
双模态Logistic Regression及其应用
2020-12-14 10:21:34孔前进王世勋孙东山翟怡星
计算机应用与软件 2020年12期
吴 蕊 孔前进 王世勋,2* 孙东山 翟怡星
1(河南师范大学计算机与信息工程学院 河南 新乡 453007)2(河南师范大学智慧商务与物联网技术河南省工程实验室 河南 新乡 453007)
0 引 言
如今,智能手机等移动终端设备已十分普及,多媒体数据已经成为人们日常生活中的重要信息来源。这些数据来源丰富、结构各异、数量庞大,为了更好地挖掘多源异构数据中的信息,人们往往使用分类算法来处理这些数据。Logistic Regression是一种有效的分类算法,它能够很好地处理单一模态数据的分类问题。然而在处理这些多源异构数据时,现有的Logistic Regression不能很好地利用模态间的语义相关性,降低了分类性能。基于这个问题,本文提出可以妥善保存模态内语义信息与模态间语义相关性的双模态Logistic Regression模型,从而可对双模态数据统一建模。先设计一个同时包含模态内损耗与模态间损耗的目标函数,再用梯度下降法交替地对各个模态进行优化求解。具体地,给定一个模态的参数初始值,按照一定策略更新另一模态的参数,利用更新过的参数再更新前一个模态的参数,从而迭代地交替更新不同模态的参数。当迭代结束之后,利用Sigmoid函数将最优预测器所产生的边缘转换成语义概念类的后验概率,进而完成双模态数据的二分类与检索任务。
1 相关工作
许多学者利用分类算法解决了实际问题,并根据具体情况改进了分类算法。为了实现对短文本的分类,王杨等[1]提出了一种基于支持向量机的分类模型。为了提高分类精度;周绪达[2]利用KNN算法提出了一种识别算法,该算法能实现中文手写数字识别。此外,李佳烨等[3]提出了一种加权K近邻投票分类方法,该方法对样本数据集的近邻加上合适的权值因子,并保持了传统多数投票分类的简单性。相对于上述算法,Logistic Regression分类算法因其原理简单而被广泛应用。文献[4]利用Logistic Regression方法训练数据,进而预测样例的类标签;文献[5]利用Logistic Regression方法求后验概率。在将二分类Logistic Regression推广至多分类Logistic Regression的问题上,学者们也做了相应的工作。通过提前为分类集设定结果值列,基于HBase的多分类逻辑回归算法[6]利用块批量梯度下降法得出每个分类的回归系数,从而实现了多分类。李慧民等[7]利用多分类Logistic Regression方法建立旧工业建筑再生模式选择模型。Lin等[8]将核Logistic Regression应用于哈希函数,进而更好地实现从特征到哈希码的非线性投影。当数据类别不平衡时,周瑜等[9]在多元Logistic Regression中定义一个新的似然函数,从而提高分类性能。王鹏[10]利用核函数方法扩展逻辑回归模型,从而提高了分类性能。但上述Logistic Regression只能解决单一模态数据分类问题,无法直接处理多模态数据。多模态数据具有低层特征异构、高层语义相关的特点[11]。传统的Logistic Regression在处理多模态数据时只考虑了模态内信息,没有考虑模态间的语义相关性,这会影响到分类效果。为此提出同时包含模态内信息与模态间语义相关性的双模态Logistic Regression模型。
多模态数据包括语义相关信息,很多专家学者在挖掘多模态数据中的语义信息与建立分类模型方面做出了不懈的努力。通过设计一种多核模糊粗糙模型,张灵均[12]对多模态数据属性进行约简,实现对数据集的粗糙分类。此外,叶婷婷[13]首先对每个模态数据训练一个相应的线性回归模型,然后联合地选择多模态数据的共同特征,最后利用多核SVM的方法实现对多模态数据的分类。在处理多模态数据类别不平衡问题时,杨杨[14]划分了不同模态数据的强弱,并提取弱模态数据的最具有判别分析子空间,从而获得较好的强模态数据的预测性能。王世勋[15]提出了包含模态内损耗和模态间损耗的多模态多分类Boosting目标函数,并使用梯度下降法交替地求解每一种模态的最优预测器,实现了对多模态数据的多分类。此外,多模态分类可对跨模态检索提供技术支持[16-17]。
2 单模态Logistic Regression
已标注的数据集为(X,H)={(x1,h1),(x2,h2),…,(xn,hn)},其中:X表示数据集;H表示语义词汇表;n是数据集的大小;hi∈{+1,-1}是第i个样本的标签。m维特征向量(xi1,xi2,…,xim)是从已标注的数据集中独立抽取的样本数据,若要判断其是否属于某一类l,则只有两种情况:xi属于l类或者不属于l类。w表示特征向量的参数,Logistic Regression通过判别评分值的符号预测标签未知的样本。若评分值符号为正,该组数据属于第l类,否则不属于第l类。通过构造损失函数求解参数w。为提高模型的泛化性能,可在损失函数后加上正则项,表达式[8]为:
(1)
式中:λ是正则项系数。
对于无约束优化问题,可利用梯度下降法求解特征向量参数w。对于给定的无标签测试样本x,可根据以下的预测器判断其是否属于某语义类。
φ=sgn(xwT)
(2)
单模态Logistic Regression在多个模态数据上的分类精度并不高,这是因为它没有考虑多模态数据间的语义相关性。此外,对不同模态的数据只能分别建模并训练参数。若将单模态Logistic Regression推广到双模态Logistic Regression,也许能提高分类的性能。
3 双模态Logistic Regression
3.1 构造模型

(3)
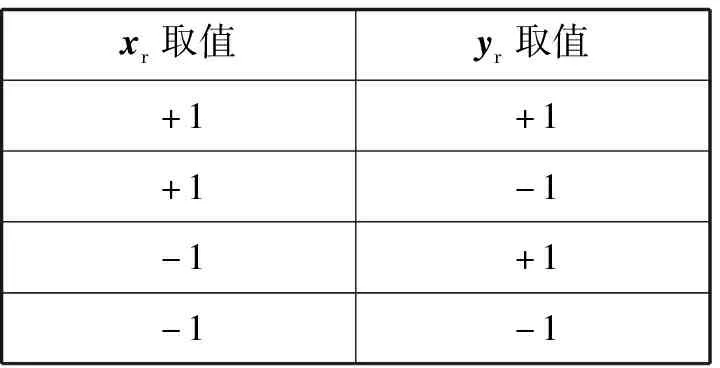
表1 两种模态的预测情况组合
为寻找不同模态的最优参数,定义风险函数如下:
R[wt,wp]=J1(wt)+J2(wp)+J3(wt,wp)
(4)
其中:
(5)
(6)
对于式(5),当k=1时,zi代指X的一个样本,hi表示其相应的标签,w表示文本特征参数;当k=2时,zi代指Y的一个样本,hi表示其相应的标签,w表示图像特征参数。
3.2 求 解
通常,梯度下降法可用于无约束优化问题的求解。固定文本特征的参数,式(4)中风险函数关于图像特征参数的一阶偏导数(其中▽表示梯度)为:
(7)
其中:
(8)
(9)
(10)
利用梯度下降法迭代地更新图像特征的参数:
(11)
其中:
(12)
式中:α0为初始步长;αj为第j次迭代的步长。随着迭代次数逐渐增大,步长逐渐减小,从而使梯度收敛。
同样地,固定图像特征向量的参数,式(4)中风险函数关于文本特征参数的一阶偏导为:
(13)
(14)
(15)
(16)
利用梯度下降法迭代地更新文本特征的参数:
(17)
对每一个模态轮流地求解,可以得到文本与图像的特征参数。给出任意未知标签的测试样本q,可通过如下的预测器来判断其是否属于某一类:
(18)
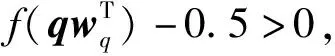
3.3 算法描述

算法1双模态LR
“ABB矢志与全中国的客户一起共创数字化未来。扎根中国,我们在中国的基础设施发展中扮演了重要角色,同时一直致力于科技创新领域的推广和投资。”ABB集团首席执行官史毕福表示。“今天,我们运用领先的ABB AbilityTM数字化解决方案和服务,帮助能源、工业、交通与基础设施领域的客户充分发掘大数据的优势来提升生产力,增强创新力,提升核心竞争力。自2017年在中国发布ABB AbilityTM以来,我们的数字化业务已实现双位增长,完美契合中国十三五计划和中国制造2025中谋划的重点产业。自去年在中国发布ABB AbilityTM以来,ABB中国的数字化业务已实现翻番。”
输出:wp,wt。
1.初始化:迭代次数j=0,文本参数与图像参数wt=0,wp=0
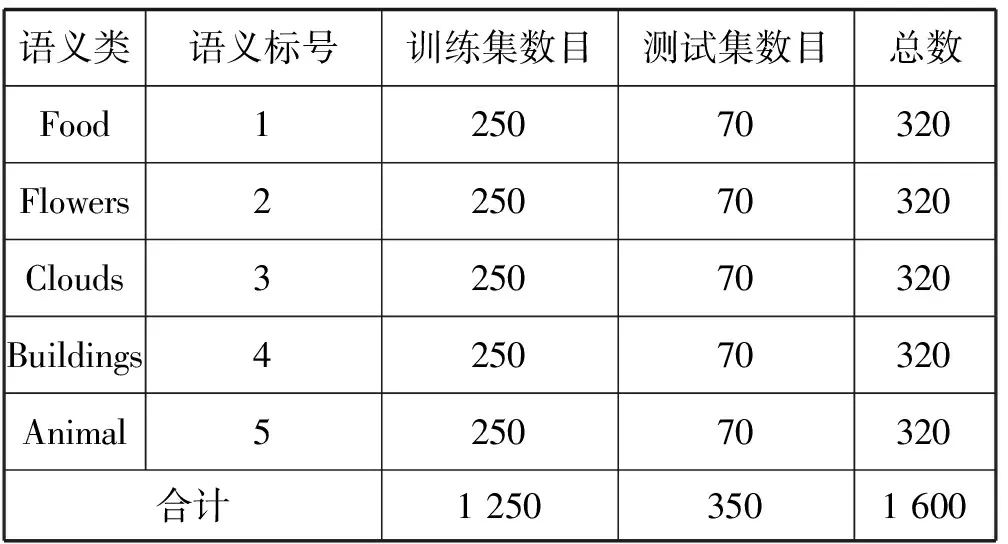
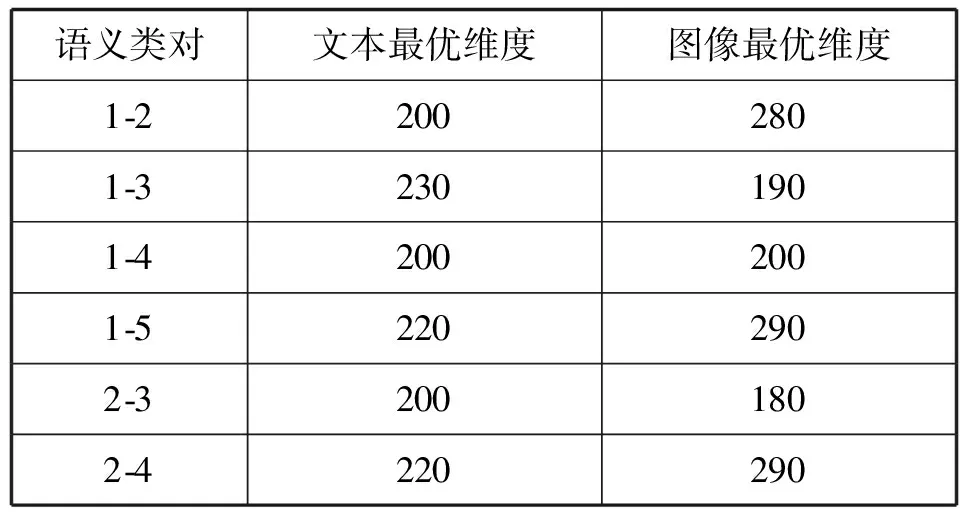
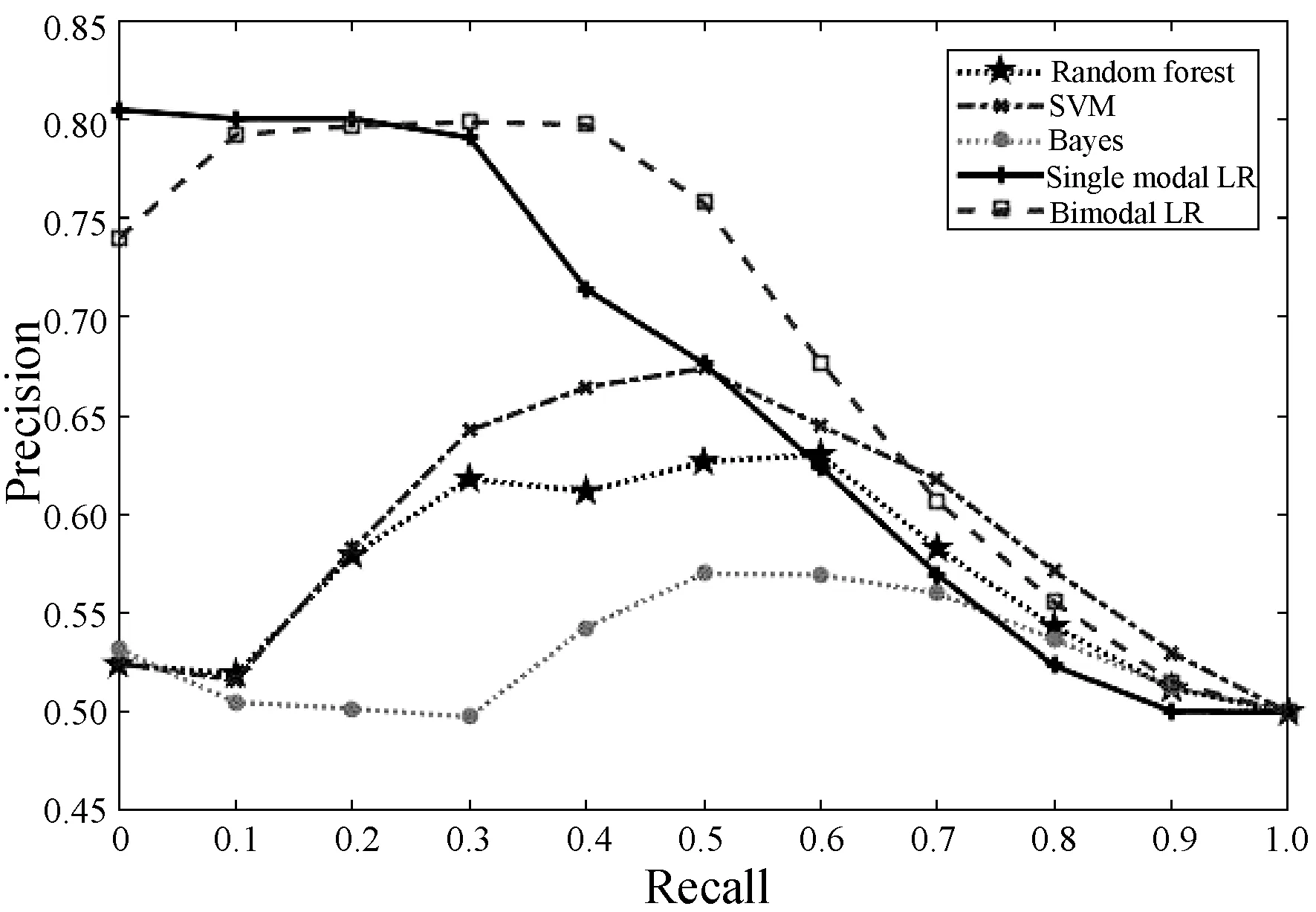
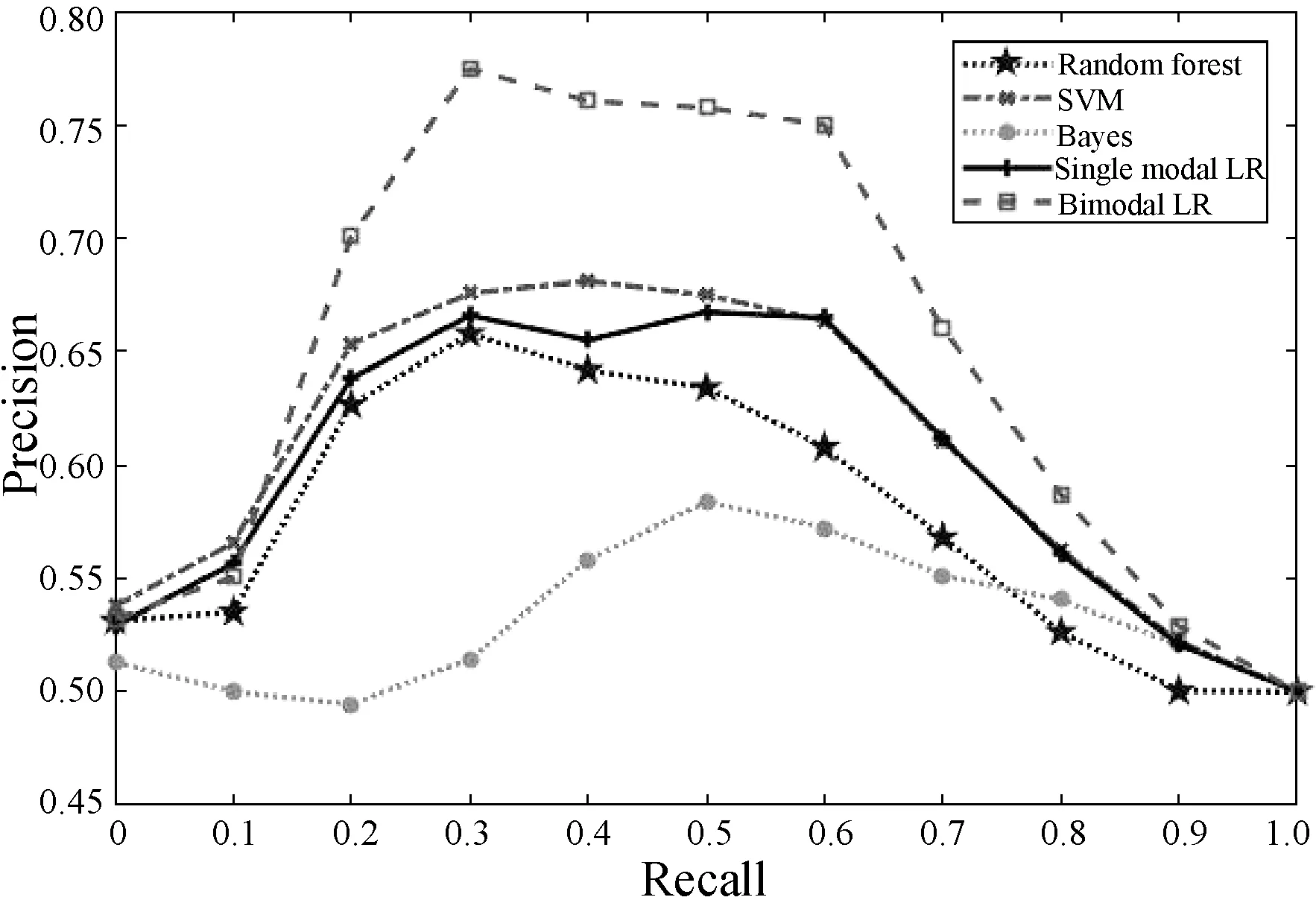
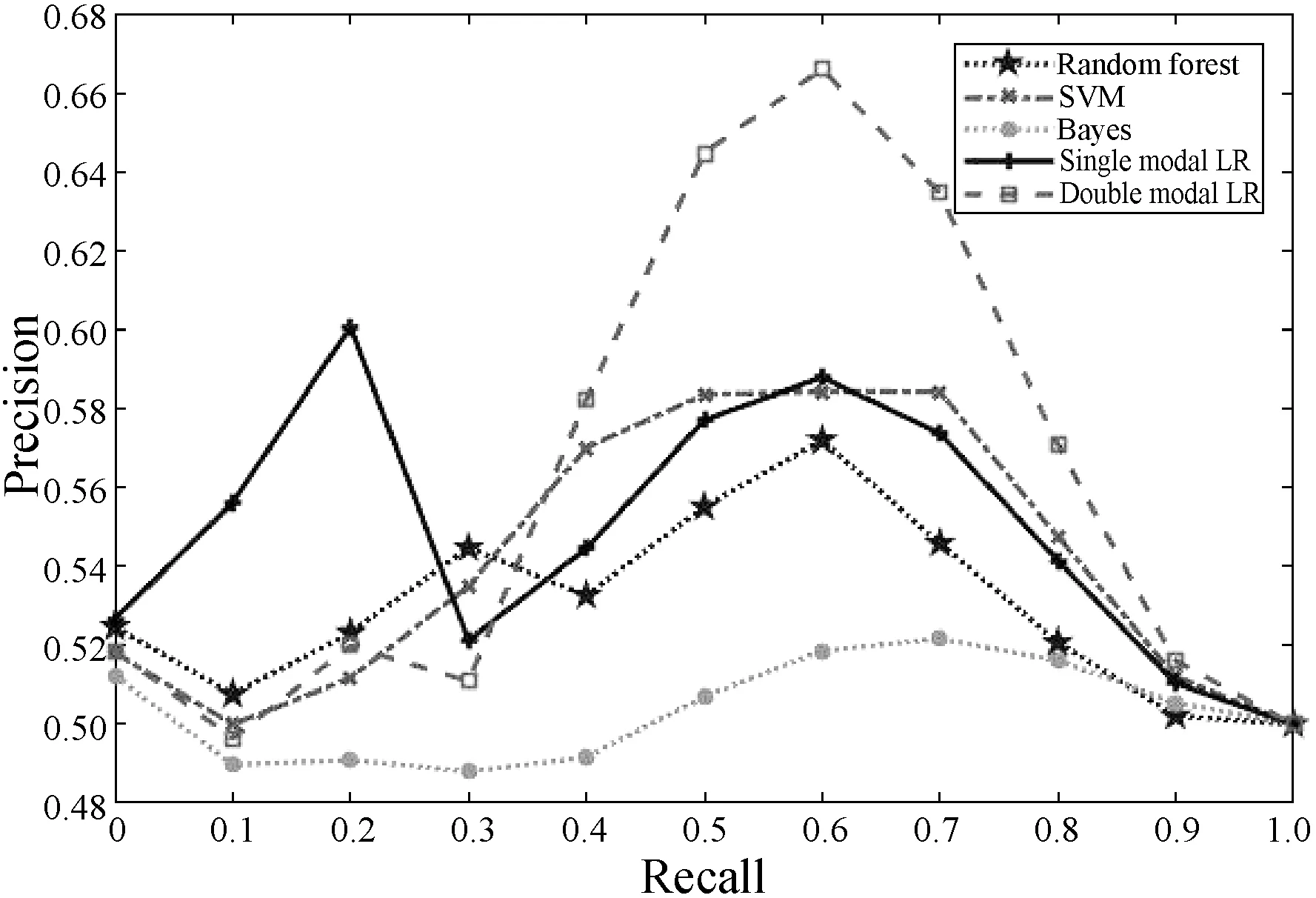
2.Whilej 8.j=j+1 9.End while NUS数据集的来源是Flickr上的图像与标注,该数据集最初包含269 648幅图像以及由81个真实语义概念所组成的词汇表。Flickr为所有的图像均提供了一些有意义的标注,因此每一个图像与其对应的标注构成了一个双模态文档,即图像文本对。类似于文献[15],采用NUS数据集中出现频率次数随机地抽取了1 600个多模态文档,并将这5个语义概念依次序标号为1、2、3、4、5。每一个多模态文档只有一个语义概念类,例如 “Food” 和“Flowers”等。每一个语义概念类包含320个多模态文档,最终的训练集与测试集分别包含了1 250个与350个多模态文档,数据集概况如表2所示。 表2 NUS数据集的概况 表3 NUS文本和图像数据集10个类对的最优维度 表3中,文本语义类对1-2最优维度为200,表示将文本Food-Flowers组降至200维。实验表明,表中每一个维度都能够保证85%以上的数据信息,并且能够很好地检索样本数据,这是因为降维操作要保证数据的可靠性。表3中得到的维度是在能够保留85%原始信息的前提下的最优维度。 先将每组NUS数据集降维到表3中对应的维度,再将双模态Logistic Regression算法与单模态Logistic Regression算法、随机森林算法、SVM算法、朴素Bayes算法在同一数据集上进行分类性能和检索效果的比较。采用AUC指标评价二分类,AUC可表述模型整体性能。AUC越大,分类器分类效果越好。双模态Logistic Regression与其他方法的AUC值如表4所示。 表4 不同方法在NUS数据集上的平均AUC 从表4中可得出SVM算法对于文本数据集分类性能较好,然而对于图像数据集却远远没有双模态Logistic Regression方法效果好。结合文本数据集与图像数据集的分类结果,双模态Logistic Regression比单模态Logistic Regression平均AUC值增长了0.229%。 平均的精度均值MAP是检索任务中常用的评价指标,它能够有效地描述模型的检索性能。MAP值越大,检索效果越好。表5中给出双模态Logistic Regression等5种方法在NUS数据集上的平均MAP值。 表5 不同方法在NUS数据集上的平均MAP 可以看出,双模态Logistic Regression方法在文本检索图像和图像检索文本这2个跨模态检索任务中超过了其他4个方法,获得了较好的平均检索性能。例如,与单模态Logistic Regression的平均MAP值相比,双模态Logistic Regression的平均MAP值为0.711,提高了1.862%。双模态Logistic Regression模型同时考虑了模态内的语义信息和模态间的语义相关性,因此,其检索性能优于单模态Logistic Regression。 此外,比较了各种模型在NUS两对数据集上的PR曲线,如图1-图4所示。可以看出,不管是文本检索图像还是图像检索文本,在这两对数据集上,双模态Logistic Regression检索效果都更好。在检索任务中,不考虑语义相关性会影响检索的性能,而双模态Logistic Regression不仅考虑了模态内的语义信息,还考虑了模态间的语义相关性,因此,检索效果比其他方法要好。 图1 Clouds vs Animal类对上图像查询文本的PR曲线 图2 Flowers vs Animal类对上文本查询图像的PR曲线 图3 Flowers vs Animal类对上图像查询文本的PR曲线 图4 Clouds vs Animal类对上图像查询文本的PR曲线 在双模态Logistic Regression分类方法中,建立一个同时包含模态内损耗和模态间损耗的目标函数。在做检索任务时,采用子空间方法,将多模态数据投影到同一个潜在的语义空间,然后进行相似性比较。在NUS数据集上的实验结果表明,双模态Logistic Regression方法检索效果比其他方法好。然而在处理高维度数据时,其训练以及测试所需时间较大,需要进一步改进。
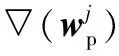

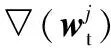

4 结果分析




5 结 语
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
意林图解作文(小学版)(2019年6期)2019-07-16 08:35:46
现代语文(2016年21期)2016-05-25 13:13:44
专利代理(2016年1期)2016-05-17 06:14:36
湖北经济学院学报·人文社科版(2015年8期)2015-12-29 05:53:07
上海电机学院学报(2015年4期)2015-02-28 14:30:00
大连民族大学学报(2015年2期)2015-02-27 08:28:11
计算物理(2014年2期)2014-03-11 17:01:39
外语学刊(2011年1期)2011-01-22 03:38:33
质量与标准化(2010年5期)2010-05-03 04:15:40
