
基于组合偏最小二乘的特征波段优选方法在氨、碱化处理玉米秸秆粗蛋白检测中的研究
2020-11-09 04:04孔庆明谷俊涛李泽东苏中滨
分析测试学报 2020年11期
孔庆明,谷俊涛,2,高 睿,李泽东,马 铮,苏中滨*
(1.东北农业大学 电气与信息学院,黑龙江 哈尔滨 150030;2.黑龙江省网络空间研究中心,黑龙江 哈尔滨 150090)
玉米种植占我国粮食种植面积的42%,2019年我国玉米产量达2.57亿吨,与此同时也遗留下2.41亿吨秸秆,如何有效利用玉米秸秆成为行业难题[1]。玉米秸秆约占整株玉米生物量的50%,目前多数国家将秸秆作为反刍动物的重要粗饲料来源,秸秆资源饲料化成为现代农业的重要发展方向[2]。但玉米秸秆的粗蛋白含量低,纤维含量高,适口性差,限制了其有效利用[3-4]。目前秸秆的氨、碱化处理结合超声技术可有效打破纤维素与木质素之间的连接,使玉米秸秆更易为微生物附着,从而加速秸秆消化过程[5],达到提高粗蛋白含量,改善适口性,增加采食量,提高消化率的最终目的。但在进行最优氨碱超声条件判定过程中,秸秆中粗蛋白、纤维含量的测定基于化学检验,方法速度慢,成效性差,不适合大批量样品的测定和筛选。目前针对秸秆成分的快速检测方法较多,从非接触式方法来看光谱技术成为首选,高光谱及近红外检测方法应用较多[6-11]。本文结合近红外光谱分析技术对氨、碱化玉米秸秆粗蛋白含量快速检测方法开展研究,并对模型构建过程中数据冗余问题进行探究,采用组合间隔偏最小二乘(SIPLS)变量优选方法进行特征波长选择。通过构建快速检测模型实现氨碱最优条件的判定,解决秸秆低能量、多纤维、难消化的营养特性问题,对充分发挥秸秆潜在营养优势、解决人畜争粮问题、推动低碳农业发展具有重要意义。
1 实验部分
1.1 样品采集、制备及标定
1.1.1 样品采集选取东北农业大学高标准试验田的优质玉米秸秆(先玉335,中单909-第一积温带上限主栽品种)共计107株为实验样品,样品制备仪器采用微型植物粉碎机、超声仪和50 mL离心管;化学试剂为5%尿素溶液和4%氢氧化钠溶液。将收获后的秸秆选取根上40 cm处切割成6组3 cm长度样品(每3组做1个平行),分别对平行样本进行氨、碱加工处理。
碱化处理:取秸秆干物质,将4%氢氧化钠溶液溶于水,均匀喷洒在秸秆上,实验室条件下保持含水量为45%左右,密封保存,经碱化处理30 d后,打开密封袋,放置排氨72 h,待排氨后放置于65 ℃烘箱中烘干48 h至恒重,再研磨粉碎过200目筛[12]。
无处理空白样:晾晒制风干样秸秆,未经其他处理,称重后将秸秆置于65 ℃烘箱中烘干48 h至恒重,再研磨粉碎过200目筛。氨、碱化处理与无处理空白样处理同时进行。
1.1.3 超声处理取过200目筛的秸秆粉末在水浴条件下进行超声波处理。超声功率分别为60、75、90、105、120 W,超声时间分别为5、10、15、20、25 min,固液比分别为1∶5、1∶10、1∶15、1∶20、1∶25,容器内声功率密度分别为1.2、1.5、1.8、2.1、2.4 W·mL。处理完成后烘干并严格密封,保证良好的厌氧环境,在室温静置稳定后测定秸秆中水分、粗蛋白、半纤维素、纤维素和木质素的含量。
1.1.4 粗蛋白含量标准测定依据国标GB 5009.3-2010《食品中蛋白质的测定标准》[13]中的凯氏定氮法对氨碱及超声处理后的玉米秸秆固体粉末进行粗蛋白测算,得107个样本的粗蛋白含量分布区间为2.481 8%~6.519 3%,平均值为3.724 6%。
1.2 光谱采集
经氨、碱及超声处理后的秸秆样本为固态粉末,采用Antaris Ⅱ光谱仪对秸秆固体样品在4 000~12 000 cm-1波段范围内进行漫反射方式扫描,扫描分辨率为4 cm-1,采用积分球扫面方式,背景扫描及样品扫描均设定为64次,共计获得2 075个特征波段点。

图1 玉米秸秆近红外光谱图像Fig.1 Near infrared spectra image of corn straw
2 结果与讨论
2.1 模型构建前处理
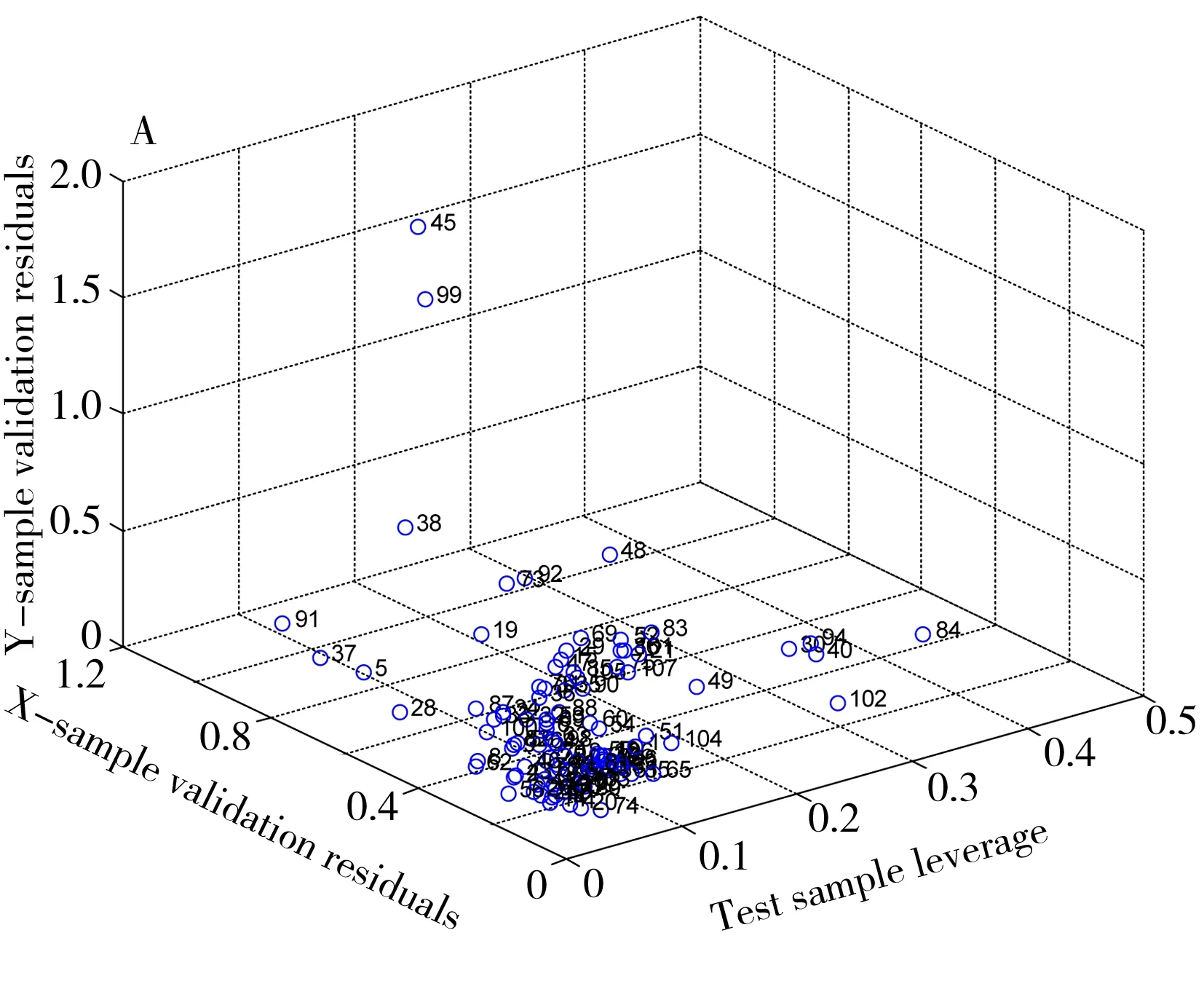
2.1.1 消除异常样本107个玉米秸秆光谱扫描结果如图1所示,部分样品明显偏离样本群体中心,因此采用基于3D视图的双残差融合杠杆值法及单残差法进行异常样本判定[14],综合二者判断结果进行异常样本剔除,对粗蛋白样本构建交互验证(Cross validation)定量分析模型,统计样本X残差(代表光谱)、样本Y残差(代表粗蛋白含量)及杠杆值(Leverage表示差异性)。由图可见,45、99样品具有明显的异常分布(距离群体中心较远,图2A)且具有较高的残差(图2B),均方根误差(RMSE)分别为1.690 3、1.443 2,因此将其剔除,对剩余105个样本进行正态分析,统计样本选择及分布,判定其是否具有代表性。
2.1.2 光谱去噪及样品分类首先采用小波变换方法进行噪声处理[15],在小波降噪过程中阈值的选取的方法直接影响降噪质量,而阈值方法中软、硬阈值各有优缺点,其中经软阈值去噪后信号较为平滑,但会丢失信号的部分特征,即相似性欠佳;硬阈值虽可保留信号特征,但平滑性不足。通常软阈值去噪相似性上的误差在允许范围内,所以较硬阈值法应用更广泛,本文选取软阈值法进行光谱去噪。采用基于DaubechiesN(DBN)系列中DB2 4层分解对比缺省阈值、Bridge-Massart策略及Penalty阈值3种数学模型的信号重构结果与原信号的信号噪声标准差作为评价标准,结果表明:上述3种模型下信号标准差分别为0.012 36、0.063 67、0.031 07。将基于缺省阈值重构的光谱数据与粗蛋白含量数据进行交互验证,从表1中可以看出,经异常样本剔除及小波去噪后粗蛋白模型的决定系数(R2CV)从0.788 9提升至0.920 8,交互验证均方根误差(RMSECV)从0.475 2降至0.329 1,表明以上方法可有效提升模型准确性。图3为原始光谱及3种阈值方法信号重构后的光谱图及105个样本的正态分析结果,可看出该样品集分布均匀,具有较好的代表性。

表1 玉米秸秆光谱预处理后模型交互验证结果Table 1 Corn straw model validation results after pretreatment

对105个样品进行分类,依据Kennardstone进行样品集分类,最终选取70 个样品为校正集,35 个为验证集,其统计分析结果如表2所示。
表中:ρ为土体密度,ω为天然含水率,ωp为土体塑限,ωL为土体液限,c为粘聚力,φ为内摩擦角,k为土体的渗透系数。

表2 玉米秸秆粗蛋白定量分析样品集分类Table 2 Classification of corn straw crude protein sample set
2.2 特征波段选取
玉米秸秆光谱含有大量冗余信息,降低了模型解析速度,需对其进行特征波段优选,常用方法有主成分分析法(PCA)、相关系数法(CC)、模拟退火法(SA)、连续投影算法(SPA)、遗传算法(GA)、间隔偏最小二乘(IPLS)、后向区间间隔偏最小二乘(BIPLS)、组合间隔偏最小二乘(SIPLS)、竞争性自适应重加权采样法(CARS)等[16-19]。其中IPLS是将整个光谱区域划分为等宽的若干个子区间,然后在每个子区间用PLS方法建立回归模型,并用交互验证法确定最佳主因子数,以交互验证均方根(RMSECV)作为局部模型的精度衡量标准,取精度较高的局部模型所在的子区间作为特征子间。SIPLS是在IPLS基础上联合同一次区间划分中精度较高的几个局部模型所在的子区间作为一个整体建立模型[20],从中选择使RMSECV值最小的组合区间即为最优的特征子区间。组合区间的数量一般取2~4个,但随着组合区间的增加,其计算量及计算时间也随之呈指数级增长。BIPLS可弥补IPLS单一区间的问题,也可弥补SIPLS计算时间较长的问题,其原理是将光谱区间分为n个等宽的子区间,每次预留出1个子区间,把剩余的n-1个子区间作为一个大区间来建立偏最小二乘回归模型,计算模型RMSE值,使剩余的n-1个子区间中具有最小RMSECV值的子区间即为第一个排除区间,直到计算只剩一个区间为止。本研究将分别论证IPLS、BIPLS以及SIPLS的特征优选实现过程及结果。
2.2.1 IPLS将整个谱图区间依据间隔数10、20、30、40进行区间划分并分别构建交互验证模型,各间隔区间的RMSECV分布见图4,从图中可以看出,RMSECV最小值明显集中于9 600~10 400 cm-1。图5为10~40间隔数下所选取最优区间及最优区间下校正集及验证集样本分布,其数据结果见表3。结合图5和表3可见,10间隔数下第8间隔在主因子数为7的情况下验证效果最好,验证集相关系数(rp)为0.966 6,验征集决定系数(R2P)为0.934 3,验征集均方根误差(RMSEP)为0.277 8。由此可见,IPLS的精准间隔划分可为特征波段的选取提供精准定位的判定依据。
2.2.2 BIPLS采用BIPLS依据间隔数10、20、30、40进行区间划分,每次预留出1个子区间,计算其余所有区间的均方根误差(RMSE),并不断排除多余区间,由于运算数据较多,运算量较大,因此本文仅展示间隔数40的波段选择过程,其特征选择的预留间隔、子区间、RMSE及变量数的变化结果见表4。从表中可看出RMSE随变量的不断减少而逐渐降低,直至预留间隔数9时RMSE达最小值0.249 0,此后RMSE随变量的继续减少发生波动并呈上升趋势,因此判定该间隔为其最优区间解。选择预留间隔数为9时的468个变量(实际间隔24~29)作为间隔数40的最优选择,其余间隔数10、20、30情况下依此类推,统计结果见表5。表中数据可见BIPLS在间隔数为10时选择7、8间隔(8 808~10 404 cm-1)具有最优模型验证精度,rp为0.978 0,R2P为0.956 4,RMSEP为0.229 1。其中BPLS间隔数为10时最优定量分析模型校正及验证结果见图6。


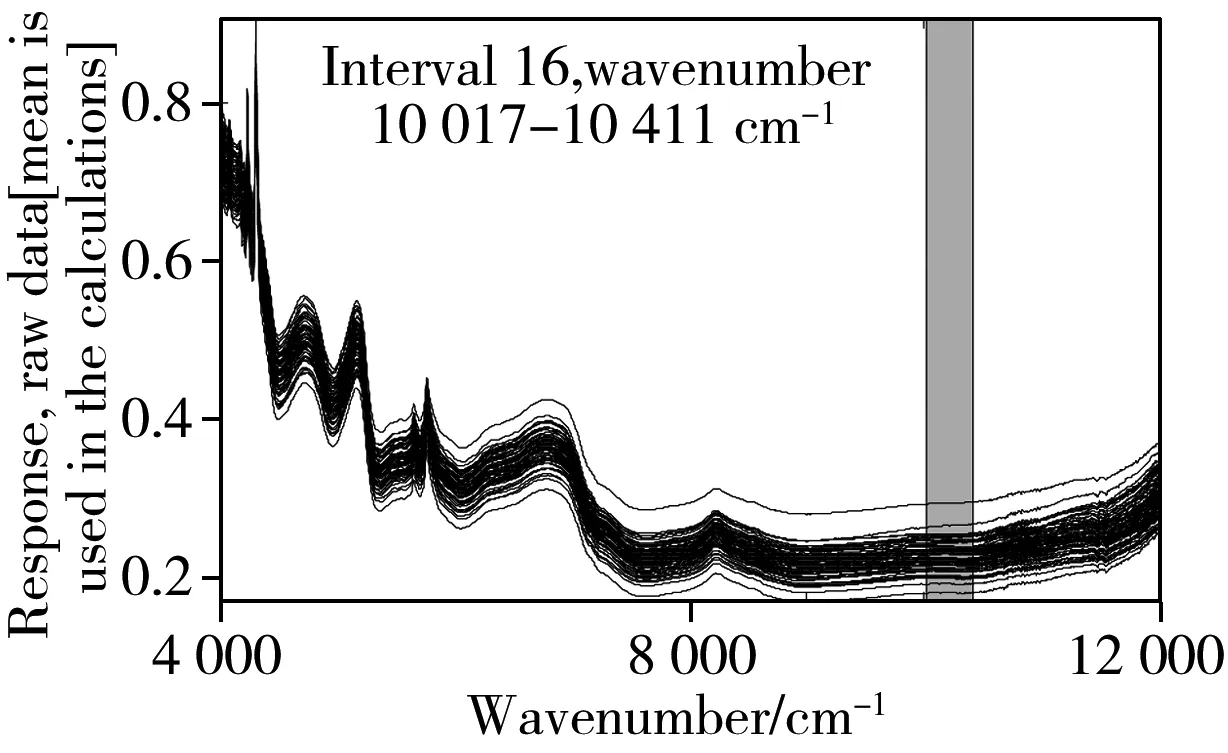
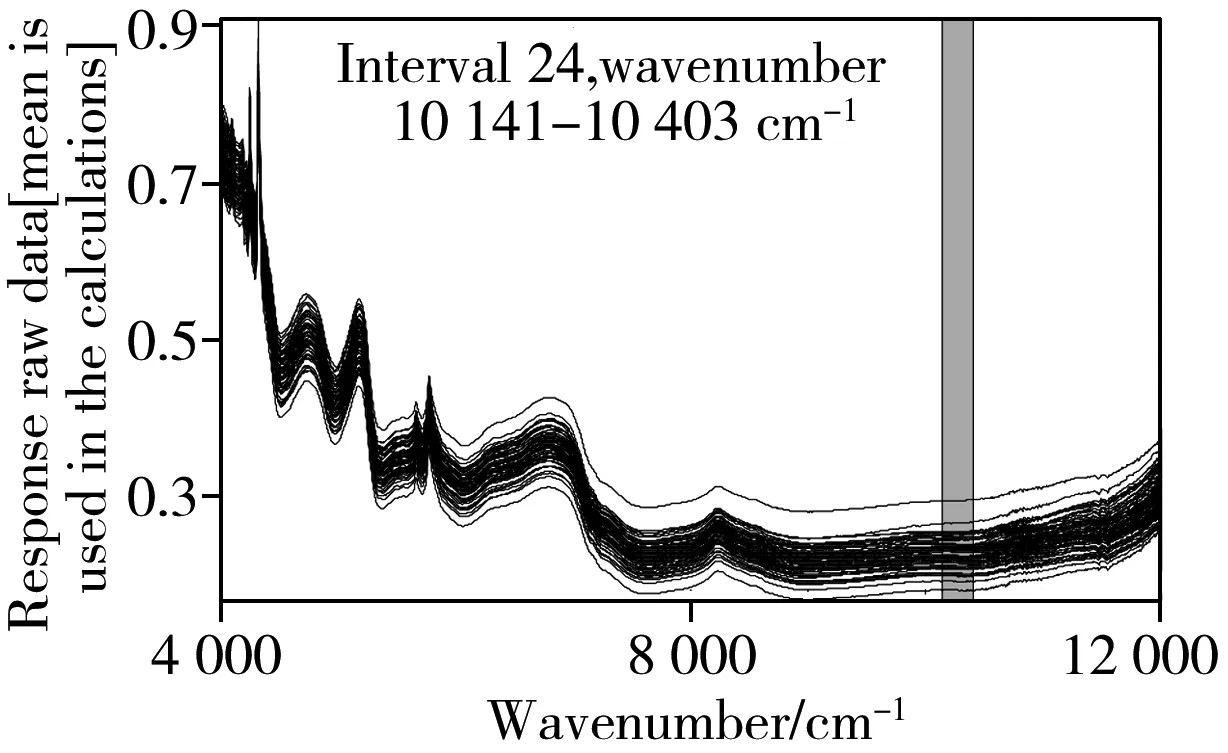
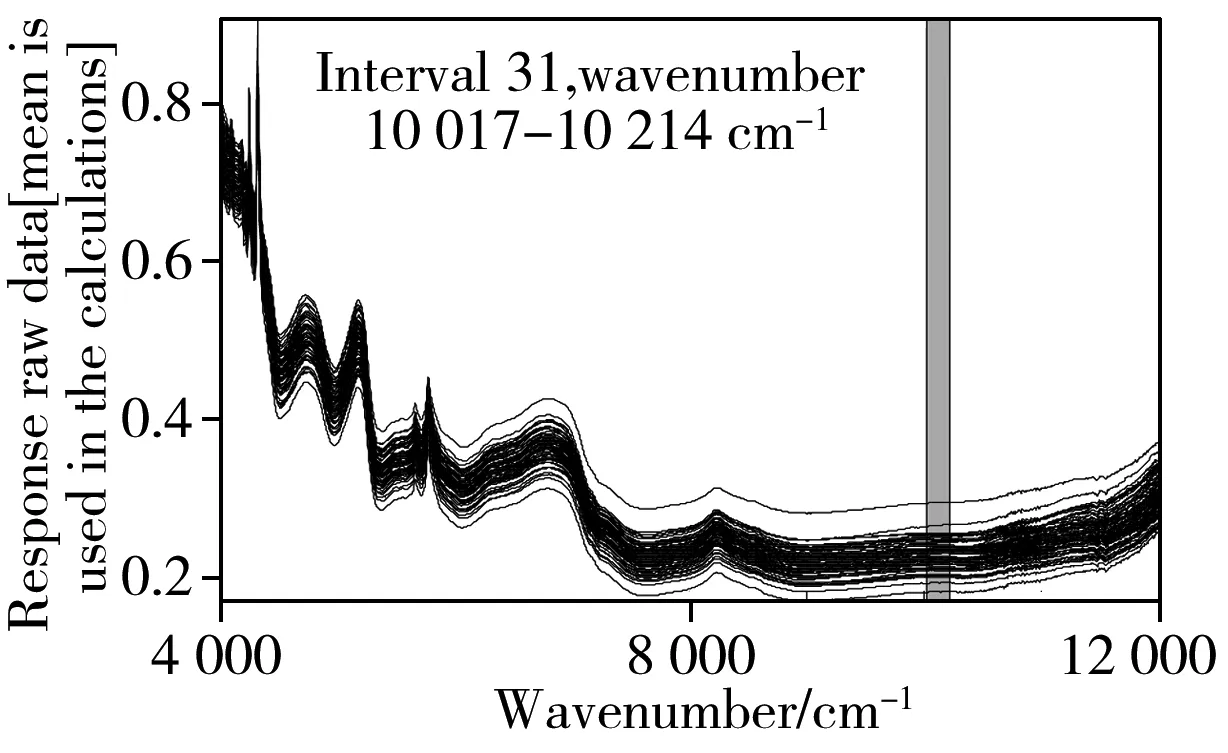

表3 IPLS优选后定量分析模型验证结果Table 3 Validation results after IPLS selection

表4 间隔40条件下RMSE及变量数量变化情况Table 4 Change of RMSE and variable number under 40 interval

表5 BIPLS优选后定量分析模型验证结果Table 5 Validation results after BIPLS selection


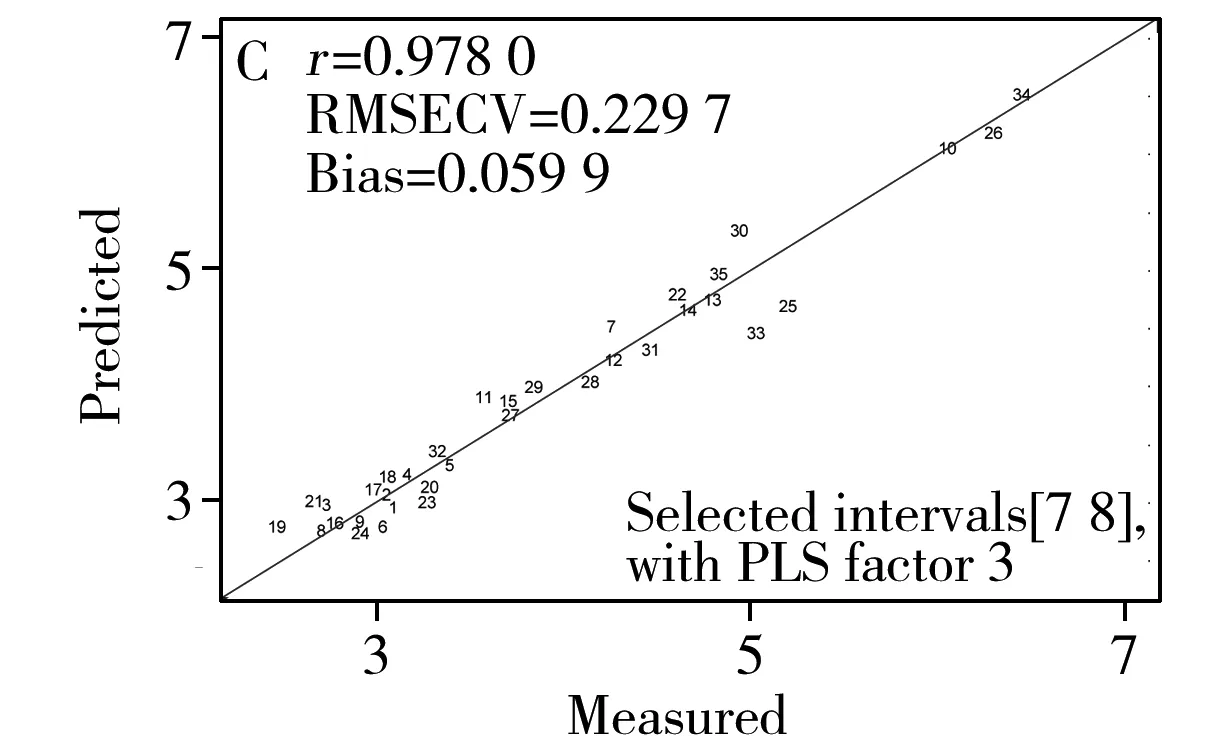
图6 BIPLS特征间隔选取及定量分析模型构建结果Fig.6 Optimal feature interval selection and model building results of BIPLSA:optimal feature interval selection(最优特征区间选取结果);B:predicted results of calibration set(校正集预测结果);C:predicted results of validation set(验证集预测结果)
2.2.3 SIPLSSIPLS以组合波段为主,其运算过程较繁杂,以间隔数40为例,其预留间隔、RMSE及变量数量变化见表6。选取2~4个变量组合并提取最优验证结果,在采用SIPLS方法特征选取的过程中发现,在间隔数10~30情况下选取2~4个变量组合,每次交互验证运算时间为0.5~1.0 min;而随着变量增大其模型验证时间呈指数级增长,在间隔数30时4变量组合执行时间明显增大,间隔数40时3变量组合模型运算次数达27 405次,4组合(间隔数40)时模型运算次数达91 300次,运算时间激增至24 min,因此本实验不计入间隔数40条件下的变量优选结果。另外,即使选择不同间隔数,其特征波段区间依然较为明显和集中,表6数据可见在执行间隔数30条件下2变量组合24、28具有最优验证结果,由此可见,不同间隔数及不同变量组合条件下其特征波长的选取均具有高度一致性,基本集中于9 800~10 400 cm-1,但执行间隔数40的多变量组合方式的运算时间过长。SIPLS方法30间隔数条件下2变量组合(24、28)的特征波长区间选取及定量分析模型校正及验证结果见图7。

表6 SIPLS优选后定量分析模型验证结果Table 6 Validation results after SIPLS selection
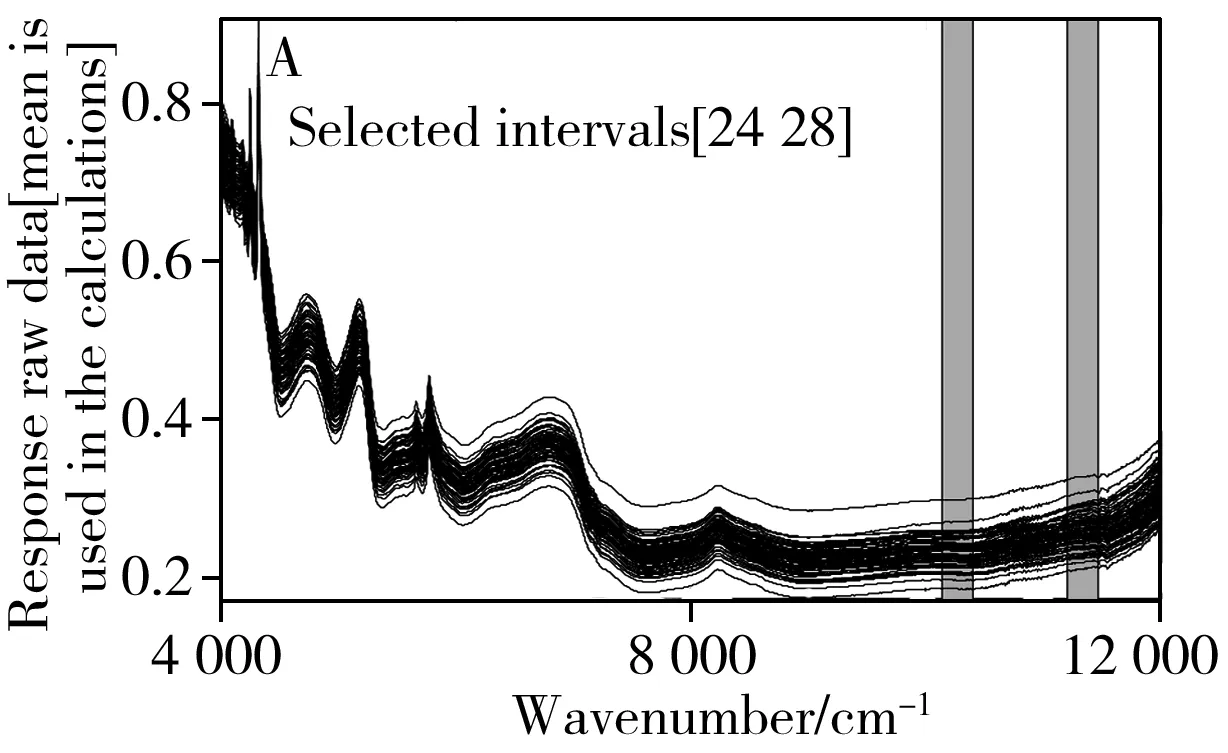


图7 SIPLS特征间隔选取及定量分析模型构建结果Fig.7 Optimal feature interval selection and model building results of SIPLSA:optimal feature interval selection(最优特征区间选取结果);B:predicted results of calibration set(校正集预测结果);C:predicted results of validation set(验证集预测结果)
2.3 分析讨论
为进一步验证玉米秸秆粗蛋白含量快速检测中SIPLS特征优选方法的优势,对多种特征波长选取方法及结果进行综合比较,PCA、相关系数法、CARS、GA、MWPLS等特征优选结果见图8。验证结果统计见表7。结果显示:采用SIPLS选取波段10 128~10 398 cm-1及11 196~11 462 cm-1时具有最优模型验证结果,rp为0.978 4(R2P为0.957 2),RMSEP为0.221 1。
综合对比IPLS/BIPLS及SIPLS等其他特征波长选择方法总结如下:
(1) 主成分分析(PCA):主成分分析法在进行特征选取中依据计算协方差等统计特征代表性实现数据降维,选取7个有效主成分即可代表所有特征波段(图8A),实现了数据重构及数据降维的特征优选。但相较于偏最小二乘建模方法,其特征选择仅针对光谱,不考虑样本特性与光谱的关联性,使得模型验证精度降低,且较低的重构主成分数无法实现对大量光谱信息的完整表达,无法完全描述非线性问题,表7中实验结果也印证了PCA在玉米秸秆粗蛋白模型构建中特征优选效果不够理想。
(2) 相关系数法:相关系数法的思想提出较早,是早期光谱模型构建的特征判定方法,分为自相关性(光谱-光谱)及互相关性(光谱-样品特性),通常自相关较低、互相关较高会具有较好的模型精度。但从相关研究可以看出[21],由于近红外吸收特性较低,多种样品间自相关与互相关性通常呈矛盾状态,如4 000~8 000 cm-1波数范围内相关系数普遍低于0.3,粗蛋白与光谱呈现较差的弱相关性,r大于0.7的强相关性区间为11 352~11 997 cm-1,相比于其他特征波段选择方法,具有明显的差异性(图8B)。



表7 不同特征波段优选定量分析模型及验证结果Table 7 Quantitative analysis model and validation results of different characteristic wavenumber
(3) CARS与GA:二者基本原理类似,均为基于进化理论而衍生的算法,其中CARS依据“适者生存”原理以指数衰减函数变化为判定依据,筛选出每次循环构建的回归系数绝对值最大的变量,如图8C所示,共选取146 个特征变量。GA通过不断种群迭代形成最优子代,通过信息的选择、变异、交叉来实现,本研究设定适应度函数为RMSE,通过不断迭代变异找到适应性最强即RMSE最小的特征变量,可见9 883、10 256 cm-1等8个波段构成的特征波段组合具有最小的RMSEP(图8D)。但CARS和GA两种方法均需借助先前经验,影响选择结果的因素较多,需设计与调整的参数(如选择方式、交叉重组方式等)较多,且选择结果的随机性较大,需多次验证(依据经验10 次平行)方可筛选出最优特征波段点,因此所选取结果不具有唯一性。
(4) 移动窗口最小二乘法MWPLS:移动窗口偏最小二乘基于窗口沿着光谱轴连续移动,每移动一个波长点,采用交互验证方式建立一个模型,得到系列不同窗口(移动波长点)和主因子数对应的残差平方和(PRESS或SSR),但移动窗口大小的宽度需不断尝试(本文通过多次试验选取31窗口,图8E)。从试验过程来看,窗口大小设置过大容易忽略和错过特征波长点,设置过小则容易陷入局部循环。
(5) SIPLS在原有IPLS基础上实现间隔波段自由组合,特征组合更为自由化,在实现特征间隔变化的基础上可实现特征波长的精确定位,不会出现GA、CARS等单独波段点提取情况,同时由于多组合、可变特征间隔相比于MWPLS的固定窗口大小更具灵活性的特性,不会破坏光谱数据的连贯性和特征吸收的渐变性,使得整个光谱区间分为多个模块进行分层次交互验证,因此在多组合、多间隔情况下模型表现较好,表7中最优模型(SIPLS 30 间隔,2组合)校正结果也论证了该方法的特性。但同时该法也存在弊端,主要表现为多间隔、多波段组合条件下特征选取运算量较大,系统响应较慢,大量特征组合变量形式构建交互验证模型消耗的时间随间隔增加呈指数级增长(40间隔4组合运算次数91 300次,耗时24 min)。目前,基于SIPLS可实现全谱波段4 000~12 000 cm-1下低于30间隔数4变量组合的特征优选,并呈现较好的准确性与实时性,但间隔数超40且变量组合数量大于4时现有服务器难以实现特征波段的快速、准确选取,特征选取响应时间较长。因此下一步工作会重点结合深度学习构建多层解析网络,整合优化非线性算法来实现多变量组合的快速选取,解决特征波段快速、精准定位的难题。
3 结 论
本文构建了玉米秸秆中粗蛋白近红外光谱定量分析模型,对样本进行异常剔除及光谱去噪后,对特征波段选取方法进行了探讨,重点对IPLS及其改进型方法BIPLS、SIPLS的波长选取原理、选取过程进行阐述,实现了定量分析模型的快速准确定标,为秸秆氨碱化处理最优条件判定提供了数据支持,研究结果如下:
(1) 数据预处理(剔除异常样本、光谱去噪)可有效提高模型样本的分布均匀性和代表性。本研究对107个样本进行残差计算,剔除2个具有明显较大残差的样本,交互验证模型决定系数R2CV从0.788 9提升至0.894 8,RMSECV从0.475 2下降至0.343 4。使用小波变换去除光谱噪声后,R2CV从0.894 8提升至0.920 8,RMSECV从0.343 4下降至0.329 1。
(2) 特征波段选取可有效提取代表性数据,降低数据冗余,提升模型解析速度并提高模型验证精度。本文采用IPLS、BIPLS、SIPLS对光谱区间重新排列,依据交互验证误差根结果进行多种特征波段选取(PCA、CARS、相关系数法、GA、MWPLS等),结果显示除PCA、GA及相关系数法外,其他特征优选验证结果都符合预期,可有效准确找到特征波段区间,其中在SIPLS 30 间隔情况下选取24、28间隔(共计138个特征波段点)时定量分析模型具有最优验证结果,rp为0.978 4,R2P为0.957 2,RMSEP为0.221 1。由此可见,SIPLS在间隔30以内可有效提取出2 组变量组合最优样品解,但在40 间隔以上拟合时间较长,变量组合超过4,运算时间呈现指数级增长,无法应用于实验室检测。要完成在线检测(大量样本、快速分析)则有待与其他方法如深度学习等进行非线性组合优化及融合。
本文构建了氨、碱处理后玉米秸秆粗蛋白含量的快速定量分析模型,发现基于SIPLS的特征优选方法可有效、快速地测定粗蛋白含量,模型精度及误差满足要求,该方法可为氨碱化秸秆处理提供重要的快速判定方法和检测手段。
猜你喜欢
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
航天返回与遥感(2022年2期)2022-05-12
数学小灵通(1-2年级)(2020年11期)2020-12-28
中国外汇(2019年13期)2019-10-10
小学生学习指导(低年级)(2019年3期)2019-04-22
电子制作(2018年2期)2018-04-18
制导与引信(2017年3期)2017-11-02
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
西藏科技(2015年4期)2015-09-26
读写算·小学低年级(2014年4期)2014-07-24
