
一种基于特征正则约束的异常检测方法
2020-12-04 02:01:38陈洪刚王正勇何小海
四川大学学报(自然科学版) 2020年6期
邓 描, 刘 强, 陈洪刚, 王正勇, 何小海
(四川大学电子信息学院, 成都 610065)
1 引 言
随着人们安全意识增强,视频监控领域的异常检测引起了很多关注,逐渐成为一项重要且极具挑战性的任务[1].因为不同场景下的某一行为异常的程度不同,即特定场景下的特定行为才能称为异常,尝试收集各种异常事件并用分类的方法解决问题几乎是不可行的,所以考虑获得更好的特征表示成为了解决问题的关键.
相较于传统的特征提取方法深度学习能够从大量的数据中自动提取出有用的特征,目前在异常检测领域取得了丰硕的成果。基于标记信息可以分为监督学习方法,如支持向量机(SVM)[2]、主成分分析(PCANet)[3]等;半监督学习方法,如自动编码器(Autoencoder)[4-5]和生成对抗网络(GAN)[6]等;无监督学习方法,如受限玻尔兹曼机(RBM),稀疏编码器(Sparse Coding)[7-8]等.但由于异常标签很难获取,标注成本高,半监督学习和无监督学习在异常检测中的应用更为广泛.自动编码器作为一种常用的半监督学习方法其原理也比较简单:对于输入样本,首先通过编码器将其压缩为低维特征,然后通过解码器对每个样本点进行重建,还原到原来的维度,整个训练模型的目的就是减小重构误差.假设输入异常样本会产生更大的误差.传统的稀疏编码算法就使用这样的框架,并且将正常样本表示为几个基本分量的组合,通过无监督的方式学习有效的数据编码. Luo等提出了时间相关稀疏编码方法[9],它可以映射到SRNN中更方便地进行参数优化并提高了异常检测的速度.自编码器具有强大的重构能力,但正因为这种能力,即使是异常样本也能得到很好的重建,导致异常检测精度下降.
为解决上述问题,使正常样本和异常样本有更明显的界限,本文提出一种新的异常检测框架:首先,为自动编码器添加跳线连接结构,这种使用U-Net风格的编码解码网络能够实现对图像空间细节的多尺度捕捉,并能从模型所学习的分布中产生高质量的图像.然后,用分类器网络迫使自动编码器学习改进的分布模型并提取输入图像的特征,以便模型能重建出低维特征向量.最后,在自动编码器上配备一个密度估计器,用一个自回归过程对潜在向量的概率分布进行正则约束.通过联合优化整个网络,模型能在重建出质量更好的图片的同时,降低潜在特征向量表示异常的可能性.
2 基本原理
2.1 结构组成
本文采用无监督的方式对提出的卷积网络架构进行训练,输入数据集D被分成训练集Dtrn和测试集Dtst.Dtrn包含m个正常样本Dtrn={(x1,y1),(x2,y2),…,(xm,ym)},其中,yi=0表示正常类.Dtst包括n个正常和异常样本Dtst={(x1,y1),(x2,y2),…,(xn,yn)},其中,yi=0或yi=1.通常情况下m>n.
基于上面定义的数据集,我们将在训练集Dtrn上训练我们的模型,并在测试集Dtst上评估它的性能.训练目标不仅是在图像空间内捕获训练样本的分布,而且还包括潜在特征向量空间.通过最小化训练目标来捕获两个维度内的分布,使网络能够学习正常图像所特有的高维特征和低维特征.
整个网络结构如图1所示,分别包括编码器EN,解码器DE,分类器C和参数密度估计器H,损失函数将在2.2节介绍.
自动编码器网络:编码器EN通过将输入样本x下采样成低维特征z来捕获输入数据的分布,其过程可以表示为z=f(x),其中,x∈w×h×c;w是输入图像的宽度;h是输入图像的高度,c是输入图像的通道数;z∈d;d是输出特征的通道数.解码器网络DE将低维特征z上采样回到输入图像维度并重建输出,表示为x′=g(z),其中,x′表示重建图像.在文献[10] 的推动下,自动编码器采用跳线连接方式,这是一种新型的特征融合方式:拼接,使得编码器网络中的每个下采样层被连接到通道数相同的上采样解码器层,形成更厚的特征层.使之能够直接地进行信息传递,保留了多尺度信息,因此能够产生更好的重建.
分类器网络:C的任务是对由自动编码器生成的伪图像x′和真实图像x进行分类,它采用了与文献[11]中DCGAN的鉴别器类似的结构.网络C还用作特征提取器,提取输入图像x和重建图像x′的低维特征.
参数密度估计器网络:想要提高模型区分正常和异常样本的能力,仅仅依靠自动编码器来缩小图像层面对正常样本的重建误差是不够的,因为它不能保证异常样本能产生很大的重构误差,所以提出在自动编码器上引入参数密度估计器H,对低维特征向量z的概率密度进行正则化约束,正则化约束是指:找到能充分覆盖正常模式的最小潜在特征向量空间,使异常值落在该子空间之外,以降低特征向量表示异常的可能性.假设输入样本x和低维特征z之间存在这样的关系如下.
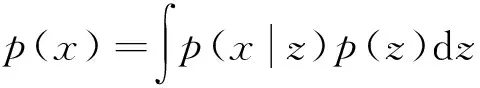
(1)
本文仅用正常样本进行训练,p(x)为正常样本的分布,p(x|z)是在给定潜在向量的先验分布p(z)的情况下所观察到的条件概率密度,即在已知特征向量为z的情况下输入样本x为正常的概率.为使低维特征z尽量不重建出异常图片,需要找到使p(x|z)最大的特征向量z,故提出使用参数密度估计器学习特征向量的分布p(z).本文不强制要求特征向量服从某一分布(如高斯分布),而是通过一个自回归过程来学习它的真实分布.自回归模型为涉及顺序预测的任务提供了通用表述,即每个输出都取决于先前的观察结果,本文采用这种技术来分解联合概率密度,分布情况如下.
(2)
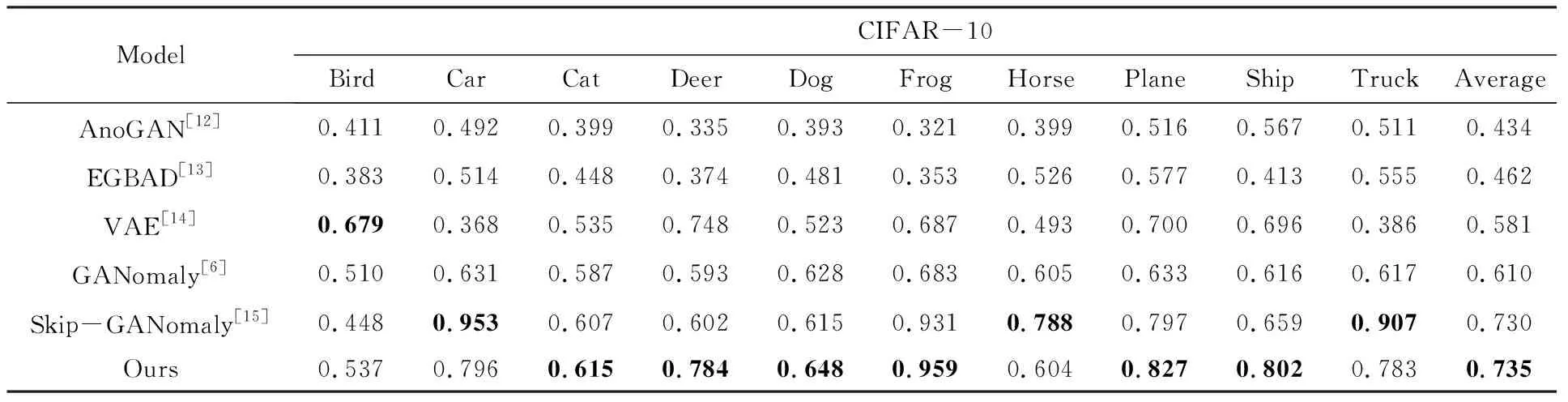
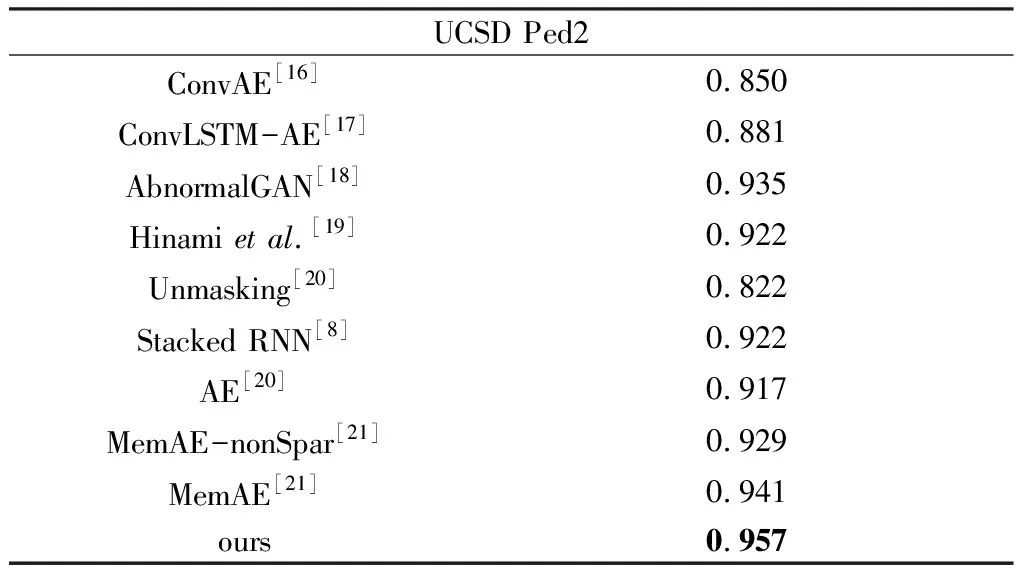
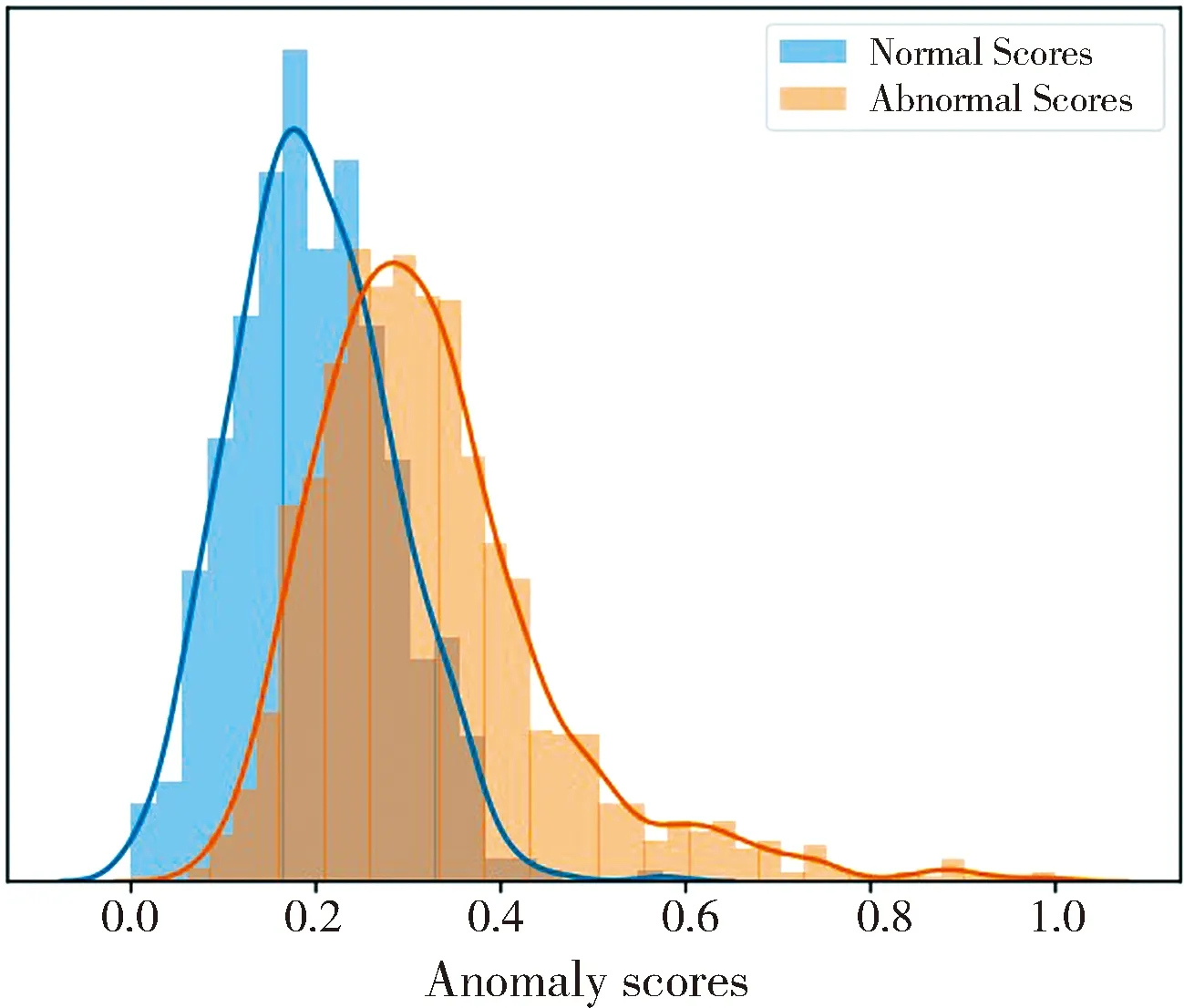
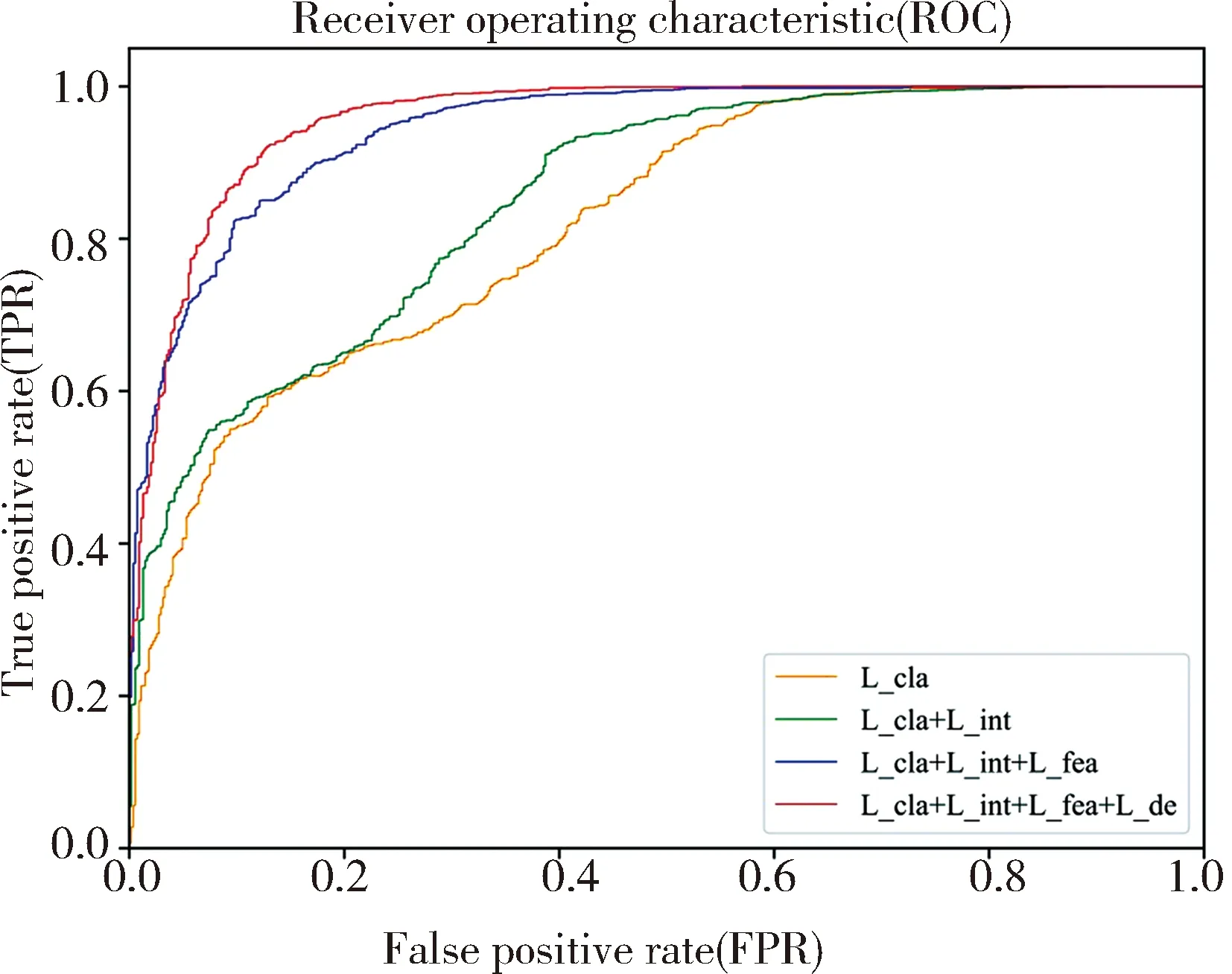
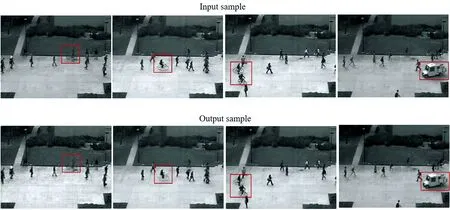
其中,我们把p(z)分解成d个条件概率密度的乘积,并且每个zi的条件概率密度是根据它之前出现的{z1,...,zi-1}的概率密度计算得出的,其中,<表示一种顺序结构.在实验中,每个条件概率密度p(zi|z (3) 其中,类型A强制严格依赖于先前的元素(并且仅用作第一个估计层),而类型B仅屏蔽后续元素.假设每个条件概率密度被建模为多项式,则最后一个自回归层的输出(在d×B中)提供构成空间量化的B个通道的概率估计. (4) 式中,⊥表示将d个多项式拼接起来,得到分布参数,进而推断出概率分布q(z). 图1 网络结构图Fig.1 Network structure diagram 本文结合了4个损失值期望模型能够重建出更高质量的图片,并且能在潜在向量空间学习到异常性,从而区分正常样本和异常样本. (1) 分类损失:式(5)中所示的该损失确保网络EN和DE尽可能逼真地重建正常图像x至x′,而分类器网络C对样本进行分类得到C(x)和C(x′).分类损失的期望表示为 (5) (2) 重建损失:为明确地学习表观特征以充分捕获输入数据分布,我们将1-范数正则化应用于输入x和重构输出x′.这种正则化确保模型能生成与输入样本类似的图像.重建损失的期望如下. (6) (3) 特征损失:分类器C除了对样本进行分类还提取x和x′的特征得到f(x)和f(x′).因此,特征向量的损失期望为 (7) (4) 密度估计损失:估计器用一种自回归的方式获取真实分布p(z)的参数模型,得到近似分布q(z).为了确保它和真实分布之间的信息差距很小,从而降低特征向量表示异常的可能性,用Lde来表示真实分布与拟合分布的KL散度,定义为 Lde=DKL(p(z)‖q(z)) (8) 最终,总损失定义为 L=λclaLcla+λintLint+λfeaLfea+λdeLde (9) 其中,λcla、λint、λfea和λde是权重参数. 对于异常性的评估是通过计算异常分数,假设正常样本的异常分数小,异常样本的分数更高.因此,对于给定样本x,它的异常分数s(x)定义为 s(x)=αI(x)+γV(x) (10) 其中,I(x)和V(x)分别表示给定样本和特征向量的重建分数;α和γ是他们的权重.最后将整个测试集中所有图像的异常分数归一化到[0,1]范围,并使用以下等式计算每个测试样本的异常分数As(x)为 (11) 为评估本文的异常检测模型,我们使用两种类型的数据集.CIFAR-10:该数据集共有6×104张彩色图像,这些图像是32×32像素,标签包含10个类别(飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车)每类6×103张图.本文选取其中一类视作异常,其他为正常,根据选取异常类别的不同总共有10种情况(如图4,每一列代表一种异常类别),每种情况都有4.5×104个正常训练样本,9×103个正常测试样本,6×103个异常测试样本.UCSD Ped2:该数据集由加州大学圣地亚哥分校创建,通过安装在一定高度、俯视人行道的摄像机来采集自然状态下发生的异常行为,主要针对人群中个体行为的识别研究,是一个被广泛认可及应用的视频异常检测数据集,它的异常情况包括:开车、骑自行车、滑冰等,其中包含有16个训练图像序列以及12个测试图像序列,图像大小均为360×240像素. 实验平台为:Ubuntu 16. 04. 5,Nvidia GTX 1080 Ti GPU,Intel(R) Xeon(R) CPUE5-2686.深度学习框架是Pytorch0.3.CIFAR-10的原尺寸32×32,UCSD Ped2的尺寸批量修改为256×256.通过Adam优化器优化训练目标,初始学习速率lr=2×10-4,具有权重衰减,动量β1=0.5,β2=0.999.实验表明,总损失的加权参数为λcla=1,λint=40,λfea=1,λde=1时模型性能最佳.在对CIFAR-10进行训练时,最初设定训练15个epoch,UCSD Ped2训练100个epoch.但在大多数情况下,它们在较少的训练周期内能够学习足够的信息.因此,当模型的性能开始下降时,我们保存网络的参数,防止其出现过拟合的情况. 模型性能由接受者操作特征曲线(Receiver Operating Characteristic Curve, ROC)和曲线下面积(Area Under Curve,AUC)评估,该函数由真实阳性率(True Positive Rate, TPR)和假阳性率(False Positive Rate, FPR)绘制.表1可看出本文的算法在CIFAR-10数据集的Cat,Deer,Dog,Frog,Plane,Ship类别上的表现都高于其他算法. 表1 CIFAR-10数据集的AUC结果 从表2可知,本文提出的算法与当前的流行算法相比具有高的准确率. 图2是测试数据的正常和异常分数的柱状图,其中,蓝色区域代表样本为正常时分数的分布情况,黄色区域代表样本为异常时分数的分布.通过对这些数据的仔细观察发现,该模型在输出异常分数上产生了明显的分离. 表2 UCSD Ped2数据集的AUC结果 图2 UCSD Ped2数据集的异常分数直方图 图3是各个损失的ROC曲线图,黄色曲线代表仅存在分类损失时的ROC曲线;绿色曲线表示分类损失和重建损失一起存在时的ROC曲线;蓝色曲线是分类损失,重建损失和特征损失同时存在时的检测效果;最后加上密度估计损失后的检测效果由红色曲线来体现.由图可知随着各个损失的添加,检测效果有了明显的提升,证明添加的每个损失都起到了相应的作用. 图3 各个损失的ROC曲线图Fig.3 ROC of each loss 图4 CIFAR-10输入样本和输出样本,每一列分别代表一种类别(鸟、汽车、猫、鹿、狗、青蛙、马、飞机、船、卡车) 图4和图5分别是CIFAR-10的测试集和UCSD Ped2的测试集输入模型后生成的图像.从外观上来看,生成图像和输入的图像具有很高的相似度,从图5可以看到,异常样本也能得到一定程度的重建,这是使用自动编码器生成图片的普遍问题,但是,如2.3节所示,异常分数能够在特征向量空间体现. 图6上面一排是CIFAR-10数据集的输入、文献[6] 的重建输出以及本文的重建输出,将红框圈中的船这一类别作为异常类别,其余类别的图像作为正常.可以看出除异常类别的图片外其他图片的重建效果都比文献[6] 的效果好.下面一排是UCSD Ped2数据集的输入、文献[16] 以及本文的重建输出,红框圈中的地方是异常(自行车)出现的地方,可以看出本文的总体重建效果要优于文献[16] ,但异常部分(自行车)人能够部分重建.这是由于自动编码器极强的重建能力. 图5 UCSD Ped2输入样本和输出样本,骑自行车和汽车表示异常 图6 CIFAR-10数据集(上排)输入样本、文献[6] 的重建样本以及本文的重建样本,UCSD Ped2数据集(下排)输入样本、文献[16] 的重建样本以及本文的重建样本 本文提出了一个新颖的异常检测框架,在传统自动编码器上结合跳线结构使模型能对样本细节进行捕捉,并引入了自回归密度估计器通过最大似然原理约束潜在特征向量的分布,一方面提高了模型的重建能力,另一方面使它能够在样本的潜在向量空间捕获到异常.CIFAR-10和UCSD Ped2两个数据集上的AUC测试结果表明,该方法能够提升异常检测的效果,并在一定程度上优于现有方法,证明了本文的异常检测模型的有效性.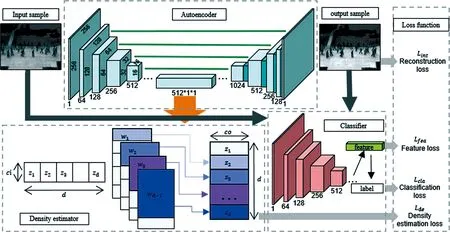
2.2 损失定义
2.3 异常分数定义
3 分析与讨论


4 结 论
猜你喜欢
九江职业技术学院学报(2022年1期)2022-12-02 09:46:54
保定学院学报(2022年2期)2022-04-07 02:26:50
数学学习与研究(2020年15期)2020-11-28 07:22:43
成都信息工程大学学报(2018年3期)2018-08-29 01:08:40
许昌学院学报(2018年4期)2018-05-02 12:27:37
中华建设(2017年1期)2017-06-07 02:56:14
电子设计工程(2017年20期)2017-02-10 03:39:29
电子器件(2015年5期)2015-12-29 08:42:24
数学年刊A辑(中文版)(2015年1期)2015-10-30 01:55:52
河北建筑工程学院学报(2015年2期)2015-04-29 12:23:52
