
一种基于GPU的枚举排序算法及其并行化
2020-12-01 03:04谷国太孙陆鹏张红艳肖汉
河南理工大学学报(自然科学版) 2020年6期
谷国太,孙陆鹏,张红艳,肖汉
(1.河南省新闻出版学校,河南 郑州 450044;2.郑州师范学院 信息科学与技术学院,河南 郑州 450044)
0 引 言
在数据处理的过程中,排序是其中非常重要的一个环节,而且排序在各种系统或应用软件中都有着非常广泛的应用,在处理数据序列的各种应用中也发挥着重要的作用[1-2]。枚举排序是通过把目标元素与其他元素进行比较,最终确定其在整个元素序列中的位置。随着社会信息化的快速发展,无论在科学研究、工业生产、娱乐,还是在社会民生、环境与商业等领域,数据量都呈现爆炸式增长,这就对计算速度提出了更高的要求,提高枚举排序的运算速度有着非常重要的意义[3-4]。
传统的枚举并行排序算法是在CPU上运行,虽然多核CPU可以提高运算速度,但是受到空间、电力、冷却等因素限制,多核系统目前面临着核数超过16个以后性能无法随内核数线性扩展以及并行软件限制等问题[5]。在基于图形处理器(graphic processing unit,GPU)的并行计算中,GPU解决了上述多核CPU在运算上的不足,同时降低了成本和功耗,为解决越来越复杂的图形和数据计算问题提供了新的方案。可以预见,在今后的发展中,GPU处理器的地位越来越重要,并将会成为提高运算速度的重要突破口[6-8]。
国内外学者对枚举算法进行了大量的研究。He G H等[9]提出一种软输入软输出度量优先MIMO检测的算法和结构。在该算法中,混合枚举策略避免了全部枚举和排序,大大降低了计算复杂度;J.Davila等[10]提出一种算法,该算法解决了稀疏枚举排序问题,比以往的算法性能更好;孙斌[11]利用MPI实现了并行枚举算法,将数据序列分成若干个小的子序列,分派给多个处理器同时进行处理排序,之后再将每个处理器的排序结果送往主节点进行整合并完成最终排序,实现了多进程并行计算,大大降低了运算时间;S.Rajasekaran[12]提出一种合并排序(LMM)算法,证明在超立方体上可以得到比Nassimi和Sahni的经典算法更简单的稀疏枚举排序;王勇超[13]利用High Performance Linpack基准测试方法对集群系统的运算速度和性能进行了研究和测试,进而深入探讨高性能计算的枚举排序算法;H.M.Alnuweiri[14]提出一种新的VLSI最优排序器设计方法,它将轮换排序和枚举排序相结合,对N个数进行排序,降低了算法时间复杂度;A.E.Perez等[15]公开了一种符号枚举排序过程的方法及使用该方法的装置,允许准确和有效地计算度量以及确定低复杂度的星座符号的最佳搜索顺序;罗明山[16]在OpenMP编程模型上实现了枚举并行排序,但是,多核处理器需要内核之间进行频繁的信息交换,实现核与核之间的同步需要大量的指令处理时间,这就需要在降低单个内核最高频率的基础上增加内核的数量。核数与主频相互牵制,并不能很好地解决问题。
目前国内外利用CUDA进行枚举排序并行算法的研究较少,大部分研究基于CPU传统的MPI或者OpenMP并行计算模型,虽然可以进行并行计算,但是加速效果不理想。为此,本文将GPU并行计算和枚举排序算法相结合,可以大大提高算法的运算能力和排序效率,着重研究如何将枚举排序算法在主从式异构计算模型下,利用GPU并行完成每个数据与其他数据大小比较以及统计记录值的计算,从而验证该结构下枚举排序并行算法对于大规模数据集数据处理的有效性。
1 CUDA体系结构
GPU由数量众多的逻辑运算部件ALU构成,这些逻辑运算部件又被划分为若干个流多处理器,而每个流多处理器中又包含若干个流处理器[17]。流多处理器是GPU结构中执行和调度的单元,包含了各自独立的控制单元,可以独立控制指令的分发和执行,流处理器是GPU最基本的计算单元[18]。
CUDA编程模型采用CPU与GPU协同工作、各司其职的工作模式,如图1所示。CPU的主要任务是逻辑分析运算和串行运算,GPU的任务主要是并行计算,目的是把并行计算任务细化和线程化。CPU与GPU都有自己相应的存储空间,且各自独立。kernel函数不是一个完整的任务,而是整个任务中可以被并行执行的步骤[19-20]。
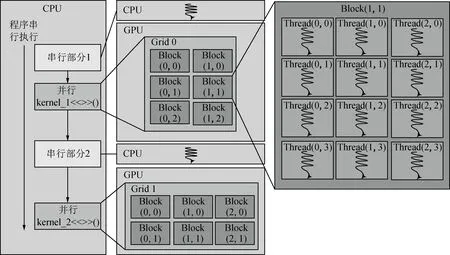
图1 CUDA编程模型
2 枚举排序算法描述
枚举排序是一种简单排序算法。算法主要思想为:对每一个待排序的元素统计小于它的所有元素的个数,从而得到该元素最终处于序列中的位置。假定待排序的n个数存在a[1],…,a[n]中[21],首先将a[1]与a[2],…,a[n]比较,记录比其小的数的个数,令其为k,a[1] ,存入有序的数组b[1],…,b[n]的b[k+1]位置上;其次将a[2]与a[1],a[3],…,a[n]比较,记录比其小的数的个数,依此类推[22]。
算法:枚举排序串行算法
输入:无序数组a[1],…,a[n]
输出:有序数组b[1],…,b[n]
Begin
for i=1 to n do
(1)k=1
(2)for j=1 to n do
if a[i]>a[j] then
k=k+1
end if
end for
(3)b[k]=a[i]
end for
End
串行的枚举排序算法描述如下。
步骤一随机产生一个数组序列a,包含n个待排序数据。
步骤二对于待排序数组元素a[i],从j=1开始依次比较a[i]和a[j],并记录比a[i]小的数的个数,记录在数组b[k+1]位置上[23]。
步骤三若i小于数组的个数n,则循环执行上述步骤二到步骤三,直至待排序数组a中的数据全部排序,否则执行步骤四。
步骤四完成排序工作[24]。
串行秩排序算法中比较操作共n*(n-1)次,时间复杂度为O(n2)。
3 GPU加速的枚举排序并行算法的分析与设计
3.1 枚举排序并行算法设计
在算法并行特征分析的基础上可以看出,每个待排序数的排序都是独立排序。结合GPU高效并行的特点,假设对一个长为n的输入序列使用n个线程进行排序,只需分配每个线程负责完成对其中一个待排序元素在有序序列中的定位和存储,使整个待排序序列的排序并行实现,接着将所有存储的信息集中到主机中即可。CUDA枚举排序并行算法描述如下。
算法:枚举排序并行算法
输入:无序数组a[1],…,a[n]
输出:有序数组a[1],…,b[n]
Begin
(1)host send a[1],…,a[n]to device
(2)for all Tiwhere 1≤i≤n par-do
(2.1)k=1
(2.2)for j=1 to n do
if(a[i]≥a[j])and(i>j)then
k=k+1
end if
end for
b[k]=a[k]
end for
(3)device send b[1],…,b[n] to host
End
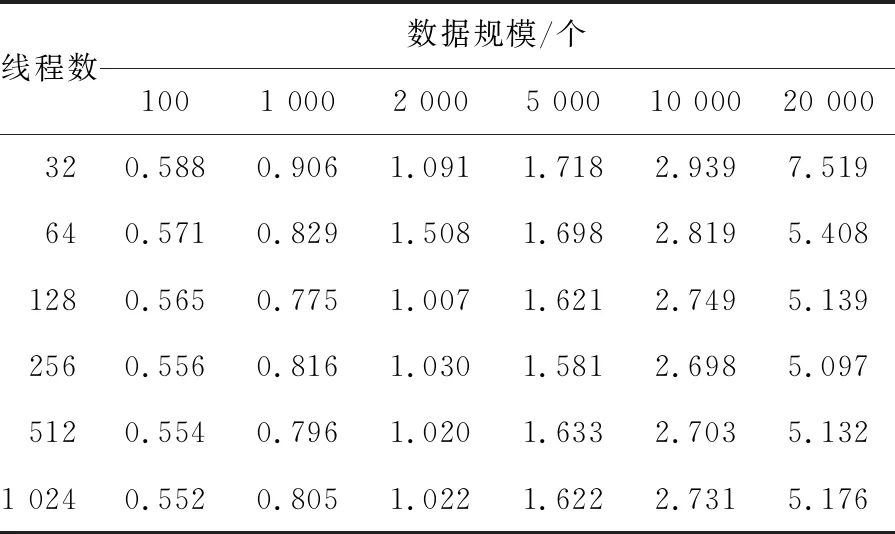
在枚举排序并行算法中使用了n个线程,由于每个线程定位一个元素,所以步骤(2)的时间复杂度为O(1);步骤(3)中设备完成的数组元素重定位操作的时间复杂度为O(n);所以总的时间复杂度为O(n)。由此可见,枚举排序并行算法时间复杂度O(n) (1)为待排序序列a和有序序列b分配设备存储器空间。 cudaMalloc((void**)& a,(n+5)*sizeof(double)) cudaMalloc((void**)& b,(n+5)*sizeof (double)) (2)把主机端的数据传递到设备端。 cudaMemcpy(a,A,(n+5)*sizdof (double),cudaMemcpyHostToDevice) (3)定义kernel配置。 线程块分配的线程数: dim3 threads(256) 网格分配的线程块数: dim3 blocks((n+threads.x-1)/threads.x) 通过实验寻找最合适的线程分配数,如表1所示。综合比较可以看出,当线程为128或256时,运算速度较快。 (4)发射kernel进行并行计算。 enume<< (5)将已排序数据从设备端传输到主机端进行输出。 cudaMemcpy(B,b,(n+5)*sizeof(double),cudaMemcpyDeviceToHost) 表1 不同线程数量运行时间对比 对枚举排序并行算法的计算效率进行测试,测试平台如下。 CPU为Intel Core i5,主频为2.50 GHz,内存为4 GB。GPU为NVIDIA GTX 580,GPU型号为GF119,属于Fermi构架。内置512个处理器核心,最高处理频率1 544 MHz。操作系统为Microsoft Window7 64位,仿真实验软件为MATLAB2013b,GPU的应用程序编程接口为CUDA7.0,开发环境为 Microsoft Visual Studio 2015。 4.2.1 实验数据 步骤一排序数据规模为100~40 000时,对基于CPU的枚举排序串行算法的运算时间计时。 步骤二排序数据规模为100~40 000时,对基于GPU的枚举排序并行算法的运算时间计时。 步骤三基于CPU的枚举排序串行实现和基于GPU的枚举排序并行实现运算时间如表2所示。 4.2.2 加速性能分析 由图2可以看出,当数据规模达到20 000时,基于GPU的枚举排序相比基于CPU的枚举排序才呈现加速效果,当数组的数值达到40 000时,基于GPU的枚举排序时间是基于CPU的枚举排序时间的1/4左右。 在枚举并行排序的过程中,如果排序数据规模比较小,CPU与GPU相比,在运算速度上有很大的优势。这是因为在GPU计算的过程中,数据在内存和全局存储器之间来回传输,数据交互带来的时间延迟是不能被忽略的,消耗了很多时间。 表2 枚举排序串并行性能对比 图2 不同数据规模的枚举排序GPU加速效率趋势图 通过实验数据可以看出,如果数据规模太小,使用CUDA并不能带来处理速度提升。因为,对于一些数据规模非常小的系统而言,串行算法运算时间非常短,甚至能够在ms级内完成。但是在使用基于CUDA计算时,由于GPU系统存在启动时间问题,在GPU上的执行时间相对就较长,而随着数据规模的不断增大,GPU运算时间增加的非常慢,而CPU运算时间则呈现迅速增长趋势,GPU强大的浮点运算能力就显现出来了。 4.2.3 系统性能瓶颈分析 在基于GPU的枚举排序并行算法中需要对存储器进行读写操作。对于n个待排序数据,需要读取n次存储器,写入n次存储器。设待排序数据集合数据为20 000,每个数据值分配存储空间大小是4字节。所以,存储器存取数据总量约为1.6 GB。除以kernel实际执行时间0.013 s,得到的带宽数值约为123.08 GB/s,这已经接近NVIDIA GTX 580显示存储器的192.38 GB/s带宽了。因而,分析可得,基于GPU的枚举排序并行算法的效率受限于全局存储器带宽。 (1)提出利用GPU并行运算提升大规模数据处理速度的方法是可行,且效果显著。 (2)通过枚举排序并行算法,在不同数据规模下,寻找每个线程块分配的最佳线程数,开展枚举排序并行算法分析,确定设计方案。 (3)通过枚举排序串并行算法实验分析发现,当数据规模达到40 000时,并行枚举排序算法时间是串行算法运行时间的1/4左右,随着数据规模的不断增大,加速比会越来越大。 (4)本文所提枚举排序并行算法是一重并行,将来研究中会继续优化并行算法,使枚举排序算法充分利用GPU的高效并行性。同时,目前主流的异构众核协处理器除了GPU以外,还有Intel的基于MIC架构众核协处理器Xeon Phi,辅助计算的能力也非常强大。下一步计划完成基于CPU+MIC的枚举排序并行算法。3.2 枚举排序算法并行化方案
4 实验与分析
4.1 实验运算平台
4.2 实验结果和性能分析


5 结 论
猜你喜欢
现代电子技术(2022年8期)2022-04-13
电脑报(2022年13期)2022-04-12
电脑报(2020年24期)2020-07-15
华东师范大学学报(自然科学版)(2020年1期)2020-03-16
网络安全技术与应用(2020年1期)2020-01-07
华东师范大学学报(自然科学版)(2019年2期)2019-06-11
电脑爱好者(2017年22期)2017-12-04
中央民族大学学报(自然科学版)(2017年2期)2017-06-11
火控雷达技术(2016年3期)2016-02-06
初中生之友·中旬刊(2015年4期)2015-06-10
