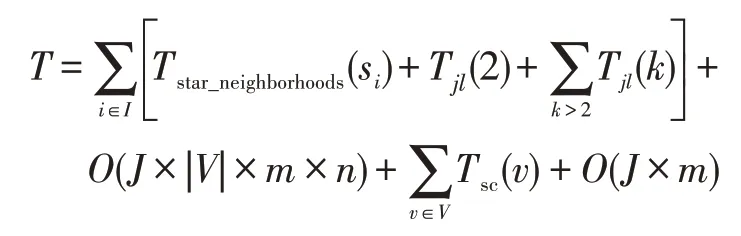
其中,针对肿瘤实例挖掘频繁co-location模式阶段是算法中最耗时的部分,后面的二分K-means聚类、规则提取主要是针对区域进行操作,区域数要比肿瘤实例数少得多,时间耗费也相对小得多。
7 结束语
传统的空间模式挖掘用邻近关系度量污染源与疾病的关系,忽略了污染源随空气、水源传播的影响,文献[15]考虑了空气、水流的影响,但导致算法太过复杂。而本文引入了区域划分方法,将污染源的影响范围扩大到整个区域,同时使用模糊理论度量污染程度、肿瘤共存程度,挖掘出了比传统的空间模式挖掘更加丰富的知识,更能反映真实世界的客观规律。
当然,本文也存在不足,在模糊度量和距离阈值的设置上依赖专家给出的建议,人为因素影响较大,下一步的工作将致力于实现从数据分布中直接得到模糊隶属度阈值和距离阈值,减少人为的影响。
猜你喜欢
环境影响评价(2020年2期)2020-12-02 01:23:24
环境保护与循环经济(2017年4期)2018-01-22 03:27:18
中国资源综合利用(2017年4期)2018-01-22 02:46:45
电子测试(2017年15期)2017-12-18 07:19:27
中学生数理化·八年级物理人教版(2017年12期)2017-04-18 12:59:46
智能系统学报(2015年4期)2015-12-27 09:38:39
电子设计工程(2015年6期)2015-02-27 12:04:53
高中生学习·高三版(2014年3期)2014-04-29 06:11:18
高中生学习·高三版(2014年3期)2014-04-29 06:10:49
华东师范大学学报(自然科学版)(2014年6期)2014-02-27 13:40:55
