
基于Bi-LSTM 神经网络的人类行为识别研究
2020-11-02 07:59詹秀菊陈凤
现代计算机 2020年27期
詹秀菊,陈凤
(广州中医药大学医学信息工程学院,广州 510006)
0 引言
人类行为识别研究是利用大量外界采集的有效数据,对行为动作的类型进行训练和识别分析,这是目前机器检测人类行为动作的主要方法,这种方法被广泛应用于医疗服务、智能环境和网络空间安全等领域[1]。在人类行为识别领域中,目前有学者[2-4]利用神经网络模型的构建对人类行为进行识别研究并取得较好的研究成果,本文基于Bi-LSTM 神经网络的识别方法,构建Bi-LSTM 神经网络模型以识别人类行为动作。
1 数据预处理
本文从UCI 公开数据集采集用户动作的自然数据(走、上楼、下楼、站、坐和躺),并将收集的数据进行分类并填写标签,实验随机将7767 个样本作为训练数据,3162 个样本作为测试数据,见图1 所示。LSTM 输入的数据需要3 维,分别是batch 批量、时间步长和特征数,因此要对数据进行维度扩张处理,将数据由(7767,561)转换成(7767,561,1)。对于一维数据的标签而言,模型的返回为每个类别的概率,即每个样本需要返回13 个类别的概率,因此需要对类别进行独热编码,由(7767,)转换为(7767,13),独热编码的数据处理见图1 所示。
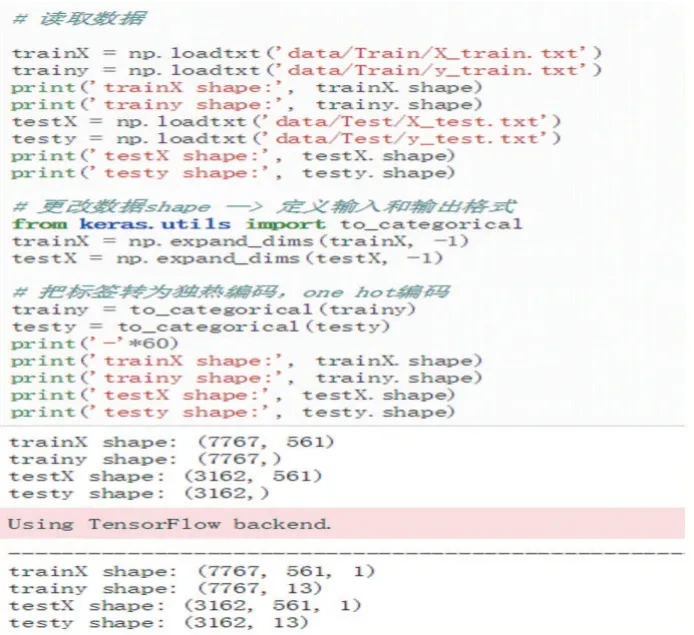
图1 数据独热编码
2 Bi-LSTM神经网络模型结构设计
本实验的Bi-LSTM 神经网络模型结构设计简单,主要由三个Conv1D(一维卷积)叠加后接入Bi-LSTM,最后连接全连接函数构成。
(1)第一层Conv1D,设置卷积核为3,通道数为8,激活函数为Relu;接入MaxPooling 最大池化层的池化核为2 且步长为2。
(2)第二层Conv1D,设置卷积核为3,通道数为16,激活函数为Relu;接入MaxPooling 最大池化层的池化核为2 且步长为2。
(3)第三层Conv1D,设置卷积核为3,通道数为32,激活函数为Relu;接入MaxPooling 最大池化层的池化核为2 且步长为2。
(4)第四层接入Bi-LSTM,隐含层单元数为32。
最后连接全连接函数,输出单元数为13,并用Softmax 函数进行分类。
3 Bi-LSTM神经网络模型构建
Bi-LSTM 神经网络模型的构建主要包括参数设置、模型定义、模型初始化、模型训练和模型测试等。
(1)参数设置
构建Bi-LSTM 神经网络模型时采用Adam 作为模型优化器,学习率为0.01,损失函数为交叉熵损失函数,评价指标采用正确率Accuracy。并设置训练集的数据为 7767 个样本,进行 1800 次迭代,完成 30 个 Epoch,每个Epoch 完成60 个 Batch,每个Batch 大小为128。
(2)模型定义
Bi-LSTM 神经网络模型结构设计和参数设置完毕之后,可在TensorFlow 深度学习平台中对模型进行定义,模型定义核心代码如图2 所示。

图2 模型定义代码
(3)模型初始化
定义好模型每一层的所有参数、优化器和Softmax分类函数之后,可进行模型初始化,初始化核心代码如图3 所示。

图3 模型初始化代码
模型初始化后,就可以进行模型训练和测试。因dropout 的比例对模型性能的影响较大,模型训练时发现当dropout 取值为0.2 时,模型准确率是最高的,因此本实验选取0.2 的比例作为Bi-LSTM 模型的dropout取值。
4 实验结果与分析
表 1 是 dropout 取值为 0.2 时 Bi-LSTM 的全部实验结果,表格中训练次数为30 次,从表中可以观察到,训练次数每增加一次,训练集的损失值不断降低,训练集的正确率不断提高;同时,测试集的损失值也不断降低,正确率也不断提高。

表1 Bi-LSTM 神经网络训练和测试结果
经过测试集测试后,可以从TensorFlow 深度学习平台中获取Bi-LSTM 神经网络的混淆矩阵,如表2 所示。

表2 Bi-LSTM 神经网络测试集混淆矩阵结果
备注:WK(走)、WU(上楼)、WD(下楼)、SD(站)、ST(坐)和LY(躺)
根据实验结果发现,对于动态的动作(走、上楼和下楼)的识别率较高,但是对于静态的动作(站、坐和躺)识别率相对较低。从实验结果可知,Bi-LSTM 神经网络模型对人类行为姿势的识别准确率为88.80%,结果表明Bi-LSTM 神经网络模型的识别率较高,可用于人类行为动作的识别。
用户行为识别是近年来的研究热点,当前的人类行为识别技术还有很多需要改进和完善的地方。随着技术的进步和研究者们进一步挖掘,会有更多的算法和分类模型提出,这也将为以后的分类识别提供更先进的技术,能够更好地提升识别效果。
猜你喜欢
农业工程学报(2022年12期)2022-09-09
舰船科学技术(2022年11期)2022-07-15
煤气与热力(2022年2期)2022-03-09
北京航空航天大学学报(2021年4期)2021-11-24
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
科学大观园(2019年10期)2019-09-10
证券市场周刊(2019年19期)2019-05-27
中国经济周刊(2019年9期)2019-05-24
