
基于师门关系的研究团队挖掘算法
2020-11-30 05:47:36李莎莎梁冬阳谭郁松吴庆波
计算机应用 2020年11期
李莎莎,梁冬阳,余 杰,纪 斌,马 俊,谭郁松,吴庆波
(国防科技大学计算机学院,长沙 410073)
(∗通信作者电子邮箱jibin@nudt.edu.cn)
0 引言
科研院校是科学研究和技术开发的基地。研究团队是院校中最基本的科研单元。同一个研究团队,研究人员的研究内容一般是相同、相近或者互为补充的。现实世界中,挖掘出合作紧密的研究团队对国家和军队的科技战略规划和人才评价体系建设都具有较大的意义。
具体而言,研究团队是指由研究者组成的集合,这个集合内部研究者之间存在很强的关系,而这个集合的研究者与其他集合的研究者之间的关系则相对较少。现有的研究工作大多把研究团队挖掘形式化为基于论文合作网络的社区发现问题。社区发现算法大体上分为重叠社区发现算法和不相交的社区发现算法[1-2]。重叠社区发现算法允许发现的社区之间存在相同节点;而不相交社区发现算法则不允许这种节点存在。常见的重叠社区发现算法有:标记传播算法[3]、主成分分析[4-5]等。不相交的社区发现算法有:鲁汶算法[6]、GN(Girvan-Newman)算法[7]、基因算法[8]、基于模块度的算法[9-11]等。利用上述社区发现算法,可以从学术论文中挖掘有紧密研究联系的研究者社区,然而这种学术合作的社区往往基于研究兴趣的聚合,研究团队中的研究者在研究兴趣点上的同质性较高,但组织连接较低,难以合作完成大规模的项目。相对的,大规模项目往往依赖于那些隶属同一组织并且有不同研究兴趣点,而兴趣点之间又相互关联的研究团队。
针对上述问题,本文利用学位论文中隐藏的师门和同门关系,提出了一种基于师门关系的研究团队发现算法,该算法在保证发现研究团队合理性的同时,提升了鲁汶算法的运行效率。该算法基于从学位论文致谢部分抽取出的教师和学生信息,构建师生之间的指导合作关系网络。构建过程中,将鲁汶算法中需要加入的老师节点的邻居节点,改为加入同门其他学生的指导老师节点。实验结果表明,该算法既保证了挖掘的研究团队的质量,又较大地提高了算法的运行效率。
1 理论与算法
1.1 术语定义
目前,精准的社区定义是不存在的,现阶段被广泛接受和使用的定义是由Newman 在文献[12]中提出来的:同一个社区内的节点之间的链接很紧密,而社区之间的链接比较稀疏。其数学描述为:假设G=G(V,E),社区发现就是指在图G中确定nc(大于1)个社区,C={C1,C2,…,Cnc}使得各社区的顶点集合构成V的一个覆盖。
师门在本文中指的是同一研究团队指导老师的集合,同门指的是同一研究团队学生的集合。
1.2 BiLSTM-CRF命名实体识别模型
BiLSTM-CRF[13]模型结合双向长短时记忆神经网络(Long Short-Term Memory,LSTM)与条件随机场(Conditional Random Field,CRF)实现命名实体识别。如图1所示,该模型自上向下分别是Embedding 层、双向LSTM 层和CRF 层。Embedding 层是句子中字符的向量表示,通过预训练语言模型获得,字符向量作为双向LSTM 层的输入。双向LSTM 层通过一个正向LSTM 和一个反向LSTM,分别计算每个字的上文与下文信息,然后将前向和后向LSTM 的隐状态输出进行拼接,形成字符的编码表示;最后,CRF 层以双向LSTM 获取的字符编码作为输入,对句子中的字符进行序列标注进而获取命名实体。

图1 BiLSTM-CRF模型Fig.1 BiLSTM-CRF model
1.3 基于模块度的鲁汶算法

模块度是Newman[12]提出来用于描述社区划分质量的一个度量,并在实际应用中验证了它的有效性。它的计算方法如式(1)所示:其中:m 为图中边的总数量;ki表示所有指向节点i 的权重之和,kj同理;表示节点i,j之间的权重,没有设置权重则默认为1;Ci为节点i所在的社区编号,函数δ(Ci,Cj)中,当节点i和j处于同一个社区时取1,否则取0。
在基于模块度的社区发现算法中,最直接的方法就是列举出所有的社区划分情况,然后计算每一种情况的模块度来选取最好的社区划分。但是当数据规模较大时,这种方式所需要的计算量太大,因此需要优化模块度的计算来降低计算量。基于模块度的社区发现算法的主要优化策略有:基于贪心策略、基于层次聚类和融合多策略的方法等。鲁汶算法就是一种融合多策略的社区发现算法。Fortunato等[14]认为鲁汶算法是当前最好的模块度优化算法,而且很多大型的复杂网络划分软件都使用了鲁汶算法。
鲁汶算法的计算过程是首先将所有的节点当成一个独立的社区,然后针对每个节点遍历它的所有邻居节点,计算加入每个邻居节点后的模块度收益,选择收益最大的邻居节点加入该节点,重复这一计算过程,直到社区趋于稳定。
2 本文算法
本章将从学位论文致谢部分师门信息的抽取形式化为命名实体识别任务,使用BiLSTM-CRF 模型抽取师门和同门命名实体,构建师生之间的指导合作关系网络,并基于师门关系改进鲁汶算法,提高算法运行效率。
2.1 师门信息抽取
在学位论文中,封面上的老师信息大多只包含导师和一个协作导师,但是大部分学生都是由隶属于一个研究团队的多个导师一起指导出来的,学位论文的致谢部分比较完整地包含了这种师生信息。学位论文作者在致谢部分对学习期间的指导老师、同学表达感谢,本文需要抽取的是师门和同门信息,这些信息一般都会有较为明显的标签,如图2 所示。其中浅黄色标签表示标注的老师信息,深红色标签表示标注的学生的信息。虽然标签特征比较明显,但因为致谢书写不规范,使得基于规则的方法难以准确地抽取师生信息。本文使用BiLSTM-CRF模型抽取师生信息。

图2 人工标注师门关系Fig.2 Manual labeling of teacher-student relationship
本文使用500 份人工标注的训练数据进行模型训练,100份人工标注的测试数据验证模型的性能,实验结果如表1 所示。从表中可以看出师门和同门信息抽取性能虽然不是很理想,但基本可以满足后续研究要求。

表1 师门和同门关系抽取实验结果 单位:%Tab.1 Results of teacher relationship and classmate relationship extraction unit:%
2.2 师生指导合作关系网络挖掘
本文通过规则抽取了封面上的导师信息,使用BiLSTMCRF模型抽取了致谢部分的师门和同门信息。师门中的指导老师和封面导师同时指导同一个学生,他们之间有着指导学生的合作关系。本文把每一个学生的指导老师和封面导师之间都用边互相链接,构建师生之间指导合作关系网络。在该网络中部分老师有着相同的名字,本文假设各个学院之间没有交叉合作的研究团队以及同一个学院中相同姓名的老师是同一个人,本文依据上述假设执行重复人名去重操作。
2.3 基于师门关系的鲁汶算法
由上文可知,鲁汶算法是一种性能优异社区发现算法,但是仍有较大的改进空间。例如de Meo 等[15]通过改善鲁汶算法的结束条件,大幅提高了算法的运行速度。
鲁汶算法的计算是遍历节点的所有邻居节点,选择最大的模块度收益,加入该节点所在社区。而在获取到师门和同门关系之后,不需要再遍历所有的邻居节点,可以通过老师节点得到所指导学生的同门学生,通过遍历同门学生指导老师节点即可。本文假设在院校中同一个研究团队的老师,会一起合作共同指导学生或者同门的其他学生,因此若老师没有共同指导的学生本文则假设两个老师不属于同一个研究团队。基于上述假设,本文改进鲁汶算法,改进后的鲁汶算法牺牲了一部分精度,但是运行效率得到了较大的提升,同时挖掘出的研究团队也更加合理,其算法伪代码如下所示。
算法1 基于师门关系的鲁汶算法。

3 实验分析
由于基于师门关系的鲁汶算法是针对特定场景对鲁汶算法的改进,本文通过两组实验对算法的性能和运行效率进行验证:实验1 通过将鲁汶算法和标签传播算法、聚集系数算法在公开的真实网络数据集进行性能对比实验,验证鲁汶算法的性能;实验2 通过比较原始鲁汶算法和基于师门关系的鲁汶算法在不同规模的学位论文数据集上的性能和运行效率,证明了基于师门关系的鲁汶算法具有较好的性能和运行效率。
3.1 实验环境
本文实验环境如下所示:硬件环境为Inter Core i7-5930K CPU,64 GB 内存,2 块GeForce GTX TITAN X 图形显卡。操作系统为Ubuntu Kylin 16.04。编程语言为Python 2.7.12。
3.2 公开数据集
实验1在American College football、Zachary karate club[16]、Dolphin social network[17]三个真实网络数据集上进行,它们分别是美国大学生足球联赛、美国大学空手道俱乐部和海豚社会关系数据集,其数据规模如表2所示。

表2 真实网络数据集规模Tab.2 Real network dataset scales
3.3 评价指标
社区发现的质量需要评价指标来衡量,下面主要介绍标准化互信息(Normalized Mutual Information,NMI)和兰德指数(Adjusted Rand Index,ARI)两种评价指标。
NMI 是用来比较两个社区划分结果的相似程度,可以用来比较社区发现算法的社区划分结果与真实社区的相似程度,以此来判断社区发现算法的有效性。其计算方法如式(2)所示,其中:N 表示节点的数量;Ca(Cb)表示在A(B)划分中总的社区数量;Ci(C·j)表示在矩阵C 中第i 行(第j 列)所有元素的求和;Cij表示在A 的划分中属于i 社区,而在B 划分中属于j社区的节点数量。NMI 的值域是0 到1,越高代表划分得越准。
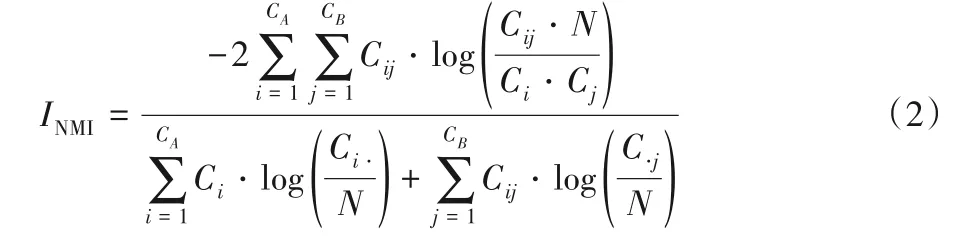
ARI 是用来衡量社区划分结果的另一个重要指标,该指标不考虑使用的聚类方法,把方法当作一个黑盒,只注重结果。计算公式如式(3)所示,其中a11、a00、a10、a01表示节点对的数量。假设A 和B 是两个节点,则a11中的第一个数字1 表示A、B 两个节点在真实的社区划分中属于同一个社区,反之则第一个数字为0;a11中的第二个数字1表示A、B两个节点在社区发现算法中划分在同一个社区,反之则第二个数字为0。所以a11、a00、a10、a01代表满足上述条件的节点对的数量。

3.4 实验分析
为验证原始鲁汶算法在社区发现中的性能,执行实验1。实验结果如表3所示。
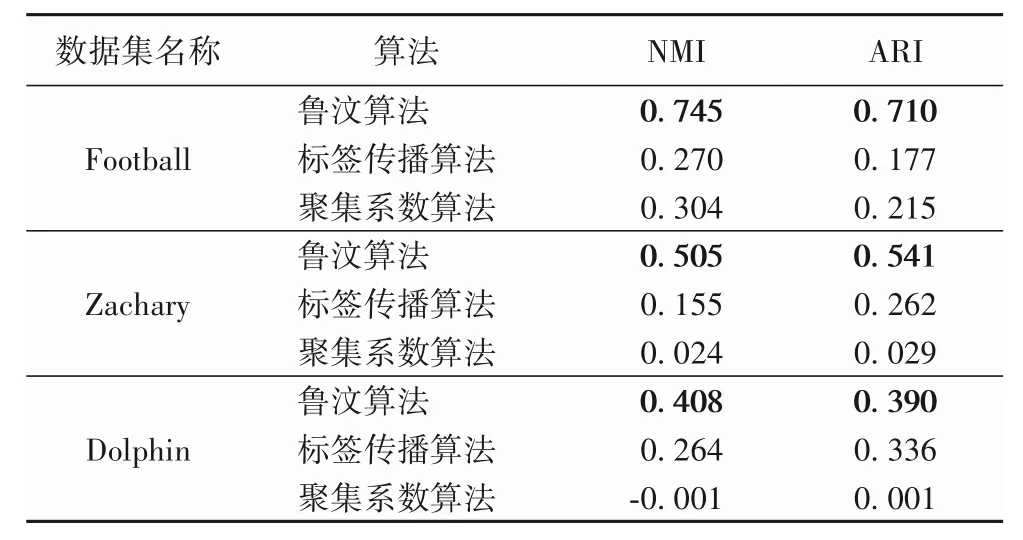
表3 社区发现算法性能对比实验Tab.3 Community detection algorithm performance comparison experiment
从表3 中可以得知,在三个数据集上,原始鲁汶算法性能均为最优,无论是只有2 个社区的Zachary 数据集和Dolphin数据集,还是有12 个社区的Football 数据集,都得到了最佳的结果,这也证明了原始鲁汶算法的鲁棒性和容错性比较强。
为了验证改进后的基于师门关系的鲁汶算法在社区发现中的运行效率,本文使用国防科技大学计算机学院学位论文、国防科技大学学位论文和军内院校学位论文三个不同规模的数据集对比原始鲁汶算法和基于师门关系的鲁汶算法的运行效率(实验2),实验结果如表4 所示,从表中可以看出数据规模越大,改进后的鲁汶算法的效率提升得越明显。

表4 社区发现算法效率对比实验Tab.4 Community detection algorithm efficiency comparison experiment
本文以国防科技大学学位论文数据集为例,以原始鲁汶算法为参照标准,验证基于师门关系的鲁汶算法在学位论文数据集上挖掘研究团队的性能,最终得到国防科技大学的研究团队信息如图3所示。

图3 国防科技大学研究团队信息Fig.3 Research teams in National University of Defense Technology
由图3 可知,使用原始鲁汶算法挖掘国防科技大学研究团队总数为409,而基于师门关系的鲁汶算法挖掘得到的总数为441。基于师门关系的鲁汶算法挖掘出的研究团队人数均在20以下,而原始鲁汶算法得到的结果中有多个超过20人的研究团队,从团队规模的角度评估,基于师门关系的鲁汶算法更为合理。在团队人数的整体分布中,两个算法基本上呈现大致相同。总的来说,基于师门关系的鲁汶算法划分的研究团队更为细致合理,合作关系更为紧密,而且划分出的研究团队整体分布与原始鲁汶算法挖掘的研究团队类似,也可以说明基于师门关系的鲁汶算法的性能与鲁汶算法类似。
目前,科研团队的挖掘大部分都是基于论文合作网络进行挖掘,这种挖掘方式有以下几个不足:一是跨学科、跨领域、跨学校的论文合作越来越多,合作作者的研究方向千差万别,甚至完全不相关的研究方向也可能是合作作者;二是在合作作者中要分辨出老师和学生也具有一定的难度,学生对于一个研究团队来说,流动性太大,毕业后就不再属于研究团队成员,导致研究团队不够稳定;三是部分论文存在合作作者可能并没有实际参与论文工作的情况。这些对于挖掘紧密合作的研究团队都会产生一定的影响。
而基于师门关系挖掘研究团队相对来说更容易得到合作紧密的研究团队。首先,同一个师门的老师需要共同完成科研任务,所以老师的研究方向基本上是一致或者相关的,此外也更容易对老师和学生进行区分。对于基于论文合作网络与基于师门关系的研究团队挖掘方法对比如表5 所示,主要从合作紧密程度、团队规模、团队内部联系和团队稳定性4 个方面进行了对比。从表中可以看出,基于师门关系的研究团队挖掘算法在上述四个方面性能更为优异。
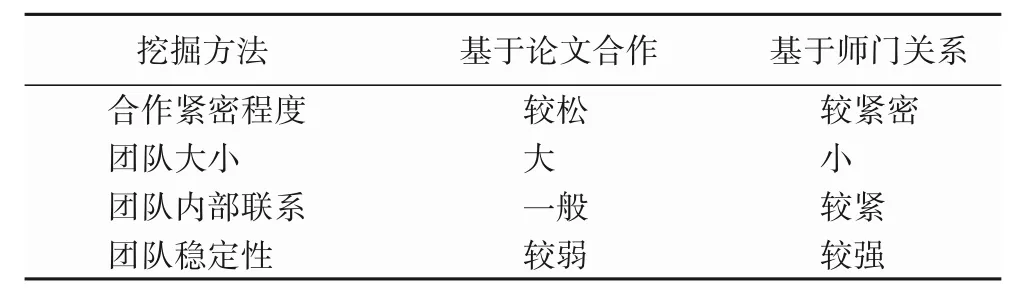
表5 研究团队挖掘方法对比Tab.5 Research team mining method comparison
4 结语
研究团队的精确挖掘对国家和军队的科技战略规划和人才评价体系建设都具有较大的意义。本文针对现有研究团队挖掘算法存在的问题,基于学位论文相关内容,提出了一种基于师门关系的研究团队挖掘算法。实验表明,相较于其他算法,该算法在运行效率、研究团队挖掘质量等方面有较明显提升。
本文提出的算法在实际应用中有一定的局限性,即无法进行深入信息挖掘进而发现研究团队的核心。将来的工作从研究团队实力分析入手,通过分析研究团队的实力来反映当前整个研究领域的现状,增强对研究领域的把握,帮助科研工作者更好地研究创新。
猜你喜欢
中华诗词(2022年6期)2022-12-31 06:42:22
青年与社会(2020年14期)2020-07-14 02:29:06
中华诗词(2018年1期)2018-06-26 08:46:46
故事作文·高年级(2017年11期)2017-11-15 11:08:57
中华诗词(2017年12期)2017-04-18 09:03:23
湖南大众传媒职业技术学院学报(2017年1期)2017-04-17 06:42:06
饮食保健(2017年5期)2017-03-24 05:35:48
新时代职业教育(2016年3期)2016-02-06 02:27:46
浙江大学学报(工学版)(2015年11期)2015-03-01 01:20:00
浙江大学学报(工学版)(2015年5期)2015-03-01 01:18:17
