
顾及相干系数的InSAR形变场采样算法
2020-12-05 01:54:56孙凯孟国杰洪顺英董彦芳李成龙
遥感信息 2020年5期
孙凯,孟国杰,洪顺英,董彦芳,李成龙
(1.中国地震局地震预测研究所 地震预测重点实验室,北京 100036;2.中国地震局地质研究所 地震动力学国家重点实验室,北京 100029)
0 引言
近20多年来,合成孔径雷达差分干涉技术(differential interferometric synthetic aperture radar, DInSAR)在测量地震形变场、监测山体滑坡、城市地表沉降以及火山运动等领域发挥出重要的作用,其中应用最有效且最广泛的是获取地震形变场[1-4]。利用DInSAR技术能够轻松获得受灾区域大面积的、连续空间覆盖的高精度形变数据,有效弥补了常规全球定位系统(global positioning system, GPS)观测中人工布设台站数目不足、易受灾害损坏以及信息采集困难等缺陷,为研究断层活动性质、地壳形变特征提供了定量化的基础数据[5-7]。形变场数据集为反演模型提供稳定的数据源。为了提高反演计算效率和减少信息冗余,InSAR形变数据需要进行降采样处理,并且在尽可能提高数据压缩率的同时,确保反演数据源中形变信息的完整性和可靠性。
不同于常规的数据压缩技术,形变数据降采样就是通过最少的数据量同时体现原形变场整体区域状况和局部重要细节特征。对于较为平滑的地表形变图,Pritchard等[8]提出一种规则采样法,通过计算邻近像素值的均值,近似代表局部像元包含的形变特征,该方法计算简便,但必须在影像细节特征和数据压缩程度二者间进行取舍,不适用于形变特征差异大的震区形变场。Simons等[9]采用影像像元分解思路,有效提高数据压缩率的同时,保留了形变场的细节特征,但该方法并未考虑采样点数据质量。张静等[10]提出一种基于InSAR数据空间相关性建立协方差函数来设定四叉树分解参数的方法,通过减少相位突变提高数据连续性,消除数据中的部分高频噪声。
现有降采样方法缺少依据InSAR干涉特性评价形变信息的可靠性。由于雷达侧视成像几何特性和InSAR数学模型的限制,目标区域地表反射特性随时间变化造成的时间失相干和空间基线导致的空间失相干都会影响InSAR干涉质量,干涉质量决定了干涉相位信息的可接受程度,反映了最终形变信息的可靠性[11]。因此,相干性可作为描述影像相位噪声水平和评价干涉图质量的指标。基于此,本文提出一种顾及InSAR相干系数的概率采样算法,估算自适应滤波后的干涉像对相干性系数作为四叉树分割约束参数,对待分割窗口内相干性系数进行自适应核运算得到相干表征量,并根据归一化后的形变信息和相干性信息,合理分配形变梯度和相干表征量之间的权重,计算接受概率,获取窗口分割指令。同时,依据数字高程模型和原始形变图无效值(not a number,NaN)生成掩膜文件,去除采样结果中的虚假信息,整体提高了反演数据源的质量。本文通过获取中国台湾地区美浓Mw6.7级地震的形变场来验证该算法的可行性,并对采样点数据质量进行定性与定量分析。
1 顾及相干系数的概率采样算法
本节在回顾经典四叉树分割算法的基础上,引入相干性系数作为额外约束参数,并结合当前待分割窗口的像元分布状况建立自适应概率采样模型。
1.1 四叉树影像分割
InSAR形变场降采样的目的是以最少的采样点达到原始影像的整体最佳逼近。对于规则采样等传统降采样方法而言,较少的采样数目和具体的细节特征不可兼顾,因此,必须合理化参考影像内容特征进行自适应采样。作为基于遥感图像内容均匀性检测的压缩算法,自适应四叉树影像分割成为形变场降采样的主流手段。
自适应算法主要思想是根据给定数据特征的参数条件,决定待处理数据下一步指令的过程。四叉树分割算法通过引入用于二维空间数据分析的四叉树,对每次下达指令后满足分割条件的局部影像进行编码。如果满足分割参数要求,则影像的当前窗口被分割为大小一致的4个方形,持续该步骤直至最小分割阈值。因此,为满足后续数据处理要求,地理编码后获取的原始形变图需经裁剪、填充,使其大小满足分割阈值的正整数倍。Jonsson[12]最先把四叉树影像分割应用于形变图降采样,将原始影像分割为4个象限,计算各象限均值,如果像元均值的均方根不满足阈值要求,则把每个象限再次分割为4个新象限,继续计算各象限像素均值的均方根并与阈值作比较,迭代该过程直至收敛。在实际采样过程中,为提高算法运算效率以及局部分割能力,一般直接将计算出的各象限最大梯度值作为参考条件,即把视线向形变量梯度值作为唯一参数,各形变图窗口进行自适应分割。但该算法只关注了形变量的数值特征,并未考虑其自身数据质量。因此,需要引入额外的描述数据质量的特征参数,约束影像分割指令,如干涉影像的相干性系数,提高采样点质量以确保反演模型解算结果的可靠性。
1.2 相干系数计算与数据预处理
利用InSAR技术获取高程模型和形变场的信息质量取决于干涉相位质量。干涉相位质量由2幅单视复数(single look complex,SLC)影像对应分辨单元内总回波信号矢量值之间差异程度决定。地物反射特性随时间的变化以及空间基线过长、卫星轨道控制误差引起的时空失相干等因素都会影响SAR影像之间的干涉质量,一般用相干系数作为评价相干性的指标。在实际数据处理过程中,利用式(1)所示的窗口估计方法求得归一化相干系数近似值[13]。
(1)

SAR影像使用雷达坐标系统,为便于后续数据分析,本文在计算主从SLC影像相干系数估计值后,基于轨道信息和成像参数将相干系数图由雷达坐标系地理编码至WGS84坐标系统。同时,如上文所述,依据四叉树算法输入数据大小要求和实际形变场分布特征,对所获取实验区域的形变数据和相干质量数据进行裁剪,并进行NaN值填充,以便于整体采样。NaN值填充一般采用邻近像素均值插值法,但对于存在NaN值较为集中分布的情况,如水体等低相干区域,均值窗口太大,会造成交界处梯度过大,导致局部四叉树分割窗口中引入额外的虚假信息;而在区域面积大的情况,设置较小的均值窗口,则会降低算法效率。因此,本文提出一种适用于四叉树采样的扩散填充方法,首先以四叉树最小分割窗口大小建立初始窗口,从NaN值和有效值交界处进行均值插值,向外扩散插值的同时,窗口扩大为前一个窗口的2倍,直至完全填充。NaN值分布主要有3种情况:小区域、内部大区域和影像边缘大区域。对于小区域的NaN值而言,利用均值计算基本不会引入误差,因此可以不用建立掩膜文件。对于大区域的NaN值,主要是防止边缘梯度过大,免于增加交界处有效信息区域多余采样点,而对于区域内部可生成掩膜文件,采样结束后剔除该区域内部的采样点。图1是对64像素×64像素的模拟数据以1×1的初始窗口得到的填充结果和掩膜文件,其中模拟数据中白色部分为NaN值区域。
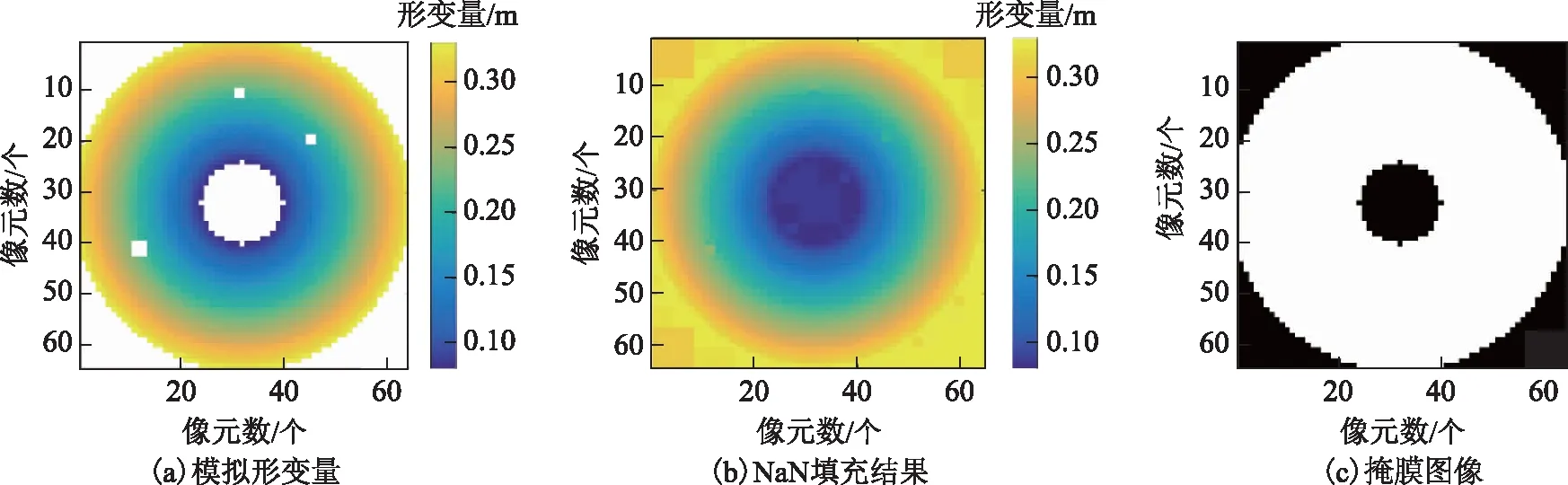
注:掩膜图像中黑色表示掩膜区域;白色表示保留区域。图1 模拟数据扩散填充结果和掩膜文件
1.3 基于相干系数的概率采样模型
不同于近似规则分布的形变场数据,相干性系数整体关联特征不明显且受局部区域多因素影响,所以在设定整体相干阈值的同时,还需要设立一种描述局部窗口总相干特征的物理量,近似体现窗口数据质量。因此,本文在给定相干系数阈值的同时,建立了描述窗口内像素值接受程度的核函数K,相干系数值核运算后获得窗口整体相干表征量γk。该窗口相干表征量γk的表达如式(2)所示。
(2)
式中:2n表示当前窗口大小;γr,c和Kr,c分别代表窗口内r行c列相干系数值及其核元素值。
在当前待分割窗口内,对于满足整体相干阈值γg的像素,其对应核元素设为1,不满足阈值要求设为k。以图2中4×4矩阵为例,假定整体相干性阈值是0.5,创建对应的核。
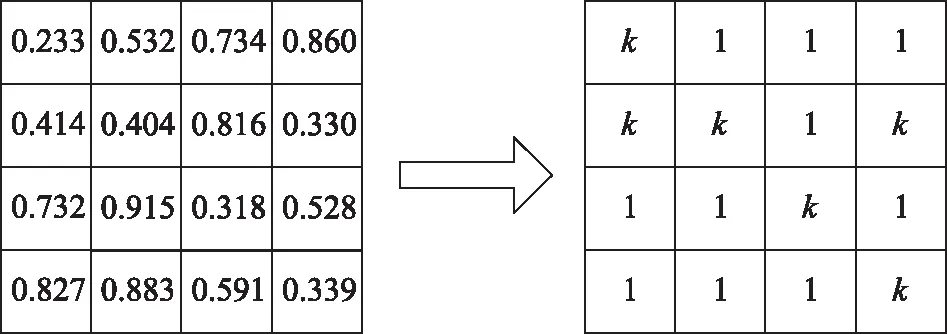
图2 核创建示意图
k值的大小决定了低相干像元在整体相干表征量中的权重,在相同大小窗口内,k值越大,低质量点位相干系数权重越高,γk的值越小,接受程度越低。图3表示在大小为4×4窗口内,低相干数目m分别是1、5、8、11和15时,低相干像元对整体表征量的影响程度关于k值的变化曲线。其中,4个*号点代表高、低质量2种像元点对整体表征量影响程度相等时k值的取值。当2种像元点数目相同时,k值取1,影响程度相同,随着低相干点位数目的增加,k值左移。在实际情况下,k取值一般在1到2之间,以保证在提高低相干点位对采样结果影响程度的同时,均衡高相干质量点位权重,以免导致采样点过少丢失重要细节信息。
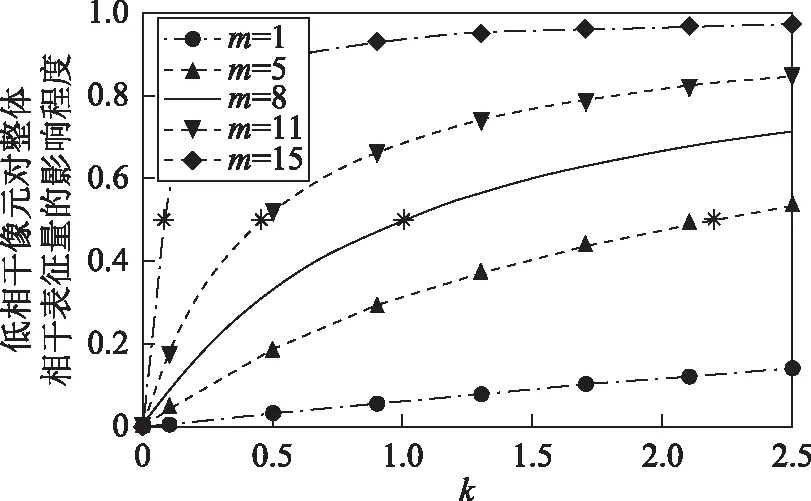
图3 低相干像元数目和k值对整体表征量影响曲线
本文算法中,形变梯度值和整体相干表征量同时作为四叉树分割的约束参数,而整体相干表征量可在归一化的相干系数值基础上计算得到,并且核运算结果并未改变其定量本质,因此,只须对形变量做归一化处理。经归一化处理后,更利于概率函数中变量权重因子的分配和调节,扩大算法优化空间。相较于常规的全局相干系数阈值降采样方法而言,本文新算法提高整体阈值γg的同时,设定了一个较低的极限阈值γ′,一般设为0.1至0.15之间,以确保合理采样较低相干点中的关键细节形变信息。当待分割窗口形变梯度满足阈值要求,而相干质量小于整体阈值时,局部窗口的下一步指令由梯度值和相干表征量综合决定。基于sigmoid函数单调、映射区间处于0到1之间、关于中心对称等特点,经适当变换创建接受分割概率函数如式(3)所示。
(3)
式中:τ是根据sigmoid函数在自变量大于4后因变量变化趋于平缓,近似为1的性质,作为压缩常量,一般取4到8之间即可,默认值为6;α和β分别是归一化后的形变量和相干表征量的权重系数;d′和γ′是形变梯度阈值和相干系数极限阈值;x=α·d+β·γ,d和γ是当前窗口的最大形变梯度和整体相干表征量。系数α和β的比值越大,则采样更偏重于低质量区域中的形变信息;反之,更偏重当前窗口的相干性,可根据实际采样要求进行设置。分割概率曲线如图4所示。
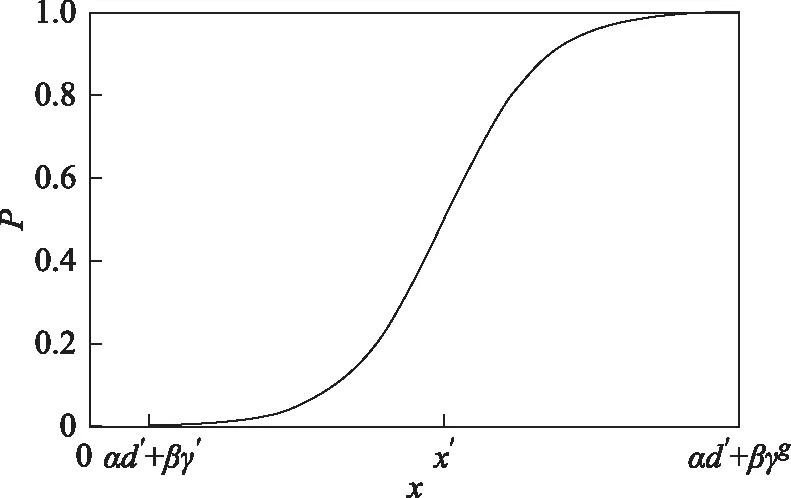
图4 分割概率曲线
该算法从整体到局部,结合形变信息、相干信息对形变场进行四叉树分割,理论上可以有效保留细节形变特征和增加高质量像元的采样率,但一定程度上不能高效判别形变场附近山体叠掩引入的虚假形变信息。因此,考虑利用该地区的数字高程模型,设置合理的高程阈值并优化上文中的掩膜文件,从而保证采样点的可靠性。图5为算法主要部分的流程图。
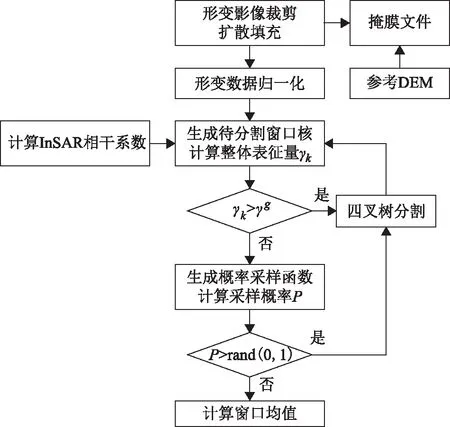
图5 基于相干系数的概率采样算法流程图
2 应用实例
为了验证本文算法的实用性和可靠性,选取2016年2月6日中国台湾地区美浓Mw6.7级地震作为实例分析,获取2016年1月9日和2016年2月14日的一对欧空局Sentinel-1A数据进行干涉处理,并引入30 m分辨率的SRTM DEM作为参考地形数据,使用GMTSAR软件获取升轨形变场。裁剪其中大小为4 096像素×4 096像素的形变区域进行算法实验和结果评价。
为保证同时顾及形变场的形变特征和质量特性,设置核元素k值为2,顾及形变特征的同时更注重像素值质量。极限阈值γ′设为1.5,根据待分割影像窗口内部像元质量分布情况创建相应的核,计算出相干表征量γk。由于实验区整体相干质量较低,为提高采样结果整体质量,整体阈值γg设为0.7,采样高质量点位的同时,合理分配较可信点位的接受概率。
图6给出了本文提出的优化算法的采样结果和常规四叉树采样结果的对比,为保证实验结果分析的合理性和公平性,2种采样算法的形变特征分割指令都是基于形变场归一化后,以0.25作为形变梯度阈值获得。其中,原始形变图中的R1、R2矩形框,L1、L2线段分别作为局部采样结果对比分析区域和远距离剖线分析区域。为合理呈现整体对比结果,本文在图6中给出算法最终采样结果的同时,统计掩膜处理前2种采样算法所获取的点位在不同质量区间的数目,绘制直方图进行直观对比。图6(e)是根据扩散填充法生成的NaN值区域以及高程大于1 000 m的山地区域生成的掩膜文件。对比常规四叉树和优化算法的采样点分布图(图6(c)和图6(f))以及数字高程模型,形变场右上角和右下角采样的虚假形变信息可以被很好地去除;同时,整体数据量由16 777 216个分别减少至5 815个(图6(c))和2 853个数据点(图6(f))。相对于经典四叉树采样,优化算法数据点数目下降了50.94%;掩膜之前数据量为4 285个,同比下降26.31%。在一定程度上,优化算法在保持形变特征的同时,压缩了采样点数量,从数据源本身提高了后续反演的计算效率。并且,由优化算法影像分割示意图(图6(d))和最终的优化采样结果(图6(f))可知,本文算法能够较好地保留形变场的整体形变信息。根据在不同相干系数区间采样点数目的统计直方图(图7)可知,相干质量越低的区间,采样点数目大量减少,例如0~0.3相干区间采样点数目降低了43.66%,而对于相干性系数大于0.5的采样点几乎都被接受。
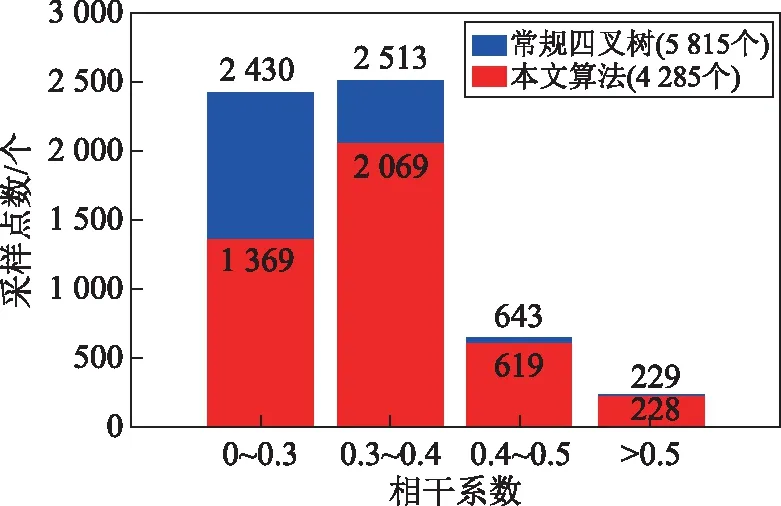
图7 掩膜前不同相干系数区间采样点数目统计图
图8是R1、R2区域基于经典四叉树和本文算法的影像分割过程示意图,以及相应区域的相干性系数图。由图8第1行(R1)可知,在局部相干质量较差时,本文算法在保证形变特征充分采样的前提下,有效减少了低质量点位的采样数目;而对比第2行(R2)的结果,局部影像左下区域和右下区域相干性系数较高,采样点数目并未减少。因此,本文算法可以在相干质量分布具有明显差异的局部区域进行高效率自适应采样,从而提高整体采样的可靠性。同时,本文给出2条主形变剖面的形变量变化曲线(图9),无论是整体变化特征还是局部细节特征都可以被完整地保留,体现了本文算法的可靠性和采样优势。如表1所示,计算原始形变场、常规四叉树及本文算法采样结果的均方根值(root mean square,RMS)作为有效值评估参考,计算结果表明3种数据RMS大致相当,说明有效信息采样率很高。本文算法运算时间比常规算法长,但在可接受范围内。
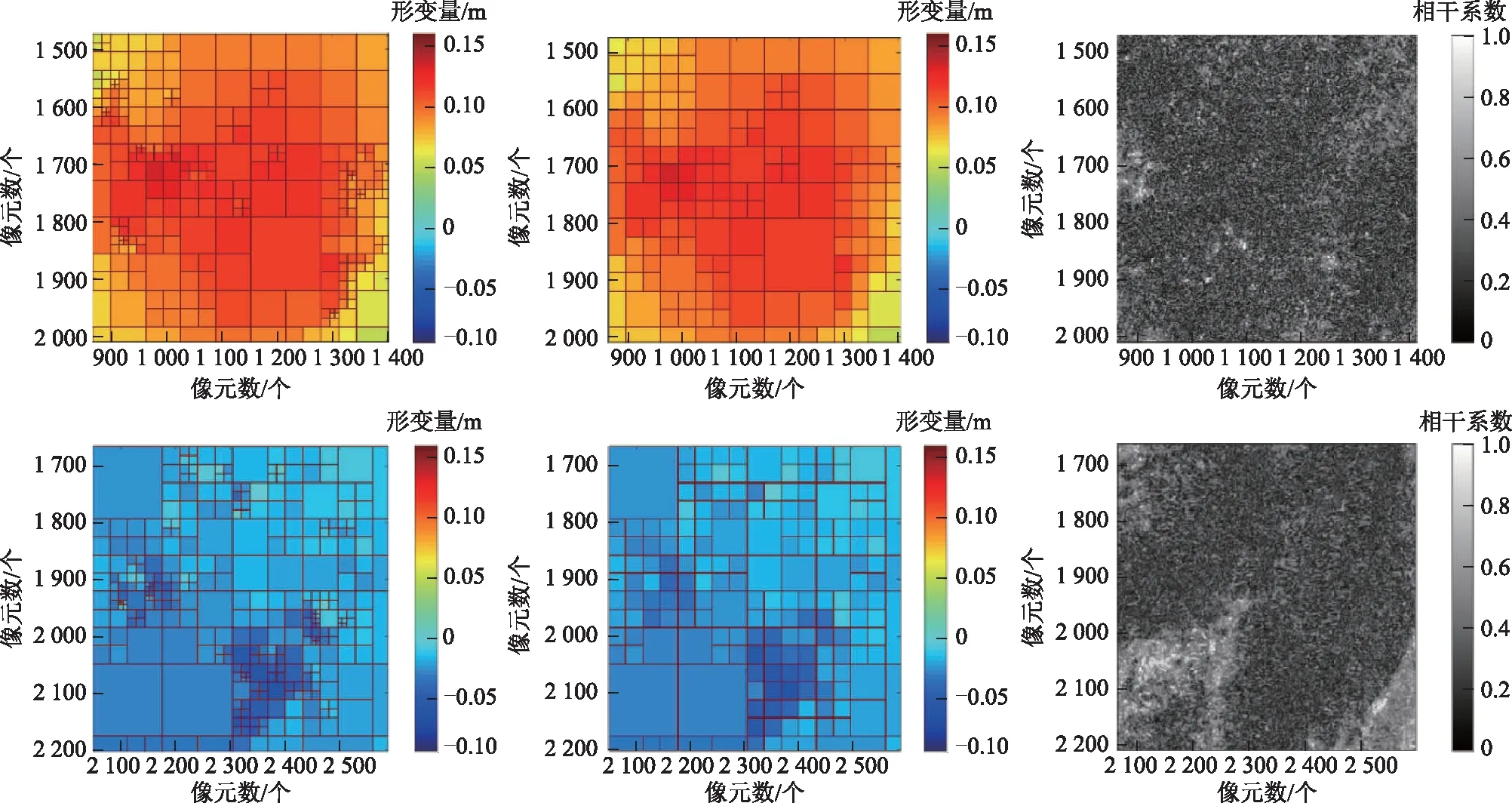
图8 局部R1和R2区域采样结果
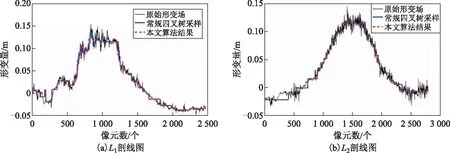
注:剖线方向为从左至右。图9 局部L1、L2形变采样结果

表1 采样算法结果对比
3 结束语
本文提出了顾及InSAR相干系数的自适应概率采样算法,并给出数据降采样处理的过程模型,即“影像扩散填充—计算形变梯度和相干表征量—计算局部自适应接受分割概率—掩膜”。通过对2016年中国台湾地区美浓Mw6.7级同震形变场进行采样实验,充分证明了该算法的可靠性和有效性。
依据真实数据的定性定量分析,将形变场相干性系数作为影像自适应分割的约束参数,能够同时从整体和局部上兼顾细节形变特征和数据质量特征,弥补了目前形变场降采样模型缺少考虑InSAR干涉质量的缺陷,从数据源本身保证了后续反演流程的可靠性,有利于提高构造形变模型反演的准确性。
猜你喜欢
导航定位学报(2022年5期)2022-10-13 08:35:28
中国体视学与图像分析(2021年3期)2021-11-24 02:20:44
原子与分子物理学报(2021年2期)2021-03-29 07:31:38
科技创新与应用(2017年35期)2017-12-19 08:33:36
制造技术与机床(2017年10期)2017-11-28 05:20:18
智富时代(2017年6期)2017-07-05 16:37:15
测绘学报(2017年1期)2017-02-16 08:24:44
天津体育学院学报(2016年3期)2016-12-18 08:24:38
科技资讯(2016年21期)2016-05-30 18:49:07
建筑材料学报(2015年3期)2015-02-28 02:36:27
