
动态外观模型和高阶能量的双边视频目标分割方法*
2020-12-15 08:13熊达铭
计算机与生活 2020年12期
田 颖,桂 彦,熊达铭
1.长沙理工大学计算机与通信工程学院,长沙410114
2.长沙理工大学综合交通运输大数据智能处理湖南省重点实验室,长沙410114
1 引言
视频目标分割是从视频中分割出用户感兴趣的目标对象,即把所有像素点划分为具有外观、运动等相关的前/背景时空区域,且是许多高级视觉应用的先决条件,如目标检测、视频检索、安防监控、影视后期制作和智能交通等。通常,不同场景下的视频可能包含相近似前/背景区域、物体遮挡、剧烈运动、模糊边界、相机抖动、光照变化、动态阴影和水流等,这些复杂现象将导致视频目标分割方法产生时空不一致的结果;且视频具有数据量大的特点,分割时间效率低下。因此,如何实现一种快速且高精度的视频目标分割方法就显得尤为重要。
现有视频目标分割方法主要分为全自动视频目标分割方法[1-16]和交互式视频目标分割方法[17-30]两大类。前者通常利用基于光流的特征点/区域跟踪[4-10]、目标建议区域[11-16]等自动估计视频中的目标对象,再通过聚类[4-11]、动态规划求解[14]、图割优化[1-3,31]等进行问题求解。该类方法能够很好地处理具有简单背景、目标对象运动显著的视频目标分割,但在目标对象估计不准确时是失效的。交互式视频目标分割方法则需要用户提供适量的交互信息,并以此作为“硬”约束条件,从而产生符合用户交互的视频目标分割结果。对于具有复杂场景视频的处理,该类方法则需要提供大量的用户交互以获得满意的分割结果,这将导致整体时间效率急剧下降。
为了进一步解决视频目标分割质量和时间效率低下等问题,本文提出一种动态外观模型和高阶能量的双边视频目标分割方法。首先,将带标记的视频序列映射到高维的双边空间,减少待处理的视频数据。然后,以非空的网格单元作为图的结点并构建图割优化模型,通过构建置信动态外观模型,准确地估计各像素点属于前/背景的可能性;并在能量函数中引入高阶能量项,增强不相邻但具有相似外观特征结点的时空相关性。最后,利用最大流/最小割算法[32]求解能量函数,实现视频像素点的标签分配。由此,本文方法能够很好地消除不利因素对分割的干扰,并且能够快速且高精度地处理具有复杂场景的视频目标分割。
2 相关工作
2.1 全自动视频目标分割方法
全自动视频目标分割方法[1-16]在无需人工干预下即可自动跟踪和分割视频目标对象。文献[1-3]首先根据外观和运动信息确定目标对象,再利用图割算法求解,但这些方法需要利用连续两视频帧间的运动信息,不能很好地处理静止目标对象的情况。而基于特征点/区域跟踪的方法[4-10]利用光流法对特征点/区域进行跟踪,将聚类的点/区域轨迹作为先验信息,并基于时域轨迹建模以实现视频目标分割。然而,这些方法在聚类时忽略了点/区域轨迹的全局运动信息,从而难以确定待分割的目标对象。文献[11-16]利用目标建议区域将视频目标分割转换成区域选择问题。这些方法是逐视频帧分割目标建议区域的,忽略了视频帧间的连续性,从而导致视频目标分割质量低下。此外,在处理具有物体遮挡和剧烈运动等复杂场景的视频时,上述方法通常难以准确地估计目标对象的形态和位置,从而容易导致视频目标的过度分割,又或产生不准确的视频目标分割结果。
2.2 交互式视频目标分割方法
交互式视频目标分割方法[17-30]通过在一帧或多帧关键帧中标注前景和背景区域以用于指导视频目标分割。该类方法通常适用于不要求实时性但对视频目标边界精度要求较高的应用,且是目前用于视频目标分割最常见的方法。
其中,基于关键帧前向传播的方法[17-22]在于正确跟踪视频序列中目标对象的轮廓,并保证视频目标分割结果的时空连续性。Agarwala等[17]提出根据用户交互跟踪视频目标对象边界的技术。Bai等[18]在目标边界处定义重叠的局部分类器,能够准确地捕获视频目标对象轮廓的变化。进一步增强颜色模型,Bai等[19]通过将运动估计结合到颜色建模中,再根据运动的局部属性自适应地调整模型参数。上述这两种方法都需要假设目标对象在视频序列中连续且运动平滑。Zhong等[20]利用多方向的局部分类器处理视频目标在时域上不连续的问题,但该方法对于具有复杂拓扑形状的目标对象难以确定分类器窗口的大小。Fan等[21]利用掩膜传播及双向运动插值实现视频目标分割。Lu等[22]提出参数化目标轮廓并定义图割能量优化模型的方法,提高目标边界的空间精确度和时间稳定性。然而,上述方法通常需要借助局部分类器跟踪视频目标区域,因此这些方法在部署、训练分类器时需要消耗较长的时间。此外,这些方法侧重于利用颜色、运动等特征实现视频目标分割,对于包含剧烈运动、前/背景颜色相似等复杂环境视频的分割效果不理想。
基于图割优化的视频目标分割方法[23-30]需要将视频数据构建为图结构,从而将视频目标分割转化为求解图的最大流/最小割问题。其中,Wang等[23]采用层次化的均值漂移算法将视频像素点聚合成二维和三维区域,以此减少待计算的图结点数量。同年,Li等[24]在相邻视频帧之间构建三维图割模型,用以保持分割结果的时空连续性。这两种方法都是利用颜色特征实现视频目标分割,且都过度强调分割的精度而忽略了时间效率。Tsai等[25]利用多标签的马尔可夫随机场(Markov random field,MRF)图结构表示视频数据,且同时进行视频目标的分割和运动估计。Jain等[26]基于时空超像素定义MRF图割模型,并引入高阶项进行软约束。Nagaraja等[27]利用光流获取像素点的时序轨迹信息并约束运动和颜色的时空一致性,以达到少量用户交互下高质量的视频目标分割。Tsai等[28]提出同时进行视频目标分割和光流估计的方法,但该方法计算复杂度较大。Marki等[29]首次提出了在双边空间进行视频目标分割,通过利用规则时空双边网格的顶点定义能量函数。针对视频中出现的遮挡、前/背景颜色相似等情况,Chen等[30]提出自适应扩大局部采样范围的方法,通过构建前景外观模型并结合运动估计的图割模型,以保证分割结果时空的平滑性。然而,该类方法容易受到杂乱的背景、噪声以及目标边界像素点的影响,且影响因素的变化会导致已分割目标对象边界的抖动,大大降低了分割结果的精度。
近年,随着深度学习在目标检测领域中的应用,其也逐渐用于解决视频目标分割问题。Perazzi等[33]提出将静态图像作为网络的输入训练卷积神经网格实现视频目标分割。Cheng等[34]提出利用卷积神经网络(convolutional neural network,CNN)联合估计光流和目标对象,并提供运动特征以产生跨时空的运动一致性分割。Bao等[35]提出在MRF图割模型中嵌入卷积神经模型的方法解决视频目标分割问题。Wang等[36]改进了全卷积孪生跟踪器以生成目标对象的二值分割,该方法虽然分割速度快,但是分割效果不佳。
3 基于双边网格鲁棒的视频目标分割方法
3.1 算法概述
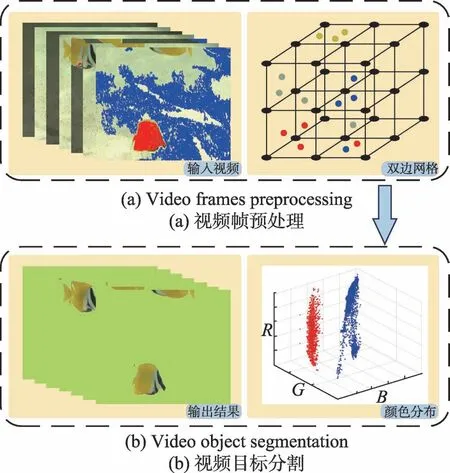
Fig.1 Overview of proposed method图1 本文方法的总体框架
本文方法的总体框架如图1所示,主要包括两个阶段:(1)高效的双边网格视频预处理;(2)快速且鲁棒的视频目标分割。给定一个视频序列,视频预处理阶段的主要任务是将带关键帧标记的视频序列的每一像素点映射到规则的高维双边网格中(图1(a))。而在视频目标分割阶段中,结合二义颜色判别准则,构建置信动态外观模型,并在传统的能量函数中进一步引入高阶项。通过采用最大流/最小割算法进行全局优化求解,以实现快速且高质量的视频目标分割(图1(b))。需要指出的是,本文采用的是六维的双边网格,但为了更好地说明和展示,图1中仅给出了三维的双边网格。
3.2 高效的双边网格视频预处理
本文方法首先需要提供用户交互信息作为待分割视频目标的先验信息。通常,以20帧为间隔选取多个关键帧,并采用交互式的图像分割方法[37-38]获得关键帧的精准分割结果,如Lazy Snapping[37]和Grabcut[38]。类似于目标快速选择工具,用户只需在关键帧中手动地对前/背景区域进行粗略标记,通过自动传播像素点的标记信息,即自动地标记所有颜色差异小于给定阈值的相邻未标记像素点,从而极大地减少用户交互的工作量。对于关键帧分割结果中产生的错误分割区域,本文允许用户进行手动校正以确保关键帧分割结果的精确度。此外,本文允许直接提供关键帧的真值图像(ground truth,GT)作为视频目标分割的先验信息,不仅免去用户交互过程,且能为视频目标分割提供准确的先验信息。
在标记关键帧之后,依据每一像素点的RGB颜色值以及时空坐标,将带关键帧标记的视频序列的每一个像素点p=[x,y,t]T映射到六维双边特征空间B=[cr,cg,cb,x,y,t]T∈R6。其中,前三维(cr,cg,cb) 表示(R,G,B)颜色值,(x,y)对应每一像素点的二维空间位置坐标,最后一维t表示视频的时间坐标。通过在每一维度上设置采样率,即指定颜色值轴的采样率sr,空间坐标轴的采样率ss和时间坐标轴的采样率st,对高维特征空间进行规则的划分,从而获得双边网格Γ。由此,通过设定合适的采样率,每一像素点p对应的双边网格单元vi可由式(1)计算得:
Γ([cr/sr],[cg/sr],[cb/sr],[x/ss],[y/ss],[t/st])+=(I(x,y,t),1)(1)
其中,[·]是向下取整操作,用来计算网格单元的坐标;齐次坐标(I(x,y,t),1)用来统计每一个网格单元vi的累积颜色值和像素点的数目;I(x,y,t)用来表示视频中每一像素点p的颜色值。直观地,网格单元的数量与每一维度的采样率成反比,且非空的网格单元数目远小于视频像素点的数目。为了后续图割模型优化,还需要计算每一网格单元的颜色值ci=。其中,是网格单元vi中第j个像素点的颜色值,Ni是网格单元vi的像素点总数目。需要注意的是,为空的网格单元不需要计算其颜色值,且不用于后续分割过程的计算。
实际上,视频像素点映射到双边网格单元的过程是对视频像素点的聚类。然而,当视频具有前景/背景相似、物体运动剧烈以及物体遮挡等复杂场景时,部分网格单元中可能会同时存在已标记的前景和背景像素点,如图1(a)所示,这些网格单元为具有冲突的网格单元。本文将重置这些网格单元中所有像素点为未标记的像素点,避免由标签冲突导致的错误分割。此外,本文根据网格单元中包含已标记像素点的情况,在双边网格中确定前景、背景种子点集。具体而言,当网格单元内已标记的前景像素点数目大于等于当前网格像素点总数目的一半时,即满足,该网格单元则视为前景网格单元。其中,表示网格单元vi中已标记的前景像素点数目。类似地,可确定背景网格单元。这些前景、背景网格单元分别构成前景种子点集Sf和背景种子点集Sb。值得注意的是,已明确标记为背景的网格单元将不用于后续计算。
3.3 快速且鲁棒的视频目标分割
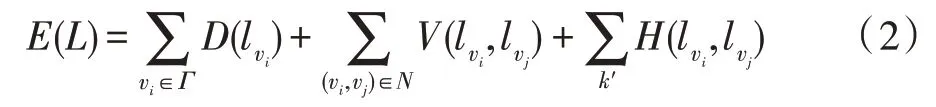
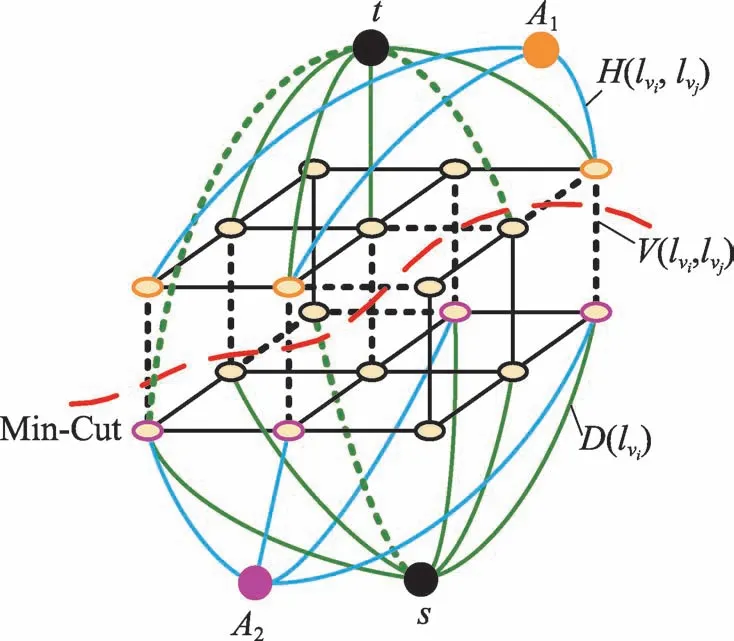
Fig.2 Graph-cuts optimization图2 图割最优
另外,本文需要将所有网格单元的标签值分配给网格单元内的像素点,即所有像素点的标签值与其所在网格单元的标签值一致,以获得最终的视频分割结果。然而,部分网格单元中可能存在前景、背景像素点被映射到同一网格单元的情况,此时这些网格单元中的部分像素点将被分配错误的标签值,这些错误分割的像素点可以看作是图割问题求解后产生的噪声。本文采用简单的中值滤波操作消除这些噪声,进一步优化视频目标分割结果。
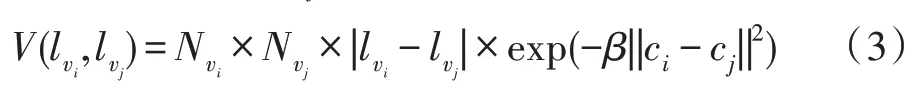
其中,Nvi是网格单元vi中像素点的总数目,用于描述该网格单元的贡献程度;||ci-cj||计算相邻两个网格顶点之间的颜色差异;是一个常量,其中表示视频序列中样本的期望值。需要注意的是,由于相邻网格单元的颜色值往往是非常相似的,计算得到的平滑项数值都较大且比较接近,因而平滑项能够鼓励为直接相邻的网格单元分配相同标签。此外,当采样率设置成sr=256,ss=1和st=1时,该平滑项V(lvi,lvj)等同于基于像素点的计算方式。另外,本文主要集中讨论如何提高视频目标分割的质量和时间效率,即本文通过构建置信动态外观模型以提高数据项的精度,并利用相距较远但具有相似外观特征的网格单元之间的时空关系定义高阶项。下面章节中将详细地给出这两项能量项的定义。
3.3.1 置信动态外观模型的数据项定义
数据项用于估计每一结点分配为前景或背景的可能性,其精度将直接影响视频目标分割结果的质量。考虑到前景、背景的外观是随着网格时间层平滑变化的,本文利用所有非空网格单元为每一时间层tl∈Γt分别构建前景外观模型和背景外观模型,其中Γt是双边网格的时间维度。所有时间层的前景(背景)外观模型构成动态前景(背景)外观模型Pf(Pb)。
具体地,当利用所有非空网格单元估计某一时间层tl的前景外观模型时,由于这些网格单元相对于当前时间层tl的位置远近和其属于前景的可能性是不同的,因此需要计算每一网格单元vi的权重,以根据其平均RGB颜色值训练前景的加权高斯混合模型:

而属于背景的可能性即为1-P(vi)。
然而,由于本文仅根据网格单元的颜色值构建动态外观模型。当存在用户交互不足、前/背景颜色相似的情况时,已构建的动态外观模型不能很好地拟合前/背景颜色分布,这使得估计的未标记网格单元属于前/背景的可能性是不可靠的,最终导致低质量的分割结果。为了解决上述问题,本文进一步定义置信的颜色判别准则,通过识别不可靠的属于前/背景的可能性,以适应不同形式的用户交互输入。

3.3.2 鲁棒高阶项的定义
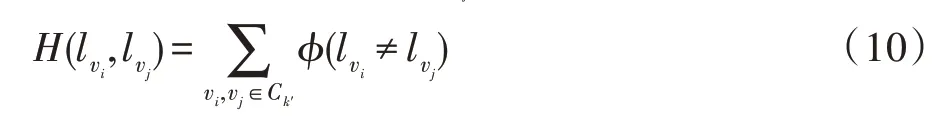
其中,φ(·)是一个指示函数,用于描述簇中任意不重复的结点分别与其辅助结点的连接,是第k′个簇的集合。
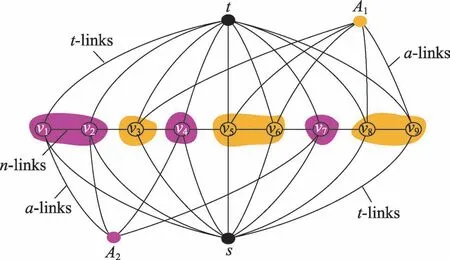
Fig.3 Illustration for graph structure with higher-order term图3 高阶项的图结构示意图
由于本文高阶项只需为每一个簇分配一个辅助结点,因而不会产生具有复杂拓扑的图结构。此外,本文将该高阶项作为一个“软”约束,使得能够为不相邻但具有相似特征的结点分配一致的标签,但不严格地要求为同一簇中的结点分配一致的标签。这是由于并非所有通过聚类获得的结点簇的质量都是足够好的,若强制对簇内的结点分配一致标签往往容易出现错误。此时,当质量不佳的簇内的网格顶点被分配不一致的标签时,该高阶项具有较高的代价。由此可见,引入高阶项并没有产生复杂的图结构且不强制为同簇结点分配相同的标签,保证了分割时间效率的同时也改善了视频目标分割的质量。
4 实验结果分析与讨论
本文在Intel®CoreTMi5-7400 3.00 GHz处理器、8 GB内存的PC机环境下,使用VS 2015和OpenCV3.1.0等开发工具进行相关实验。首先,在视频预处理、概率图、有无高阶项及不同用户交互四方面验证本文方法,并探讨这些方面对实验结果的影响。然后,在DAVIS 2016[40]和SegTrack v2[9]数据集上与现有的视频目标分割方法进行大量对比实验,并从分割精度和分割效率两方面对所有方法进行评估,进一步验证本文方法的有效性。
4.1 本文方法验证
4.1.1 视频预处理结果比较
图4所示为同一视频在相同用户交互下,使用不同大小双边网格获得的视频过分割以及视频目标分割结果。其中,第一、三行为映射到不同大小双边网格中视频帧的过分割结果,第二、四行为对应双边网格大小下视频目标分割结果。在给出的6组不同大小的网格中,分别在颜色域(图4(a)~图4(c))、空间域(图4(d)、图4(e))和时间域(图4(e)、图4(f))上将网格大小的取值依次增大,此时双边网格的采样率是逐渐减小的。当网格大小设置为Γ(8,8,8,8,8,8)时,采样率较大且网格单元数目较少,部分网格单元中可能会同时包含前景像素点和背景像素点,因此在该双边网格下得到的视频目标分割结果错误较多。随着各个域的采样率逐渐减小,网格单元的数目逐渐增加,能够逐渐改善视频目标分割结果的精准度,如图4(a)~图4(f)第二、四行所示。此外,随着待处理的网格单元数量的逐渐增加,分割所需的时间也是逐渐增加的。当网格大小达到Γ(16,16,16,30,50,8) 之后,所得到的视频目标分割结果变化不明显。若继续减小采样率,在产生相同视频目标分割结果下分割速率将变得非常低下。
4.1.2 概率图结果比较

Fig.4 Results of video over-segmentation and video object segmentation with different sizes of bilateral grid图4 不同大小双边网格下的视频过分割及视频目标分割结果
为了验证本文中置信动态外观模型的有效性,图5所示为采用K-means算法构建的颜色模型、高斯混合模型(Gaussian mixture model,GMM)算法[24]和本文置信动态外观模型获得的概率图的比较。其中,图5(a)所示为黑熊和足球视频序列中的部分视频帧,图5(b)、图5(d)和图5(f)分别是上述方法所产生的概率图,而图5(c)、图5(e)和图5(g)为对应的视频目标分割结果。给定的视频序列中存在部分前/背景颜色相似、背景内容复杂等情况,此时利用K-means算法和GMM算法构建的颜色模型具有较差的辨别能力,估计的概率图中包含较多的错误信息(图5(b)和图5(d)),导致产生不准确的视频目标分割结果(图5(c)和图5(e))。然而,本文的置信外观模型能够准确地辨别出视频中未标记和二义的颜色特征以识别不可靠的属于前/背景的概率估计值,最终获得更为准确的概率估计图(图5(f))和视频目标分割结果(图5(g))。
同时,进一步定量评估这些颜色模型的性能,本文采用增益率Rg和错误率Re这两个指标[41]进行量化评价:
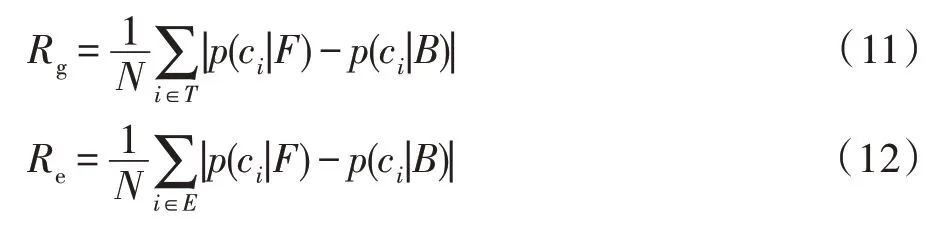
其中,N为视频像素的总数,T是正确分类的像素点总数,E为错误分类的像素点总数。表1所示为上述算法所得到的概率图的增益率Rg与错误率Re的统计。由表1可知,K-means算法估计出的概率图的增益率最低且错误率最高。GMM算法的增益率最高,但同时也具有较高的错误率。本文构建的置信外观模型的增益率低于GMM算法,这是因为本文方法中为未标记和具有二义颜色特征的像素点都分配了一个不重要的概率值(设为0.5),但本文方法所估计的概率图的错误率在这3种颜色模型中最低。综上所述,本文的置信动态外观模型更加可靠。
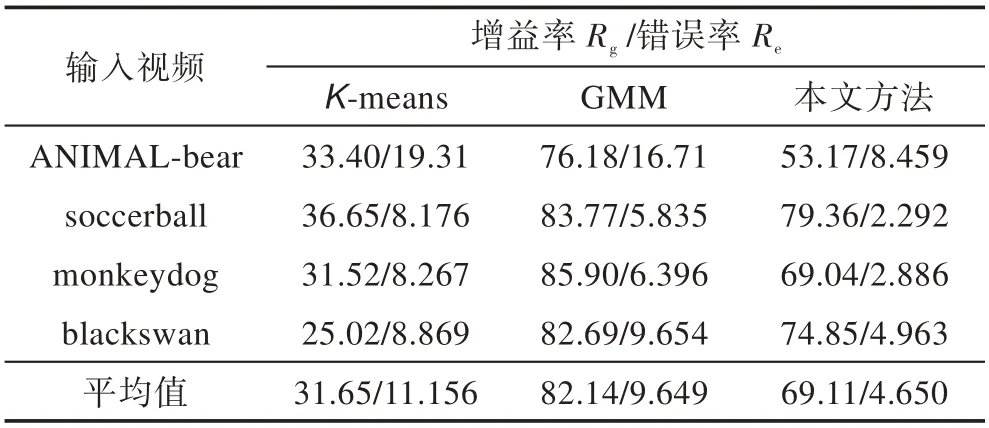
Table 1 Statistics of gain and error of probability maps表1 概率图的增益率和错误率统计%
4.1.3 有无高阶项的结果比较

Fig.5 Probability maps generated by different algorithms and video object segmentation results图5 不同算法的概率图及其视频目标分割结果
本文方法通过引入高阶项作为软约束进一步提高分割结果的精准度。图6所示为本文方法在有无高阶项时获得的视频目标分割结果。其中,从左至右分别是部分原视频帧、真值图像、无高阶项和有高阶项下的分割结果。给定的视频中背景内容较为复杂且目标对象与背景有相近似的颜色,导致分割难度较大。当未引入高阶项时,获得的结果中出现目标对象的部分区域明显缺失、前/背景分割错误的情况,如图6(c)所示。而通过引入高阶项,鼓励所有不相邻但具有相似特征的网格单元分配一致标签,且允许为聚类效果不佳的同簇网格单元结点分配不一致的标签,确保获得正确的视频目标分割结果,进一步地提高分割精准度,如图6(d)所示。

Fig.6 Results of video object segmentation with or without higher-order term图6 有无高阶项的视频目标分割结果
4.1.4 不同用户交互结果比较
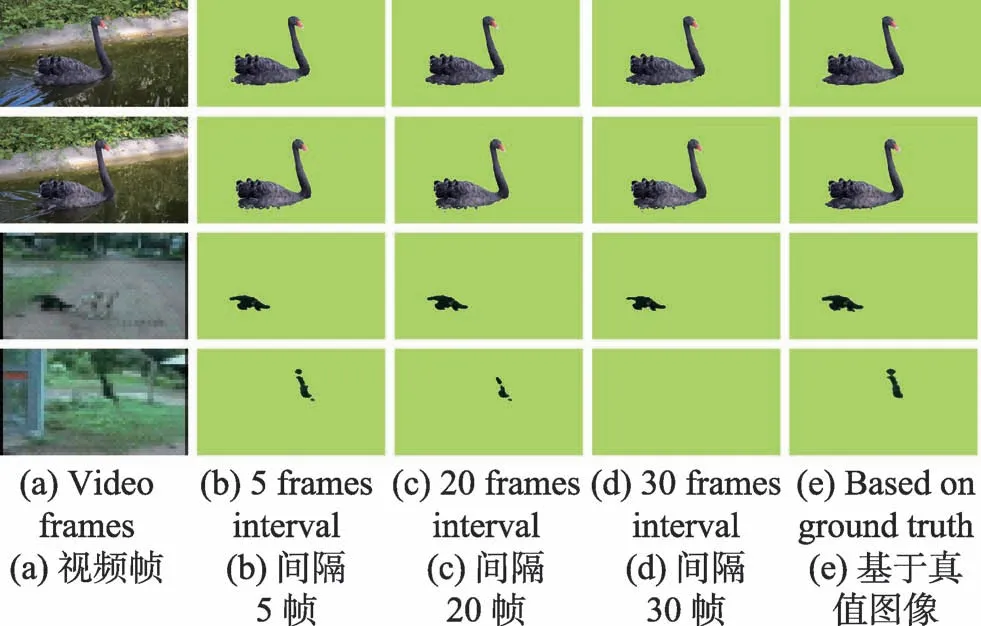
Fig.7 Comparison of experiment results in different user interaction图7 不同用户交互的实验结果对比
图7所示为不同用户交互的实验结果对比。其中,图7(b)至图7(d)分别间隔5、20和30帧选取关键帧进行用户交互,图7(e)为使用真值图像提供先验信息的实验结果。图7(b)至图7(d)中,用户交互不同且关键帧间隔依次增大,用以视频目标分割的先验信息依次减少,分割质量逐渐递减。但前两行中目标对象运动缓慢,不同用户交互对分割质量影响并不明显。后两行视频中存在前/背景颜色复杂、目标对象运动剧烈的复杂现象,使得图7(d)中部分视频帧未分割出目标对象。根据视频的复杂程度不同,图7(e)前两行间隔20帧、后两行间隔15帧选取真值图像提供先验信息,都获得了较为理想的分割结果。
4.2 不同数据集的视频目标分割
4.2.1 DAVIS 2016数据集实验结果
DAVIS 2016数据集包含50个全高清视频序列,其中每一视频素材的分辨率包含480p和1080p两种,且所有的视频帧都给定了准确的真值分割图像。该数据集的视频内容涵盖了常见的物体遮挡、运动模糊和外观变化等情况,因此具有一定的分割难度。图8所示为DAVIS 2016中部分视频序列的分割结果,分别由传统的基于层级图(hierarchical graphbased video segmentation,HVS)分割方法[42]、基于时间超像素(temporal superpixels,TSP)分割方法[43]、全连接目标建议区域(fully connected object proposals,FCP)分割方法[16]、基于双边空间(bilateral space video segmentation,BVS)分割方法[29],以及基于深度学习的静态图像(MaskTrack)分割方法[33]、联合光流信息(Segflow)分割方法[34]、MRF模型联合CNN(MRFCNN)分割方法[35]、在线目标跟踪(SiamMask)分割方法[36]获得。如图8(b)~图8(e)所示,这些方法获得的分割结果都出现部分目标对象缺失和背景区域被错误分类的情况。其中,HVS和TSP仅依赖单一的颜色特征实现视频目标分割,难以准确地区分颜色相近的目标对象和背景,严重降低了视频目标分割的精度。虽然FCP产生的分割结果较为理想,但是利用SVM(support vector machine)分类器提取目标建议区域,并跟踪跨越整个视频序列的目标对象时,容易导致分类器过度拟合,从而易产生过度分割的实验结果。BVS仅利用标准的图割优化算法对网格单元进行二值标签分配,该方法往往难以辨别具有相似颜色特征的前/背景网格单元结点,因此部分相似颜色的背景被错误识别为前景,使得最终的分割结果噪声较多。图8(f)~图8(i)所示为利用深度学习方法获得的视频目标分割结果,相对于前几种方法可以获得较好的分割结果。但对具有前/背景相似、运动剧烈、遮挡等复杂场景视频时,MaskTrack、Segflow、MRFCNN和SiamMask方法获得的分割结果也并不理想。本文方法通过结合置信动态外观模型和鲁棒的高阶项,不仅能够辨别出未被标记和具有二义的颜色,还能为不相邻但具有相似颜色特征的网格单元分配一致的标签,因此本文方法能够获得高精度的分割结果,如图8(j)所示。

Fig.8 Comparison of experiment results in different methods from DAVIS 2016 dataset图8 DAVIS 2016数据集中不同方法的实验结果对比
图9所示为1080p视频在本文与BVS方法获得的视频目标分割实验结果对比。由于1080p视频待处理的视频数据量大,导致视频目标分割难度进一步增加。如图9(c)和图9(d)所示,1080p视频目标分割结果质量低于图8中480p视频目标分割结果,但本文方法在1080p视频目标分割中仍能获得比较好的结果。值得注意的是,本文仅图9使用1080p视频进行实验,其余统一使用480p的视频素材进行实验,且先验信息直接由真值图像给定。

Fig.9 Comparison of experiment results in 1080p图9 1080p实验结果对比
本文进一步使用交并比(intersection over union,IoU)量化上述各种视频目标分割方法的实验结果的精确度,如表2所示,该值越大则表示视频目标分割越准确。表2中详细地给出了对比方法和本文方法在DAVIS 2016数据集中部分视频序列的IoU和分割时间统计情况。由表2可知,本文方法并不是所有视频都能获得最优的分割结果,但是本文方法的平均IoU值较传统和基于深度学习的视频分割方法的平均IoU值高。如表2第3列至第6列所示,在传统的分割方法中,TSP方法平均IoU值最低仅0.289,即使平均IoU最高的HVS方法也比本文低约0.18。相对于传统的视频目标分割方法,基于深度学习的方法获得的分割质量有所提高,如表2第7列至第10列平均IoU所示。然而,本文方法增加对未知类别和二义颜色特征的判别并引入高阶项能量项,进一步提高了视频目标分割的质量,因此与基于深度学习方法进行比较也具有一定的竞争力,即本文方法的平均IoU略高于最好的MRFCNN方法0.007。SiamMask方法虽然平均IoU较低,但是其分割速度最快。而本文方法平均每帧分割的时间约为0.39 s,虽不及SiamMask方法的0.02 s,但是平均IoU提高了约0.23。本文分割时间略高于BVS方法(0.37 s)是由于本文引入了高阶项并增加了置信动态外观模型。值得注意的是,表2中平均IoU值是由表中列举的视频的IoU值计算得到的,且所有表中时间仅包含视频预处理和视频目标分割过程的时间统计。
4.2.2 SegTrack v2数据集实验结果
SegTrack v2数据集一共包含14个视频序列,以及准确分割的真值图像,这些视频具有明显的物体遮挡、运动剧烈、前/背景颜色相似等内容复杂的情况。图10所示为SegTrack v2中部分视频序列的分割结果,分别由自动生成关键目标(key-segments,KEY)的分割方法[11]、快速无约束(fast object segmentation in unconstrained video,FST)的分割方法[1]、基于分层有向无环图(DAG)的分割方法[14]、基于相似区域投票(non-local consensus voting,NLC)的分割方法[15]与本文方法在相同运行环境下获得的实验结果进行比较。其中,KEY方法的分割结果中错误分割的背景区域较多,甚至未分割出部分视频帧中的目标对象,如图10(b)所示。这主要是由于该方法无法模拟目标对象的形状及位置随时间的演变,导致出现视频目标对象严重缺失的情况。FST方法通过获得与物体轮廓一致的但非闭合的目标边界轮廓图,能够捕获目标对象的形变,但是对于目标对象与背景颜色相近似的区域难以完全分割出来,如图10(c)所示。DAG方法采用有向无环图从视频序列假设对象中提取目标对象,通常能够得到较为理想的分割结果,如图10(d)所示,但是运行过程比较耗时。NLC方法利用光流法确定视频目标的位置,因此分割结果通常不能很好地贴合目标边界,使得分割结果包含较多的背景区域,如图10(e)所示。然而,本文方法通常能够获得与目标对象边界贴合度较高且完整的分割结果,如图10(f)所示。
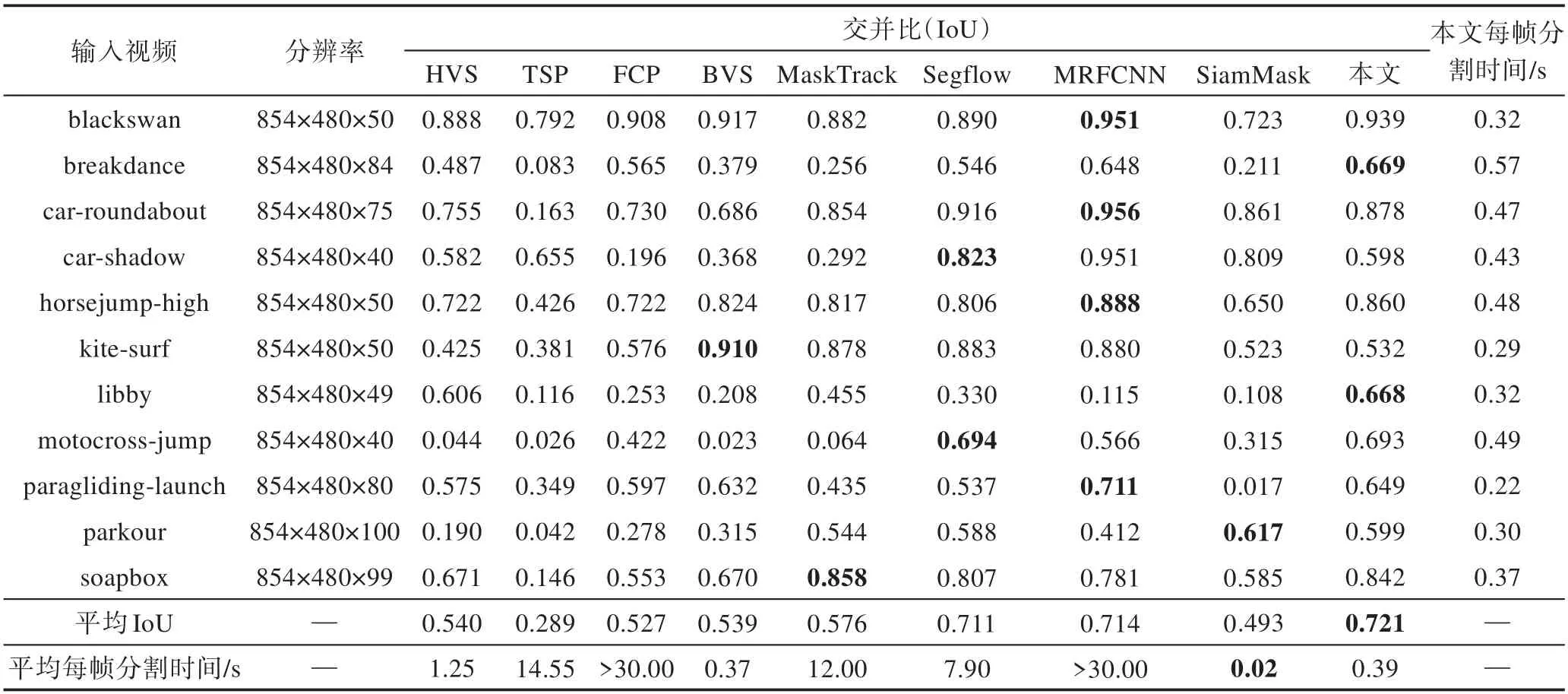
Table 2 Intersection-over-union(IoU)and time statistics of different methods on DAVIS 2016 dataset表2 DAVIS 2016数据集中不同方法的交并比及时间统计

Fig.10 Comparison of experiment results in different methods from SegTrack v2 dataset图10 SegTrack v2数据集中不同方法的实验结果对比
上述方法在SegTrack v2数据集中的IoU和分割时间统计如表3所示,其平均值是由该数据集中所有视频目标分割的结果计算得。从表3可以看出,本文方法的平均IoU高于其他4种方法,且在分割时间效率上明显快于其他方法。其中,KEY方法在分割birdfall视频时,由于未能正确地分割出目标对象,因此其IoU为0。在时间效率上,这些方法通常需要获取待分割的目标对象,并逐视频帧跟踪视频目标对象,因此分割时间都较长。结合平均IoU值和平均分割时间这两个指标对上述5种视频目标分割方法进行量化评估,进一步表明本文方法能够快速且准确地完成视频目标分割任务。需要注意的是,由于penguin视频序列中包含多个重复的目标对象,但真值图像中仅标记了一个目标对象,上述方法都未使用该视频进行实验,因此表3中仅给出本文方法的分割结果。
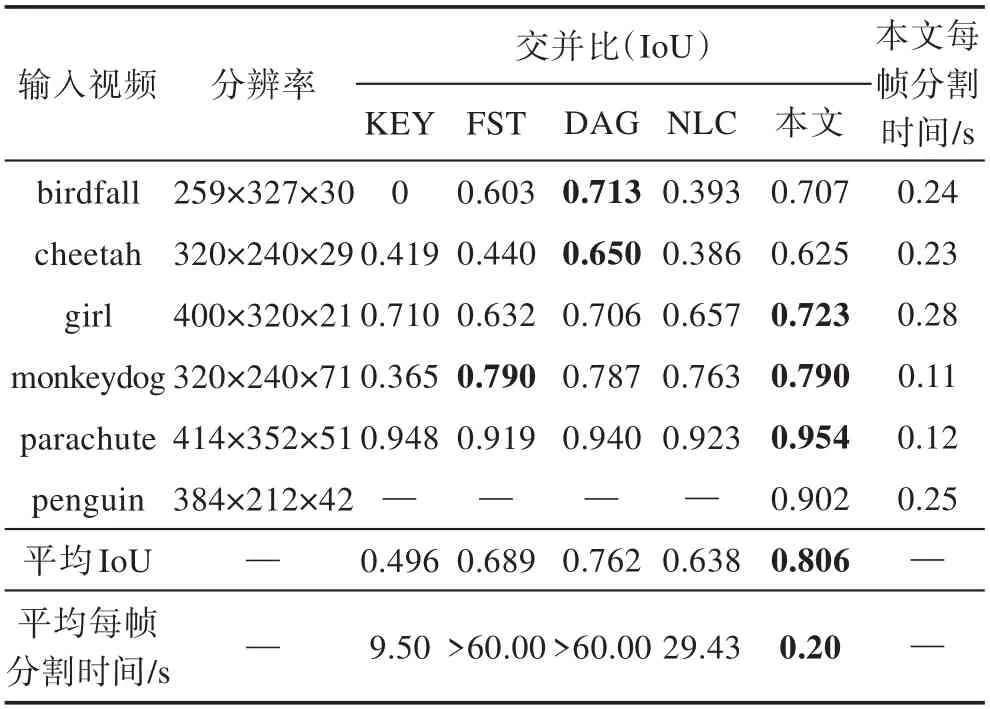
Table 3 Intersection-over-union(IoU)and time statistics of different methods on SegTrack v2 dataset表3 SegTrack v2数据集中不同方法的交并比及时间统计
5 结束语
为了解决复杂场景下的视频目标分割质量不佳和时间效率低下等问题,本文提出一种动态外观模型和高阶能量的双边视频目标分割方法。该方法采用双边网格技术预处理视频数据减少了待处理的数据量,并在规则采样的双边网格顶点上定义图割优化模型,从而避免了复杂拓扑的图结构。本文关键在于构建置信动态外观模型并定义鲁棒高阶项,不仅能准确地估计各像素点属于前/背景的可能性,还能用以增强不相邻但具有相似外观特征结点的时空相关性,从而极大提高分割结果的质量。大量实验结果证明,本文方法能够快速地处理具有复杂场景及超高分辨率视频分割任务,并确保能够获得高精度的分割结果。下一步,本文将考虑增加视频目标对象的运动信息,进一步提高视频目标分割的精准度。
猜你喜欢
计算技术与自动化(2022年1期)2022-04-15
华人时刊(2021年23期)2021-03-08
现代电子技术(2021年1期)2021-01-17
作文新天地(初中版)(2019年6期)2019-08-15
福建基础教育研究(2019年7期)2019-05-28
数学学习与研究(2018年15期)2018-11-12
现代电子技术(2018年18期)2018-09-12
上海师范大学学报·自然科学版(2018年3期)2018-05-14
电脑知识与技术(2018年35期)2018-02-27
科学家(2017年12期)2017-08-10
