
基于MFCC 特征提取的全新节能机器人设计与实现
2020-11-02 07:59江跃龙龚俭龙钟宇轩杨世杰黄震
现代计算机 2020年27期
江跃龙,龚俭龙,钟宇轩,杨世杰,黄震
(1.广州铁路职业技术学院,广州 510610;2.广东交通职业技术学院,广州 510650)
0 引言
人的自生以来的听觉系统是非常特殊的一个非线性系统,人类的耳朵能够响应不同频率信号[2]。因此,在语音特征提取方面,借助人类与生俱来的听觉系统,它不仅能够提取语义的信息,同时还可以提取说话人的特征,这些人类的特性在现有的语音识别系统所望洋兴叹。本文设计秉承“绿色环保、节能减排”与“深度学习人工智能”的设计理念,将以MFCC 特征提取技术与全新节能技术融入人工智能应用领域中。
1 系统设计思路与实现
本文将基于MFCC 特征提取的全新节能机器人进行了研究,并将面向服务的深度学习技术应用,其中构建了原始语音信号频谱和预加重后语音信号频谱分析和特征提取。本文实现的功能:基于MFCC 特征提取的智能语音识别交互控制的机器人与无线Wi-Fi 通信技术及红外控制技术相结合,实现与人进行交流对话、查询天气、查询时间、语音控制等功能。硬件模块由太阳能光伏供电模块、ARM 处理器主控模块、无线Wi-Fi通信模块、LCD 显示模块、检测室内环境传感器模块、MIC 输入模块、语音处理模块以及人工智能处理模块等组成,其系统总体设计框图如图1所示。
2 语音信号提取预处理
全新节能机器人在复杂的应用环境下,作为语音类应用的前端接口,语音信号预处理显得尤为重要,其可以细分出处理噪声干扰的语音增强和处理人声干扰的语音分离[1]。语音在实际的传输过程中,环境噪声和人的声音干扰都会对全新节能机器人语音识别产生一定的影响,使得语音的质量和可懂性能大大地下降,同时也给后续全新节能机器人语音识别方面的应用带来挑战,例如语音识别、说话人的语音识别等。

图1 系统总体设计框图
2.1 语音输入
利用麦克风阵列的语音输入设备进行语音原始未经处理信号进行录制。由本人录音,在无噪音环境下录制“小云”语音为实验的对象,经过格式转换后,实验语音数据分别命名为xiaoyun.wav。该关键词的“小云”语音信号是在较为安静的环境下录制而成的。在釆集的该语音输入信号过程当中,将会直接消除或减少语音输入时间序列数据受偶然性因素干扰而产生不规则样本或说话人自己造成的不规则样本。
2.2 语音预处理
预处理的常用方法有预加重、端点检测、分帧、声道转换、去加重、加窗、重采样等,不同的语音识别在预处理方法和处理顺序上有一定差别。在进行关键词“小云”语音信号特征提取之前,都要对原始序列做一系列的预处理,目的是尽可能保证后续语音处理得到的信号更均匀、平滑,为信号参数提取提供优质的参数,提高语音处理质量,同时,消除采集语音信号的设备所带来的混叠、高次谐波失真、高频等因素,以免对关键词的“小云”语音信号质量的影响。
2.3 语音信号预加重
语音信号预加重(Pre-emphasis)是一种将低频段关键词“小云”语音信号能量放大,在高频段的信号能量变小。因此,在传输之前把关键词“小云”语音信号的高频部分进行处理(如加重处理),然后接收端再去重处理,以此来提高信号的传输质量,要在对关键词“小云”语音信号进行分析之前对其高频部分加以提升,以便于关键词“小云”信号的频谱分析或者声道参数分析。
设关键词“小云”语音信号t 时刻的语音采样为S(t),经预加重处理后结果为 Y(t)=S(t)-μ*S(t-1),其中μ根据经验值取μ取值为0.97。通常设置一阶数字滤波器:

上式中,μ值=预加重系数,其范围为:0.9<μ<1.0。
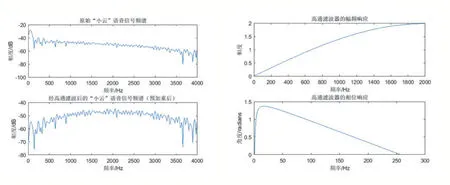
图2 原始小云语音信号频谱及预加重后频谱
2.4 语音分帧与加窗
语音处理过程需要我们理解语音信号各个频率成分具体分布情况,这时就需要利用傅里叶变换分析频率成分。傅里叶变换要求输入语音信号是平稳的,在宏观上来看语音信号是不平稳的,从微观上来看,语音信号在非常短时间内可以看作是具有平稳的。由此可见,从宏观角度来看语音信号的特性和表征,它的本质特征和相关参数都是随时间而变化的,所以语音信号是一个不平稳态的信号,不能用处理数字信号处理技术(如傅里叶变换)的对其进行平稳信号分析处理。但是,微观角度来看,虽然语音信号具有时变特性,但是在一个非常短的时间(在10~30ms 时间内)范围内,语音信号特性和参数基本保持不变,即语音信号保持相对稳定的状态,所以我们可将语音信号看作其具有短时间内平稳性准稳态过程。

图3 语音分帧

图4 汉明窗(hamming window)
将语音信号分帧处理(如图3 所示)后,我们将每一帧代入汉明窗(hamming window)窗函数如图4 所示,窗外的值通常设为0,是为了消除每一个帧的两端信号可能会造成的频谱泄露spectral leakage(即不连续性)现象。理论上窗函数越宽,产生的平滑效果就会越好,同时也会使窗函数的坡度不断增大,导致频谱泄露现象比较严重,截断效应也会很严重。所以综合分析与考虑,我们将汉明窗的主瓣设为较宽而旁瓣设为较低,对语音信号处理的平滑效果更明显,根据窗函数的频域特性,汉明窗的主瓣比较宽而旁瓣比较低,对处理语音信号的平滑性效果比较好。常采用汉明窗,公式如下:

2.5 语音信号的特征提取
梅尔(Mel)频率分析是基于人类的听觉感知系统实验的,经实验观测发现人的听觉系统对不同的频率是有一定地选择性的,人耳类似一个滤波器组一样,它只关注个别特殊频率的分量。换句话说,它只让某些特定的频率信号通过,同时可以对不想感知的频率信号过滤掉。这些滤波器在频率的坐标轴上不是成统一分布,在低频信号区域有很多的滤波器,它们分布较为密集,而在高频区域,滤波器的个数就变得较少,分布也较为稀疏。若我们利用语音处理技术在语音识别系统中能够模拟类似人类的听觉感知,那么就极有可能提高和改善语音识别率。
通常语音信号的特征参数MFCC 提取过程,具体如图5 所示步骤。

图5 MFCC提取流程图

图6 Mel滤波器组
由于人耳对应外界不同频率的敏感程度是不同的,而且成为一种非线性关系,为此将语音信号频谱按人耳敏感程度划分多个梅尔(Mel)滤波器组如图6 所示,在梅尔(Mel)刻度范围内将各个滤波器的中心频率f(m)等间隔的线性分布和频率范围形成非相等间隔,然后将线性分布的频谱映射到类似人的听觉感知梅尔(Mel)非线性频谱中,最后转换到梅尔(Mel)倒谱上。将普通频率转化到梅尔(Mel)频率的公式如下:
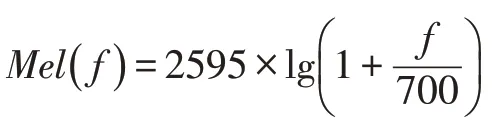
上式中f 为频率,Mel(f)为梅尔(Mel)频率,单位为Hz。
将该信号的能量谱通过一组Mel 三角形滤波器组(Mel-Filter banks),定义一个用 24 个滤波器(0-4000Hz)总点数,每个滤波在中心频率f(m)的响应都是1,然后左右两边线性下降到相邻的三角形滤波器的中心频率f(m)处为0,如图6 所示。
3 语音识别实验与分析
本文实验是在基于MATLAB 2017b 软件平台,语音样本由作者规定为普通话“小云”录音组成,并在安静环境内完成的。选用Windows 10 自带录音软件进行录制,CompressionMethod:'Uncompressed',NumChannels: 2,SampleRate: 48000,TotalSamples: 354304,Duration: 7.3813,BitsPerSample: 16 保存文件为 xiaoyun.wav格式。音频数据x=xiaoyun.wav,采样率fs=8000Hz,采用端点检测,最后提取MFCC 特征参数,实验输出数据:(N=分帧个数,M=特征维度)大小的特征参数矩阵,特征参数为M=24 倒谱系数为12 维,一阶差分为12维。通过实现分帧、加窗、快速傅里叶变换(FFT)、梅尔滤波器组(Mel-bank)、离散余弦变换(DCT)等过程来计算得到语音信号MFCC 特征提取如7 图所示。

图7 MFCC特征提取
4 结语
本文梅尔频率倒谱系数(MFCC)方法应用于全新节能机器人设计与实现进行了研究与实验,并将面向服务的深度学习技术应用。在梅尔滤波(Mel filter)实验过程中,对原始小云语音信号时域波形、语谱图绘制,然后对该信号进行预加重,并分析其分帧的语音信号在短时间(通常10-30ms)内具有平稳性。通过录入小云语音信号进行实验加入短时能量特征,并引入梅尔频率倒谱系数(MFCC)的一阶差分和二阶差分,对语音数据特征提取和降低运算维度感知敏感度,从而提高了特征提取的有效性。在此基础上,能够更好地反映全新节能机器人在复杂环境下,它能够较好地表述语音信号特征并且能准确提取语音信号特征,为后期语音匹配时对输入语音的采集及识别做出一定积累经验。
猜你喜欢
客联(2022年4期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
莫愁(2020年7期)2020-03-17
红领巾·探索(2019年2期)2019-04-19
红领巾·萌芽(2019年3期)2019-04-18
畅谈(2018年17期)2018-10-28
幼儿教育·父母孩子版(2018年4期)2018-09-13
智能计算机与应用(2016年1期)2016-03-02
阅读(2014年11期)2014-11-07
家教世界·创新阅读(2013年1期)2013-03-25
