
基于机器学习的恶意命令检测方法*
2020-11-20 03:13
通信技术 2020年11期
(上海交通大学,上海 200240)
0 引言
互联网+时代,网络空间安全保障已然成为影响国家安全、社会稳定、经济发展和文化传播的基础性问题[1-2]。入侵检测作为一种主动防御方法,能够对外部入侵、内部攻击和误操作的行为提供防护,并根据威胁采取措施。从发起攻击的来源出发,可以将攻击分为外部攻击和内部伪装攻击,其中内部伪装攻击是指未经授权的用户将自己伪装成合法用户进入组织内部访问、修改、删除关键数据或执行其他非法操作的行为[3]。
1 基于频率的检测方法
1.1 相关研究简述
目前,针对用户输入命令进行的检测方法可以大致分为两类:一类侧重于用户输入频率信息,另一类侧重于对用户行为进行建模。前者具有简单高效的特点,但是在传统检测手段下检测效果往往欠佳。近年来,基于机器学习的检测方法在多方面表现出优于传统分类方法的特点。因此,可以使用机器学习方法进行改进以提高检测能力。
AT&T Shanon 实验室提供的SEA 数据集是恶意命令检测领域使用最为广泛的数据集[3]。Maxion[4]等人最先将朴素贝叶斯方法引入恶意命令序列检测过程中,根据某条命令在数据集中出现的概率对用户输入命令的概率进行预测,但最终准确率仅为69.3%。Zhou Jian 等人[5]基于N-gram 分别使用SVM 和AdaBoost 方法进行检测,分别取得了80.1%和89.2%的准确率。Dai Geng[6]等人提出了一种既考虑频率信息又考虑用户行为转换特征的方法,最终取得了95.2%的准确率。Subrat[7]等人基于适应性朴素贝叶斯(Adaptive Naive Bayes)提出了在频率信息之外考虑用户行为偏差的方法,但是没有能够进一步提高准确率。
1.2 实验方案设计
SEA 数据集记录了50 名用户操作数据,每名用户采集15000 条命令输入信息,其中前5000 条命令是正常用户行为,而后10000 条命令则添加了恶意命令行为,每100 条命令划分为一个组块。
文本向量化方法是一种将文本信息转换为向量的方法,虽然该方法能够表达的特征较为简单,但是有着受数据脱敏处理影响小的优点,因而在恶意命令检测目标上具有一定优势。使用文本向量化方法将命令序列转换为向量的过程如下:
(1)定义一个集合A,该集合应当包含全部或有意义的用户命令输入;
(2)逐行遍历用户的全部记录信息,除非该命令已经包含在集合A中,否则向集合A中添加这一命令;
(3)按照数据集的原始划分遍历50×150 个组块,对于每一个组块,记录集合A中元素出现的次数,将遍历结果记录为向量L,其长度等同集合A元素的个数。
通过对SEA 数据集进行清洗、提取、计数、筛选等操作,共获得有意义的命令857 种,出现频率排在前十位的有sh、cat、netscape、generic、ls、popper、sendmail、date、rm、sed。表1 展示了该方法示例。

表1 文本向量化示例
1.3 实验结果验证
实验选用四项指标以衡量检测效果,依次为准确率、漏检率、误报率和F1-score。将实际为正样本且检测结果也为正样本的样本数量记录为TP,实际样本为负样本且检测也为负样本的数量记录为TN,实际为正样本却检测为负样本的数量记录为FN,实际为负样本却检测为正样本的数量记录为FP。四项指标计算公式如下:

为对比不同机器学习算法和测试集大小对实验结果的影响,选用Naive Bayes(朴素贝叶斯)、Linear SVM(Linear Support Vector Machine,线性支持向量机)、BPNN(Back Propagation Neural Network,后向传播神经网络)、Decision Tree(决策树)和Random Forest(随机森林)算法分别以70%、50%、20%的训练集大小进行实验,结果如表2 所示。从表中可以看出,训练集大小对检测结果影响并不明显。随机森林在全部实验中都表现出了最好的性能,线性支持向量机和决策树算法也表现出了优于朴素贝叶斯的性能,后向传播神经网络方法表现最为糟糕。多个模型表现都优于早先研究提出的检测方法。
深度学习方法在恶意命令检测领域的研究成果相对较少,王毅[8]等人将深度学习方法用于SEA 数据集检测,但是准确率并没有表现出相较传统机器学习方法的优势(表3);牟宸洲等人使用BiLSTM进行恶意命令序列检测[9],但其使用的是经过编辑的SEA 数据集,因此将实验结果进行直接对比并不妥当。由此得出,本文提出的方法能够显著提高基于用户输入频率的检测能力,且其表现甚至可能好于深度学习方法。

表2 基于频率的检测结果
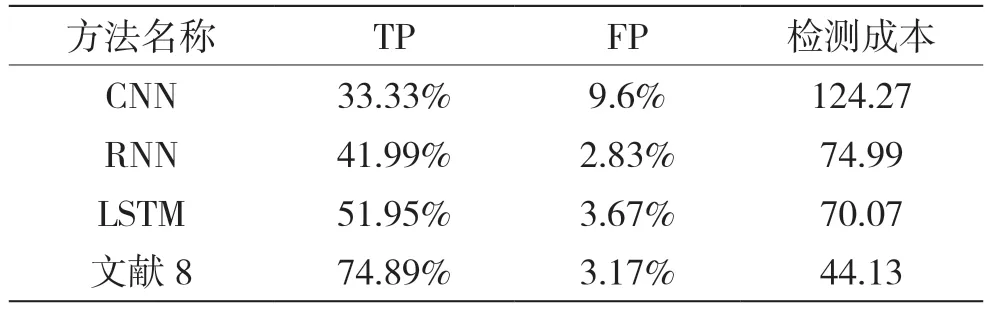
表3 文献8 对比的深度学习方法
1.4 存在的不足
尽管实验表现出了很好的结果,但是依然存在下列不足:
(1)考虑到50 名用户数量较少的问题,随着用户数量增加和提供命令行方法的软件或工具增多,有可能面临维数过多的问题。
(2)虽然该方法表现出了很好的检测能力,但是如果样本出现了训练集中不具有的命令内容,该检测方法对其检测能力仍需检验。
(3)当组块中只包含某种恶意行为的一部分信息时,是否能表现出良好检测能力仍未知。
2 基于频率和知识的改进检测方法
2.1 数据集编辑
为了模拟真实环境下组块划分不够精确造成的干扰,首先确定一批用于向数据集中插入的恶意命令序列,这些命令序列包含了大量遍历文件目录、大量删除文件、恶意webshell、反弹shell 生成、创建加密文件等恶意行为。

表4 修改后的组块示例
在对组块执行插入时,将一种恶意行为包含的命令信息分散插入多个组块中,将有数据插入的组块标识为负样本,而没有被插入的组块则维持原有标识。表4 给出了一些修改后的组块示例。经过修改的数据集更加贴近当今网络安全形势。
2.2 输入频率特征选取
根据先前实验的结果,随机森林分类方法在恶意命令检测上表现出了最佳的性能,因此可以参照随机森林的特征重要性进行特征选取。该方法的中心思想是以决策树中单个特征的相对秩为依据,评估该特征对结果预测的相对重要性。例如,在树顶部使用的特征有助于对更大比例的输入样本进行预测,因此它们贡献的样本的期望分数可以用于估计特征的相对重要性。为了避免出现频率过低的特征重要性被夸大,在选定特征前进行信息量计算,设定信息量阈值为0.3%,只有提供的信息量占比高于阈值的特征才会被选用。将满足信息量要求的前100 项命令选出,并在出现频率之外统计其连续出现频率、出现频率间隔等统计特征,作为最终的频率特征。

2.3 基于知识的特征抽取
为应对未知输入,需要发掘相应异常检测方法。在如今威胁情报数量和获取方式都得到了不同程度发展的背景下,基于知识的方法可以发挥更大的作用。通过查阅资料,使用Terran Lane[10]提供的UNIX 用户数据集作为知识库正样本,删去数据集中命令参数数量等信息以同SEA 保持一致。对于负样本,从经过编辑后的SEA 数据集的负样本中预先抽取10%的负样本作为知识库中的负样本。表5和图1 展示了特征获取过程。

表5 基于知识的特征
2.4 实验结果与分析
实验采用同1.3 节相同的算法和参数,将70%的数据用作训练集,剩下30%作为测试集。最终结果如表6 所示。实验结果表明,基于频率和知识的方法具有良好的检测能力。

表6 实验结果
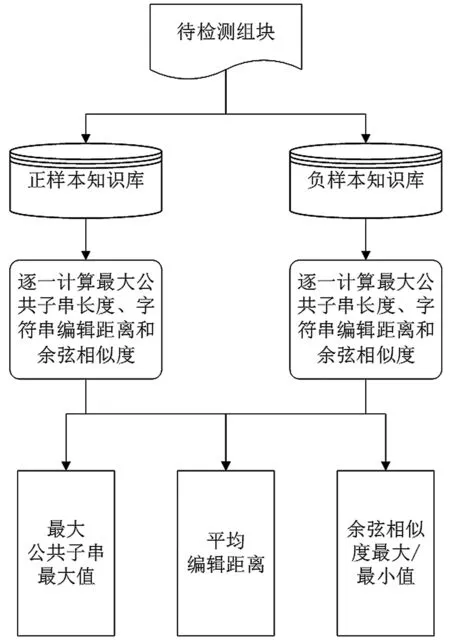
图1 特征选取过程
3 结语
针对传统基于用户输入频率的恶意命令检测效果不佳的问题,本文提出了一种借助机器学习方法的频率检测方法,在SEA 数据集上的实验表明:该方法能够显著提高检测能力。为了研究在更贴近真实环境下的表现,对原始数据集进行了修改使其更符合真实环境,面对新实验环境提出了基于用户输入频率特征的特征选取方法和基于知识的特征抽取方法,结果表明能够较好地检测出恶意命令特征。
尽管通过修改数据集的方式贴近了真实环境,然而本文提出的方法仍然是在小规模用户数据基础上进行的,缺少在大型数据上的实验;与此同时,基于知识的特征在知识库十分庞大时会消耗大量计算时间,因此下一步应考虑采用分布式计算等方法缩短用时。
猜你喜欢
娃娃乐园·综合智能(2022年3期)2022-04-19
电脑爱好者(2021年12期)2021-06-22
天天爱科学(2020年6期)2020-09-10
中学课程辅导·教师通讯(2020年22期)2020-02-04
网络安全和信息化(2019年1期)2019-12-22
船海工程(2019年1期)2019-03-04
军营文化天地(2018年2期)2018-04-20
爱你(2017年24期)2017-08-09
探索科学(2017年4期)2017-05-04
电脑爱好者(2016年22期)2016-12-16
