
基于事件描述的社交事件参与度预测
2020-12-02 06:27孙鹤立孙玉柱张晓云
计算机应用 2020年11期
关键词:信息
孙鹤立,孙玉柱,2*,张晓云
(1.西安交通大学计算机科学与技术学院,西安 710049;2.西安交通大学外国语学院,西安 710049)
(∗通信作者电子邮箱sunyuzhu12@xjtu.edu.cn)
0 引言
2014 年,Liu 等[1]提出了EBSNs 的概念,即基于事件的社会网络(Event Based Social Networks,EBSNs)。EBSNs 不仅包含深度的线上交互(Online Interactions),还包含范围广泛的线下交互(Offline Interactions)。EBSNs 典型的网络平台代表有:Meetup、Google+Events、Groupon 和豆瓣等。依托这些平台,用户可以发布、参与社交事件,比如各种聚会、筹集资金、分发物品等[2]。近年来,越来越多的学者开始关注该领域,并开展了关于事件推荐[3-5]、事件安排[5-7]、行为分析[8-9]、参与预测[10-12]等方面的研究。
本文重点关注社交事件参与预测,文献[10]预测了兴趣组的未来存在可能,由于一个兴趣小组的三月存活率不到30%,因此作者通过研究组的创办者,组成员数量的增长速度以及其他因素,来预测最终该组是否能够存活。文献[11]预测了事件的参与人员组成,由于人们在选择事件时通常基于某种模式,因此通过学习历史数据可以预测出哪些人可能对该事件感兴趣。文献[12]提出了基于多特征的模型用于预测活跃组员和非活跃组员的参与度。
在EBSNs体系中,事件是运转枢纽,而事件描述是事件的重要属性,对于组织者和参与者均有重要的作用。事件描述可综合包含多种信息,如事件意义、安排、预期等,可辅助用户决策是否参加。同时,事件描述给了组织者最大的自由度来使事件更有吸引力,尤其在其他因素被限制的情况下(时间、地点等)。在当前的研究中,事件描述通常只被用来衡量事件间的相似度,以及事件与用户兴趣的契合度。比如在文献[11]中,事件描述被用来计算事件间的相似度,根据用户参与事件的历史数据,为用户推荐相似事件。文献[13]使用TF-IDF(Term Frequency-Inverse Document Frequency)算法来处理事件描述,并用其计算事件间的相似度。文献[14]提出用Vader对事件描述进行情感分析,并使用Jaccard 相似度来衡量事件的新奇性。目前,基于事件描述开展的工作还非常有限。
尽管事件描述包含了事件的重要信息,但由于评价事件描述效果的主观性、算法限制等原因,直接度量事件描述仍较为困难,同时如何充分利用事件描述中的信息,如语义分析、预测、预警也是当前的难点问题。针对以上问题,本文开展了如下工作:
1)提出了成功事件、相同事件、相似事件、事件相似度的概念,并针对事件进行分类度量。
2)基于所提出概念,分别设计了基于拉索(Lasso)回归、卷积神经网络和门控循环神经网络的事件描述分析方法。
3)设计了针对每种模型的训练方案,并用其他数据结合分类算法预测事件人数,且分析了三种模型的预测结果,定量地研究了事件描述对预测事件参与度的影响,证明了事件描述对于增加事件吸引力的积极作用。
1 问题概述
在EBSNs 中,一个对组织者非常重要的问题是如何使自己的活动更受欢迎,进而吸引更多的参加者。同时,事件的属性多种多样,包括主题、举办时间、地点、所在组、事件描述等。作为自由度最大的属性之一,问题描述在提高事件吸引力方面影响显著,以下面两段描述为例:
1)Let’s get ready to get in our bikinis and board shorts(speedos for the europeans)and enjoy the la summer heat on the beach! this year the event is on saturday,august 10th,starting at 1pm.We will have muchies,drinks and games.For those that are into volleyball,let’s repeat what we did last year.I saw a lot of losers,I mean winners.lol.Let’s enjoy a few good volleyball games.
2)Open to the public for a group class package and individual classes.
从自然语言理解角度,第一段描述显然比第二段更有吸引力,而事实也是如此,第一个事件的参与人数(超过97%的同类事件)远高于后者(超过5%的同类事件)。因此,如何定义事件描述,对事件举办者至关重要。
同时,定量研究事件描述对事件参与度的影响也是一个难点问题。一方面由于事件描述是自然语言,难以建模。虽然近年出现了一些文本建模方法,如基于循环神经网络的语言模型(Recurrent Neural Network Language Modeling,RNNLM),较好地克服了传统自然语言处理中的一些问题(例如反义词),并在机器翻译、文本生成等领域取得了不错的效果,但它并不能很好地解决语义一致性的问题。例如在文本空间中,this flower smells pretty 和this flower smells pretty bad会比较接近,但它们的含义却截然不同。另一方面,文本建模方法的本质是拟合文本序列的概率分布,以最大化某个目标函数的期望或概率,而不能真正理解语义,导致信息损失或失真,这两方面导致定量研究事件描述的作用变得格外困难。
为解决以上问题,本文采用逆向思路,首先并从事件结果出发,提出事件相似度定义,从而判定事件的成功性并标注,进而让三种预测模型学习标注结果,并进行预测,最后根据预测结果分析事件描述对参与度的影响。此思路可有效规避直接分析语句带来的算法偏差,如语义一致性、信息损失问题。
1.1 问题定义
本文的数据来源为Meetup 平台,Meetup 平台中存在3 个基本对象:用户、小组、事件。具有相同兴趣的用户形成小组,组织者可以在小组中发布事件,用户可选择是否参与该事件。事件连接了用户和小组,是体系运转的枢纽,本文提取事件的相关要素进行分析。
为了方便描述,本文使用一个七元组来表示事件eid(id,t,d,h,a,l,c)。其中:id是事件的唯一标识,t是事件举办时间,d 是事件描述,h 是事件所在组,a 是事件参与人,l 是事件所在地点,c 是事件主题。用四元组来表示组gid(id,e,m,c)。其中:id 是事件的唯一标识,e 是事件,m 是组内成员,c 是该组的主题。
接下来给出事件的相关定义。
成功事件 给定一个事件eid和与其相似的事件集合E=若eid的参与人数超过了70%的相似事件的参与人数,则eid为成功事件。
衡量事件举办结果的指标较多,如参与人数、小组参与比例、经费规模等,相对于其他指标,参与人数是事件参与度最为直观的指标。对于举办者来说,如果所举办事件的参与人数超过了70%的同类事件,那么该事件可以看作是成功事件。
相似事件 给定事件eid1和eid2,若sim(eid1,eid2)>γ,则eid1和eid2互为相似事件,其中sim 表示相似矩阵,γ 为阈值。相似矩阵建立将在1.2 节中介绍,阈值γ 的选择将在第3.1.2 节中介绍。相同事件 指对于事件eid1和事件指事件eid1的事件描述。
Meetup 平台中约30%的事件属于相同事件,它们对于推荐算法意义重大,但在计算事件描述对事件参与度的影响时,则会起到相反的作用:一方面由于在衡量事件描述产生的影响时,该类事件会增加其事件描述的影响比重,进而导致结果偏向于重复出现的事件描述;另一方面由于参与这类事件的人重叠度高,它们是基于经历而不是基于事件描述来选择该事件的,故对事件描述不敏感,因此剔除该类事件是有必要的。对于相同事件,本文只保留其平均值。
1.2 事件相似度
由于不同种类事件之间的参与人数差别较大,如演唱会可能会有数万人参加,而读书会的参与人数可能只有几人,如果采用统一的标准,某些种类的事件成功率将会大大超过其他事件,这不是本文期望的,所以定义相似度以区分不同类别的事件。两个事件,如果所在组相似、主题相似、距离相近、时间相近,那么它们很有可能是相似的。接下来,本文将分别定义组相似度、主题相似度、时间相似度和地点相似度,从而定义事件相似度。
1)组相似度。两个组的相似度可以从两个方面度量:一是组的主题相似度,二是组的成员相似度:
a)主题相似度group_cat_sim:
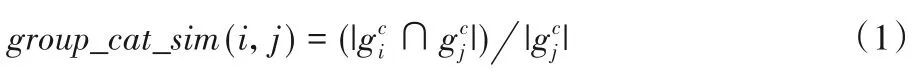
b)成员相似度group_mem_sim:
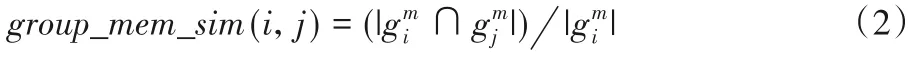
2)事件主题相似度和组主题相似度类似,定义如下:
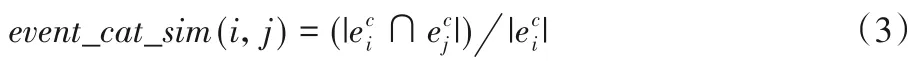
3)时间相似度。通常事件举办时间越接近,时间相似度越大,为了计算需要,时间相似度的值域取[0,1],此处使用负指数函数定义时间相似度。

4)地点相似度。同样的,距离越近的事件地点相似度越高。这里使用haversine公式计算两点之间的距离:

5)事件相似度。基于以上公式,定义事件相似度如下:给定事件i和事件j,它们之间的相似度可定义为组相似度、主题相似度、时间相似度、地点相似度的线性组合,可用式(6)表示:
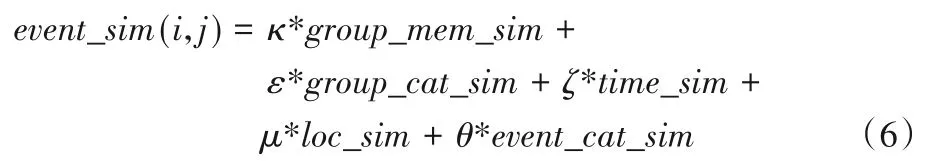
另外,1.1 节中事件相似度函数sim(eid1,eid2)>γ 中阈值γ的取值应该考虑event_sim函数的取值范围。
2 预测模型
本文分别设计了基于拉索回归、卷积神经网络和门控循环神经网络的预测模型。
2.1 基于拉索回归的预测模型
虽然事件描述和事件参与结果之间不是线性关系,但如果不考虑文本的序列性,仅将文本看作词的集合,那么事件描述和事件参与度之间可近似看作线性关系。本文未采用传统的线性回归,而使用拉索回归,因为拉索回归可以有效地处理线性数据,反映出事件描述中的单词对于不同事件的重要性。由于同一类事件的发布者倾向对事件做出相似的描述,因此拉索回归模型可以捕捉事件描述中的关键词信息,从而对参与结果进行判断。拉索回归的预测模型如下:
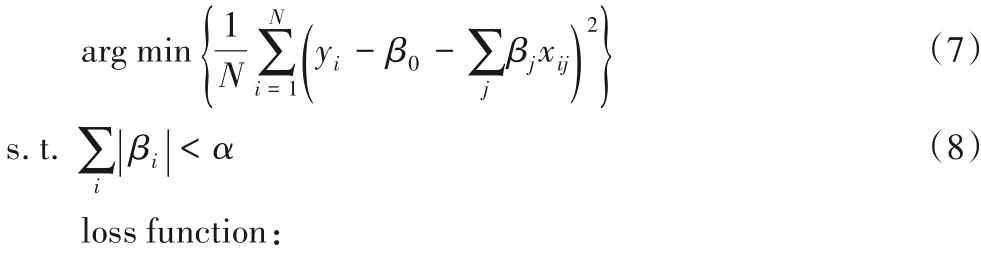

式(7)中:yi为第i 个事件参与人数,xij为中第j 个单词。式(8)为损失函数,MSE(Mean Squared Error)为均方误差。
在实现中,为了与后面两个预测模型统一,本文使用了输出维数为1 的单层线性神经网络,并采用了L1 正则,以突出某些词的作用。预测模型的输入是序列化后的文本,输出为参与人数。
2.2 基于卷积神经网络的预测模型
拉索回归模型虽然可以捕获在同一类事件描述中影响较大的词语,但是对于词语的组合方式并不敏感,而在现实世界中,词语的不同组合方式可能表达完全相反的含义。因此本文利用卷积神经网络对于词语的组合特征进行分析,通过不同长度的卷积核捕捉不同长度的词语组合的信息,从而提高判断的准确性。卷积操作首先对文本信息中不同长度的词语组合进行采样,然后以词语组合为特征分析其对于事件参与结果的影响程度,相较于拉索回归模型以单词为单位的方式,可以捕捉到更高层次的特征,从而达到更好的效果。
为了将文本的序列信息纳入考量范围,本文参考了seqGan[15]中判别器的结构,设计了卷积神经网络,将卷积核的宽度设置成词向量的维度,将卷积核的高度设置为25。判别器的具体处理过程如下。
首先将输入文本ω0,ω1,…,ωt表示成如下形式:

其中:xi为ωi对应的k维词向量是拼接符号是一个t×k的矩阵。

⊗为元素积(element-wise product)之和,b 为偏移量,ρ 为非线性函数。在实现中本文使用多个相同尺寸的核进行卷积,然后取Ci中的最大值。例如图1 中第一个卷积核的l 为3,使用了4 个不同的卷积核,即对于相同的窗口一次输出四个结果,然后取其中的最大值,即窗口大小为l 所对应的卷积结果。为了得到不同窗口尺寸下的上下文关系,本文使用不同尺寸的核,最后将结果拼接起来,得到处理后的特征向量,送入下一个环节。下一个环节为带隐含层的线性网络,假设得到最终的特征向量为(图中对应的k为9),那么接下来本文对ℏ进行如下操作。

其中:ω0,ω1分别对应第一和第二个浅色方块,σ为非线性函数,·为矩阵乘法运算,b0、b1为偏移量。
本文使用了均方误差(MSE)损失函数,并对最后两个线性神经网络采用了L2正则(式(14))。这里采用L2正则的原因是希望最后的线性神经网络能尽可能考虑前面卷积神经网络输出的所有维度,而不是过度地依赖某些维度来做出判断。
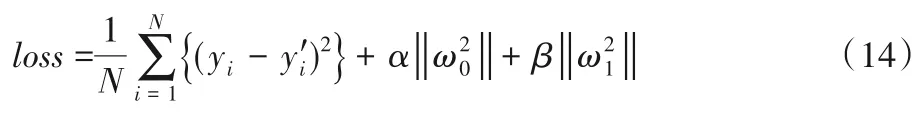
在计算过程中,输入文本序列,首先经过词向量层转换成词向量,然后进行卷积和池化,将结果拼接起来,再使用双曲正切(tanh)归一化,最后经过一个带隐含层的线性前馈神经网络输出最终结果。

图1 基于卷积层的神经网络模型Fig.1 Convolution layer based neural network model
2.3 基于GRNN的预测模型
在上一小节,本文使用卷积层对原始输入文本转换成的词向量进行处理,得到了一个新的特征向量。这个过程也可看成是定义了一个函数f :Rm×k→Rn,将原本在Rm×k空间中的样本编码到了Rn中。这样做的目的是方便后续处理,即把一条文本转换成一个向量,接下来的工作将基于该向量展开。但如何定义函数f,是此方法成败的关键。f 需具有如下特点:1)能处理序列信息;2)能在转换过程中尽量保留原始信息;3)易于实现。而之前的卷积层神经网络并不完全满足这三个条件。首先,它能处理序列信息,但它处理序列信息的能力来源于窗口大小的设置,因此,合理地设置窗口大小非常重要。而在文本处理中,如何设置窗口大小是件困难的事情。其次,因为池化层的存在,它在转换过程中能保留多少原始信息是存疑的。
循环神经网络(Recurrent Neural Network,RNN)可以很好地满足上面三个条件,因此近年来在自然语言处理领域得到了广泛的应用。RNN 能很好地克服卷积层的缺陷。RNN的感受野是整个句子,同时对文本从左到右(或双向阅读)的处理方式也与人的阅读习惯相似,克服了卷积层中卷积核感受野的限制,能够更好地收集原始文本中的信息。
门控循环单元神经网络是长短期记忆(Long Short-Term Memory,LSTM)神经网络的变体。LSTM 解决了RNN 在处理远距离依赖时的梯度消失或梯度爆炸问题,可以很好地保持时序数据中长短距离的依赖关系。GRU 在保持了LSTM 优势的同时网络结构也更简单,相较于LSTM 输入门、输出门、遗忘门的三门结构,GRU只有更新门和重置门[16]。
门控循环单元神经网络在处理序列文本的同时,更好地保留了事件描述中原始文本信息,尤其是长文本中的信息,相对于卷积神经网络,能够捕捉更多文本信息,从而提高判断的准确率。本文使用文献[17]中的GRU结构,如图2所示。
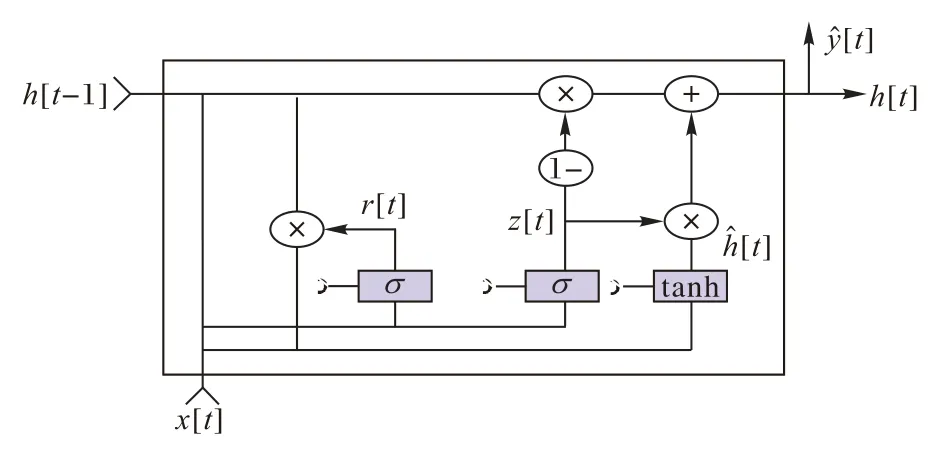
图2 GRU的结构Fig.2 Structure of GRU
图中:z[t]为更新门,r[t]为重置门,h[t]为当前t时刻的隐含状态,椭圆中为算符,方框表示非线性函数。
GRU的前向传播函数如下:
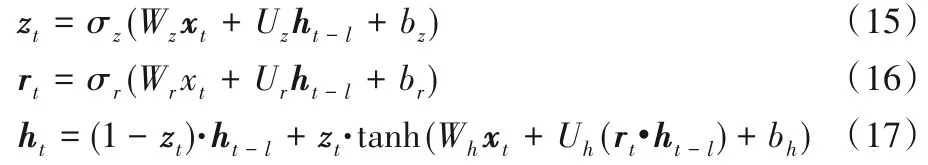
其中:W、U、b 为参数;xt为输入向量,ht为输出向量;zt、rt为更新门和重置门向量。同样的,根据链式法则,可以得到其反向传播公式。
将之前的神经网络的卷积层替换为GRU,便得到了另一个新的预测模型(如图3)。

图3 基于GRU的神经网络模型Fig.3 GRU based neural network model
在计算过程中,输入文本序列,首先经过词向量层转换成词向量,然后进行GRU 编码,将结果拼接起来,再使用双曲正切(tanh)归一化,最后经过一个带隐含层的线性前馈神经网络输出最终结果。
在以上几个模型中,本文使用文献[18]中word2vec 算法来计算词向量,以避免独热编码维度高、稀疏、词之间相关性差的缺点。
3 实验设计与结果
3.1 数据获取与处理
实验使用的数据集为Meetup 平台上美国洛杉矶2018 至2019年的部分活跃组别和其成员及事件,详细信息如表1所示。

表1 洛杉矶Meetup平台数据集Tab.1 Dataset of Meetup platform in Los Angeles
3.1.1 数据预处理
由于爬取的数据描述为HTML 格式,同时包含很多非英语词,例如表情、HTML 控制标签,因此,在正式在预处理之前,本文对文本进行如下处理:1)去除所有非英文词和HTML标签;2)去除停止词;3)将数字替换为“#”,将出现次数少于5次的词替换为“<ukn>”;4)去除事件中无意义的属性,例如图片链接,最终选择了如下属性:时间、地点、事件描述、事件种类,部分数据如表2所示。

表2 部分处理后数据Tab.2 Part processed data
3.1.2 计算事件相似度与成功性标注
根据事件相似度的定义event_sim 函数计算所有事件的相似度,经计算,得到的event_sim 函数相似矩阵值的分布如图4所示,可以看出,相似矩阵值在0.5附近有较大的差异,并且分布比例恰好在8∶2 左右,因此把1.1 节中事件相似度sim函数的阈值γ 取为0.5。然后利用事件成功的定义对所有事件的成功性进行判断并标注。
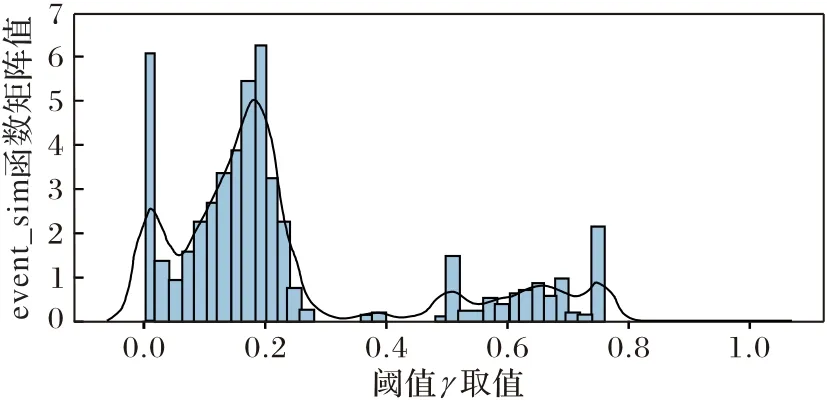
图4 相似矩阵值分布Fig.4 Distribution of similar matrix values
3.2 实验设计
本文设计了两组实验来比较不同文本处理方式的效果:第一组实验对比了不同的预测器在预测参与人数上的差异;第二组实验中,本文将比较不同的文本处理方式对预测事件结果准确率的提升。
在参数设置方面,本文使用了网格搜索和四折交叉验证的方式,确定了最佳参数,如表3 所示。针对第一个实验,本文使用了均方误差(MSE)来衡量预测值和参与人数的距离,具体如下:

其中:yi为真实参与人数,为预测参与人数。
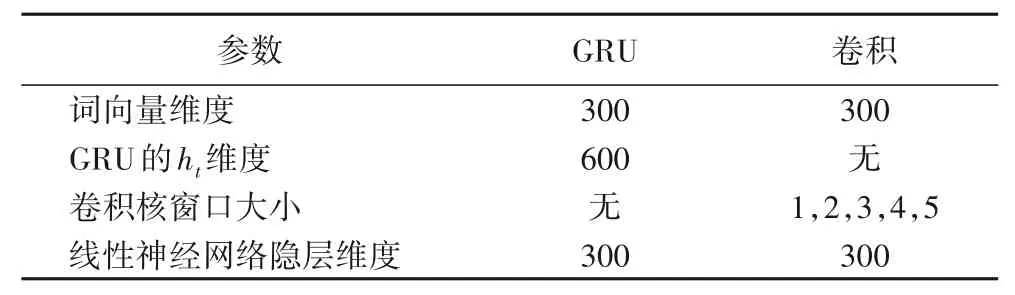
表3 相关参数设置Tab.3 Settings of relative parameters
在第二个实验中,本文使用准确率作为评价指标,准确率为成功事件与所有事件的比值,如式(19)所示:

其中:R为准确率,为Ms成功事件数量,Ma为所有事件数量。
3.3 实验结果与分析
3.3.1 不同预测器预测参与人数差异实验
首先使用80%的事件训练三种预测模型,并使用剩下的数据对预测模型进行评估。训练及测试过程的损失函数变化如图5和图6所示。
从图中可以看出,使用GRU 作为编码器的神经网络的表现最好,其次是线性预测模型(Lass),使用卷积层的神经网络(conv)表现最不理想。卷积层神经网络效果较差的原因可能是卷积层在自然语言处理中比较适合短文本分类,即能区分文法上有明显区别的句子,但由于其感受野的限制,不适合用来区分整个文本的语义区别。而另一点值得注意的是,尽管GRU 在此次实验中的表现最好,但是其结果仍然不是十分理想(从测试环节损失函数的曲线的抖动也可以看出这一点),这是因为在预测过程中本文仅使用了事件描述这一属性,而没有参考其他属性,例如事件种类、所在组别、举办时间、举办地点、举办者等,属性的缺失限制了这些预测模型的上限。如果在预测时加上这些属性,可以预见准确度会有所提升。
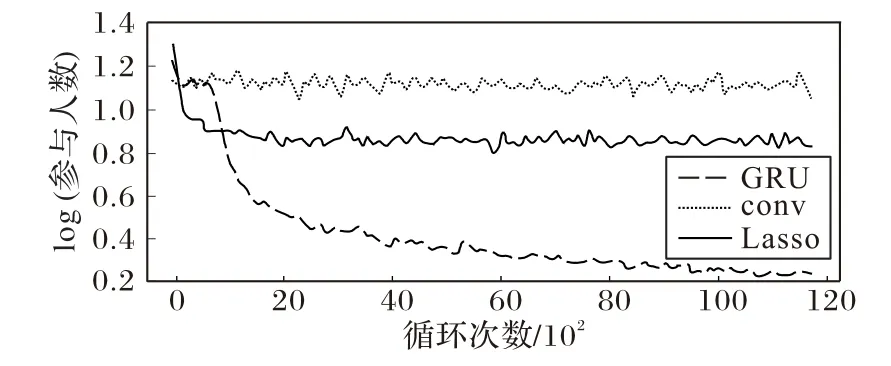
图5 训练过程中的损失函数变化Fig.5 Loss function change during training process
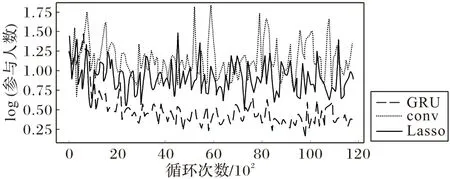
图6 测试过程中的损失函数变化Fig.6 Loss function change during testing process
3.3.2 不同文本处理方式预测事件结果准确率实验
此实验中,为了衡量事件描述对事件参与人数的影响,本文将事件描述作为一个可选的属性,使用随机森林、Adaboost等分类器对事件成功性进行预测。如果加入的属性提高了预测结果的准确率,那么便可推测,该属性会对事件结果产生正向影响。由于在第一个实验中卷积神经网络的效果并不理想,所以第二个实验中将其舍弃,仅用拉索回归和GRU 来处理事件描述。
在训练回归模型时,本文从去重的原始数据中抽取50%的事件,将其移出数据库,以免对接下来的实验结果造成干扰。在训练分类器时,本文从数据库中抽取10 000条数据,并采用重复采样的方式使正负数据比例达到1∶1,以避免不平衡数据集对实验结果带来的影响。最终本文使用Adaboost、决策树、K 最近邻(K-Nearest Neighbor,KNN)和随机森林作为分类器,采用四折交叉验证,并使用网格搜索来确定最佳参数。
使用GRU 作为编码器的神经网络处理事件描述时,采用70%的数据作为训练数据,剩余的30%用来评估分类结果,仍然使用交叉验证和网格搜索的方式来确定最佳参数。最终实验结果如表4所示。
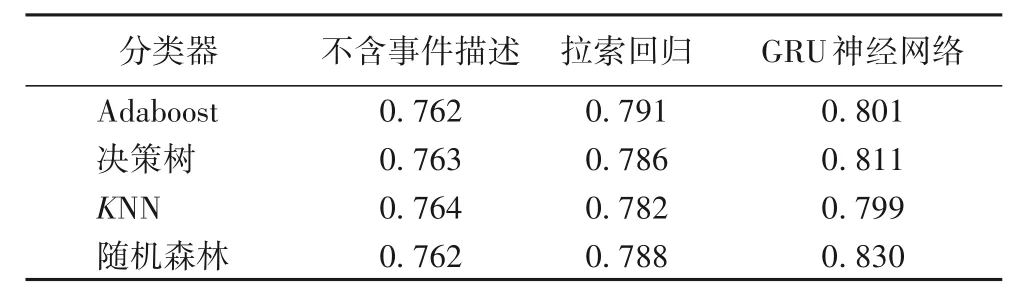
表4 不同文本处理方法和分类器对预测事件结果的影响Tab.4 Effect of different text processing methods and different classifiers on event prediction results
对比使用拉索回归处理和不包含事件描述的预测结果,可以发现,分类精度提高2.35%(KNN 分类器)~3.8%(Adaboost分类器)。对比使用GRU神经网络处理和不包含事件描述的预测结果,分类精度提高4.5%(KNN 分类器)~8.9%(随机森林分类器),这证明事件描述能够影响事件结果。对比GRU 神经网络和拉索回归两种处理方式,无论基于哪种分类器,GRU 神经网络处理方式的分类精度均更高。由于拉索回归将文本序列视作词的集合,丢失了序列信息,而序列信息对于文本处理非常重要,基于GRU 的神经网络不但保留了序列信息,而且在转换过程中尽量保留原始信息,更忠于原始文本,所以取得了更好的效果。同时可以看出,无论基于何种分类器,添加事件描述后分类精度都有了提高,这证明事件描述在提高事件参与度方面的重要作用。
4 结语
本文主要应用拉索回归、卷积层的神经网络、门控循环神经网络三种方式研究了事件描述对事件参与度的影响。实验证明,增加事件描述能够提高事件参与度,且使用GRU 的神经网络在预测事件参与人数的精度上都要高于其他两个预测模型,显示了循环神经网络在处理时序信息上的能力。与此同时,可以看到,只凭事件描述预测事件参与人数准确率提升有限。未来工作中,将进一步结合其他因素,如时间、地点、组织者、事件类型等进行综合预测,以提高预测的准确度。
猜你喜欢
中华手工(2017年2期)2017-06-06
中外会展(2014年4期)2014-11-27
大众创业(2009年10期)2009-10-08
数字社区&智能家居(2009年7期)2009-09-29
数字社区&智能家居(2009年11期)2009-06-25
数字社区&智能家居(2009年3期)2009-04-21
数字社区&智能家居(2009年2期)2009-03-27
数字社区&智能家居(2009年12期)2009-02-03
建筑创作(2001年3期)2001-08-22
祝您健康(1987年3期)1987-12-30
