
一种面向AAC音频MDCT系数域的隐写分析方法
2020-11-26 01:36熊翘楚
广州大学学报(自然科学版) 2020年2期
熊翘楚, 蓝 海, 陈 晶*
(1. 武汉大学 国家网络安全学院,湖北 武汉 430072; 2. 武汉烽火信息集成技术有限公司, 湖北 武汉 430072)
0 引 言
随着计算机技术和互联网的飞速发展,信息安全已经与人们的生活密不可分.隐写术和隐写分析是信息安全领域中的热门研究方向[1],隐写术以多媒体数据为载体,如文本、图像、音频和视频等,通过将隐秘信息以无感知的形式嵌入到多媒体数据中,生成载密样本进行隐秘信息的传播[2].隐写术在提高信息通讯安全性和隐蔽性的同时,也易被不法分子利用.目前,越来越多的恶意软件采用隐写术进行隐秘通信,造成了巨大的安全隐患.隐写分析技术作为隐写术的对抗技术,主要通过对可疑样本进行各个维度的统计特征分析,判断可疑样本是否被嵌入了秘密信息,进而分析可疑隐写通道、信息长度等,达到完整提取秘密信息的目的[3].
目前,音视频通信和数字化服务已经在互联网上得到了广泛应用,数字音频在人们的生活中无处不在.AAC音频是3GPP(3rd Generation Partnership Project,3GPP)组织指定的移动互联网音频压缩编码标准之一[4],在相同码率条件下,相较于MP3音频格式具有更好的听觉质量,被广泛应用于多种主流高清电视标准以及其他软硬件设备,例如,iTunes、YouTube、Twitter、QQ Music、iPhone和Sony PlayStation等[5].
AAC音频因其编码原理[6]复杂,涉及的编码模块较多,在被广泛应用的同时,也带来了非常丰富的隐写空间.目前,针对AAC音频已经出现了多种隐写方法,根据隐写嵌入域的不同,可分为以下三种:量化MDCT系数域、比例因子域以及Huffman编码域.MDCT系数作为AAC音频的主要编码参数,占音频数据总量的60%以上,对MDCT系数的微量修改不会对听觉感知造成明显影响,具有良好的不可感知性和较大的嵌入容量.AAC音频编码流程及主要隐写域见图1所示.
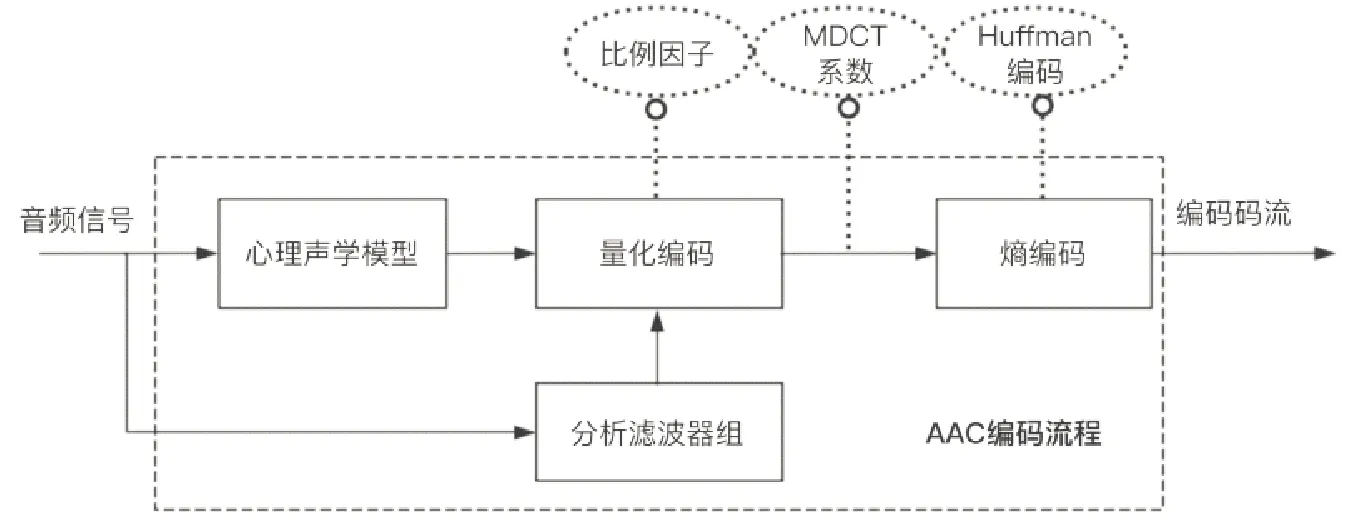
图1 AAC音频编码流程及主要隐写域Fig.1 AAC audio coding procedure and main embedding domains
目前已经出现了多种针对MDCT系数的隐写算法.文献[7](以下称MIN方法)中,王昱洁等在编码过程中,根据采用的码书序号将每一帧的MDCT系数划分为小值区、中值区和大值区,其中小值区MDCT系数值的范围为1、2号码书对应的4个MDCT系数区域.在进行隐写时,根据秘密信息来修改末位的MDCT系数值.文献[8](以下称SIGN方法)中,Zhu等利用编码过程中MDCT系数的符号位会被单独编码这一特点,根据选定的阈值T和待嵌入的秘密信息,对范围在[-T, T]内的MDCT系数对应的符号位进行修改,从而实现秘密信息的隐写.Pinel等[9]通过秘密信息来控制MDCT系数的量化区间,利用QIM算法对MDCT系数进行修改,实现了音频水印的嵌入.朱杰[10]提出在Huffman编码过程中通过设计矩阵编码算法,对溢出的MDCT系数进行LSB(Least Significant Bit,LSB)位嵌入.Wei等[11]通过修改比例因子来控制量化后MDCT系数比特位,在MDCT系数冗余位上进行秘密信息的嵌入.Zhu等[12]通过对音频每一帧的分区过程进行修改,实现基于分区过程的隐写操作.由于MP3与AAC音频在编码过程中均采用滤波器MDCT变换对音频采样数据进行处理,因此,针对MP3音频MDCT系数域的隐写算法原理同样也适用于AAC音频.常见的MP3隐写工具以及隐写算法包括MP3Stego[13]、UnderMP3Cover[14]、MP3Stegz[15]、EECS(Equal length Entropy Code Substitution,EECS)[16]、AHCM(Adaptive Huffman Coding Mapping,AHCM)[17]和JED(Joint Embedding Distortion function,JED)[18]等.
针对以上隐写算法,现有的隐写分析方法主要是利用音频的短时相关性原理,利用专家先验知识来构造具有差异性的隐写分析特征模型.王昱洁[19]通过提取MDCT系数的Markov转移概率特征,实现针对MDCT系数的有效隐写分析检测.Ren等[20]通过构建富模型特征,提取帧间和帧内MDCT系数的一阶和二阶差分Markov转移概率及联合概率密度作为隐写分析特征,对特征组进行概率加权融合,并使用SVM分类器进行分类.MP3音频的隐写分析算法对设计AAC隐写分析算法具有启发性.Yan等[21]根据MP3相邻帧量化步长间的差异实现针对MP3Stego的有效隐写分析.Yan等[22]和Yu等[23]利用重压缩技术设计基于音频统计特征的隐写分析方法实现有效检测.Qiao等[24]、Kuriakose等[25]及Jin等[26]通过分析MP3音频子带中MDCT系数的帧间相关性,设计基于MDCT系数统计分布特征的隐写分析方法.
以上通过专家经验设计出的传统隐写分析特征具有特征覆盖面较窄、检测层面有限和无法对样本进行小粒度检测等缺点,在面对未知隐写算法时,检测效果难以保证.深度学习作为一种由算法进行自动特征挖掘和表示的有效学习方法,已经在图像语音识别等很多领域得到广泛应用,并取得了非常好的效果.张坚等[27]提出一种基于重压缩预处理的CNN(Convolutional Neural Networks,CNN)低嵌入率MP3stego隐写分析方法.Wang等[28]使用高通滤波器对音频数据进行预处理,实现基于CNN的MP3隐写分析检测.目前,基于深度学习的音频音协分析方法还处于发展阶段,相较于传统方法在检测效果和通用性上已经有了很大的进展.
本文针对AAC音频MDCT系数隐写域,提出一种基于深度残差网络的通用隐写分析方法.利用多元线性拟合函数设计合适的滤波器,通过滤波操作减少音频内容对隐写分析的影响,增大隐写所引入噪声在整个音频内容信号上的比例.通过设计包含三类卷积模块的深度残差网络,对两种AAC音频MDCT系数隐写算法[8-9]进行隐写分析特征提取和分类.实验结果表明,本文提出的隐写分析方法具有良好的检测效果,相较于传统隐写分析特征检测性能有明显提升.
1 MDCT系数的短时相关性分析
根据AAC音频的编码原理,在音频码流中存在两种类型的音频帧:长帧和短帧.当音频信号平滑且舒缓时,使用1个长窗进行MDCT变换,每个长帧包含1 024个MDCT系数;当音频信号比较激烈时,将1 024个MDCT系数使用8个短窗分别进行编码,每个短帧包含128个MDCT系数.图2为AAC音频的帧结构.
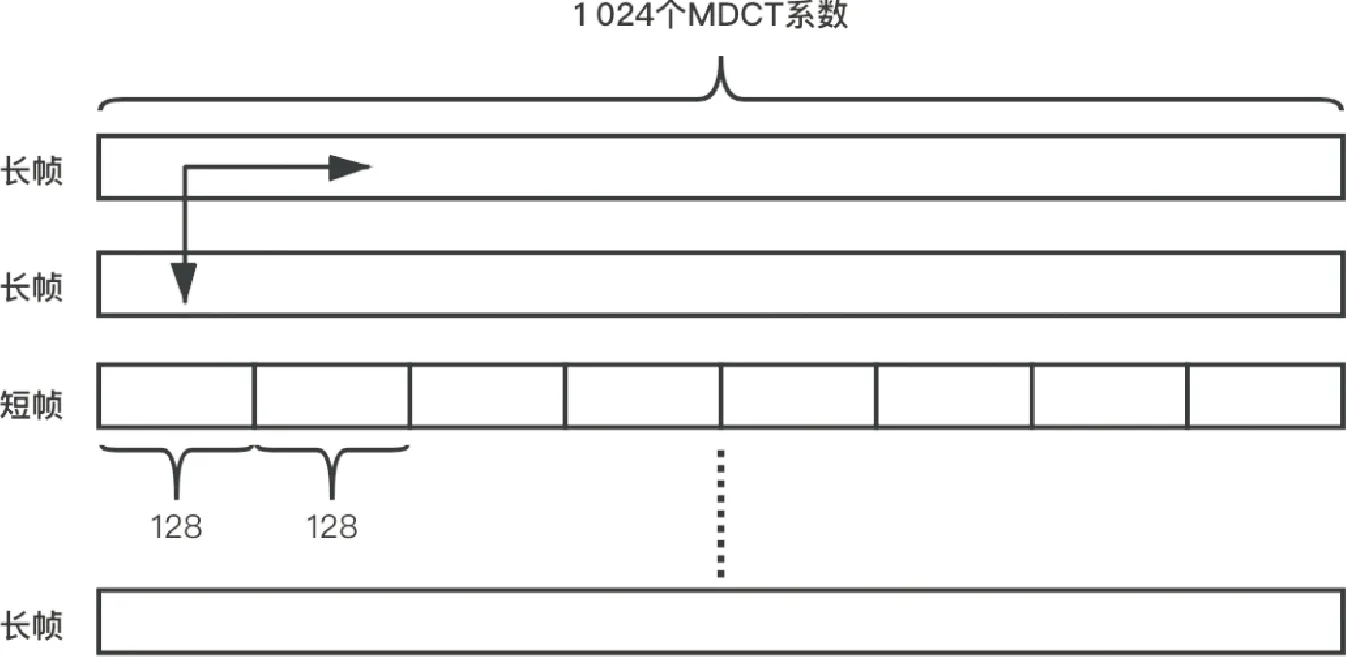
图2 AAC音频的帧结构Fig.2 The construction of AAC audio frame
在AAC音频编码过程中对音频模拟信号进行有损压缩,其中在MDCT系数量化编码过程中对音频信号的采样点进行了有损量化.虽然量化对其原始载体信号造成了一些损失,但是在很短的时间内,MDCT系数依旧能够表现出时序和频域的连续性,即语音音频具有短时的连续性和相关性.面向MDCT系数域的隐写方法通过不同的策略修改MDCT系数值,则会破坏这种短时相关性.
受图像空域富模型特征[29](Rich models for steganalysis)隐写分析方法启发,本小节利用多元线性拟合函数,对AAC音频的MDCT系数矩阵进行短时相关性度量.使用FAAC[30]编码器对100段WAV音频进行编码,本文所采用的WAV音频均为16 KHz采样频率、16位采样、时长2 s的单声道音频,得到100段32 Kbps的cover样本.提取cover样本的MDCT系数矩阵MN×1 024={f1,f2,…,fi,…,fN},其中,N表示音频帧数,1 024表示每一帧含有1 024个MDCT系数,fi表示第i帧的MDCT系数向量值.由于音频在编码过程中是按帧进行编码,因此,在提取MDCT系数矩阵时,将音频每一帧的MDCT系数作为一行进行分析.根据式(1)所描述的多元线性回归模型进行相关性计算:
y=β0+β1×x1+β2×x2+…+βn×xn+E
(1)
其中,x为自变量,β为回归多项式系数,y为待预测的期望值,E为偏置.
针对100段cover样本的MDCT系数矩阵,分别构建3×3和5×5两个维度的线性回归系数矩阵,结果如图3所示.在MDCT系数矩阵的水平方向(帧内)和垂直方向(帧间)均具有较强的相关性,且水平方向相关性强于垂直方向,而斜对角方向的相关性较弱.
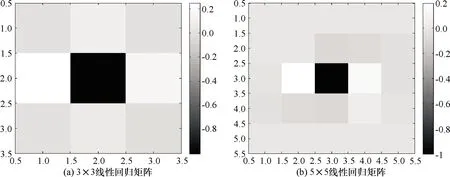
图3 cover样本MDCT系数矩阵线性回归拟合结果Fig.3 The results of the linear regression about MDCT coefficients of cover audio samples
2 基于深度残差网络的MDCT系数域的隐写分析方法
基于以上分析,本文提出一种针对MDCT系数域的深度残差网络隐写分析框架,整体结构如图4所示,主要包括三个部分:MDCT系数特征预处理模块、隐写分析网络主体模块及分类模块.

图4 AAC音频MDCT系数域隐写分析网络框架Fig.4 Architecture of the proposed steganalysis scheme for MDCT coefficients
MDCT系数特征预处理模块是利用专家先验知识,根据MDCT系数的帧间与帧内相关性,设计合适的滤波器,最大程度减少音频内容对隐写噪声的掩蔽,提高隐写噪声在整个音频数据流中的比例.隐写分析网络主体模块为深度残差网络结构,针对特定滤波后的特征信号进行深层次的隐写分析特征提取.分类模块采用二分类方式,将待测音频根据预测概率分类为载体样本或载密样本.
2.1 MDCT系数特征预处理模块
MDCT系数特征预处理模块的具体结构如图5所示.首先,提取原始音频信号的MDCT系数矩阵,然后对系数矩阵进行滤波,将滤波后的残差信号输入到截断线性单元激活函数,并将结果输入至网络主体结构中.

图5 MDCT系数特征预处理模块Fig.5 Preprocess module of MDCT coefficients
根据前述分析可知,音频MDCT系数在帧间与帧内均具有较强的相关性,为降低需要训练的网络参数数量,本文将特征预处理中的滤波器尺寸设定为3×3,以提高网络的收敛速度.固定值滤波器设计如图6所示,其中加粗的圆形符号表示中心点.
2.2 基于深度残差网络的隐写分析框架
待测音频的MDCT系数矩阵经预处理模块后,得到的残差信号将会作为隐写分析框架的数据,进行深层次的隐写分析特征提取.主体框架中主要包括一个初始卷积层和A、B、C三类卷积单元,通道数量分别为16、32、64,卷积核尺寸为3×3,步长为1,卷积单元具体结构如图7所示.
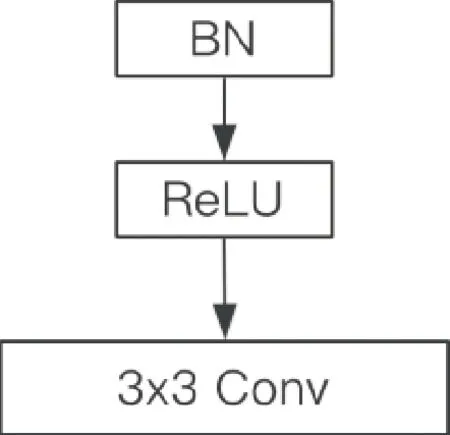
图7 卷积单元结构Fig.7 The structure of the convolutional units
每隔两个卷积单元进行一次shortcut链接,最后将提取的隐写分析特征输入到分类模块中进行分类.隐写分析框架的主体结构如图8所示.
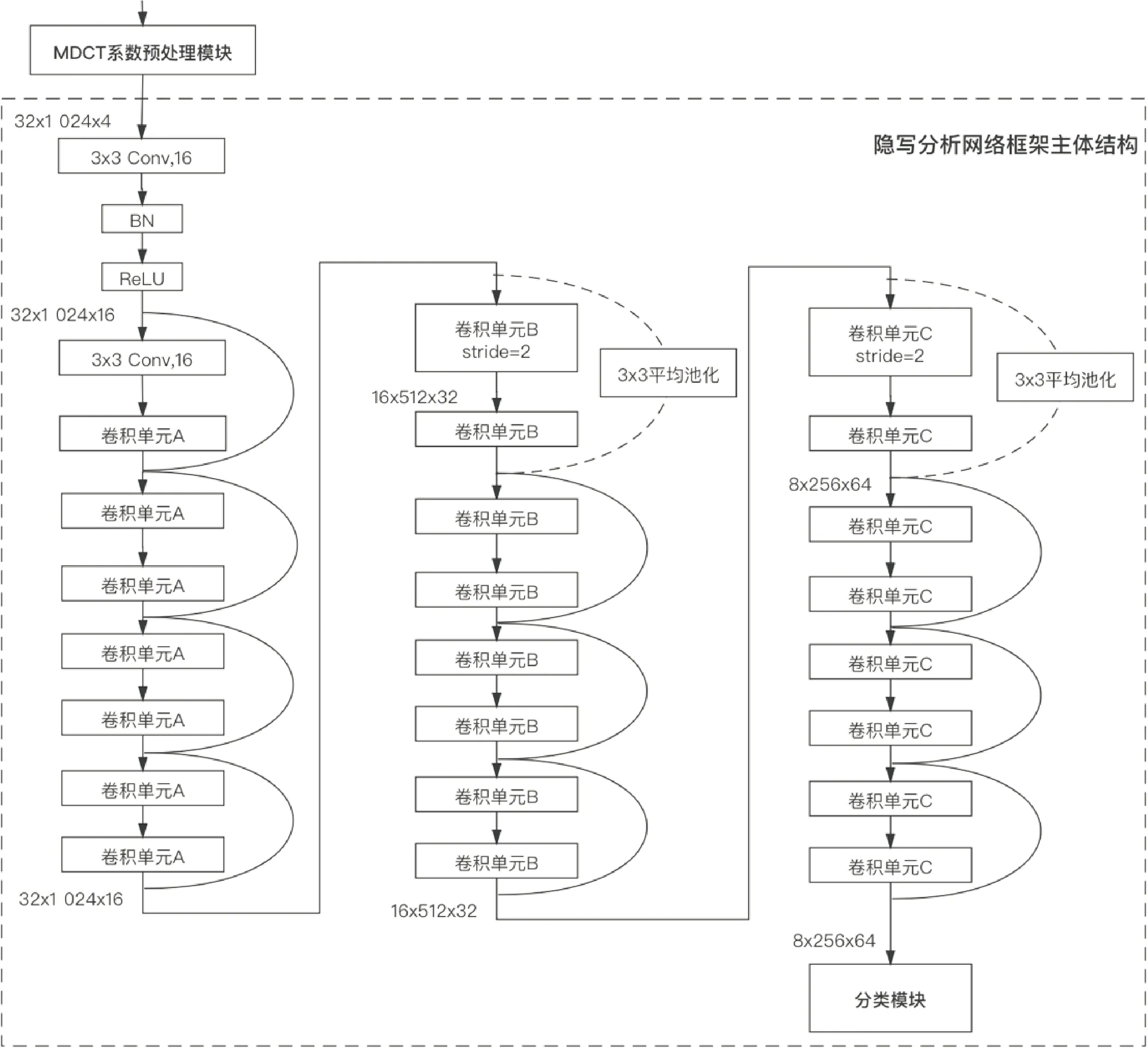
图8 基于深度残差网络的MDCT系数的隐写分析框架主体架构Fig.8 The main structure of the proposed deep residual steganalysis network
2.3 分类模块
隐写分析框架中分类模块如图9所示,对提取的隐写分析特征图谱进行全局平均池化操作,最后使用SoftMax函数对输出进行二分类,从而得到每个待测样本的cover与stego分类概率.

图9 基于深度残差网络的MDCT系数的隐写分析框架分类模块Fig.9 The classification module of the proposed deep residual steganalysis network
3 实验结果与分析
本文通过三个不同维度的实验来评估所提出的隐写分析算法的有效性.针对MIN和SIGN两种隐写算法,在不同相对嵌入率的条件下进行隐写分析检测,同时与文献[20]中的隐写分析方法进行对比实验,实验结果采用TPR(Ture Positive Rate,TPR)和TNR(Ture Negative Rate,TNR)来表示.
3.1 AAC音频样本库
由于目前没有大型公开的AAC音频样本库,本文通过自建AAC音频样本库进行实验,音频样本库具体描述如下:
WAV_DB:无损WAV音频样本来自于互联网上的公开音频网站,音频样本的内容覆盖不同语言、不同性别、不同音乐风格.将其制作为采样率16 KHz、16位采样、音频时长2 s的10 000段单声道WAV音频.
Cover_DB:将WAV_DB中10 000段音频通过公开的AAC音频编码器FAAC进行编码,得到10 000段编码码率为32 Kbps的cover样本.
Stego_MIN:采用MIN隐写算法对cover样本进行随机秘密信息嵌入,编码码率为32 Kbps,相对嵌入率为10%、20%、30%、50%和100%,分别得到对应的stego样本,共10 000×5=50 000段.
Stego_SIGN:采用SIGN隐写算法对cover样本进行随机秘密信息嵌入,编码码率为32 Kbps,相对嵌入率为10%、20%、30%、50%和100%,分别得到对应的stego样本,共10 000×5=50 000段.
3.2 实验方案及结果分析
(1)隐写分析特征有效性测试
分别针对MIN和SIGN两种隐写算法的每个相对嵌入率样本集合进行隐写分析模型训练,以验证该隐写分析方法的有效性.以Cover_DB和Stego_MIN(10%)为例,将样本集合中的20 000个样本(cover和stego样本各10 000个)划分为训练集、验证集和测试集三个集合,其中,训练集占70%,验证集占10%,测试集占20%.
在训练隐写分析网络时,采用Adam优化算法加速神经网络的收敛速度, 每个BatchSize为64,其中包括32组cover和32组stego,权值衰减率为2×10-4,学习率衰减为0.9,每隔500次迭代进行一次衰减,实验结果如表1所示.
根据表1的实验结果分析可知,在嵌入率为10%时,MIN和SIGN隐写算法的检测结果中,cover样本和stego样本的检测正确率均达到了0.92以上.本文所提出的隐写分析方法能有效区分cover和stego,但在不同相对嵌入率上的表现有所差异,随着相对嵌入率的降低,隐写分析检测正确率也在下降.
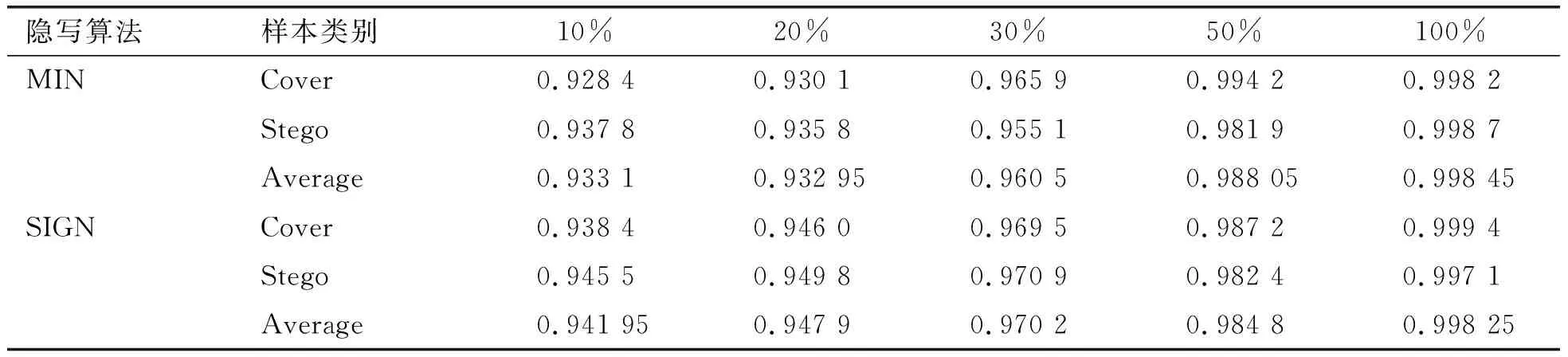
表1 隐写分析特征有效性测试结果Table 1 The validity and performance of the steganalysis features
在实际检测中,检测方一般处于盲检测状态,无法知晓待测样本的实际相对嵌入率,且相对嵌入率的范围较广,在构建模型时无法做到枚举全部的相对嵌入率.因此,通过设计隐写分析特征的嵌入率泛化能力测试实验,来验证本文所提出的隐写分析方法对不同嵌入率具有较好的隐写分析能力.
(2)隐写分析特征嵌入率泛化能力测试
为验证本文提出的隐写分析方法对不同嵌入率具有良好的泛化能力,针对MIN和SIGN隐写算法分别进行隐写分析网络模型训练,每个网络模型训练样本均包含该隐写算法对应的全部5种相对嵌入率的stego样本.以Cover_DB和Stego_MIN为例,选取cover样本7 000个、Stego_MIN(20%)样本3 500个、Stego_MIN(30%)样本3 500个作为训练样本,从5种相对嵌入率的stego样本中各选取1 000个作为校准样本,利用训练好的隐写分析网络模型对余下的所有cover和stego样本进行检测.实验结果如表2所示.

表2 隐写分析特征泛化能力测试结果Table 2 The generalization and performance of the steganalysis features
根据表2的实验结果分析可知,在对MIN和SIGN隐写算法的检测结果中,cover样本的检测正确率均达到了0.92以上;在相对嵌入率为10%时,针对两种隐写算法所生成的stego样本的检测正确率均达到了0.85以上;在相对嵌入率为20%时,针对两种隐写算法所生成的stego样本的检测正确率均达到了0.93以上.实验结果表明,该隐写分析方法针对同一种隐写算法的不同相对嵌入率样本集合,在保证了较高检测正确率的同时,也具有较好的对于不同嵌入率的泛化检测能力.
(3)隐写分析特征通用能力测试
为了进一步验证所提出的隐写分析方法在面向不同隐写算法时,依旧具有较好的通用隐写分析检测性能,本文设计了隐写分析特征的通用能力实验,对面向MIN和SIGN隐写算法的全部5种相对嵌入率进行通用隐写分析网络模型训练.选取cover样本7 000个、Stego_MIN(20%)样本1 000个、Stego_MIN(30%)样本1 500个、Stego_SIGN(20%)样本2 000个,Stego_SIGN(30%)样本1 000个及Stego_SIGN(50%)样本1 500个进行混合模型训练.从不同隐写算法不同相对嵌入率的stego样本中各选取1 000个作为校准样本,利用训练好的神经网络模型对余下的所有样本进行检测.
同时,将该实验结果与文献[20]中所提出的基于AAC音频MDCT系数的马尔科夫转移概率和累积邻接密度矩阵隐写分析特征进行对比.由于文献[20]中所提出的隐写分析特征所针对的是时长为20 s的AAC音频载体,而本文所针对的音频载体时长为2 s,为保证在音频时长维度上的一致性,有效地进行隐写分析方法的对比评估,本文利用文献[20]中所提出的隐写分析方法,针对自建音频时长为2 s的样本库进行特征提取,采用SVM分类器对隐写分析特征进行分类.同时,根据原始WAV_DB,制作1 000段音频时长为20 s的AAC音频Cover_20s、Stego_MIN_20s及Stego_SIGN_20s样本,利用SVM分类器对文献[20]中的隐写分析特征信息检测.具体实验结果如表3所示.
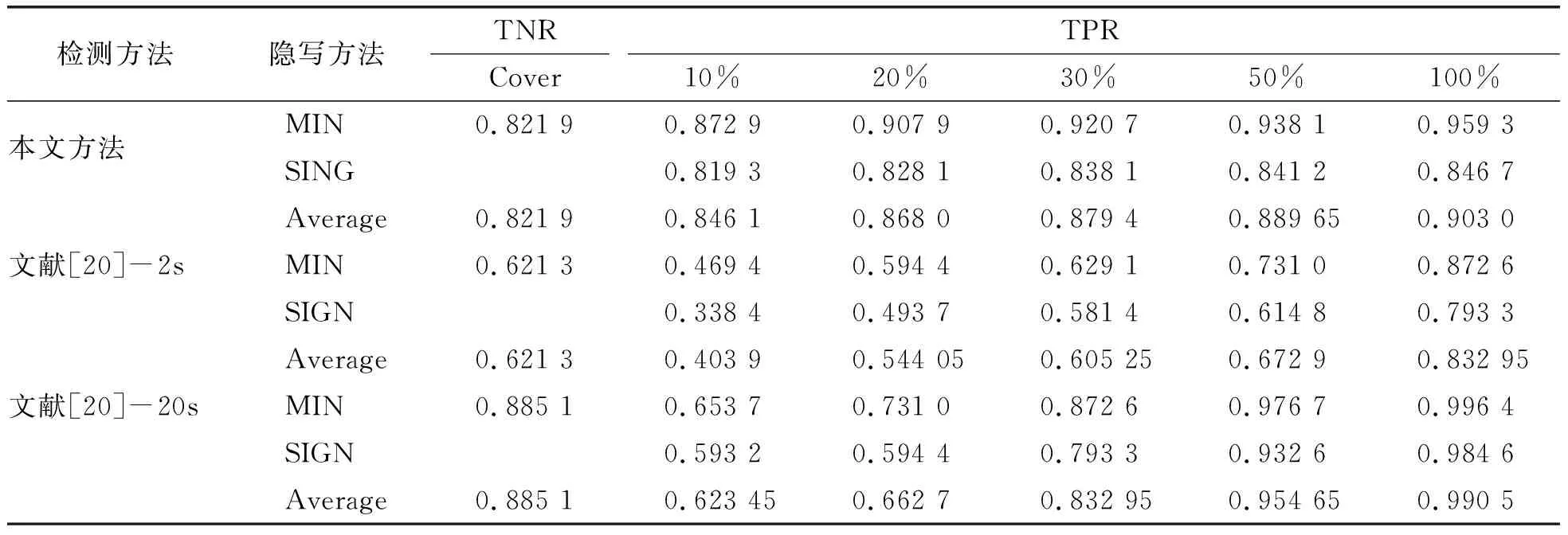
表3 隐写分析特征通用性对比结果Table 3 The universality and performance of the steganalysis features
根据表3的实验结果分析可知,当音频时长为2 s时,本文所提出的隐写分析混合模型对cover样本的平均检测正确率达到了0.82以上;在相对嵌入率为10%时,针对两种隐写算法所生成的stego样本的平均检测正确率达到了0.84以上;在相对嵌入率为100%时,平均检测正确率达到了0.90以上.
对比隐写分析算法,在音频时长为20 s时,针对高嵌入率(相对嵌入率为50%、100%)具有较好的检测效果,平均检测正确率高于本文所提出的方法.在低嵌入率(相对嵌入率为10%、20%)条件下,隐写分析检测效果低于本文所提出的隐写分析算法.在音频时长为2 s的条件下,文献[20]所提出的隐写分析特征组合的检测性能较差;在相对嵌入率不超过30%时,该隐写分析特征对于cover和stego样本几乎没有区分能力.相比较之下,本文提出的基于深度残差网络的隐写分析模型在音频时长较短、相对嵌入率较低的情况下,依旧具有良好的隐写分析检测性能,且优于对比算法,证明本隐写分析方法针对不用隐写算法的不同嵌入率具有较好的通用性.
以上三个实验综合表明,本文提出的基于深度残差神经网络的隐写分析方法具有良好的隐写分析特征表达能力,且针对不同的隐写算法和相对嵌入率具有较好的泛化能力和通用性.与现有的针对MDCT系数域的隐写分析方法进行对比,在音频市场较短且相对嵌入率较低时,检测效果具有明显提升,在高嵌入率时,隐写分析性能依旧表现良好.
4 总 结
本文利用深度残差网络的强大特征表达能力,将专家先验知识与深度残差网络相结合,提出了一种面向AAC音频MDCT系数域的隐写分析方法,实现了对MDCT系数域的有效隐写分析检测.隐写分析框架主要包括:MDCT系数预处理模块、网络主体模块以及分类模块.在MDCT系数预处理模块中,构建MDCT系数的多元线性拟合预测函数,量化分析音频帧间与帧内MDCT系数之间的连续性和相关性.根据分析结果设计出4种固定值滤波器,以降低音频内容对隐写分析特征的干扰.在隐写分析网络主体结构中,设计了3种不同的卷积单元,完成了对待测音频的深度隐写分析特征提取,在提高深度神经网络收敛速度的同时,提升了隐写分析检测结果,最终实现针对AAC音频MDCT系数域的隐写分析方法.实验结果表明,在编码码率为32 Kbps、音频时长为2 s的情况下,针对cover样本的平均检测正确率能达到0.82以上,针对相对嵌入率为10%的stego,平均检测正确率能达到0.84以上,针对相对嵌入率为100%的stego,平均检测正确率能达到0.90以上.相较于对比算法,本文提出的隐写分析方法的检测性能具有明显提升.
鉴于AAC音频与MP3音频在编码原理上的相似性,本文提出的隐写分析网络框架也可应用于基于MP3音频MDCT系数修改的隐写算法检测分析.同时,该隐写分析方法可作为生成式对抗网络(Generative adversarial networks)模型中的判别模型,用以提升对应隐写算法的安全性和不可检测性.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
四川轻化工大学学报(自然科学版)(2021年1期)2021-06-09
汉字汉语研究(2020年2期)2020-08-13
重型机械(2020年2期)2020-07-24
电子制作(2019年22期)2020-01-14
中国航海(2019年2期)2019-07-24
家庭影院技术(2018年11期)2019-01-21
疯狂英语·新读写(2018年3期)2018-11-29
电子制作(2018年19期)2018-11-14
电子制作(2017年9期)2017-04-17
