
基于局部特征共生关系的行为识别算法
2020-12-05 02:17李建新
合肥工业大学学报(自然科学版) 2020年11期
李建新
(东莞职业技术学院 计算机工程系,广东 东莞 523808)
0 引 言
行为识别由于其广泛的应用价值,长期以来一直是计算机视觉和模式识别领域的研究热点之一[1-5]。根据研究的出发点和思路不同,行为识别的研究可以分为两类:基于运动特征的行为识别方法[1-11]和基于姿态估计的行为识别方法[12-23]。许多研究者分别从这2条思路展开了对行为识别的研究工作。除此之外,目前深度学习算法已经逐步应用到行为识别领域。
近年来,受目标识别方法的启发,基于局部特征和词包模型的方法[24-27]已经在行为识别领域得到了较大的进展。该类方法先从视频中提取能代表视频中目标运动的局部特征,这些局部特征代表了行为显著变化的视觉外观,然后对这些局部特征进行矢量量化形成直方图向量特征来表示行为。该类方法一般采用硬投票的方式进行映射过程,即当提取的局部特征与某个视觉单词最相似时,则认为该视觉单词对应的运动模式出现了1次,然后统计所有出现的次数得到直方图向量来表示该行为。直方图向量中的某个分量越大代表该运动模式出现的频率越高。在得到直方图向量的行为表示后,该类方法采用模板匹配或者统计模型的方法得到行为分类的结果。
然而基于局部特征和词包模型的方法没有考虑特征间的时间和空间关系,而特征间的时空关系(特别是时间关系)对于行为表示和行为识别非常重要[28-29]。特征间的时空关系能够丰富行为的表示,并刻画行为的一些运动细节。对于某些行为,例如跑步、慢跑和走路这几类行为,利用局部特征可能无法将这些行为分开。这些行为的主要区别是手臂和腿运动的快慢频率,其对应于特征间的时间和空间关系,因此需要对特征间的时间和空间关系进行建模来区分这些行为。
针对以上问题,本文提出一种共生关系来分别对局部特征之间的时空关系进行建模。本文中的共生关系指的是特征之间同时发生的约束关系。具体来说,对于局部特征之间的时空关系而言,共生关系指的是局部特征之间在一个局部时间和空间的区域内先后相继出现的约束关系。
1 局部特征间共生关系建模行为识别方法
针对基于词包模型方法的缺点(没有考虑局部特征之间的时间关系),本文提出一种对局部特征间的时间关系建模的行为识别方法,主要对局部特征在一个局部时空区域内的共生关系进行建模。
局部特征在时间上共生关系的示意图如图1所示。图1a中,红色、绿色和蓝色的圆圈表示从视频中提取的局部特征(具体指的是时空特征,这些特征代表了不同的运动模式); 图1b中,红色、绿色和蓝色的方块对应图1a中的局部特征,这些特征按照时间顺序排列,黑色框表示这些局部特征是从同一个视频中提取的; 图1c中,蓝绿色、洋红色和黄色的圆圈表示从视频中提取的局部特征;图1d中,蓝绿色、洋红色和黄色的方块表示按照时间顺序排列的局部特征。在一个局部时间区域内,局部特征会呈现依次出现的模式(图1b、图1d)。本文将这种依次出现的模式定义为特征间的共生关系。为了从局部特征的集合中挖掘这种共生关系,本文提出一种基于2层采样的Adaboost框架。

图1 局部特征在时间上的共生关系示意图
行为识别的整体框架如图2所示。
图2a为训练样本;图2b为从视频中提取的局部特征;图2c为利用2层采样Adaboost框架得到的具有判别力的局部特征和局部特征间的共生模式的集合,其中红色圆圈内的局部特征表示这些局部特征存在时间上的共生关系;图2d为通过匹配得到识别的结果;图2e为从测试样本中提取的局部特征;图2f为测试样本。
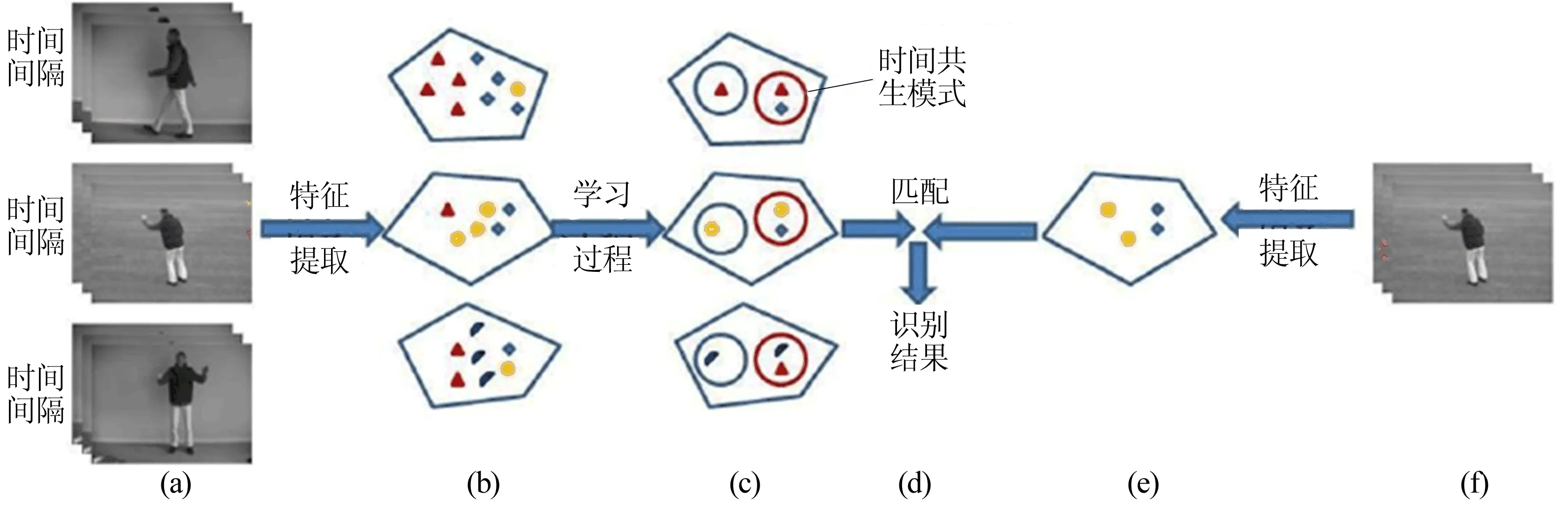
图2 系统框架示意图
1.1 模型表示
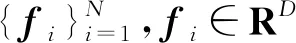
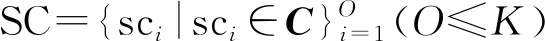
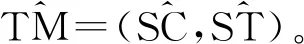
1.2 学习过程
(1)
其中,W为样本权重。本文所采用的Adaboost框架可以分为如下3个步骤:① 通过采样得到弱分类器;② 更新分布;③ 将弱分类器组成强分类器。首先需要从2个多项式分布中采样得到弱分类器,这2个多项式分布定义如下:
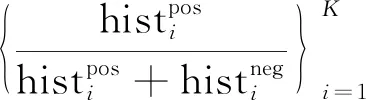
(2)

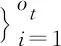
(3)
其中,K为词典中元素的个数;T为弱分类器的总数。在学习过程的前期,算法能够很容易地选择一些具有较强泛化能力的弱分类器。然而在学习过程的后期,算法需要增加comp的值来提高选择具有较强泛化能力的弱分类器的可能性。
为了使得在下一轮采样中得到的弱分类器关注于分类错误的样本,需要更新SR1和SR22个分布参数。与Adaboost的权重更新类似,SR1的更新过程如下:
ωj=ωiβ1-ei,
(4)
其中,当样本lj分类正确时,ei=0;当分类错误时,ei=1。通过对分类正确的样本权重相加来更新SR1。该分布更新的方式是:当分类错误时,赋予该样本更大的权重。SR1反映了需要将更多的关注放在这些局部特征上。由于样本的权重变化,导致最优的共生模式也发生了变化。因此,SR2也需要根据权重的变化而变化来得到最优的弱分类器。SR2的更新过程如下:
SR2,i=SR1,iSR2,i,i=1,…,K
(5)
最后,通过将得到的T个弱分类器联合,得到一个强分类器,即
(6)
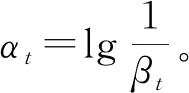
1.3 模型推断
模型推断指的是从测试样本中所提出的局部特征中推断该测试样本的行为类别标签。对于测试样本,本文采用匹配的方法对测试样本进行分类。该分类过程可以定义为:
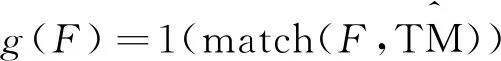
(7)
其中,F为从测试样本中提取的局部特征;1(·)为指示函数。
2 实验结果
为了验证本文提出的算法的有效性,本节在公开数据集KTH数据库上进行了实验,该数据库包含600段视频,步行、慢跑、跑步、拳击、挥手及拍手6类行为。每一类行为由25个人分别重复多次。具体来说,大部分视频片段由一个人重复4次,少部分视频片段由一个人重复3次,其中还有一个视频片段缺失。本节将所有的视频片段按照行为重复的次数分割成多段小视频,这些小视频片段只包含有单个人的单次行为。因此,小视频片段的总个数为2 391个。全部视频在4种不同场景中拍摄:户外1(没有尺度变化)、户外2(有尺度变化)、户外3(穿着不同的衣服)和室内。大多数视频的背景很简单,且没有显著的变化。
本文采用与文献[2]相同的实验设置,即将数据库按照不同的人划分为测试集(9个人,标号分别为2、3、5、6、7、8、9、10 、22)和训练集(16个人,标号分别为11、12、13、14、15、16、17、18、19、20、21、23、24、25、1、4)。因此训练集一共包含1 528段视频,测试集一共包含863段视频。本节采用MoWLD时空兴趣点检测子从视频中检测时空兴趣点形成一个直方图向量。在本实验中,与采样相关的参数(numSR1,numSR2,compSR1,compSR2)被分别设置为2、10、10、5,时间区间Thi被设置为10。本节采用一对多的方式来训练模型,即当前行为作为正样本,其他类行为作为负样本。
本节在KTH数据库上得到的混淆矩阵如图3所示。该混淆矩阵中的第i行第j列表示模型将第i类行为中的视频识别为第j类行为的比例。从图3中可以看出,最容易混淆的2类行为为慢跑和跑步。本节提出的算法容易将跑步这个动作识别成慢跑动作。这主要是由于这2类行为的外观很相似,因此从这2类行为中提取的时空兴趣点描述子比较相似。对描述子进行矢量量化时会将这些描述子分配给同一个视觉单词,因此造成本节提出的算法难以区分这2类行为。本节提出的方法能够通过增加视觉词典的大小来提高识别率,6类行为识别率随词典大小变化的情况如图4所示。从图4可以看出,随着视觉词典增加,平均识别率具有增加的趋势。由于这些局部描述子容易混淆,针对跑步这种行为得到的模型选取的判别特征较多,而针对慢跑得到的模型选择的判别特征较少,因此跑步和慢跑这2种行为的识别率的增长趋势相反。
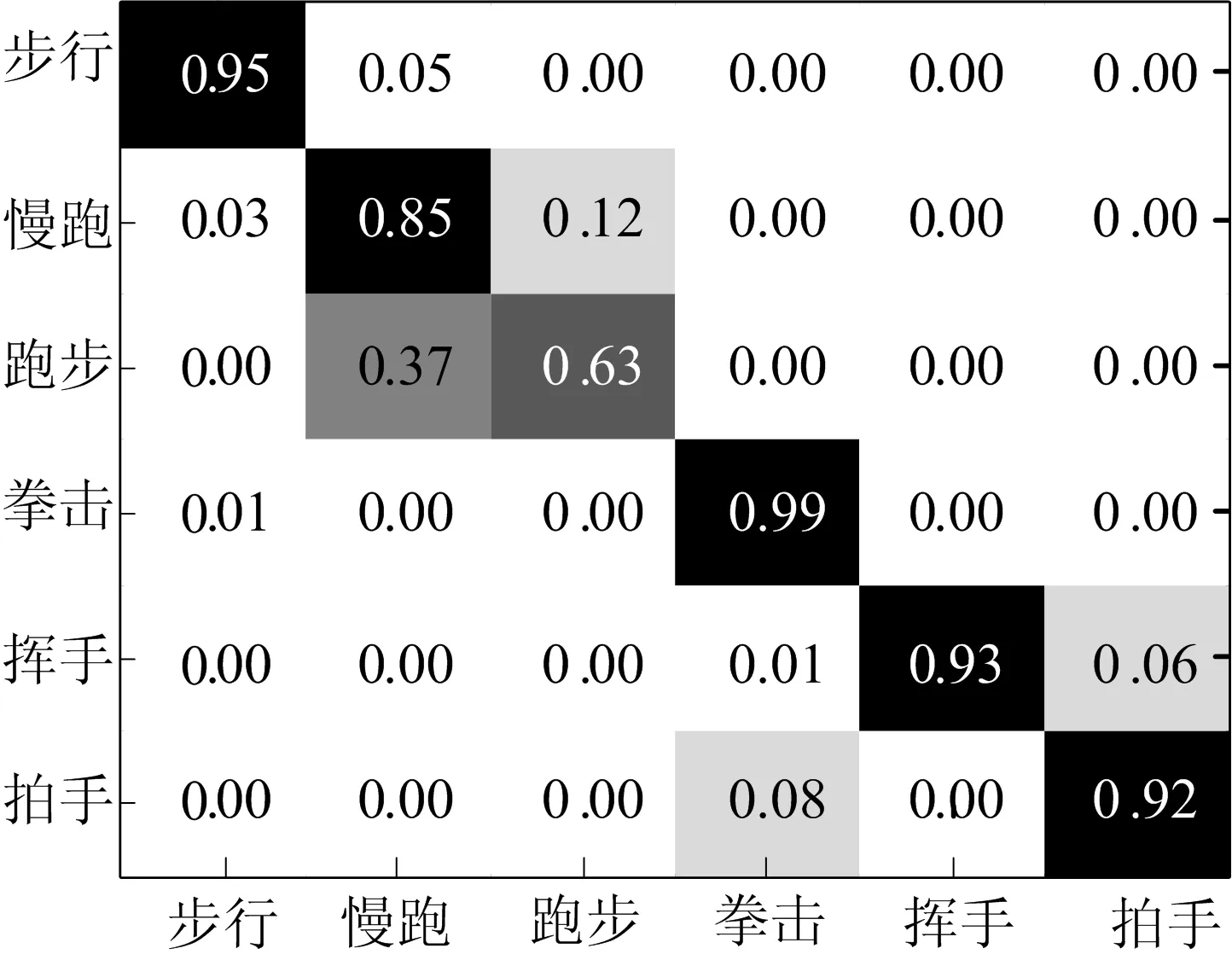
图3 在KTH数据库上得到的混淆矩阵
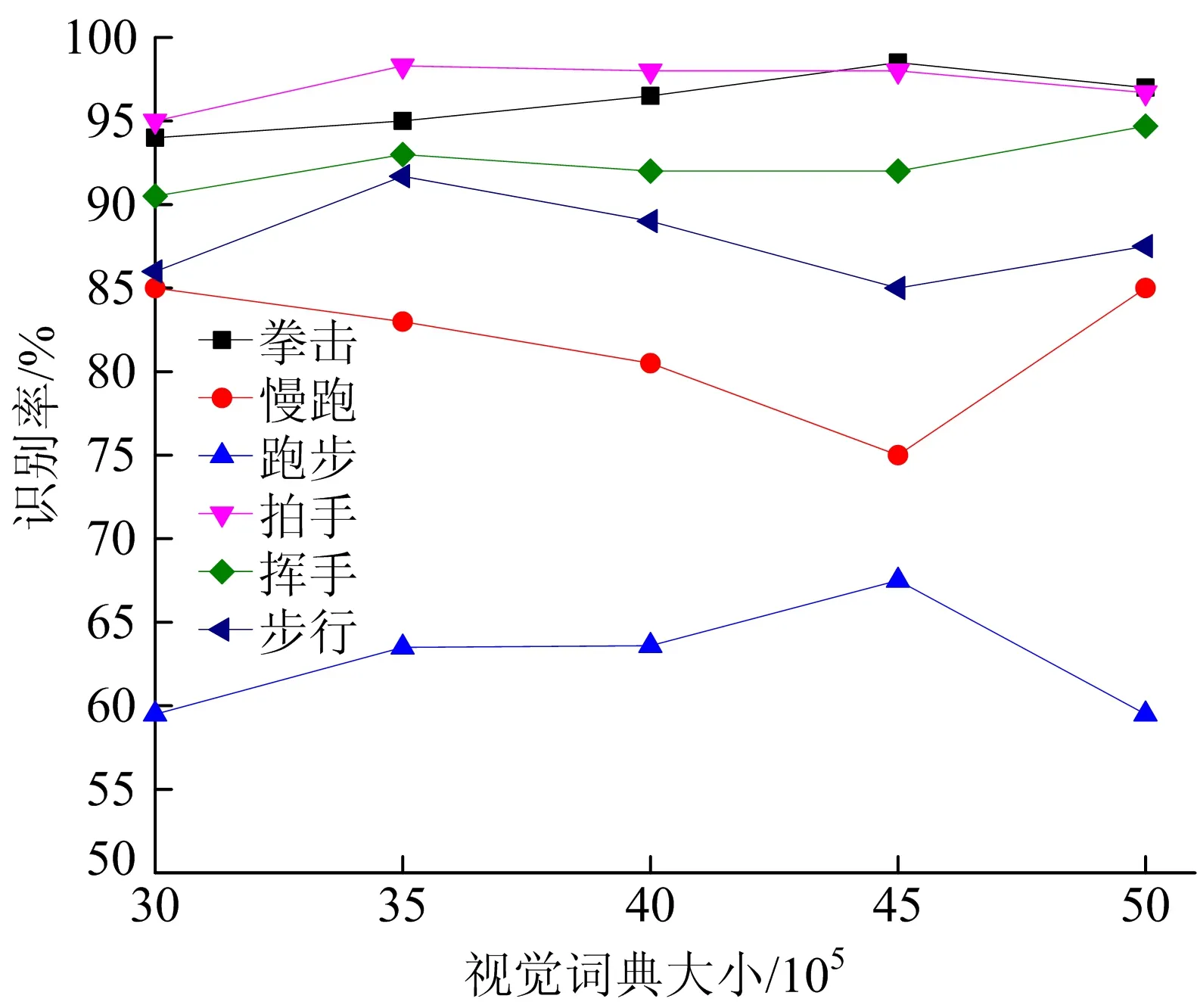
图4 6类行为识别率随词典大小变化的情况
本文提出的方法与其他方法的对比结果见表1所列。从表1可以看出,本文提出的方法取得了较好的结果。然而Laptev提出的方法平均识别率达到了91.8%,优于本节所提出方法的识别率。这主要是由于与本节提出的方法相比,Laptev提出的方法采用卡方核的非线性SVM强分类器,而本节所提出的方法只对局部特征进行了匹配。为了进一步验证本节所提出算法的有效性,忽略共生模式ST,只利用具有判别能力的局部特征的集合来表示行为,使用共生模式和不使用共生模式模型对比结果如图5所示。从图5可以看出,利用共生模式的模型比不利用共生模式的模型取得更高的平均识别率。该实验表明了局部共生模式能够丰富行为表示,并刻画了行为的细节信息,因此能有效地区分相似的行为。

表1 在KTH数据库的平均识别率对比

图5 使用共生模式和不使用共生模式模型对比结果
3 结 论
本文主要对局部特征之间的共生关系进行建模,采用Adaboost的学习框架来获得具有判别能力的局部特征以及具有共生关系模式的集合。该方法能够对局部特征间丰富的时间信息进行挖掘,获得更为丰富的行为表示。实验结果表明,对局部特征间的共生关系进行建模能够提高系统的性能,该方法能够克服复杂场景下行为类内变化较大的问题。实验结果验证了本文所提出方法的有效性。
猜你喜欢
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年2期)2021-02-23
小学生作文(低年级适用)(2020年10期)2020-11-10
电子技术与软件工程(2019年18期)2019-11-18
福建基础教育研究(2019年2期)2019-09-10
中国听力语言康复科学杂志(2019年3期)2019-06-24
福建基础教育研究(2019年2期)2019-05-28
电子技术与软件工程(2017年14期)2017-09-08
军工文化(2017年12期)2017-07-17
中国高新技术企业(2017年5期)2017-05-05
