
基于轻量级深度神经网络的环境声音识别
2020-11-30 05:47赵红东
计算机应用 2020年11期
杨 磊,赵红东
(河北工业大学电子信息工程学院,天津 300300)
(∗通信作者电子邮箱zhaohd@hebut.edu.cn)
0 引言
环境声音是指一类在具体日常生活场景中自发产生的各种声音的集合,与音乐和语音这类结构化的声音相比,它具有声源种类繁多、发声具有偶发性、主要声音和噪声并存等特点。环境声音识别(Environment Sound Recognition,ESR)是指机器能够在真实的环境声音中排除噪声干扰、识别出有用信息的能力,它是机器智能视听系统的重要组成部分,被广泛应用在便携式情景感知设备上,例如嵌入自动音频分类的物联网声学监控[1]、公共交通中基于智能音频的监控系统[2]。与视频不同,音频具有易于记录、存储和分析等特点,且录音受到设备所处位置的影响小,因而安装有环境声音识别模块的情景感知设备可在无人工干预的情况下,对其周围环境声音进行持续监控并完成相应任务。
环境语音识别是在融合信号处理、机器学习、深度学习、声学、数学等多学科知识基础上发展起来的一类应用技术。在ESR 早期发展中,研究人员主要应用包括矩阵分解[3]、支持向量机(Support Vector Machine,SVM)[4]等在内的机器学习模型来识别环境声音。近年来,随着深度神经网络[5-6]在图像、语音等领域的发展,卷积神经网络(Convolutional Neural Network,CNN)在提取环境声音特征方面极大促进模型识别性能的提升[7-10]。Piczak[11]在多个公共数据集上测试CNN 对环境声音的短音频片段的分类效果,开启了CNN 在ESR 领域的应用研究。越来越多的学者关注于如何改进基于CNN 的方法。Boddapati 等[12]在环境声音识别方面运用深度卷积神经网络GoogleNet提取声音的频谱图特征,获得了93%的识别准确率;文献[13]使用两个含有五层卷积层的MelNet 和RawNet 分别训练环境音的log 梅尔谱和原始波形特征,为保留更多信息,这两个模型舍弃传统CNN 模型在卷积层后设置最大池化层的做法,在保证高识别准确率的同时,做到缩小网络层数和保证充足信息量二者之间的平衡;文献[14]提出一个TSCNN-DS(Two Stacked CNN based on D-S evidence theory)模型,使用两组四层卷积层CNN 对由log 梅尔谱、色度、光谱对比度和音调组合的特征进行运算,然后将两组网络在全连接层实现融合;Abdoli 等[15]提出了一种基于一维的端到端环境声音分类方法,通过Gammatone 滤波器组对第一层进行初始化,直接从音频信号中提取声音特征。这些基于CNN 改进的模型通过一定的网络结构设计,从环境声音中学习多种代表性的声音特征,极大促成模型分类能力的提升。
本文的主要贡献如下:
1)在城市环境声音识别研究方面,利用SqueezeNet 核心结构Fire 模块[16]构建轻量级网络,该网络在保证识别准确率的同时,通过缩小模型参数规模,达到节省硬件内存资源、提升模型运算性能的目的。
2)以Dempster⁃Shafer(D⁃S)证据理论为基础,将基于SqueezeNet 核心结构Fire 模块建立的轻量级网络与深度神经网络(Deep Neural Network,DNN)融合,通过增加输入环境声音的全局特征变量,使得融合后的模型识别能力得到进一步的提升,展现出轻量级网络强大的识别性能,为深度网络模型在资源有限的分布式终端设备上应用提供了有力支持。
1 实验数据集与预处理
1.1 数据集
本实验使用UrbanSound8K 数据集[17],它是目前应用于自动城市环境声分类研究的公共数据集,该数据集包含8 732条已标注声音类别的音频片段(≤4 s),声音类别涵盖10个类别,表1 显示该数据集中每个声音类别所含音频片段的数量。由于数据采集于真实环境,每个音频片段都包含背景声音和事件声音。数据集由10个名为fold1~fold10的文件夹组成,每个文件夹包含约873个WAV格式的文件。
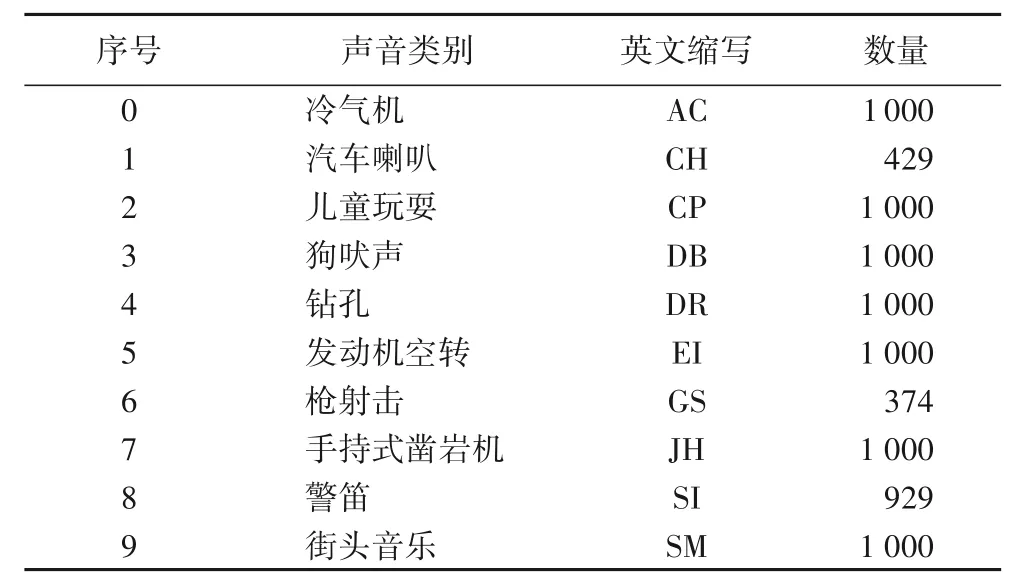
表1 UrbanSound8K数据集声音类别Tab.1 Sound categories of UrbanSound8K dataset
1.2 特征选择
因为人耳感觉到的声音高低与其频率不呈线性关系,人耳对低频信号比高频信号更加敏感,根据人耳的特性模拟出梅尔频率刻度,式(1)表示梅尔频率fMel与语音频率f 的关系,因而梅尔(Mel)倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC)被广泛应用在语音识别系统中。在环境声音分析领域,MFCC常被用作衡量新技术优势的基准。
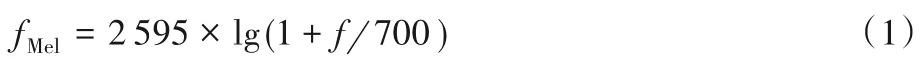
将语音频率划分成一系列三角形的滤波器,即Mel 滤波器组,取各三角形滤波器带宽内所有信号幅度加权和作为滤波器组的输出,再对所有滤波器的对数幅度谱进行离散余弦变化(Discrete Cosine Transform,DCT)得到MFCC[18],计算如式(2)所示:
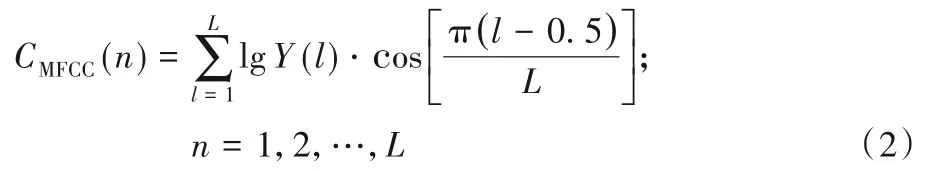
式(2)中:L 代表Mel 滤波器组的通道数量;l 为第l 个Mel 滤波器;Y(l)表示第l个Mel滤波器的输出。
本实验以25 ms 的窗口和10 ms 帧长为参数从音频片段中提取特征,计算出0~22 050 Hz的40个梅尔(Mel)波段,并保留40 个MFCC 系数,得到的特征矩阵为40×174×1,即频率×时间×通道,如图1所示,在这一过程中,需要对时间维度不足的特征矩阵进行补零至统一长度。
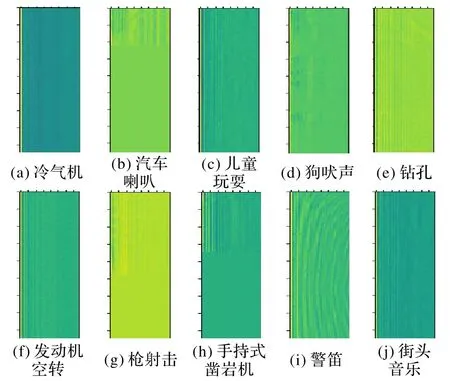
图1 十类声音可视化MFCC谱图Fig.1 Ten kinds of sound visualized MFCC spectrums
除图1 所示的40 维MFCC 谱图外,为获得环境声音更全面的特征,还需从环境音频片段提取另一组40 维全局特征向量。提取过程如下:首先从片段的每一帧中提取40 维特征向量,其中1~4 维分别是频谱均方根、频谱质心、频谱带宽和频谱滚降点,5~40维分别是12维MFCC、12维MFCC一阶差分参数和12 维MFCC 二阶差分参数;然后在每个维度上对所有帧的结果取算数平均值,从而得到40维全局特征向量。
MFCC差分计算如式(3)所示:

式(3)中:dt表示第t 个一阶差分;Ct代表第t 个倒谱系数;Q 为倒谱系数的阶数;K 表示一阶导数的时间差,可取1 或2。将MFCC 一阶差分参数再代入式(3),得到MFCC 二阶差分的参数。
2 模型构建
2.1 参考卷积神经网络
实验首先搭建一个传统CNN 模型作为参考,并将其命名为Cnet 模型。该模型包括一个输入层、四组“卷积+池化”结构和一个输出层。每组“卷积+池化”结构中,卷积层的步幅为1,卷积核的大小设置为3×3;池化层的步幅设置为2;使用线性整流函数(Rectified Linear Unit,ReLU)[19]作为激活函数。输出层使用Softmax 函数获得分类概率,模型参数如表2所示。
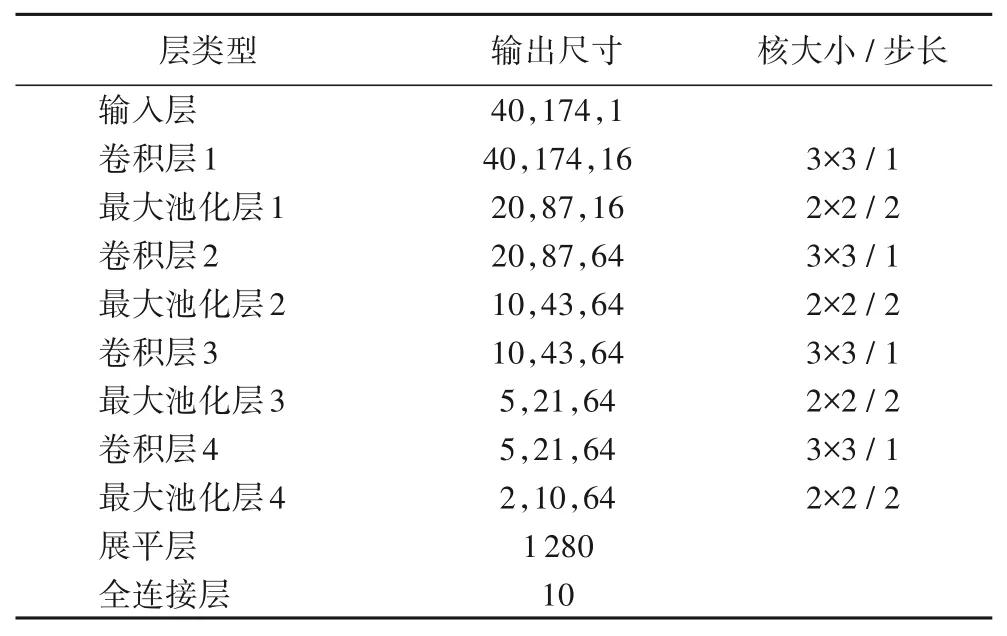
表2 Cnet 模型参数Tab.2 Cnet model parameters
2.2 SqueezeNet卷积神经网络模型
SqueezNet 卷积神经网络模型是由加利福尼亚大学伯克利分校和斯坦福大学的研究学者在2016 年联合提出的一种旨在降低模型参数输入量的网络模型,它能解决AlexNet[20]和VGGNet(Visual Geometry Group Net)[21]模型因参数量巨大而降低运算效率的问题。该网络通过缩小模型卷积核大小、用平均池化层代替全连接层的方式构建Fire模块结构以达到在保证识别准确率的基础上减少模型参数量的目的。Fire 模块结构包含两层卷积层:压缩层和扩展层,它们各自连接一个ReLU 激活层,其中压缩层全部由S 个1× 1 的卷积核构成,扩展层包含E1个1× 1 的卷积核和E3个3× 3 卷积核,卷积核的数量关系满足S <E1+E3,见图2。
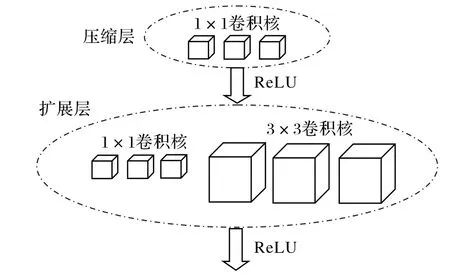
图2 Fire模块结构Fig.2 Structure of Fire module
在文献[16]中,SqueezeNet 网络模型共有9 组Fire 模块,中间穿插3 个最大池化层,并用全局平均池化层代替全连接层以减少参数数量,同时为控制输入和输出的大小,在上层和下层各使用一个卷积层。在本实验中,“S”代表压缩层中卷积核数量,“E”代表扩展层中卷积核数量,并设定E1=E3,E=E1+E3。SqueezeNet 网络模型为处理ImageNet 数据集而设计,它对UrbanSound8K 数据集进行分类会产生过拟合,从而无法有效分类,本实验使用SqueezeNet 网络的核心Fire 模块结构搭建网络。
Fire 模块将H1×W1×D1大小的特征图作为输入,H2×W2×D2大小的特征图作为输出,其中H1×W1和H2×W2分别是输入特征图和输出特征图的尺寸,D1和D2分别是输入特征图和输出特征图的通道数量。本实验以卷积核乘法运算次数作为统计计算量的依据,Fire模块的计算量CFire如式(4)所示:
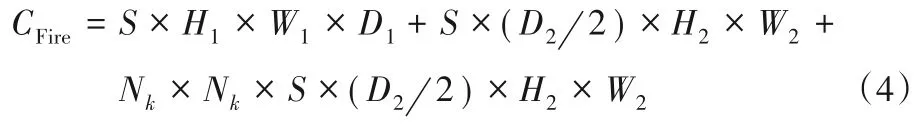
Fire模块的卷积核参数数量设为NFire,计算见式(5):
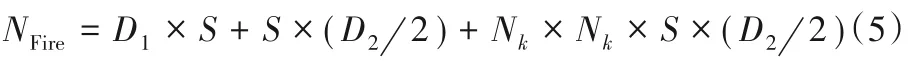
式(4)和(5)中:Nk为扩展层中E3的卷积核尺寸[22],通常选择Nk值为3。
卷积核的计算量为CCNN,如式(6)所示:
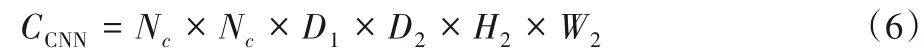
卷积核参数数量为NCNN,如式(7)所示:

式(6)和(7)中:Nc为卷积核尺寸,一般选择Nc值为3、5 或7。通常情况H1×W1和H2×W2相同,由式(4)~(7)可知,Fire 模块与卷积核的计算量比值及其参数数量比值均为R,见式(8):

当Fire 模块(S,E)分别取(8,32)和(16,64)时,按表2 层类型中卷积层2 的输入通道参数和输出通道参数,计算出R值分别为0.29和0.57。由此可见,在网络计算量和参数数量方面,与Cnet模型相比,基于Fire模块的轻量级网络模型具有明显优势。
2.3 D⁃S证据理论
D-S 证据理论是20 世纪70 年由哈佛学者Dempster 和Shafer 提出的一种不确定推定理论,在80 年代后逐渐引起归纳逻辑、人工智能等领域的研究学者的关注[14]。该理论实质上是在由一系列互斥的基本命题组成的识别框架上,通过引入信任函数概念对各命题分配信任程度,即基本概率分配(Basic Probability Assignment,BPA),并提出不同证据信息的基本概率分配共同作用生成一个反映融合信息的新的基本概率分配的证据组合规则。
1)基本概率分配。
假设某问题的所有可能答案组成一个互斥的非空完备集合Θ={A1,A2,…,An},也称识别框架,其中元素Ai称为的基元,将Θ 的幂集用2Θ表示。如果集函数映射并满足那么称该映射m 是识别框架Θ上的基本概率分配函数(BPA),也称为mass函数;Φ为不可能事件;∀A ⊆Θ,m(A)称为A的基本概率分配。
2)Dempster证据合成规则。
对于∀A ⊆Θ,在同一识别框架Θ 上的两个mass 函数m1,m2,其基元分别为B 和C,Dempster 合成规则如式(9)~(10)所示:
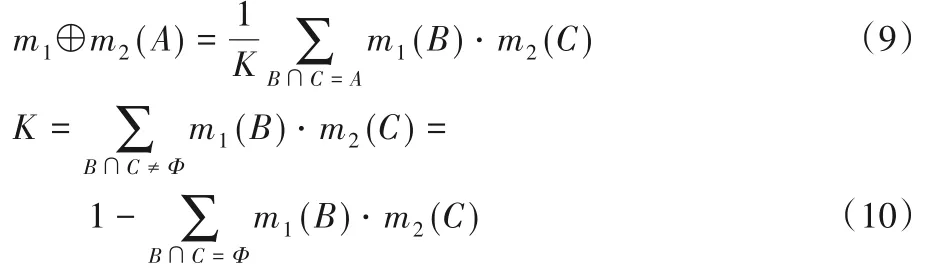
对于∀A ⊆Θ,识别框架Θ 上的有限个mass 函数m1,m2,…,mn的Dempster合成规则如式(11)~(12)所示:
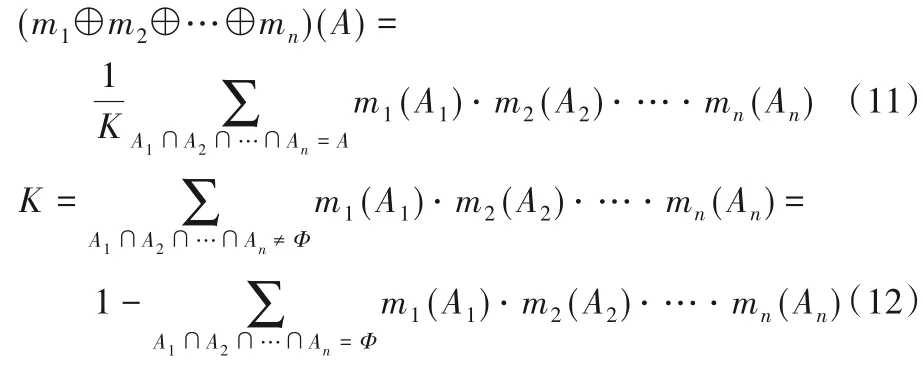
式(12)中:A1∩A2∩…∩An=Φ 表示信息冲突的部分;A1∩A2∩…∩An=A 表示信息一致的部分;⊕为正交和;K为剔除冲突干扰的归一化因子,其作用是将空集上丢失的信任度按比例分配到非空集上,从而满足概率分配要求。K 值越小说明证据的冲突越大;如果K=0 则证据完全冲突,合成规则不再适用。
2.4 基于Fire模块的网络
本实验针对参考卷积神经网络模型Cnet[23],设计一类基于SqueezNet 网络Fire 模块的轻量级网络模型,并将其命名Fnet,见图3。
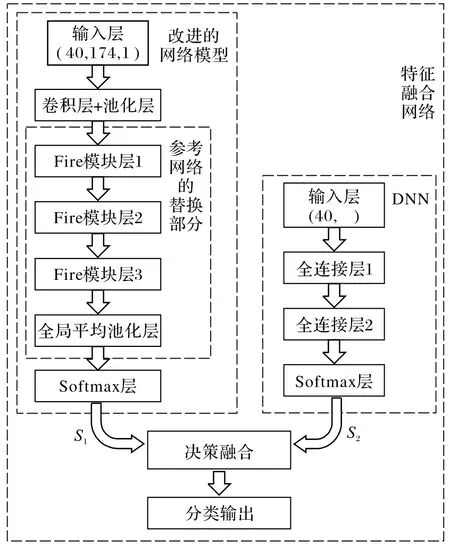
图3 基于Fire模块的网络Fig.3 Fire module based network
Fnet由输入层、一组16个3×3卷积核构成的“卷积+池化”结构、三组Fire模块、全局平均池化层和输出层构成。为有效验证模型性能,本实验采取两种策略进行对比研究:一种策略是控制压缩层和扩展层中的卷积核数量,使用S 和E 分别为(8,32)与(16,64)的两种Fire模块进行比较实验,并相应标记为Fnet1 模型和Fnet2 模型;另一种策略是为充分挖掘环境声音的特征、提高模型性能,基于Fnet2 模型融合DNN 构建FnetDNN 模型。DNN 由一个输入层、两个全连接层和一个Softmax 层组成,其中全连接层的隐含单元分别设置为128 和64。利用D-S 证据理论将Fent2 预测结果S1和DNN 预测结果S2进行信息融合生成新的基本概率分配,并以此作为决策依据。
3 实验过程与分析
3.1 实验环境与参数设置
实验在一台英特尔i5 处理器、英伟达Tesla K80 显卡和8 GB 内存的笔记本上验证本文提出的降低模型参数量的方法有效性。实验过程中,采用UrbanSound8K 数据集,在GPU上运用Keras2.0和Tensorflow2.0框架建模。实验超参数设置如下:Dropout 参数[24]0.2;优化Adam;迭代次数200;批量数64。以ReLU 作为激活函数,选择交叉熵作为损失函数,如式(13)所示:

式(13)中:yi是网络输出的第i 个预测分类,Yi是第i 个分类标签,n是分类的样本总数。最后,在全连接层后应用Softmax函数输出判断结果。
3.2 实验结果与讨论
首先,本实验以Cnet 作为参考网络,使用Fire 模块搭建Fnet1和Fnet2模型,两个模型都采用图1提取的MFCC谱图作为输入,输入维度为40×174×1。从图4的实验结果可以看出:参数数量越多,模型分类的稳定性就越高。从训练迭代200次后的分类准确性来看,Fnet1 与Cnet 具有相似的准确性,Fnet2的准确度略优于Cnet。
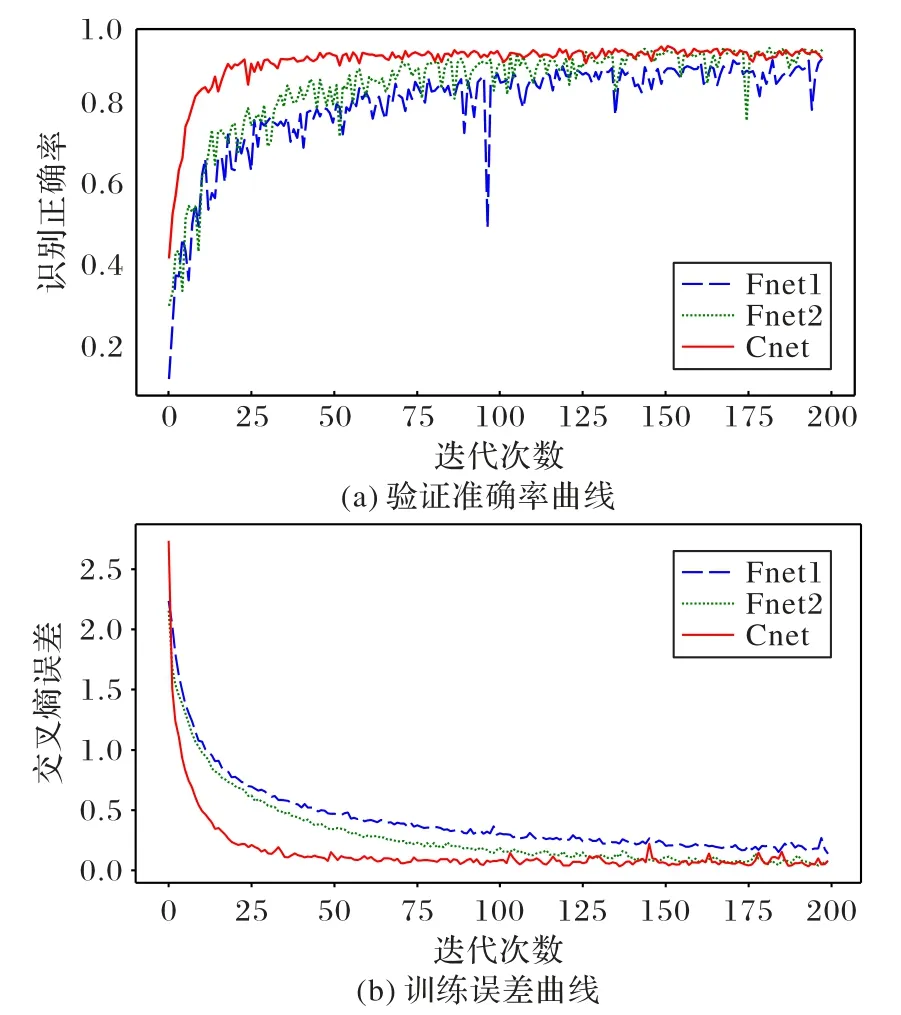
图4 模型结果比较Fig.4 Comparison of model results
表3 列示三个模型的卷积核参数量和识别准确率。实验结果说明在相同特征信息输入条件下,适当缩小网络参数规模可以带来网络分类性能的提升。由于轻量级深度神经网络能有效地节省内存资源、降低计算成本,因而它在资源有限的移动设备上更具备开发和应用的发展前景。
进一步进行实验分析,先以40 维环境声音信号的全局特征向量作为DNN 的输入,训练得到S2,再利用D-S证据理论将Fnet2 和DNN 的预测结果S1、S2进行信息融合,生成新的基本概率,如图3所示。表4为关于某一样本数据的分析结果。
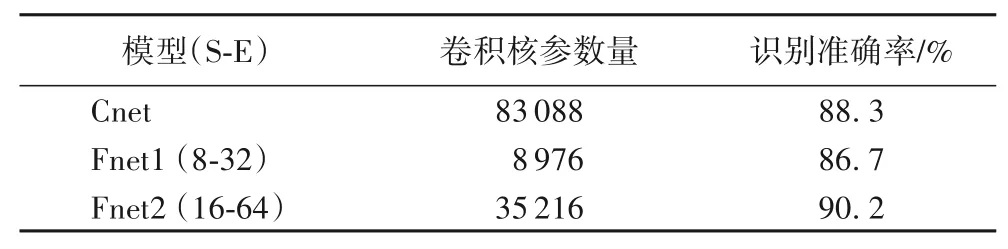
表3 模型卷积核参数量和识别准确率比较Tab.3 Comparison of models on convolution kernel parameter number and classification accuracy
对于本样本,Fnet2错误预测分类AC,DNN 正确预测分类EI,FnetDNN 通过融合后获得新的基本概率分配输出正确分类EI,对Fnet2 错误预测结果进行了校正。实验结果显示,尽管FnetDNN 参数数量略有增加,但能将分类准确率提高到94.4%。图5 从细颗粒度分析角度分析DNN、Fnet2 与FnetDNN在具体声音类别上的识别能力:FnetDNN在狗吠声、钻孔和发动机空转声类别上的识别效果更加明显;在环境声音较为复杂的街头音乐类别上,FnetDNN也具有优势。
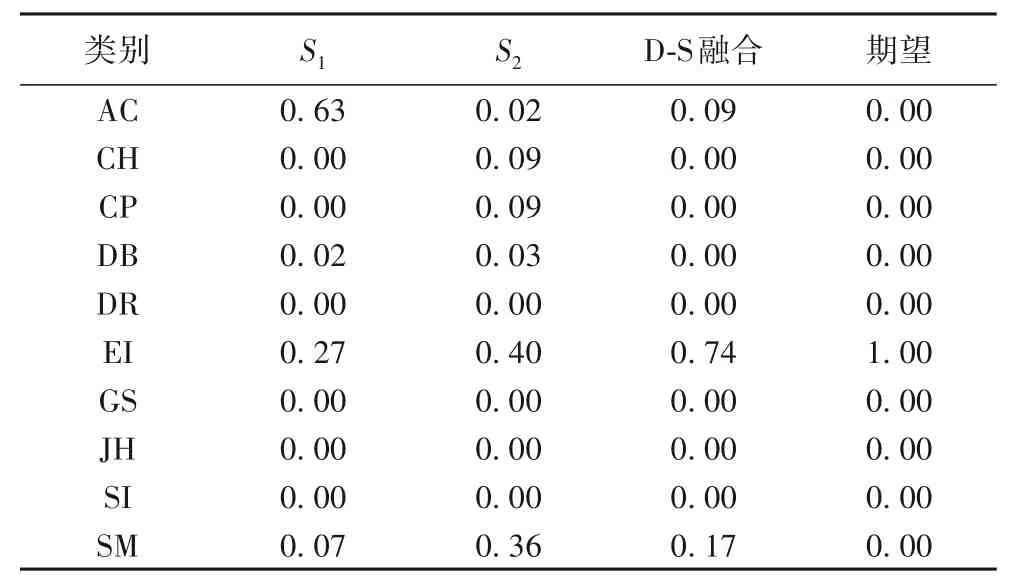
表4 模型预测概率、融合结果和期望值Tab.4 Prediction probabilies,fusion results and expected values of models
最后,表5 所示了ESR 领域近年的研究成果,与这些研究成果相比,FnetDNN 模型具有参数数量少、训练所需样本数量少和分类准确率较高的特点。由此可以看出,基于Fire 模块的网络模型Fnet 不仅可以压缩冗余参数,还可以与其他网络相融合,具有模型扩展能力。

图5 归一化混淆矩阵Fig.5 Normalized confusion matrix
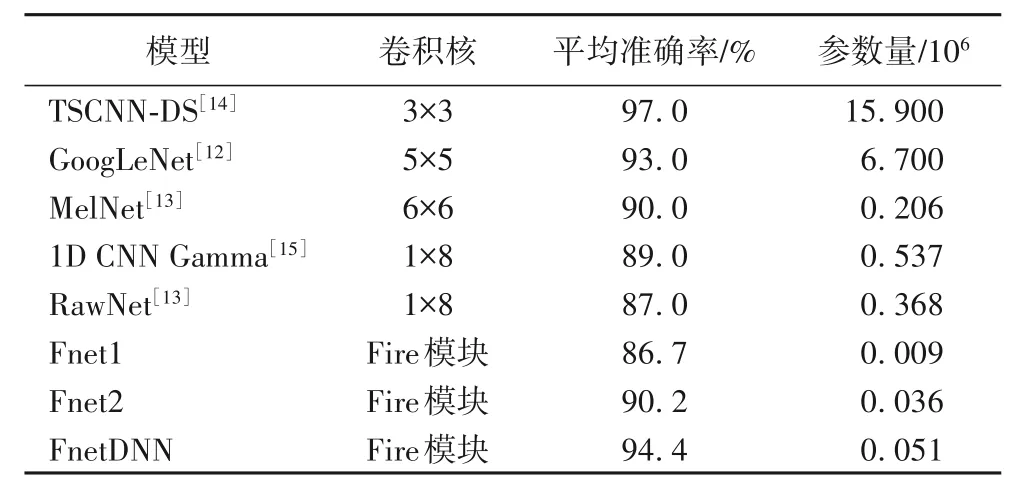
表5 UrbanSound8K上8种模型的准确率Tab.5 Accuracies of 8 models on UrbanSound8K
4 结语
本文通过对比实验证明了SqueezeNet 的Fire 模块可以直接用于压缩常规网络参数,轻量级网络Fnet1的卷积核参数数量较Cnet 网络模型减少,但可以达到与Cnet 相似的准确度,Fnet2和FnetDNN 可在存储受限的条件下,获得高水平的环境声音识别准确度,这为深度网络模型在资源有限的移动端设备上应用开发提供了有力支持。接下来的工作是优化ESR模型,提升环境音识别准确度并确保在移动端工作的实时性能。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
小学生学习指导(低年级)(2019年3期)2019-04-22
小天使·一年级语数英综合(2017年11期)2017-12-05
初中生世界·七年级(2017年9期)2017-10-13
少儿科学周刊·儿童版(2017年3期)2017-06-29
初中生世界·七年级(2017年2期)2017-01-20
小猕猴智力画刊(2016年6期)2016-05-14
