
基于动态规划与机器学习的插电式混合动力汽车能量管理算法研究*
2020-10-26 07:27:40陈渠殷承良张建龙秦文刚
汽车技术 2020年10期
陈渠 殷承良 张建龙 秦文刚
(1.上海交通大学,汽车电子控制技术国家工程实验室,上海 200240;2.联合汽车电子有限公司,上海 201206)
主题词:插电式混合动力汽车 能量管理算法 动态规划 K-均值聚类 BP神经网络
1 前言
插电式混合动力汽车(Plug-in Hybrid Electric Vehicle,PHEV)的能量管理算法通常分为3 类,即基于规则的、基于优化理论的和基于工况自适应的能量管理策略[1]。基于规则的能量管理算法通常根据特定的规则分配发动机和电机的扭矩,从而达到节能的目的[2]。基于优化的能量管理算法可以分为瞬时优化和全局优化两种。等效燃油消耗最小策略(Equivalent Fuel Consumption Minimization Strategy,ECMS)是目前混合动力汽车上应用最广泛的瞬时优化策略[3],通过等效系数将电量平衡所需能量转换为燃油消耗量,当等效系数选择合适时,ECMS 作为次优解,可以获得接近全局最优解的控制效果[4]。基于全局优化的能量管理策略,如动态规划(Dynamic Programming,DP)算法,虽然可以获得全局最优解,但需预知行驶工况信息,且计算时间长,难以用于实车控制[5]。
基于工况自适应的能量管理策略通过已有的工况信息进行数据分析整理,进而对未来的行驶工况进行预测,根据预测的工况信息调整能量管理策略中的相关参数进而实现PHEV根据工况变化的自适应控制[6]。随着人工智能的快速发展,越来越多的学者将机器学习应用到工况识别和整车能量分配上。文献[7]应用学习向量量化(Learning Vector Quantization,LVQ)神经网络进行工况预测,根据不同的预测结果应用不同类型的能量管理策略。文献[8]建立了马尔科夫模型预测驾驶员行为,结合ECMS 调整等效燃油系数,实现功率的自适应分配。文献[9]在统计若干城市循环工况数据的基础上建立需求功率的马尔科夫预测模型,对预测的结果应用动态规划算法,获取发动机和电机之间的功率优化分配。
基于对上述PHEV能量管理算法的探讨,本文提出基于动态规划与机器学习(Dynamic Programming and Machine Learning,DPML)的PHEV能量管理算法。首先选择能够代表各种工况类型的20 个标准工况,分别将其划分为时长150 s 的工况段,以平均速度和巡航时间比为特征参数,采用K-均值聚类算法将其划分为3 个类型,然后利用动态规划算法对20 个标准工况进行仿真计算,得到不同类型工况的最优功率分配方式,分别对每种工况段类型训练相应的神经网络模型。最后针对某随机工况提取特征参数,进行工况识别,根据当前所属的工况段类型选择相应的神经网络模型进行功率分配,验证本文算法的有效性。
2 PHEV整车模型
2.1 整车及动力系统模型
本文采用的P2构型PHEV 整车结构如图1所示[10],发动机和电机模型均采用查表方式进行建模,整车和动力系统模型参数见文献[11]。
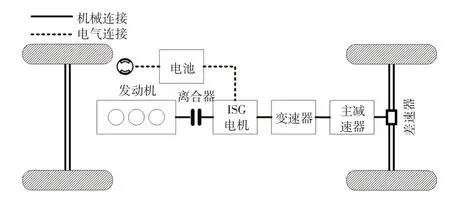
图1 PHEV动力传动系统结构
不考虑车辆的振动和操纵稳定性时,车辆的纵向动力学表达式为:
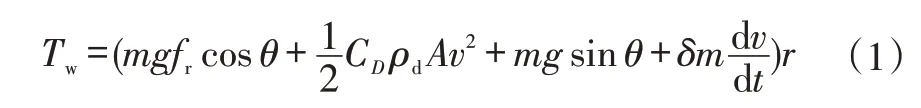
式中,Tw为需求扭矩;m为整车质量;g为重力加速度;fr为滚动阻力系数;θ为坡道角度;CD为空气阻力系数;ρd为空气密度;A为迎风面积;v为车速;δ为旋转质量换算系数;t为时间;r为车轮滚动半径。发动机和电机的扭矩和转速关系为:
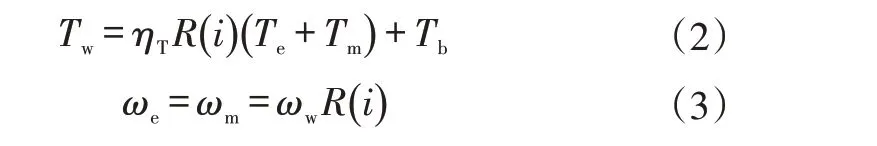
式中,ηT为变速器与驱动桥的总传动效率;R(i)为变速器第i挡速比与主减速比的乘积;Te为发动机输出扭矩;Tm为电机输出扭矩;Tb为摩擦制动器的制动扭矩;ωw为车轮转速;ωe为发动机转速;ωm为电机转速。
2.2 电池模型
SOC是整车能量管理的重要变量,直接影响需求扭矩在发动机和电机之间的分配。本文将动力电池简化为等效电路模型,可得:
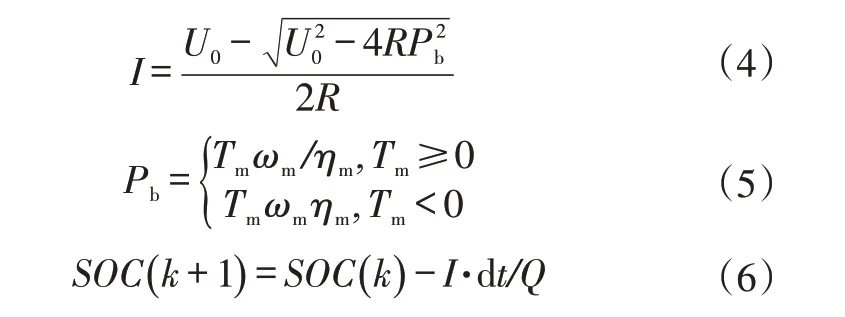
式中,I为电池电流;U0为电池开路电压;R为电池内阻;Pb为电池充、放电功率;ηm为电池充、放电效率;Q为电池容量;SOC(k)为k时刻荷电状态。
当电机输出扭矩Tm≥0 时,电池处于放电状态,当Tm<0 时,电池处于充电状态。
3 能量管理算法
首先将标准工况划分成等长的工况段,利用K-均值聚类算法将工况段划分成不同的聚类中心;然后利用动态规划算法求解不同标准工况的最优控制规律;最后,针对不同类型的工况段,利用神经网络模型离线探索其能量管理最优控制规律,进而提出基于动态规划与机器学习的PHEV能量管理算法。
3.1 K-均值聚类算法工况识别
车辆在行驶过程中从某时刻开始,经过时间tl后到达下一时刻,2个时刻之间的运动过程作为一个数据单元,这种运动学片段称为工况段。工况识别是实时归纳过去tp(识别周期)时间内的车速变化规律,预测未来tq(预测周期)时间内的行驶趋势变化,当识别周期为150 s,预测周期为3 s 时,识别结果的精度较高[12],所以本文设tp=150 s,tq=3 s。
工况特征参数的作用是进行工况识别,目前工况特征参数约有62种,参照文献[8],选取平均速度和巡航时间比为本文的特征参数:
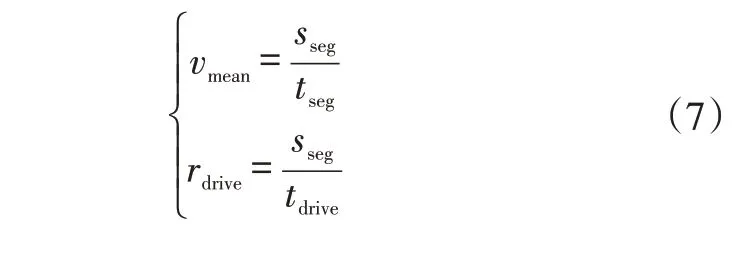
式中,vmean为工况段的平均速度;sseg为工况段的总路程;tseg为工况段的总时间,本文取150 s;rdrive为工况段的巡航时间比;tdrive为工况段的巡航时间。
本文从ADVISOR 车辆仿真软件中选取20 个标准工况进行K-均值聚类分析,标准工况包括:WLTC、NEDC、UDDS、HWFET、LA92、NYCC、US06、UNIF01、SC03、REP05、OCC、NurembergR36、MANHATTAN、INRETS、INDIA_HWY、INDIA_HWY、IM240、HL07、HHDDT65、ARB02。
将以上20个标准工况划分为时长150 s的216个工况段,利用K-均值聚类分析,得到最终的聚类中心,结果如图2所示。图2中工况段数据划分为3个簇,簇1代表拥堵工况,簇2代表缓行工况,簇3代表高速工况,最终的聚类中心分别为(14.01,71.73%)、(34.47,83.38%)、(66.40,97.37)。其中拥堵工况88个样本,缓行工况63个样本,畅通工况65 个样本,各类型工况分布平均,说明以上20个标准工况的选取较为合理。
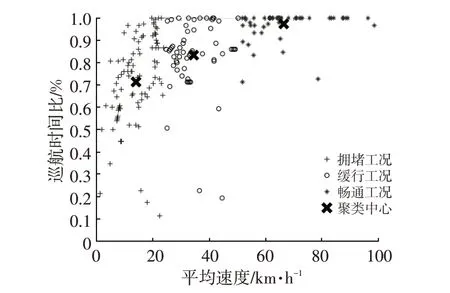
图2 标准工况段的聚类分析结果
K-均值聚类算法工况识别的思路是:提取当前时刻前的识别周期内工况的特征参数,将提取的特征参数作为一个数组,计算出该数组与各最终聚类中心的欧氏距离,与数组距离最近的聚类中心为该数组所属的簇,当前时刻所属的工况为此簇所代表的工况类别。
3.2 动态规划算法
3.2.1 原理
动态规划算法求解需要2 个过程:第1 个过程逆向进行,利用递归方程从最后一个阶段开始,求得各阶段每个状态的最优性能指标和最优控制变量参数;第2个过程为正向递推过程,进行最优控制序列和最优轨迹的复原,从给定的初始状态找到对应的最优控制,并根据系统状态转移方程求得下一时刻的状态,得到对应的最优控制。
定义系统的状态变量x(k)和控制变量u(k)为:
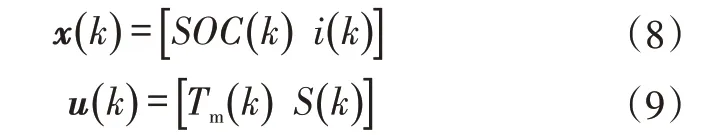
式中,S(k)为系统k阶段的换挡信号。
系统的状态转移函数为式(6)和式(10):
本文所研究的全局最优控制策略以燃油消耗量最小为目标,不考虑排放问题,因此定义k阶段的燃油消耗量代价函数L(x(k),u(k))为:
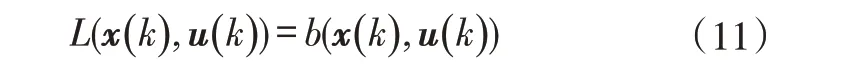
式中,b(x(k),u(k))为k阶段车辆的燃油消耗率,可以由发动机的输出扭矩Te(k)和转速ωe(k)查表获得。
k阶段目标函数Jk,N定义为第k~N阶段的代价函数之和:
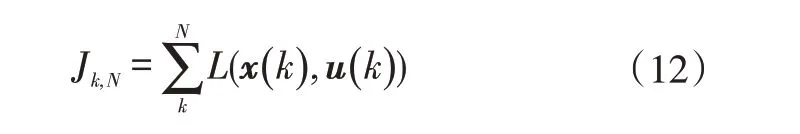
所以最优目标函数的动态递归方程为:
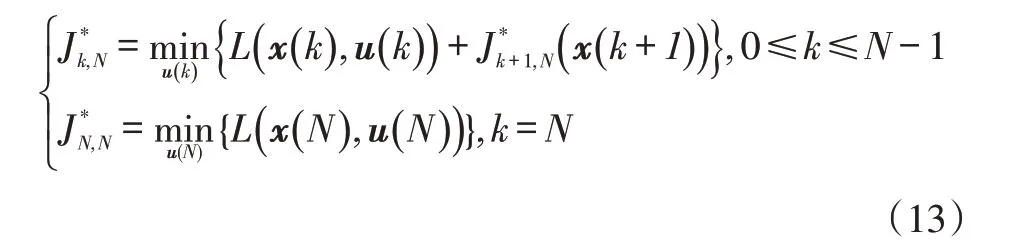
3.2.2 计算可行域
由于DP 程序由多层循环嵌套,根据所选工况的不同及状态变量和控制变量离散化程度不同,其计算时间可达十几甚至几十小时。参照文献[13]和文献[14]的方法,求解整个循环工况下SOC的可行域,预先去除不可行的SOC离散点,从而减少计算时间。
3.2.3 计算结果
PHEV 的SOC初始值可以是0~1 内的任意值。所以针对以上20 个标准工况,利用动态规划算法分别求解10 组不同SOC初始值(0.1、0.2、0.3、0.4、0.5、0.6、0.7、0.8、0.9、1.0)的最优功率分配,在较好地覆盖PHEV 动力电池在车辆实际行驶中的情况的同时可以增加神经网络模型的训练数据量。动态规划求解的WLTC 标准工况初始SOC为0.6 时的状态变量和控制变量结果如图3所示。
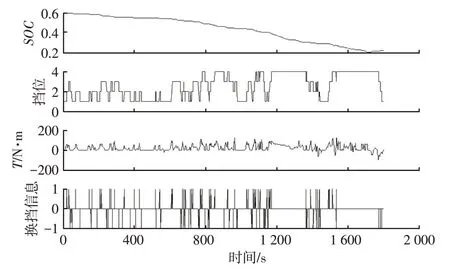
图3 WLTC工况动态规划计算结果
3.3 神经网络模型
在特定循环工况下,动态规划算法的最优控制变量与状态变量之间存在确定的非线性关系。本文采用BP神经网络对动态规划算法计算出的不同类型工况段的最优控制律与状态变量之间的非线性关系进行解析,分别得到3个适应不同类型工况段的神经网络模型。
采用前文动态规划方法求解PHEV 在各工况下最优控制问题,独立的状态变量有电池SOC和变速器挡位,独立的控制变量有电机扭矩信息和换挡信息。假设车辆的行驶速度能完全跟踪给定的循环工况速度轨迹,即车速、需求转矩在每个时刻均为已知量,发动机和电机转速信息可以根据式(3)确定,发动机扭矩信息可以由式(2)确定。因此,本文建立的BP神经网络的输入量为当前时刻和前一时刻的车速、驾驶员需求转矩、电池SOC和挡位信息,其输出变量为当前时刻驱动电机的扭矩和换挡信息,模型如图4所示。
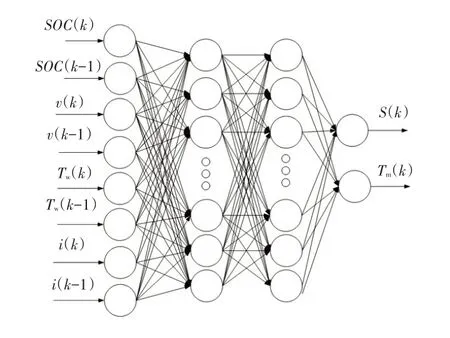
图4 BP神经网络模型
本文以拥堵类型的工况段为例说明神经网络的训练过程。拥堵类型的工况段数量为88 个,针对每个标准工况,前文利用动态规划算法均求解了10 组不同SOC初始值的最优功率分配,即每个标准工况下的工况段均有10组计算结果,而每个工况段时长为150 s,所以每个工况段均有150 个最优状态点,则共有132 000 个样本点,其他类型的数据量如表1所示。
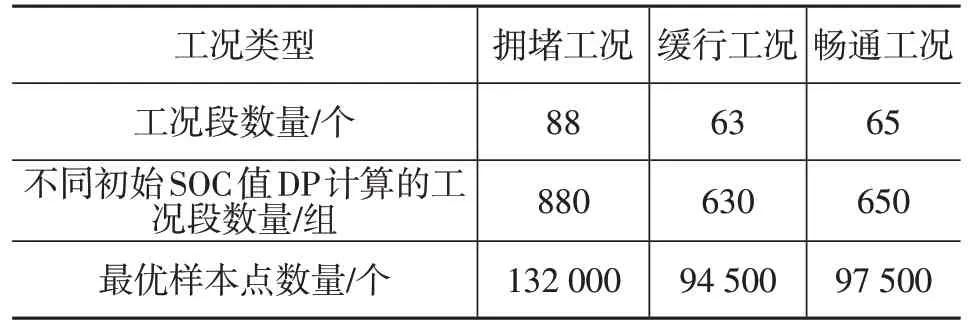
表1 神经网络训练数据量
随机分配70%的样本数据作为训练数据,另15%的样本数据作为验证数据,剩余的15%作为测试数据。参考文献[15],建立隐含层层数为2的神经网络,第1隐层的节点数量为20个,第2隐层的节点数量确定为10个,训练算法采用Lervenberg-Marquardt,用均方误差测量训练性能。网络的训练误差曲线如图5 所示,经过102次训练迭代后,验证误差为0.007 857 8,表明此时的网络输出较为精确。最后,将训练完成的神经网络进行封装,生成MATLAB 神经网络模型自定义函数。至此,拥堵工况段类型的神经网络模型构建完成。
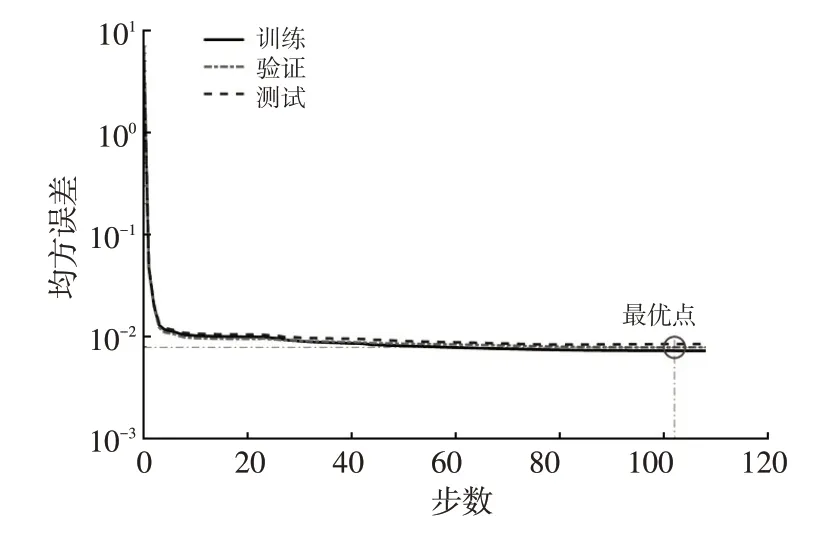
图5 神经网络的训练误差
4 仿真分析
4.1 控制策略流程
基于动态规划与机器学习的PHEV 能量管理算法控制流程如图6 所示。该算法将动态规划与机器学习算法相结合,具体分为4个步骤,其中前3个步骤为离线运算,第4步为实时运算:
a.将20 组标准工况段划分为时长150 s 的工况段,提取特征参数,利用K-均值聚类算法对工况段进行聚类分析,得到聚类中心;
b.利用动态规划算法得到20 组标准工况的最优功率分配方案;
c.将得到的最优功率分配方案根据每个工况段所属的类型进行划分,得到不同类型工况的最优功率分配方案,并分别训练神经网络模型;
d.针对某段随机工况,提取特征参数,利用K-均值聚类算法进行工况识别,根据当前所属工况段类型选择相应的神经网络模型进行功率的优化分配,提高PHEV的燃油经济性。
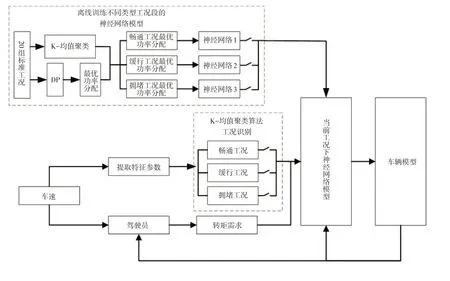
图6 控制策略流程
4.2 仿真结果分析
利用MATLAB/Simulink搭建整车仿真模型,评估和验证本文提出的能量管理算法。采用上海市某段随机工况进行控制策略的验证,该工况如图7 所示。采用K-均值聚类算法的工况识别结果如图8所示,可知该随机工况较均匀地包含了3种类型的工况段。
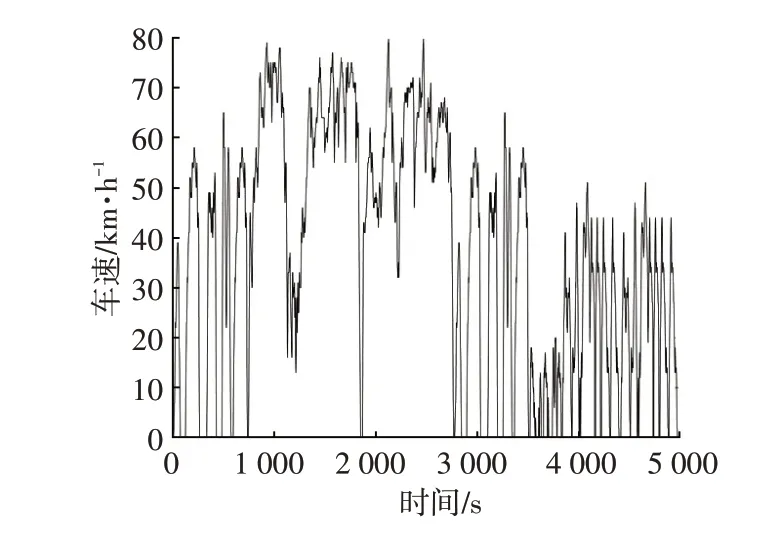
图7 随机工况
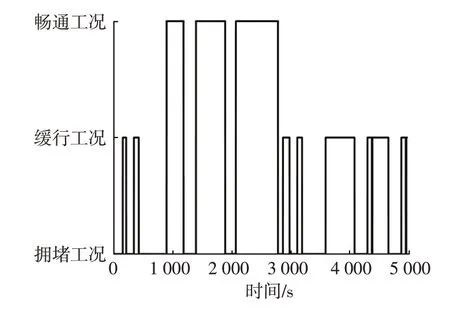
图8 工况识别结果
表2 对比了CD-CS、DPML 和DP 算法在不同初始SOC值而终点SOC≈0.2 时的燃油消耗量,由表2 可知,相较于CD-CS 策略,DPML 和DP 算法的优化效果呈现先上升再下降的趋势,因为在终点SOC值不变的情况下,当初始SOC值较大,满足纯电动行驶时,全程不起动发动机,DPML与DP算法的优化效果不明显,而当初始SOC值较小,接近终点SOC值时,发动机需要全程起动,DPML与DP算法的优化效果也不明显。当初始SOC值为0.7 时,基于DPML 的能量管理算法燃油消耗量为1.385 8 L/(100 km),与CD-CS 策略相比,下降了7.51%,具有明显的优化效果,虽相较于DP 算法的优化效果下降了0.97%,但其克服了DP 算法需要提前获取实车路谱和不满足实时性要求的缺点。
图9 所示为发动机工作点分布情况,基于DPML 的能量管理算法得到的发动机工作点大多分布在最佳效率曲线附近,以达到提高整车燃油经济性的目的。图10~图12分别为3种算法计算得到的发动机扭矩、电机扭矩和电池SOC随时间的变化曲线。CD-CS 策略先进行纯电动行驶,进入电量消耗模式,SOC减小到临界值后起动发动机,进入电量维持模式,所以SOC曲线呈现先下降再维持的趋势,整车燃油经济性较差。DP 算法利用递归方程可以求得全程每个状态点的最优控制量,在最优的时间起动发动机,其最优SOC曲线呈现全程缓慢下降的趋势。DPML算法以DP算法的最优功率分配数据分别训练3个类型工况段的神经网络模型,在控制过程中基于K-均值聚类算法选择适当的神经网络模型,在随机工况下控制规律与DP算法相似,即提前起动发动机,SOC曲线呈现全程缓慢下降的趋势,从而可以接近DP全局最优解。
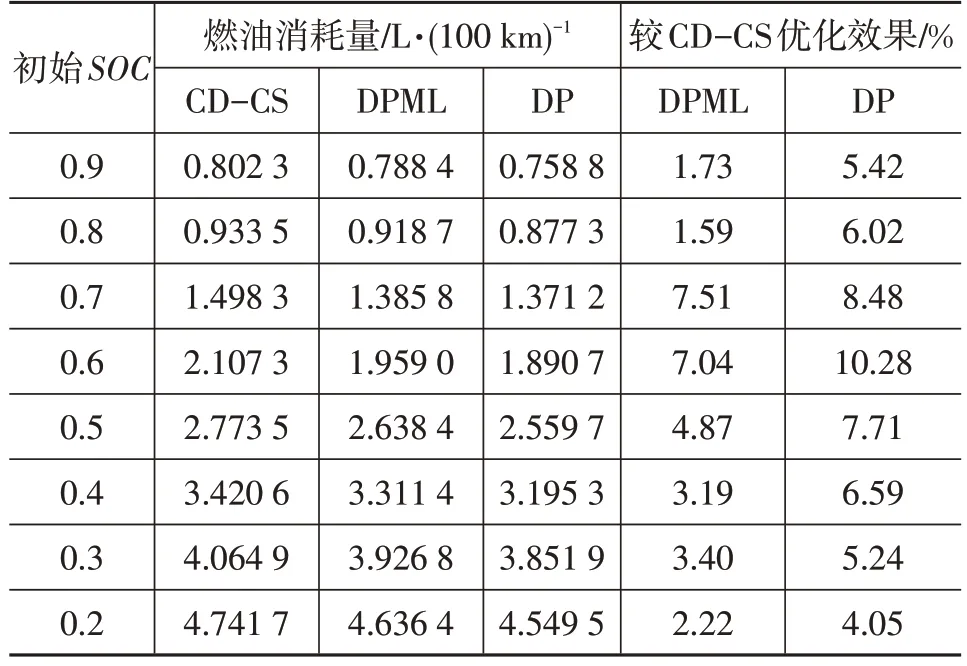
表2 不同策略下燃油消耗量对比
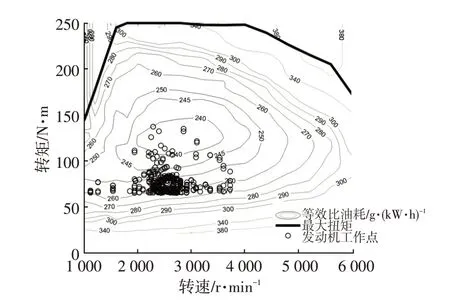
图9 发动机工作点
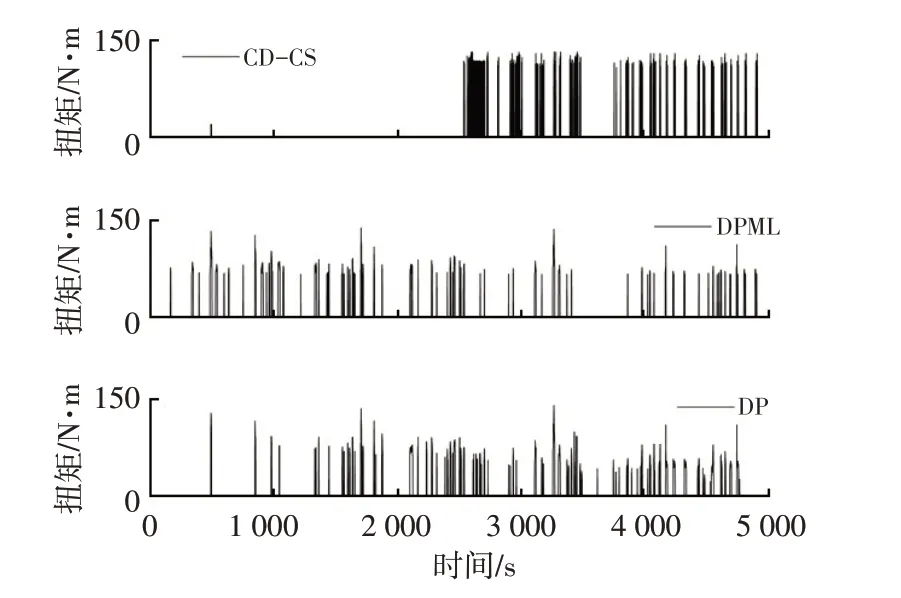
图10 发动机扭矩对比
根据动态规划算法计算得到的20 组标准工况结果,按照不同的工况类型,统计发动机起动时间与该工况类型总时间的比值如图13所示,由图13可以看出,拥堵工况、缓行工况和畅通工况下该比值依次增大,说明在动态规划控制策略下,发动机更倾向于在拥堵工况下关闭,在畅通工况下运行,从而确保了发动机运行在高效区域,提高燃油经济性。
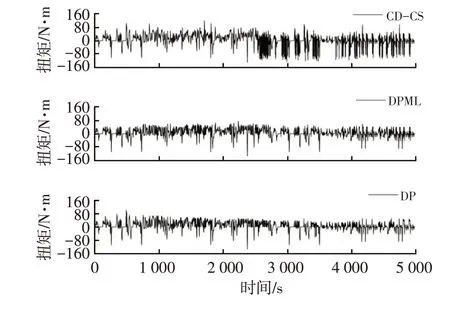
图11 电机扭矩对比
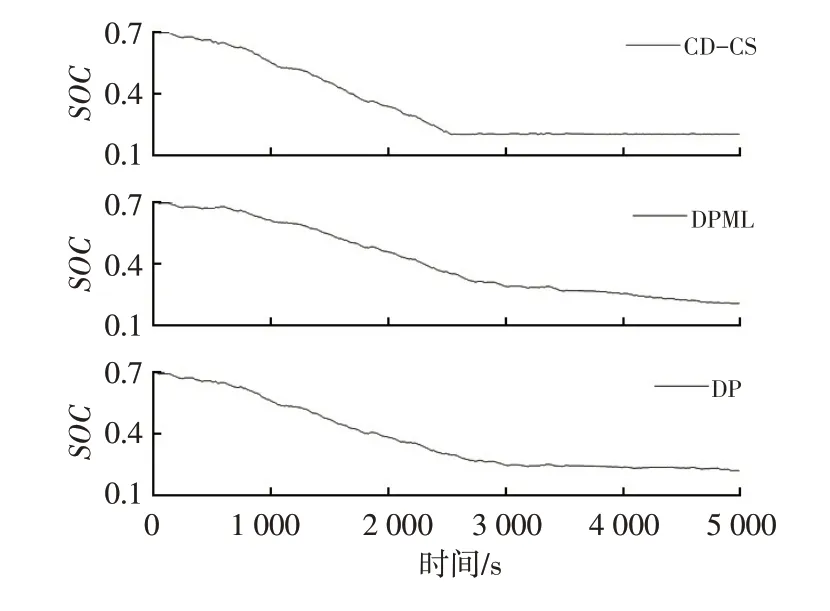
图12 SOC曲线对比
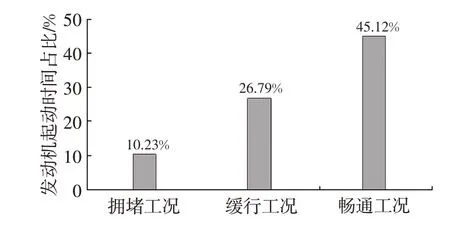
图13 不同工况下发动机起动时间与总时间比值
拥堵工况、缓行工况、畅通工况的神经网络模型分别记为NNL、NNM 和NNH,单独采用以上3 个模型,不根据工况识别结果切换进行仿真,当初始SOC值为0.7时,得到的发动机扭矩、电池SOC随时间变化曲线与DPML的对比如图14和图15所示。不同模型的燃油消耗量对比如表3所示。
SOC值下降到门限值前,NNL起动发动机的时间较短,控制规律与前文训练数据的分析相符,当SOC值下降到门限值后,发动机才开始长时间运行,与动态规划的最优控制规律不同。其燃油消耗量为1.402 7 L/(100 km),与DPML 相比,油耗增加了1.22%。由图8 可知,拥堵工况时长占总时长的44%,在该随机工况下,由于DPML 有大部分的时间切换到NNL 控制策略,所以两者的燃油经济性接近。NNM 的SOC曲线较NNL 下降更平缓,燃油消耗量为1.397 4 L/(100 km),仅比DPML增加了0.84%的油耗。由图13 可知,缓行工况下训练数据的发动机起动频率为26.79%,而在该随机工况下DPML 发动机的理论起动频率(工况类型时间占比与该工况下发动机起动频率乘积之和)为24.95%,两者十分接近,所以NNM 的燃油经济性也接近于DPML。而NNH 模型在整个工况下都更加倾向于起动发动机,所以其发动机运行时间最长。其SOC曲线虽然缓慢下降,但到终点时,还有多余电量,不能最大程度发挥PHEV 的节能潜力。
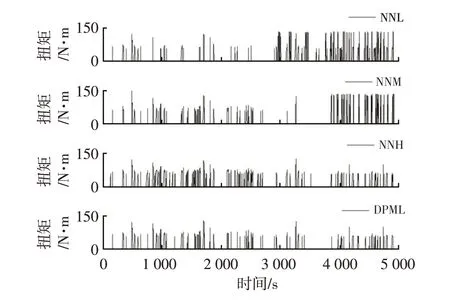
图14 发动机扭矩对比
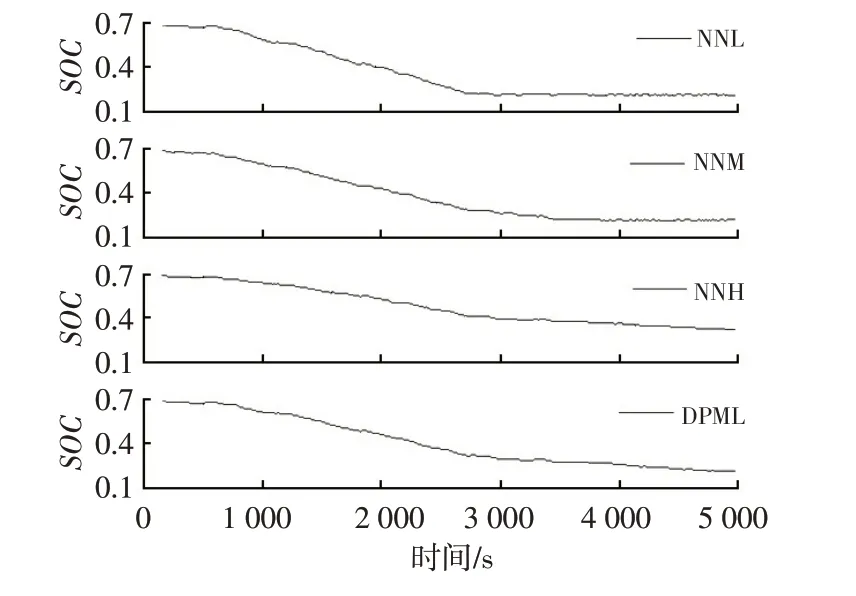
图15 SOC曲线对比
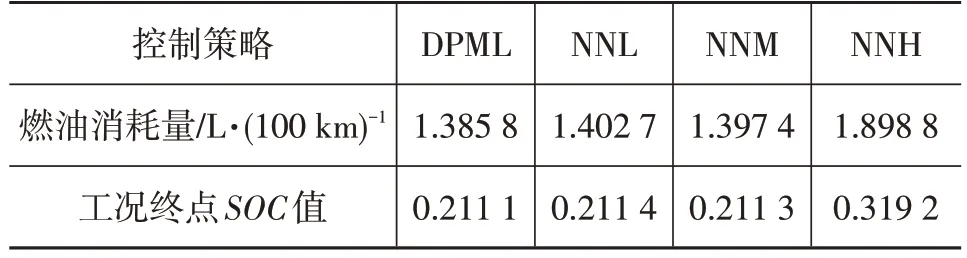
表3 不同模型的百公里油耗对比
综上所述,DPML可以根据工况类型切换神经网络模型进行控制,在拥堵的工况采用NNL模型,降低发动机运行的频率,避免发动机运行在低效区,在缓行工况采用NNM 模型,适时起动发动机,在畅通工况采用NNH模型,增大发动机运行的频率,发动机可以运行在高效区,从而提高了算法在不同工况类型下的适应性,优于单个工况类型神经网络模型,体现了根据工况类型切换相应控制模型的必要性。
5 结束语
本文设计了基于动态规划与机器学习的插电式混合动力汽车能量管理算法,首先利用K-均值聚类算法将20个标准工况划分为3个类型的工况段,然后利用动态规划算法的最优功率分配数据,分别训练3个类型工况段的神经网络模型,最后在控制过程中根据实际工况段类型选择相应的神经网络模型优化能量分配。仿真结果表明:其控制规律与动态规划算法相似,相较于CD-CS 策略,整车油耗下降了7.51%,且优于单个工况类型的神经网络模型,从而验证了本文算法的有效性。
本文的仿真结果中,基于动态规划与机器学习的算法相较于拥堵工况和缓行工况神经网络模型燃油经济性的提升有限,不同工况类型的占比会影响其优化性能,后续研究可进一步探讨工况分类的合理性以及工况类型的分布对其优化性能的影响。
猜你喜欢
客车技术与研究(2023年6期)2023-12-19 01:21:18
卫星应用(2022年7期)2022-09-05 02:36:02
卫星应用(2022年3期)2022-05-23 13:44:30
卫星应用(2022年1期)2022-03-09 06:22:20
中国煤层气(2021年5期)2021-03-02 05:53:14
环球慈善(2019年6期)2019-09-25 09:06:24
电子测试(2017年15期)2017-12-18 07:19:27
凿岩机械气动工具(2017年3期)2017-11-22 07:21:50
智能系统学报(2015年4期)2015-12-27 09:38:39
华东理工大学学报(自然科学版)(2015年4期)2015-12-01 04:00:50
