
基于分层部分核实数据对二项比例的齐性检验*
2020-11-16 04:37李天骄
重庆工商大学学报(自然科学版) 2020年6期
李 天 骄
(重庆理工大学 理学院,重庆 400054)
0 引 言
疾病患病率(二项比例)的估计是临床试验和医学研究中的一个重要课题,可以从特定的群体中抽取受试者进行诊断并分类为患有或不患有疾病,以此来估计疾病的患病率。筛检方法通常用于诊断过程的第一阶段,其优点是价格相对便宜、能够快速获得结果,并且对受试者通常是无害的。然而,筛检方法的结果往往是存在误判的,使用这些被错误分类的数据研究疾病流行率会导致估计有偏差[1]。另一方面,完全无误判的检测方法(金标准)往往价格昂贵且耗时,因而不能对所有个体使用。Tenenbein[2]为了解决这个问题,提出了二重抽样的方法。在二重抽样中,所有的受试者都将接受筛检方法的检测,但只有其中n个人接受了金标准的检测,因而有部分个体只接受了筛检方法的检测。Tang等[3]将通过这样的方法得到的数据称之为部分核实数据。
二重抽样的设计和分析一直是统计研究中的重要课题。国内外已有大量学者进行了研究。例如,Espland和Odoroff[4]提出了对数线性模型,并通过EM算法的最大似然估计导出了参数估计和参数函数的协方差的表达式;Geng和Asano[5]提出了用于二重抽样下有误判的分类数据的贝叶斯估计方法;Alonzo[6]对各种疾病患病率的形式和属性进行了对比,并提出了半参数有效方法是二阶段研究中患病率估计的首选方法;Tang等[7]提出了12种构建患病率置信区间的方法;Qiu等[8]分别考虑了根据显著性检验和置信区间宽度的样本量确定;邱等[9]基于两种模型提出了在给定置信水平下的样本量的近似公式;邱和何[10]在无金标准情况下对2组疾病流行率进行了比较研究;Lui[11]提出了3个简单的统计量,用于在有患者不配合的情况下的分层随机临床试验中风险比的齐性检验。然而在大多数情况下,当年龄不同或生活环境等其他因素不相同时,人群中的患病率总是不相同的。这时就需要对受试者进行分层归类,探究分层情况下的疾病流行率问题。现研究在金标准存在时,基于分层设计下的部分核实数据,考虑了各层的敏感度和特异度不同时二项比例(疾病流行率)的齐性检验过程。
1 统计模型及检验统计量
1.1 模型与参数估计
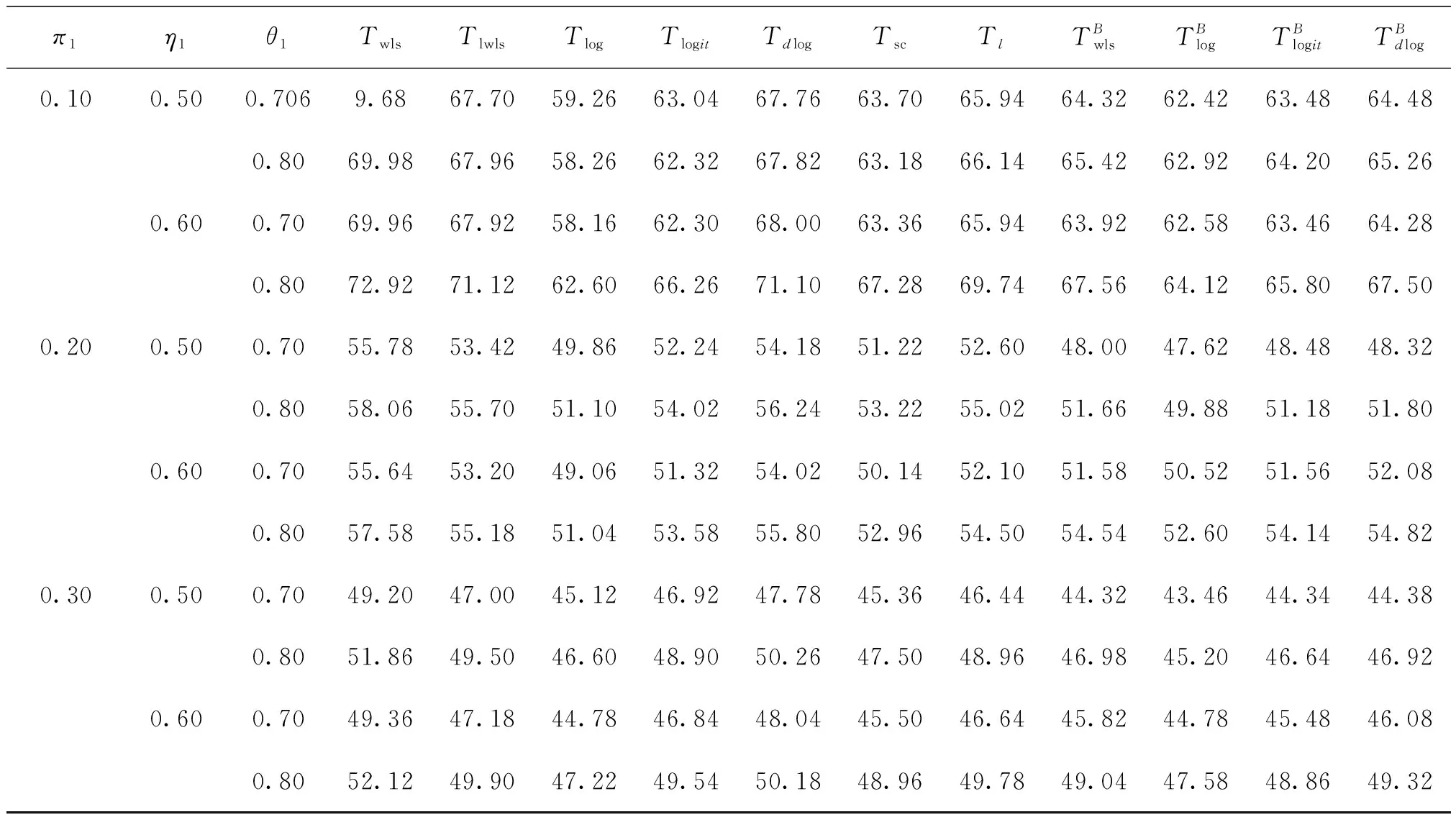
假设有Nj个个体是从第j个总体中随机抽取的,这Nj个个体每个都接受筛选检测,检测的结果为Tj。设Tj=0表示个体检测呈阴性,否则,Tj=1;从Nj个个体中随机抽取nj(nj 表1 第j组的数据结构Table 1 Data structure of Jth group 令πj=P(Dj=1)表示第j个总体的疾病流行率,ηj=P(Tj=1|Dj=1)和θj=P(Tj=0|Dj=0)分别表示第j个总体的筛检检测的敏感度和特异度。pj表示第j个总体中用筛检方法判断为阳性的概率,显然,pj=ηjπj+(1-θj)(1-πj),1-pj=πj(1-ηj)+ θj(1-πj)。 对如下的假设检验感兴趣: H0:π1=π2=…πj=π↔H1:π1,…,πj 不全相等。令: m={(n11j,n10j,n01j,n00j,xj,yj)′,j=1,…,J}, 则对数似然函数为 (1) 以上对数似然函数分别对πj,ηj,θj(j=1,…,J)求偏导,并令式子等于零,得到非限制性极大似然估计: (2) (3) 在原假设H0:π1=π2=…πj=π下,对数似然函数为 其中,pj1=ηjπ+(1-θj)(1-π),以上对数似然函数分别对π,ηj,θj(j=1,…,J)求偏导并令式子等于零,可得π的限制性极大似然估计为 此方程组没有显式解,可通过迭代法如牛顿迭代法求解。 对于齐性检验H0:π1=π2=…πj=π↔H1:π1,…,πj至少有一个不相等。考虑了以下统计量: 1.2.1 加权最小二乘统计量 根据Fleiss等[12]可得,当原假设成立,在Nj趋于无穷大时,Twls渐近服从自由度为J-1的卡方分布。 1.2.2Twls的对数变换统计量 根据Fisher等[13],对数变换后的Twls检验统计量将更加接近正态分布。因此,基于Twls统计量考虑如下的检验统计量: Tlwls={log(Twls/(J-1))/2+ 当原假设成立,在Nj趋于无穷大时,统计量渐近服从标准正态分布。即当Tlwls≥z1-α,则拒绝原假设,其中z1-α为标准正态分布的上α分位数。 1.2.3 基于对数变换的检验统计量 1.2.4 基于logit变换的检验统计量 其中 当原假设成立,在Nj趋于无穷大时,Tlogit渐近服从自由度为J-1的卡方分布。 1.2.5 基于双对数变换的检验统计量 其中, 当原假设成立,在Nj趋于无穷大时,Tdlog渐近服从自由度为J-1的卡方分布。 1.2.6 Score检验统计量 根据Rao[14]的score检验的一般理论,由对数似然函数l1可得到原假设H0下第j层的Fisher信息阵为 其中,pj1=ηjπ+(1-θj)(1-π),1-pj1=π(1-ηj)+θj(1-π) 根据Tang等[3],第j层的score统计量为 1.2.7 似然比检验统计量 根据式(1)和式(2),对于假设检验H0:π1=π2=…πj=π↔H1:π1,…,πj不全相等的似然比检验统计量为:Tl=2[l1(m;π,η,θ)-l2(m;π,η,θ)]。当原假设成立,在Nj趋于无穷大时,Tl渐近服从自由度为J-1的卡方分布。 1.3.1 渐近的检验过程 1.3.2 Bootstrap重抽样检验过程 渐近的检验过程的模拟结果表明,小样本下除了score检验和似然比检验的其他检验统计量的表现并不是很好,此时,bootstrap重抽样检验过程是一个有效的选择。因而,基于Twls,Tlog,Tlogit和Tdlog考虑了如下步骤的基于bootstrap重抽样的检验过程: Step 1计算观测数据m={(n11j,n10j,n01j,n00j, 基于Bootstrap重抽样方法的检验p值为 (q=wls,log,logit,dlog),其中,I(*)为示性函数。在显著性水平α下,如果pq<α,则拒绝原假设(q=wls,log,logit,dlog)。 为了检验提出的各种检验的有效性,通过蒙特卡罗模拟方法对各种检验过程进行评价。考虑了J=3的模型和如下的样本量:平衡设计样本量 在显著性水平α=0.05下,每个检验统计量犯第一类错误的概率为:检验统计量拒绝原假设的次数/5 000(H0成立下);经验功效的计算公式为:检验统计量拒绝原假设的次数/5 000(H1成立下)。犯第一类错误的模拟结果见表2—表5。对于功效由于篇幅的限制只列出了中等样本(平衡与非平衡设计)的模拟结果,见表6—表7。 表2 在小样本下各种检验犯第一类错误的概率(显著性水平α=0.05) % Table 2 Actual type I error rates of the various procedures in small-sample performance(notability level α=0.05) % 表3 在中等样本下各种检验犯第一类错误的概率(显著性水平α=0.05) %Table 3 Actual type I error rates of the various procedures in moderate-sample performance(notability level α=0.05)% 表4 在大样本下各种检验犯第一类错误的概率(显著性水平α=0.05) % Table 4 Actual type I error rates of the various procedures in large-sample performance(notability level α=0.05) % 表5 在不平衡样本下各种检验犯第一类错误的概率(显著性水平α=0.05) %Table 5 Actual type I error rates of the various procedures in unbalanced-sample performance(notability level α=0.05)% 表6 在中等样本下各种检验的检验功效(显著性水平α=0.05) % Table 6 Actual test powers of the various procedures in moderate-sample performance(notability level α=0.05) % 表7 在不平衡样本下各种检验的检验功效(显著性水平α=0.05) % Table 7 Actual test powers of the various procedures in unbalanced-sample performance(notability level α=0.05) % 模拟结果表明: (1) 即使在小样本(如(n1,n2,n3,N1,N2,N3)=(30,30,30,50,50,50))下,基于score统计量的渐近的检验过程犯第一类错误的概率都很接近给定的显著性水平且功效也较高。 (2) 除了在π=0.1外,基于似然比统计量的渐近的检验过程也表现较好,其第一类的概率接近给定的显著性水平且具有较高的检验功效。 (3) 随着样本量的增大,基于各种统计量的渐近的检验过程犯第一类错误的概率越来越接近给定的显著性水平。 根据Nedelman[15]的文章,世界卫生组织和尼日利亚政府在1969—1976年间对尼日利亚的疟疾进行了大规模的流行病学和控制研究。按照受试者的年龄将调查结果分为了7个年龄段,选取了其中3个成年人组(即19~28岁,29~43岁和44岁以上)的数据说明提出的方法。将高级显微镜学家的判断假定为金标准,数据结构如表8: 表8 尼日利亚疟疾数据Table 8 Malaria data in Nigeria
π=(π1,…,πJ)′,η=(η1,…,ηj)′,θ=(θ1,…,θj)′,

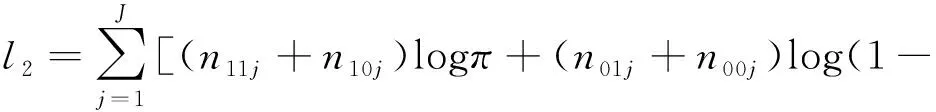
1.2 检验统计量


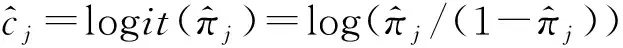




1.3 检验过程




2 模拟研究
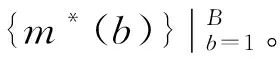






3 实例分析


4 结 论
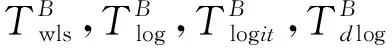
猜你喜欢
临床肝胆病杂志(2022年6期)2022-11-25
心理学报(2022年10期)2022-10-12
健康体检与管理(2022年2期)2022-04-15
黑龙江大学自然科学学报(2022年1期)2022-03-29
中国循证心血管医学杂志(2022年1期)2022-03-15
魅力中国(2021年51期)2021-11-28
西南林业大学学报(2021年5期)2021-10-21
昆明医科大学学报(2021年5期)2021-07-22
昆明医科大学学报(2021年1期)2021-02-07
电子制作(2019年24期)2019-02-23
