
改进的阵列处理器数据Cache实时动态迁移机制*
2020-12-15 08:13:30冯雅妮
计算机与生活 2020年12期
冯雅妮,蒋 林,山 蕊,刘 阳,张 园
1.西安邮电大学电子工程学院,西安710121
2.西安科技大学集成电路实验室,西安710054
3.西安邮电大学计算机学院,西安710121
1 引言
随着半导体工艺的飞速发展,单个芯片能够集成更多的处理器核,一定程度上可以提升阵列处理器计算能力,但是核数的增多使得“存储墙[1-2]”问题日益突出。同时,面向超高清视频编解码等计算密集型应用时[3],处理器需进行大量的并行计算,因此数据的吞吐量成为了影响系统性能提升的瓶颈。
为了缓解阵列处理器中日益严重的“存储墙”问题,通常在片上集成大容量的Cache以实现数据共享和信息交互,从而减小访问延迟[4]。共享Cache容量大、失效率低,且一致性维护开销小,但在访问冲突情况下,访问延迟较大;私有Cache在本地命中情况下访问延迟低,具有较高的并行度,但一致性维护开销较大,且可能出现负载不均衡现象,导致Cache整体有效空间减少[5-6]。目前研究人员大多采用多级Cache技术,以减少访问延迟并提高访问带宽[7-8]。多级Cache具有层次化的存储结构,其一致性维护增加了电路的复杂度及功耗。为了降低访问延迟并且提高访问的并行度,面向阵列处理器设计的分布式共享存储结构采用统一编址方式,从逻辑上提供了一个片上大容量存储资源,并采用软硬件协同技术,实现了片上存储资源的高效利用[9]。针对片上互连结构中访问延迟的不均衡特性,Kim等人首次提出了非一致Cache体系结构(non-uniform Cache architecture,NUCA)[10]的概念。Huang等人提出了自适应动态非一致性访问(pressure self-adapting dynamic non-uniform Cache assess,PSA-NUCA)机制[11],研究了存储访问的不对称分布特征和非一致性访问延迟结构,可有效缓解失效率和实际命中延迟之间的矛盾。为了充分发挥NUCA在多核系统下的性能优势,可以根据提前预测的关键路径信息对Cache中的数据进行迁移[12]。但是,关键路径只能提前预测而不能实时响应,因此基于关键路径预测进行数据迁移并不适用于阵列处理器这种数据量级访问的系统。
为了缓解阵列处理器中远程访问情况下分布式存储结构存在的长延迟问题,论文基于分布式Cache结构设计了一种改进的数据Cache实时动态迁移机制,以一段时间内远程Cache中数据块的访问频率为依据,通过四级全互连和迁移互连,对远程数据进行动态调度。本文的贡献如下:
(1)设计实时动态迁移机制,基于分布式Cache结构对频繁访问的远程数据进行动态调度;
(2)设计迁移互连,在保证数据一致性的前提下,建立迁移与取消迁移链路,同时确保阵列处理器对已迁移数据的正确访问;
(3)采用运动补偿算法对所提出的动态迁移机制进行验证,并分析访存性能。
2 阵列处理器分布式Cache结构
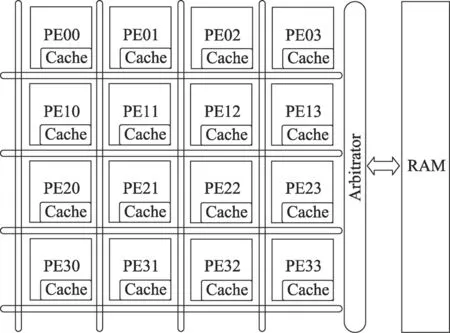
Fig.1 Dstributed Cache structure of array processor图1 阵列处理器分布式Cache结构
阵列处理器的簇内分布式Cache结构如图1所示。阵列处理器中处理元簇(processing element group,PEG)由4×4个处理元(process element,PE)以阵列的形式组成。阵列结构中每个PE各具有一个本地Cache从而构成分布式Cache结构,每个PE对本地Cache和远程Cache都具有读写访问权限。当PE发出访问请求时,根据PE发出的访问信息,通过四级全互连对访问的目的Cache进行索引,进而对相应的Cache进行访问。若访问命中,则直接对分布式Cache中的数据进行访问;若访问不命中,则通过仲裁器仲裁出一路访问请求去访问主存,将目的数据块从主存搬移到Cache中,再将目的数据返回给PE。
当Cache接收PE发送的访问请求时,Cache内部首先通过比较访问请求中的标志信息与该Cache的标志信息,并结合Cache当前的状态信息判断本次访问是否命中。为保证Cache与主存间的数据一致性,访问不命中且Cache内无空闲行时,采用最近最少用算法(least recently used,LRU)对Cache行数据进行替换,同时向数据存储单元发送脏与不脏时的控制信息,若替换行脏,还需遵循写回策略将脏的替换行数据写回主存。
在阵列处理器的大规模数据访问过程中,若簇内的PE访问16个Cache的概率相当,则PE访问本地Cache的概率仅为6.25%,并且本地Cache容量有限。由此可见,远程访问是整个系统访存操作的重要组成部分。在分布式Cache中,PE频繁访问远程Cache中数据将带来较大的访问延迟。因此,为了缓解频繁的远程访问带来的长延迟问题,本文提出了一种改进的基于分布式数据Cache的实时动态迁移机制,通过动态和静态相结合的地址映射方式降低远程访问延迟。
3 数据Cache实时动态迁移机制
论文设计的改进的数据Cache实时动态迁移机制,在远程访问情况下,根据数据访问的局部性,并以PE在一段时间内访问远程数据Cache的频率为主要迁移依据对远程数据进行动态调度,将频繁访问的远程Cache行数据迁移到距离该PE最近的存储单元中,从而降低远程访问延迟。
3.1 分布式Cache实时动态迁移结构
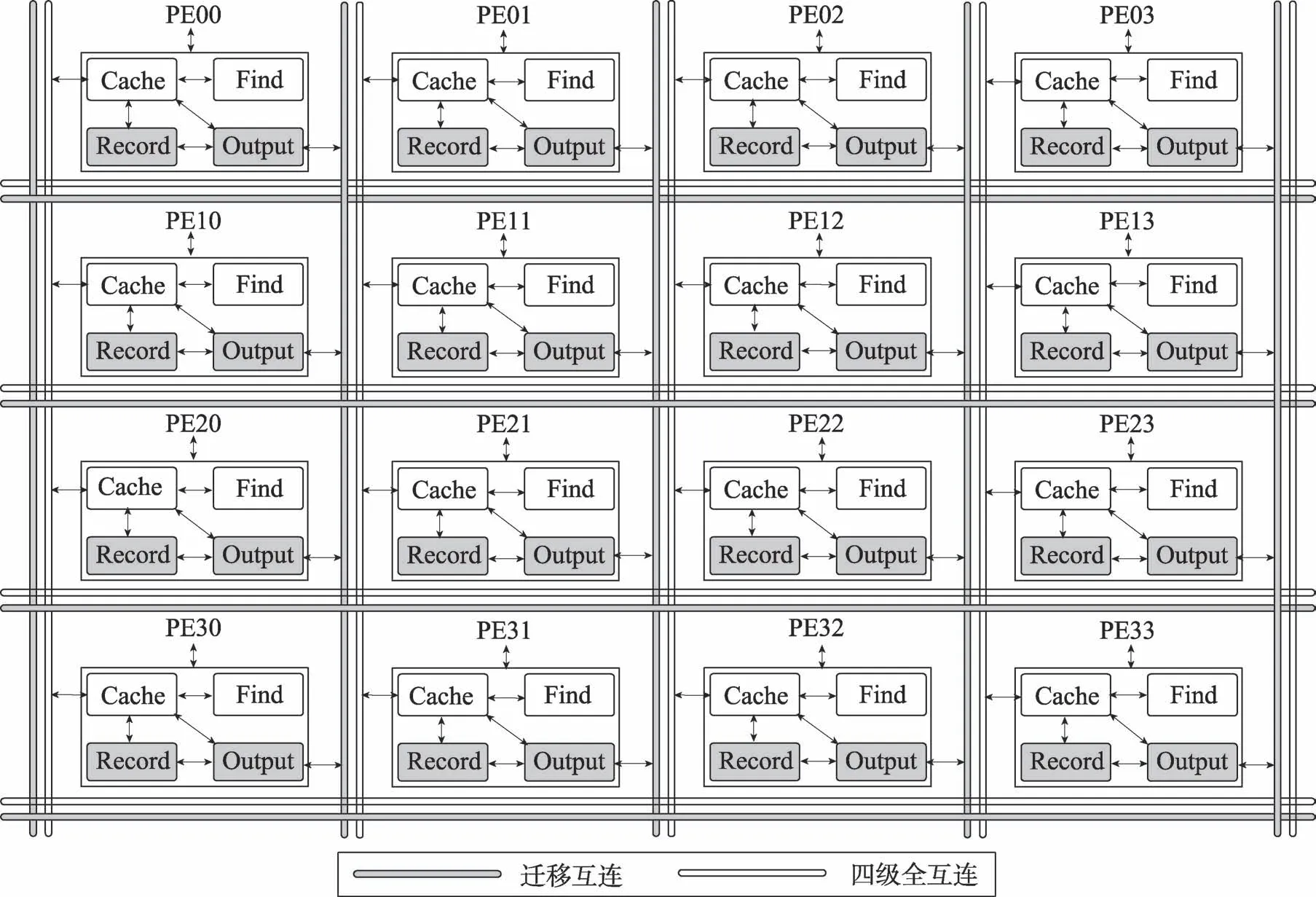
Fig.2 Real-time dynamic migration structure of distributed Cache图2 分布式Cache实时动态迁移结构
分布式Cache实时动态迁移结构主要由迁移查找表(Find)、四级全互连、数据Cache、访问记录表(Record)、迁移输出单元(Output)及迁移互连六部分组成,如图2所示。迁移查找表是距离PE最近的本地存储单元;PE通过四级全互连准确地访问目的Cache;访问记录表统计Cache行被PE访问的频率;当PE在一段时间内访问某远程Cache行中的数据的频率达到迁移阈值时,迁移输出单元输出该远程Cache行,并通过迁移互连迁移这个频繁访问的Cache行数据到该PE本地的迁移查找表中。其中,一段时间由总访问次数确定,当访问次数达M次,当前时间段结束,进入下一时间段,同时访问次数重新计数。当该PE再次访问已迁移的数据时,只需一个时钟周期就可在本地的迁移查找表中完成访问。
在采用实时动态迁移机制的分布式Cache中,PE发出访问请求后,并不直接访问Cache,而是首先根据访问信息访问本地迁移查找表,在迁移查找表中命中时,直接完成访问;在迁移查找表不命中时,才通过四级全互连访问Cache。目的Cache在响应访问请求的同时,对应的访问记录表实时记录目的Cache行在一段时间内被阵列内的16个PE访问的频率。
根据Cache中迁移记录表统计的PE访问该Cache中数据块的频率,可将数据块的状态划分为频繁访问和非频繁访问两种。在一段时间内,如果数据块被访问频率小于迁移阈值B,则此数据块处于非频繁访问状态;如果数据块被访问频率达到迁移阈值B,则此数据块处于频繁访问状态。
为了降低分布式Cache在远程访问下的访问延迟,采用实时动态迁移机制,动态调度处于频繁访问状态的数据块。远程Cache根据迁移记录表得到PEi频繁访问的Cache行信息,并输出该Cache行数据到迁移输出单元,通过迁移互连最终写入PEi本地的迁移查找表中。迁移后PEi仅需一个时钟周期直接在本地迁移查找表中完成访问,无需再访问远程Cache。对于已经迁移到本地迁移查找表的Cache行数据,如果在一段时间内不再被PEi频繁访问,则该数据块处于非频繁访问状态,需建立取消迁移链路,通过迁移互连把该数据块中的脏数据迁回原静态映射位置对应的远程Cache中,并将取消迁移操作完成的反馈信号返回到本地的迁移查找表,以便下一个频繁访问的数据块可正常迁入。动态迁移数据通路如图3所示,其中虚线框内表示数据块动态迁移过程。
3.2 迁移互连
迁移互连由mig_connect和find_ca_connect两部分组成。其中,mig_connect的主要功能是建立迁移与取消迁移链路。
(1)迁移链路:PEi对应的mig_connect_i接收来自15个远程迁移输出单元的迁移使能及Cache行,并采用最远优先响应的原则仲裁出一路远程Cache行及对应的地址信息,发至PEi的本地迁移查找表中,迁移查找表接收完远程Cache行数据后,结合其对应的地址信息,将迁移完成的反馈信号通过mig_connect_i返回给该远程Cache行迁移前的静态映射位置,完成迁移链路。远程Cache接收到迁移完成的反馈信号后,将对应Cache行的状态更新为已迁移,同时访问记录单元不再对该Cache行的访问频率计数。
(2)取消迁移链路:PEi本地的迁移查找表中的远程数据块不再被频繁访问时,迁移查找表发出取消迁移使能,通过mig_connect_i通知对应的远程Cache将该Cache行状态更新为未迁移,对应的访问记录单元对该Cache行的访问频率重新开始计数,同时该远程Cache通过mig_connect_i返回取消迁移操作完成的反馈信号,迁移查找表收到该反馈信号后,更新表内访问计数器为0,数据区无效,数据区脏位为0。

Fig.3 Dynamically scheduled data path图3 动态调度数据通路
find_ca_connect的主要功能是确保PE可正确访问已迁移的Cache行数据,包括以下两种情况:
(1)PEi频繁访问某远程Cache行,且迁移操作未完成时已将访问请求发送至该远程Cache行的原静态映射位置。当远程命中访问达B次时,迁移该远程Cache行到本地的迁移查找表中,同时将远程Cache对应的数据行状态更新为已迁移状态,已发送至该远程Cache行的原静态映射位置的第B+1次命中访问请求在等待迁移操作完成后,转发至find_ca_connect_i,经过仲裁后传到PEi的迁移查找表完成响应,并通过find_ca_connect_i将响应完成的反馈信号返回给远程Cache,最终由远程Cache反馈给PEi完成访问。
(2)其他远程PE访问已迁移的Cache行。当某远程Cache行已迁移至PEi的迁移查找表且有效时,其远程Cache内对应的数据行状态已更新为已迁移状态,此时若PEj也发出访问该Cache行的请求,首先访问该Cache行的静态映射地址,由于目的Cache行状态为已迁移,该Cache接收来自PEj的访问请求后,根据迁移输出单元的地址信息,将访问请求转发至find_ca_connect_i,经过仲裁后传到PEi的迁移查找表完成响应,并通过find_ca_connect_i将响应完成的反馈信号返回给远程Cache,最终由远程Cache反馈给PEj完成访问。
3.3 动态迁移阈值B
在本文提出的数据Cache实时动态迁移机制中,主要的迁移依据为PE在一段时间内对一个远程数据Cache的访问次数,并采用记录表的形式记录PE访问远程数据的频率。当PEi访问远程Cache中的某行数据时,记录本次访问的计数器加1。统计一段时间内,迁移记录表中各PE访问远程Cache行数据的频率,如果PEi在一段时间内访问远程Cache行数据达到迁移阈值B次,即PEi在这段时间内频繁访问该远程Cache行数据,则迁移该Cache行到PEi的本地迁移查找表中。在迁移之后的每次访问中,PEi每次仅需一个时钟周期就可得到远程数据,而无需消耗较多延迟通过访问远程Cache获取。因此,当分布式Cache远程访问延迟很大时,可以采用实时动态迁移机制来降低访问延迟。针对迁移阈值B,本文构建了一种数学模型,计算公式如下:
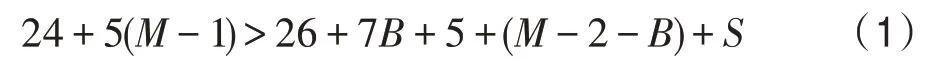
其中,不等式左边代表未采用迁移机制的分布式Cache在一段时间内对一个远程Cache行进行M次访问的总延迟,远程访问情况下首次不命中访问平均需24个时钟周期,命中访问平均需5个时钟周期。不等式右边表示基于动态迁移机制的分布式Cache在一段时间内对一个远程Cache行进行M次访问的总延迟,基于迁移机制的分布式Cache首次不命中访问远程Cache行平均需26个时钟周期,迁移机制启动前,命中访问平均需7个时钟周期。当远程命中访问达B次时,启动迁移机制,迁移该Cache行到本地的迁移查找表中,迁移后需通过迁移互连经历5个时钟周期完成第B+1次命中访问,之后的命中访问仅需1个时钟周期。在本文中,Cache从产生迁移使能到接收迁移查找表返回的迁移操作完成的反馈信号共需19个时钟周期,因此,迁移代价S=19,代入上述公式可得式(2):

由式(2)可知,迁移阈值B的选取与一段时间内的访问次数M有关。随着M增大,B可变范围逐渐增大,并且尽早采用实时动态迁移机制,整体性能提升越明显。当迁移阈值B选取过大时,实时动态迁移机制的启用要求过高,使得性能的提升受到限制;当迁移阈值B选取过小时,实时动态迁移机制启用过早,可能存在后期访问频率更大的远程Cache行来不及被迁移的情况,同时还可能造成迁移和取消迁移操作的频繁发生,增大了迁移代价,削弱了迁移优势。因此迁移阈值B的选取与实际访问频率和访问顺序有关。
3.4 迁移取消方法
采用实时动态迁移机制的分布式Cache,将一段时间内频繁访问的远程Cache行数据迁移到距离PE最近的本地的迁移查找表中,降低访问延迟。但由于迁移查找表容量较小,为了进一步降低访问延迟,当迁移查找表中已经迁移的Cache行不再被频繁访问时,建立取消迁移链路,将迁移查找表中已经迁移的Cache行置为无效,以便于下一个频繁访问的Cache行迁入。根据取消迁移的数据行的状态,可分为以下两种情况执行取消迁移操作。
(1)当迁移查找表中需取消迁移的数据行脏位为0时,将迁移查找表中的数据行置为无效,并输出迁移取消使能,通知访问记录单元对原Cache中静态映射位置的Cache行正常计数,完成取消迁移操作。
(2)当迁移查找表需取消迁移的数据行脏位为1时,不仅置迁移查找表中的远程数据行为无效,还需写回迁移查找表中的脏数据行至远程Cache行的原静态映射位置,更新脏位为0,完成取消迁移操作。
因此一个PE频繁访问并迁移N个不同的远程Cache行数据的执行时间如式(3)所示:
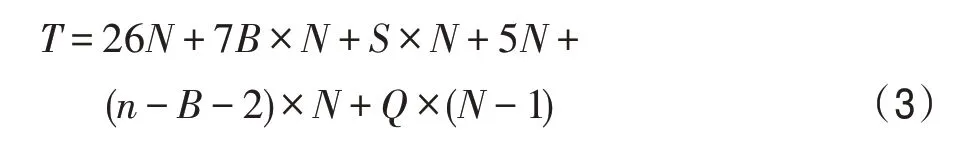
其中,假设平均访问每个远程Cache行n次,一个PE的N次迁移操作必然产生N-1次取消迁移操作。在本文中,当脏位为0时,迁移查找表输出迁移取消使能到收到取消迁移完成的反馈信号需4个时钟周期,因此取消迁移代价Q=4;当脏位为1时,从产生写回脏数据行的使能到整个取消迁移操作完成需19个时钟周期,因此取消迁移的代价Q=19。
3.5 迁移一致性策略
PE发出远程访问请求时,首先在本地的迁移查找表中判断此次访问是否命中,若命中则直接在迁移查找表中对数据进行操作,无需访问远程Cache。因此,为保证分布式Cache与迁移查找表的数据一致性,基于实时动态迁移机制的数据访问需:
(1)迁移过程中,阵列处理器中的所有PE不能访问正在迁移的Cache行数据,直到迁移完成;迁移操作完成后,如果PE发出访问请求并在本地的迁移查找表中命中时,若为读访问,则迁移查找表数据行脏位保持;若为写访问,则更新迁移查找表数据行脏位为1。
(2)取消迁移过程中,除了将已迁移的Cache行置为无效之外,为保证一致性,需把迁移查找表中的脏数据行写回原Cache中的静态映射位置,并更新脏位为0。与迁移操作相同,为保证其他PE能够正确取数,在取消迁移过程中,其他PE不能访问正在执行取消迁移操作的Cache行,直到取消迁移完成,即迁移查找表中所有脏数据均被写回原静态映射位置。
(3)若某远程Cache行数据已迁移至PEi的迁移查找表且有效,PEj也发出访问该Cache行的请求,为保证PEj能正确地取得最新数据,PEj通过迁移互连至PEi的本地的迁移查找表中访问该Cache行的最新数据。
4 基于FPGA的硬件测试与性能分析
4.1 FPGA硬件测试平台
本文提出的数据Cache实时动态迁移机制以阵列处理器为硬件验证平台,其中阵列处理器簇内16个PE通过二维mesh结构的四级全互连完成4×4个分布式L1级Cache的数据通信。通过编写典型访问情况下的测试激励,使用QuestaSim对基于实时动态迁移机制的分布式Cache进行功能仿真后,与阵列处理器和Xilinx定制存储器IP互连,通过Xilinx的Zynq系列xc7z045-2-ffg900开发板进行硬件测试,具体参数如表1所示。
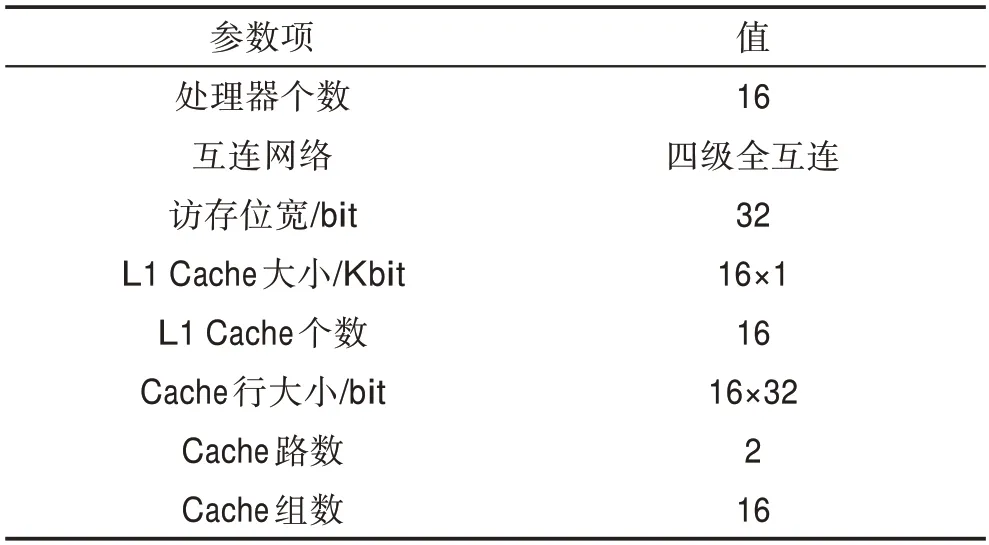
Table 1 Structural parameters of distributed Cache using migration mechanism表1 采用迁移机制的分布式Cache结构参数
通过Xilinx ISE对设计进行综合,综合结果如表2所示。

Table 2 FPGA synthesis result表2 FPGA综合结果
4.2 算法映射与功能验证
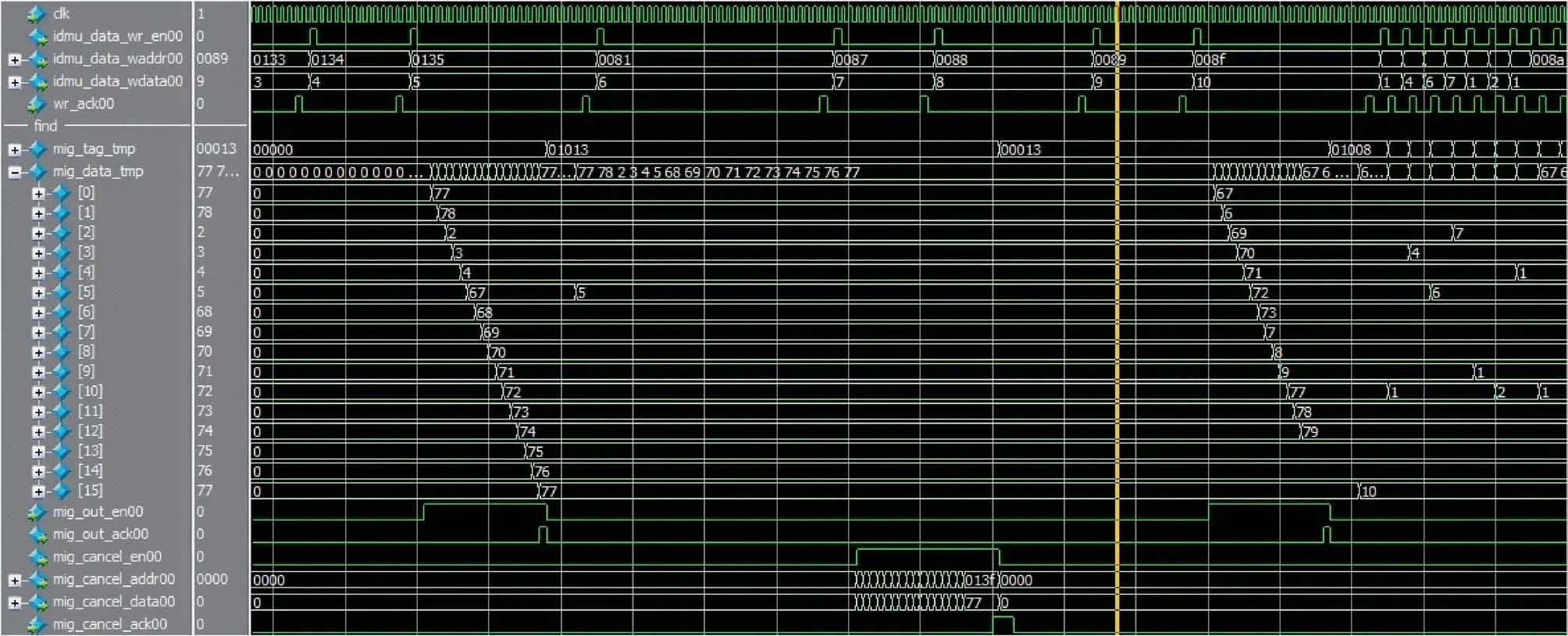
Fig.4 Functional simulation of real-time dynamic migration mechanism of data Cache图4 数据Cache实时动态迁移机制功能仿真
本文基于簇内分布式Cache结构,采用改进的数据Cache实时动态迁移机制,在PE远程访问次数大于迁移阈值B的情况下,功能仿真结果如图4所示。当PE访问某远程数据块(mig_tag_tmp[11:0])达到迁移阈值B时,将该频繁访问的远程数据块迁移到本地的迁移查找表中,迁移后仅需一个时钟周期就可完成访问。迁移后的远程数据块不再被该PE频繁访问时(mig_tag_tmp[17:13]<迁移阈值B),建立取消迁移链路(mig_cancel_en置1),将该远程数据块迁回对应的远程Cache(mig_tag_tmp[11:0]),并将该迁移查找表置为无效(mig_tag_tmp[12]置0)。一段时间后该PE将迁移下一个频繁访问的远程数据块(mig_tag_tmp[11:0]),并将迁移查找表置为有效(mig_tag_tmp[12]置1)。
为进一步验证改进的数据Cache实时动态迁移机制的正确性和可行性,本文将分布式Cache与阵列处理器平台互连,并在该平台上映射运动补偿算法。基于阵列处理器的运动补偿算法如下所示。
算法1Motion compensation

图5统计了不同参数下,8×8运动补偿算法的执行时间。为了灵活、高效地表示视频场景中的不同纹理细节、运动变化的视频内容或者视频对象,HEVC(high efficiency video coding)将图像划分成不同尺寸的编码块[13]。运动补偿算法以8×8的编码块通过远程访问读取参考像素值,与原始像素值进行残差操作,并将结果输出至远程存储中。因此,一段时间内访问次数M取15时,算法执行时间最短。动态迁移阈值B选取较小,可较早地启用实时动态迁移机制,有效减少算法的执行时间,但过早地执行迁移操作可能引起频繁的迁移及取消迁移,增大迁移代价,削弱迁移优势。
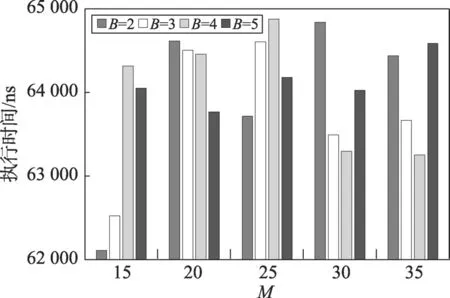
Fig.5 8×8 motion compensation algorithm execution time statistics图5 8×8运动补偿算法执行时间统计
4.3 访存性能分析
在可重构阵列处理器的分布式Cache结构下,采用改进的实时动态迁移机制的分布式Cache比未采用该机制的分布式Cache访问延迟平均多2个时钟周期,但迁移机制启动后,平均每次远程命中访问仅需1个时钟周期,远程命中访问时间平均降低了80%。
由表达式(2)可知,迁移阈值B的选取与一段时间内的访问次数M有关。图6(为了更清楚地显示延迟降低率的变化曲线,在图中将延迟降低率扩大3倍表示)统计了在迁移阈值B一定,访问次数M变化的情况下,两种访问机制对同一个远程Cache块的总访问延迟的变化情况。其中,M次访问均为读访问,分布式Cache读不命中访问需25个时钟周期,读命中访问需7个时钟周期,实时动态迁移机制下读不命中访问需27个时钟周期,命中访问需9个时钟周期。根据表达式(1)左侧可知,分布式Cache总访问延迟周期数为25+7×(M-1),根据表达式(1)右侧可知,迁移机制下总访问延迟周期数为27+9×B+5+(M-2-B)+S,此时迁移阈值B取2,迁移代价S=19。分析可知,随着访问次数M的增大,相比未采用实时动态迁移机制的分布式Cache,采用该机制的分布式Cache在相同访问频率下,延迟降低率逐渐增大,整体性能提升越大,采用实时动态迁移机制优势越明显。
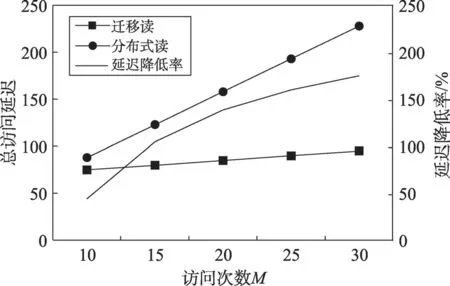
Fig.6 Statistics of total access delay with parameter M图6 总访问延迟随参数M 变化统计
由表达式(2)可知,随着访问次数M的增大,迁移阈值B的取值范围也增大,但访问同一远程数据块时,在访问次数M一定的情况下,迁移阈值B增大,总访问延迟与未采用动态迁移机制的分布式Cache访问延迟相比,延迟降低率逐渐减小,如图7所示。此时M取20,未采用实时动态迁移机制的分布式Cache总访问延迟为120个时钟周期。当迁移阈值B选取过大时,实时动态迁移机制的启用要求过高,使得性能的提升受到限制。因此,在一段时间内频繁访问一个远程数据块时,尽早启用动态迁移机制,性能提升越明显。

Fig.7 Statistics of total access delay with migration threshold B图7 总访问延迟随迁移阈值B 变化统计
当一段时间内访问多个远程Cache时,访问顺序及迁移阈值B的选取影响迁移链路与取消迁移链路的建立与撤销,进而影响总访问延迟。选取4个之前没有被访问过的远程Cache行R1、R2、R3、R4,分别进行40次读写访问,未采用动态迁移机制的分布式Cache的40次读操作总访问延迟为352个时钟周期,写操作总访问延迟为240个时钟周期。本文在采用动态迁移机制的基础上,进一步优化了访存顺序以降低访存延迟,优化前后读、写操作总访问延迟统计分别如图8、图9所示。取M=20,前20次访问为时间段1,后20次访问为时间段2。

Fig.8 Statistics of total access latency of read operations before and after optimization图8 优化前后读操作总访问延迟统计

Fig.9 Statistics of total access latency of write operations before and after optimization图9 优化前后写操作总访问延迟统计
(1)优化前的访问顺序为时间段1内R1、R2分别访问1次,R3访问5次,R4访问13次,时间段2内的20次访问均访问R4。与未采用迁移机制的分布式Cache相比,读、写操作总访问延迟分别降低达32.10%和15.00%。
(2)优化1的访问顺序为时间段1内R1、R2分别访问1次,R4访问13次,R3访问5次,时间段2内访问顺序不变,这种访问顺序可使最被频繁访问的远程Cache行R4最先被迁移,不必等R3被取消迁移后在时间段2内才被迁移。与优化前相比,避免了多次迁移及迁移取消操作带来的访存开销,与未采用迁移机制的分布式Cache相比,读、写操作总访问延迟分别降低达38.92%和21.25%。
(3)优化2的访问顺序为时间段1内R1访问1次,R4访问13次,R3访问5次,其中第B次和第B+1次命中访问R4之间访问1次R2,时间段2内访问顺序不变,由于迁移R4与访问R2并不冲突,与优化1相比,迁移R4的代价被覆盖,进一步降低了总访问延迟。与未采用迁移机制的分布式Cache相比,读、写操作总访问延迟分别降低达45.45%和30.83%。
表3分析了优化前读访问延迟变化,当B取2时,远程Cache行R3在时间段1内首先达到迁移阈值,但R3迁移时,第B+1次命中访问请求已到达R3原静态映射的远程Cache,此时通过迁移互连将访问请求发送至本地迁移查找表中响应,之后迁移后的R3仅被本地PE直接访问1次,不再被频繁访问,因此在时间段1结束时,迁移取消R3,因取消迁移的数据块不脏,无需写回,故取消迁移代价为4。但由于迁移取消R3与访问R4不冲突,因此取消迁移的代价被覆盖。在时间段2内R4重新计数达到迁移阈值,迁移后每次访问仅需1个时钟周期;当B取3时,与B取2情况类似,第B+1次命中访问请求通过迁移互连响应,之后R3不再被本地PE直接访问;当B取4时,完成R3迁移,但迁移后的R3不再以任何方式被访问,并且因为迁移R3与访问R4不冲突,所以迁移R3的代价被覆盖;当B取5时,R4在时间段1内已达到迁移阈值,且迁移后被频繁访问,因此在时间段1结束后不执行取消迁移,在时间段2内PE仍可直接从本地的迁移查找表中访问R4;B取6、7时,与B取5情况类似,仅较晚启动迁移机制。
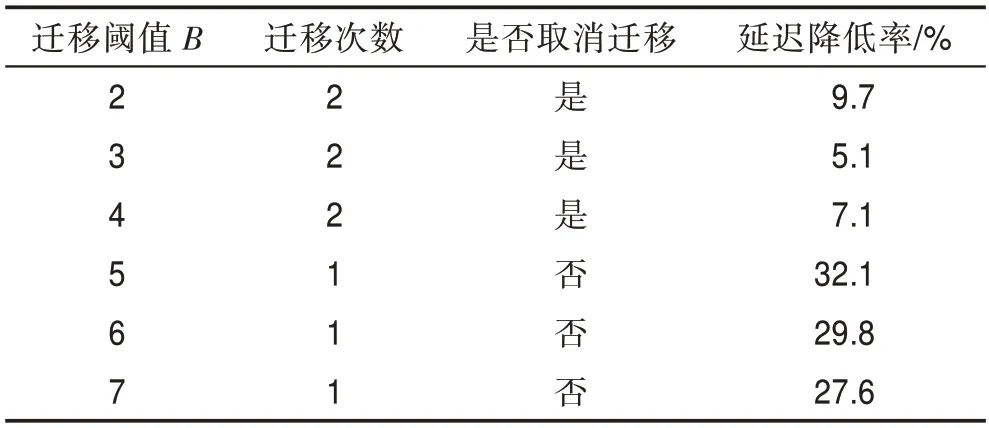
Table 3 Analysis of changes in read access latency before optimization表3 优化前读访问延迟变化分析
表4分析了优化前写访问延迟变化,与优化前读访问延迟变化类似,区别在于当B取2、3时,对已迁移的R3执行了写操作,R3成脏数据块,在取消迁移时,需写回至原静态映射位置,统计得取消迁移操作需19个时钟周期,由于迁移取消R3与访问R4不冲突,但下一次访问R4时需等待迁移取消操作完成,因此迁移取消R3的代价与一次写访问R4的访问延迟重叠,因此看起来迁移代价减少为13个时钟周期。当B取4时,迁移后的R3不再以任何方式被访问,因此迁移取消时无需写回R3的数据。

Table 4 Analysis of changes in write access latency before optimization表4 优化前写访问延迟变化分析
文献[14]提出了自适应选择性复制(adaptive selective replication,ASR),通过动态监视工作负载,选择性复制数据,减少缓存访问时间。文献[15]设计的多层次分布式存储结构由私有存储层和共享存储层两层结构组成,并基于目录协议的Cache一致性策略进行通信。两种存储结构下的远程Cache访问延迟如表5所示。文献[16]通过实现L1 Cache的伪随机替换策略来提高系统访存的整体性能,在此机制下进行FPGA实现最高可达160 MHz的工作频率。文献[17]设计的迁移机制仅迁移一个频繁访问的远程数据,电路工作频率较高,但访存位宽较小,程序访问局部性不高。本文与文献[16]、文献[17]性能对比结果如表6所示。

Table 5 Comparison of average remote access delay表5 平均远程访问延迟对比
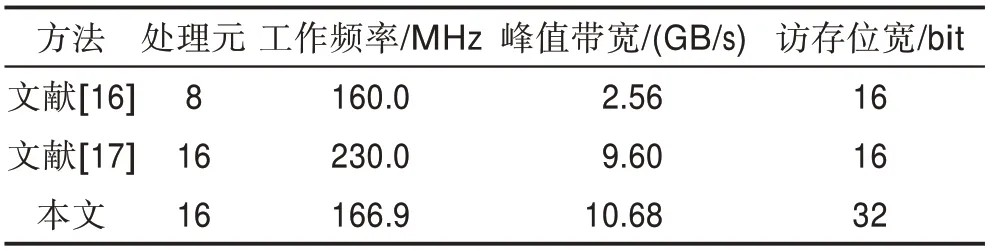
Table 6 Comparison of performance表6 性能对比
5 结论
针对阵列处理器中远程访问情况下的长延迟问题,设计一种实时动态迁移机制,以处理器对远程数据的访问频率为依据,实现对远程数据的动态调度。当处理器PEi频繁访问远程Cache行时,启用迁移机制,通过迁移互连将远程Cache行数据迁移至距离PEi最近的本地迁移查找表中,相比于不采用迁移机制的分布式Cache,平均远程命中访问延迟降低了80%。为进一步提高迁移机制的性能,在保证Cache数据一致性的情况下,对于迁移后不再被频繁访问的Cache行,通过取消迁移的操作,将其迁回至原静态映射位置。与同类结构相比,平均远程访问延迟降低了46.5%,并且工作频率与峰值带宽均有提高。通过运动补偿算法的实现,以及对远程Cache行的多种访问模式进行访存分析,对所提出的动态迁移机制进行全面验证测试。
猜你喜欢
纺织科学研究(2023年9期)2023-10-23 11:18:10
移动通信(2021年5期)2021-10-25 11:41:48
数学小灵通·3-4年级(2021年9期)2021-10-12 05:47:46
小学生学习指导(低年级)(2020年10期)2020-11-09 09:21:58
今日农业(2020年13期)2020-08-24 07:35:24
意林(2017年8期)2017-05-02 17:40:37
数学大王·中高年级(2017年2期)2017-02-08 15:52:55
学苑创造·A版(2016年4期)2016-04-16 17:57:51
医学研究杂志(2015年5期)2015-06-10 06:43:26
中国交通信息化(2014年3期)2014-06-05 03:07:09
