
YOLO算法在安检异常图像中的研究
2020-11-10 07:10李浩方李孟州
计算机工程与应用 2020年21期
张 震,李浩方,李孟州
郑州大学 电气工程学院,郑州 450001
1 引言
随着中国经济的快速发展,人民生活水平日益提高,乘坐汽车、火车、飞机等交通工具日益频繁。在汽车站、火车站和机场等人口密集的场所,安检是保证公共安全的重要保证措施之一。
从国内的安检行业的发展来看,X 光安检机[1]结合人工安检是主要的手段。但是,即使人工借助X光安检仪,如果遇到客流高峰等突发状况,安检工作人员的熟练程度和精神状态可能会影响安检的准确率[2],使公共安全存在隐患。因此,如何确保安检的高准确率和高效率,是人工检测现阶段比较突出的问题。
由于深度学习在目标检测领域中的快速发展,将神经网络与实际运用场景结合是目前一个热门方向[3]。目前基于深度学习目标检测与识别的方法可以分为两类:第一类是依赖候选区(Region Proposals)的提取的方法有 R-CNN[4]、SPP-NET[5]、FAST R-CNN[6]、FASTER R-CNN[7]、R-FCN[8]等,这些算法按照两阶段处理模式:提出候选区域,识别候选区域中的对象,这些方法在小目标的检测精度较高,但是检测的速度较慢;第二类是不依赖候选区的模型而基于回归的目标检测方法有SSD[9]、YOLO[10]等。由于YOLO采用是端到端的目标检测和识别,将物体检测作为回归问题求解,采取将候选框和对象识别两个阶段进行整合,直接输入图像经过推理,从而便能得到图像中所有物体的位置和其所属类别及相应的置信概率。YOLO算法相比较其他算法,不仅满足目标检测实时性的要求,还有较高的准确率。
因此,为了解决人工安检利用X光安检机不能实时确保准确率和效率的问题,本文基于深度学习中目标检测的YOLO 算法,提出了一种改进的Dense-YOLO 算法,对可疑物进行目标检测,能够提升安检中的准确率和效率。
2 基础算法介绍
2.1 YOLO-v3算法改进
YOLO(You Only Look Once)目标检测和识别算法是Redmon 和Farhadi 等人于2015 年提出的基于单个神经网络的目标检测系统。到2018年YOLO已经发展到第三个版本。相比较YOLO-v2[11],YOLO-v3[12]算法进行了如下改进:
(1)采用更深的卷积神经网络Darknet-53 取代Darknet-19,加深了网络层数。
(2)加入残差网络[13]。一方面,保证网络结构在较复杂的情况下能够收敛,并且有效提升分类和检测的检测效果,特别是对于小目标识别检测效果有了较大的提升。另一方面,残差网络中的1×1 的卷积,一定程度上减少了参数量和计算量。
(3)借鉴FPN[14](Feature Pyramid Networks)架构和引入Faster R-CNN 中锚定框思想,实现多尺度检测。采用多尺度来对不同大小的目标进行检测,采用3个尺度进行预测,每个尺度有3个锚定框。
(4)改进分类器-类别预测方法。YOLO-v3 用多个独立的逻辑(logistic)分类器替换softmax[15]函数,以计算输入属于特定标签的可能性。在计算分类损失时,YOLO-v3 对每个标签使用二元交叉熵损失,避免使用softmax函数而降低了计算复杂度。YOLO-v3算法结构如图1所示。

图1 YOLO-v3算法结构
2.2 DenseNet介绍
2017 年 Huang 等借鉴 ResNet 的思想,提出了一种全新的密集连接的卷积神经网络DenseNet[16](Dense Convolutional Network)。DenseNet 网络中任意两层都是直接联系的,网络中每一层的输入都是前面所有输出层的交集,并且每层网络中学习的特征图也会直接传输给后面的层作为输出,因此可以加强特征的复用。DenseNet的网络结构图如图2所示。

图2 Densenet网络结构
DenseNet网络中主要的结构有:稠密块(Dense Block)、瓶颈层(Bottleneck layer)和过渡层(Transition layer)。其中稠密块是密集连接网络的合集,主要由多层卷积层构成,可以有效地学习图像的特征;瓶颈层主要是减少输入特征图的数量,通过3×3 卷积对特征维度进行降维,起到了模型加速和压缩的作用;过渡层主要是对输出的特征图进行降维,由一个1×1的卷积层和2×2的平均池化层组成。
3 网络改进
YOLO-v3 在目标检测领域有较为出色的检测效果,但针对安检可疑物品的检测任务,需要对网络进行改进。本文结合自制数据集中可疑物品的特点,提出了一种改进的Dense-YOLO网络模型,改进的方法如下:
(1)Dense-Yolo网络设计[17]。借鉴了DenseNet网络中特征复用的思想,改进YOLO-v3 中的Darknet-53 网络结构,进一步加强特征在网络中的传递,一定程度上保留待检测目标图像整体轮廓的原始信息,提升可疑物品中小目标的识别。
(2)改进K-means[18]聚类。针对本文中的可疑物品数据集,需要重新采用改进K-means 聚类,得到新的聚类中心,以适应可疑物品的检测任务。
(3)卷积层改进。将原有网络中卷积层进行改进,将其中的卷积操作和批次归一化[19]操作进行合并,改进后可以提升网络的推理速度,一定程度上减少训练过程中的时间。
(4)采用多尺度训练。网络训练的过程中,采取随机选择某一个尺寸作为输入的图像,实现多尺度训练,增强模型的泛化能力。
3.1 Dense-Yolo网络设计
YOLO-v3 使用Darknet-53 网络来提取特征。由于网络层数的加深,容易出现过拟合或梯度(弥散、爆炸)的问题,因此,Darknet-53 网络中借鉴了残差网络的思想:将某一层的原始输出直接连接到后面的层中,在一些相同维度的层之间构建了res层。采用跳层连接的方式解决了深度神经网络中梯度消失的问题。
而本文借鉴DenseNet 网络思想:网络中每一层的输入都是前面所有层输出的累加和,同时该层的输出也会向后传播,成为后面一层输入的一部分。新的Dense-Yolo网络,采用密集连接可以通过通道上的维度连接来实现特征的复用,有助于可疑物小目标的特征提取,同时,减少参数和降低计算成本,提高网络效率。因此需要将Darknet-53中部分的残差层改为密集连接网络,同时参考DenseNet网络进行从新命名修改。改进后的网络结构模型如图3所示。
具体的改进方式为:由于Darknet-53 的第13 层到第36 层的维度相同,不需要进行维度的转换,因此将Darknet-53中res层更改为密集连接层,将Darknet-53中15 层、18 层、21 层、24 层、27 层、30 层、33 层和 36 层的shortcut 层改为route 层,原先res 层更改为密集连接层,实现相同维度特征的密集连接,将其设计命名为一个Dense Block-1;将第 40 层、43 层、46 层、49 层、52 层、55层、58层和61层的shortcut层改为route层,原先res层更改为密集连接层,将其设计命名为一个Dense Block-2;同理,将第 65 层、68 层、71 层和 74 层的 shortcut 层改为route层,原先res层更改为密集连接层,将其设计命名为一个Dense Block-3。Darknet-53 中第37 层卷积层与DenseNet 网络的过渡层(Transition layer)功能相似,都是对输出的特征图进行降维,故将第37 层重新命名为Transition layer-1;同理,将第62层重新命名为Transition layer-2。改进的网络模型输出的可视化图像如图4所示。

图3 改进的网络模型

图4 特征可视化图像
Dense-Yolo网络使用YOLO检测层进行类别输出,采用3个不同预测尺度对不同大小的目标进行检测,不同预测尺度分别为13×13、26×26和52×52。预测尺度输出特征图有两个维度是提取到的特征的维度,比如13×13,还有一个维度是采用以下公式进行计算:

式中,B表示每个预测的边界框的数量,C表示边界框的类别数。因此另外一个特征维度是3×(5+6)=33。对于本文所制作的数据集,有6 个类别,类别预测使用多标签分类,使用多个独立的逻辑logistic 分类器。预测的边界框的数量是3个,每个边界框有(x,y,w,h,confidence)五个基本参数。
3.2 标注框维度聚类的改进
YOLO-v3 中先验框参数是应用K均值聚类,预先选择9 个聚类簇,通过在COCO 数据集中聚类得到的,涉及种类众多,不适合用于训练检测安检异常物品,因此需要对先验框重新聚类。
由于传统的K-means算法采用欧式距离的算法,在聚类时易出现局部最优解的情况,为了获得更好的IoU(Intersection Over Union)得分,而与样本框的大小无关,减少大框于小框之间产生无关的错误。综合考虑,对传统的K-means算法进行改进,在锚聚类的过程中使用重叠度IoU作为两个框位置相似的度量,计算公式和新距离公式为:

式中,Ground truth表示为真实区域,Prediction表示为预测区域,box代表样本框,centroid代表K-means算法产生的聚类中心,IoU表示样本框和聚类中心框的交并比。改进K-means算法实现步骤如下:
(1)从数据集中随机选取一个样本点作为初始聚类中心xi。
(2)首先计算每个样本与当前存在聚类中心之间的距离,用D(x)表示;其次计算每个样本点被选为下一个聚类中心的概率。
(3)重复第(2)步,直到选择K个聚类中心。
(4)再针对数据集中的每个样本xi,计算K个聚类中心的距离,用D(x)表示;并将其分到距离最小的聚类中心所对应的类中。
(5)针对每个类别ci,重新计算它的聚类中心ci=(属于该类的所有样本质心)。
(6)重复第(4)步和第(5)步,直到聚类中心的位置不再发生变化。
因此,本文中进行上述方法的改进,根据自制数据集重新聚类分析,聚类过程中簇的中心个数K和平均交并比的关系如图5所示。根据坐标轴可知在K=9 时平均交并比的得分高并且曲线收敛,因此选择K=9,从而确定网络中的锚点数量和坐标位置。新聚类出来的9个锚定框为:(27×19),(33×28),(48×35),(51×43),(63×55),(78×64),(99×82),(118×104),(139×127)。

图5 聚类结果图
3.3 卷积层的改进
由于Darknet-53 的模型结构是由一系列的1×1 和3×3 的卷积层组成。在每个卷积层后都会跟一个BN(Batch Normalization)层和一个 LeakyReLU 层。在YOLO-v3中卷积层与BN层的计算公式为:

其中,xconv为卷积之后的计算结果,wi为连接权重,γ为缩放因子,β为偏置,σ2为方差,μ为均值,ε取0.000 000 1。
随着网络层数的增多,模型在训练过程中会占用更多显存和内存,由于BN层不仅能改善神经网络的梯度,减少对初始化的依赖,并且能够改善正则化策略,控制过拟合现象的发生。因此,有必要将卷积层和BN层整合,整合后的计算公式如下:
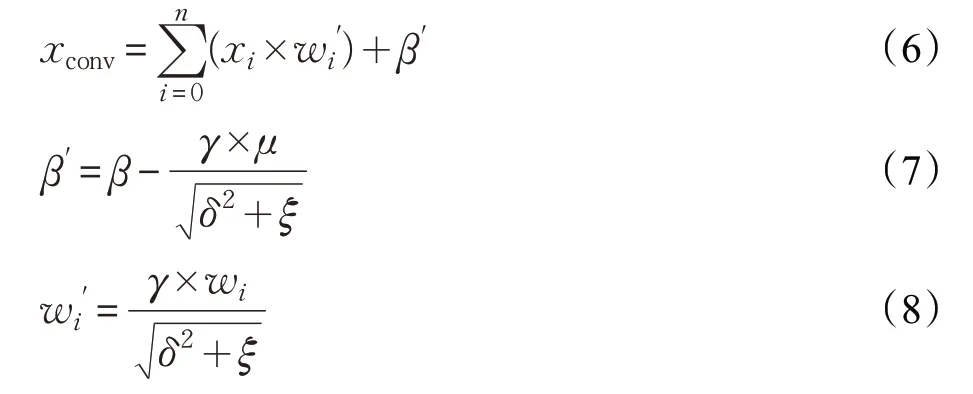
通过实验证明,将卷积层与BN层整合后,能够有效提升网络的推理速度和加速模型的训练过程。改进卷积层结构对比如图6所示。

图6 改进卷积层结构图
3.4 多尺度训练
改进后的检测算法中采用卷积网络来提取特征,未使用全连接层来得到预测值,因此,网络在训练过程中输入图片的尺寸不需要固定。
由于改进网络中包含有4 个残差模块和一个密集连接块,因此最小尺寸的图像为输入图像的1/32,所以在改变图像尺寸时,需要保证是32的倍数。因此,将训练集的图片大小分为多种图像尺度[20],分别为{320,352,…,608}。训练时采取每迭代10 次随机选取一种尺度训练。多尺度训练过程示意图如图7所示。

图7 多尺度训练过程示意图
4 实验结果及对比
4.1 实验数据集制作
由于X光机下的异常物品没有大规模的数据集,因此需要自己制作数据集。本文的数据主要来源于某汽车站人工检测异常的照片和安检培训中异常照片。一共收集到异常照片4 780张。
对收集到的数据利用LabeLImg工具对数据集进行目标分类标记,将标记工具生成的xml的文件进行整理,制作成标准的VOC2007数据集格式。将标注分类主要分为以下6类:可疑液体、打火机、剪刀、手机、电脑、充电宝。数据集中的标注的部分异常样例图像如图8所示。

图8 数据集中标注的异常样例图像
由于数据量相对较小,这导致在训练的过程中容易出现过拟合的问题,因此,本文采用两种数据增强的方法增加训练数据的多样性和复杂性。第一种采用线下数据增强方法,对所收集到的图片进行裁剪大小、调整角度、调整对比度和添加噪声,将数据集扩充到27 000张。第二种采用实时数据增强方法,主要是对训练图片进行随机的平移和水平翻转。在实验时,随机将80%照片作为训练集,剩下的20%作为测试集。
4.2 实验平台及网络训练
4.2.1 实验平台
本实验在PC端完成,实验平台配置如表1所示。其中YOLO-v3算法使用了darknet-53框架,Fast-RCNN和SSD算法使用了Caffe框架。

表1 实验平台配置
4.2.2 超参数设置和网络训练
改进的Dense-YOLO 模型,训练采用YOLO-v3 的权重参数作为初始化参数。在训练过程中采用动态监控,因此,训练1 000 次保存一次网络权重,方便选取最优的权重文件。改进网络检测效果最优的部分实验训练参数设置如表2所示。
Welcome to the world beard competition(世界胡须锦标赛)in Germany(德国)!Here,you can see funny beards.Three hundred men with beards from different countries come together.The one with the most special(特别的)beard wins.
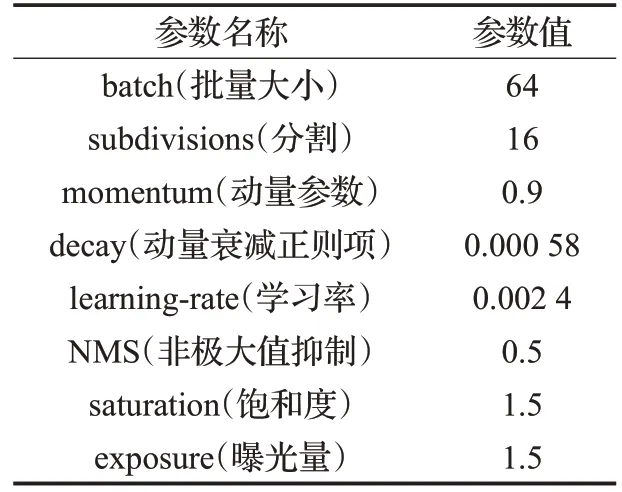
表2 网络训练参数表
Dense-YOLO 网络训练中,网络结构损失函数Loss值越小越好,期望值为0。为达到最优性能,迭代的次数选择20 000。现将迭代5 000 次以后的loss 进行说明:在5 000 到8 500 次时损失函数值较快速下降;8 500 次时降低为初始学习率的0.1 倍,损失值缓慢下降;在15 000 次时学习率在上一次的基础上再缩小0.1 倍,损失函数值逐渐减小并趋于平稳;17 500次以后损失值在0.02 左右,在20 000 次后结束训练。训练loss 变化如图9所示。

图9 训练过程中loss损失图
4.3 检测模型性能分析
4.3.1 网络结构改进分析
为了验证对自制数据集中可疑物的检测效果,本文进行对比实验。对比实验中,YOLO-v3 网络是采用darknet 框架对自制数据集进行训练,对YOLO-v3 网络采取优化的三种方法为:(1)修改新的学习率为0.001 8;(2)迭代20 000次;(3)采用新的聚类算法后得到的锚定框;(4)使用尺寸为608×608 的数据集进行训练。而Dense-YOLO网络使用本文中提到的卷积层改进、多尺度训练方法和迭代20 000 次。两种算法的检测对比以训练结束时得到的6种目标的AP值进行对比。图10中列举了6种不同物体在两种算法下的检测对比。

图10 两种算法的检测对比
由图10 可知,改进后的Dense-YOLO 网络模型,对于大目标的检测,例如电脑、手机和充电宝,检测精度较高,mAP[21]提升了4.6%;对于小目标的检测,例如打火机、剪刀,这类的小目标,检测精度有了较大提升,mAP提升了12.2%。由于可疑液体的检测结果有一定提升,但易受到容器大小和容器颜色的影响,因此对于可疑液体还需进一步安检。改进后的检测效果如图11所示。

图11 改进后检测效果
实验证明,改进后的Dense-YOLO 网络模型比原YOLO-v3 网络模型检测精度有所提升,其中mAP 提升了7.89%。其次,改进后的网络提升了可疑物的小目标检测精度,增强了模型的可靠性。
4.3.2 卷积层改进的对比实验
在3.3 节中提出改进卷积层的设计,对比实验采用Dense-YOLO模型,分为卷积层合并的最优模型和未合并的最优模型两组进行实验。使用测试集中随机挑选2 000 张照片在GPU 上进行预测推理,并将推理预测的时间进行平均统计。实验结果如表3所示。

表3 不同卷积结构推理对比表
实验结果表明,将卷积层与BN 层合并后的网络结构,在推理时间上提升了7.89%。说明对于卷积层的合并改进,可以减少计算来提升模型的推理速度。卷积层结构的改进,不仅可以提升训练速度,还能减少占用的内存和显存空间。
4.3.3 不同分辨率图像的性能分析
根据3.4 节中提出的多尺度训练的方法,本文对测试集中挑选四种尺寸进行性能分析,其中尺寸分别为320×320、416×416、512×512 和608×608。YOLO-v3 网络分别对四种尺寸的数据集进行训练,Dense-YOLO网络使用4.3.1小节中训练结果。图12代表两种算法针对不同图像尺寸测试结果以mAP数值对比。

图12 两种算法在不同尺寸下的对比
由图12可知,改进后的Dense-YOLO网络模型相比较YOLO-v3网络有两点提升:
(1)采用多尺度的训练策略,改进后的网络在不同尺寸上的检测精度均比YOLO-v3算法在检测精度上有一定提升,mAP 平均提升4.67%,同时增强模型对于不同输入尺寸检测可疑物品的适应性。
(2)采用多尺度训练策略相比于单一尺度的训练,多尺度训练对于高分辨的检测有着更好的检测结果。因此,提高输入网络中X 光安检仪图像的分辨率[22],能进一步提升可疑物品的检测精度。
4.3.4 检测模型的对比实验
为了验证模型在相同数据集上的检测效果,使用文献中Fast-RCNN、SSD、YOLO-v3 三种算法与改进算法作对比。采用图像的尺寸为608×608,数据集中随机选取12 000 张,按照8∶2 的比例将其分为训练集和测试集。对比的性能指标以mAP和FPS作为评价指标。实验的结果如表4所示。

表4 不同算法的性能分析
从实验结果分析可知,在四种算法中Fast-RCNN的识别准确率最高,但是检测的速度是最慢的。改进后的Dense-YOLO网络的mAP稍低于Fast-RCNN网络,但是在检测速度快147.5 倍。改进后的网络与SSD 算法和YOLO-v3 算法相比,改进后的网络在mAP 和检测速度上都有一定提高。由此说明,改进的网络在准确率和检测速度均有提高,并且能解决人工利用X光安检仪检测可疑物品中效率和准确率无法实时保证的问题。
5 结束语
本文基于YOLO 框架,借鉴DenseNet 网络中密集连接的思想,利用自制X 光下可疑物品的数据集,提出了一种改进的Dense-YOLO 可疑物目标检测算法。首先通过使用密集连接,实现了特征融合和复用;其次,对自制数据集采用改进的K-means算法进行维度聚类;然后对卷积层中的网络进行合并;最后采用多尺度的训练方法。通过多种方法改进的Dense-YOLO算法,在精度上达到了91.68%,检测速度上达到了59 f/s,不仅可以帮助安检人员高效的利用X安检仪,还能对可疑物品进行准确检测,一定程度上减少公共隐患。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年13期)2020-01-14
铁道通信信号(2019年6期)2019-10-08
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
雷达学报(2017年6期)2017-03-26
太空探索(2016年5期)2016-07-12
互联网天地(2016年1期)2016-05-04
智能系统学报(2015年4期)2015-12-27
