
处理器微体系结构时间侧信道攻击与防御
2020-11-26 01:36苑风凯
广州大学学报(自然科学版) 2020年2期
苑风凯, 侯 锐
(中国科学院 信息工程研究所 信息安全国家重点实验室,北京 100093)
过去的二十年,研究者已经提出层出不穷的侧信道攻击,通过处理器微体系结构窃取安全关键信息.微体系结构侧信道攻击不仅能够窃取加密密钥、监听设备输入、提取浏览器访问历史等敏感信息,破解地址随机化ALSR,还成为了近期引起广泛关注的幽灵[1]、熔断[2]等瞬态执行攻击的帮凶,将“瞬态”获取的敏感信息通过微体系结构状态的改变传递给攻击者[3].本文聚焦基于时间的侧信道,由于不同于基于电磁或功耗侧信道,时间侧信道攻击不需要物理接触目标设备,仅需恶意程序与受害者程序运行于同一处理器,更具威胁和现实意义.
站在体系结构的视角,基于时间的侧信道与处理器底层硬件存在着天然的联系.性能优先的处理器设计理念导致基于时间的侧信道不可避免.首先,这些侧信道的前提是运行与处理器的不同程序对相应的微架构组件的共享,而资源共享是处理器动态性能的最有力保障.其次,以性能优化为目标的微架构设计导致了程序快速和慢速的微架构行为,例如,从缓存命中获取数据的延迟显著低于缓存缺失.毋庸置疑,微架构共享以及快速/慢速行为特性助推了现代处理器计算能力的迅猛发展.
然而,设计师追求性能优化不断为微架构添加新特性的同时,越来越多的微体系结构漏洞被安全研究者披露并利用,对现实的商业处理器发起更具威胁的侧信道攻击.纵览现有的针对微架构组件的攻击,笔者将微体系结构侧信道的利用概括为基于复用和基于竞争两大类.前者直接复用受害程序在微架构组件内的共享信息,获知被害者的微架构行为.后者通过与受害程序竞争微架构组件的资源,感知被害者的微架构行为.辅以必要的去噪声手段,一旦掌握足量的与被害者秘密相关微架构行为轨迹,攻击者就可以恢复出安全关键信息,例如,加/解密算法秘钥.
为了补救微体系结构侧信道,研究者提出了很多基于硬件的防御措施.这些防御可以归纳为基于隔离、基于随机以及基于检测等三大类.这三类措施分别旨在消除程序间的微架构组件共享,加入微架构行为噪声干扰攻击者观测,以及监控并捕获可疑的微架构异常行为特征而后发出预警或实施反制.纵观这些措施,微体系结构侧信道防御或多或少需要付出性能、逻辑及存储代价,这与能效提升为目标的设计理念相违.值得注意的是,Intel SGX[4]和ARM TrustZone[5]都是通过逻辑隔离为敏感数据代码提供安全的执行环境.由于性能的考虑,安全和非安全域仍然共享着大量硬件资源,导致了侧信道信息泄露风险[6-7],这在机密性方面削弱了它们的安全承诺.本文试图通过分析微体系结构侧信道的建立以及攻防博弈的展示,引发处理器硬件社区对性能优先的设计理念的重新审视,助力设计师在微架构设计阶段就优化新特性可能带来的信息泄露风险进行评估.本文做出的贡献具体如下:
(1)结合若干重要微架构组件的特点,比照微架构共享及快速/慢速行为特征,分析微架构组件各自时间侧信道的建立.
(2)纵览现有的微体系结构侧信道,根据微架构组件利用的共性,将攻击概括为两大类:基于复用的攻击和基于竞争的攻击.
(3)介绍基于硬件的微体系结构侧信道补救,将现有防御归纳为三大类:基于隔离的防御、基于随机的防御以及基于检测的防御.
1 微体系结构侧信道
理解微体系结构侧信道攻击,需要了解处理器不同微架构组件的特点,以及它们如何形成了基于时间的侧信道,从而导致信息泄漏.图1展示了将要分析时间侧信道建立的微架构组件.值得注意的是,不同的程序共享微架构组件为程序间观测微架构行为提供了前提条件.进一步,在了解(逆向工程)微架构组件设计的前提下,执行时间揭示了程序发生快速还是慢速的微架构行为.掌握攻击者自身或者受害程序的执行时间就可以掌握受害者秘密相关的微架构行为信息,从而建立起时间侧信道.
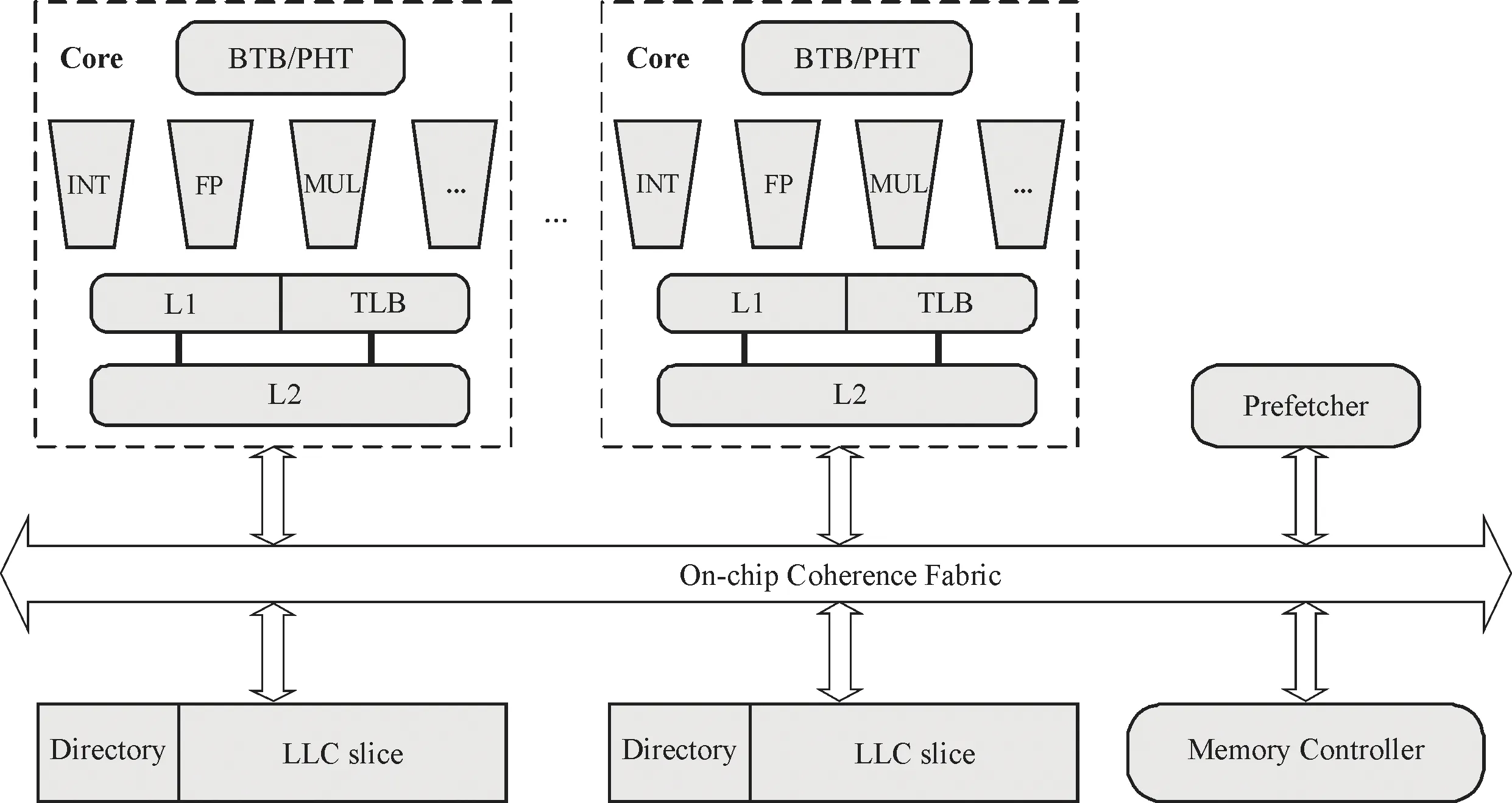
图1 面临侧信道风险的处理器微架构组件(灰色)Fig.1 Processor microarchitecture components facing side channel risk (gray)
1.1 执行单元(端口)
高性能处理器采用同时多线程(SMT)技术,每个处理器核通常有两条或多条流水线,而这些流水线共享“执行阶段”和其中的执行单元(端口).当不同流水线的程序尝试执行相同的计算操作时就会出现竞争,例如,如果两个程序均尝试执行浮点运算,则一个程序将停止运行(Stall),直到浮点单元可用为止,导致了程序执行时间的差异.由此,恶意程序可以根据自身的执行时间,判断受害程序是否发生了使用目标执行单元的微架构行为.近期的研究显示,端口竞争(Port Contention)侧信道可以为幽灵、熔断等攻击,在缓存侧信道之外,提供新的途径传递瞬态执行获取的敏感信息[8].
1.2 分支预测器
分支预测器负责在遇到条件或者间接分支时,预测下一步应执行哪些指令.分支预测器尝试学习程序的分支行为,其内部状态是通过观察过去的分支建立的.根据分支指令的地址,建立分支的目标地址历史.遇到分支指令时,根据分支指令的地址查找历史并预测目标地址.为了提高预测效率,分支预测器对处理器核内运行的所有程序收集全局的历史记录,导致不同的程序会影响分支预测,造成彼此执行时间受到影响.攻击者利用分支预测器可以通过自身被影响分支执行的时间,感知受害者安全关键分支指令的执行情况,并推断与该分支相关的敏感信息.
1.3 缓存
处理器设计人员使用缓存层次结构(Cache Hierarchy)将最近和最常用的数据带入最接近处理器核的缓存中,以便在有内存访问或指令获取时可以从其中一个缓存层级中获取数据,而无需一路走到内存.然而,最快的缓存层级也是最小的,需要替换策略决定哪些数据应该放在最快的缓存层级.最常使用的是(Least Recently Used, LRU)类的替换策略,驱逐最少使用的数据,并保留最近使用的数据.当程序执行内存访问时,它们将新数据带入缓存快速层级,并将最少使用的数据驱逐到低速层级或最终到内存.在整个缓存中跟踪最少使用的数据是不切实际的.因此,如图2所示,组相联(Set-association)结构将缓存分为组(Set),每个缓存行(Line)只能映射到一个特定的Set,而每个Set最多容纳的行数为相联度(Association),而替换策略就在Set内维护.
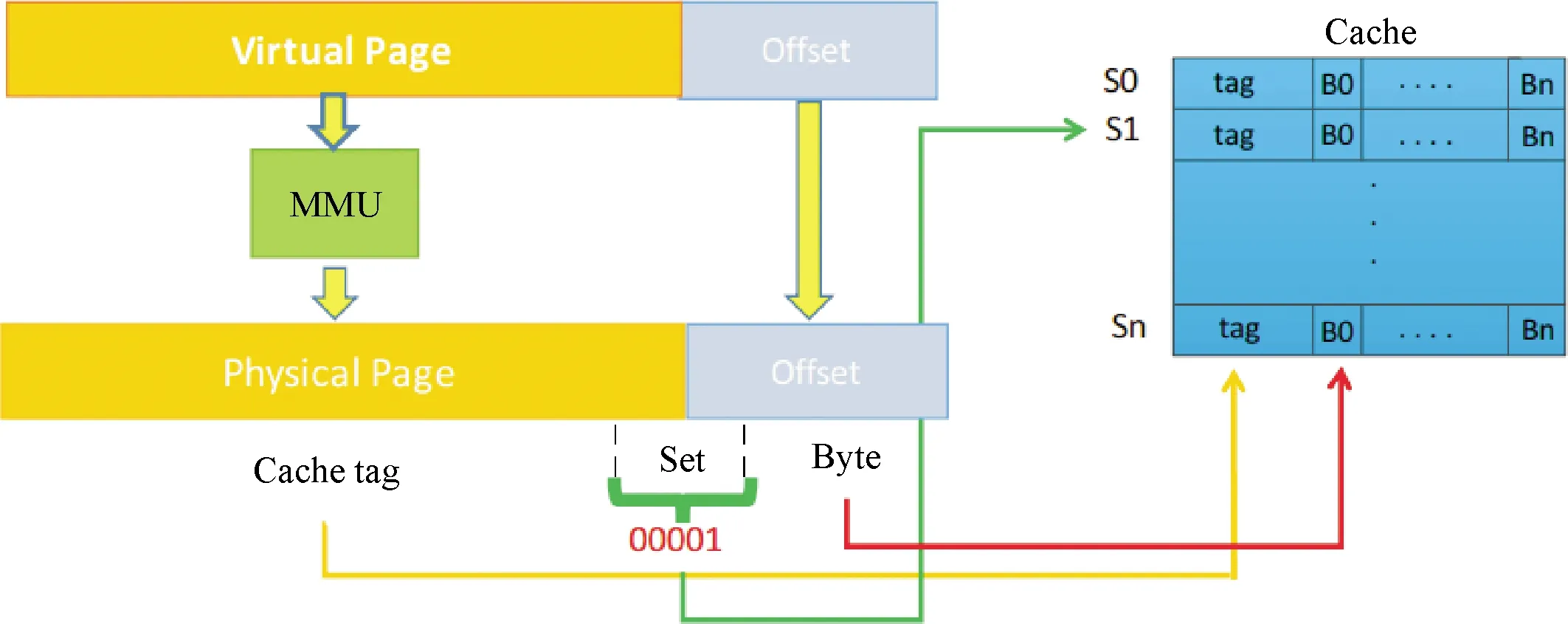
图2 组相联缓存结构[9]Fig.2 Set-associative cache architecture[9]
无论从效率还是功耗考虑,相联度都不宜过大(一般为4至16),这就为不同程序在Set内造成竞争进而引起缓存行驱逐,最终导致不同缓存层级间乃至内存的访问时延差异,创造了优越的快捷条件(如图2,构造{B0,…,Bn}地址集就可以确保将同Set内任意目标缓存行驱逐).攻击者也可以利用同受害者共享地址空间,通过将共享的缓存行预先驱逐至低速缓存层级,之后重访(复用)该行,根据访问时延判断受害者是否访问并将该行带入快速缓存层级.如图3所示,攻击者可以根据Reload的时延(红条的长短)判断受害者目标缓存行访问情况.目前研究主要关注可以跨处理器核的末级缓存(Last Level Cache, LLC)攻击,因为这为攻击放松了限制,不要求攻击者和受害者位于相同的处理器核,使得攻击更容易发起,在当前云环境和虚拟技术背景下也更具现实意义.
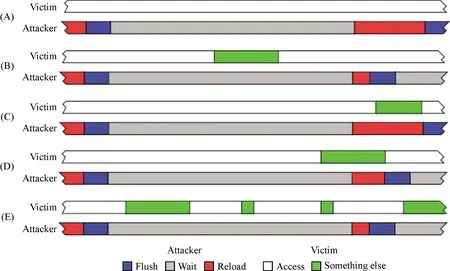
图3 Flush + Reload攻击示意图[11]Fig.3 Scheme of Flush + Reload attacks[11]攻击者观测受害者访问目标缓存行情况:(A)未访问;(B)访问(C)访问重叠;(D)访问部分重叠;(E)多次访问
近期研究表明[10],在非包含型(Non-inclusive)缓存架构中,除了末级缓存,可以利用一致性目录(Directory),发起涉及私有L1/L2的跨核侧信道攻击.在包含型(Inclusive)缓存架构中,目录条目与末级缓存行是一一对应的关系,对缓存的侧信道攻击也相当于攻击目录.相反,在非包含型缓存架构中,被受害程序访问的数据会加载到核内私有缓存,位于其他核的攻击者难以利用末级缓存冲突观测受害者的访存行为.然而,非包含型架构下目录包含L2目录和LLC目录两级结构.共享的L2目录使得攻击者可以利用L2目录冲突影响受害者的私有缓存行,进而利用L2和LLC的访问延迟差异建立跨核时间侧信道,推断出受害者的私有缓存行为.
1.4 Translation look-aside buffer (TLB)
现代系统中,程序使用的内存地址为虚拟地址,CPU访问内存使用的为物理地址.CPU每次访问内存需要首先将虚拟地址翻译为物理地址.用于虚拟地址到物理地址翻译的多级页表存储在内存中,每次地址翻译都要多次访问内存.为加速地址翻译过程,TLB中存储部分虚拟页号到物理页号的直接映射.TLB是类似于Cache的缓存,为多路组相联结构.用于数据访问进行地址翻译的为L1 dTLB,用于指令访问进行地址翻译的为L1 iTLB.L2 sTLB为数据地址和指令地址翻译共享.同一进程中不同特权级对TLB的共享和开启超线程时不同进程对TLB的共享,使得攻击者可以探测受害者页粒度的访存信息.
攻击分为复用引起的攻击(用户态和内核态共享TLB)和竞争引起的攻击(超线程的不同进程共享TLB).前者,用户态访问内核态的页面会因权限检查失败产生页错误.当访问的页面为已分配的页面时,内存管理单元(MMU)会创建对应的TLB项.若访问的页面为未分配页面,由于地址翻译失败,MMU不会创建TLB项.当再次从用户态访问该内核态页面时,虽然仍会发生页错误,但已分配页面的访问会发生TLB命中,从而页错误处理时间更短.用户态程序可以根据该时间差异探测内核态地址访问踪迹.TLB的相联度也较小(一般为4至12),不同进程在TLB Set内同样存在竞争导致可以互相驱逐TLB项,可以创造不同级TLB访问和TLB访问与内存的访问延迟差.攻击者可以利用超线程和受害者共享TLB,通过将一组TLB项预先加载至TLB Set,等待一个时间片后再重新访问该组TLB项,根据时延判断是否和受害者发生访问竞争即受害者是否访问该TLB set.针对TLB的侧信道攻击只能获得页粒度的访问信息,相较攻击缓存行,粒度更粗.利用该粗粒度的访存信息推测细粒度的敏感信息是研究难点.
1.5 预取器
现代处理器通常会采用预取机制将系统未来可能需要的数据(或指令)提前放置到缓存,以避免因缺失引起的较长内存延迟,提高程序的执行速度.预取通常有软件预取和硬件预取.前者由编译器支持,后者由专用的硬件依据规则对预取进行决策.本文聚焦硬件预取器.最基本的是顺序(Sequential)预取器,即在访问地址x时,会将x+1预取到缓存.主流处理器已经普遍采用了基于步距预测的方法,即跨步(Stride)预取器.具体地,当处理器连续多次地以相同的间距访问地址时,后续的地址会被预取.例如,当地址A+m,A+2m,A+3m被访问时,预测期会推断A+4m大概率也会被处理器需要,进而提前预取到缓存中以降低缺失率.上述的预测依赖于访问预测表(RPT)对过去的访问历史的记录,这种相同步距的规律性访问会使得该表处于稳定状态并进行持续的预测.尽管预取器提升了性能,一些原本与敏感信息无关的数据却可能因为预取机制与敏感信息产生关联.忽视对预取数据的保护会再一次出现新的时间侧信道以致信息泄露.
1.6 内存
内存控制器(Memory Controller)负责管理进出处理器芯片和内存的数据.内存控制器包含用于处理器请求的队列(读和写,通常来自LLC),它必须调度这些请求在发出请求的缓存之间进行处理,并处理DRAM的资源竞争.不同程序共享内存控制器和DRAM,来自每个处理器核的请求需要进行排序和排队以便由内存处理. 动态更改一个处理器核的内存需求将影响另一个核的内存访问延迟.虽然内存控制器试图实现公平性,但并不总是能够平衡来自不同内核的内存流量.特别是,当今的DRAM内部的数据在进行实际处理之前以内存行(Row)为单位首先要载入行缓冲区(Row Buffer).内存行的大小一般为2~4物理页,后续的访问若发生在相同内存行则延迟较低,而如果发生在不同行则引起行冲突(Row Conflict),需先将当前行写回,再将当前访问行载入行缓冲区,导致明显的内存访问延迟差异.攻击者既可以利用内存控制器的队列竞争,也可以制造行冲突来获取受害者的内存访问足迹,窃取相关的敏感信息.
2 微体系结构侧信道攻击
现有的微体系结构侧信道攻击可以分为两大类:基于复用的攻击和基于竞争的攻击,如表1所示.基于复用的攻击中,攻击者直接读取微架构组件中受害者程序遗留的历史,获取相关的安全敏感信息.基于竞争的攻击中,攻击者通过抢占微架构组件,迫使受害者程序竞争该微架构组件的资源,并观察自身所受的影响,推断出受害者的微架构行为,进而获取相关的安全敏感信息.

表1 微体系结构侧信道攻击Table 1 Microarchitectural side channel attacks
2.1 基于复用的攻击
针对缓存,基于Flush的攻击能够精准地确定一个缓存行在特定的时间间隔内是否被受害者使用.以Flush + Reload[11]为例,该攻击分为三个阶段:①Flush阶段:攻击者使用clflush (x86架构)类指令将目标缓存行从缓存中驱逐;②Wait阶段:攻击者等待预设的时间间隔,受害者程序如果访问了目标地址,则会将缓存行载入缓存;③Reload阶段:通过观察目标缓存行的访问延迟,攻击者可以确定受害者是否访问了该缓存行.此外,这类攻击还有Flush+Flush[14]、Flush+Prefetch[15]和Invalidate+Transfer[16]等变种.因为复用特定缓存行,攻击在效率和准确度上很有大优势.但由于clflush指令的限制,这种攻击只能针对攻击者和受害者共享的缓存行.
针对TLB、Double Page Fault攻击[17]基于用户态和内核态对TLB的共享.利用在用户态访问该内核态页面时,页错误处理时间会因已分配页面的TLB(用户态直接访问内核页面TLB项)访问发生命中而更短,攻击者推断出了内核空间的内存地址分配布局,可用于进一步绕过KASLR获得内核空间的基址及内核驱动的地址.
针对分支预测器,攻击利用的是程序间能互相使用保存在分支预测器中彼此的历史信息.以针对(Prediction History Table, PHT)攻击的BranchScope[12]为例,攻击者首先找到PHT中与受害者程序敏感信息依赖的分支项的共享的组(Set),并设置其饱和计数器至特定的状态,例如Weak Taken.受害者程序执行敏感分支后,该项内容会更新.切换回攻击者程序后,本应跳转的指令在采用被更新的共享项预测,Strong Taken与Not Taken会有执行时间上的差异.据此,攻击者可以感知该关键指令的执行情况,进而推测受害者的执行路径.另外一个典型的攻击实例是Branch Shadowing攻击[13],该攻击通过构造受害程序的影子代码,来检测目标分支指令是否残留(Branch Transfer Buffer)BTB中,从而观察SGX中受害者分支的跳转方向.
针对预取器,与敏感信息相关的被预取的数据可能成为新的侧信道攻击目标.例如,Shin等[18]指出Branchless Montgomery ladder (OpenSSL的一种加解密算法)在执行过程中因为跨步预取器的存在,会有一些地址与密码存在紧密相关的特性.在不同的密钥下,这些地址会出现不同的缓存缺失率的变化.当攻击者尝试不同的密钥并找到与受害者相同的缺失率记录时,就成功破译了密钥.恒定执行时间是一种有效的缓解侧信道攻击的策略,但是Bhattacharya等[19]指出因为顺序预取器的存在,这种恒定会受到干扰,进而存在可以利用的时间差异,依据此特性,攻击者成功恢复了128位CLEFIA密钥.
2.2 基于竞争的攻击
针对缓存,基于竞争的攻击观察一个缓存Set在特定时间内是否被受害者访问.以Prime + Probe[23]为例,该攻击同样包含三个阶段.在发起攻击前,攻击者首先会构造一个针对目标缓存行的驱逐集(Eviction Set),该缓存行集合包含与Set相联度相同的元素并且每个元素都于目标地址落入相同的Set.①Prime阶段:攻击者使用构造好的驱逐集占据缓存中特定的组,将目标地址从缓存驱逐;②Wait阶段:攻击者同样需要等待特定的时间.在该间隔内,若受害者访问了目标地址,由于冲突(Set Conflict),驱逐集中的一个元素必然会被驱逐;③Probe阶段:攻击者重访这个驱逐集并观测访问延迟,若发现出现了长延迟则可以推断受害者访问了目标地址.基于竞争的攻击还有Evict + Perfetch[15]、Alias-driven Attack[24]和Evict + Time[25]等变种.
针对分支预测器,攻击利用的是分支预测器允许程序间互相抢占分支预测表的项.攻击者通过探测分支预测器是否发生竞争,从而感知受害者分支执行的情况.以针对BTB攻击的SBPA[21]为例,攻击者首先占用BTB中与受害者目标分支共享组中的所有路.在受害者程序执行时,敏感分支由于历史信息缺失,预测跳转方向为Not Taken.根据BTB更新机制,若最终该指令not taken,则不会更新BTB;否则会由于错误预测更新BTB,抢占原攻击者的一条分支历史项.在切换回攻击者后,攻击者依据被抢占分支的执行时间,确认该项历史是否被替换,从而得知受害者敏感分支是否Taken.文献[22]提到PHT中也面临着类似的安全隐患.
针对TLB,TLBleed[26]攻击使用类似于cache攻击中的Prime+Prime方法监测TLB set的访问踪迹:攻击者首先通过访问一组虚拟地址,地址翻译产生的TLB项会填满某个TLB Set,等待一个时间片后,攻击者再次访问改组虚拟地址并记录访问时间,若访问延迟较短,则受害者未访问过该TLB Set,若访问延迟较长,则受害者访问过该TLB set.虽然受害加密算法的不同分支访问了相同的数据TLB Set,但访问的时间模式不同.根据数据访问的时间模式不同,攻击者区分了受害者安全敏感函数执行的不同分支,进一步破解了256位EdDSA密钥和92%的RSA密钥.TLBleed只监测一次密码操作就能破解密钥,该时间远小于ASLR重随机化地址的时间片,从而不受ASLR影响.
针对执行单元(端口),PortSmash[20]发起Port Contention攻击,以连接一系列执行单元的端口为目标构建高分辨率的时间侧信道.因为不像其他针对缓存或者TLB 的攻击那样依赖于存储子系统,所以该攻击具有天然的隐蔽性.攻击程序与ECDSA P-384并行执行,测量Port Contention延迟创建一个时间信号Trace,并最终恢复出了TLS服务器的ECDSA私钥.针对内存,Wang等[27]表明时间侧信道攻击可以通过共享内存控制器来实现.通过测量其自身内存访问的延迟,攻击者能够观测同时运行的程序的动态内存需求,推断受害者程序的私密信息.DRAMA[28]利用DRAM中的Row Buffer冲突,建立了一个时间侧信道,可以通过Template攻击自动地定位并监视内存访问.
3 微体系结构侧信道防御
针对微体系结构侧信道攻击的防御主要分为三大类:基于隔离的防御、基于随机的防御和基于检测的防御,如表2所示.基于隔离的防御的核心就是消除时间侧信道,取缔不同程序对微架构的共享,通过隔离阻止攻击者影响并观察受害者对微架构组件的使用.基于随机的防御旨在通过噪声注入的方式干扰攻击者观测,阻止其对时间侧信道利用的同时,保留不同程序对微架构组件的共享.基于检测的防御倾向于基于特定的规则或者机器学习(统计学)来识别可疑的微架构异常行为特征,发现潜在的侧信道利用,进而发起预警或者采取针对性的反制措施.
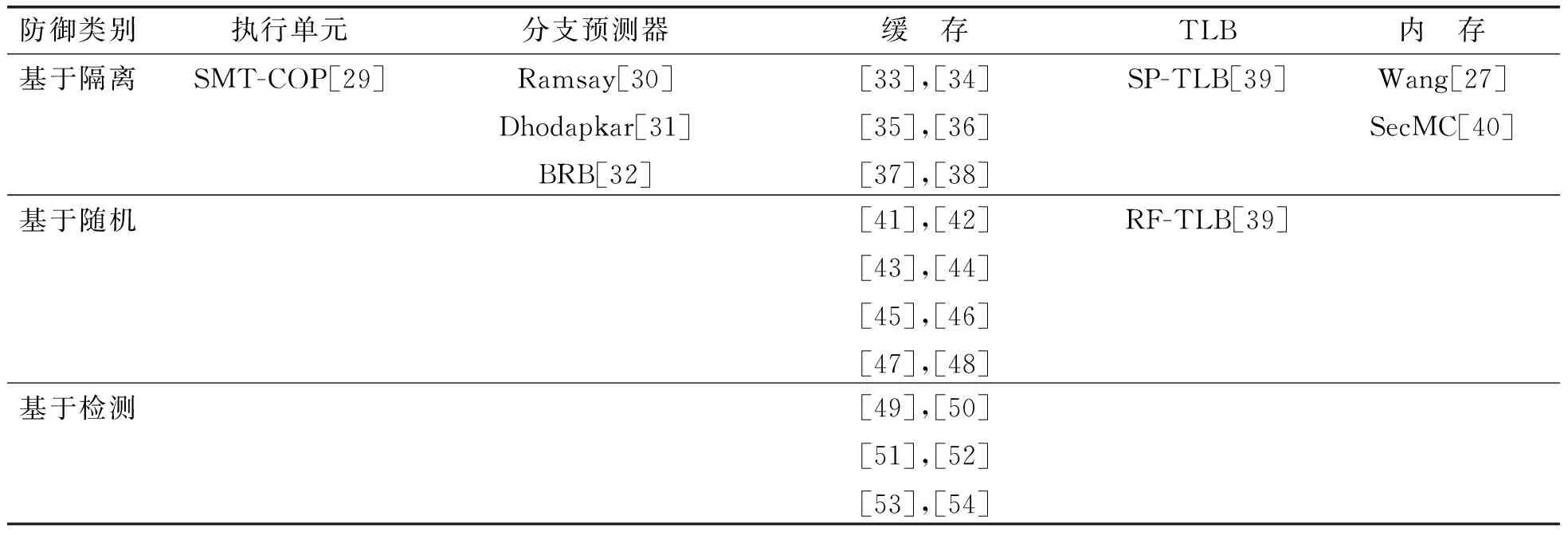
表2 微体系结构侧信道防御Table 2 Microarchitectural side channel defenses
3.1 基于隔离的防御
对于缓存,Liu等[33]利用Intel的资源调配技术(Cache Allocation Technology, CAT[55])将敏感信息和普通信息分配到不同的缓存其余,使得攻击者永远无法影响和观测被标注敏感的目标地址.Shi等[34]基于缓存着色技术(Page Coloring)提出了动态染色机制,将敏感信息分配到特定的缓存区域,而其余的进程将不能使用.当安全页和非安全页切换频繁时,这种方案会带来明显的性能下降.STEALTHMEM[35]为每个处理器核预留空间存放隐藏页,这些页会被锁定在共享缓存内不被其余的核驱逐.SecDCP[36]将所有程序分割到不同等级的安全域中,并依据需求动态为各个安全域分配可用的缓存组相联度,阻止高安全域向低安全域信息泄露,同等级的安全域则采用静态分配缓存的方式.CacheBar[37]同样选择周期性地为每个安全域配置在每个缓存组中最大的可用相联度以实现隔离.文献[38]为页表项和普通数据分配不同的缓存空间,防御了AnC[56]和Xlate[57]类基于MMU和CPU核共享cache的侧信道攻击.
对于分支预测器,防御为需要保护的程序以及危险的程序分配不同的分支预测表项.例如对于SGX中运行的敏感程序,采用单独的分支预测信息,避免不可信的进程对敏感进程的污染[12].对于云平台上同时运行在同一个物理核上的程序存在Residual的攻击场景,而且不依赖于上下文切换,危险性要大于单核上的信息泄露.之前的研究表明SMT采用各自的分支预测器并未带来性能优势[30].文献[31]提出在上下文切换时,用VMM将分支预测信息压缩并保存至VMM专属的内存空间,对软件不可见.BRB[32]提出为不同的程序分配各自的分支预测历史表,在上下文切换时,将安全敏感的预测信息保存至片上SRAM.但考虑到备份面积以及VMM的空间,引入的备份个数有限,仍存在共享引起的安全隐患.
对于TLB,SP-TLB[39]在组相联TLB中,按路为受害者和攻击者进程分配不同的TLB空间.同传统TLB,当地址和进程号都匹配时TLB命中.但发生TLB缺失时,进程号不同的TLB条目不可互相替换,受害者和攻击者都只能替换属于其分区的TLB条目.通过静态分区可以防止外部干扰引起的攻击,但是无法阻止内部干扰.
对于执行单元(端口),SMT-COP[29]通过在同一处理器核上运行的线程之间划分执行单元和/或与之关联的发射端口,从而消除SMT处理器中的执行单元端口侧信道.对于内存,Temporal Partitioning (TP)[27]显示,静态轮转调度可以消除内存控制器时间侧信道,但是会产生较高的性能开销.SecMC[40]通过交错不同Bands和Ranks的访问请求,消除时间侧信道的同时,实现动态的、紧凑的内存调度,从而提升性能.
3.2 基于Randomization的防御
对于缓存,HybCache[41]将敏感数据放置到一些改造成全相连结构的缓存区域,并采用随机替换的策略阻止攻击者精准的驱逐.Random Fill Cache[42]将被请求的数据直接传递给处理器,在缓存上则将其可配置窗口内的临近数据随机载入,以此避免攻击者发起针对特定地址的基于重用的攻击.随机缓存映射改变物理地址到缓存Set的映射关系,从而阻止攻击者构建驱逐集来发起基于竞争的攻击.RPCache[43]和NewCache[44]依赖间接表来记录每个缓存行新的映射关系,这种记录应用在较小的L1 cache上可行,但在LLC上采用上述策略会引起不可接受的存储开销.ScatterCache[45]和PhantomCache[46]选择同时引入多个哈希函数,使得一个物理地址在缓存中存在多个Set位置可选,由于难以寻找到覆盖到多位置的驱逐集,攻击者难以实现观测.CEAER[47]和CEASER-S[48]倾向以周期性变更密钥的方式实现Set映射关系的不确定性.
对于TLB,RF-TLB[39]采用与Random Fill Cache类似的方法,对于安全域的地址访问,不是将请求的地址转换载入TLB,而是随机选择其他地址转换载入TLB.请求的地址直接返回给CPU.在RF-TLB中,发生命中时,处理逻辑和传统TLB相同.当发生TLB缺失时,若请求的地址翻译或将要被替换的地址转换属于非安全域,请求的地址不会载入TLB而直接返回给CPU,同时随机选取其他地址翻译进行替换:当请求的地址来自非安全域时,随机选取的地址为TLB索引不同的地址,使得攻击者无法确定性地驱逐安全域地址;当请求的地址来自安全域时,随机选取的地址为安全域内的地址, 攻击者虽然可以观察到TLB的状态改变,但是由随机选取的地址引起.
3.3 基于检测的防御
基于规则的检测:SHARP[49]发现基于竞争的跨核缓存侧信道攻击中,被驱逐和观测的目标通常是那些不仅在末级缓存还在私有缓存中存在备份的缓存行.基于此,该方案更改了末级缓存的替换策略优先驱逐仅存在于末级缓存的缓存行,从而避免潜在的攻击目标地址被攻击者观测.而当不存在可以优先驱逐的缓存行时(所有候选的替换缓存行都有私有缓存备份),对这些缓存行实施随机替换策略,且当此类替换发生次数超过阈值时,向操作系统发出预警.Wang等[50]指出由于每轮迭代攻击获取的信息量有限,攻击者通常需要频繁的探测目标缓存行.这种持续性的攻击过程会引发目标缓存行在各缓存层级(或内存)间频繁的迁移,呈现出异常的乒乓流量.该防御提出扩展的整流器目录,记录每个缓存行的重访次数识别异常流量的乒乓模式,并针对性地触发保护动作(Preload或Lock),从而干扰攻击者的探测结果.Panda[51]指出被攻击的缓存行存在着Back-Invalidation-Hits的特性,即攻击者首先要在缓存层次无效化目标,再通过命中或缺失确定受害者的访问特性.因此,该方案选择对出现这种特征的缓存行触发硬件预取以干扰对此类潜在的目标地址的攻击.
基于机器学习的检测:Zhang等[52]使用无监督学习分析加密程序执行过程中每个程序片段的末级缓存缓存命中和缺失,若测试集某个片段出现异常的值偏离则认为存在潜在的攻击,但是该方案需要标记进程号以标注需要被监控的程序.CHIAPPETTA等[53]分析多个程序执行过程的特征(如总指令数、L3命中和缺失等),获得均值、方差和概率密度函数,从而鉴别异常和正常程序微架构行为.上述两种探测机制仅能够对加密程序有效,FortuneTeller[54]利用循环神经网络(RNN)同时训练正常程序和多种攻击程序,在识别微体系结构侧信道攻击的基础上,还能发现诸如幽灵、熔断等新攻击.
4 结 语
本文阐述了存在处理器微体系结构时间侧信道的根本原因,程序间的微架构共享以及快/慢速微架构行为特性.结合若干重要微架构组件各自的特点,分析了微体系结构时间侧信道是如何被恶意程序建立并利用的.纵览现有的针对微架构组件的攻击,依据攻击手段将微体系结构侧信道的利用分为两大类,即基于复用和基于竞争,并分别进行介绍.本文分析了现有的基于硬件的微体系结构侧信道补救,将这些防御分为三大类,即基于隔离、基于随机和基于检测.本文系统性地介绍处理器微体系结构侧信道,通过分析微架构组件时间侧信道的建立以及对攻防博弈的全局概括,倡导重新审视性能优先的设计理念,助力微架构设计师对优化新特性的信息泄露风险进行评估.
猜你喜欢
指挥与控制学报(2022年4期)2022-02-17
爱你(2018年16期)2018-06-21
系统工程与电子技术(2016年4期)2016-08-24
现代防御技术(2016年1期)2016-06-01
海军航空大学学报(2015年1期)2015-11-11
指挥与控制学报(2015年4期)2015-11-01
中国健康心理学杂志(2015年5期)2015-09-05
空间控制技术与应用(2015年4期)2015-06-05
母子健康(2015年1期)2015-02-28
中国社会公共安全研究报告(2013年1期)2013-03-11
