
智能模糊决策树算法在英语机器翻译中的应用
2020-11-03 11:36:50陶媛媛
计算机测量与控制 2020年10期
陶媛媛,陶 丹
(1.西安交通大学 城市学院,西安 710000;2.西安市曲江第一中学,西安 710000)
0 引言
自然语言处理是计算机科学中一种从人类语言中获取和分析含义,并以智能的方式与人类进行交互的方法[1]。机器翻译主要涉及使用计算机软件将文本或语音形式的语言从一种自然语言翻译为另一种自然语言,同时保留其含义和解释。从一种自然语言到另一种语言的简单单词替换是机器翻译中使用的基本过程和方法之一[2]。由于对整个短语的识别和理解,并将其与最接近的短语进行匹配需要目标语言中的对应语言存在偏差,单独使用该方法可能会导致对原始文本的误导性解释。
在机器翻译中主要部分是“翻译过程”。这个过程可以简单地解释为对源文本的含义进行解码,然后将其重新编码为目标语言。显然,此过程需要复杂的算法才能成功,因为能够完全解码示例文本的含义意味着解释器必须能够分析文本的所有功能,这就需要深入了解源语言的语法结构、语义、习语、语法等等涉及语言学的诸多方面[3],亦不能忽略考虑源语言的文化背景。因此,正如同声传译员或者口译员需要具备大量语言学以外的知识,才能将词汇所表达的含义重新编码为目标语言,从而避免错误告知或歪曲源文本[4]。
机器翻译训练数据从来都不是完美的,双语句子对常常是错误的逐句排列,或者由于人为错误,这些句子对彼此的翻译不佳。通常,目标上下文被建模为SMT的语言模型。当前,主要重点工作是从单语上下文转换为双语上下文[5],例如,双语语言模型和操作序列模型基于最小翻译单位。通常,这些方法依赖于传统n-gram方法,由于数据稀疏,其缺点是窗口有限且语义表示效率低下[6]。为了加强上下文的语义表示,国内外许多专家学者使用神经网络来研究相关问题(双语语境表示的神经网络)。NN联合模型(NNJM),其编码使用前馈NN,以减少目标方的重复发生;因此,可以集成到翻译解码中[7]。尽管如此,由于基于窗口的前馈NN的性质,NNJM在捕获源侧上下文之间的长距离依赖项方面存在缺陷。
互联网是人们获取信息的重要来源,但是互联网上存在的很多错误的分级英语机器翻译模型极大地阻碍了这一发展过程,使人们无法有效地获取信息,更无法有效的翻译信息。因此,目前对于如何建立有效的分层的英语机器翻译模型已成为迫在眉睫的问题。在互联网上,大部分的英语机器翻译的模型主要以分层英语机器翻译的形式呈现[8]。仅当信息的语义是真实的情况下,相应英语的机器翻译才是分层英语机器翻译,反之亦然,英语机器翻译在语义上是不正确的。基于分层英语机器翻译的特征,肯定存在与任何否定分层英语机器翻译平行的确定分层英语机器翻译。此外,可以通过构造相应的准确的分级英语机器翻译模型来构建否定的分层英语机器翻译模型[9]。
本文提出了一种基于智能模糊决策算法的英语机器翻译模型(HEMTM)。通过搜索有关英语机器翻译的相关HEMTM模型来操作该模型;该模型在构建机器翻译的过程中,考虑了基于HEMTM与相应的英语机器翻译支持关系之间的差异。以期将该模型应用于具有多个答案的英语机器翻译的构建。
1 方法论
1.1 模糊决策树
决策树(DT,decision tree)是检索新的有趣知识的一种广泛使用方法。决策树代表了一种从标记实例中进行归纳的简单而强大的方法[10]。模糊决策树是模糊环境中决策树的推广。模糊决策树所代表的知识对于人类的思维方式来说更为自然。经典的清晰决策树广泛应用于模式识别,机器学习和数据挖掘。引入决策树来归纳分类模型,可通过沿着从根到叶的路径传播样本来对样本进行分类,该路径包含分类信息。
模糊决策树(FDT,fuzzy decision tree)是一种更通用的表示知识的方法[11]。该方法使我们能够在学习阶段(树的构造)或泛化阶段使用数字值和符号值来表示模糊模态。此外,Bouchon-Meunicr和Marsala等研究人员认为模糊决策树等效于一组模糊规则并且可以引入这种归纳规则来优化数据库的查询过程或从数据中推断决策[12]。
模糊决策树的目标是具有较高的可理解性,使模糊系统具有渐进和优美的行为。因此,使用模糊集和近似推理来扩展符号决策树,以进行树的构建和推理过程。同时,借用了丰富的现有决策树方法来处理不完整的知识,并扩展为利用模糊表示中可用的新信息[12]。
模糊集的概念由研究人员Zadeh于1965年通过隶属函数提出。为了度量模糊事件,Zadeh于1978年提出了可能性度量的概念。模糊熵是不确定性的一种度量。
特别地,当ζ是一个模糊集,取具有隶属度的值xi,i=1,2,...,n时,De Luca和Termini分别将其熵定义为如公式(1)所示:
(1)
当S(t)=-1lnt-(l-t)ln(l-t)时,很容易验证该函数S(t)关于t=0.5对称,严格按照间隔[0,0.5]增大,严格按照间隔[0.5,1]减小,并达到其唯一最大值在t=0.5时是ln2。
描述熵的不确定性主要是由于语言的模糊性而不是信息的缺乏而引起的,并且当模糊变量是一个可能的变量时其消失。然而,希望看到当模糊变量退化为清晰数时熵为0,而当模糊变量为等值时熵最大。
1.2 模型构建
分层英语机器翻译的模型(HEMTM)构建如图1所示。输入是分层英语机器翻译,输出是分层英语机器翻译模型构建的结果。

图1 分级英语机器翻译模型
机器翻译将相关的HEMTM与相应的分级机器翻译相结合,为相关的HEMTM和相应的分级英语机器翻译之间的支持关系的评估奠定了基础。HEMTM智能模糊决策树算法中的ri和fs是句子的机器翻译,sti和fs是集合机器翻译[13]。词之间的机器翻译为生成语义向量和词序向量奠定了基础。单词之间的机器翻译的公式如式(2)所示。公式(2)用于计算单词的机器翻译wi个和词w2。l和h分别代表w1和w2在词网中的最短距离,并且w1和w2两者都存在于该词网。单词之间的机器翻译可以以更好的方式,通过式(2)进行评价,此时α=0.2和β=0.45。
(2)
在公式(1)中,如果w1=w2,其相关性可以视为1;此外,因为设计的词网中的信息无法覆盖所有单词。因此,如果w1是个否则w2无法被词网覆盖,Sw(w1,w2)=0。
假设s1是句子sti从ri中选择的,并且s2是对应的ri、fs的分层英语机器翻译,接下来,将通过计算以下内容的机器翻译来演示机器翻译的过程s1和s2。
1.3 语义向量相关性
文献[14]通过用NN编码整个源句子来捕获长距离依赖。此外,他们都将整个源句子在不同的翻译时间步上表示为固定向量,而不是动态向量,这在机制中已显示出了应用前景。语义向量相关性的计算:通过生成相应的句子语义向量来计算语义向量的相关性句子s1和句子s2以及语义向量之间的余弦机器翻译的计算。假设结束词被分为s1和s2,相应的单词集分别是W1={w11,w12,...,w1n和W2={w21,w22,...,w2n}。假设W=W1∪W2,且W={w1,w2,...,wk},如果wi∈W1,那么vli=1。在公式(3)中,wi∈W。如果wiW,并且存在最匹配的单词wbm,那么当搜索时wi(目标词)来自句子s1,然后vli=Sw(wi,wbm)。否则,如果vli=0,将开始获取最佳匹配词的过程。
可以应用类似的计算以获得对应的语义向量s2,V2。s1和s2的语义向量相关性可以通过V1和V2的机器余弦转换来计算。详细的计算可以证明为式(3)所示:
(3)
1.4 词序向量相关性
文献[15]引入了一种神经概率语言模型,该模型在目标语言上下文词而不是离散词的分布式表示上顺序运行。将矫正的线性单位和噪声对比估计引入Bengio等人的神经概率语言模,并将其应用于大型词汇。词序向量相关性的计算方法:通过生成相应的句子的词序向量,并用式(4)来计算句子的词序向量相关性,然后计算词序向量的相关性。在式(4)中,O1和O2分别代表的词序向量s1和s2。s1生成的词序向量是O1={o11,o12,...o1k}。结果可以通过以下方式计算:1)wi∈W1,如果wi∈W1,o11的位置是在s1中的wi;2)wi∈W1,如果wiW1,搜索的最匹配词wi,wbm已经完成。如果存在wbm,o1i的位置是位于s1中的wbm,否则o1i=0。在找出词序向量的过程中,参数的最优值ζ在算法2中使用的是0.4。
(4)
1.5 智能模糊决策算法
用智能模糊决策算法计算,智能模糊决策算法s1和s2可以通过式(5)基于语义向量相关性和词序向量相关性来计算。如果s1是句子sti从中ri选择,并且s2是相应的英语机制翻译fs,在式(5)中,sti和fs可以分别代表s1和s2。在式(5)中,参数的最佳值θ是0.85。
(5)
上式第一个式子是ri对fs没有倾向趋势,第二个式子是代表有倾向趋势。ri是否倾向于fs是基于获取过程中是否存在否定的语法依存关系以及否定副词在ri中,例如hardly、rarely、few、seldom等。
2 实验分析
分层英语机器翻译模型构建的仍是当前研究热点。文献[16]使用相关语言之间的词形相似度或精确的上下文匹配来推断可能的翻译。文献[17]提出了在ConceptNet上的主题感知传播方法,以提高语言质量。不同的词在不同的主题下会有不同的情感。生成的主题感知情感词典提高了文本分类的性能。他们的系统预测了文本的极性以及文本中最可能的主题和概念的情感价值。文献[18]使用常识知识库来检测含义不清楚的单词。他们利用ConceptNet工具包确定单词替换,并计算了任意两个给定术语之间的概念相似度,并定义了平均平均概念相似度(MACS)度量标准来识别上下文外的术语。因此,本文采用的数据集是从TREC2007中收集的分级英语机器翻译数据集。可靠的分级英语机器翻译由30种,由真实语义唯一答案的分级英语机器翻译和20种从TREC2007中随机选择的多答案的真实语义的分级英语机器翻译组成[19-20]。为了进行对比分析,本实验建立了模糊算法模型(FQ)和基于模糊决策树的算法模型(HEMTM)。FQ模型是通过搜索与分层英语机器翻译未加入特征算法的模型。实验分析了在FQ和HEMTM两种模型构建下,机器翻译的有序分布。图2和图3分别显示了当HEMTM数量为150(n=150)时以FQ和HEMTM的模型构建方式,CBrank,CBGrank,CFrank和CFGrank的分布。横坐标代表信息收集中的HEMTM站点,纵坐标代表相应站点中HEMTM的机器翻译平均排名。
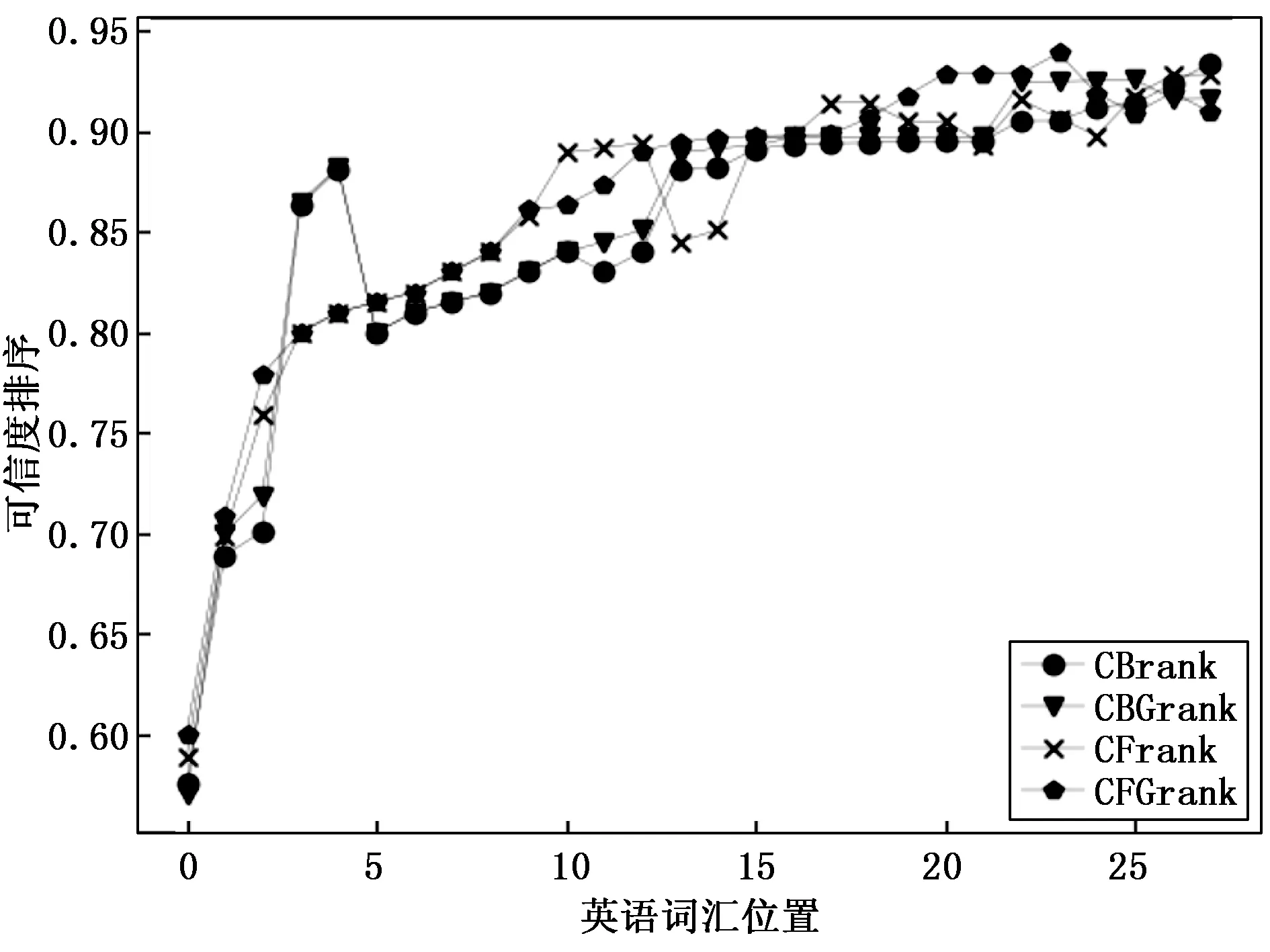
图2 FQ模型的机器翻译
从图2中可以看出,机器翻译的顺序与HEMTM所在的英语机器翻译信息集合的顺序没有明显的相关性。在HEMTM的集合中,HEMTM机器翻译排名并不总是比质量最高的英语机器翻译排名差。究其原因,与CBrank和CFrank相比,排名间隔在CBGrank和CFGrank,CBGrank和CFGrank显示具有较大的跨度。可以从图3进行推断,机器翻译的顺序符合图2趋势的HEMTM的翻译,而在FQ的模型下,HEMTM机器翻译的分布更加集中。
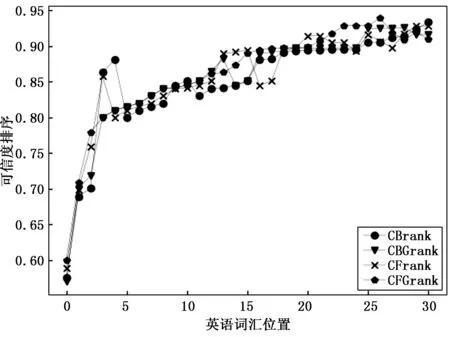
图3 HEMTM模型的机器翻译
从上述实验中可以得出以下结论,当机器翻译等级为CFGrank时,构建的模型基本具有较高的准确性。图5描述了构建模型准确度,当机器翻译选用为FG模型等级为CFGrank时,准确度是由n和δ的关系决定。从图4可以看出,当δ是确定的时候,随着n的值变大,精度将上升然后下降。原因是当n很小时,由于相关HEMTM的数量有限,因此分层英语机器翻译的某些部分无法正确构建;而当n较大时,对相应的分层英语机器翻译的贡献率将高于对相应的分层英语机器翻译的贡献率。因此导致最后的结果为降低模型构建的准确性。而当n是确定的时候,精度将随着δ的增加而上升,然后再下降。

图4 准确性趋势n=60(FQ)
与机器翻译的精度不同,从该图可以看出,当n>90时,精度随着n值的增加先上升然后下降。从图4和图5可以看出,当采用FQ的方式利用Alexa排名间隔的机器翻译时,可以获得较高的精度;而当对CFGrank进行机器翻译的排名时,可以获得更高的精度。
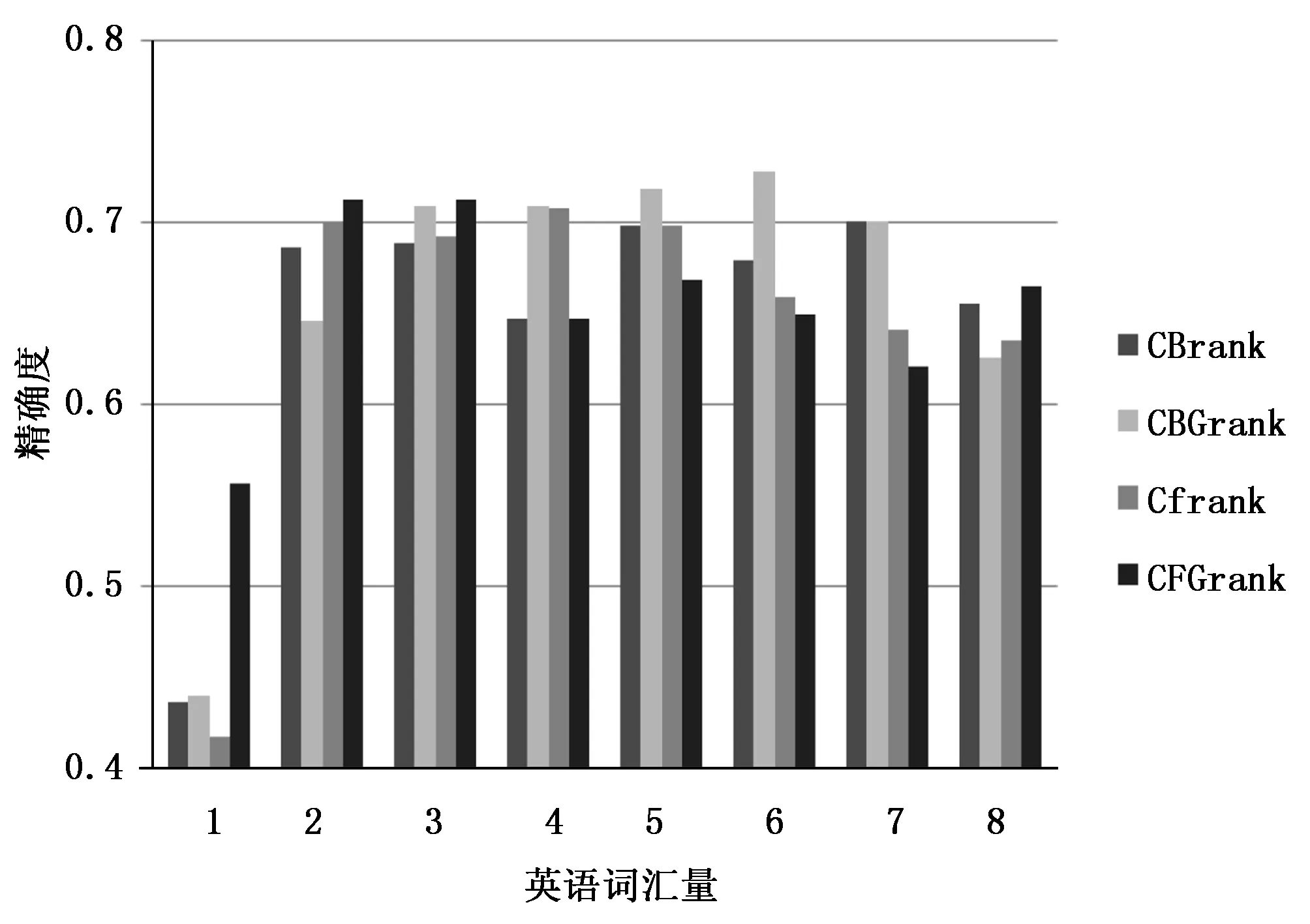
图5 准确性趋势δ=0.9(HEMTM)
结合图4、图5可以看出,4种相关HEMTM模型机器翻译等级影响其准确性的参数与FQ模型影响准确性参数相一致。但是,由于HEMTM模型捕获的语言信息量质量较差,因此准确性略低于FQ模型。采用HEMTM的CFGrank等级,在n=60,δ=0的情况下,基本模型构建的准确性为68%。
3 结束语
本文提出了一种基于智能模糊决策树算法HEMTM的分层英语机器翻译方法。通过捕获和分析相应的分层英语机器翻译中相关特征来实现模型构建。机器翻译的过程中,考虑了基于HEMTM与相应的英语机器翻译支持关系之间的差异。经实际验证,在n=60,δ=0时,模型准确率可达到68%。该模型可应用于具有多个答案的英语机器翻译。
猜你喜欢
开放教育研究(2020年2期)2020-03-31 01:54:14
孩子(2019年12期)2019-12-27 06:08:44
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
电子制作(2018年16期)2018-09-26 03:27:06
心理与行为研究(2016年4期)2016-12-16 10:36:46
北方文学·中旬(2016年6期)2016-08-01 12:04:30
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
现代语文(2016年21期)2016-05-25 13:13:44
江西教育C(2015年4期)2015-05-25 21:11:27
郑州大学学报(医学版)(2015年1期)2015-02-27 14:50:26
