
基于紧耦合时空双流卷积神经网络的人体动作识别模型
2020-11-30 05:47杨文柱陈向阳苑侗侗王玉霞
计算机应用 2020年11期
李 前,杨文柱,陈向阳,苑侗侗,王玉霞
(河北大学网络空间安全与计算机学院,河北保定 071002)
(∗通信作者电子邮箱wenzhuyang@163.com)
0 引言
人体动作识别[1]是目前视频分析与理解领域的研究热点之一,广泛应用于家庭安防、医疗监控与人机交互等诸多领域。人体动作识别的目的是从一个未知的视频或图像序列中自动分析并识别出其中包含的人体动作,其本质是时序相关的空间特征提取、表示与分类的过程。早期的动作识别主要是以手工设计特征来表示动作,然而由于人体动作种类较多,相似动作的类间差异小、类内差异大,使得动作识别任务的准确率难以提升[2-3]。近年来,随着深度学习方法在图像识别、自然语言处理等方面取得了重大的研究进展,使得其在人体动作识别领域也得到了广泛的应用[4-5]。
在人体视觉感知模型中,腹侧流(Ventral stream)主要负责物体识别,而背侧流(Dorsal stream)主要负责处理空间信息以及运动控制信息[6]。双流卷积神经网络(Two-Stream convolutional neural network,Two-Stream)[7]通过效仿人体视觉感知过程,构建两个并行的卷积神经网络分别用来提取RGB(Red,Green,Blue)视频帧中的表层信息以及堆叠光流中的运动信息,最后融合表层信息和运动信息对人体动作类别进行判定。然而,双流卷积神经网络仅仅操作单个帧(空间网络)或者短时间内的连续帧(时间网络),忽略了视频中人体动作各环节在较长时间内的相关性。Wang 等[8]以长时间建模为目标构建了时间分段网络(Temporal Segment Network,TSN),该网络首先从整个视频中稀疏地提取一系列采样片段,每个片段都将给出自身对于动作类别的初步预测,然后运用段共识函数结合这些片段的类别预测得出最后的视频级动作预测结果。为了尽可能多地获取动作视频中的运动信息,Sun等[9]提出了一种新的紧凑运动表示,称为光流导向特征(Optical Flow guided Feature,OFF),它能够快速地从卷积神经网络中提取鲁棒的时空信息,通过汇总RGB、OFF(RGB)、Optical Flow、OFF(Optical Flow)为输入的四流卷积网络得分进行动作识别。虽然双流卷积网络已经在动作识别领域取得了显著的成就,但大多数的双流卷积网络在训练阶段都只是单独训练空间网络和时间网络,时空流之间缺乏信息交互,最终导致网络整体性能降低。因此,Hao 等[10]提出了时空蒸馏密集连接网络(Spatio Temporal Distilled Dense-Connectivity Network,
STDDCN),该网络结构依据DenseNet 网络思想,在空间流和时间流之间采用密集连接方式,时间流的每一层网络都与空间流对应层以及后面的层次相连接,用时间流加强空间流,同时增强了时间流与空间流的交互性。
根据双流网络模型做出改进固然是一个不错的选择,但以此为基础结合其他网络模型的优势更加能够提升网络模型的整体性能。3D 卷积方法是将动作视频划分成很多固定长度的片段,然后利用其可以同时提取三维信息的特性从连续帧之间直接提取出相应的时间信息[11]。杨天明等[12]结合双流卷积网络与3D 卷积网络,以双流卷积网络提取时空特征,再用3D 卷积神经网络提取出时空特征中蕴含的深层运动相关信息,最终提升了动作识别的准确率。另一方面,长短期记忆(Long Short-Term Memory,LSTM)网络是一种特殊的循环神经网络(Recurrent Neural Network,RNN),其中包含判断信息是否有用的输入门、遗忘门和输出门结构[13]。当信息输入到LSTM 网络中时,可以根据相应的规则判断此信息的价值,只有高价值的信息才会被保留,而低价值的信息则通过遗忘门丢弃。此结构更真实地表征和模拟了动作过程、逻辑发展和神经组织的认知过程,因此在较复杂的动作识别上更具有潜力。毛志强等[14]将双流卷积网络提取的时空特征进行融合得到时空融合特征,然后将时空融合特征输入到LSTM 网络中增强其在时间流上的建模能力。虽然上述方法巧妙运用了不同网络间的互补性能,但这种网络间的简单叠加并没有深刻剖析出人体运动的本质,没有表达出更细节的运动特征。
通过上述分析,本文结合双流卷积和LSTM 网络模型的优势,构建了一种基于紧耦合时空双流卷积的人体动作识别模型。该模型首先采用时空双流卷积网络分别提取动作视频序列中的时间特征和空间特征;然后利用LSTM 网络中的遗忘门模块在各采样片段之间建立特征层次的紧耦合连接;接着利用双向长短期记忆(Bi-directional Long Short-Term Memory,Bi-LSTM)网络评估各采样片段的重要性并为其分配自适应权重;最后结合时空双流特征完成人体动作识别。
1 模型结构设计
本文提出的紧耦合时空双流网络结构如图1 所示,该网络主要包含4 个模块:时空特征的提取、采样片段间的紧耦合连接、基于Bi-LSTM 的自适应权重分配、结合时空流的视频级特征实现动作识别。首先,训练两个2D 卷积神经网络,分别用来提取视频中的空间特征和时间特征;然后,利用LSTM 网络中的遗忘门模块在采样片段之间建立特征层次的紧耦合连接;接着,将各采样片段的时空特征依次输入到Bi-LSTM 中获取自适应权重并结合得到的权重完成视频级预测;最后,融合时空网络的预测结果实现人体动作识别。
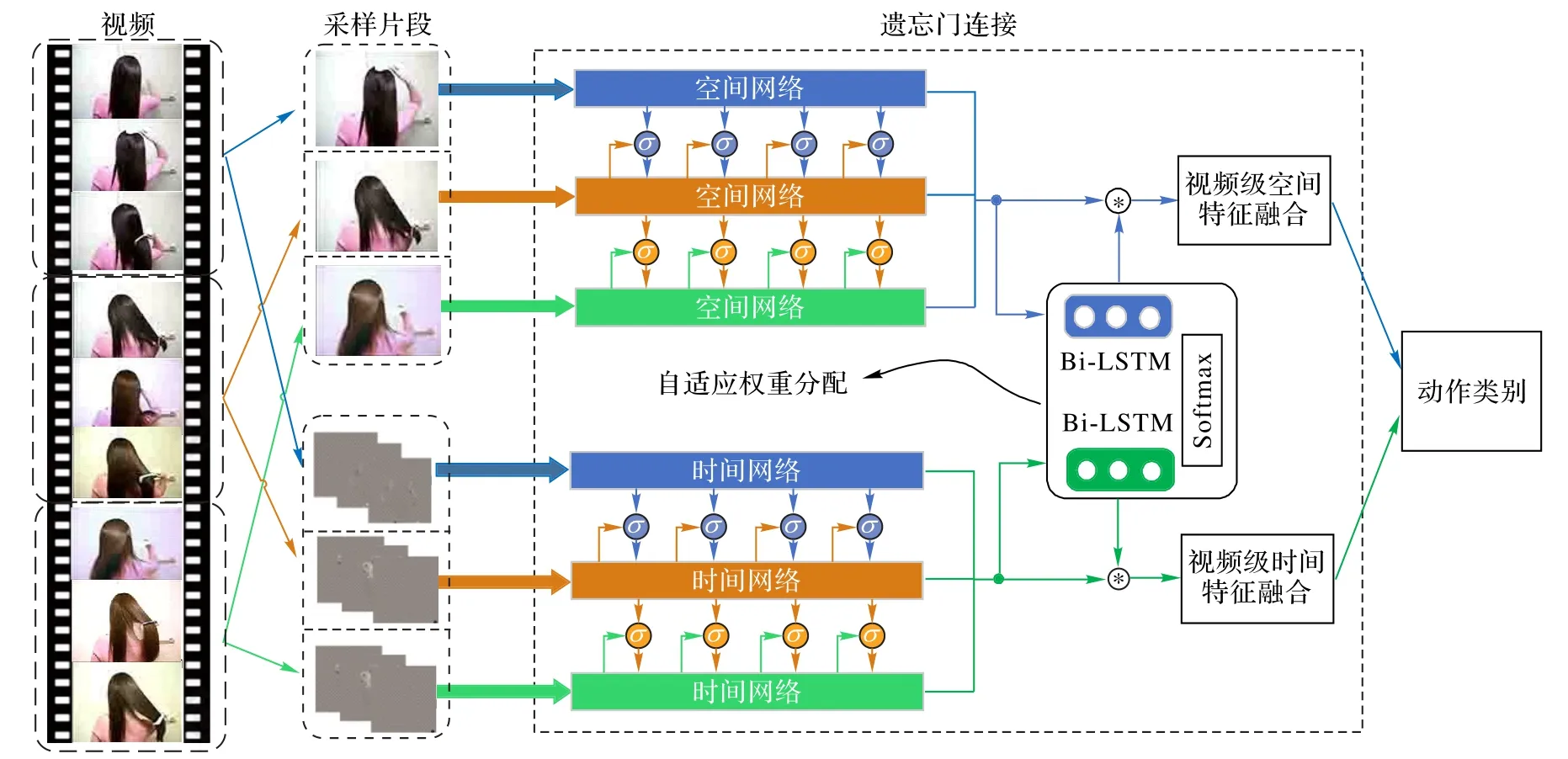
图1 紧耦合时空双流网络总体结构Fig.1 Overall structure of tightly coupled spatiotemporal two-stream network
1.1 空间流卷积神经网络
空间流卷积神经网络以RGB 视频帧作为输入,通过提取静态图片中的表层信息来实现视频中的人体动作识别,其本质上是一种图片分类结构。对于视频中那些时序相关性较弱、过程较单一的动作,仅仅依靠空间流卷积神经网络就能够很好地进行分类和识别。本文构建的空间流卷积神经网络采用的是荣获2017 年IEEE 国际计算机视觉与模式识别会议(IEEE Conference on Computer Vision and Pattern Recognition,CVPR)最佳论文的密集网络DenseNet169 模型[15],其结构如图2所示。

图2 空间流卷积神经网络结构Fig.2 Structure of spatial stream convolutional network
1.2 时间流卷积神经网络
时间流卷积神经网络结构如图3 所示,同样采用的是DenseNet169模型。与空间流的输入不同,时间流卷积神经网络的输入是经若干连续视频帧计算得来的光流图。光流图可以理解为连续视频帧之间的像素点位移场,分为水平和垂直两个方向,它们更显式地描述了视频的“瞬时速度”,能够更加清晰直观地表征人体运动信息,因此对那些时序相关性较强的动作有着更加显著的判别效果。

图3 时间流卷积神经网络结构Fig.3 Structure of temporal stream convolutional network
1.3 采样片段间的紧耦合连接
在采样片段之间建立连接不仅可以利用采样片段间的互补信息,还可以增强时序上建模的连续性,进而提升人体动作识别的准确率。比如“站起”和“坐下”两个动作,如果把采样片段分开训练会破坏时间信息的连续性,从而增加误识别的可能。然而采样片段间的直接连接会加入较多的冗余信息,低价值信息的过多注入会弱化动作识别模型的识别效果,因此本文利用遗忘门的遗忘性能,在各采样片段的特征层次上建立紧耦合连接以实现低价值历史信息的遗忘与高价值历史信息的传播,其详细连接结构如图4所示。
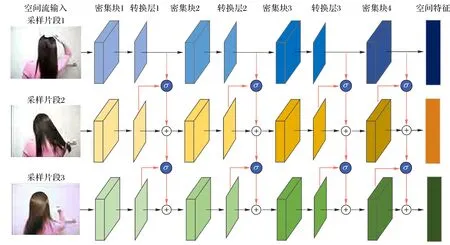
图4 采样片段间的遗忘门连接结构Fig.4 Framework of forget gate connections between sampled segments
首先,分别提取各采样片段中不同深度密集块的输出特征;然后,将相邻采样片段间对应密集块的输出特征进行遗忘门操作以得到相应的高价值补偿信息;接着,将此高价值补偿信息以元素级累加的方式注入到下一个采样片段中,从而实现采样片段间的信息流传递。图4 中符号“σ”表示遗忘门操作,符号“+”表示元素级相加,具体方法如下所示:
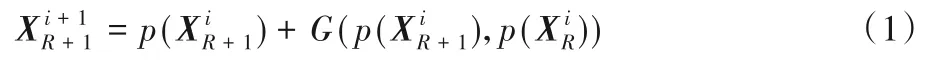
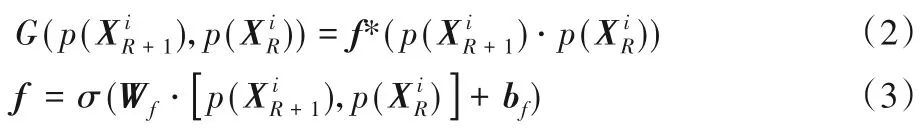
式(2)中:⋅表示元素级对应相乘;*表示矩阵相乘;f 表示遗忘门,用来过滤信息,并且f 中的所有元素都在0~1 区间内。当元素为0时表示该位置的信息会被全部遗忘;当元素为1时表示该位置的信息会全部保留;当元素在0~1 区间内时表示该位置的信息会被部分遗忘。式(3)表示LSTM 中的遗忘门模块计算公式,其中σ表示sigmoid函数,Wf和bf分别表示相应的权重和偏置。
1.4 基于Bi-LSTM的自适应权重分配
在采样片段之间建立紧耦合连接固化了时间连接性,强化了视频信息的整体表示能力,但采样片段之间的连接会使得各采样片段所包含的信息量发生改变。后面的采样片段包含了前面采样片段的部分信息,因此越后面的采样片段所包含的信息量也就越多。同时考虑到动作不同阶段的采样片段对于动作识别的贡献不同,因此本文利用Bi-LSTM 网络结构结合上下文的能力,为各个采样片段分配自适应权重。Bi-LSTM 网络相较于LSTM 网络可以更好地捕捉前后两个方向的语义关系,故而其评估可信度更高。自适应权重的计算公式如下所示:
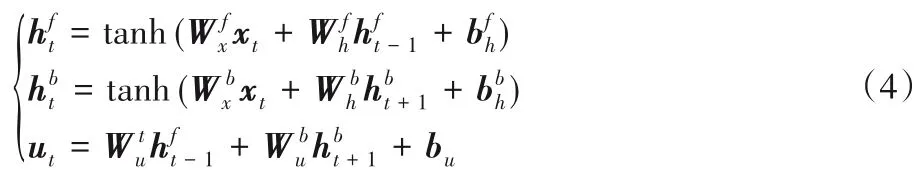
基于Bi-LSTM网络的自适应权重分配结构如图5所示。
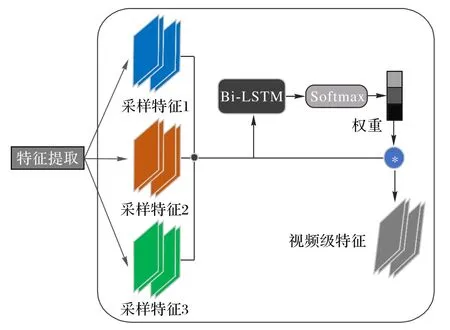
图5 基于Bi-LSTM的自适应权重分配结构Fig.5 Adaptive weight allocation structure based on Bi-LSTM
首先将各采样片段得到的卷积特征按次序依次输入到Bi-LSTM 网络中,由于Bi-LSTM 网络结构是双向传播的,中间层输出更能够考虑到前后两个方向的语义信息,故而选择中间层的输出作为结果,并将其输入到Softmax 层进行归一化处理,最终得出各采样片段的权重分配。然后结合权重分配结果计算出视频级特征,最后利用视频级特征完成动作识别,其计算公式如下所示:

其中:Mi表示经网络结构提取出的第i 个采样片段的卷积特征,S(i)表示获取的第i个采样片段的自适应权重,V表示结合相应权重得到的视频级特征,y 表示动作类别预测,Wl为相应的权重参数。
最后结合空间流和时间流的预测得分,按照文献[8]中的比例预测出动作的类别。
2 实验
2.1 实验设计
实验选择深度学习框架Pytorch 平台实现,网络训练采用小批量随机梯度下降法。时空双流卷积神经网络采用在ImageNet 数据集[16]上进行预训练的DenseNet169 模型提取时空特征。以等间隔稀疏采样的RGB 视频帧作为空间流的输入,使用统一计算设备架构(Compute Unified Device Architecture,CUDA)加速的OpenCV 模块提取TVL1 光流,并以此作为时间流的输入。
在训练阶段先把输入的图片大小固定为256×340,然后随机从集合{256,224,192,168}中选择一个候选的裁剪大小进行裁剪,最后把裁剪下来的图片重新固定为224×224 的大小。训练过程中,将批次大小设置为8,动量设置为0.9。对于空间流网络,将丢失率设置为0.8,初始学习率设置为0.001,每15 000 次迭代学习率缩小为原来的1/10,直至迭代50 000次后停止训练;对于时间流网络,将丢失率设置为0.7,初始学习率设置为0.005,在第50 000次迭代后每50 000次迭代学习率缩小为原来的1/10,直至迭代200 000 次后停止训练。
实验数据集采用UCF101[17]和HMDB51[18]数据集。UCF101 数据集包含101 个动作类别,共有13 320 个视频段,其中每个类别包含100至200个视频段。UCF101数据集是在无约束的现实环境下拍摄的网络视频,包含不同的光照变化,也存在着部分遮挡和相继运动的现象。该数据集可大体分为5 个主要类别:1)人与物体的交互;2)人体的运动;3)人与人的交互;4)弹奏乐器;5)体育运动。而HMDB51 数据集包含51个动作类别,共有6 766个视频段。由于HMDB51数据集里的视频片段大部分来源于电影片段,还有一部分来自YouTube 等视频网站,所以其视频帧像素较低、所含噪声信息也较多,故而HMDB51 数据集相对于UCF101 数据集更具有挑战性。UCF101 和HMDB51 数据集的部分动作采样样本如图6所示。

图6 UCF101和HMDB51数据集的部分动作采样样本Fig.6 Some action samples of UCF101 and HMDB51 datasets
实验中上述数据集均依据国际上的THUMOS13 挑战按照3∶1的比例对训练集和测试集进行划分。
2.2 结果分析
通过时空双流DenseNet169 模型分别提取RGB 视频帧中包含的空间特征以及堆叠光流中包含的时间特征,然后运用LSTM 网络中的遗忘门模块在采样片段之间建立特征层次的紧耦合连接,最后结合Bi-LSTM 网络对采样片段进行自适应权重分配。由于本实验是在TSN[8]的基础上进行改进的,故而实验对比了原始的TSN、结合紧耦合连接的TSN 以及最终结合紧耦合连接与自适应权重的TSN,其动作识别的准确率如表1所示。
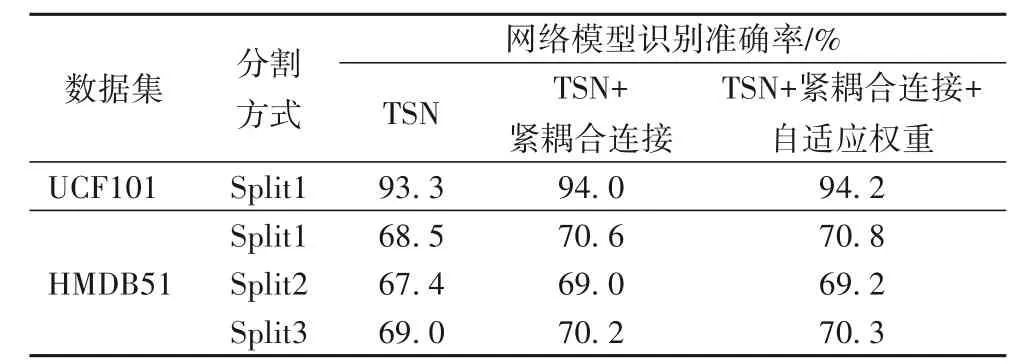
表1 不同改进方式下的识别准确率比较Tab.1 Comparison of recognition accuracy under different improvements
从表1 中可以发现,在采样片段之间加入紧耦合连接后,动作识别的准确率相较于各采样片段单独训练的TSN结构提升了0.7至2.1个百分点,而且对于识别难度较高的HMDB51数据集提升更多。这一实验结果表明在各采样片段之间增加紧耦合连接可以提升动作识别的准确率。此外,紧耦合连接模块表现的好坏受数据集中各采样片段异构性强弱的影响,采样片段间的异构性越强采样片段间的互补性信息就越多,紧耦合连接模块所展现出的效果就越好。加入自适应权重模块使得动作识别的准确率大约整体提升0.2 个百分点。一方面经过紧耦合连接,不同采样片段所含的信息量不同;另一方面不同阶段的采样片段重要性不一,故而自适应权重模块也起到了一定的效果。此外,原始的TSN 结构是以BN(Batch Normalization)-Inception 网络为基础构建的,模型参数量为41.6 MB。而本文在此基础上以DenseNet 网络替换BNInception 网络,并增加紧耦合连接模块与自适应权重模块来提高信息利用率,由于引入的参数量不多,因此模型规模并没有变化很大,其模型参数量为51.2 MB。
最后,将本文方法与其他动作识别方法在UCF101 和HMDB51 数据集上进行比较,对比实验结果如表2 所示。其中文献[10]所提出的STDDCN 与本文方法最为相似,不同之处在于本文方法是在采样片段之间建立紧耦合连接,而STDDCN 是在时空网络之间建立密集连接,从实验结果来看,本文方法的识别效果更好。此外还对比了改进的密集轨迹算法(Improved Dense Trajectories,IDT)[3]、双流卷积神经网络(Two-Stream)[7]、3D 卷积网络(Convolutional 3D,C3D)[11]、时间分段网络[8]、时空相关网络(SpatioTemporal Relation Network,STRN)[4]、时空3D 卷积神经网络(Spatiotemporal Convolutional Neural Network based on 3D-gradients,Spatiotemporal-3DCNN)[12]等经典方法以及栅格化长短期记忆网络(Lattice Long Short-Term Memory,Lattice LSTM)[19]、双流膨胀3D 卷积神经网络(Two-stream Inflated 3D Convolutional Neural Network,Two-Stream I3D)[20]等近年来主流方法。表2中的实验结果表明,本文提出的基于紧耦合时空双流卷积的人体动作识别方法识别效果比上述主流方法更好,并将动作识别准确率在HMDB51 数据集上提升了1.8 个百分点,在UCF101数据集上提升了0.4个百分点。
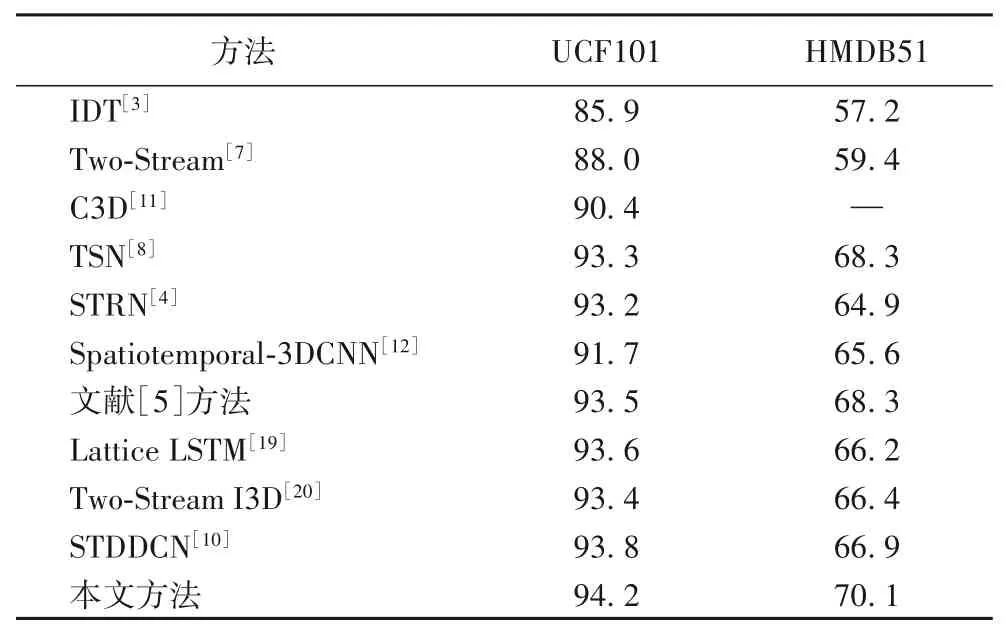
表2 本文方法与其他方法准确率的比较 单位:%Tab.2 Comparison of the accuracy of the proposed method and other methods unit:%
3 结语
本文提出了一种基于紧耦合时空双流卷积的人体动作识别方法。首先,利用时空双流网络提取视频序列中的时空特征;然后,利用LSTM 网络中的遗忘门模块在采样片段之间建立特征层次的紧耦合连接;接着,利用Bi-LSTM 网络评估各采样片段的重要性并为其分配自适应权重;最后,结合时空双流特征完成人体动作识别。在UCF101 和HMDB51 数据集上的实验表明:在采样片段之间建立紧耦合连接可以很好地实现采样片段间的信息流传递并提高时间信息利用率;自适应性权重模块能够根据上下文语义信息为采样片段分配自适应权重;本文提出的算法相较于现有的最优识别结果在UCF101数据集上提升了0.4 个百分点,在HMDB51 数据集上提升了1.8 个百分点。另外此算法在复杂度较高、时序相关性较强的动作类别上更能展现其优势。在接下来的工作中,将考虑如何提升双流网络在时空维度的交互性,使空间信息和时间信息在网络训练阶段就能够有效地进行信息交互,从而更进一步提升视频中人体动作识别的准确率。
猜你喜欢
现代经济信息(2022年22期)2022-11-13
辽宁工业大学学报(自然科学版)(2022年4期)2022-09-19
中小学校长(2022年7期)2022-08-19
四川党的建设(2022年8期)2022-04-28
作文大王·低年级(2022年2期)2022-02-28
房地产导刊(2021年12期)2021-12-31
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2020年10期)2020-11-14
作文大王·低年级(2018年10期)2018-12-06
动漫星空(兴趣英语)(2018年9期)2018-10-30
