
高光谱半监督分类的标签约束弹性网图算法
2020-12-14 09:14闫培新陈基伟孙玉宝
计算机应用与软件 2020年12期
陈 逸 闫培新 陈基伟 孙玉宝*
1(江苏省大气环境与装备技术协同创新中心江苏省大数据分析技术重点实验室 江苏 南京 210044)2(南京信息工程大学自动化学院 江苏 南京 210044)3(中国人民解放军63936部队 北京 102202)
0 引 言
20世纪80年代,高光谱遥感技术开始兴起并且得到迅速发展,该成像技术在对空间地物进行成像的同时,能够捕捉到其对应的光谱信息,因此高光谱图像呈现为一个三维数据立方体,实现了图谱合一成像[1]。每个像素可包含几十至几百个谱段,形成了近似连续的光谱曲线,反映了地表事物成分的丰富信息,可以用于识别不同的地物类型,为人类观测与认识地表事物提供了新的技术手段。目前,高光谱图像分类已经成为高光谱遥感领域的研究热点[2]。由于高光谱图像的自身特性,如光谱维度高、图谱合一成像等,在高光谱图像特征表达以及分类器设计等方面也面临着一定的挑战。
在高光谱图像的特征表示方面,学者们进行了很多尝试[3-5]。最初的方法通常直接使用光谱信息作为分类特征,由于成像噪声以及光谱变化影响,较难得到稳健的分类结果。地物在空间分布具有连续性,后续的研究表明,利用这一特性有利于提升特征的鲁棒性。为此,Pesaresi等[6]采用形态学方法来提取空间结构信息,构建形态轮廓特征(Morphological Profile,MP)。文献[7]进一步拓展形成扩展形态学轮廓特征EMP,并联同光谱信息形成空谱联合特征表示,可有效提升分类性能。
在高光谱图像分类器设计方面,主要包括监督模型、非监督模型与半监督分类模型,区别在于模型训练阶段是否使用到了带有标签的数据样本。非监督方法不依赖于样本的标签信息,主要使用聚类算法来获得高光谱像素的分布特性,但无法准确判别其类别。相比较而言,监督模型的分类效果更好,但需要大量的标定样本进行学习[8]。对于高光谱图像而言,训练样本的标定需要消耗大量的人力与物力成本。半监督分类模型充分利用高光谱图像有限的标记样本和大量的未标记样本进行联合学习[9],有效缓解了高光谱图像训练样本不足的问题,有助于提高分类性能。
诸多文献研究了高光谱图像的半监督分类算法[10-11],基于图模型的半监督分类是其中主流方法之一[12-14]。该类方法将每个样本作为图的顶点,并通过边连接将少量标定样本的标签信息传播给近邻,在图拉普拉斯约束下实现各顶点的标签预测,构建有效的图模型是该类方法的研究重点。Camps-Valls等[15]利用复合核函数计算样本间的相似性,并为每个顶点选择最为相似的k个顶点建立边连接,即经典的K近邻法(K-Nearest Neighbors,KNN)构图。不同于核函数度量的近邻选择方式,基于表示的构图方法通过样本在字典上的表示系数来建立边连接,例如:文献[16]提出了l1稀疏图模型,利用数据的稀疏表示选择近邻样本,文献[17-18]中将l1稀疏图应用于高光谱半监督分类问题,并使用EMP作为顶点特征建立稀疏图模型。也有文献通过构建超图模型[19]表示高光谱数据,不同于常规图的两两顶点连接,超边可以同时连接多个顶点,有利于表示高阶的复杂关系。
构建有效的图表示模型是高光谱图半监督分类算法的关键[20]。然而当前算法在构图过程中并未能充分利用给定的样本标签信息,比如不同类的样本不应存在边连接,同类样本应建立连接等。为此,本文提出了高光谱图像半监督分类的标签约束弹性网图算法,如图1所示。在特征表示上,联合了光谱信息和形态学剖面的空间信息作为样本特征。在构图方法上,充分利用给定的样本标签信息,经过标签传递形成各顶点间的标签约束,自适应选取符合标签约束的像素作为表示字典;基于所构建的字典对每个像素点进行弹性网表示,以表示系数作为边连接权重,进而构建高光谱图像的弹性网图模型;基于所构建的图模型,实现半监督分类。在Indian Pines和Salinas Scene数据集上同多个现有算法进行对比,本文算法获得了更优的分类结果,验证了其有效性。

图1 高光谱半监督分类的标签约束弹性网图算法
1 标签约束的弹性网表示模型
本文将各高光谱像素视为图的顶点,基于标签约束的弹性网表示建立边连接,有效捕获高光谱像素间的内在关联结构。具体而言,考虑到高光谱图像的空谱关联性[21],本文联合空间EMP与光谱特征作为顶点的特征表示:
(1)
式中:X为光谱特征矩阵;EMP为EMP特征矩阵,由每个像素点x的EMP(x)特征向量联合而成,EMP(x)={MPPC1(x),MPPC2(x),…,MPPCm(x)}由m个主成分(PC)的MP特征联合组成[22],每个PC的MP特征由不同圆形结构元素在像素点x处进行开操作和闭操作得到;n是半径不同的圆形结构元素的个数,则一个MP特征维度为(2n+1),d是光谱波段的数量,N为样本数量。
不同于现有模型直接将所有样本自身作为字典的方式,本文利用标签约束信息对每个样本构建对应的表示字典,建立标签约束的弹性网表示来生成图模型,有利于提升构图的准确性。整个模型的框图如图2所示。

图2 标签约束的弹性网表示
1.1 标签约束的字典生成
文献[16-18]针对顶点集中每一顶点,将其他所有顶点作为字典进行稀疏分解,由于字典中包含了所有类别的顶点,这增加了误选不同类别顶点作为近邻的概率,同时增加了样本系数分解的复杂度。本文利用给定的样本标签,通过标签传递形成顶点间的标签约束矩阵,标识各顶点间属于同一类别的置信度,进而利用该信息,可选择置信度高的像素作为当前样本的表示字典,有利于降低误选不同类别顶点作为近邻的概率。
由于高光谱图像只存在少量有限的样本具有标签约束信息,所以希望通过初始的标签约束信息,将其传递到无标签约束的样本上,使得所有样本之间都拥有标签约束信息。
首先,定义初始约束矩阵Z=[zij]N×N如下:
(2)
然后,通过高斯核函数度量样本之间的相似性。成对约束的传递可以看作一个两类的半监督学习问题,具体可以定义为[23]:
(3)
式中:δ>0为正则化参数;tr为矩阵的迹算子;Z是初始约束矩阵;L是图的正则化拉普拉斯矩阵;U是期望获得的标签约束矩阵。
式(3)具有解析解,标签约束矩阵U计算如下:
(4)
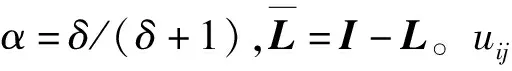
基于获得的标签约束矩阵U,可为每一顶点构建标签约束的字典。对于高光谱图像的每一个像素点xi,根据标签约束信息Ui,挑选出前M个置信度最高的像素xj构建标签约束字典Di:
Di={xj|RM(Ui),j≠i}
(5)
式中:RM(Ui)表示选取Ui中前M个最大置信度的像素作为字典原子。根据标签约束信息,只有与当前顶点类别最为一致的样本才会被选中作为字典的原子,有利于提升后续分解的准确性。
1.2 标签约束的弹性网表示
基于式(5)的字典生成方法,本文进一步构建高光谱图像的弹性网表示模型,该模型在l1约束的基础上加上l2惩罚项[24],能够度量非零系数间的相关性,选取多个相关的样本来表征当前样本。
基于每个像素点构建的标签约束字典,进行弹性网表示,获取样本稀疏表示的系数矩阵。关于构建标签约束字典的方法,已在1.1节中详细阐述,由式(5)即可得到。通过求解下面的约束优化问题找到数据集X中所有像素点的弹性网表示[25]:
(6)
s.t.xi=Dici+ei1≤i≤N
式中:ci是xi基于字典Di获得的表示系数;C=[c1,c2,…,cN]是系数矩阵;E是表征误差矩阵;λ和γ是正则化参数。本文使用最小角回归法(Least Angle Regression,LARS)求解式(6)的模型,可获得所有样本的表示系数矩阵C。
2 半监督分类算法设计

本文利用前l个样本的标签信息,通过式(4)获得标签约束矩阵后,进一步求解式(6)的标签约束弹性网表示模型。根据每个样本点的弹性网稀疏表示系数C可以构建用于半监督分类的图模型,样本之间的系数可以直接作为边的权重:
(7)
进一步建立该图上的半监督分类模型,对高光谱图像进行分类。图的半监督学习模型可以表示为以下正则化问题:
(8)
式中:第一项约束前l个样本的预测标签与真实标签应趋于一致;第二项约束预测标签分布的光滑性;Δ是标签约束弹性网图的拉普拉斯矩阵,Δ=I-D-1/2WD-1/2;D为所构建图的度矩阵;tr为矩阵的迹算子;μ是正则化参数,权衡两项的作用。
式(8)可通过迭代算法进行求解,迭代F(t+1)=βΔF(t)+(1-β)Y直至收敛,其中β∈(0,1)。F*是{F(t)}的收敛值,最终的优化解析解可以表示为:
F*=(I-βΔ)-1Y
(9)
根据获得的矩阵F,每个样本的类别判别为:
(10)
完整的算法流程参见算法1。
算法1高光谱半监督分类的标签约束弹性网图算法
输入:高光谱数据矩阵X,初始标签约束矩阵Z。
输出:分类结果f1,f2,…,fn。
1)构建空谱联合特征。
2)根据式(4)进行标签传递得到标签约束矩阵U。
3)根据U针对每个像素点构建字典Di。
4)根据式(6)求解标签约束的弹性网表示,获取系数矩阵C。
5)构建高光谱图像的标签约束弹性网图模型,计算拉普拉斯矩阵Δ=I-D-1/2WD-1/2,W是邻接矩阵,D是度矩阵。
7)依据式(10)判别各像素点xi的预测标签fi。
3 实 验
为了验证本文提出的高光谱图像半监督分类的标签约束弹性网图算法(LCE+SSL)的有效性,将其与以下几种方法进行比较,包括:
1)只使用光谱特征的支持向量机进行像素分类(PX+SVM);
2)采用支持向量机对扩展形态学特征和光谱特征级联的像素进行分类(EMP+SVM)[7];
3)文献[15]中提出的基于图的半监督学习(Graph+SSL);
4)利用形态学属性剖面的稀疏表示进行分类(SR+EMAPs)[18];
5)对空谱联合特征仅使用高斯核构图的半监督分类学习(GGraph+SSL);
6)空谱联合特征的标签约束高斯核构图的半监督分类学习(LCG+SSL)。
本文采用以下定量指标来评估分类结果的性能:每类样本分类的准确率,所有样本分类的总体准确率OA,各类样本分类的平均准确度AA,Kappa系数。
3.1 高光谱数据集
本文所使用的高光谱图像数据集主要为:
1)Indian Pines(IP)高光谱数据集。该高光谱数据集是20世纪90年代由AVIRIS传感器采集的印第安纳州西北部的Indian Pines实验基地图像。其图像大小为145像素×145像素,原始波段去除掉24个受干扰的光谱波段,一般使用留下的200个光谱波段进行实验,地面分辨率为20 m×20 m,地面覆盖物的类别一共有16类。
2)Salinas Scene(SS)高光谱数据集。该高光谱数据集也是由AVIRIS传感器所采集的,是美国加利福尼亚州Salinas山谷上空的图像。图像大小为512像素×217像素,原始波段去除掉20个不可用的光谱波段,使用留下的204个光谱波段进行分类实验,地面分辨率为3.7 m×3.7 m,地面覆盖物的类别一共有16类。
3.2 实验设置
由于高光谱图像的特殊性,利用构图来进行分类时,直接处理整个高光谱图像会导致非常大的计算负担。例如IP数据集的大小为145像素×145像素,如果对其直接进行构图,其权重矩阵的大小为21 025×21 025,所以在进行实验的时候选择将其分割为大小约为73像素×73像素的不重叠小块,逐一对其进行处理与实验,最后再合成观察实验效果。
关于实验中两个参数α和β对分类性能的影响,从给定的集合{0.1,0.3,0.5,0.7,0.9}中选取这两个参数进行实验。经过大量实验对比,找到最优的α和β以获得最好的分类效果。
3.3 实验对比
在每个数据集中,分别从每个类中随机选取10%的像素作为标签样本。分类结果分别见表1和表2,最优的结果用粗体显示。

表1 标签样本为10%的IP数据集的OA、AA、Kappa系数和平均类准确率 %

表2 标签样本为10%的SS数据集的OA、AA、Kappa系数和平均类准确率 %
表1列出了各算法在Indian Pines(IP)高光谱数据集上的实验结果,在使用支持向量机的两个实验中,通过OA、AA、Kappa系数三个指标来观察,EMP+SVM的分类效果明显优于PX+SVM,由此可以学习到空谱联合特征的使用确实可以提升分类效果。Graph+SSL也取得了不错的分类效果,与SVM不同的是,基于图的方法将标签通过边传播到近邻的顶点上,使其获得正确标签达到分类的结果。另外利用EMAPs的稀疏表示模型和高斯核构图的方法在分类效果上有了大幅度提升,可见构建特征表示的模型方法也很重要。与GGraph+SSL相比,LCG+SSL在构图时利用到了标签成对约束信息,三个指标都有所提升,特别是AA得到了很大的提升,可见标签约束对构图及分类效果的提高起到相当可观的作用。LCE+SSL与LCG+SSL相比,虽然在构图时都使用到了标签约束信息,但是构图时使用弹性网的方法,进一步提升了分类准确性。综上所述,从OA、AA、Kappa系数三个方面结合来看,本文提出的高光谱图像半监督分类的标签约束空谱联合特征弹性网图算法(LCE+SSL)比其他方法得到的分类效果都要好。本文方法不仅在三个指标上都达到了90%以上的正确率,并且在每类样本的分类上都达到了很好的效果。由于部分样本的训练样本数量较少,如第1类、第9类等样本,因此其他方法分类的效果都比较差,而本文方法的分类效果明显有了很大的提升。
图3为IP数据集上各个实验的分类效果图,可以看出本文方法的分类图出错率更低,分类效果更好。

(a)假彩色合成图像
表2是基于Salinas Scene(SS)高光谱数据集进行的实验,与IP数据集一样,选择从每类样本中随机选择10%的像素作为标签样本。该数据集由于每类样本的分布较为均匀,所有的算法基本上都可以达到比较不错的分类效果,尤其是本文方法,更是达到了99%以上的优异效果,有些样本的分类正确率甚至达到了100%。该数据集的分类效果图如图4所示。

(a)假彩色合成图像
实验结果证明,本文方法总体上的分类效果最优,利用标签约束信息的弹性网构图有助于提高分类准确性。
4 结 语
针对高光谱图像的分类问题,本文提出了一种标签约束的弹性网表示图模型用于高光谱图像半监督分类。在特征表示上,选择将空间特征与光谱特征相联合构成空谱联合特征。在弹性网分解时利用了标签约束信息,降低了计算复杂度,使得构图更加准确。在基于图的半监督分类模型上,本文使用两个高光谱图像进行多次实验,采用六种方法与本文的方法进行对比,实验结果均表明,本文方法具有较好的分类性能。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
黑龙江大学自然科学学报(2022年1期)2022-03-29
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
电子技术与软件工程(2020年4期)2020-06-10
小学阅读指南·低年级版(2017年1期)2017-03-13
人生十六七(2015年6期)2015-02-28
食品工业科技(2014年23期)2014-03-11
计算机辅助工程(2012年5期)2012-11-21
中学生数理化·高一版(2009年6期)2009-08-31
